
Anmerkung des Autors: Das Qwen3.5-35B-A3B erreicht mit nur 3 Mrd. aktiven Parametern 69,2 Punkte im SWE-bench Verified-Benchmark und übertrifft damit das Vorgängermodell Qwen3-235B. In der r/LocalLLaMA-Community gilt dies als Meilenstein für Open-Source-Modelle, die zu proprietären Lösungen aufschließen. Dieser Artikel analysiert die technische Architektur und den praktischen Nutzen.
Die r/LocalLLaMA-Community diskutiert derzeit intensiv: Das Qwen3.5-35B-A3B erreicht mit nur 3 Mrd. aktiven Parametern 69,2 Punkte im SWE-bench Verified-Benchmark. Damit übertrifft es nicht nur das Vorgängermodell Qwen3 mit 235 Mrd. Parametern, sondern setzt auch neue Maßstäbe für die Programmierfähigkeiten lokal ausführbarer Modelle. Die Community sieht darin ein wichtiges Signal, dass Open-Source-Modelle zu proprietären Modellen aufschließen – ein 35B-Modell, das auf Consumer-Hardware läuft und dessen Programmierfähigkeiten nahezu das Niveau von GPT-5 mini erreichen.
Kernnutzen: Nach der Lektüre dieses Artikels verstehen Sie, warum das Qwen3.5-35B in der Open-Source-Community für Aufsehen sorgt, wie seine MoE-Architektur „große Leistung bei geringem Ressourcenverbrauch“ ermöglicht und wie Sie es lokal sowie in der Cloud einsetzen können.

Qwen3.5-35B Kernpunkte
| Punkt | Beschreibung | Bedeutung |
|---|---|---|
| Gesamtparameter | 35 Mrd. (35B) | MoE-Architektur |
| Aktive Parameter | Nur 3 Mrd. (3B) | Maximale Effizienz |
| SWE-bench Verified | 69,2 Punkte | Übertrifft Qwen3-235B |
| GPQA Diamond | 84,2 Punkte | Schlussfolgerung auf Graduiertenniveau |
| Kontextfenster | Nativ 256K / Erweitert 1M+ | YaRN-Erweiterung |
| Anforderungen | 22 GB RAM/VRAM | Consumer-Hardware-tauglich |
| Open-Source-Lizenz | Apache 2.0 | Vollständig offen |
Warum die r/LocalLLaMA-Community über Qwen3.5-35B diskutiert
r/LocalLLaMA ist die aktivste Community für lokale Großes Sprachmodell auf Reddit. Die Mitglieder konzentrieren sich auf die Kernfrage: Welches Modell läuft auf meiner Hardware und ist gleichzeitig leistungsfähig genug?
Das Qwen3.5-35B-A3B trifft genau diesen Bedarf:
- 35 Mrd. Gesamtparameter, aber nur 3 Mrd. aktive Parameter pro Inferenz – das bedeutet, es läuft flüssig auf Macs oder GPUs mit 22 GB RAM.
- Die Programmierfähigkeiten (SWE-bench 69,2) übertreffen das Vorgängermodell Qwen3-235B, das siebenmal mehr Parameter besitzt.
- Vollständig Open-Source unter Apache 2.0, ohne kommerzielle Einschränkungen.
Die Community meint dazu: „Run Qwen 35B. It's a great chatbot, good enough for task automation.“ Dies spiegelt die Kernanforderungen der lokalen Anwender wider: funktional, schnell und kostengünstig.
