
2026년, 92%의 개발자가 이미 AI 프로그래밍 도구를 사용하고 있으며, 전체 코드의 41%가 AI의 도움으로 생성되고 있습니다. 하지만 당혹스러운 현실이 하나 있습니다. 바로 개인이 체감하는 시간 절감 효과는 30~60%에 달하지만, 조직의 실제 생산성 향상은 약 10%에 불과하다는 점입니다. 이 격차는 어디서 발생할까요? 바로 '워크플로우'입니다.
적절한 모델 조합과 워크플로우를 사용하면 AI 프로그래밍은 10배의 효율을 내는 부스터가 되지만, 잘못 사용하면 그저 "돌아는 가는데 언제 터질지 모르는" 코드를 찍어내는 생성기에 불과합니다.
핵심 가치: 이 글을 읽고 나면 검증된 멀티 모델 AI 프로그래밍 워크플로우를 마스터하게 됩니다. 가성비가 뛰어난 모델(예: GLM-5)로 코드를 생성하고, 최고 성능의 모델(예: Claude Sonnet 4.6)로 코드 리뷰를 진행하며, Claude Code를 통해 전체 과정을 자동화하는 방법을 알려드립니다.
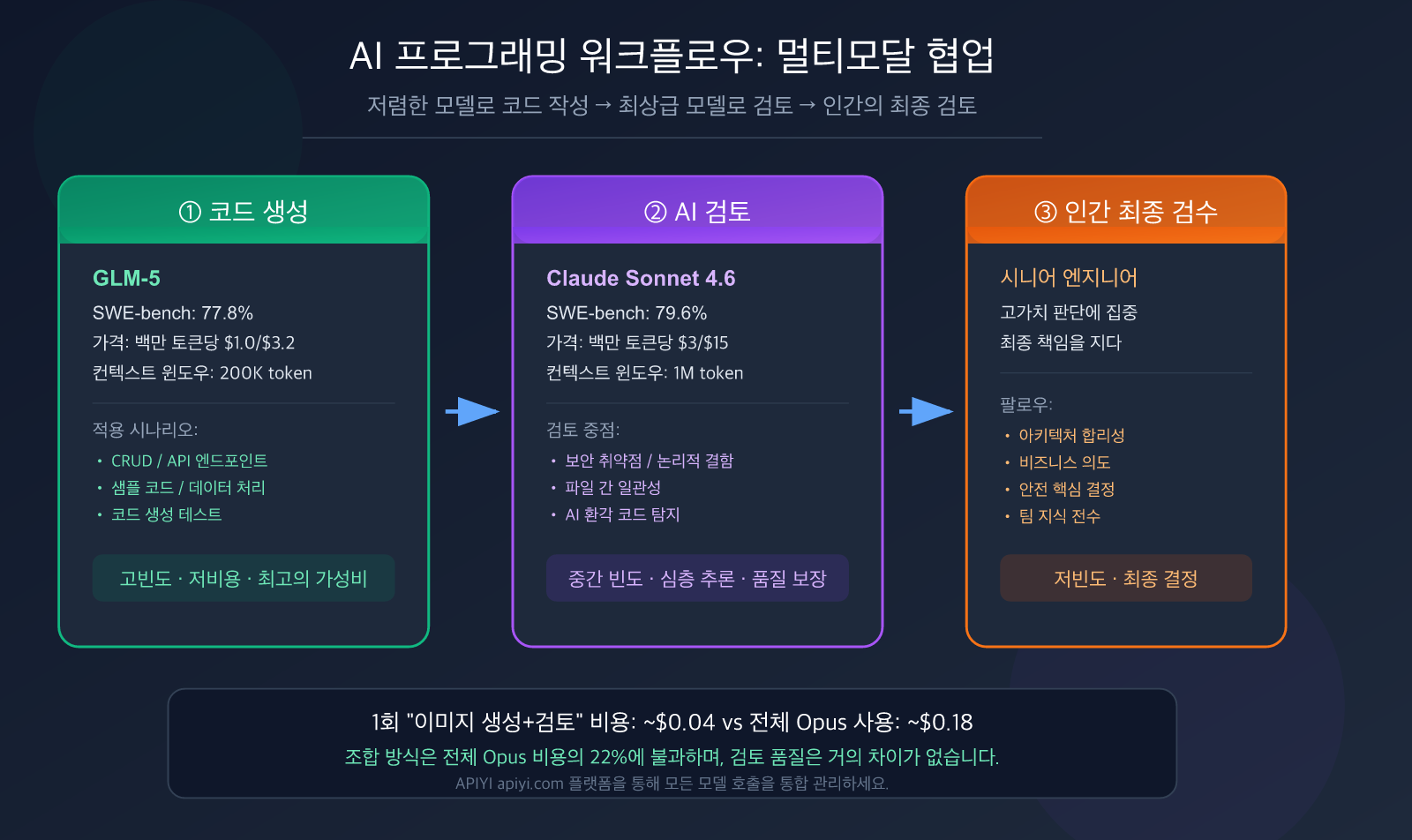
AI 프로그래밍 워크플로우의 근본적인 변화
개발자 역할의 전환: "코드를 짜는 사람"에서 "AI를 지휘하는 사람"으로
2026년의 소프트웨어 개발에서 개발자의 핵심 업무는 더 이상 코드를 한 줄씩 작성하는 것이 아닙니다. 이제는 다음과 같은 역할이 중요해졌습니다.
