
В 2026 году 92% разработчиков уже используют AI-инструменты для программирования, а 41% кода генерируется с помощью ИИ. Но есть неприятная реальность: разработчики сообщают об экономии времени на 30-60%, однако реальный прирост продуктивности организации составляет лишь около 10%. В чем разрыв? В рабочем процессе.
Если подобрать правильную комбинацию моделей и выстроить рабочий процесс, AI-программирование станет инструментом для 10-кратного повышения эффективности. Если ошибиться — это превратится в генератор кода, который «вроде бы работает, но в любой момент может взорваться».
Основная ценность: Прочитав эту статью, вы освоите проверенный рабочий процесс AI-программирования с использованием нескольких моделей: генерация кода с помощью экономичных моделей (например, GLM-5), проверка кода с помощью топовых моделей (например, Claude Sonnet 4.6), а также автоматизация полного цикла с помощью Claude Code.
Фундаментальные изменения в рабочем процессе программирования с ИИ
Трансформация роли разработчика: от «писателя кода» к «дирижеру ИИ»
В разработке ПО 2026 года основная работа программиста заключается уже не в написании кода строка за строкой, а в следующем:
- Написание спецификаций (Specification Engineering) — определение требований, ограничений и архитектурных предпочтений.
- Выбор комбинации моделей — использование разных моделей на разных этапах.
- Проверка и контроль — гарантия того, что результат работы ИИ соответствует инженерным стандартам.
- Принятие окончательной ответственности — ИИ лишь инструмент, человек — ответственное лицо.
Адди Османи (технический руководитель команды Google Chrome) сформулировал ключевой принцип: «Сначала планируй, потом пиши код. Менять план дешево, менять код — дорого».
Новый рабочий процесс vs Традиционный
| Параметр | Традиционный процесс | ИИ-ориентированный процесс |
|---|---|---|
| Основная деятельность | Написание кода построчно | Написание спецификаций + проверка вывода ИИ |
| Роль разработчика | Кодер (Coder) | Оркестратор (Orchestrator) |
| Генерация кода | 100% вручную | ~40% ИИ + ручная доработка |
| Фокус проверки | Логика и стиль | Качество вывода ИИ + архитектурная целостность |
| Инструментарий | IDE + Git | ИИ-агент + IDE + Git + мультимодальные модели |
| Узкое место | Скорость кодинга | Скорость проверки и принятия решений |
Ключевые данные: реальное положение дел в ИИ-программировании
| Данные | Источник |
|---|---|
| 92% разработчиков используют ИИ-инструменты | Отраслевой опрос 2026 г. |
| 41% коммитов кода созданы с помощью ИИ | Данные GitHub |
| Лишь 30% предложений ИИ принимаются напрямую | Отчет CodeRabbit |
| Лишь 29-46% разработчиков доверяют выводу ИИ | Сводные опросы |
| Реальный рост продуктивности команд ~10% | Консенсус 6 независимых исследований |
| Уровень дефектов в ИИ-коде в 1,7 раза выше, чем у людей | Анализ 470 PR |
🎯 Ключевой инсайт: Ключ к росту продуктивности не в том, сколько кода может сгенерировать ИИ, а в наличии у вас эффективной системы проверки и верификации. Через платформу APIYI (apiyi.com) вы можете гибко комбинировать различные модели для построения такой системы.