Tiefenanalyse der Architektur von Qwen3.5-35B
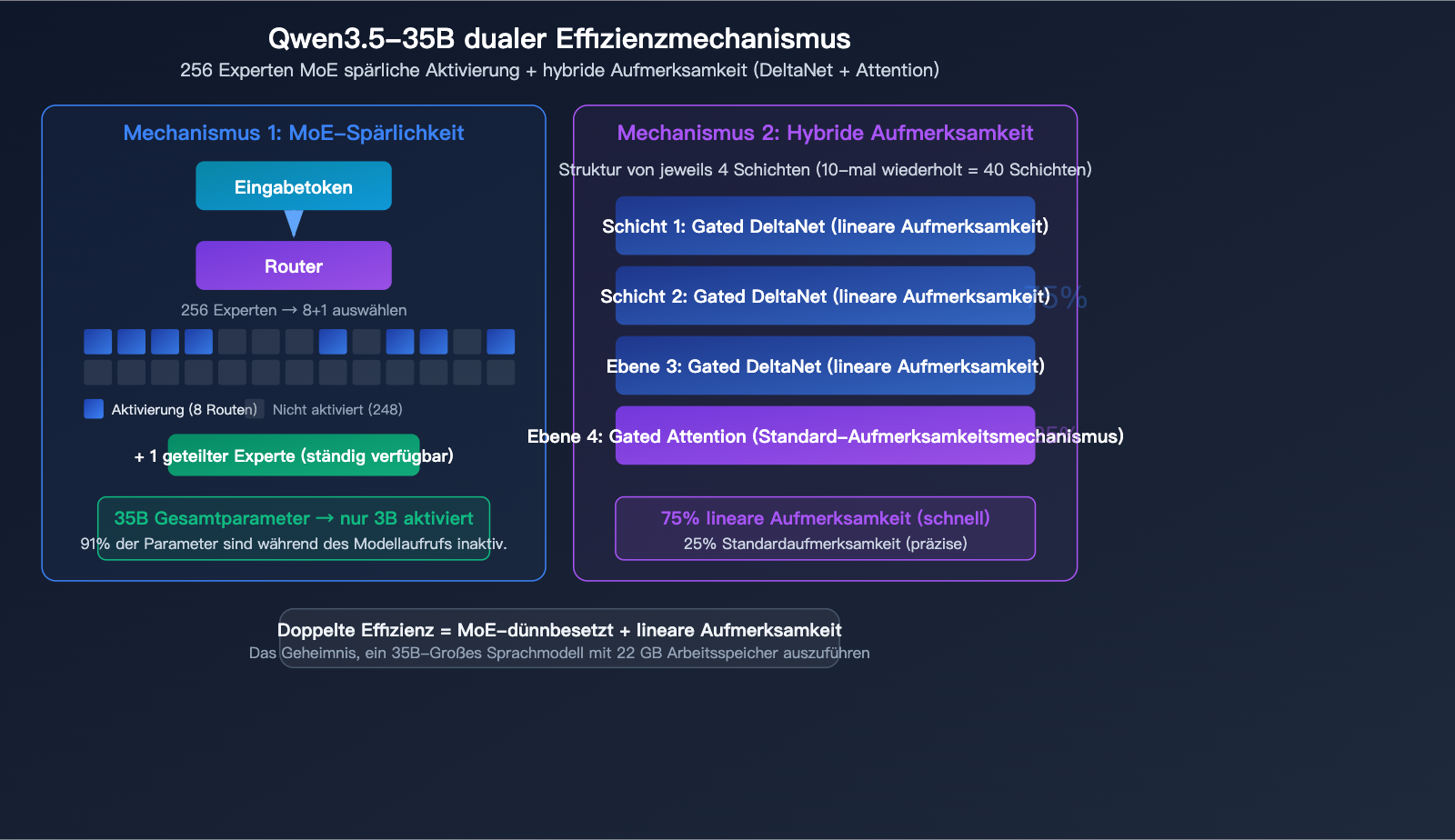
MoE-Architektur mit 256 Experten
Das Modell Qwen3.5-35B-A3B setzt auf eine extrem fein abgestimmte Mixture-of-Experts (MoE) Architektur:
| Architektur-Parameter | Wert | Erläuterung |
|---|---|---|
| Gesamtparameter | 35B | Summe aller Expertenparameter |
| Aktive Parameter | 3B | Aktivierung pro Inferenz |
| Experten insgesamt | 256 | Hochgradig granulare Aufgabenverteilung |
| Aktive Experten | 8 Routing + 1 Shared | 9 Experten pro Durchlauf |
| Schichten | 40 | Deep-Network-Struktur |
| Hidden Dimension | 2048 | Kompaktes Design |
Hybrider Aufmerksamkeitsmechanismus
Qwen3.5-35B ist kein reiner Transformer, sondern nutzt ein Hybrid-Attention-Design:
Die Struktur pro 4 Schichten besteht aus: 3 Schichten Gated DeltaNet (lineare Aufmerksamkeit) + 1 Schicht Gated Attention (Standard-Aufmerksamkeit).
