
ملاحظة من المؤلف: حقق نموذج Qwen3.5-35B-A3B نتيجة 69.2 نقطة في اختبار SWE-bench Verified باستخدام 3 مليار بارامتر نشط فقط، متجاوزاً بذلك الجيل السابق Qwen3-235B. يعتبره مجتمع r/LocalLLaMA علامة فارقة في سعي النماذج مفتوحة المصدر للحاق بالنماذج مغلقة المصدر. يقدم هذا المقال تحليلاً عميقاً لبنيته التقنية وقيمته العملية.
يشهد مجتمع r/LocalLLaMA مؤخراً نقاشات حادة حول حقيقة أن: نموذج Qwen3.5-35B-A3B حقق 69.2 نقطة في اختبار SWE-bench Verified مع 3 مليار بارامتر نشط فقط، ولم يكتفِ بتجاوز الجيل السابق Qwen3-235B، بل سجل رقماً قياسياً جديداً في القدرات البرمجية للنماذج التي يمكن تشغيلها محلياً. يرى المجتمع في هذا إشارة مهمة على قدرة النماذج مفتوحة المصدر على اللحاق بالنماذج مغلقة المصدر؛ حيث أصبح لدينا نموذج بحجم 35 مليار بارامتر يمكن تشغيله على أجهزة المستهلكين، مع قدرات برمجية تقترب من مستوى GPT-5 mini.
القيمة الجوهرية: بعد قراءة هذا المقال، ستفهم لماذا أحدث Qwen3.5-35B ضجة في مجتمع المصادر المفتوحة، وكيف تحقق بنيته من نوع MoE "قدرات هائلة في حجم صغير"، وكيف يمكنك استخدامه محلياً وفي السحابة.

النقاط الجوهرية لنموذج Qwen3.5-35B
| النقطة | الوصف | الأهمية |
|---|---|---|
| إجمالي البارامترات | 35 مليار (35B) | بنية MoE |
| البارامترات النشطة | 3 مليار فقط (3B) | كفاءة فائقة |
| SWE-bench Verified | 69.2 نقطة | تفوق على Qwen3-235B |
| GPQA Diamond | 84.2 نقطة | استنتاج بمستوى الدراسات العليا |
| نافذة السياق | 256 ألف أصلي / 1 مليون+ موسع | توسيع YaRN |
| متطلبات التشغيل | 22 جيجابايت ذاكرة/VRAM | متاح لأجهزة المستهلكين |
| رخصة المصدر المفتوح | Apache 2.0 | مفتوح بالكامل |
لماذا يناقش مجتمع r/LocalLLaMA نموذج Qwen3.5-35B؟
يعد r/LocalLLaMA أكثر مجتمعات النماذج اللغوية الكبيرة المحلية نشاطاً على Reddit، حيث يركز الأعضاء على سؤال جوهري: ما هو النموذج الذي يمكنني تشغيله على أجهزتي، وفي نفس الوقت يتمتع بقدرات قوية كافية؟
يأتي Qwen3.5-35B-A3B ليلبي هذا الاحتياج تماماً:
- إجمالي 35 مليار بارامتر، ولكن يتم تفعيل 3 مليار فقط في كل عملية استنتاج — مما يعني أنه يمكن تشغيله بسلاسة على أجهزة Mac أو بطاقات الرسوميات بذاكرة 22 جيجابايت.
- قدرات برمجية (69.2 في SWE-bench) تتفوق على الجيل السابق Qwen3-235B الذي يمتلك 7 أضعاف حجم البارامترات.
- مفتوح المصدر بالكامل بموجب رخصة Apache 2.0، دون أي قيود تجارية.
يقول أعضاء المجتمع: "قم بتشغيل Qwen 35B. إنه روبوت محادثة رائع، وجيد بما يكفي لأتمتة المهام." وهذا يمثل المطلب الأساسي للاعبين في مجال النشر المحلي — كافٍ، سريع، واقتصادي.
