
Quer fazer a IA "pensar antes de responder" como um ser humano? O modo Gemini Thinking é o mais recente recurso de raciocínio profundo lançado pelo Google, permitindo que o modelo mostre todo o seu processo de pensamento antes de entregar a resposta. Este artigo detalha como configurar corretamente o modo Gemini Thinking em dois dos principais clientes de IA: Cherry Studio e Chatbox.
Valor central: Ao ler este artigo, você aprenderá a ativar o modo de pensamento do Gemini no Cherry Studio e no Chatbox, visualizar o processo de raciocínio do modelo e melhorar a eficácia na resolução de tarefas complexas.
Pontos Principais do Modo Gemini Thinking
O modo Gemini Thinking é uma funcionalidade de raciocínio profundo introduzida pelo Google nas séries de modelos Gemini 2.5 e 3. Ao contrário de uma conversa comum, o modo Thinking faz com que o modelo realize um raciocínio interno antes de fornecer a resposta final, aumentando significativamente a precisão em tarefas complexas.
| Ponto Chave | Descrição | Valor |
|---|---|---|
| Visualização do pensamento | Mostra o processo de raciocínio do modelo | Entender como a IA chegou à conclusão |
| Raciocínio aprimorado | Raciocínio lógico em várias etapas | Resolver problemas complexos de matemática e programação |
| Profundidade controlável | Ajusta o orçamento de Tokens de pensamento | Equilibrar velocidade e precisão |
| Compatibilidade de modelos | Toda a série Gemini 2.5/3 | Flexibilidade para escolher o melhor cenário |
Modelos compatíveis com o Modo Gemini Thinking
Atualmente, os modelos Gemini que suportam o modo Thinking são:
| Nome do Modelo | ID do Modelo | Parâmetro de Pensamento | Comportamento Padrão |
|---|---|---|---|
| Gemini 3 Pro | gemini-3-pro-preview |
thinking_level | Pensamento dinâmico (HIGH) |
| Gemini 3 Flash | gemini-3-flash-preview |
thinking_level | Pensamento dinâmico (HIGH) |
| Gemini 2.5 Pro | gemini-2.5-pro |