- 사양 정의 (Specification Engineering) — 요구사항, 제약 조건, 아키텍처 선호도 정의
- 모델 조합 선택 — 단계별로 최적의 모델 활용
- 검토 및 관리 — AI 결과물이 엔지니어링 표준을 충족하는지 확인
- 최종 책임 — AI는 도구일 뿐, 책임은 인간에게 있음
Addy Osmani(Google Chrome 팀 기술 책임자)가 요약한 핵심 원칙: "코드를 짜기 전에 먼저 계획하라. 계획은 수정하기 쉽지만, 코드는 수정하기 어렵다."
새로운 워크플로우 vs 전통적인 워크플로우
| 구분 | 전통적인 워크플로우 | AI 기반 워크플로우 |
|---|---|---|
| 핵심 활동 | 코드 한 줄씩 작성 | 사양 정의 + AI 결과물 검토 |
| 개발자 역할 | 코더 (Coder) | 오케스트레이터 (Orchestrator) |
| 코드 생성 | 100% 수동 | ~40% AI 생성 + 수동 수정 |
| 검토 중점 | 로직 및 스타일 | AI 결과물 품질 + 아키텍처 일관성 |
| 도구 체인 | IDE + Git | AI 에이전트 + IDE + Git + 멀티 모델 |
| 병목 현상 | 코딩 속도 | 검토 속도 및 판단력 |
핵심 데이터: AI 프로그래밍의 실제 현황
| 데이터 | 출처 |
|---|---|
| 92% 개발자가 AI 프로그래밍 도구 사용 | 2026년 업계 조사 |
| 41%의 코드 커밋이 AI 보조를 받음 | GitHub 데이터 |
| AI 제안 중 30%만 직접 채택 | CodeRabbit 보고서 |
| 29-46%의 개발자만 AI 결과물을 신뢰 | 다수 조사 종합 |
| 조직의 실제 생산성 약 10% 향상 | 6개 독립 연구 공통 결과 |
| AI 생성 코드 결함률이 인간보다 1.7배 높음 | 470개 PR 분석 |
🎯 핵심 통찰: 생산성 향상의 핵심은 AI가 얼마나 많은 코드를 생성하느냐가 아니라, 얼마나 효율적인 검토 및 검증 체계를 갖추었느냐에 달려 있습니다. APIYI(apiyi.com) 플랫폼을 통해 다양한 모델을 유연하게 조합하여 이러한 체계를 구축할 수 있습니다.
모델 선정 전략: 코딩은 저렴하게, 검토는 최고급으로
이것이 바로 본문의 핵심 방법론입니다. 단계별로 다른 모델을 사용하는 것이죠. 레이싱 팀이 F1 머신으로 배달을 하지 않고, 화물차로 경주에 나가지 않는 것과 같은 이치입니다.