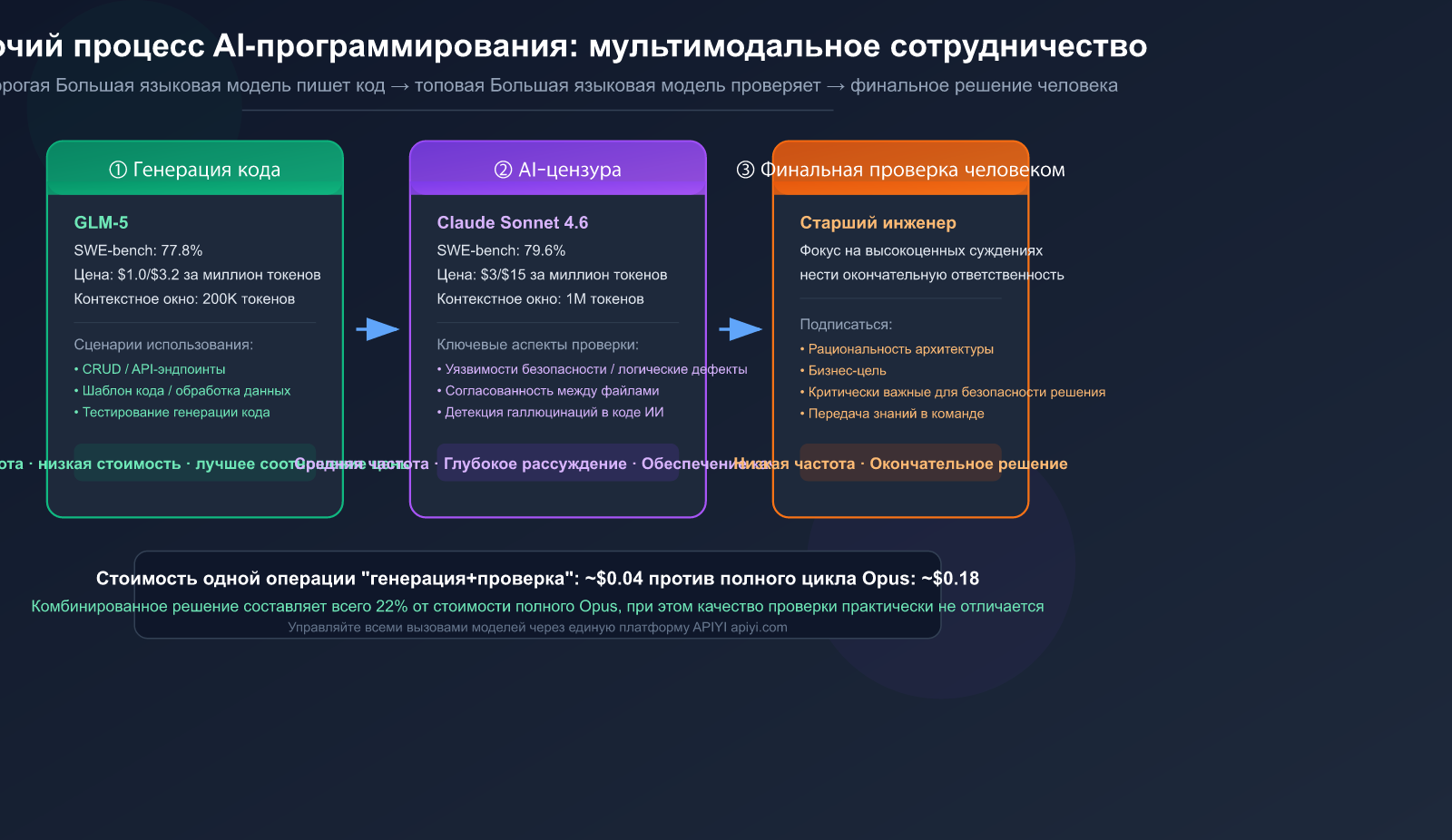
Стратегия выбора моделей: дешево пишем, качественно проверяем
Это ключевая методология данной статьи — использование разных моделей на разных этапах. Как гоночная команда не отправит болид F1 на доставку грузов, так и грузовик не пустит на трек.