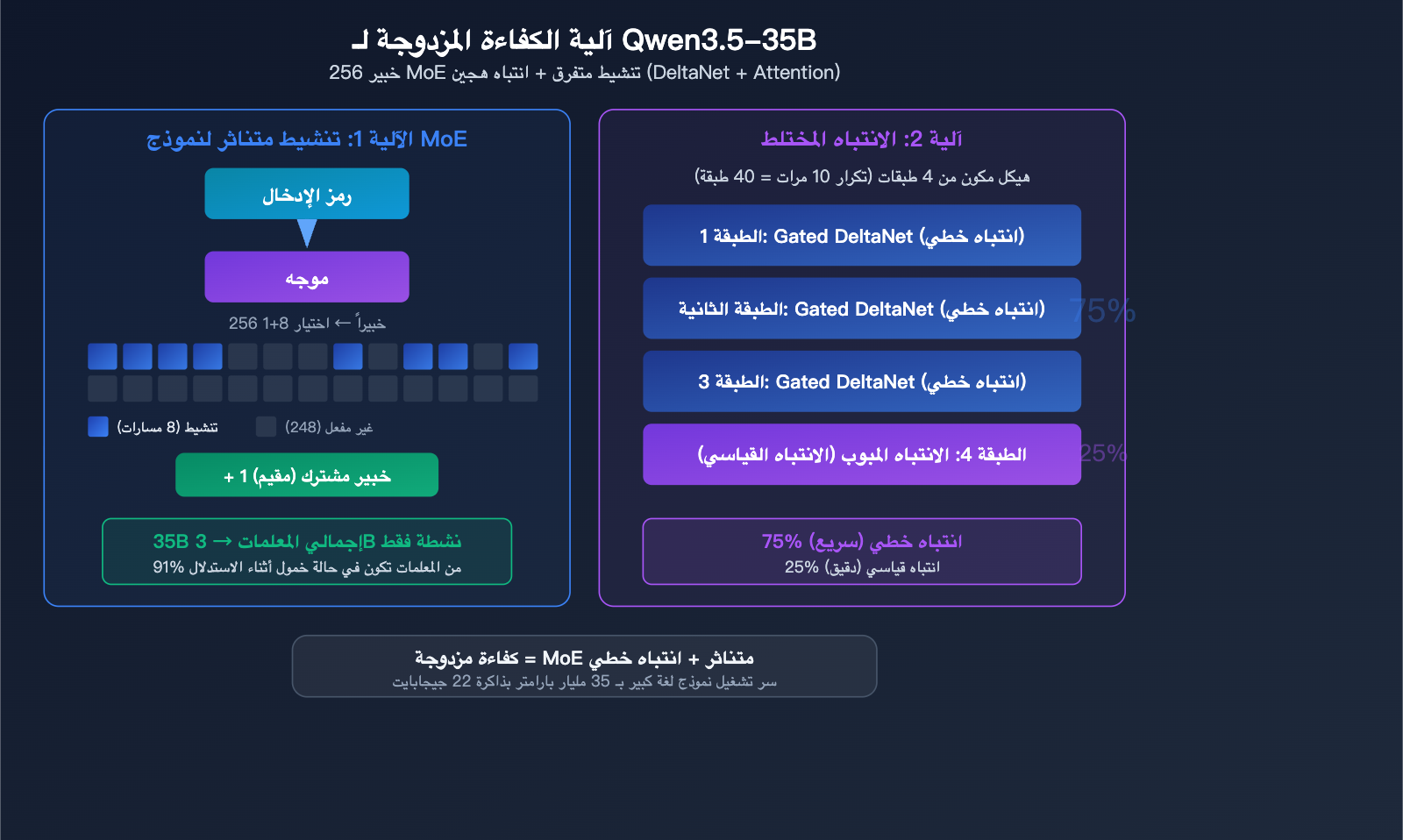
تحليل معماري عميق لـ Qwen3.5-35B
معمارية MoE بـ 256 خبيراً
يعتمد نموذج Qwen3.5-35B-A3B على معمارية "خليط الخبراء" (MoE) فائقة الدقة:
| معلمات المعمارية | القيمة | الشرح |
|---|---|---|
| إجمالي المعلمات | 35B | مجموع معلمات جميع الخبراء |
| المعلمات النشطة | 3B | يتم تفعيلها في كل عملية استنتاج |
| إجمالي الخبراء | 256 خبيراً | توزيع مهام دقيق للغاية |
| الخبراء النشطون | 8 توجيه + 1 مشترك | اختيار 9 خبراء في كل مرة |
| عدد الطبقات | 40 طبقة | شبكة عميقة |
| أبعاد التضمين | 2048 | تصميم مدمج |
آلية الانتباه الهجين
نموذج Qwen3.5-35B ليس مجرد Transformer تقليدي، بل يستخدم تصميم الانتباه الهجين:
يتكون الهيكل لكل 4 طبقات من: 3 طبقات Gated DeltaNet (انتباه خطي) + طبقة واحدة Gated Attention (انتباه قياسي)
| نوع الانتباه | نسبة الطبقات | الميزات |
|---|---|---|
| Gated DeltaNet | 75% | انتباه خطي، استنتاج سريع |
| Gated Attention | 25% | انتباه قياسي، دقة عالية |
تكمن عبقرية هذا التصميم الهجين في أن معظم العمليات الحسابية تتم باستخدام الانتباه الخطي عالي الكفاءة، بينما يُستخدم الانتباه القياسي الأكثر استهلاكاً للموارد في الطبقات الحاسمة فقط. هذا هو سر امتلاك 35 مليار معلمة مع استهلاك 22 جيجابايت فقط من الذاكرة—ليس فقط من خلال التنشيط المتناثر للخبراء، بل تم تحسين آلية الانتباه نفسها أيضاً.
