
Im Jahr 2026 nutzen bereits 92 % der Entwickler KI-Programmiertools, und 41 % des Codes werden KI-gestützt generiert. Doch die ernüchternde Realität lautet: Während Zeitersparnisse von 30–60 % gemeldet werden, steigt die tatsächliche Produktivität in Unternehmen nur um etwa 10 %. Wo liegt die Lücke? Im Workflow.
Mit der richtigen Modellkombination und dem passenden Workflow ist KI-Programmierung ein Produktivitäts-Turbo; falsch eingesetzt ist sie nur ein „sieht-gut-aus-aber-explodiert-jederzeit“-Codegenerator.
Kernnutzen: Nach diesem Artikel beherrschen Sie einen bewährten Multi-Modell-KI-Programmier-Workflow – nutzen Sie kosteneffiziente Modelle (wie GLM-5) für die Codegenerierung, Spitzenmodelle (wie Claude Sonnet 4.6) für das Code-Review und erfahren Sie, wie Sie mit Claude Code eine durchgängige Automatisierung erreichen.
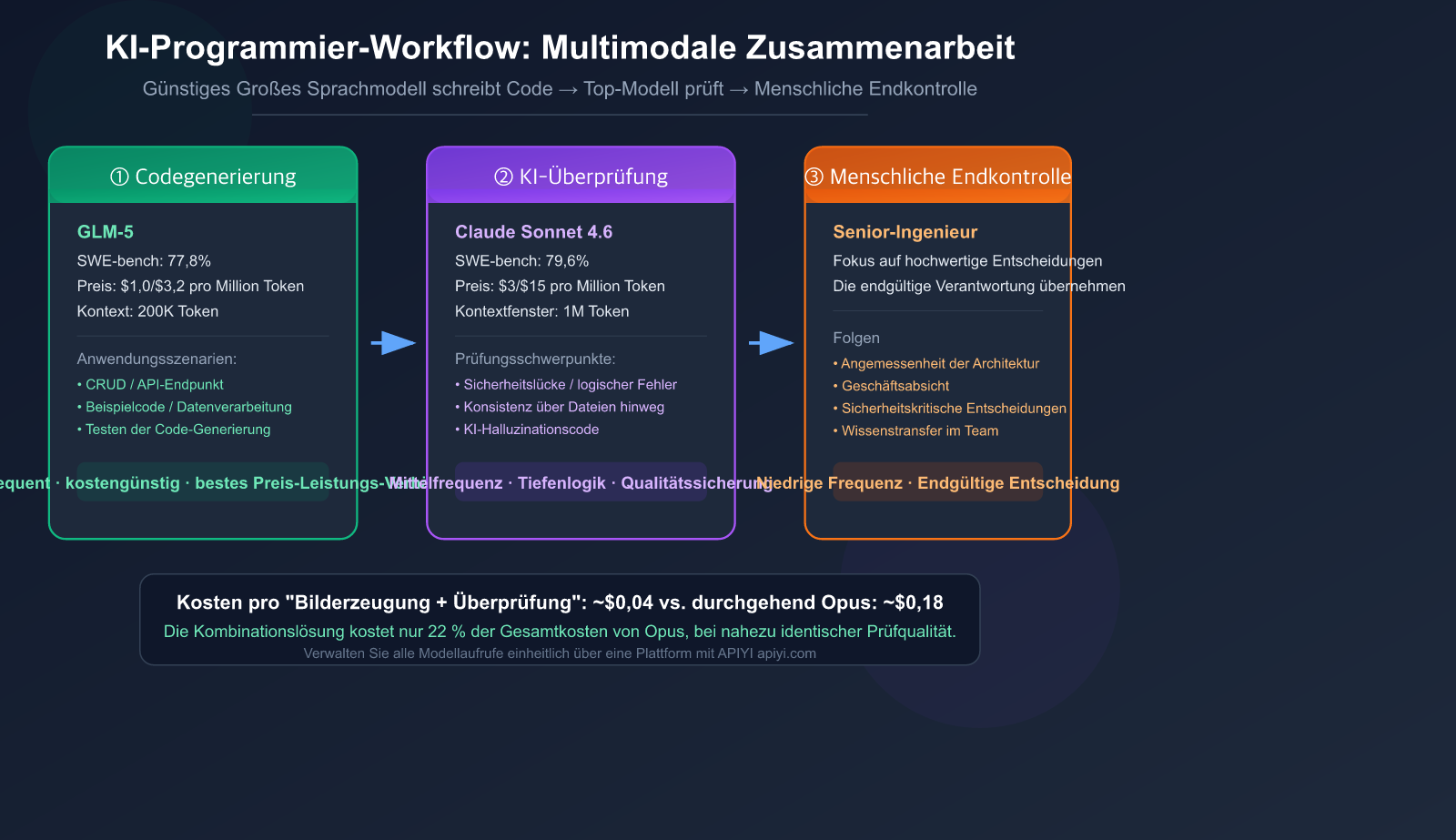
Grundlegende Transformation des KI-Programmier-Workflows
Der Wandel der Entwicklerrolle: Vom "Coder" zum "KI-Dirigenten"
In der Softwareentwicklung des Jahres 2026 besteht die Kernaufgabe eines Entwicklers nicht mehr darin, Zeile für Zeile Code zu schreiben, sondern:
- Spezifikations-Engineering — Definition von Anforderungen, Einschränkungen und Architekturpräferenzen.