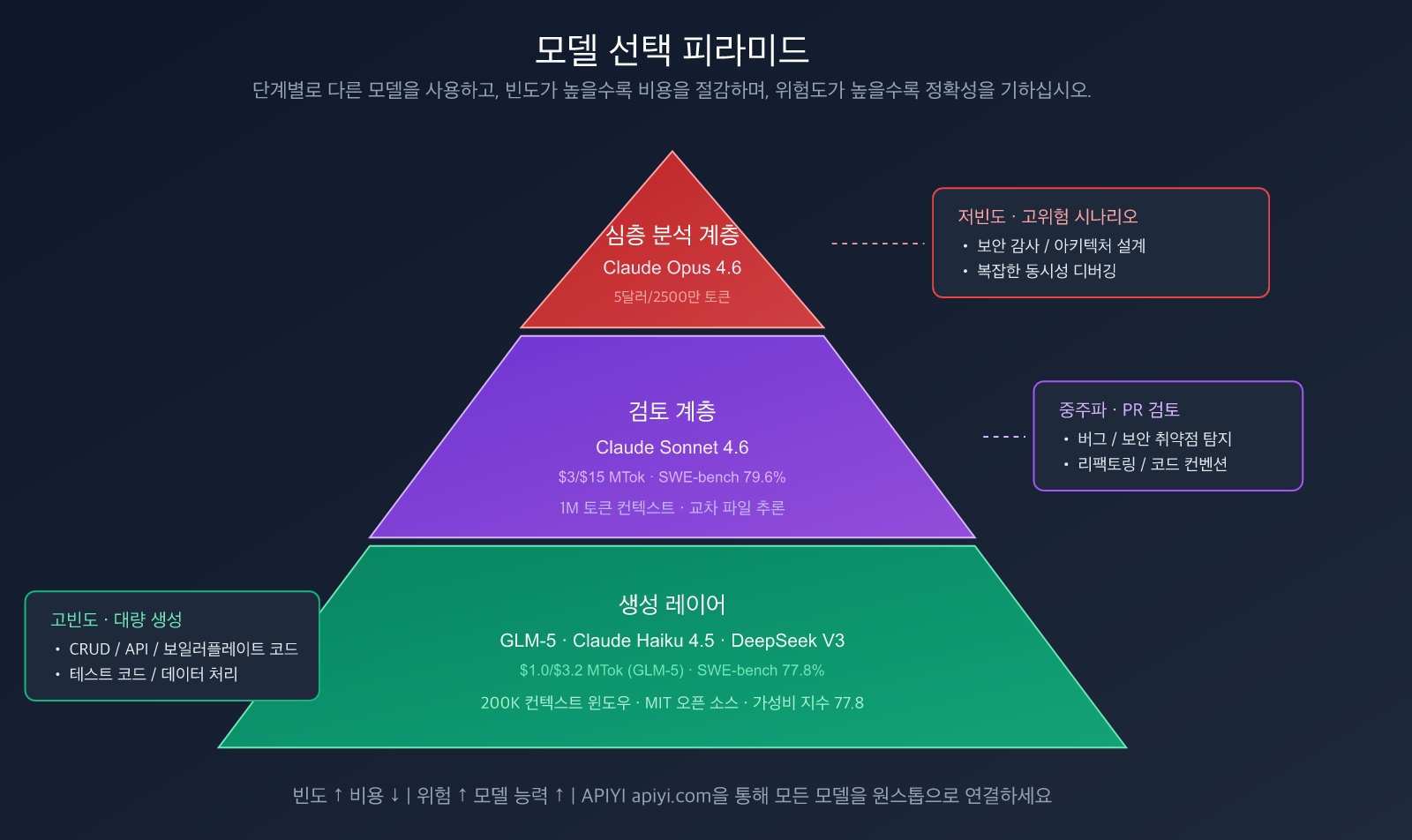
3단계 모델 피라미드
| 계층 | 용도 | 추천 모델 | 입/출력 가격 | 호출 빈도 |
|---|---|---|---|---|
| 생성 계층 | 코드 작성, CRUD, 보일러플레이트 | GLM-5, Claude Haiku 4.5 | $1.0/$3.2 (GLM-5) | 고빈도 |
| 검토 계층 | PR 검토, 버그 탐지, 리팩토링 제안 | Claude Sonnet 4.6 | $3/$15 | 중빈도 |
| 심층 계층 | 아키텍처 설계, 보안 감사, 복잡한 디버깅 | Claude Opus 4.6 | $5/$25 | 저빈도 |
코드 생성에 GLM-5를 선택하는 이유
GLM-5는 2026년 2월 智谱 AI(Zhipu AI)에서 발표한 오픈 소스 대규모 언어 모델로, 코드 생성 분야에서 압도적인 가성비를 자랑합니다.
GLM-5 핵심 사양:
- 파라미터 수: 744B (MoE 아키텍처, 256개 전문가, 매번 8개 활성화, 약 40B 활성 파라미터)
- 컨텍스트 윈도우: 200K 토큰
- SWE-bench Verified: 77.8% (오픈 소스 모델 1위)
- 라이선스: MIT (완전 상업용 가능)
- 입력 가격: $1.00/백만 토큰 — Claude Sonnet 4.6의 1/3 수준
GLM-5 vs 폐쇄형 모델 SWE-bench 비교:
| 모델 | SWE-bench Verified | 입력 가격 (백만 토큰당) | 가성비 지수 |
|---|---|---|---|
| Claude Opus 4.6 | 81.4% | $5.00 | 16.3 |
| Claude Sonnet 4.6 | 79.6% | $3.00 | 26.5 |
| GPT-5.2 | 80.0% | — | — |
| GLM-5 | 77.8% | $1.00 | 77.8 |
GLM-5의 가성비 지수(SWE-bench 점수 / 입력 가격)는 Claude Sonnet 4.6보다 약 3배 높습니다. 코드 생성과 같은 고빈도 작업에서는 호출량이 늘어날수록 비용 차이가 크게 벌어집니다.