🎯 رؤية تقنية: يمثل تصميم معمارية Qwen3.5-35B أحدث اتجاهات نماذج MoE لعام 2026—استخدام 256 خبيراً بدقة متناهية + الانتباه الهجين. إذا كنت ترغب في تجربة كفاءة هذه المعمارية، يمكنك استدعاء واجهة برمجة تطبيقات (API) سلسلة Qwen3.5 مباشرة عبر APIYI (apiyi.com)، دون الحاجة إلى النشر المحلي.
قراءة شاملة لبيانات تقييم Qwen3.5-35B
تقييم البرمجة لنموذج Qwen3.5-35B
| معيار التقييم | Qwen3.5 35B-A3B | مرجع المقارنة | ملاحظات |
|---|---|---|---|
| SWE-bench Verified | 69.2 | Qwen3-235B: <69 | يتفوق على الجيل السابق بـ 7 أضعاف الحجم |
| LiveCodeBench v6 | 74.6 | – | أداء برمجي قوي في الوقت الفعلي |
| CodeForces | 2,028 | – | مستوى مسابقات البرمجة |
تقييم الاستدلال والمعرفة لنموذج Qwen3.5-35B
| معيار التقييم | Qwen3.5 35B-A3B | ملاحظات |
|---|---|---|
| GPQA Diamond | 84.2 | استدلال علمي بمستوى الدراسات العليا |
| MMLU-Pro | 85.3 | معرفة متعددة التخصصات |
| MMLU-Redux | 93.3 | فهم المعرفة |
| HMMT Feb 2025 | 89.0 | مسابقات الرياضيات |
| IFEval | 91.9 | اتباع التعليمات |
تقييم الوسائط المتعددة لنموذج Qwen3.5-35B
| معيار التقييم | Qwen3.5 35B-A3B | ملاحظات |
|---|---|---|
| MMMU | 81.4 | فهم متعدد الوسائط (يقترب من 79.6 لنموذج Claude Sonnet 4.5) |
| MMMU-Pro | 75.1 | مهام متعددة الوسائط عالية الصعوبة |
| MathVision | 83.9 | استدلال رياضي بصري |
| VideoMME | 86.6 | فهم الفيديو |
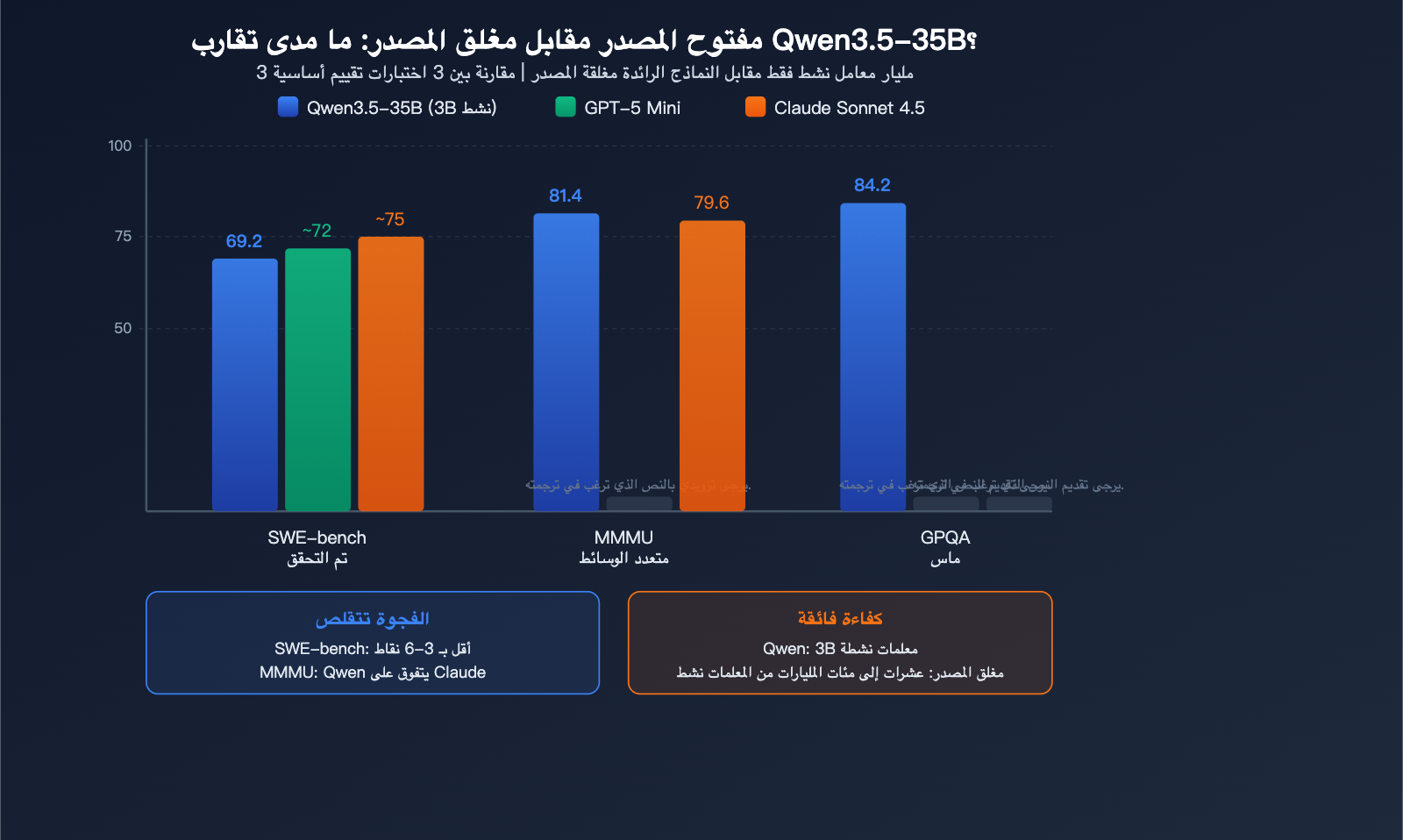
مقارنة Qwen3.5-35B مع النماذج مغلقة المصدر
هذا هو السؤال الأكثر إثارة لاهتمام المجتمع: إلى أي مدى يمكن للنماذج مفتوحة المصدر بحجم 35B أن تلحق بالنماذج مغلقة المصدر؟