- Auswahl des Modell-Mixes — Einsatz unterschiedlicher Modelle für verschiedene Phasen.
- Überprüfung und Qualitätssicherung — Sicherstellen, dass der KI-Output technischen Standards entspricht.
- Übernahme der Endverantwortung — Die KI ist nur ein Werkzeug, der Mensch bleibt verantwortlich.
Addy Osmani (Technical Lead beim Google Chrome-Team) fasst das Kernprinzip zusammen: "Plane zuerst, schreibe dann den Code. Pläne zu ändern ist günstig, Code zu ändern ist teuer."
Neuer Workflow vs. Traditioneller Workflow
| Dimension | Traditioneller Workflow | KI-gestützter Workflow |
|---|---|---|
| Kernaktivität | Zeilenweises Programmieren | Spezifikationsschreiben + KI-Review |
| Entwicklerrolle | Coder | Orchestrator |
| Code-Generierung | 100 % manuell | ~40 % KI-generiert + manuelle Anpassung |
| Review-Fokus | Logik und Stil | KI-Output-Qualität + Architekturkonsistenz |
| Toolchain | IDE + Git | KI-Agent + IDE + Git + Multimodell-Ansatz |
| Engpass | Codiergeschwindigkeit | Review-Geschwindigkeit und Urteilsvermögen |
Wichtige Daten: Der aktuelle Stand der KI-Programmierung
| Daten | Quelle |
|---|---|
| 92 % der Entwickler nutzen KI-Tools | Branchenumfrage 2026 |
| 41 % der Code-Commits sind KI-unterstützt | GitHub-Daten |
| Nur 30 % der KI-Vorschläge werden direkt übernommen | CodeRabbit-Bericht |
| Nur 29–46 % der Entwickler vertrauen KI-Output | Diverse Umfragen |
| Produktivitätssteigerung in Unternehmen um ca. 10 % | Konsens aus 6 Studien |
| KI-generierter Code hat 1,7-mal mehr Fehler | Analyse von 470 PRs |
🎯 Kern-Erkenntnis: Die Produktivitätssteigerung hängt nicht davon ab, wie viel Code die KI generiert, sondern ob Sie über ein effizientes System zur Überprüfung und Validierung verfügen. Über die Plattform APIYI (apiyi.com) können Sie flexibel verschiedene Modelle kombinieren, um genau dieses System aufzubauen.
Modell-Auswahlstrategie: Günstig für Code, Top-Modelle für Reviews
Dies ist die Kernmethodik dieses Artikels — Einsatz unterschiedlicher Modelle für verschiedene Phasen. Ein Rennstall lässt schließlich auch keinen Formel-1-Wagen ausliefern und keinen LKW am Rennen teilnehmen.
