
Author's Note: Qwen3.5-35B-A3B has achieved a score of 69.2 on SWE-bench Verified with only 3B active parameters, surpassing the previous generation Qwen3-235B. It is regarded by the r/LocalLLaMA community as a milestone for open-source models catching up to closed-source ones. This article provides an in-depth analysis of its technical architecture and practical value.
The r/LocalLLaMA community has been buzzing lately: Qwen3.5-35B-A3B has achieved a score of 69.2 on SWE-bench Verified with only 3B active parameters. Not only does this outperform the previous generation 235B parameter Qwen3, but it also sets a new record for coding capabilities among locally runnable models. The community sees this as a major milestone for open-source models catching up to their closed-source counterparts—a 35B model that can run on consumer-grade hardware with coding abilities nearing the GPT-5 mini level.
Core Value: After reading this article, you'll understand why Qwen3.5-35B is causing such a stir in the open-source community, how its MoE architecture achieves "big power in a small package," and how to use it both locally and in the cloud.

Qwen3.5-35B Key Highlights
| Feature | Description | Significance |
|---|---|---|
| Total Parameters | 35 Billion (35B) | MoE Architecture |
| Active Parameters | Only 3 Billion (3B) | Extreme Efficiency |
| SWE-bench Verified | 69.2 Score | Surpasses Qwen3-235B |
| GPQA Diamond | 84.2 Score | Graduate-level Reasoning |
| Context Window | Native 256K / Extended 1M+ | YaRN Extension |
| Hardware Requirements | 22GB RAM/VRAM | Consumer-grade Ready |
| Open Source License | Apache 2.0 | Fully Open |
Why the r/LocalLLaMA community is talking about Qwen3.5-35B
r/LocalLLaMA is the most active community for local Large Language Models on Reddit, where members focus on one core question: "What model can run on my hardware while still being powerful enough?"
Qwen3.5-35B-A3B hits this requirement perfectly:
- 35B total parameters, but only 3B are activated per inference—meaning it can run smoothly on a Mac or GPU with 22GB of memory.