| البعد | Qwen3.5 35B | GPT-5 Mini | Claude Sonnet 4.5 | الفجوة |
|---|---|---|---|---|
| SWE-bench | 69.2 | ~72 | ~75 | فرق 3-6 نقاط |
| MMMU | 81.4 | – | 79.6 | تفوق |
| GPQA Diamond | 84.2 | – | – | مستوى رائد |
| المعاملات النشطة | 3B | ~عشرات المليارات | غير معروف | كفاءة فائقة |
| التشغيل المحلي | نعم (22GB) | لا | لا | ميزة فريدة |
رأي المجتمع: تقلصت الفجوة بين Qwen3.5-35B ونماذج فئة GPT-5 Mini في البرمجة لتصل إلى 3-6 نقاط فقط، بل وتفوق عليها في الوسائط المتعددة. وبالنظر إلى أنه يتطلب 3B من المعاملات النشطة فقط ويمكن تشغيله محلياً، فإن نسبة الكفاءة إلى القدرة قد تكون الأعلى بين جميع النماذج المتاحة للجمهور.
💡 نصيحة عملية: إذا كنت ترغب في مقارنة الأداء الفعلي بين Qwen3.5-35B والنماذج مغلقة المصدر، يمكنك استخدام خدمة وكيل API عبر APIYI (apiyi.com) لاستدعاء Qwen3.5 وClaude وGPT في وقت واحد وإجراء مقارنة A/B على مهامك الخاصة.
دليل النشر المحلي لنموذج Qwen3.5-35B
متطلبات الأجهزة وطرق النشر
| طريقة النشر | متطلبات الأجهزة | السيناريوهات الموصى بها |
|---|---|---|
| Ollama | ذاكرة عشوائية/فيديو 22 جيجابايت+ | الأسهل، تشغيل بضغطة زر |
| vLLM | معالج رسومي + ذاكرة فيديو 24 جيجابايت+ | إنتاجية على مستوى الشركات |
| SGLang | معالج رسومي + ذاكرة فيديو 24 جيجابايت+ | موصى به للإنتاجية العالية |
| KTransformers | معالج مركزي + معالج رسومي هجين | للأجهزة ذات المواصفات المنخفضة |