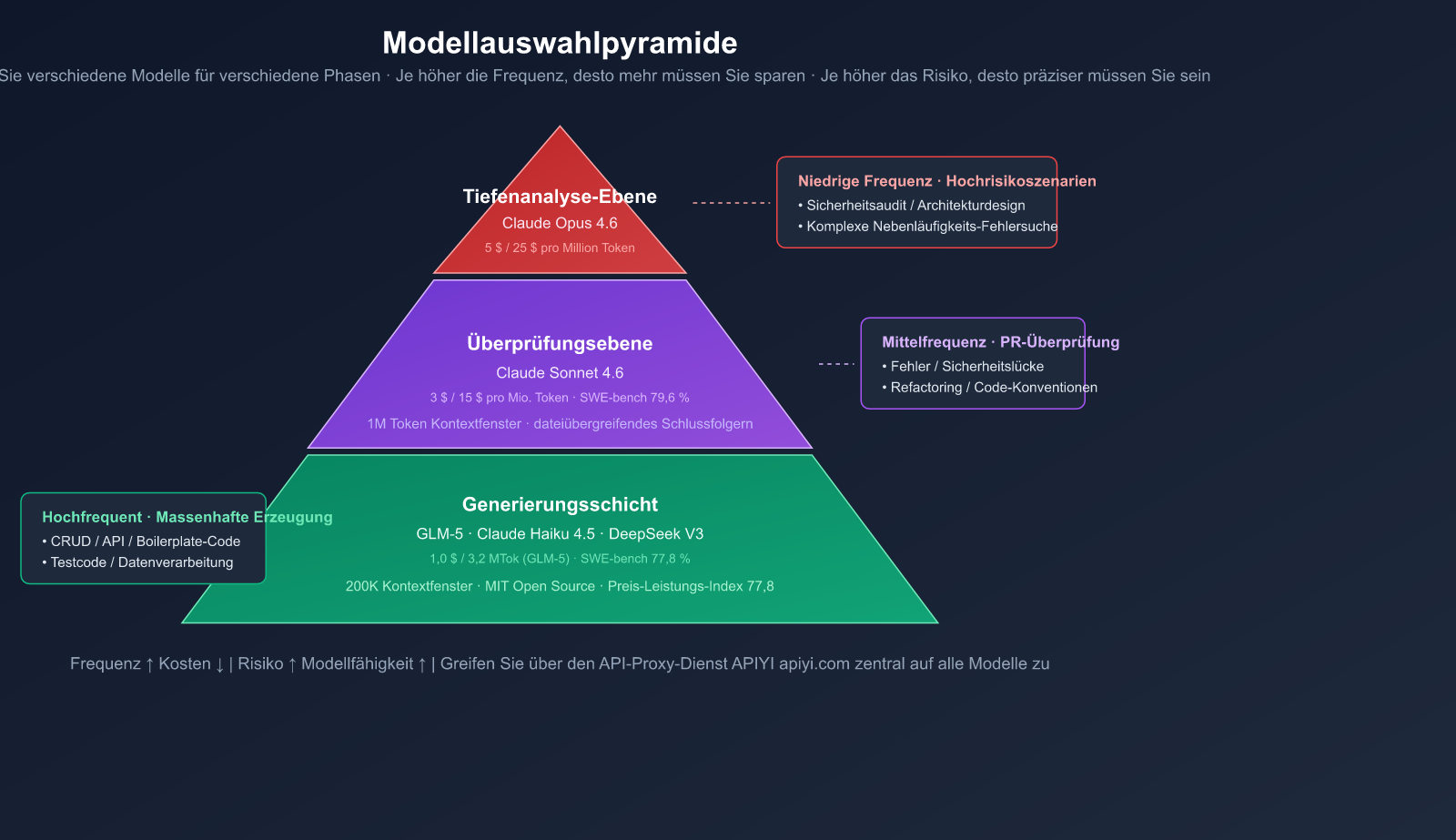
Das Drei-Schichten-Modell-Pyramide
| Ebene | Zweck | Empfohlene Modelle | Preis (Eingabe/Ausgabe) | Frequenz |
|---|---|---|---|---|
| Generierung | Code-Schreiben, CRUD, Boilerplate | GLM-5, Claude Haiku 4.5 | $1.0/$3.2 (GLM-5) | Hoch |
| Review | PR-Review, Bug-Suche, Refactoring | Claude Sonnet 4.6 | $3/$15 | Mittel |
| Deep Analysis | Architektur, Security, Debugging | Claude Opus 4.6 | $5/$25 | Niedrig |
Warum GLM-5 für die Code-Generierung?
GLM-5 ist ein Open-Source-Großes Sprachmodell, das im Februar 2026 von Zhipu AI veröffentlicht wurde und im Bereich der Code-Generierung ein exzellentes Preis-Leistungs-Verhältnis bietet.
GLM-5 Kernspezifikationen:
- Parameter: 744B (MoE-Architektur, 256 Experten, 8 aktiv pro Token, ca. 40B aktive Parameter)
- Kontext: 200K Token
- SWE-bench Verified: 77,8 % (Führend unter Open-Source-Modellen)
- Lizenz: MIT (voll kommerziell nutzbar)
- Eingabepreis: $1,00/Million Token — nur 1/3 von Claude Sonnet 4.6
GLM-5 vs. Closed-Source-Modelle (SWE-bench Vergleich):
| Modell | SWE-bench Verified | Eingabepreis (pro Mio. Token) | Preis-Leistungs-Index |
|---|---|---|---|
| Claude Opus 4.6 | 81,4 % | $5,00 | 16,3 |
| Claude Sonnet 4.6 | 79,6 % | $3,00 | 26,5 |
| GPT-5.2 | 80,0 % | — | — |
| GLM-5 | 77,8 % | $1,00 | 77,8 |
Der Preis-Leistungs-Index von GLM-5 (SWE-bench-Score / Eingabepreis) ist fast dreimal so hoch wie der von Claude Sonnet 4.6. Bei hochfrequenten Aufgaben wie der Code-Generierung summieren sich diese Kostenvorteile schnell.