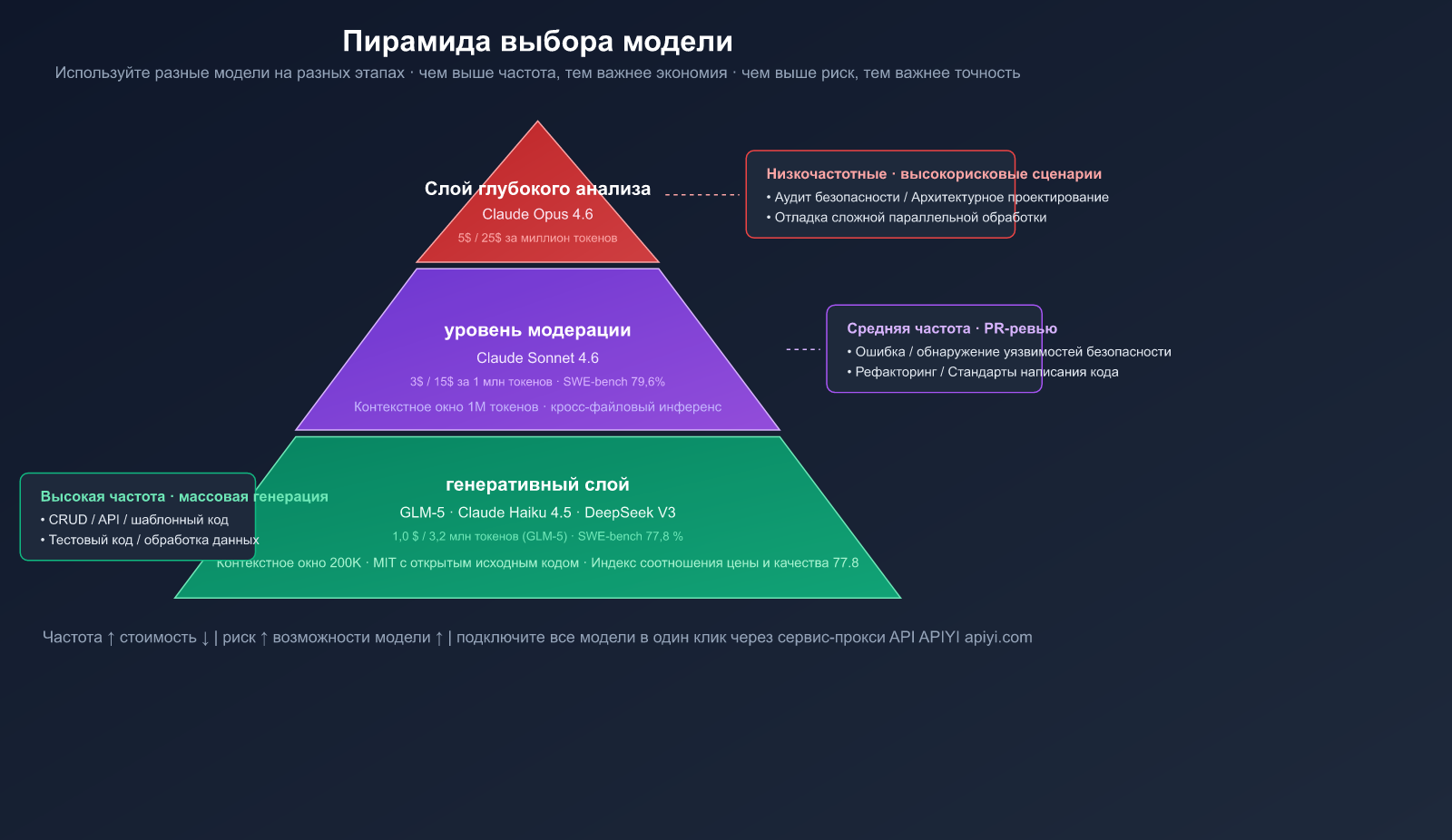
Трехуровневая пирамида моделей
| Уровень | Назначение | Рекомендуемая модель | Цена (вход/выход) | Частота вызовов |
|---|---|---|---|---|
| Генерация | Написание кода, CRUD, шаблонный код | GLM-5, Claude Haiku 4.5 | $1.0/$3.2 (GLM-5) | Высокая |
| Проверка | PR-ревью, поиск багов, рефакторинг | Claude Sonnet 4.6 | $3/$15 | Средняя |
| Глубокий анализ | Архитектура, аудит безопасности, отладка | Claude Opus 4.6 | $5/$25 | Низкая |
Почему GLM-5 для генерации кода
GLM-5 — это открытая большая языковая модель, выпущенная Zhipu AI в феврале 2026 года, обладающая высочайшей эффективностью в задачах генерации кода.