| LM Studio | ذاكرة عشوائية 22 جيجابايت+ | واجهة رسومية سهلة الاستخدام |
النشر السريع عبر Ollama
# بعد التثبيت، يمكنك التشغيل بأمر واحد فقط
ollama run qwen3.5:35b
استدعاء النموذج عبر API (بدون الحاجة للنشر المحلي)
إذا كنت لا ترغب في عناء النشر المحلي، فإن الاستدعاء عبر API هو الطريقة الأسهل:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{
"role": "user",
"content": "ساعدني في مراجعة كود Python هذا، وحدد اختناقات الأداء"
}],
temperature=0.6, # يوصى بـ 0.6 لمهام البرمجة
max_tokens=32768
)
print(response.choices[0].message.content)
عرض التبديل بين وضع التفكير (Thinking) والوضع العادي
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# وضع التفكير (استنتاج عميق، مناسب للمهام المعقدة)
response_thinking = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "حلل التعقيد الزمني لهذه الخوارزمية"}],
temperature=1.0,
top_p=0.95,
max_tokens=32768
)
# وضع غير التفكير (إجابة سريعة)
response_fast = client.chat.completions.create(
model="qwen3.5-35b-a3b",
messages=[{"role": "user", "content": "اكتب دالة للترتيب السريع (Quick Sort)"}],
temperature=0.7,
top_p=0.8,
max_tokens=32768,
extra_body={"chat_template_kwargs": {"enable_thinking": False}}
)
🚀 نصيحة للنشر: النشر المحلي مناسب للسيناريوهات الحساسة للخصوصية والعمل دون اتصال بالإنترنت. للتطوير اليومي، نوصي باستخدام خدمة APIYI عبر apiyi.com — فهي أسرع، ولا تتطلب صيانة للأجهزة، وتتيح لك التبديل بحرية بين Qwen3.5 وClaude وGPT.