| Attention-Typ | Anteil | Besonderheit |
|---|---|---|
| Gated DeltaNet | 75% | Lineare Aufmerksamkeit, schnelle Inferenz |
| Gated Attention | 25% | Standard-Aufmerksamkeit, hohe Präzision |
Der Clou an diesem hybriden Design: Der Großteil der Berechnungen erfolgt über die effiziente lineare Aufmerksamkeit, während die rechenintensivere Standard-Aufmerksamkeit nur in kritischen Schichten zum Einsatz kommt. Das ist das Geheimnis hinter den 35B Parametern bei nur 22 GB Speicherbedarf – nicht nur die Expertenaktivierung ist spärlich, auch der Aufmerksamkeitsmechanismus selbst wurde optimiert.
🎯 Technischer Einblick: Das Architekturdesign von Qwen3.5-35B repräsentiert den neuesten Trend bei MoE-Modellen für 2026 – 256 Experten bei extrem feiner Granularität kombiniert mit hybrider Aufmerksamkeit. Wenn Sie die Effizienzsteigerungen dieser Architektur selbst erleben möchten, können Sie die Qwen3.5-API direkt über APIYI (apiyi.com) aufrufen, ganz ohne lokale Bereitstellung.
Umfassende Analyse der Evaluierungsdaten von Qwen3.5-35B
Programmierungsevaluierung von Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Vergleichsreferenz | Anmerkung |
|---|---|---|---|
| SWE-bench Verified | 69,2 | Qwen3-235B: <69 | Übertrifft Vorgänger mit 7-facher Größe |
| LiveCodeBench v6 | 74,6 | – | Starke Echtzeit-Programmierung |
| CodeForces | 2.028 | – | Wettbewerbsniveau |
Schlussfolgerungs- und Wissensevaluierung von Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Anmerkung |
|---|---|---|
| GPQA Diamond | 84,2 | Wissenschaftliche Schlussfolgerung auf Graduiertenniveau |
| MMLU-Pro | 85,3 | Fachübergreifendes Wissen |
| MMLU-Redux | 93,3 | Wissensverständnis |
| HMMT Feb 2025 | 89,0 | Mathematikwettbewerb |
