
Google hat am 19. Mai 2026 auf der Google I/O 2026 offiziell die Gemini Omni multimodale Modellfamilie vorgestellt, wobei das erste Modell, Gemini Omni Flash, noch am selben Tag für Nutzer freigeschaltet wurde. Für Neulinge, die diesen Namen zum ersten Mal hören, ist der Begriff „Omni“ weit wichtiger, als man zunächst annehmen könnte – er steht für die neue Ausrichtung von Google, die intelligenten Schlussfolgerungsfähigkeiten von Gemini mit Medien-Generierungsfunktionen vollständig zu verschmelzen. In diesem Artikel erfahren Sie in nur 5 Minuten auf verständliche Weise, was Google Omni ist, was es leisten kann, wie es sich von dem früheren Veo unterscheidet und wie Sie als Entwickler oder Creator damit starten können.
Kernnutzen: Nach dem Lesen dieses Artikels kennen Sie die Positionierung, die Leistungsgrenzen, die Zugangskanäle und die Branchenbedeutung von Google Omni (Gemini Omni) und lassen sich nicht mehr von den Fachbegriffen in den Schlagzeilen verwirren.
Was ist Google Omni: Ein Überblick über die Kerninformationen
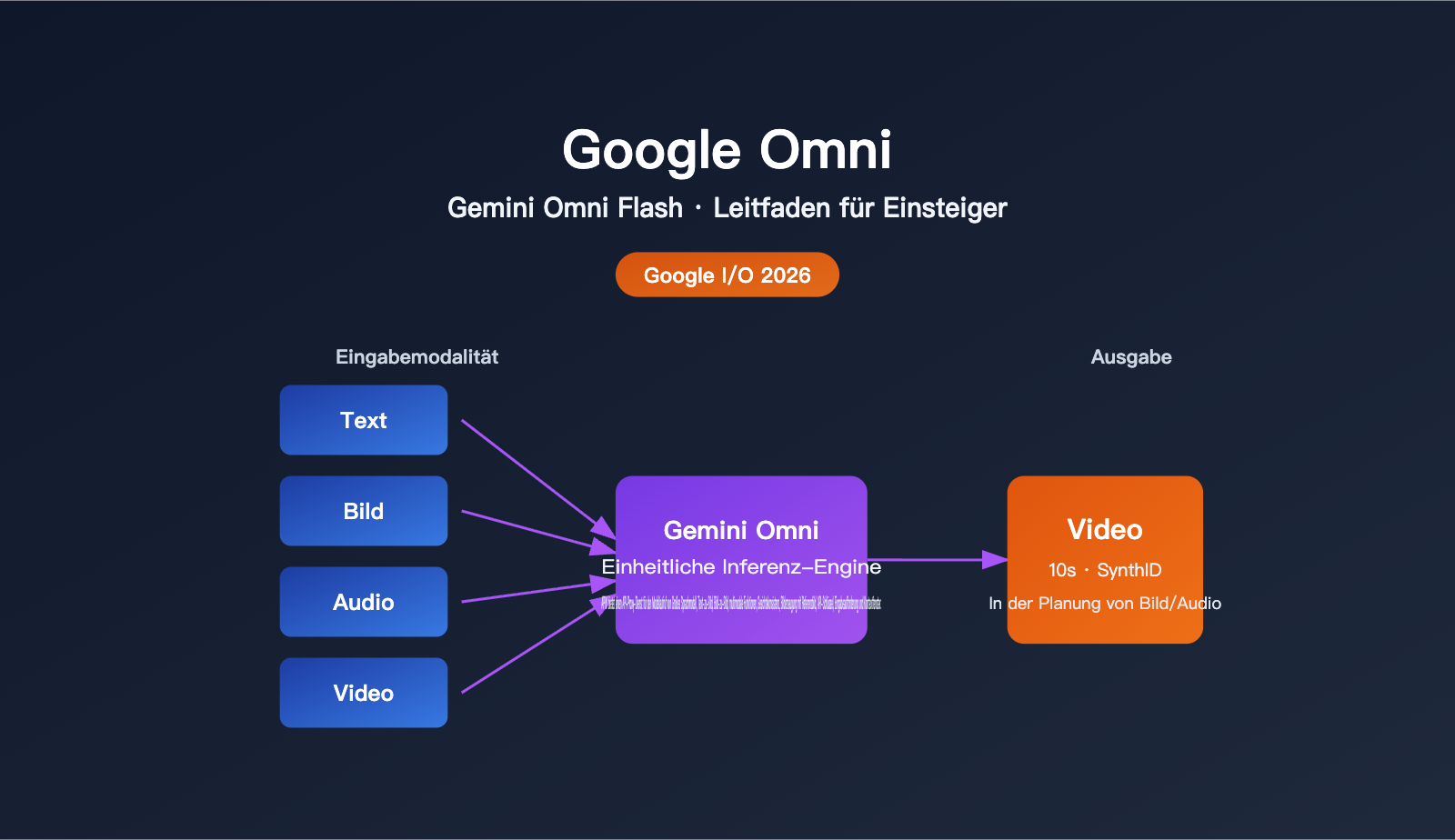
Kurz zusammengefasst: Google Omni ist die von Google eingeführte „multimodale Generierungsmodellfamilie“, deren erstes Modell Gemini Omni Flash ist. Das wichtigste Verkaufsargument ist nicht „ein weiterer KI-Videogenerator“, sondern die Fähigkeit, „Text, Bilder, Audio und Video beliebig zu kombinieren, um sie einheitlich zu verarbeiten und daraus ein zusammenhängendes Video zu erstellen“.
Google-CEO Sundar Pichai beschrieb die Positionierung in seiner Keynote sehr treffend: „create anything from any input“. Anders ausgedrückt: Früher benötigte man ein Modell, um ein Bild zu generieren, und ein weiteres, um dieses Bild in ein Video umzuwandeln; Omni versucht, die gesamte multimodale Schlussfolgerung und Generierung mit einem einzigen Modell abzudecken.