- Coding capability (SWE-bench 69.2) exceeds the previous generation Qwen3-235B, which has 7 times the parameter count.
- Apache 2.0 fully open-source, with no commercial restrictions.
The community's verdict: "Run Qwen 35B. It's a great chatbot, good enough for task automation." This represents the core demand of local deployment enthusiasts—capable, fast, and cost-effective.
Deep Dive into the Qwen3.5-35B Architecture
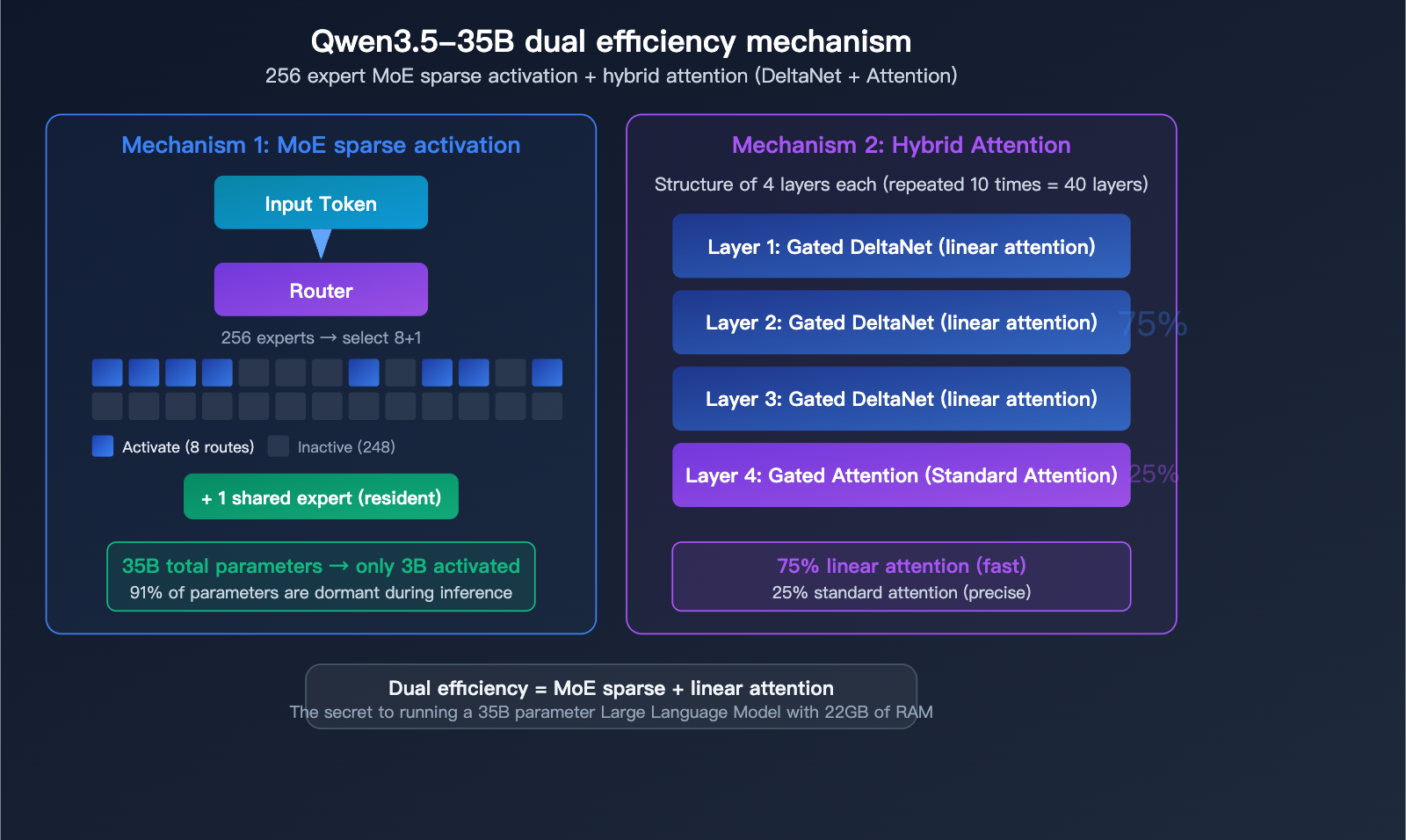
256-Expert MoE Architecture
The Qwen3.5-35B-A3B utilizes a highly granular Mixture-of-Experts (MoE) architecture:
| Architectural Parameter | Value | Description |
|---|---|---|
| Total Parameters | 35B | Sum of all expert parameters |
| Active Parameters | 3B | Activated per inference |
| Total Experts | 256 | Ultra-fine-grained specialization |
| Activated Experts | 8 Routed + 1 Shared | 9 experts selected per pass |
| Layers | 40 | Deep network |
| Hidden Dimension | 2048 | Compact design |
Hybrid Attention Mechanism
Qwen3.5-35B isn't a pure Transformer; it employs a hybrid attention design:
Every 4-layer block consists of: 3 layers of Gated DeltaNet (linear attention) + 1 layer of Gated Attention (standard attention).
| Attention Type | Layer Ratio | Characteristics |
|---|---|---|
| Gated DeltaNet | 75% | Linear attention, fast inference |
| Gated Attention | 25% | Standard attention, high precision |
The brilliance of this hybrid design lies in performing the bulk of calculations using efficient linear attention, while reserving the more computationally intensive standard attention for critical layers. This is the secret behind achieving 35B parameters while requiring only 22GB of memory—it's not just sparse expert activation; the attention mechanism itself has been optimized.
🎯 Technical Insight: The architectural design of Qwen3.5-35B represents the latest 2026 trend for MoE models—256-expert ultra-fine granularity combined with hybrid attention. If you want to experience the efficiency gains of this architecture, you can invoke the Qwen3.5 series API directly via APIYI (apiyi.com), with no local deployment required.