| IFEval | 91,9 | Befolgen von Anweisungen |
Multimodale Evaluierung von Qwen3.5-35B
| Benchmark | Qwen3.5 35B-A3B | Anmerkung |
|---|---|---|
| MMMU | 81,4 | Multimodales Verständnis (nahe an 79,6 von Claude Sonnet 4.5) |
| MMMU-Pro | 75,1 | Hochkomplexe multimodale Aufgaben |
| MathVision | 83,9 | Visuelle mathematische Schlussfolgerung |
| VideoMME | 86,6 | Videoverständnis |
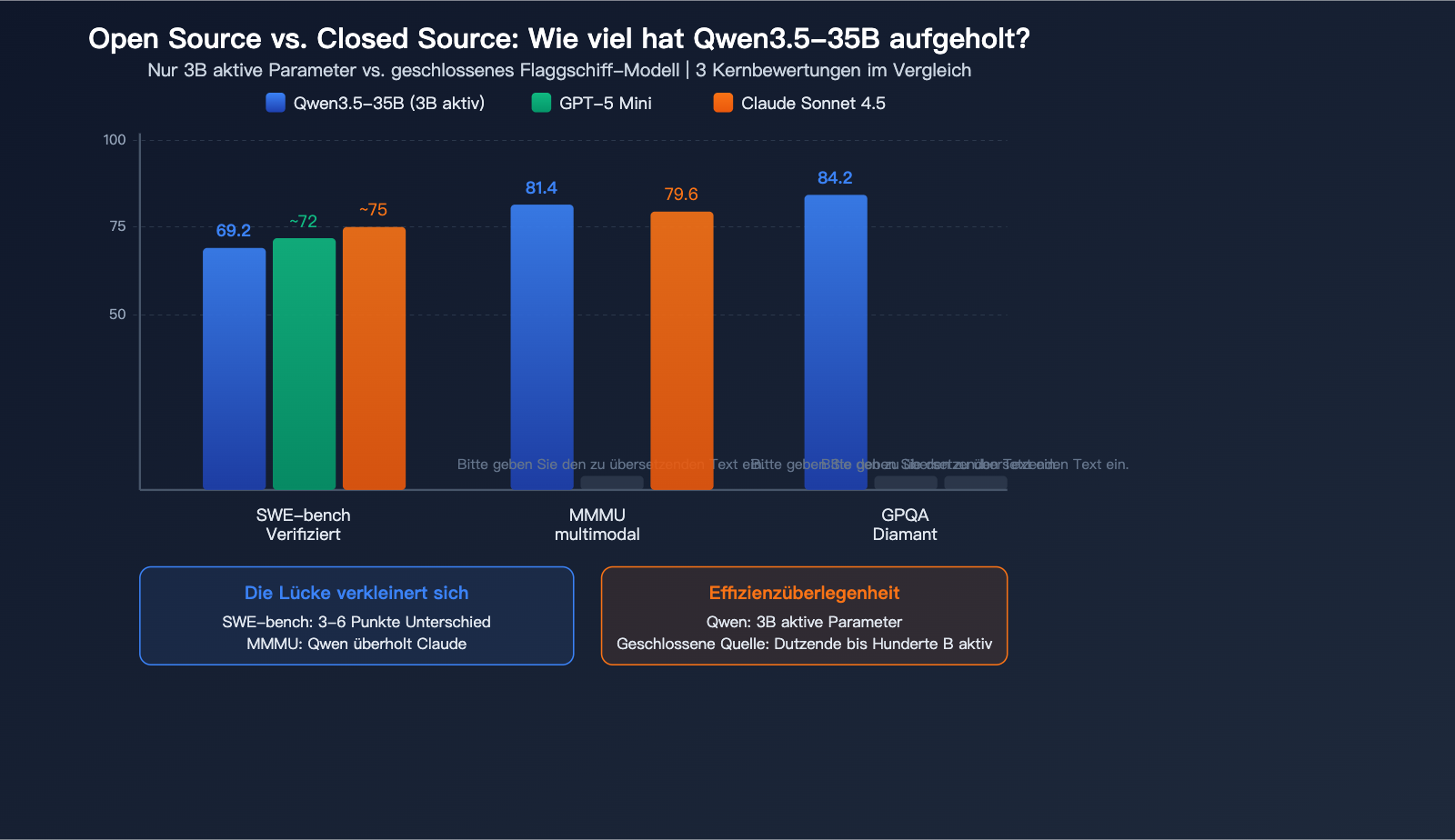
Vergleich von Qwen3.5-35B mit Closed-Source-Modellen
Dies ist die Frage, die die Community am meisten beschäftigt: Wie nah kommt ein Open-Source-Modell mit 35B Parametern an Closed-Source-Modelle heran?
| Dimension | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | Differenz |
|---|---|---|---|---|
| SWE-bench | 69,2 | ~72 | ~75 | 3-6 Punkte |
| MMMU | 81,4 | – | 79,6 | Überholt |
| GPQA Diamond | 84,2 | – | – | Spitzenklasse |
| Aktive Parameter | 3B | ~Dutzende B | Unbekannt | Überlegene Effizienz |
| Lokal ausführbar | Ja (22GB) | Nein | Nein | Einzigartiger Vorteil |
Kernmeinung der Community: Bei der Programmierung hat sich der Abstand von Qwen3.5-35B zu Modellen der GPT-5 Mini-Klasse auf 3-6 Punkte verringert, bei multimodalen Aufgaben übertrifft es sogar Claude Sonnet 4.5. In Anbetracht der Tatsache, dass es nur 3B aktive Parameter benötigt und lokal ausgeführt werden kann, ist das Verhältnis von Effizienz zu Leistung wahrscheinlich das höchste unter allen öffentlich verfügbaren Modellen.
💡 Praktischer Tipp: Wenn Sie die tatsächliche Leistung von Qwen3.5-35B im Vergleich zu Closed-Source-Modellen testen möchten, können Sie über APIYI (apiyi.com) Qwen3.5, Claude und GPT gleichzeitig aufrufen, um einen A/B-Vergleich für Ihre eigenen Aufgaben durchzuführen.