| Information | Details |
|---|---|
| Veröffentlichungsdatum | 19. Mai 2026 (Google I/O 2026) |
| Herausgeber | Google (Google DeepMind & Google Labs) |
| Erstes Modell | Gemini Omni Flash |
| Modellpositionierung | Einheitliche Modellfamilie für multimodale Schlussfolgerung + Mediengenerierung |
| Eingabemodalitäten | Text, Bild, Video, Audio (beliebige Kombination) |
| Ausgabemodalität | Video (zunächst im Fokus), Bild und Audio folgen später |
| Maximale Dauer | Bis zu 10 Sekunden (Einschränkung in der Bereitstellungsphase, kein Modell-Limit) |
| Inhaltskennzeichnung | Alle Videos enthalten automatisch ein unsichtbares SynthID-Wasserzeichen |
| Zukunftsplanung | Gemini Omni Pro (Pro-Version), längere Dauer, Audio-Bearbeitungsfunktionen |
💡 Tipp für Neulinge: Wenn Sie die verschiedenen Mainstream-Modelle, einschließlich der Gemini-Serie, sofort ausprobieren möchten, können Sie APIYI (apiyi.com) nutzen, um sie über eine einheitliche Schnittstelle aufzurufen und sich die mühsame Registrierung auf jeder Plattform zu sparen.
Interpretation der Kernfähigkeiten von Google Omni: Warum es als „neue Generation“ gilt
Wenn man nur auf „Input und Output“ achtet, könnte man Omni leicht in die gleiche Kategorie wie Videomodelle wie Sora, Veo oder Runway stecken. Doch Nicole Brichtova, Product Director bei Google, lieferte eine präzisere Einordnung: „Dies ist der nächste Schritt, der die Intelligenz von Gemini mit den Rendering-Fähigkeiten von Medienmodellen kombiniert.“ Die folgenden vier Fähigkeiten sind für Einsteiger entscheidend, um den Unterschied zwischen Omni und herkömmlichen Videomodellen zu verstehen.