코드 검토에 Claude Sonnet 4.6을 선택하는 이유
코드 검토에는 속도보다 깊이 있는 이해와 정확한 판단력이 필요합니다. Sonnet 4.6은 이 부분에서 생성 계층 모델보다 훨씬 뛰어납니다.
- 100만 토큰 컨텍스트: 전체 코드베이스 + PR diff + 의존 관계를 한 번에 로드 가능
- 교차 파일 추론: A 파일 수정이 B 파일의 로직 단절을 유발하는지 파악하는 능력
- SWE-bench 79.6%: Opus 4.6 대비 단 1.8%p 차이
- 개발자 선호도: Claude Code 테스트에서 개발자들은 Sonnet 4.6을 이전 플래그십인 Opus 4.5보다 59% 더 선호함
- 과도한 엔지니어링 방지: 이전 모델보다 "과도한 엔지니어링"이나 "대충 처리하는 현상"이 적다는 평가
비용 비교: Sonnet 4.6으로 검토하는 비용은 Opus 4.6의 1/5 수준이지만, 검토 품질은 거의 대등합니다. 대부분의 PR 검토 시나리오에서 최적의 선택입니다.
💡 선정 제안: APIYI(apiyi.com) 플랫폼을 통해 GLM-5와 Claude Sonnet 4.6 API를 동시에 연동하여 하나의 키로 여러 모델을 관리하세요. 생성 단계에서는 GLM-5를 호출해 비용을 절감하고, 검토 단계에서는 Sonnet 4.6으로 전환하여 품질을 확보하세요.
6단계 실전 워크플로우: 요구사항 정의부터 병합까지
검증된 완벽한 워크플로우를 소개합니다. 핵심 개념은 **탐색(Explore) → 계획(Plan) → 생성(Generate) → 검토(Review) → 테스트(Test) → 커밋(Commit)**입니다.
1단계: 사양 명세 (Specification)
코드를 작성하기 전에 먼저 명확한 요구사항 사양서를 작성하세요:
## 요구사항
사용자 등록 API 엔드포인트 구현
2단계: 계획 및 설계 (Plan)
구현하기 전에 구조를 먼저 잡아야 합니다. APIYI의 도구를 활용해 복잡한 로직을 세분화하세요.
3단계: 생성 (Generate)
이제 대규모 언어 모델을 사용하여 코드를 생성합니다. 프롬프트를 구체적으로 작성할수록 결과물의 품질이 높아집니다.
4단계: 검토 (Review)
생성된 코드를 그대로 사용하지 마세요. 보안 취약점이나 비효율적인 로직이 없는지 직접 검토하는 과정이 필수적입니다.
5단계: 테스트 (Test)
작성한 코드가 요구사항을 충족하는지 테스트합니다. 단위 테스트를 통해 모델 호출이 정상적으로 이루어지는지 확인하세요.
6단계: 커밋 (Commit)
모든 과정이 완료되었다면 코드를 저장소에 병합합니다. 변경 사항을 명확하게 기록하는 습관을 들이세요.
이 워크플로우를 따라가면 개발 효율성을 획기적으로 높일 수 있습니다. 더 많은 기술 팁은 APIYI에서 확인해 보세요!
제약 사항
- FastAPI 프레임워크 사용
- 비밀번호는 bcrypt로 암호화
- 이메일은 반드시 고유해야 하며, 중복 시 409 Conflict 반환
- PostgreSQL에 저장하며, SQLAlchemy ORM 사용
- JWT 토큰 반환
제외 사항
- 이메일 인증 절차 (추후 반복 작업에서 진행)
- 소셜 로그인
3단계: AI 계획 (Plan)
Claude Sonnet 4.6을 사용하여 아키텍처를 설계합니다 (설계 단계는 성능 좋은 모델을 사용하는 것이 좋습니다).
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": "당신은 수석 아키텍트입니다. 요구사항에 따라 파일 구조, 핵심 함수 시그니처, 데이터 흐름을 포함한 구현 계획을 출력하세요. 전체 코드를 작성하지 마세요."},
{"role": "user", "content": spec_content}
]
)
print(response.choices[0].message.content)
4단계: AI 코드 생성 (Generate)
계획이 확정되면 GLM-5를 사용하여 구현 코드를 생성합니다.