نظرة عامة على عائلة نماذج Qwen3.5
مقارنة مواصفات سلسلة Qwen3.5
| النموذج | إجمالي المعلمات | المعلمات النشطة | SWE-bench | الحد الأدنى للذاكرة | التموضع |
|---|---|---|---|---|---|
| Qwen3.5-4B | 4B | 4B (كثيف) | – | 8GB | خفيف للمبتدئين |
| Qwen3.5-9B | 9B | 9B (كثيف) | – | 12GB | فعال للاستخدام اليومي |
| Qwen3.5-27B | 27B | 27B (كثيف) | 72.4 | 22GB | دقة عالية وكثافة |
| Qwen3.5-35B-A3B | 35B | 3B (MoE) | 69.2 | 22GB | ملك الكفاءة |
| Qwen3.5-122B-A10B | 122B | 10B (MoE) | – | – | متوسط إلى عالي |
| Qwen3.5-397B-A17B | 397B | 17B (MoE) | 76.4 | – | رائد (Flagship) |
نصائح الاختيار:
- أجهزة بذاكرة 22 جيجابايت: اختر 35B-A3B (نموذج MoE، سريع ولكن بدقة أقل قليلاً) أو 27B (نموذج كثيف، أبطأ قليلاً ولكن أكثر دقة).
- لأفضل قيمة مقابل الأداء: اختر 35B-A3B، حيث يستخدم 3B فقط من المعلمات في كل استدعاء.
- لأعلى دقة ممكنة: اختر 27B Dense، فهو لا يعتمد على بنية MoE.
🎯 اختيار الـ API: يمكنك عبر APIYI (apiyi.com) استدعاء سلسلة Qwen3.5 كاملة، من 4B إلى 397B حسب الحاجة. مفتاح واحد يكفي للتبديل بمرونة بين أحجام مختلفة من نماذج Qwen والنماذج المغلقة مثل Claude وGPT.
الأسئلة الشائعة
س1: أيهما أختار، Qwen3.5-35B أم 27B؟
كلا النموذجين يتطلبان حوالي 22 جيجابايت من الذاكرة. نموذج 35B-A3B يستخدم معمارية MoE (أسرع بـ 3-5 مرات ولكن بدقة أقل قليلاً)، بينما 27B يستخدم معمارية Dense (أكثر دقة ولكن أبطأ). في مهام البرمجة، الفارق بينهما ليس كبيراً (69.2 مقابل 72.4 في اختبار SWE-bench). للمحادثات اليومية، نوصي بـ 35B (لأنه أسرع)، أما للمهام الدقيقة، فننصح بـ 27B (لأنه أدق). يمكنك استدعاء النموذجين عبر APIYI (apiyi.com) للمقارنة بينهما.
س2: هل تلحق النماذج مفتوحة المصدر حقاً بالنماذج مغلقة المصدر؟
نعم، ولكن بشروط. يتفوق Qwen3.5-35B على Claude Sonnet 4.5 في اختبار MMMU (81.4 مقابل 79.6)، والفارق بينه وبين GPT-5 Mini في اختبار SWE-bench هو 3 نقاط فقط. ومع ذلك، في أصعب مهام البرمجة والاستنتاج المعقد، لا تزال النماذج الرائدة مغلقة المصدر (مثل Claude Opus 4.5 و GPT-5.4) تتمتع بميزة واضحة. النماذج مفتوحة المصدر تقلص الفجوة، لكنها لم تتساوى تماماً مع أفضل النماذج المغلقة بعد.