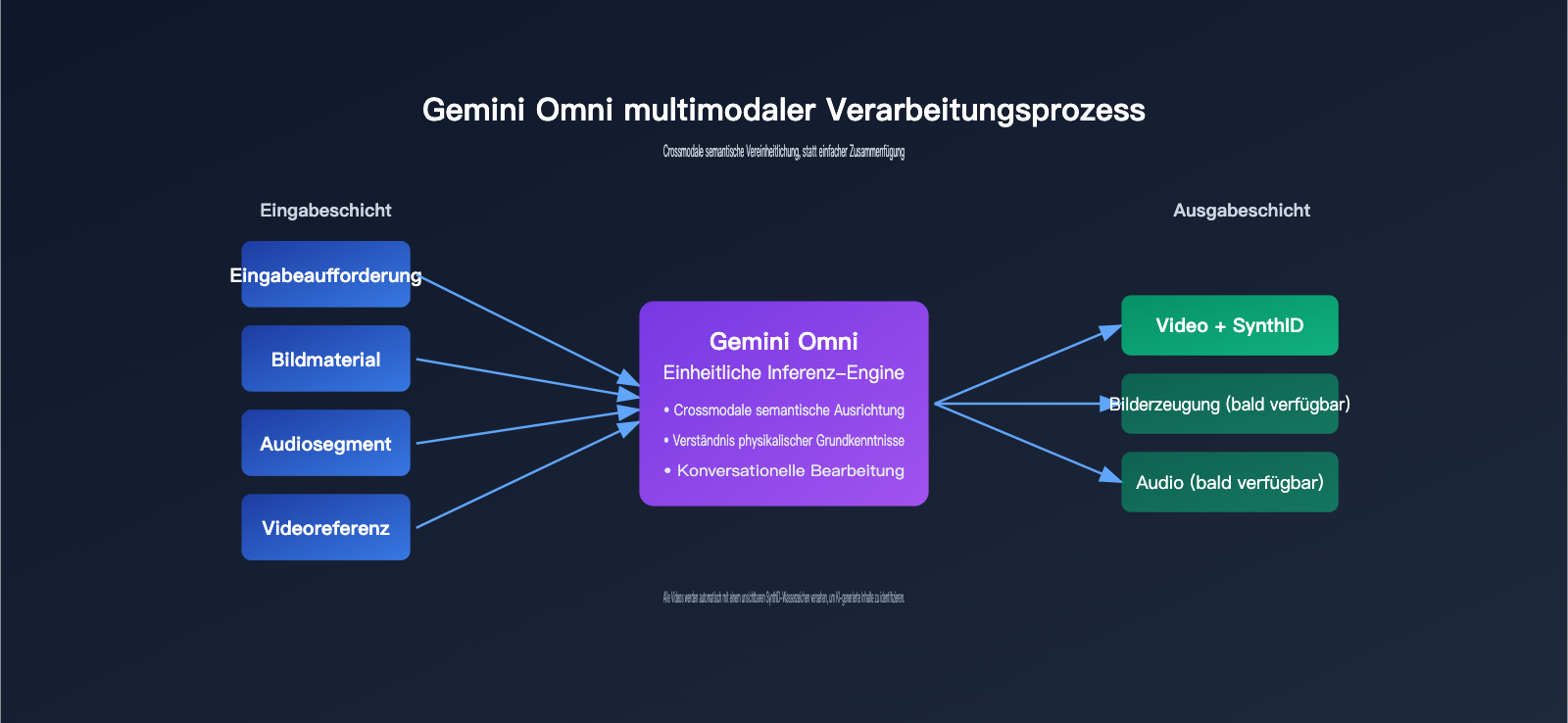
1. Multimodale Schlussfolgerung statt einfacher Zusammenfügung
Herkömmliche Videogenerierung folgt oft einem zweistufigen Prozess: „Text → Video“ oder „Bild + Text → Video“. Der Ansatz von Gemini Omni besteht darin, alle Eingaben in dasselbe Modell einzuspeisen, damit es intern ein einheitliches semantisches Verständnis aufbaut und das Video in einem einzigen Durchgang rendert.
Ein Beispiel: Wenn Sie ein Produktfoto, einen Hintergrundtrack und einen Werbetext gleichzeitig an Omni übergeben, versteht das Modell, dass „das Produkt beim Rhythmuswechsel erscheinen muss“ und „der Text mit den Bewegungen im Bild korrespondieren sollte“, anstatt die Musik einfach nur über das Video zu legen. Diese Fähigkeit, „erst zu verstehen und dann zu generieren“, entspringt der logischen DNA des Gemini-Modells selbst.