Warum Claude Sonnet 4.6 für Code-Reviews?
Bei Code-Reviews kommt es nicht auf Geschwindigkeit an, sondern auf tiefes Verständnis und präzise Urteilskraft. Sonnet 4.6 ist hier den Modellen der Generierungsschicht weit überlegen:
- 1 Million Token Kontext: Lädt das gesamte Repository + PR-Diff + Abhängigkeiten in einem Durchgang.
- Cross-File-Reasoning: Erkennt, wenn Änderungen in Datei A zu logischen Brüchen in Datei B führen.
- SWE-bench 79,6 %: Nur 1,8 Prozentpunkte hinter Opus 4.6.
- Entwickler-Präferenz: In Tests mit Claude Code bevorzugten Entwickler Sonnet 4.6 zu 59 % gegenüber dem früheren Flaggschiff Opus 4.5.
- Kein Over-Engineering: Sonnet 4.6 gilt als weniger anfällig für "Over-Engineering" oder "Faulheit" als Vorgängermodelle.
Kostenvergleich: Ein Review mit Sonnet 4.6 kostet nur 1/5 im Vergleich zu Opus 4.6, bei nahezu identischer Qualität. Für die meisten PR-Review-Szenarien ist dies die optimale Wahl.
💡 Empfehlung: Über die Plattform APIYI (apiyi.com) können Sie sowohl GLM-5 als auch Claude Sonnet 4.6 über eine API anbinden und mit einem einzigen Schlüssel verwalten. Nutzen Sie GLM-5 zur Kostensenkung bei der Generierung und wechseln Sie für die Review-Phase zu Sonnet 4.6, um die Qualität zu sichern.
6-Schritte-Workflow für die Praxis: Von der Anforderung bis zum Merge
Hier ist ein bewährter, vollständiger Workflow. Das Kernkonzept lautet: Explore → Plan → Generate → Review → Test → Commit.
Schritt 1: Spezifikation (Specification)
Bevor Sie eine Zeile Code schreiben, erstellen Sie eine klare Anforderungsspezifikation:
## Anforderungen
Implementierung eines API-Endpunkts für die Benutzerregistrierung
Anforderungen
- Verwendung des FastAPI-Frameworks
- Passwort-Hashing mittels bcrypt
- Eindeutigkeit der E-Mail-Adresse erforderlich, Rückgabe bei Konflikt: 409
- Speicherung in PostgreSQL unter Verwendung von SQLAlchemy ORM
- Rückgabe eines JWT-Tokens
Nicht erforderlich
- E-Mail-Verifizierungsprozess (für spätere Iterationen geplant)
- Social Login
### Schritt 2: KI-Planung (Plan)
Erstellen Sie die Architekturplanung mit Claude Sonnet 4.6 (die Planungsphase ist es wert, ein leistungsfähiges Modell zu nutzen):
```python
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI einheitliche Schnittstelle
)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": "Du bist ein leitender Architekt. Erstelle basierend auf den Anforderungen einen Implementierungsplan, einschließlich Dateistruktur, wichtiger Funktionssignaturen und Datenflüsse. Schreibe keinen vollständigen Code."},
{"role": "user", "content": spec_content}
]
)
print(response.choices[0].message.content)
Schritt 3: KI-Code-Generierung (Generate)
Nach Bestätigung des Plans wird GLM-5 für die Implementierung des Codes verwendet:
# Wechsel zu einem kosteneffizienten Modell für die Codegenerierung
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": f"Implementiere den Code gemäß folgendem Architekturplan:\n{plan}"},
{"role": "user", "content": "Bitte implementiere den vollständigen Code für die Benutzerregistrierungs-API"}
],
max_tokens=8192
)
Wichtige Prinzipien:
- Generieren Sie immer nur eine Funktion/ein Modul auf einmal, nicht das gesamte Projekt auf einen Schlag.
- Führen Sie nach der Generierung sofort ein
git commitdurch, um einen "Wiederherstellungspunkt" zu setzen. - Lassen Sie repetitiven Code (CRUD, Formularvalidierung) ruhig von der KI erstellen.
- Sicherheitskritischen Code (Authentifizierung, Verschlüsselung, Berechtigungen) sollten Sie manuell schreiben oder doppelt prüfen.