Основные характеристики GLM-5:
- Количество параметров: 744B (архитектура MoE, 256 экспертов, 8 активных на запрос, ~40B активных параметров)
- Контекстное окно: 200K токенов
- SWE-bench Verified: 77.8% (лучшая среди открытых моделей)
- Лицензия: MIT (полностью коммерческая)
- Цена за вход: $1.00/млн токенов — всего 1/3 от цены Claude Sonnet 4.6
Сравнение GLM-5 с закрытыми моделями на SWE-bench:
| Модель | SWE-bench Verified | Цена за вход (млн токенов) | Индекс эффективности |
|---|---|---|---|
| Claude Opus 4.6 | 81.4% | $5.00 | 16.3 |
| Claude Sonnet 4.6 | 79.6% | $3.00 | 26.5 |
| GPT-5.2 | 80.0% | — | — |
| GLM-5 | 77.8% | $1.00 | 77.8 |
Индекс эффективности GLM-5 (счет SWE-bench / цена за вход) почти в 3 раза выше, чем у Claude Sonnet 4.6. Для высокочастотных операций, таких как генерация кода, разница в стоимости быстро становится ощутимой.
Почему Claude Sonnet 4.6 для проверки кода
Для проверки кода важна не скорость, а глубокое понимание и точность суждений. Sonnet 4.6 в этом плане значительно превосходит модели генеративного уровня:
- Контекст 1 млн токенов: позволяет загрузить весь кодовый репозиторий + PR diff + зависимости за один раз.
- Кросс-файловый анализ: способность обнаруживать логические разрывы в файле B, вызванные изменениями в файле A.
- SWE-bench 79.6%: всего на 1.8 процентных пункта ниже, чем у Opus 4.6.
- Предпочтения разработчиков: в тестах Claude Code разработчики выбирали Sonnet 4.6 чаще, чем флагман Opus 4.5, в 59% случаев.
- Отсутствие избыточности: по сравнению с предыдущими моделями, Sonnet 4.6 реже «переусложняет» код или «халтурит».
Сравнение затрат: использование Sonnet 4.6 для ревью стоит в 5 раз дешевле, чем Opus 4.6, при сопоставимом качестве проверки. Для большинства сценариев PR-ревью это оптимальный выбор.
💡 Совет по выбору: Через платформу APIYI (apiyi.com) вы можете одновременно подключить API GLM-5 и Claude Sonnet 4.6, управляя несколькими моделями через один ключ. Используйте GLM-5 на этапе генерации для экономии, и переключайтесь на Sonnet 4.6 для обеспечения качества на этапе проверки.
6-шаговый рабочий процесс: от требований до коммита
Вот проверенный на практике полный рабочий процесс. Основная концепция: Explore (Исследование) → Plan (Планирование) → Generate (Генерация) → Review (Проверка) → Test (Тестирование) → Commit (Коммит).
Шаг 1: Спецификация (Specification)
Прежде чем писать хоть строчку кода, составьте четкое описание требований:
## Требования
Реализовать API-эндпоинт для регистрации пользователей
Ограничения
- Используем фреймворк FastAPI
- Пароли шифруем с помощью bcrypt
- Email должен быть уникальным, при дублировании возвращаем ошибку 409 Conflict
- Запись в PostgreSQL через SQLAlchemy ORM
- Возвращаем JWT-токен
Что не нужно
- Процесс подтверждения email (отложим на следующие итерации)
- Социальная авторизация
### Шаг 2: Планирование с помощью ИИ (Plan)
Используем Claude Sonnet 4.6 для проработки архитектуры (на этапе планирования стоит использовать мощную модель):
```python
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": "Ты — ведущий архитектор. На основе требований составь план реализации, включая структуру файлов, сигнатуры ключевых функций и потоки данных. Не пиши полный код."},
{"role": "user", "content": spec_content}
]
)
print(response.choices[0].message.content)
Шаг 3: Генерация кода с помощью ИИ (Generate)
После утверждения плана используем GLM-5 для написания кода:
# Переключаемся на экономичную модель для генерации кода
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": f"Реализуй код согласно следующему архитектурному плану:\n{plan}"},
{"role": "user", "content": "Пожалуйста, напиши полный код API для регистрации пользователя"}
],
max_tokens=8192
)
Ключевые принципы:
- Генерируйте по одной функции или модулю за раз, не пытайтесь создать весь проект целиком.
- Сразу после генерации делайте
git commit— это будет вашей «точкой сохранения» для отката. - Рутинный код (CRUD, валидация форм) смело отдавайте ИИ.