2. Physikalisches Verständnis und Weltwissen
Google demonstrierte in der Präsentation zwei Beispiele: eine Aufnahme einer rollenden Achatkugel, bei der das Abprallen, Verweilen und die Kollisionsgeräusche der physikalischen Realität entsprechen; und eine lehrreiche Animation im Claymation-Stil über Proteinfaltung, deren geometrische Struktur den Grundlagen der Molekularbiologie entspricht. Diese Demos wirken simpel, basieren jedoch auf dem Verständnis des Modells für „Gesetzmäßigkeiten der realen Welt“ und nicht nur auf einer pixelbasierten Annäherung.
Für Einsteiger bedeutet dies, dass von Omni generierte Videos weniger anfällig für typische KI-Videofehler wie „objektive Teleportation“, „fehlerhafte Licht- und Schatteneffekte“ oder „überzählige Finger“ sind.
3. Konversationsbasierte iterative Bearbeitung
Omni unterstützt das Prinzip „erst generieren, dann mit natürlicher Sprache bearbeiten“. Nachdem das Modell ein Video erstellt hat, können Sie sagen: „Ändere den Hintergrund in einen Sonnenuntergang“ oder „Lass die Kamera langsamer schwenken“. Das Modell nimmt lokale Anpassungen vor, während die Konsistenz von Personen, Szenen und Bewegungen gewahrt bleibt.
Diese Interaktionsweise ähnelt eher einem Gespräch mit einem Cutter, als einmalig einen langen Prompt zu schreiben. Dies ist besonders einsteigerfreundlich für Nutzer ohne Erfahrung im Bereich Prompt-Engineering.
4. Benutzerdefinierte digitale Avatare
Omni ermöglicht es Benutzern, durch eine biometrische Verifizierung ihren eigenen digitalen Avatar zu erstellen und diesen in generierte Videos einzubetten. Google betont, dass dieser Schritt zwingend vom Nutzer selbst durchgeführt werden muss, um das Risiko des Missbrauchs durch Deepfakes zu minimieren.
🎯 Zusammenfassung der Fähigkeiten: Der Schlüssel bei Omni liegt nicht in „höherer Auflösung“ oder „längerer Dauer“, sondern im Trio aus „multimodaler Schlussfolgerung + physikalischem Verständnis + konversationsbasierter Bearbeitung“. Um diese Fähigkeiten in eigene Produkte zu integrieren, empfehlen wir, die Effekte verschiedener Modellkombinationen über aggregierte Schnittstellen wie APIYI (apiyi.com) zu testen, bevor Sie sich für eine Hauptlösung entscheiden.
Was ist der Unterschied zwischen Gemini Omni und Veo: Die zwei Namen, die Einsteiger am häufigsten verwechseln
Viele Einsteiger fragen: Hat Google nicht schon Veo, was macht dann Omni? Das ist eine sehr berechtigte Frage, da beide „Videos generieren können“, aber ihre Positionierung ist völlig unterschiedlich. Die folgende Tabelle ist der schnellste Weg für Einsteiger, den Zusammenhang zwischen beiden zu verstehen.
| Vergleichsdimension | Veo | Gemini Omni |
|---|---|---|
| Modelltyp | Spezialisiertes Medienmodell | Multimodale Schlussfolgerung + einheitliches Mediengenerierungsmodell |
| Input-Unterstützung | Text, Bild | Text + Bild + Audio + Video (beliebige Kombination) |
| Schlussfolgerungstiefe | Fokus auf Rendering-Ebene | Nutzung von Gemini-Schlussfolgerung, einheitliche multimodale Semantik |
| Bearbeitungsmodus | Fokus auf Neu-Generierung | Unterstützt konversationsbasierte inkrementelle Bearbeitung |
| Physikalisches Verständnis | Durchschnittlich | Deutlich verbessert (offiziell in Demos hervorgehoben) |
| Zielgruppe | Professionelle Videocreator | Creator + Endverbraucher + Entwickler |
| Aktuelle Positionierung | Hochwertiges Videogenerierungstool | Multimodales „Create anything“-Basismodell |
Ein einfacher Vergleich: Veo ist wie ein High-Fidelity-Drucker – man gibt ihm ein Bild und er liefert ein exzellentes Ergebnis. Omni hingegen ist wie ein Allround-Assistent, der Ihre Absichten versteht; Sie werfen ihm einfach einige Materialien und eine Anforderung in einem Satz hin, und er liefert das fertige Video. Beide werden in Zukunft wahrscheinlich koexistieren, aber Omni repräsentiert den Weg der „einheitlichen Multimodalität“, auf den Google setzt.