thinking_budget | Dinâmico (8192 tokens) |
| Gemini 2.5 Flash | gemini-2.5-flash |
thinking_budget | Dinâmico (-1) |
| Gemini 2.5 Flash-Lite | gemini-2.5-flash-lite |
thinking_budget | Desativado por padrão (0) |
🎯 Sugestão Técnica: No desenvolvimento prático, recomendamos usar a plataforma APIYI (apiyi.com) para chamadas unificadas aos modelos Gemini Thinking. A plataforma oferece interfaces compatíveis com o formato OpenAI, eliminando a necessidade de lidar com processos complexos de autenticação da API do Google.
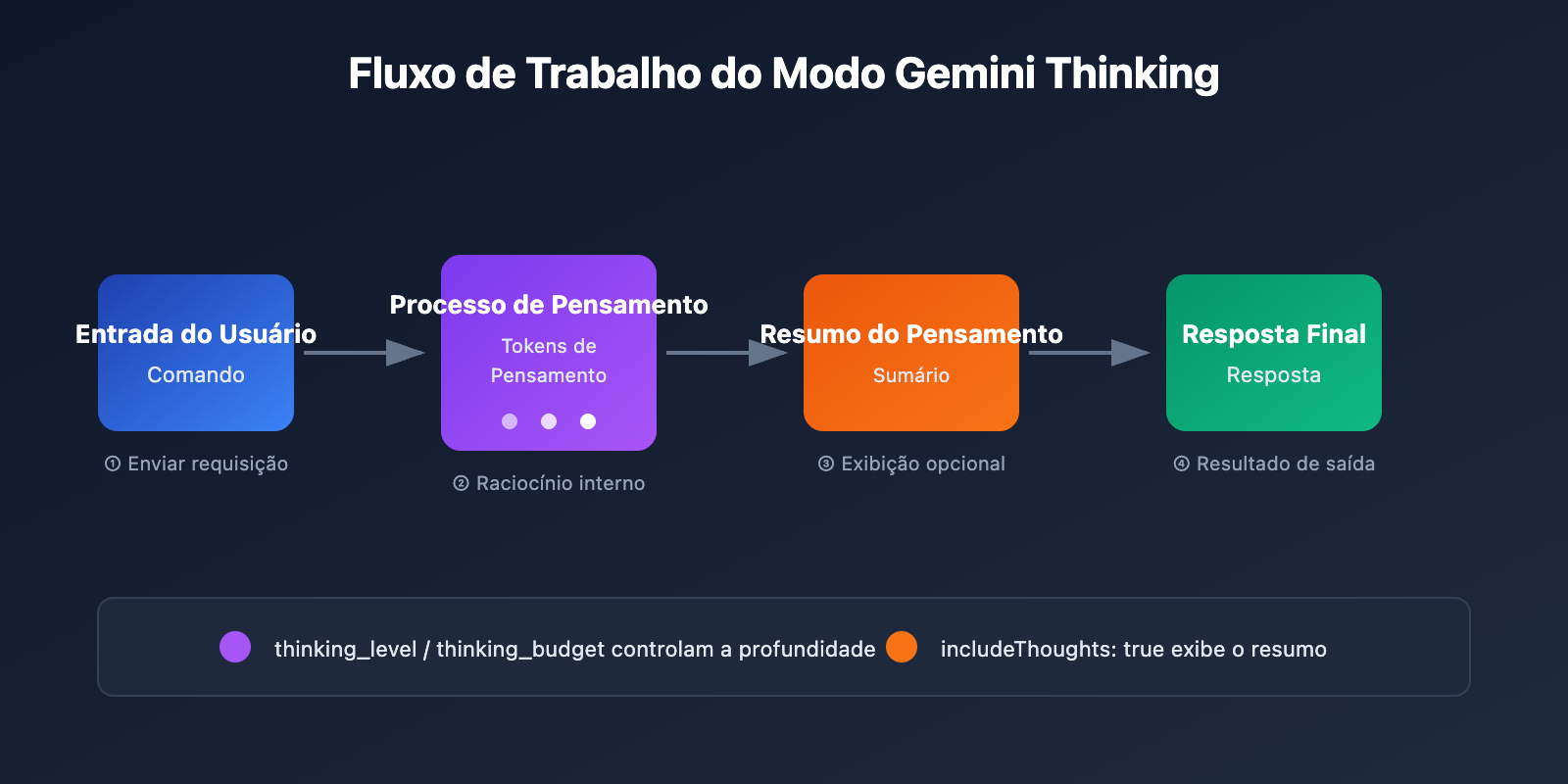
Detalhes dos Parâmetros da API do Modo Gemini Thinking
Diferentes versões dos modelos Gemini utilizam parâmetros diferentes para controlar o pensamento:
Série Gemini 3 – Parâmetro thinking_level
| Nível | Descrição | Cenário de Uso |
|---|---|---|
minimal |
Pensamento mínimo | Perguntas e respostas simples |
low |
Pensamento baixo | Diálogos cotidianos |
medium |
Pensamento médio | Raciocínio geral |
high |
Pensamento profundo (padrão) | Tarefas complexas |
Série Gemini 2.5 – Parâmetro thinking_budget
| Valor | Descrição | Cenário de Uso |
|---|---|---|
0 |
Desativar pensamento | Resposta rápida |
-1 |
Pensamento dinâmico (recomendado) | Ajuste automático |
128-32768 |
Número específico de Tokens | Controle fino |
Configurando o Modo Gemini Thinking no Cherry Studio
O Cherry Studio é um cliente de IA poderoso que suporta mais de 300 modelos e diversos provedores de IA. Abaixo, detalhamos os passos para configurar o Modo Gemini Thinking no Cherry Studio.
Passo 1: Adicionar o Provedor de API do Gemini
- Abra o Cherry Studio e vá em Configurações → Provedores
- Encontre o Gemini ou Provedor Personalizado
- Insira as informações de configuração da API:
Endereço da API: https://api.apiyi.com/v1
Chave de API: Sua chave da APIYI
💡 Dica de configuração: Use a APIYI (apiyi.com) como endereço da API para obter um acesso mais estável e um formato de interface unificado.