- Критически важный код (аутентификация, шифрование, права доступа) пишите вручную или подвергайте двойной проверке.
Шаг 4: ИИ-ревью (Review)
После генерации кода переключаемся на Claude Sonnet 4.6 для проверки:
# Переключаемся на модель для ревью
generated_code = open("app/routes/auth.py").read()
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Пожалуйста, проведи ревью этого кода:\n\n{generated_code}"}
],
max_tokens=4096
)
Посмотреть полный шаблон промпта для ревью
REVIEW_PROMPT = """Ты — эксперт по код-ревью. Этот код сгенерирован ИИ, обрати особое внимание на:
1. **Типичные ошибки ИИ**: несуществующие API, выдуманные функции библиотек, код, который выглядит верным, но содержит логические ошибки.
2. **Безопасность**: инъекции, захардкоженные ключи, небезопасное шифрование, обход прав доступа.
3. **Граничные условия**: пустые значения, конкурентность, большие объемы данных, таймауты сети.
4. **Архитектурная целостность**: соответствует ли код стилю проекта? Именование, слои, обработка ошибок.
5. **Тестируемость**: легко ли написать unit-тесты? Можно ли внедрять зависимости?
Выводи отчет по уровням критичности:
- 🔴 Обязательно к исправлению (ошибки безопасности/логики)
- 🟡 Рекомендуется исправить (качество кода)
- 💡 Предложения по улучшению (опционально)
Если проблем нет, напиши "Ревью пройдено". Не выдумывай несуществующие проблемы."""
Шаг 5: Тестирование (Test)
После успешного ревью генерируем тесты (все еще используем GLM-5 для экономии):
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Напиши unit-тесты на pytest для следующего кода, покрыв нормальные сценарии и граничные условия."},
{"role": "user", "content": generated_code}
]
)
Шаг 6: Финальная проверка человеком + слияние
После того как ИИ провел ревью и тесты пройдены, человек делает финальный вывод:
- Разумны ли архитектурные решения?
- Соответствует ли код бизнес-задачам?
- Есть ли контекстные риски, которые ИИ не может распознать?
🚀 Эффективность: Главное преимущество этого рабочего процесса в том, что внимание человека сосредоточено на самом важном. ИИ берет на себя 80% рутины (генерация, проверка стиля, базовые баги), а человек фокусируется на 20% высокоуровневых задач (архитектура, безопасность, бизнес-логика). Используя платформу APIYI apiyi.com, вы управляете API-ключами для GLM-5 и Claude 4.6 в одном месте, избавляясь от необходимости регистрироваться и следить за множеством сервисов.
Claude Code: ультимативное решение для AI-программирования полного цикла
Если вы не хотите самостоятельно настраивать сложные рабочие процессы с использованием нескольких моделей, Claude Code предлагает решение «все в одном». Это AI-агент, работающий прямо в терминале, который способен самостоятельно изучать кодовую базу, редактировать файлы, выполнять команды и решать задачи.

Ключевые преимущества Claude Code
| Возможности | Claude Code | Cursor | Windsurf |
|---|---|---|---|
| Тип | Автономный агент в терминале | Улучшенный VS Code | Улучшенный VS Code |
| Концепция | Автономное выполнение AI | AI-помощник в редактировании | AI-коллаборация в коде |
| Контекст | 200K+ токенов | ~120K токенов | ~100K токенов |
| Обработка файлов | 100+ файлов | 30-50 файлов | 30-50 файлов |
| Специализация | Архитектурные изменения | Повседневный код, задачи | Итеративная сборка, прототипы |
| Цена | $100-200/мес или по API | $20/мес | $15/мес |
Лучшие практики работы с Claude Code
1. Дайте AI способ проверить свою работу
Это рекомендация из официальной документации, которая дает максимальный эффект:
# Хороший промпт
"Реализуй функцию регистрации пользователя, напиши соответствующие pytest-тесты и отправь изменения только после успешного прохождения тестов"
# Плохой промпт
"Реализуй функцию регистрации пользователя"
2. Режим двух сессий: Автор/Рецензент
Запустите два сеанса Claude Code:
- Сессия A (Автор): фокусируется на реализации функционала.
