
En 2026, 92 % des développeurs utilisent déjà des outils de programmation assistés par IA, et 41 % du code est généré avec leur aide. Pourtant, une réalité déconcertante persiste : si les gains de temps déclarés sont de 30 à 60 %, la productivité réelle des organisations n'augmente que d'environ 10 %. D'où vient ce fossé ? Du flux de travail.
Avec la bonne combinaison de modèles et un flux de travail optimisé, la programmation par IA devient un multiplicateur d'efficacité par 10 ; dans le cas contraire, ce n'est qu'un générateur de code "qui semble fonctionner mais qui peut exploser à tout moment".
Valeur ajoutée : En lisant cet article, vous maîtriserez un flux de travail de programmation par IA multi-modèles éprouvé : utiliser des modèles au rapport coût-efficacité élevé (comme GLM-5) pour la génération de code, des modèles de pointe (comme Claude Sonnet 4.6) pour la revue de code, et découvrir comment automatiser l'ensemble du processus avec Claude Code.
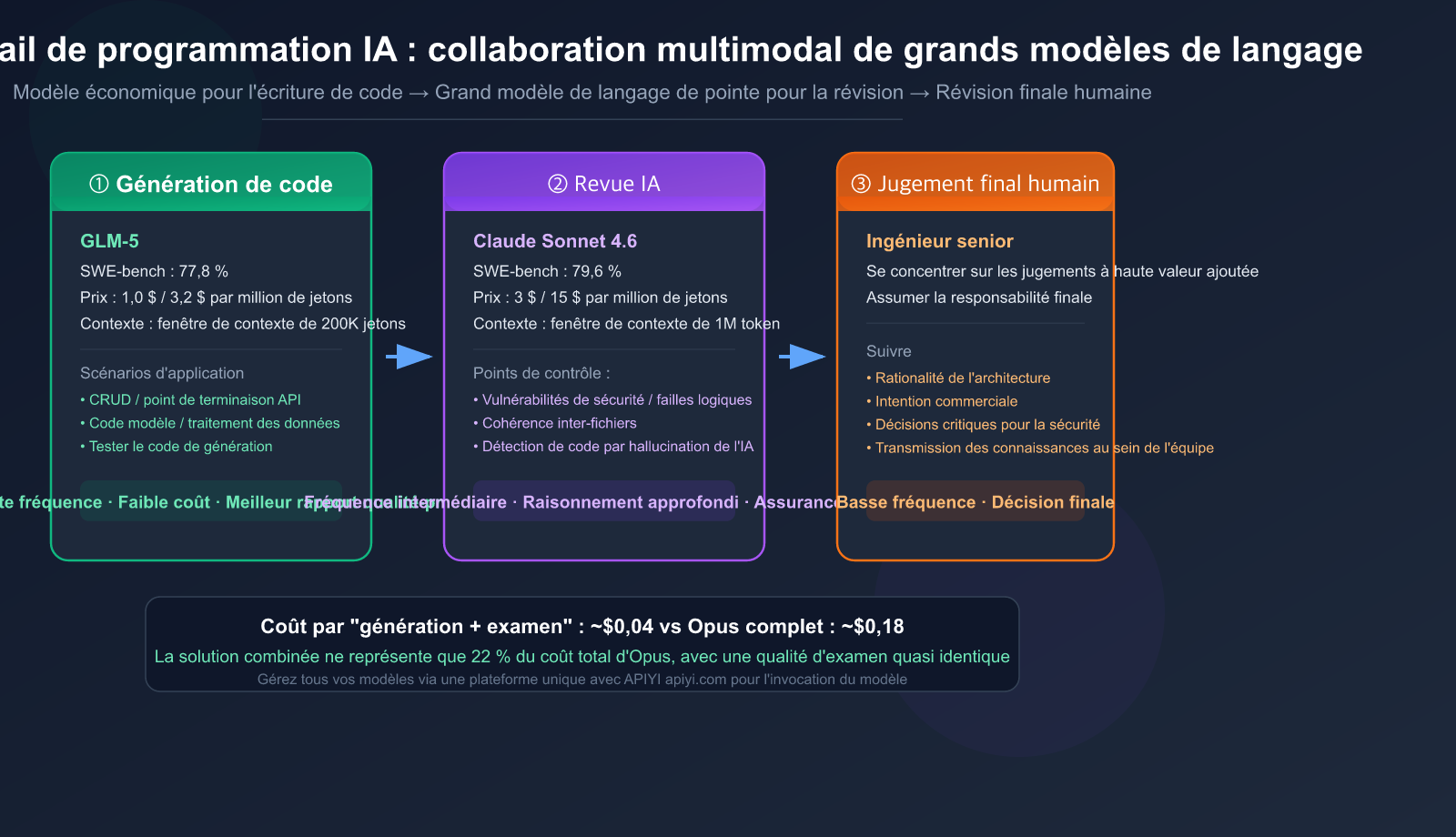
Révolution fondamentale du flux de travail de programmation IA
Le changement de rôle du développeur : de "celui qui écrit le code" à "celui qui dirige l'IA"
En 2026, le travail principal du développeur n'est plus d'écrire du code ligne par ligne, mais de :
- Rédiger des spécifications (Specification Engineering) — définir les besoins, les contraintes et les préférences architecturales.
- Sélectionner des combinaisons de modèles — utiliser différents modèles selon les étapes.
- Réviser et valider — s'assurer que les résultats de l'IA respectent les normes d'ingénierie.
- Assumer la responsabilité finale — l'IA n'est qu'un outil, l'humain est le responsable.