Passo 2: Adicionar os Modelos Gemini Thinking
Clique no botão "Gerenciar" ou "Adicionar" na parte inferior para adicionar manualmente os seguintes modelos:
| Nome do Modelo Adicionado | Descrição |
|---|---|
gemini-3-pro-preview |
Gemini 3 Pro (Versão Thinking) |
gemini-3-flash-preview |
Gemini 3 Flash (Versão Thinking) |
gemini-2.5-pro |
Gemini 2.5 Pro (Versão Thinking) |
gemini-2.5-flash |
Gemini 2.5 Flash (Versão Thinking) |
Passo 3: Ativar a Chave do Thinking Mode
Na interface de chat:
- Clique no ícone de configurações no canto superior direito
- Encontre a opção Thinking Mode
- Mude a chave para ON
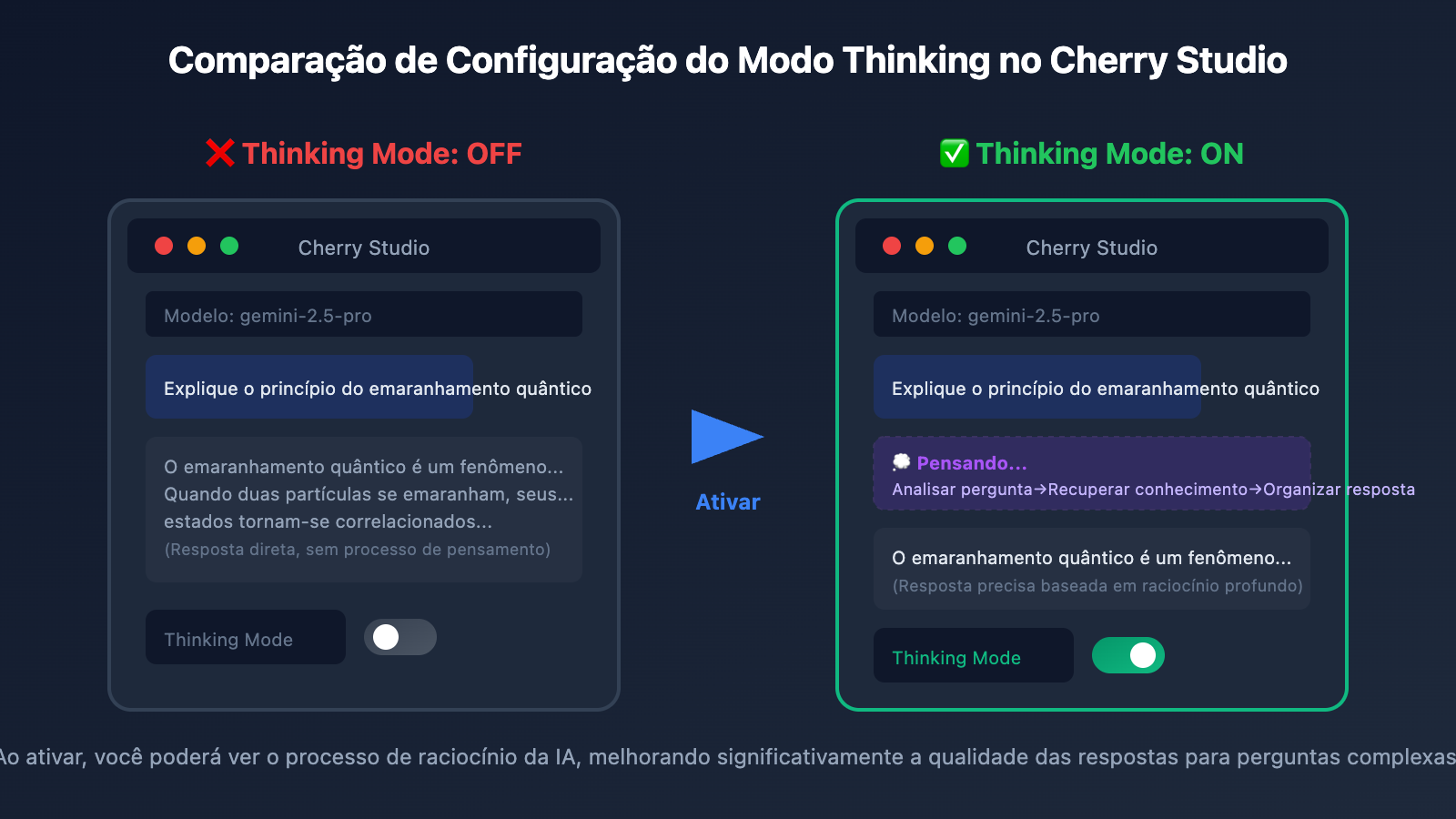
Configuração de Parâmetros Personalizados no Cherry Studio
Se a chave na interface (UI) não funcionar, você precisará configurar os parâmetros personalizados manualmente:
Para modelos Gemini 3:
{
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Para modelos Gemini 2.5:
{
"generationConfig": {
"thinkingConfig": {
"thinkingBudget": -1,
"includeThoughts": true
}
}
}
Cole a configuração JSON acima na área de Parâmetros Personalizados (Custom Parameters) do Cherry Studio.