A Comprehensive Breakdown of Qwen3.5-35B Benchmark Data
Qwen3.5-35B Programming Benchmarks
| Benchmark | Qwen3.5 35B-A3B | Comparison | Notes |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | Outperforms predecessor 7x its size |
| LiveCodeBench v6 | 74.6 | – | Strong real-time coding |
| CodeForces | 2,028 | – | Competitive programming level |
Qwen3.5-35B Reasoning and Knowledge Benchmarks
| Benchmark | Qwen3.5 35B-A3B | Notes |
|---|---|---|
| GPQA Diamond | 84.2 | Graduate-level scientific reasoning |
| MMLU-Pro | 85.3 | Multi-disciplinary knowledge |
| MMLU-Redux | 93.3 | Knowledge comprehension |
| HMMT Feb 2025 | 89.0 | Math competition |
| IFEval | 91.9 | Instruction following |
Qwen3.5-35B Multimodal Benchmarks
| Benchmark | Qwen3.5 35B-A3B | Notes |
|---|---|---|
| MMMU | 81.4 | Multimodal understanding (approaching Claude Sonnet 4.5's 79.6) |
| MMMU-Pro | 75.1 | High-difficulty multimodal |
| MathVision | 83.9 | Visual math reasoning |
| VideoMME | 86.6 | Video understanding |
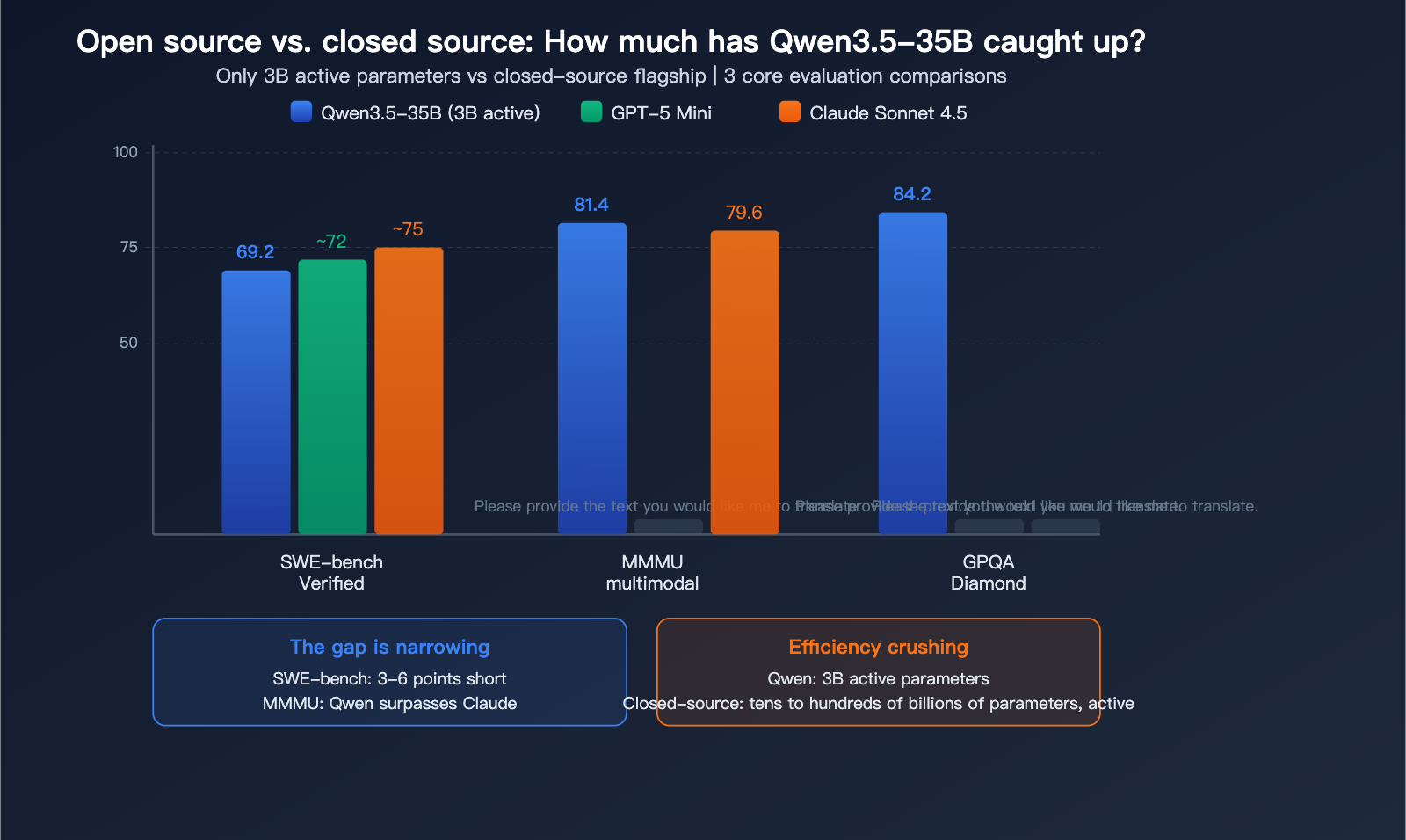
Qwen3.5-35B vs. Closed-Source Models
This is the question on everyone's mind: just how close can an open-source 35B model get to closed-source giants?