- Сессия B (Рецензент): проверяет вывод Автора с использованием «чистого» контекста.
Такой подход «AI проверяет AI» позволяет эффективно находить слепые зоны, которые может пропустить один агент.
3. Используйте конфигурацию проекта CLAUDE.md
# CLAUDE.md
Технологический стек проекта
Python 3.12 + FastAPI + SQLAlchemy + PostgreSQL
Стандарты написания кода
- Аннотации типов: все функции должны содержать аннотации типов.
- Обработка ошибок: используйте кастомный класс
AppError. - Логирование: бизнес-события — уровень INFO, отладка — DEBUG.
Запреты
- Не используйте
print(), используйтеlogger - Не хардкодьте конфигурации, используйте переменные окружения
- Не пишите SQL-запросы напрямую в функциях маршрутизации
**4. Правило сочетания инструментов 80/15/5**
Рекомендуемое распределение инструментов от опытных разработчиков:
- **80%**: Автодополнение и инлайн-редактирование (Cursor/Copilot) — для повседневного кодинга.
- **15%**: Агентные задачи средней сложности (Cursor Agent/Windsurf) — для реализации функционала.
- **5%**: Сложные архитектурные изменения в нескольких файлах (Claude Code) — для масштабного рефакторинга.
> 💰 **Совет по затратам**: Режим API для Claude Code тарифицируется по токенам. Если подключаться через сервис-прокси API APIYI (apiyi.com), можно получить доступ к моделям Claude по более выгодным ценам, чем напрямую. Для сценариев, где не требуется полный функционал Claude Code, можно напрямую вызывать Claude Sonnet 4.6 через API для проведения ревью.
---
## Практический кейс: полный цикл генерации и проверки кода
Ниже показан реальный сценарий: генерация модуля аутентификации пользователей FastAPI с помощью GLM-5 и последующая проверка через Claude Sonnet 4.6.
### Код рабочего процесса
```python
import openai
import logging
# Настройка логгера вместо print
logger = logging.getLogger(__name__)
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
# ===== Шаг 1: Генерация кода с помощью GLM-5 =====
gen_response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Ты эксперт по бэкенду на Python."},
{"role": "user", "content": """
Реализуй эндпоинт регистрации пользователя в FastAPI:
- POST /api/v1/register
- Принимает email и password
- Хеширует пароль через bcrypt
- Сохраняет в PostgreSQL
- Возвращает JWT-токен
"""}
],
max_tokens=4096
)
generated_code = gen_response.choices[0].message.content
# ===== Шаг 2: Ревью с помощью Claude Sonnet 4.6 =====
review_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Проверь следующий AI-сгенерированный код:\n\n{generated_code}"}
],
max_tokens=4096
)
review_result = review_response.choices[0].message.content
logger.info("=== Результат проверки ===")
logger.info(review_result)
Анализ затрат
| Шаг | Модель | Входящие токены | Исходящие токены | Стоимость |
|---|---|---|---|---|
| Генерация кода | GLM-5 | ~500 | ~2000 | ~$0.007 |
| Ревью кода | Sonnet 4.6 | ~3000 | ~1500 | ~$0.032 |
| Итого | — | — | — | ~$0.04 |
Полная стоимость одного цикла «генерация + проверка» составляет менее $0.04. Даже если делать 50 таких циклов в день, месячные затраты составят всего около $60.
Если использовать только Claude Opus 4.6, стоимость того же рабочего процесса составит около $0.18 за раз — это в 4.5 раза дороже, чем комбинированный подход.
🎯 Ключевые цифры: Комбинированная схема (генерация через GLM-5 + проверка через Sonnet 4.6) стоит всего 22% от стоимости использования Opus 4.6 на всех этапах, при этом качество проверки практически не отличается. Все вызовы можно выполнять через один API-ключ на платформе APIYI (apiyi.com).
Часто задаваемые вопросы
Q1: Достаточно ли хорошего качества кода, написанного дешевыми моделями?
GLM-5 набирает 77,8% в бенчмарке SWE-bench Verified, что всего на 2 процентных пункта ниже, чем у Claude Sonnet 4.6, при этом цена составляет лишь 1/3. Для большинства задач по генерации кода (CRUD, API-эндпоинты, обработка данных) этого качества вполне достаточно. Главное — наличие последующего этапа проверки. Через APIYI apiyi.com можно одновременно подключить обе модели и гибко переключаться между ними.