Ver instruções detalhadas de configuração do Cherry Studio
Detalhes dos passos de configuração:
- Abrir configurações do modelo: Clique no nome do modelo no topo da caixa de diálogo.
- Acessar configurações avançadas: Role até a área de "Parâmetros Personalizados".
- Colar o JSON: Copie a configuração JSON correspondente ao modelo acima.
- Salvar e testar: Envie uma mensagem para verificar se o processo de pensamento é exibido.
Solução de Problemas Comuns:
- Certifique-se de que o formato JSON está correto, sem vírgulas extras.
- Confirme se o nome do modelo corresponde à configuração.
- Verifique se a Chave de API é válida.
🚀 Começo Rápido: Recomendamos usar a plataforma APIYI (apiyi.com) para obter sua Chave de API. Ela suporta toda a linha de modelos Gemini e a configuração é mais simples.
Configurando o modo Gemini Thinking no Chatbox
O Chatbox é outro cliente desktop de IA amplamente popular, com uma interface limpa e suporte para várias plataformas. Veja a seguir como configurar o modo Gemini Thinking no Chatbox.
Passo 1: Configurar o Provedor de API
- Abra o Chatbox e clique em Configurações no canto inferior esquerdo.
- Selecione Provedor de Modelo → Custom (Personalizado).
- Configure as informações da API:
Nome: Gemini Thinking
Tipo de API: OpenAI Compatible
API Host: https://api.apiyi.com
API Key: sk-seu-token-apiyi
Passo 2: Selecionar o Modelo Thinking
No seletor de modelos, digite ou selecione:
gemini-3-pro-preview– Maior capacidade de raciocíniogemini-2.5-pro– Equilíbrio entre desempenho e custogemini-2.5-flash– Resposta rápida
Passo 3: Configurar os Parâmetros de Pensamento
O Chatbox permite configurar o modo de pensamento através de Parâmetros Extras (Extra Parameters):
{
"thinking_config": {
"thinking_level": "high"
}
}
Ou use o thinking_budget:
{
"thinking_config": {
"thinking_budget": 8192
}
}
Configurações de Exibição do Processo de Pensamento no Chatbox
Por padrão, o Chatbox exibe o processo de pensamento de forma recolhida, mas você pode ajustar a exibição:
| Item de Configuração | Função | Valor Recomendado |
|---|---|---|
| Mostrar processo de pensamento | Expandir/recolher o conteúdo do pensamento | Ativado |
| Estilo do processo de pensamento | Bloco independente/Exibição em linha | Bloco independente |
| Recolhimento automático | Recolher automaticamente pensamentos longos | Ativado |
Ver exemplo de código de configuração no Chatbox
# Usando o SDK da OpenAI para configurar o Gemini Thinking
import openai
client = openai.OpenAI(
api_key="sk-seu-token-apiyi",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[
{"role": "user", "content": "Por favor, explique por que 1+1=2"}
],
extra_body={
"thinking_config": {
"thinking_budget": 8192,
"include_thoughts": True
}
}
)
# Exibe o processo de pensamento e a resposta
print(response.choices[0].message.content)
Melhores Práticas para o Modo Gemini Thinking
Configuração da Profundidade de Pensamento para Diferentes Cenários
| Cenário de Uso | Modelo Recomendado | Configuração de Pensamento | Descrição |
|---|---|---|---|
| Prova Matemática | gemini-3-pro-preview | thinking_level: high | Exige raciocínio rigoroso |
| Depuração de Código | gemini-2.5-pro | thinking_budget: 16384 | Análise de lógica complexa |
| Perguntas e Respostas Diárias | gemini-2.5-flash | thinking_budget: -1 | Adaptação dinâmica |
| Resposta Rápida | gemini-2.5-flash-lite | thinking_budget: 0 | Desativa o pensamento |
| Escrita de Artigos | gemini-3-flash-preview | thinking_level: medium | Equilíbrio entre criatividade e eficiência |
Sugestões de Orçamento de Tokens para Pensamento (Thinking Tokens)
Perguntas simples: 0-1024 tokens
Raciocínio geral: 1024-4096 tokens
Tarefas complexas: 4096-16384 tokens
Raciocínio extremo: 16384-32768 tokens
💡 Dica de Escolha: A profundidade de pensamento depende principalmente da complexidade da tarefa. Recomendamos realizar testes práticos na plataforma APIYI (apiyi.com) para encontrar a configuração ideal para o seu caso. A plataforma suporta todos os modelos Gemini Thinking, facilitando a comparação rápida de resultados.