🧭 Empfehlung für Einsteiger: Wenn Sie nur hochwertige Kurzfilme generieren möchten, ist Veo nach wie vor ausreichend. Wenn Sie Anwendungsszenarien mit „gemischtem Input aus Text, Bild, Audio und Video“ entwickeln, ist Omni die passendere Richtung. Um die tatsächliche Leistung dieser beiden Modelltypen schnell zu vergleichen, empfehlen wir A/B-Tests über eine Schnittstelle wie APIYI (apiyi.com), die den Wechsel zwischen verschiedenen Modellen unterstützt, sodass Sie innerhalb desselben Codes den Prozess beibehalten, aber das Modell austauschen können.
Gemini Omni Flash nutzen: Ein Leitfaden für Einsteiger
Zum Zeitpunkt der Veröffentlichung wurde Gemini Omni Flash verschiedenen Nutzergruppen zugänglich gemacht, jedoch über unterschiedliche Kanäle. Die folgende Vergleichstabelle hilft Einsteigern dabei, schnell zu entscheiden, wo sie am besten starten.
| Benutzertyp | Empfohlener Zugang | Kostenpflichtig | Anmerkung |
|---|---|---|---|
| Privatnutzer | Gemini App | Erfordert Google AI Plus/Pro/Ultra Abo | Persönliche Kreativität, Kurzvideos |
| Content Creator | Google Flow | Erfordert Google AI Abo | Für professionelle kreative Workflows |
| Kurzvideo-Nutzer | YouTube Shorts, YouTube Create App | Kostenlos | Zeitlich begrenzte kostenlose Testversion, ideal für den Einstieg |
| Entwickler / Unternehmen | Google API (bald verfügbar) | Preisgestaltung noch offen | Start in wenigen Wochen, Ankündigungen verfolgen |
| Modell-Evaluatoren | Drittanbieter-API-Plattformen | Je nach Plattform | Ideal für Teams, die mehrere Modelle vergleichen |
Der einfachste Weg für Einsteiger
- Wenn Sie bisher keine kostenpflichtigen KI-Tools nutzen, empfehle ich, die kostenlose Omni-Bilderzeugung über YouTube Shorts oder die YouTube Create App auszuprobieren. Dies ist der Zugang mit der niedrigsten Hürde.
- Wenn Sie bereits ein Google AI Plus-Abo (oder höher) besitzen, öffnen Sie einfach die Gemini App. Dort finden Sie den Zugang zur Omni-Bilderzeugung direkt im Kreativ-Panel.
- Als Entwickler ist es derzeit am sinnvollsten, die Funktionen zunächst als Endnutzer zu testen, während Sie auf die offizielle API warten. Nutzen Sie in der Zwischenzeit APIYI (apiyi.com), um bereits verfügbare Gemini-Modelle anzubinden und Ihre multimodale Pipeline vorzubereiten.
Ein Beispiel für einen minimalen Modellaufruf (nach Veröffentlichung der offiziellen API)
Obwohl die offizielle Entwickler-API für Omni noch „einige Wochen entfernt“ ist, können wir die Aufrufstruktur bereits vorab entwerfen, um sie nach der Freigabe direkt zu implementieren.
# Beispiel für einen aggregierten Modellaufruf (Struktur-Schema, nach Freigabe der Omni-API einfach das Modell ersetzen)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche Anbindung über APIYI
)
# Aktuell verfügbarer Aufruf für bereits veröffentlichte Gemini-Modelle
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "Erkläre den Kernwert multimodaler Modelle in einem Satz"}]
)
print(response.choices[0].message.content)
💡 Tipp für den schnellen Start: Sie müssen nicht warten, bis alle offiziellen APIs verfügbar sind. Nutzen Sie APIYI (apiyi.com), um Ihre Workflows mit anderen Gemini-Modellen aufzubauen. Sobald die Omni-API erscheint, müssen Sie lediglich den Modellnamen austauschen – die Migrationskosten sind nahezu null.