Schritt 4: KI-Überprüfung (Review)
Nach der Codegenerierung wird für die Überprüfung zu Claude Sonnet 4.6 gewechselt:
# Wechsel zum Überprüfungsmodell
generated_code = open("app/routes/auth.py").read()
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Bitte überprüfe folgenden Code:\n\n{generated_code}"}
],
max_tokens=4096
)
Vollständige Review-Prompt-Vorlage anzeigen
REVIEW_PROMPT = """Du bist ein erfahrener Code-Review-Experte. Dieser Code wurde von einer KI generiert. Achte besonders auf:
1. **KI-typische Probleme**: Halluzinierte APIs, nicht existierende Bibliotheksfunktionen, Code, der korrekt aussieht, aber logische Fehler enthält.
2. **Sicherheit**: Injektionen, hartcodierte Schlüssel, unsichere Verschlüsselung, Umgehung von Berechtigungen.
3. **Randbedingungen**: Nullwerte, Nebenläufigkeit, große Datenmengen, Netzwerk-Timeouts.
4. **Architekturkonsistenz**: Entspricht der Code dem bestehenden Projektstil? Benennung, Schichtung, Fehlerbehandlung.
5. **Testbarkeit**: Ist der Code einfach per Unit-Test zu prüfen? Sind Abhängigkeiten injizierbar?
Klassifiziere die Ausgabe nach Schweregrad:
- 🔴 Muss behoben werden (Sicherheits-/Logikfehler)
- 🟡 Empfohlene Korrektur (Codequalität)
- 💡 Verbesserungsvorschlag (optionale Optimierung)
Wenn keine Probleme vorliegen, bestätige dies explizit mit "Überprüfung bestanden". Erfinde keine nicht existierenden Probleme."""
Schritt 5: Testvalidierung (Test)
Nach bestandener Überprüfung wird der Testcode generiert (weiterhin mit GLM-5, um Kosten zu sparen):
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Schreibe pytest-Unit-Tests für den folgenden Code, die sowohl den Normalfall als auch Randbedingungen abdecken."},
{"role": "user", "content": generated_code}
]
)
Schritt 6: Menschliche Endkontrolle + Zusammenführung
Nachdem die KI-Überprüfung und die Tests bestanden sind, erfolgt die finale Bestätigung durch einen Menschen:
- Ist die Architekturentscheidung sinnvoll?
- Entspricht sie der geschäftlichen Absicht?
- Gibt es kontextuelle Risiken, die die KI nicht wahrnehmen kann?
🚀 Effizienzdaten: Der Kernvorteil dieses Workflows liegt darin, die menschliche Aufmerksamkeit auf die wertvollsten Schritte zu konzentrieren. Die KI übernimmt 80 % der mechanischen Arbeit (Generierung, Stilprüfung, grundlegende Fehlererkennung), während der Mensch sich auf die 20 % der hochwertigen Entscheidungen (Architektur, Sicherheit, Geschäftslogik) konzentriert. Durch die Nutzung von APIYI apiyi.com können Sie die API-Aufrufe für GLM-5 und Claude 4.6 zentral verwalten und sparen sich die mühsame Registrierung und Verwaltung mehrerer Konten.
Claude Code: Die ultimative Lösung für KI-gestützte Programmierung
Wenn Sie keine Lust haben, komplexe Multi-Modell-Workflows selbst zu konfigurieren, bietet Claude Code eine "All-in-One"-Lösung. Es handelt sich um einen KI-Programmier-Agenten, der direkt im Terminal läuft, eigenständig Codebasen analysiert, Dateien bearbeitet, Befehle ausführt und Probleme löst.