<!-- 示例任务 -->
<rect x="105" y="100" width="150" height="70" rx="6" fill="#1e293b" stroke="#22c55e" stroke-width="1" />
<text x="180" y="120" text-anchor="middle" fill="#22c55e" font-size="11" font-weight="bold" font-family="system-ui, sans-serif">Tarefas aplicáveis</text>
<text x="115" y="140" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Tradução simples</text>
<text x="115" y="155" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Busca de informações</text>
<!-- 连接线 -->
<line x1="180" y1="170" x2="180" y2="280" stroke="#22c55e" stroke-width="1" stroke-dasharray="4,4" opacity="0.5" />
<!-- 示例任务 -->
<rect x="260" y="100" width="155" height="70" rx="6" fill="#1e293b" stroke="#3b82f6" stroke-width="1" />
<text x="337" y="120" text-anchor="middle" fill="#3b82f6" font-size="11" font-weight="bold" font-family="system-ui, sans-serif">Tarefas aplicáveis</text>
<text x="270" y="140" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Explicação de código</text>
<text x="270" y="155" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Resumo de artigos</text>
<!-- 连接线 -->
<line x1="337" y1="170" x2="337" y2="230" stroke="#3b82f6" stroke-width="1" stroke-dasharray="4,4" opacity="0.5" />
<!-- 示例任务 -->
<rect x="420" y="100" width="155" height="60" rx="6" fill="#1e293b" stroke="#f59e0b" stroke-width="1" />
<text x="497" y="118" text-anchor="middle" fill="#f59e0b" font-size="11" font-weight="bold" font-family="system-ui, sans-serif">Tarefas aplicáveis</text>
<text x="430" y="136" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Algoritmos • Depuração</text>
<text x="430" y="151" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Comparação • Arquitetura</text>
<!-- 连接线 -->
<line x1="497" y1="160" x2="497" y2="170" stroke="#f59e0b" stroke-width="1" stroke-dasharray="4,4" opacity="0.5" />
<!-- 示例任务 -->
<rect x="580" y="175" width="155" height="60" rx="6" fill="#1e293b" stroke="#ef4444" stroke-width="1" />
<text x="657" y="193" text-anchor="middle" fill="#ef4444" font-size="11" font-weight="bold" font-family="system-ui, sans-serif">Tarefas aplicáveis</text>
<text x="590" y="211" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Provas matemáticas • Programação complexa</text>
<text x="590" y="226" fill="#e2e8f0" font-size="9" font-family="system-ui, sans-serif">• Raciocínio profundo • Planejamento estratégico</text>
Comparação: Modo Thinking vs. Modo Comum
| Dimensão de Comparação | Modo Comum | Modo Thinking |
|---|---|---|
| Velocidade de Resposta | Rápida (1-3 seg) | Mais lenta (3-10 seg) |
| Profundidade de Raciocínio | Superficial | Profunda e multi-etapas |
| Consumo de Tokens | Baixo | Médio-Alto |
| Precisão (Tarefas Complexas) | 60-70% | 85-95% |
| Explicabilidade | Baixa | Alta (permite ver o raciocínio) |
| Cenários Aplicáveis | Perguntas simples | Tarefas de raciocínio complexo |
Perguntas Frequentes
Q1: O Cherry Studio não exibe o processo de pensamento mesmo após ativar o Thinking Mode?