# 가성비가 좋은 모델로 전환하여 코드 생성
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": f"다음 아키텍처 계획에 따라 코드를 구현하세요:\n{plan}"},
{"role": "user", "content": "사용자 등록 API의 전체 코드를 구현해 주세요"}
],
max_tokens=8192
)
핵심 원칙:
- 한 번에 전체 프로젝트를 생성하지 말고, 함수/모듈 단위로 나누어 생성하세요.
- 생성 직후
git commit을 수행하여 롤백을 위한 "저장 지점"을 만드세요. - 반복적인 코드(CRUD, 폼 검증)는 AI에게 과감히 맡기세요.
- 보안에 민감한 코드(인증, 암호화, 권한)는 직접 작성하거나 철저히 검토하세요.
5단계: AI 검토 (Review)
코드 생성 후, Claude Sonnet 4.6으로 전환하여 검토를 진행합니다.
# 검토 모델로 전환
generated_code = open("app/routes/auth.py").read()
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"다음 코드를 검토해 주세요:\n\n{generated_code}"}
],
max_tokens=4096
)
전체 검토 Prompt 템플릿 보기
REVIEW_PROMPT = """당신은 베테랑 코드 리뷰 전문가입니다. 이 코드는 AI가 생성한 것이므로 다음 사항을 주의 깊게 확인하세요:
1. **AI의 흔한 실수**: 환각 API, 존재하지 않는 라이브러리 함수, 그럴듯해 보이지만 논리가 틀린 코드
2. **보안**: 인젝션, 하드코딩된 키, 안전하지 않은 암호화, 권한 우회
3. **경계 조건**: 빈 값, 동시성, 대용량 데이터, 네트워크 타임아웃
4. **아키텍처 일관성**: 프로젝트의 기존 스타일과 일치하는가? 명명 규칙, 계층 구조, 에러 처리
5. **테스트 용이성**: 단위 테스트를 작성하기 쉬운가? 의존성 주입이 가능한가?
심각도에 따라 분류하여 출력하세요:
- 🔴 필수 수정 (보안/논리 오류)
- 🟡 수정 권장 (코드 품질)
- 💡 개선 제안 (선택적 최적화)
문제가 없다면 "검토 통과"라고 명확히 밝히세요. 존재하지 않는 문제를 지어내지 마세요."""
6단계: 테스트 검증 (Test)
검토가 완료되면 테스트 코드를 생성합니다 (비용 절감을 위해 여전히 GLM-5를 사용합니다).
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "다음 코드를 위한 pytest 단위 테스트를 작성하세요. 정상 경로와 경계 조건을 모두 포함해야 합니다."},
{"role": "user", "content": generated_code}
]
)
7단계: 인간의 최종 검토 + 병합
AI 검토와 테스트가 모두 통과된 후, 사람이 최종 확인을 진행합니다.
- 아키텍처 결정이 합리적인가?
- 비즈니스 의도와 부합하는가?
- AI가 인지하지 못하는 컨텍스트상의 위험 요소는 없는가?
🚀 효율성 데이터: 이 워크플로우의 핵심 강점은 인간의 주의력을 가장 가치 있는 부분에 집중시키는 것입니다. AI는 80%의 기계적인 작업(생성, 스타일 검사, 기본 버그 탐지)을 처리하고, 인간은 20%의 고가치 판단(아키텍처, 보안, 비즈니스 로직)에 집중합니다. APIYI(apiyi.com) 플랫폼 하나로 GLM-5와 Claude 4.6의 API 호출을 관리하면, 여러 계정을 각각 등록하고 관리하는 번거로움을 덜 수 있습니다.
Claude Code: 풀스택 AI 프로그래밍의 끝판왕
복잡한 멀티 모델 워크플로우를 직접 구축하고 싶지 않으신가요? Claude Code가 그 해답을 제시합니다. 터미널에서 실행되는 AI 프로그래밍 에이전트인 Claude Code는 코드베이스를 스스로 읽고, 파일을 수정하며, 명령어를 실행하고, 문제를 해결하는 '올인원' 솔루션입니다.