| Dimension | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Gap |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | 3-6 points |
| MMMU | 81.4 | – | 79.6 | Outperformed |
| GPQA Diamond | 84.2 | – | – | Top-tier |
| Active Parameters | 3B | ~Tens of B | Unknown | Efficiency win |
| Local Run | Yes (22GB) | No | No | Unique advantage |
The Community Consensus: The gap between Qwen3.5-35B and GPT-5 Mini-level models in programming has narrowed to just 3-6 points, and it even outperforms Claude Sonnet 4.5 in multimodal tasks. Considering it only requires 3B active parameters and can run locally, its efficiency-to-capability ratio is likely the highest among all publicly available models.
💡 Pro Tip: If you want to compare the real-world performance of Qwen3.5-35B against closed-source models, you can use APIYI (apiyi.com) to perform A/B testing on your own tasks by invoking Qwen3.5, Claude, and GPT simultaneously.
Qwen3.5-35B Local Deployment Guide
Hardware Requirements and Deployment Methods
| Deployment Method | Hardware Requirements | Recommended Scenario |
|---|---|---|
| Ollama | 22GB+ RAM/VRAM | Simplest, one-click run |
| vLLM | GPU + 24GB+ VRAM | Production-grade throughput |
| SGLang | GPU + 24GB+ VRAM | High throughput recommended |
| KTransformers | CPU + GPU Hybrid | Lower-end hardware |
| LM Studio | 22GB+ RAM | GUI-friendly |
One-Click Deployment with Ollama
# Run with a single command after installation
ollama run qwen3.5:35b
Model Invocation via API (No Local Deployment Required)
If you'd rather skip the hassle of local deployment, using an API is the easiest way to get started:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Help me review this Python code and identify performance bottlenecks."
}],
temperature=0.6, # 0.6 is recommended for programming tasks
max_tokens=32768
)
print(response.choices[0].message.content)
Switching Between Thinking and Non-Thinking Modes
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking mode (Deep reasoning, suitable for complex tasks)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Analyze the time complexity of this algorithm."}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Non-Thinking mode (Fast response)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Write a quicksort function."}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Deployment Advice: Local deployment is great for privacy-sensitive and offline scenarios. For daily development, we recommend using the APIYI (apiyi.com) API proxy service—it's faster, requires no hardware maintenance, and lets you switch freely between Qwen3.5, Claude, and GPT.
Overview of the Qwen3.5 Model Family
Qwen3.5 Series Specification Comparison
| Model | Total Parameters | Active Parameters | SWE-bench | Min. Memory | Positioning |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | – | 8GB | Lightweight entry-level |
| Qwen3.5-9B | 9B | 9B (Dense) | – | 12GB | Efficient daily use |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22GB | Dense high-precision |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | Efficiency king |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | Mid-to-high end |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | Flagship |
Selection Advice:
- 22GB Devices: Choose 35B-A3B (MoE, fast but slightly lower precision) or 27B (Dense, slightly slower but more accurate).