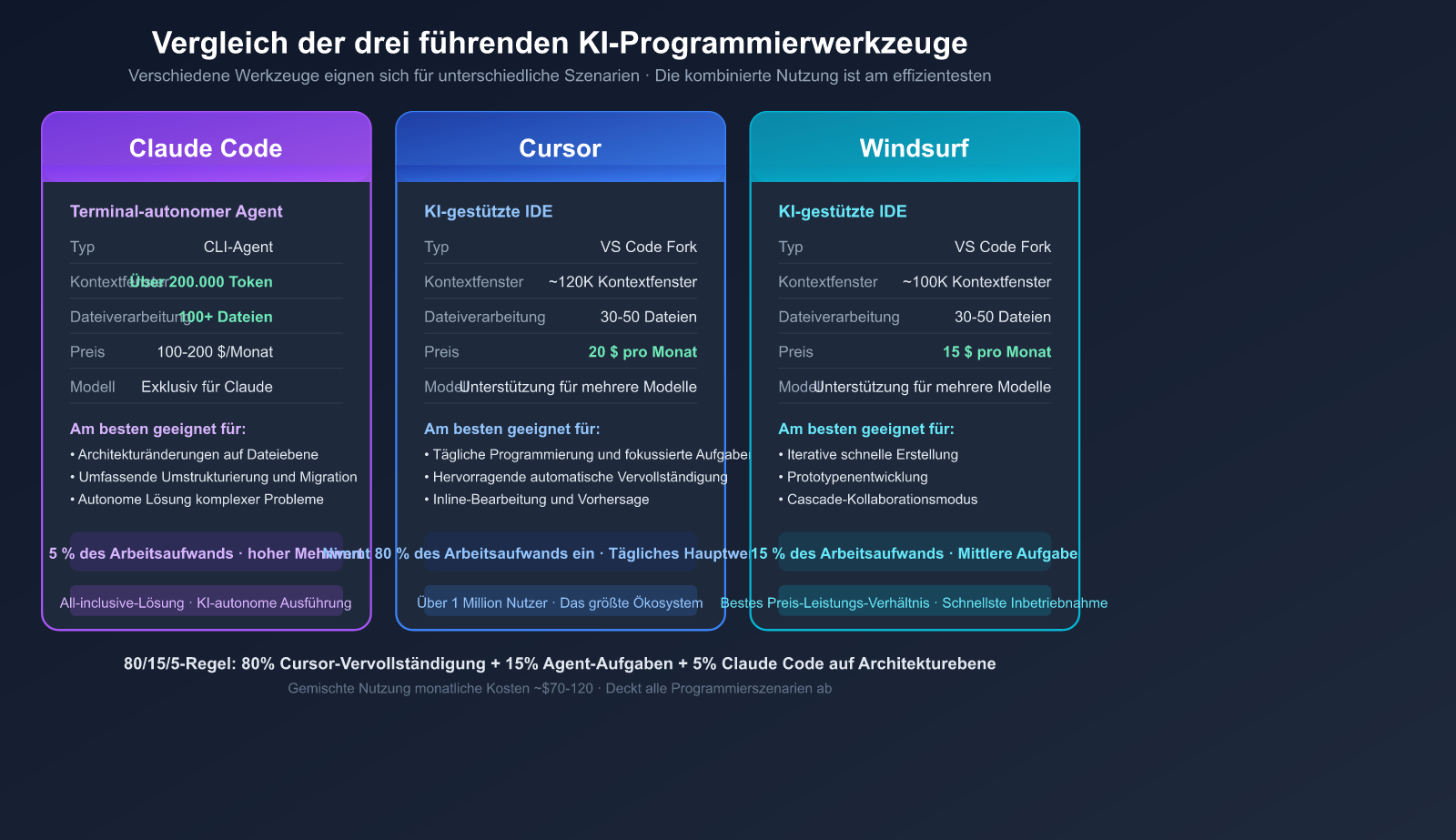
Die Kernvorteile von Claude Code
| Fähigkeit | Claude Code | Cursor | Windsurf |
|---|---|---|---|
| Typ | Terminal-Agent | VS Code-Erweiterung | VS Code-Erweiterung |
| Konzept | Autonome KI-Ausführung | KI-gestützte Bearbeitung | KI-kollaboratives Coding |
| Kontext | 200K+ Token | ~120K Token | ~100K Token |
| Dateiverarbeitung | 100+ Dateien | 30-50 Dateien | 30-50 Dateien |
| Stärken | Architektur-Änderungen | Tägliches Coding, Aufgaben | Iteratives Bauen, Prototypen |
| Preis | $100-200/Monat oder API | $20/Monat | $15/Monat |
Best Practices für Claude Code
1. Geben Sie der KI eine Möglichkeit, ihre Arbeit zu validieren
Dies ist die laut offizieller Dokumentation effektivste Methode:
# Gute Eingabeaufforderung
"Implementiere die Benutzerregistrierung, schreibe entsprechende pytest-Tests und committe erst, wenn die Tests erfolgreich durchlaufen."
# Schlechte Eingabeaufforderung
"Implementiere die Benutzerregistrierung"
2. Writer/Reviewer-Modus mit zwei Sitzungen
Starten Sie zwei Claude Code-Sitzungen:
- Sitzung A (Writer): Konzentriert sich auf die Implementierung.
- Sitzung B (Reviewer): Überprüft die Ausgabe des Writers mit einem frischen Kontext.
Dieser "KI überprüft KI"-Ansatz hilft dabei, blinde Flecken effektiv aufzudecken.
3. Nutzen Sie die Projektkonfiguration CLAUDE.md
# CLAUDE.md
Projekt-Tech-Stack
Python 3.12 + FastAPI + SQLAlchemy + PostgreSQL
Code-Richtlinien
- Typannotationen: Alle Funktionen müssen über Typannotationen verfügen.
- Fehlerbehandlung: Verwendung der benutzerdefinierten Klasse
AppError. - Protokollierung: Geschäftsvorfälle als INFO, Debugging-Informationen als DEBUG.