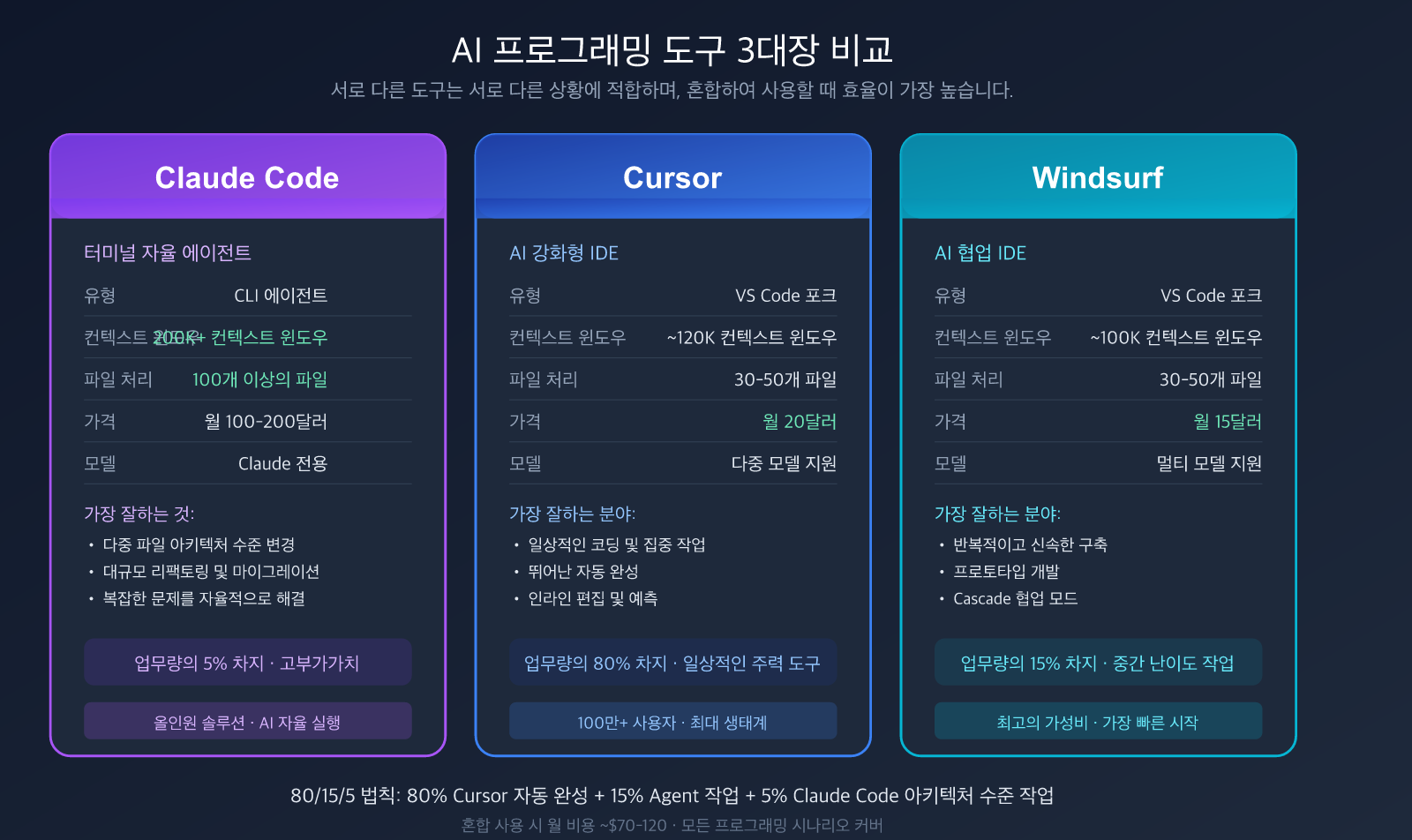
Claude Code의 핵심 강점
| 능력 | Claude Code | Cursor | Windsurf |
|---|---|---|---|
| 유형 | 터미널 자율 에이전트 | VS Code 강화판 | VS Code 강화판 |
| 철학 | AI 자율 실행 | AI 보조 편집 | AI 협업 코딩 |
| 컨텍스트 | 200K+ 토큰 | ~120K 토큰 | ~100K 토큰 |
| 파일 처리 | 100+ 파일 | 30-50 파일 | 30-50 파일 |
| 강점 | 다중 파일 아키텍처 변경 | 일상 코딩, 특정 작업 | 반복 빌드, 프로토타입 |
| 가격 | $100-200/월 또는 API 사용량 | $20/월 | $15/월 |
Claude Code 베스트 프랙티스
1. AI에게 스스로 작업 방식을 검증하게 하세요
공식 문서에서도 강조하는 가장 효율적인 방법입니다.
# 좋은 프롬프트
"사용자 등록 기능을 구현하고, pytest 테스트 코드를 작성해. 테스트가 통과된 것을 확인한 후 커밋해줘."
# 나쁜 프롬프트
"사용자 등록 기능 구현해줘."
2. Writer/Reviewer 듀얼 세션 모드
Claude Code 세션을 두 개 띄워놓고 사용해 보세요.