- Best Cost-Performance Ratio: 35B-A3B, using only 3B parameters per inference.
- Highest Precision: 27B Dense, which avoids the MoE route.
🎯 API Selection: You can access the entire Qwen3.5 series via APIYI (apiyi.com), choosing from 4B to 397B as needed. A single API key allows you to flexibly switch between different Qwen model sizes and closed-source models like Claude and GPT.
FAQ
Q1: Should I choose Qwen3.5-35B or 27B?
Both require about 22GB of memory. The 35B-A3B uses a MoE architecture (3-5x faster but slightly lower precision), while the 27B uses a Dense architecture (more precise but slower). There isn't a huge gap in programming tasks (SWE-bench 69.2 vs 72.4). For daily conversations, I'd recommend the 35B for its speed, while the 27B is better for tasks requiring high precision. You can compare both side-by-side using the APIYI apiyi.com API proxy service.
Q2: Are open-source models really catching up to closed-source ones?
Yes, but with caveats. Qwen3.5-35B has surpassed Claude Sonnet 4.5 on MMMU (81.4 vs 79.6), and it's only 3 points behind GPT-5 Mini on SWE-bench. However, for the most challenging programming tasks and complex reasoning, closed-source flagships (like Claude Opus 4.5 or GPT-5.4) still hold a clear advantage. Open-source is definitely closing the gap, but it hasn't fully caught up to the top-tier closed-source models yet.
Q3: Can a 22GB Mac run Qwen3.5-35B?
Yes, it can. Qwen3.5-35B-A3B only activates 3B parameters per inference, so a Mac with 22GB of unified memory (like the base M2/M3/M4 configurations) can run it smoothly. I recommend using Ollama (ollama run qwen3.5:35b) for a one-click setup. If you'd rather not deploy it locally, using it via the cloud through APIYI apiyi.com is even more convenient.
Summary
Here are 5 key takeaways regarding how Qwen3.5-35B has set a new record for open-source programming:
- Efficiency Revolution: With 35B total parameters and only 3B active, it runs on 22GB of memory while outperforming the previous generation of 235B models in programming.
- Programming Prowess: With scores of 69.2 on SWE-bench, 2028 on CodeForces, and 74.6 on LiveCodeBench, it's the new benchmark for local models.
- Architectural Innovation: Features a 256-expert MoE + hybrid attention (DeltaNet + standard Attention), offering the best balance between efficiency and capability.
- Closing the Gap: It has surpassed Claude Sonnet 4.5 on MMMU and is nearing GPT-5 Mini on SWE-bench; the gap is shrinking.
- Fully Open: Released under the Apache 2.0 license with no commercial restrictions, making local deployment cost-free.
Qwen3.5-35B proves one thing: Open-source models are no longer just "budget" versions of closed-source ones; they are catching up and even surpassing them with much higher efficiency. I recommend using APIYI apiyi.com to access the full Qwen3.5 series alongside closed-source models, allowing you to compare their performance on your specific tasks with a single API key.
📚 References
-
Qwen3.5-35B-A3B Model Card – Hugging Face: Complete technical specifications and evaluation data.
- Link:
huggingface.co/Qwen/Qwen3.5-35B-A3B - Description: Includes architecture details, benchmark scores, and recommended inference parameters.
- Link:
-
Qwen3.5 GitHub Repository: Open-source code and deployment guides.
- Link:
github.com/QwenLM/Qwen3.5 - Description: Contains links for full model weight downloads and deployment documentation.
- Link:
-
Qwen3.5 Complete Guide: Full series evaluation and architectural analysis.
- Link:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Description: Detailed comparison of the entire model family and head-to-head reviews against closed-source models.
- Link:
-
Ollama – Qwen3.5:35B: One-click local deployment.
- Link:
ollama.com/library/qwen3.5:35b - Description: The easiest way to run the model locally.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to share your experience with local Qwen3.5 deployment in the comments. For more resources on AI model integration, visit the APIYI documentation center at docs.apiyi.com.