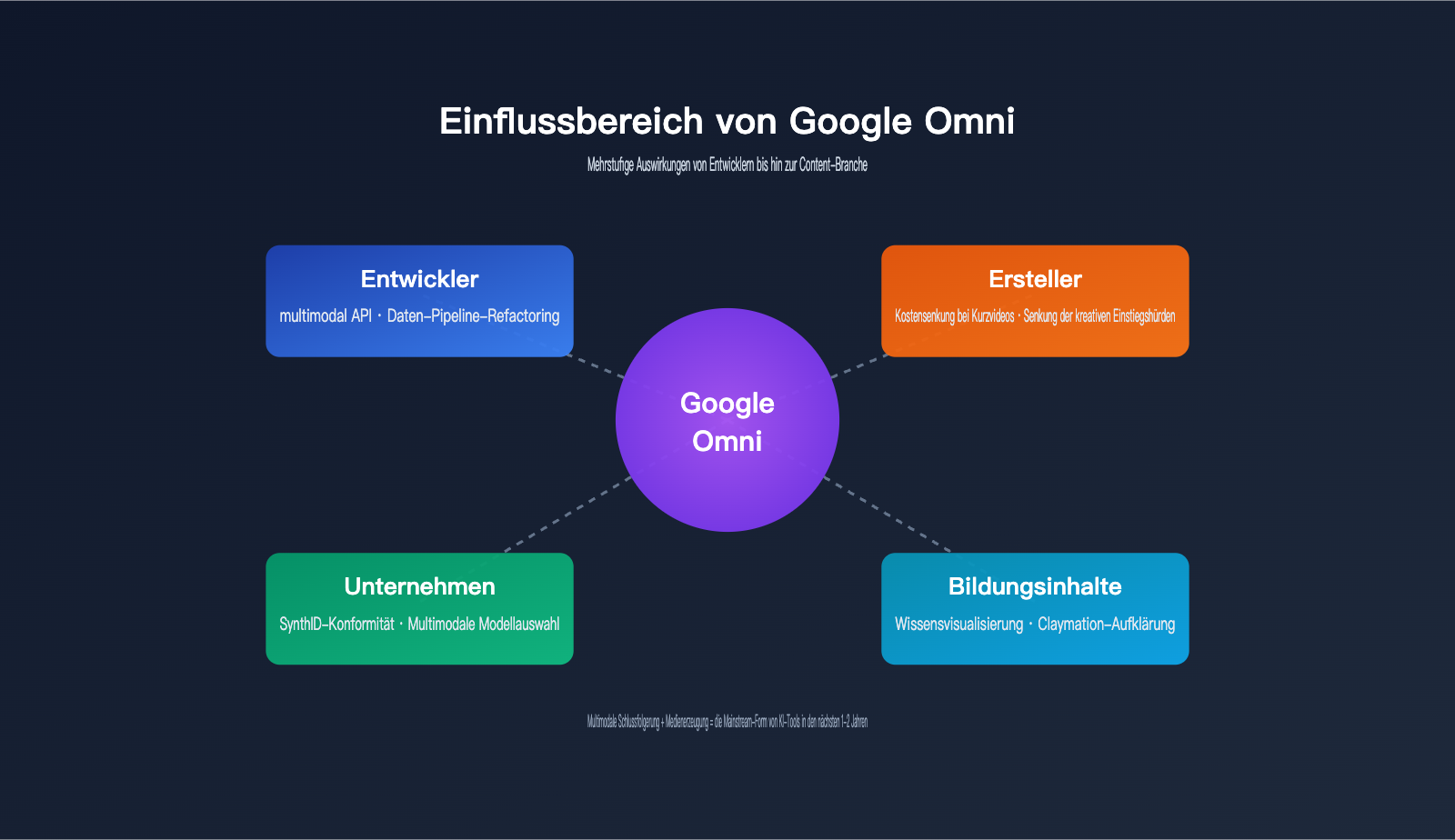
Auswirkungen von Google Omni auf Entwickler und die Branche
Viele Einsteiger fragen sich: Was bedeutet dieses neue Modell für mich? Die Antwort fällt je nach Zielgruppe unterschiedlich aus.