Verbote
- Verwenden Sie kein
print(), nutzen Sie stattdessenlogger. - Hardcodieren Sie keine Konfigurationen, verwenden Sie Umgebungsvariablen.
- Schreiben Sie kein SQL direkt in Routenfunktionen.
**4. Die 80/15/5-Regel für den Tool-Einsatz**
Die von erfahrenen Entwicklern empfohlene Verteilung der Werkzeuge:
- **80%**: Autovervollständigung und Inline-Bearbeitung (Cursor/Copilot) — für die tägliche Programmierung
- **15%**: Agenten-Aufgaben mittlerer Komplexität (Cursor Agent/Windsurf) — für die Implementierung von Funktionen
- **5%**: Komplexe Architekturänderungen über mehrere Dateien hinweg (Claude Code) — für größere Refactorings
> 💰 **Kostentipp**: Der API-Modus von Claude Code wird nach Token abgerechnet. Wenn Sie den Dienst über APIYI (apiyi.com) nutzen, profitieren Sie von günstigeren Preisen für Claude-Modelle als beim offiziellen Anbieter. Für Szenarien, in denen nicht der volle Funktionsumfang von Claude Code benötigt wird, können Sie Claude Sonnet 4.6 auch direkt über die API für Code-Reviews ansprechen.
---
## Praxisbeispiel: Ein vollständiger Prozess für Codegenerierung und Review
Im Folgenden zeigen wir ein reales Szenario: Wir generieren mit GLM-5 ein FastAPI-Modul für die Benutzerauthentifizierung und lassen es anschließend von Claude Sonnet 4.6 prüfen.
### Code für den vollständigen Workflow
```python
import openai
import logging
# Logger statt print verwenden
logger = logging.getLogger(__name__)
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche APIYI-Schnittstelle
)
# ===== Schritt 1: Code mit GLM-5 generieren =====
gen_response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Du bist ein Experte für Python-Backend-Entwicklung."},
{"role": "user", "content": """
Implementiere einen FastAPI-Endpunkt für die Benutzerregistrierung:
- POST /api/v1/register
- Empfange E-Mail und Passwort
- Verschlüssele das Passwort mit bcrypt
- Speichere es in PostgreSQL
- Gib ein JWT-Token zurück
"""}
],
max_tokens=4096
)
generated_code = gen_response.choices[0].message.content
# ===== Schritt 2: Review mit Claude Sonnet 4.6 =====
review_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Überprüfe den folgenden KI-generierten Code:\n\n{generated_code}"}
],
max_tokens=4096
)
review_result = review_response.choices[0].message.content
logger.info("=== Review-Ergebnis ===")
logger.info(review_result)
Kostenanalyse
| Schritt | Modell | Eingabe-Token | Ausgabe-Token | Kosten |
|---|---|---|---|---|
| Codegenerierung | GLM-5 | ~500 | ~2000 | ~$0,007 |
| Code-Review | Sonnet 4.6 | ~3000 | ~1500 | ~$0,032 |
| Gesamt | — | — | — | ~$0,04 |
Die Gesamtkosten für einen vollständigen "Generierungs- und Review-Zyklus" liegen bei unter $0,04. Selbst bei 50 Zyklen pro Tag belaufen sich die monatlichen Kosten auf nur etwa $60.
Würde man durchgehend Claude Opus 4.6 verwenden, lägen die Kosten für denselben Workflow bei etwa $0,18 pro Durchlauf – das ist das 4,5-fache der Kombinationslösung.
🎯 Wichtige Kennzahl: Die Kombination aus GLM-5 zur Generierung und Sonnet 4.6 für das Review kostet nur 22% dessen, was eine reine Nutzung von Opus 4.6 kosten würde, bei nahezu identischer Review-Qualität. Über die Plattform APIYI (apiyi.com) lassen sich alle Aufrufe bequem mit einem einzigen API-Schlüssel abwickeln.
Häufig gestellte Fragen
Q1: Ist die Codequalität von günstigen Modellen ausreichend?
GLM-5 erreicht auf SWE-bench Verified einen Wert von 77,8 %, was nur etwa 2 Prozentpunkte unter dem von Claude Sonnet 4.6 liegt, bei nur einem Drittel der Kosten. Für die meisten Code-Generierungsaufgaben (CRUD, API-Endpunkte, Datenverarbeitung) ist die Qualität absolut ausreichend. Entscheidend ist ein anschließender Überprüfungsprozess als Sicherheitsnetz. Über APIYI (apiyi.com) können Sie beide Modelle gleichzeitig einbinden und flexibel zwischen ihnen wechseln.