Addy Osmani (responsable technique de l'équipe Google Chrome) résume le principe fondamental : "Planifiez d'abord, codez ensuite. Modifier un plan coûte peu cher, modifier du code coûte cher."
Nouveau flux de travail vs flux de travail traditionnel
| Dimension | Flux traditionnel | Flux piloté par l'IA |
|---|---|---|
| Activité principale | Écriture ligne par ligne | Rédaction de spécifications + révision |
| Rôle du développeur | Codeur | Orchestrateur |
| Génération de code | 100 % humain | ~40 % IA + modifications humaines |
| Focus de révision | Logique et style | Qualité de l'IA + cohérence architecturale |
| Chaîne d'outils | IDE + Git | Agent IA + IDE + Git + modèles multiples |
| Goulot d'étranglement | Vitesse de codage | Vitesse de révision et jugement |
Données clés : la réalité de la programmation par IA
| Donnée | Source |
|---|---|
| 92 % des développeurs utilisent des outils IA | Enquête secteur 2026 |
| 41 % des commits sont assistés par l'IA | Données GitHub |
| Seulement 30 % des suggestions IA sont acceptées | Rapport CodeRabbit |
| Seulement 29-46 % des développeurs font confiance à l'IA | Synthèse d'enquêtes |
| Productivité réelle en hausse d'environ 10 % | Consensus de 6 études |
| Taux de défauts 1,7x plus élevé que l'humain | Analyse de 470 PR |
🎯 Insight clé : L'augmentation de la productivité ne dépend pas de la quantité de code générée par l'IA, mais de votre système de révision et de vérification. Grâce à la plateforme APIYI apiyi.com, vous pouvez combiner différents modèles pour construire ce système.
Stratégie de sélection de modèles : le bon marché pour coder, le haut de gamme pour réviser
C'est la méthodologie centrale de cet article : utiliser des modèles différents selon les étapes. Tout comme une écurie de course ne ferait pas courir une F1 pour faire de la livraison, ni un camion pour une compétition.