Auswirkungen auf Entwickler
| Aspekt | Konkrete Auswirkung |
|---|---|
| Aufruf-Logik | Multimodale Eingabeaufforderungen ersetzen die „Text-zu-Bild-zu-Video“-Pipeline |
| Toolchain | SDKs müssen für „Video-/Audio-Input-Streams“ statt nur für Text angepasst werden |
| Compliance | SynthID-Wasserzeichen werden zum Standard; Planung für Erkennung und Anzeige erforderlich |
| Kostenstruktur | Kosten pro Generierung könnten höher sein als bei Text; präzises Monitoring erforderlich |
Für Ingenieure, die KI-Anwendungen entwickeln, sendet Omni ein klares Signal: Die KI-Schnittstellen der Zukunft sind nicht mehr „Text rein, Text raus“, sondern „multimodal rein, multimodal raus“. Wer seine Datenpipelines frühzeitig umstellt und Assets nach Modalitäten verwaltet, hat beim Start der Omni-API einen entscheidenden Vorsprung.
Auswirkungen auf die Content-Branche
Kurzvideoplattformen, Werbeagenturen und Produzenten von Bildungsinhalten profitieren am stärksten. Ein 10-sekündiges, hochwertiges Video, das früher Stunden an Schnittarbeit erforderte, kann mit Omni Flash in wenigen Minuten als erster Entwurf erstellt werden. Für kleinere Creator sinkt die Hürde „vom Bild zum fertigen Video“ massiv.
Beachten Sie jedoch: Die obligatorische Einbettung des SynthID-Wasserzeichens macht „KI-generierte Inhalte“ zunehmend transparent. Plattformen, Marken und Regulierungsbehörden werden ihre Strategien zur Kennzeichnung und Prüfung von Inhalten entsprechend anpassen.
Auswirkungen auf Unternehmenskunden
Unternehmenskunden interessieren sich primär für zwei Dinge: Compliance/Markensicherheit und Skalierbarkeit der Kosten. Das SynthID-Wasserzeichen löst einen Teil der ersten Frage; die zweite hängt von der zukünftigen Preisgestaltung der Google-API ab. Für kostenbewusste Teams ist es ratsam, über Plattformen wie APIYI (apiyi.com) die Video- oder multimodalen Fähigkeiten verschiedener Anbieter wie Gemini, GPT oder Claude zu vergleichen, um eine fundierte Entscheidung basierend auf Kosten und Qualität zu treffen.
Häufig gestellte Fragen
Q1: Sind Google Omni und Gemini Omni dasselbe?
Ja. Google Omni ist eine inoffizielle Kurzbezeichnung; die offizielle Bezeichnung von Google lautet „Gemini Omni“ und gehört zum multimodalen Zweig der Gemini-Modellfamilie. Gemini Omni Flash ist das erste Modell dieser Reihe. Beide Namen beziehen sich auf dieselbe Technologie.
Q2: Können Neulinge Gemini Omni derzeit kostenlos ausprobieren?
Ja. Der direkteste Weg ist die Nutzung der Omni-Videogenerierungsfunktion in YouTube Shorts oder der YouTube Create App, die derzeit für Creator kostenlos zugänglich ist. Wenn Sie es innerhalb der Gemini-App nutzen möchten, ist ein Abonnement von Google AI Plus, Pro oder Ultra erforderlich.
Q3: Warum ist ein Videoclip bei Gemini Omni auf 10 Sekunden begrenzt?
Dies ist eine Einschränkung der aktuellen Bereitstellungsphase und nicht die Obergrenze der Modellkapazität. Die offizielle Erklärung lautet: „In Zeiten hoher Rechenlast wollen wir die Funktionen zunächst für mehr Nutzer zugänglich machen.“ Zukünftige Modelle wie Omni Pro werden die Videolänge schrittweise erweitern.
Q4: Beeinträchtigt das SynthID-Wasserzeichen die Videoqualität oder die kommerzielle Nutzung?