Q2: In welchen Szenarien sollte man keine günstigen Modelle für die Code-Generierung verwenden?
Sicherheitskritischer Code (Authentifizierung, Verschlüsselung, Zugriffskontrolle), Nebenläufigkeits- und verteilte Logik sowie Code, der Präzision bei Finanzberechnungen erfordert. In diesen Fällen empfehle ich, direkt Claude Sonnet 4.6 oder Opus 4.6 zu verwenden oder den Code manuell zu schreiben und durch KI prüfen zu lassen.
Q3: Ist Claude Code für jeden geeignet?
Claude Code eignet sich am besten für erfahrene Entwickler, die komplexe, dateiübergreifende Architekturaufgaben bearbeiten. Wenn Ihre Arbeit hauptsächlich aus Änderungen an einzelnen Dateien und täglicher Programmierung besteht, sind Cursor oder Windsurf möglicherweise besser geeignet (und zudem kostengünstiger). Viele erfahrene Entwickler nutzen eine Mischform: Cursor für den Alltag, Claude Code für komplexe Aufgaben.
Q4: Wie lässt sich die Effektivität dieses Workflows messen?
Verfolgen Sie vier Kennzahlen: (1) Veränderung des Code-Outputs pro Kopf; (2) Veränderung der Bug-Rate (Fehler nach dem Deployment); (3) Veränderung der Zeit für Code-Reviews; (4) Kosten für Modellaufrufe. Ich empfehle einen zweiwöchigen Testlauf, um die Daten vor und nach dem Pilotprojekt zu vergleichen. Mit der Nutzungsstatistik von APIYI (apiyi.com) lassen sich die API-Kosten bequem nachverfolgen.
Q5: Welche kosteneffizienten Modelle für die Code-Generierung gibt es außer GLM-5 noch?
Claude Haiku 4.5 (extrem schnell, ideal für einfache Aufgaben), DeepSeek V3 (Open Source, stark bei chinesischen Inhalten) und GPT-5.3 Codex (auf Code spezialisiert). Die Wahl hängt von Ihren Sprachpräferenzen und dem spezifischen Szenario ab. Über APIYI (apiyi.com) können Sie all diese Modelle zentral einbinden und vermeiden so den Verwaltungsaufwand mehrerer Plattformen.
Fazit: Der richtige Ansatz für KI-Programmierung
Der Kern der KI-Programmierung besteht nicht darin, "die KI den gesamten Code schreiben zu lassen", sondern einen effizienten Workflow für die Zusammenarbeit mehrerer Modelle zu etablieren. Die Best Practices für 2026 lauten:
Formel für die Modellauswahl:
- 🟢 Hohe Frequenz, geringes Risiko (Boilerplate-Code, CRUD) → Kosteneffiziente Modelle wie GLM-5
- 🟡 Mittlere Frequenz, mittleres Risiko (PR-Reviews, Refactoring) → Claude Sonnet 4.6
- 🔴 Geringe Frequenz, hohes Risiko (Sicherheitsaudits, Architekturdesign) → Claude Opus 4.6
Workflow-Formel:
- Erst Spezifikation, dann Planung, dann Generierung, dann Überprüfung, dann Testen und schließlich die menschliche Endabnahme.
- Die KI übernimmt 80 % der mechanischen Arbeit, der Mensch konzentriert sich auf die 20 % der wertschöpfenden Entscheidungen.
Es empfiehlt sich, über APIYI (apiyi.com) alle gängigen Modelle wie GLM-5, Claude Sonnet 4.6 und Opus 4.6 zentral einzubinden, um über eine einzige Plattform einen vollständigen, modellübergreifenden KI-Programmier-Workflow aufzubauen.
Referenzmaterialien
-
Addy Osmani: LLM-Programmier-Workflow 2026
- Link:
addyosmani.com/blog/ai-coding-workflow
- Link:
-
Claude Code Offizielle Best Practices: Leitfaden für agentenbasiertes Programmieren
- Link:
code.claude.com/docs/en/best-practices
- Link:
-
GLM-5 Technisches Paper: Von Vibe Coding zu KI-gestützter Softwareentwicklung
- Link:
arxiv.org
- Link:
-
Anthropic Offiziell: Ankündigung von Claude Sonnet 4.6
- Link:
anthropic.com/news/claude-sonnet-4-6
- Link:
-
MIT Technology Review: Generative Programmierung als bahnbrechende Technologie 2026
- Link:
technologyreview.com
- Link:
Autor: APIYI Team | Wir erforschen Best Practices für KI-gestützte Softwareentwicklung. Besuchen Sie APIYI unter apiyi.com für eine einheitliche API-Schnittstelle für die gesamte Modellreihe von GLM-5 und Claude 4.6.