Q2: В каких сценариях не стоит использовать дешевые модели для генерации кода?
Код, критически важный для безопасности (аутентификация, шифрование, контроль прав доступа), логика параллельных и распределенных вычислений, а также код, требующий высокой точности в финансовых расчетах. В таких случаях рекомендуется использовать Claude Sonnet 4.6 или Opus 4.6, либо писать код вручную с последующей проверкой ИИ.
Q3: Подходит ли Claude Code всем?
Claude Code лучше всего подходит опытным разработчикам для решения сложных архитектурных задач, затрагивающих множество файлов. Если ваша работа в основном сводится к правкам в отдельных файлах и повседневным задачам кодинга, Cursor или Windsurf могут подойти лучше (и они дешевле). Многие опытные разработчики используют комбинированный подход: Cursor для повседневных задач, Claude Code — для сложных.
Q4: Как оценить эффективность этого рабочего процесса?
Отслеживайте 4 показателя: (1) изменение объема кода на разработчика; (2) изменение уровня ошибок (количество дефектов после релиза); (3) изменение времени на проверку (ревью); (4) стоимость вызовов API. Рекомендуется провести двухнедельный пилотный проект и сравнить данные до и после. С помощью функции статистики использования на APIYI apiyi.com можно легко отслеживать затраты на API.
Q5: Какие еще модели для генерации кода, помимо GLM-5, обладают хорошим соотношением цены и качества?
Claude Haiku 4.5 (очень высокая скорость, подходит для простых задач), DeepSeek V3 (open-source, отлично работает с китайским языком), GPT-5.3 Codex (специализируется на коде). Выбор зависит от ваших языковых предпочтений и конкретных задач. Через APIYI apiyi.com можно получить доступ ко всем этим моделям в одном месте, избавившись от необходимости управлять множеством платформ.
Резюме: как правильно подходить к AI-программированию
Суть AI-программирования не в том, чтобы «заставить ИИ написать весь код», а в создании эффективного процесса взаимодействия нескольких моделей. Лучшая практика 2026 года выглядит так:
Формула выбора модели:
- 🟢 Часто, низкий риск (шаблонный код, CRUD) → GLM-5 и другие модели с хорошим соотношением цены и качества
- 🟡 Средне, средний риск (PR-ревью, рефакторинг) → Claude Sonnet 4.6
- 🔴 Редко, высокий риск (аудит безопасности, архитектурное проектирование) → Claude Opus 4.6
Формула рабочего процесса:
- Сначала спецификация, затем планирование, генерация, проверка, тестирование и, наконец, финальное решение человека.
- ИИ берет на себя 80% рутинной работы, человек фокусируется на 20% высокоуровневых решений.
Рекомендуем использовать APIYI apiyi.com для единого доступа ко всем основным моделям, включая GLM-5, Claude Sonnet 4.6 и Opus 4.6, чтобы выстроить полноценный рабочий процесс AI-программирования на одной платформе.
Справочные материалы
-
Addy Osmani: Рабочий процесс программирования с LLM 2026
- Ссылка:
addyosmani.com/blog/ai-coding-workflow
- Ссылка:
-
Официальные рекомендации Claude Code: Руководство по агентному программированию
- Ссылка:
code.claude.com/docs/en/best-practices
- Ссылка:
-
Техническая статья GLM-5: От Vibe Coding к инженерному AI-программированию
- Ссылка:
arxiv.org
- Ссылка:
-
Официальный блог Anthropic: Анонс выпуска Claude Sonnet 4.6
- Ссылка:
anthropic.com/news/claude-sonnet-4-6
- Ссылка:
-
MIT Technology Review: Прорывные технологии в генеративном программировании 2026 года
- Ссылка:
technologyreview.com
- Ссылка:
Автор: Команда APIYI | Исследуем лучшие практики использования ИИ в разработке ПО. Посетите APIYI (apiyi.com), чтобы получить доступ к единому API для всей линейки моделей GLM-5 и Claude 4.6.