Nein. SynthID ist ein unsichtbares Wasserzeichen, das für das menschliche Auge nicht wahrnehmbar ist und die Bildqualität nicht beeinträchtigt. Es dient dazu, dass Plattformen und Tools während der Verbreitung von Inhalten erkennen können, dass „dieses Video von einer KI generiert wurde“. Die kommerzielle Nutzung muss den Nutzungsbedingungen von Google entsprechen.
Q5: Was sollten Entwickler jetzt vorbereiten?
Erstens: Machen Sie sich mit der Logik von multimodalen Eingabeaufforderungen vertraut, anstatt nur textbasierte Eingabeaufforderungen zu schreiben. Zweitens: Strukturieren Sie Ihre Materialbibliothek und kategorisieren Sie diese nach Modalitäten. Drittens: Testen Sie den Modellaufruf-Prozess frühzeitig. Wir empfehlen die Nutzung von APIYI (apiyi.com), um die bestehenden Gemini-Modelle über eine einheitliche Schnittstelle aufzurufen, damit Sie nahtlos wechseln können, sobald die Omni-API offiziell verfügbar ist.
Q6: Wird Gemini Omni Veo ersetzen?
Kurzfristig nicht. Veo bleibt der Standard für hochwertige, spezialisierte Videogenerierung, während Omni die einheitliche Richtung von „multimodaler Schlussfolgerung + Mediengenerierung“ repräsentiert. Es ist wahrscheinlicher, dass beide Modelle in unterschiedlichen Szenarien koexistieren.
Zusammenfassung: Drei Dinge, die sich Neulinge merken sollten
Erstens: Das Wesen von Gemini Omni ist ein einheitliches Modell für „übergreifende multimodale Schlussfolgerung + Mediengenerierung“ und nicht einfach nur „eine weitere Video-KI“. Seine differenzierte Leistungsfähigkeit zeigt sich in den drei Dimensionen: physikalisches Verständnis, dialogbasierte Bearbeitung und multimodale Schlussfolgerung.
Zweitens: Der schnellste Weg für Neulinge zum Ausprobieren ist der kostenlose Zugang über YouTube Shorts oder die YouTube Create App, gefolgt von den Abonnement-Kanälen der Gemini-App. Die Entwickler-API befindet sich in der Phase „Einführung in den kommenden Wochen“ – Sie können also bereits mit der Architekturplanung beginnen.
Drittens: Omni wird Ihre vertrauten Werkzeuge nicht sofort ersetzen, aber es repräsentiert die Hauptform der multimodalen KI in den nächsten 1-2 Jahren. Wenn Sie die Eingabe- und Ausgabemethoden, die SynthID-Compliance-Anforderungen und die Positionierungsunterschiede zu Veo frühzeitig verstehen, ersparen Sie sich bei der nächsten Welle von KI-Tool-Upgrades unnötige Umwege. Wenn Sie Gemini, GPT, Claude und andere führende Modelle über eine einzige Schnittstelle aufrufen möchten, ist APIYI (apiyi.com) derzeit die komfortabelste Lösung, die Ihnen auch den sofortigen Zugriff auf die Gemini Omni API ermöglicht, sobald diese offiziell freigeschaltet wird.
Referenzen
-
Offizieller Google-Blog – Ankündigung von Gemini Omni
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - Beschreibung: Autoritative Einführung von Google zur Positionierung und den Fähigkeiten von Gemini Omni.
- Link:
-
TechCrunch – Tiefenbericht zu Gemini Omni
- Link:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - Beschreibung: Zitate und wichtige Stellungnahmen von Sundar Pichai und Nicole Brichtova.
- Link:
-
9to5Google – Erfahrungsbericht zu Gemini Omni Flash
- Link:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - Beschreibung: Enthält Beschreibungen der offiziellen Demos und Informationen zur Verfügbarkeit über verschiedene Kanäle.
- Link:
APIYI-Team | Für weitere Updates zu KI-Großsprachmodellen und praktische Anleitungen besuchen Sie APIYI unter apiyi.com. Dort erhalten Sie kostenlose Testguthaben und können über eine einheitliche Schnittstelle auf verschiedene führende Modelle, einschließlich der Gemini-Serie, zugreifen.