Qwen3.5-35B Lokale Bereitstellungsanleitung
Hardwareanforderungen und Bereitstellungsmethoden
| Bereitstellungsmethode | Hardwareanforderungen | Empfohlene Szenarien |
|---|---|---|
| Ollama | 22GB+ RAM/VRAM | Am einfachsten, Ein-Klick-Ausführung |
| vLLM | GPU + 24GB+ VRAM | Produktionsreifer Durchsatz |
| SGLang | GPU + 24GB+ VRAM | Empfohlen für hohen Durchsatz |
| KTransformers | CPU + GPU Hybrid | Hardware mit geringer Leistung |
| LM Studio | 22GB+ RAM | Benutzerfreundliche grafische Oberfläche |
Ollama Ein-Klick-Bereitstellung
# Nach der Installation mit einem einzigen Befehl ausführen
ollama run qwen3.5:35b
Modellaufruf via API (keine lokale Bereitstellung erforderlich)
Wenn Sie sich den Aufwand einer lokalen Bereitstellung sparen möchten, ist der Aufruf über die API der einfachste Weg:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "Hilf mir, diesen Python-Code zu überprüfen und Leistungsengpässe zu finden"
}],
temperature=0.6, # 0.6 für Programmieraufgaben empfohlen
max_tokens=32768
)
print(response.choices[0].message.content)
Umschalten zwischen Thinking-Modus und Standard-Modus
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking-Modus (tiefgründiges Schlussfolgern, geeignet für komplexe Aufgaben)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Analysiere die Zeitkomplexität dieses Algorithmus"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# Standard-Modus (schnelle Antwort)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "Schreibe eine Funktion für Quicksort"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 Bereitstellungsempfehlung: Die lokale Bereitstellung eignet sich für datenschutzsensible und Offline-Szenarien. Für die tägliche Entwicklung empfehlen wir den API-Proxy-Dienst von APIYI (apiyi.com) – er ist schneller, erfordert keine Hardwarewartung und ermöglicht den flexiblen Wechsel zwischen Qwen3.5, Claude und GPT.
Übersicht der Qwen3.5-Modellfamilie
Spezifikationsvergleich der Qwen3.5-Serie
| Modell | Gesamtparameter | Aktive Parameter | SWE-bench | Mindestspeicher | Positionierung |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (Dense) | – | 8GB | Leichtgewichtiger Einstieg |
| Qwen3.5-9B | 9B | 9B (Dense) | – | 12GB | Effizient für den Alltag |
| Qwen3.5-27B | 27B | 27B (Dense) | 72.4 | 22GB | Dicht & hohe Präzision |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | Effizienzkönig |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | Mittel- bis Oberklasse |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | Flaggschiff |
Auswahlempfehlung:
- 22GB-Geräte: 35B-A3B (MoE, schnell, aber etwas geringere Präzision) oder 27B (Dense, etwas langsamer, aber präziser)
- Maximale Kosteneffizienz: 35B-A3B, nutzt nur 3B Parameter pro Inferenz
- Höchste Präzision: 27B Dense, ohne MoE-Architektur
🎯 API-Auswahl: Über APIYI (apiyi.com) können Sie die gesamte Qwen3.5-Serie von 4B bis 397B je nach Bedarf abrufen. Mit einem einzigen API-Schlüssel können Sie flexibel zwischen verschiedenen Qwen-Modellgrößen sowie geschlossenen Modellen wie Claude und GPT wechseln.
Häufig gestellte Fragen
Q1: Sollte ich Qwen3.5-35B oder 27B wählen?
Beide benötigen etwa 22 GB Arbeitsspeicher. Das 35B-A3B-Modell nutzt eine MoE-Architektur (3-5-mal schneller, aber etwas geringere Präzision), während das 27B-Modell eine Dense-Architektur verwendet (präziser, aber langsamer). Bei Programmieraufgaben ist der Unterschied gering (SWE-bench 69,2 vs. 72,4). Für alltägliche Konversationen empfehle ich das 35B-Modell (schneller), für präzise Aufgaben das 27B-Modell (genauer). Über APIYI (apiyi.com) können Sie beide Modelle für einen direkten Vergleich aufrufen.
Q2: Holen Open-Source-Modelle wirklich zu den geschlossenen Modellen auf?