س3: هل يمكن تشغيل Qwen3.5-35B على جهاز Mac بذاكرة 22 جيجابايت؟
نعم، يمكن ذلك. نموذج Qwen3.5-35B-A3B ينشط 3 مليار بارامتر فقط في كل عملية استنتاج، لذا يمكن لأجهزة Mac ذات الذاكرة الموحدة بسعة 22 جيجابايت (مثل M2/M3/M4 بالإعدادات الأساسية) تشغيله بسلاسة. نوصي باستخدام Ollama (ollama run qwen3.5:35b) للتشغيل بضغطة زر. وإذا كنت لا ترغب في النشر المحلي، فإن استدعاءه عبر السحابة باستخدام APIYI (apiyi.com) يعد خياراً أكثر ملاءمة.
ملخص
إليك 5 نقاط رئيسية حول تحقيق Qwen3.5-35B رقماً قياسياً جديداً في البرمجة مفتوحة المصدر:
- ثورة في الكفاءة: إجمالي 35 مليار بارامتر مع 3 مليارات نشطة فقط، يمكن تشغيله بذاكرة 22 جيجابايت، مع قدرات برمجية تتفوق على نماذج الجيل السابق ذات الـ 235 مليار بارامتر.
- قوة البرمجة: سجل 69.2 في SWE-bench، و2028 في CodeForces، و74.6 في LiveCodeBench، مما يجعله المعيار الجديد للنماذج المحلية.
- ابتكار المعمارية: يستخدم 256 خبيراً (MoE) مع انتباه هجين (DeltaNet + Standard Attention)، مما يوفر أفضل توازن بين الكفاءة والقدرات.
- تقليص الفجوة: تفوق على Claude Sonnet 4.5 في MMMU، واقترب من GPT-5 Mini في SWE-bench، مما يؤكد تقلص الفجوة مع النماذج المغلقة.
- انفتاح كامل: مرخص بموجب Apache 2.0، بدون قيود تجارية، وتكلفة تشغيل محلية صفرية.
يثبت Qwen3.5-35B حقيقة واحدة: النماذج مفتوحة المصدر لم تعد مجرد نسخة منخفضة الأداء من النماذج المغلقة، بل أصبحت تلحق بها بل وتتفوق عليها بكفاءة أعلى. نوصي باستخدام APIYI (apiyi.com) للوصول إلى سلسلة Qwen3.5 الكاملة جنباً إلى جنب مع النماذج المغلقة، واستخدام مفتاح API واحد للمقارنة بين أداء النماذج المفتوحة والمغلقة في مهامك الفعلية.
📚 المراجع
-
بطاقة نموذج Qwen3.5-35B-A3B – Hugging Face: المعايير التقنية الكاملة وبيانات التقييم
- الرابط:
huggingface.co/Qwen/Qwen3.5-35B-A3B - الوصف: تتضمن تفاصيل البنية، ونتائج التقييم، وتوصيات معلمات الاستدلال.
- الرابط:
-
مستودع Qwen3.5 على GitHub: الكود المصدري المفتوح وأدلة النشر
- الرابط:
github.com/QwenLM/Qwen3.5 - الوصف: يحتوي على روابط تحميل أوزان النموذج الكاملة ووثائق النشر.
- الرابط:
-
دليل Qwen3.5 الشامل: تقييم السلسلة الكاملة وتحليل البنية
- الرابط:
techie007.substack.com/p/qwen-35-the-complete-guide-benchmarks - الوصف: مقارنة تفصيلية لعائلة النماذج بالكامل ومراجعة مقارنة مع النماذج مغلقة المصدر.
- الرابط:
-
Ollama – Qwen3.5:35B: النشر المحلي بضغطة زر
- الرابط:
ollama.com/library/qwen3.5:35b - الوصف: أسهل طريقة لتشغيل النموذج محلياً.
- الرابط:
المؤلف: فريق APIYI التقني
تبادل الخبرات: نرحب بمشاركتكم لتجاربكم في نشر Qwen3.5 محلياً في قسم التعليقات، وللمزيد من المعلومات حول ربط نماذج الذكاء الاصطناعي، يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com.