Este é um problema conhecido. A chave na interface de alguns provedores pode não funcionar corretamente, sendo necessário adicionar manualmente a configuração JSON em "Parâmetros Personalizados":
{
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
Certifique-se de que includeThoughts esteja definido como true, pois este é o parâmetro crucial para exibir o processo de pensamento. Ao realizar chamadas através da plataforma APIYI (apiyi.com), o retorno do resumo do pensamento já vem ativado por padrão.
Q2: Qual é a diferença entre os parâmetros do Gemini 2.5 e do Gemini 3?
As duas séries utilizam parâmetros diferentes para controlar o modo de pensamento:
- Série Gemini 3: Utiliza o parâmetro
thinkingLevel, com os valores: minimal/low/medium/high. - Série Gemini 2.5: Utiliza o parâmetro
thinkingBudget, com valores numéricos entre 0 e 32768.
Não é possível misturar os parâmetros, caso contrário, a API retornará um erro. Recomendamos utilizar a interface unificada da APIYI (apiyi.com), onde a plataforma processa automaticamente a compatibilidade dos parâmetros.
Q3: Quanto o modo de pensamento aumenta o consumo de Tokens?
Os Tokens de pensamento são cobrados adicionalmente. Tomando o Gemini 2.5 Pro como exemplo:
- Orçamento de pensamento padrão: 8192 tokens
- Orçamento de pensamento máximo: 32768 tokens
O consumo real depende da complexidade da tarefa. Para perguntas simples, o modelo pode usar apenas algumas centenas de tokens de pensamento; para questões complexas, pode esgotar o orçamento. Configurar thinkingBudget: -1 permite que o modelo se ajuste automaticamente, sendo a opção com melhor custo-benefício.
Q4: Como obter apenas o resumo do pensamento em vez do processo completo?
Ao configurar includeThoughts: true na chamada da API, o que é retornado é o resumo do pensamento, e não os tokens de pensamento internos completos. O resumo é mais conciso e ideal para exibição em interfaces de usuário (UI). O processo de pensamento completo não está disponível para o público no momento.
Q5: Quais tarefas são mais adequadas para o modo Thinking?
O modo Thinking é especialmente indicado para tarefas que exigem raciocínio em múltiplas etapas:
- Provas matemáticas e cálculos complexos
- Depuração de código (debugging) e design de algoritmos
- Raciocínio lógico e análise de problemas
- Planejamento estratégico e análise de decisão
Tarefas simples como consultas de informações, traduções ou resumos curtos não precisam do modo Thinking ativado, pois ele apenas aumentaria a latência e o custo.
Resumo
O modo Gemini Thinking é uma funcionalidade poderosa para elevar a capacidade de raciocínio do seu Modelo de Linguagem Grande. Através deste tutorial de configuração, você aprendeu:
- Entender os princípios do modo Thinking: Dominar a diferença entre os parâmetros
thinking_levelethinking_budget. - Métodos de configuração no Cherry Studio: Ativar o modo de pensamento via interface ou parâmetros JSON personalizados.
- Métodos de configuração no Chatbox: Utilizar os "Extra Parameters" para configurar os parâmetros de pensamento.
- Melhores Práticas: Escolher a profundidade de pensamento adequada de acordo com a complexidade da tarefa.
Recomendamos utilizar a APIYI (apiyi.com) para validar rapidamente os efeitos do modo Gemini Thinking. A plataforma oferece uma interface unificada compatível com OpenAI, suporte para todas as séries de modelos Gemini 2.5 e 3, com configuração simplificada e acesso mais estável.
Referências
-
Documentação oficial do Google Gemini Thinking: Descrição completa dos parâmetros da API
- Link:
ai.google.dev/gemini-api/docs/thinking
- Link:
-
Documentação oficial do Cherry Studio: Guia de configuração do cliente
- Link:
docs.cherry-ai.com
- Link:
-
Lista de modelos Gemini: Lista de modelos compatíveis com o Thinking
- Link:
ai.google.dev/gemini-api/docs/models
- Link:
Autor: Equipe APIYI
Suporte Técnico: Para obter a API do Gemini ou consultoria técnica, acesse APIYI em apiyi.com