Ja, aber unter bestimmten Voraussetzungen. Qwen3.5-35B übertrifft Claude Sonnet 4.5 bei MMMU (81,4 vs. 79,6), und bei SWE-bench beträgt der Abstand zu GPT-5 Mini nur noch 3 Punkte. Bei den schwierigsten Programmieraufgaben und komplexen Schlussfolgerungen haben die Flaggschiff-Modelle (Claude Opus 4.5, GPT-5.4) jedoch weiterhin einen deutlichen Vorsprung. Open-Source schließt die Lücke, hat die Top-Modelle aber noch nicht vollständig eingeholt.
Q3: Kann ein Mac mit 22 GB RAM Qwen3.5-35B ausführen?
Ja. Qwen3.5-35B-A3B aktiviert pro Inferenz nur 3B Parameter, daher können Macs mit 22 GB Unified Memory (wie die Einstiegskonfigurationen von M2/M3/M4) das Modell flüssig ausführen. Wir empfehlen die Nutzung von Ollama (ollama run qwen3.5:35b) für einen schnellen Start. Wenn Sie keine lokale Bereitstellung wünschen, ist der Cloud-Modellaufruf über APIYI (apiyi.com) bequemer.
Zusammenfassung
Die 5 wichtigsten Erkenntnisse zum neuen Open-Source-Programmierrekord von Qwen3.5-35B:
- Effizienzrevolution: 35B Gesamtparameter bei nur 3B aktiven Parametern; 22 GB RAM reichen aus, wobei die Programmierleistung die der 235B-Modelle der vorherigen Generation übertrifft.
- Programmierstärke: SWE-bench 69,2, CodeForces 2028, LiveCodeBench 74,6 – ein neuer Maßstab für lokale Modelle.
- Architekturinnovation: 256-Experten-MoE + hybride Aufmerksamkeit (DeltaNet + Standard-Attention) sorgen für ein optimales Verhältnis von Effizienz zu Leistung.
- Open-Source holt auf: Übertrifft Claude Sonnet 4.5 bei MMMU und nähert sich GPT-5 Mini bei SWE-bench – der Abstand schrumpft.
- Vollständig offen: Apache 2.0-Lizenz, keine kommerziellen Einschränkungen, keine Kosten für die lokale Bereitstellung.
Qwen3.5-35B beweist eines: Open-Source-Modelle sind nicht mehr nur eine abgespeckte Version geschlossener Modelle, sondern holen mit höherer Effizienz auf und überholen diese teilweise. Wir empfehlen, über APIYI (apiyi.com) die gesamte Qwen3.5-Serie sowie geschlossene Modelle einzubinden, um mit einem einzigen API-Schlüssel die Leistungsunterschiede bei Ihren spezifischen Aufgaben direkt zu vergleichen.
📚 Referenzmaterialien
-
Qwen3.5-35B-A3B Modellkarte – Hugging Face: Vollständige technische Parameter und Evaluierungsdaten
- Link:
huggingface.co/Qwen/Qwen3.5-35B-A3B - Beschreibung: Enthält Architekturdetails, Evaluierungsergebnisse und Empfehlungen für Inferenzparameter
- Link:
-
Qwen3.5 GitHub-Repository: Open-Source-Code und Bereitstellungsleitfaden
- Link:
github.com/QwenLM/Qwen3.5 - Beschreibung: Enthält den Download für vollständige Modellgewichte und die Dokumentation zur Bereitstellung
- Link:
-
Qwen3.5 Vollständiger Leitfaden: Evaluierung der gesamten Serie und Architekturanalyse
- Link:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - Beschreibung: Detaillierter Vergleich der gesamten Modellfamilie und Gegenüberstellung mit Closed-Source-Modellen
- Link:
-
Ollama – Qwen3.5:35B: Lokale Bereitstellung mit einem Klick
- Link:
ollama.com/library/qwen3.5:35b - Beschreibung: Die einfachste Methode für den lokalen Betrieb
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Teilen Sie gerne Ihre Erfahrungen mit der lokalen Bereitstellung von Qwen3.5 in den Kommentaren. Weitere Informationen zur Anbindung von KI-Modellen finden Sie im APIYI Dokumentationszentrum unter docs.apiyi.com.