- 세션 A (Writer): 기능 구현에 집중
- 세션 B (Reviewer): 새로운 컨텍스트에서 Writer의 결과물을 검토
이렇게 'AI가 AI를 검토하는' 방식을 사용하면 단일 AI가 놓칠 수 있는 사각지대를 효과적으로 발견할 수 있습니다.
3. CLAUDE.md 프로젝트 설정 활용하기
# CLAUDE.md
# 프로젝트 규칙, 코드 스타일, 필수 테스트 절차 등을 명시하여 AI의 가이드라인으로 활용하세요.
프로젝트 기술 스택
Python 3.12 + FastAPI + SQLAlchemy + PostgreSQL
코드 컨벤션
- 타입 힌트: 모든 함수에는 반드시 타입 힌트를 명시해야 합니다.
- 에러 처리: 사용자 정의
AppError클래스를 사용하여 처리합니다. - 로깅: 비즈니스 이벤트는 INFO 레벨, 디버깅은 DEBUG 레벨을 사용합니다.
금지 사항
print()사용 금지,logger사용 권장- 설정값 하드코딩 금지, 환경 변수 사용
- 라우트 함수 내 직접적인 SQL 작성 금지
**4. 80/15/5 도구 조합 법칙**
숙련된 개발자들이 추천하는 도구 배분 비율입니다:
- **80%**: 자동 완성 및 인라인 편집 (Cursor/Copilot) — 일상적인 코딩
- **15%**: 중간 복잡도의 에이전트 작업 (Cursor Agent/Windsurf) — 기능 구현
- **5%**: 복잡한 다중 파일 아키텍처 변경 (Claude Code) — 대규모 리팩토링
> 💰 **비용 제안**: Claude Code의 API 모드는 토큰 단위로 과금됩니다. APIYI(apiyi.com)를 통해 접속하면 공식 모델보다 더 저렴한 가격으로 Claude 모델을 이용할 수 있습니다. Claude Code의 모든 기능이 필요하지 않은 경우, API를 통해 Claude Sonnet 4.6을 직접 호출하여 코드 리뷰를 진행할 수도 있습니다.
---
## 실전 사례: 완벽한 코드 생성 + 리뷰 프로세스
실제 시나리오를 예로 들어보겠습니다. GLM-5로 FastAPI 사용자 인증 모듈을 생성하고, Claude Sonnet 4.6으로 리뷰하는 과정입니다.
### 전체 워크플로우 코드
```python
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
# ===== 1단계: GLM-5로 코드 생성 =====
gen_response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "당신은 Python 백엔드 전문가입니다."},
{"role": "user", "content": """
FastAPI 사용자 등록 엔드포인트 구현:
- POST /api/v1/register
- email과 password 수신
- bcrypt로 비밀번호 암호화
- PostgreSQL에 저장
- JWT 토큰 반환
"""}
],
max_tokens=4096
)
generated_code = gen_response.choices[0].message.content
# ===== 2단계: Claude Sonnet 4.6으로 리뷰 =====
review_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"다음 AI 생성 코드를 리뷰하세요:\n\n{generated_code}"}
],
max_tokens=4096
)
review_result = review_response.choices[0].message.content
# logger를 사용하여 리뷰 결과 출력
logger.info(f"=== 리뷰 결과 ===\n{review_result}")
비용 분석
| 단계 | 모델 | 입력 토큰 | 출력 토큰 | 비용 |
|---|---|---|---|---|
| 코드 생성 | GLM-5 | ~500 | ~2000 | ~$0.007 |
| 코드 리뷰 | Sonnet 4.6 | ~3000 | ~1500 | ~$0.032 |
| 합계 | — | — | — | ~$0.04 |
"생성+리뷰" 전체 과정의 비용은 1회당 $0.04 미만입니다. 하루에 50번씩 이 과정을 반복해도 월 비용은 약 $60 수준입니다.
만약 전체 과정을 Claude Opus 4.6으로 진행한다면 동일한 워크플로우 비용이 약 $0.18/회로, 조합 방식보다 4.5배 더 비쌉니다.
🎯 핵심 요약: GLM-5 생성 + Sonnet 4.6 리뷰 조합을 사용하면, 전체 과정을 Opus 4.6으로 진행할 때보다 비용을 22% 수준으로 절감하면서도 리뷰 품질은 거의 차이가 없습니다. APIYI(apiyi.com) 플랫폼의 API 키 하나로 모든 모델을 간편하게 호출해 보세요.
자주 묻는 질문 (FAQ)
Q1: 저렴한 모델로 작성한 코드의 품질은 충분한가요?