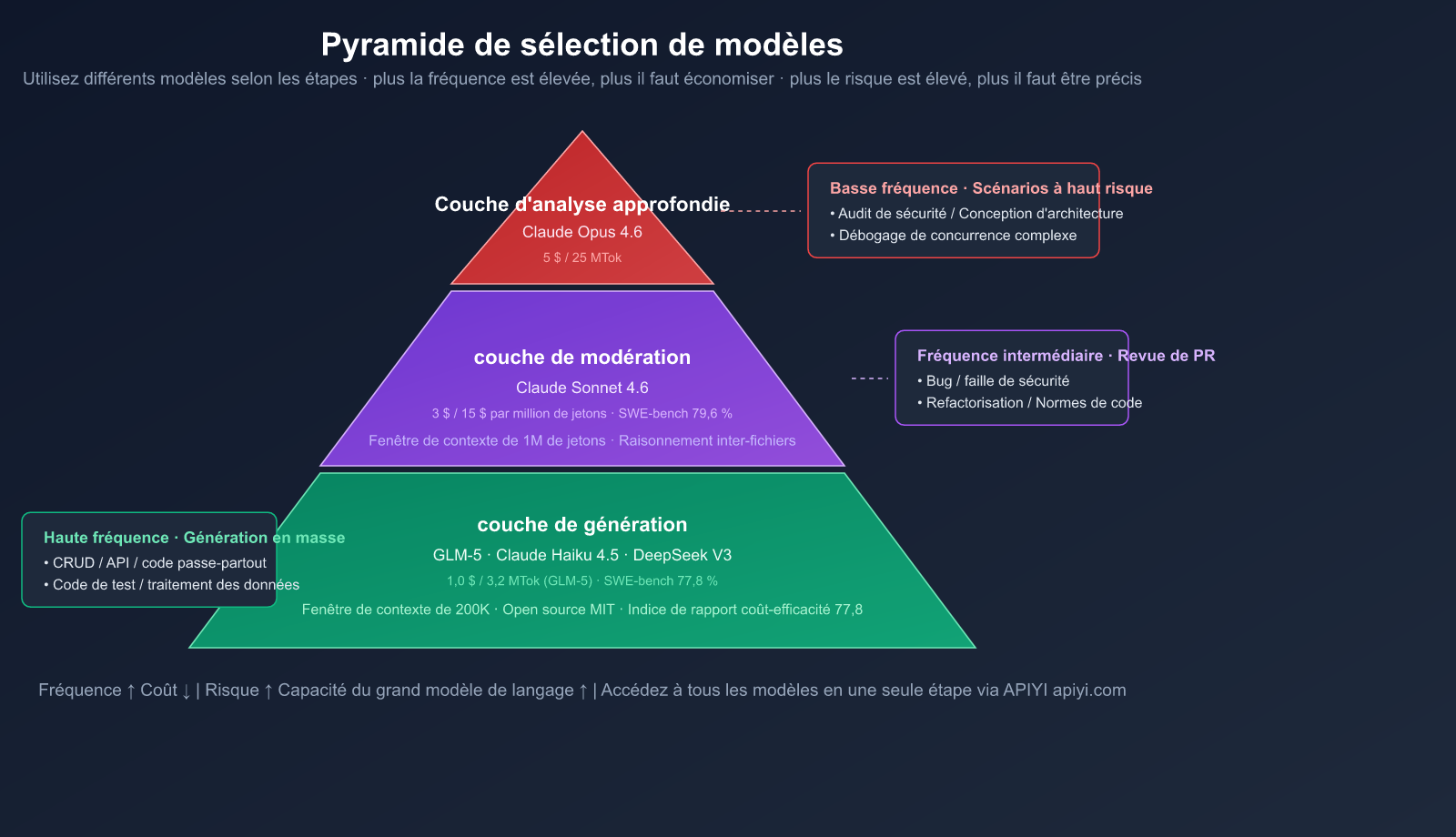
Pyramide des modèles à trois niveaux
| Niveau | Usage | Modèle recommandé | Prix Entrée/Sortie | Fréquence |
|---|---|---|---|---|
| Génération | Écriture de code, CRUD, boilerplate | GLM-5, Claude Haiku 4.5 | 1,0 $/3,2 $ (GLM-5) | Élevée |
| Révision | Revue de PR, détection de bugs, refactorisation | Claude Sonnet 4.6 | 3 $/15 $ | Moyenne |
| Approfondi | Architecture, audit sécurité, débogage complexe | Claude Opus 4.6 | 5 $/25 $ | Faible |
Pourquoi choisir GLM-5 pour la génération de code
GLM-5 est un grand modèle de langage open source publié par Zhipu AI en février 2026, offrant un excellent rapport qualité-prix pour la génération de code.