GLM-5는 SWE-bench Verified에서 77.8점을 기록했는데, 이는 Claude Sonnet 4.6보다 약 2% 포인트 낮을 뿐이지만 가격은 1/3 수준입니다. 대부분의 코드 생성 작업(CRUD, API 엔드포인트, 데이터 처리)에는 품질이 충분합니다. 핵심은 후속 검토 과정을 통해 보완하는 것입니다. APIYI(apiyi.com)를 통하면 두 모델을 동시에 연동하여 유연하게 전환할 수 있습니다.
Q2: 어떤 상황에서 저렴한 모델을 사용하면 안 되나요?
보안이 중요한 코드(인증, 암호화, 권한 제어), 동시성 및 분산 처리 로직, 금융 계산이 포함된 정밀한 코드 등입니다. 이러한 작업은 Claude Sonnet 4.6이나 Opus 4.6을 직접 사용하거나, 수동 작성 후 AI 검토를 받는 것을 권장합니다.
Q3: Claude Code는 모두에게 적합한가요?
Claude Code는 복잡한 다중 파일 아키텍처 작업을 처리하는 숙련된 개발자에게 가장 적합합니다. 만약 단일 파일 수정이나 일상적인 코딩이 주 업무라면 Cursor나 Windsurf가 더 적합할 수 있습니다(비용도 더 저렴합니다). 많은 시니어 개발자가 일상 업무에는 Cursor를, 복잡한 작업에는 Claude Code를 혼합하여 사용합니다.
Q4: 이 워크플로우의 효과는 어떻게 측정하나요?
다음 4가지 지표를 추적하세요: (1) 1인당 코드 생산량 변화, (2) 버그 발생률 변화(배포 후 결함 수), (3) 검토 시간 변화, (4) API 호출 비용. 2주간 시범 운영을 통해 전후 데이터를 비교하는 것을 추천합니다. APIYI(apiyi.com)의 사용량 통계 기능을 활용하면 API 비용을 쉽게 추적할 수 있습니다.
Q5: GLM-5 외에 가성비 좋은 코드 생성 모델은 무엇이 있나요?
Claude Haiku 4.5(속도가 매우 빨라 간단한 작업에 적합), DeepSeek V3(오픈 소스, 중국어 환경에 강점), GPT-5.3 Codex(코드 특화) 등이 있습니다. 어떤 모델을 선택할지는 언어 선호도와 구체적인 상황에 따라 다릅니다. APIYI(apiyi.com)를 통하면 이 모든 모델을 한곳에서 연동할 수 있어 여러 플랫폼을 관리하는 번거로움을 덜 수 있습니다.
요약: AI 프로그래밍을 제대로 활용하는 방법
AI 프로그래밍의 핵심은 "AI에게 모든 코드를 맡기는 것"이 아니라, 효율적인 다중 모델 협업 프로세스를 구축하는 것입니다. 2026년의 베스트 프랙티스는 다음과 같습니다.
모델 선택 공식:
- 🟢 고빈도 저위험 (보일러플레이트 코드, CRUD) → GLM-5 등 가성비 모델
- 🟡 중빈도 중위험 (PR 검토, 리팩토링) → Claude Sonnet 4.6
- 🔴 저빈도 고위험 (보안 감사, 아키텍처 설계) → Claude Opus 4.6
워크플로우 공식:
- 사양 정의 → 계획 수립 → 코드 생성 → 검토 → 테스트 → 최종 인간 검수
- AI는 80%의 기계적인 작업을 처리하고, 인간은 20%의 고가치 판단에 집중하세요.
APIYI(apiyi.com)를 통해 GLM-5, Claude Sonnet 4.6, Opus 4.6 등 모든 주요 모델을 한 번에 연동하고, 하나의 플랫폼에서 완벽한 다중 모델 AI 프로그래밍 워크플로우를 구축해 보세요.
참고 자료
-
Addy Osmani: LLM 프로그래밍 워크플로우 2026
- 링크:
addyosmani.com/blog/ai-coding-workflow
- 링크:
-
Claude Code 공식 모범 사례: 에이전트 기반 프로그래밍 가이드
- 링크:
code.claude.com/docs/en/best-practices
- 링크:
-
GLM-5 기술 논문: Vibe Coding에서 엔지니어링 AI 프로그래밍으로
- 링크:
arxiv.org
- 링크:
-
Anthropic 공식: Claude Sonnet 4.6 출시 발표
- 링크:
anthropic.com/news/claude-sonnet-4-6
- 링크:
-
MIT Technology Review: 생성형 프로그래밍 2026년 혁신 기술
- 링크:
technologyreview.com
- 링크:
저자: APIYI 팀 | AI 기반 소프트웨어 개발의 모범 사례를 탐구합니다. APIYI(apiyi.com)에서 GLM-5, Claude 4.6 전 시리즈 모델의 통합 API를 만나보세요.