Spécifications clés de GLM-5 :
- Paramètres : 744B (architecture MoE, 256 experts, 8 activés par jeton, env. 40B paramètres actifs)
- Fenêtre de contexte : 200K jetons
- SWE-bench Verified : 77,8 % (n°1 des modèles open source)
- Licence : MIT (commerciale)
- Prix d'entrée : 1,00 $/million de jetons — soit 1/3 de Claude Sonnet 4.6
Comparaison SWE-bench GLM-5 vs modèles propriétaires :
| Modèle | SWE-bench Verified | Prix Entrée (par million) | Indice de rentabilité |
|---|---|---|---|
| Claude Opus 4.6 | 81,4 % | 5,00 $ | 16,3 |
| Claude Sonnet 4.6 | 79,6 % | 3,00 $ | 26,5 |
| GPT-5.2 | 80,0 % | — | — |
| GLM-5 | 77,8 % | 1,00 $ | 77,8 |
L'indice de rentabilité de GLM-5 (score SWE-bench / prix d'entrée) est près de 3 fois supérieur à celui de Claude Sonnet 4.6. Pour des opérations fréquentes comme la génération de code, les économies s'accumulent rapidement.
Pourquoi choisir Claude Sonnet 4.6 pour la révision de code
La révision de code ne nécessite pas de la vitesse, mais une compréhension profonde et un jugement précis. Sonnet 4.6 surpasse ici les modèles de génération :
- Contexte de 1 million de jetons : permet de charger l'intégralité du code source + le diff de la PR + les dépendances.
- Raisonnement inter-fichiers : capacité à détecter si une modification dans le fichier A casse la logique du fichier B.
- SWE-bench 79,6 % : seulement 1,8 point de moins que Opus 4.6.
- Préférence des développeurs : dans les tests Claude Code, Sonnet 4.6 est préféré à l'ancien flagship Opus 4.5 par 59 % des développeurs.
- Pas d'over-engineering : comparé aux versions précédentes, Sonnet 4.6 est jugé moins enclin à la "sur-ingénierie" ou à la "paresse".
Comparaison des coûts : Réviser avec Sonnet 4.6 coûte 5 fois moins cher qu'avec Opus 4.6, pour une qualité quasi équivalente. C'est le choix optimal pour la plupart des revues de PR.
💡 Conseil de sélection : Via la plateforme APIYI apiyi.com, vous pouvez accéder simultanément aux API de GLM-5 et de Claude Sonnet 4.6 avec une seule clé. Utilisez GLM-5 pour la génération afin de réduire les coûts, et basculez sur Sonnet 4.6 pour garantir la qualité lors de la révision.
6 étapes pour un workflow efficace : du besoin à la fusion
Voici un workflow complet et éprouvé. Le concept clé : Explorer → Planifier → Générer → Réviser → Tester → Valider.
Étape 1 : Spécification (Specification)
Avant d'écrire la moindre ligne de code, rédigez une spécification claire des besoins :
## Besoins
Implémenter le point de terminaison de l'API pour l'inscription des utilisateurs
Contraintes
- Utilisation du framework FastAPI
- Chiffrement des mots de passe avec bcrypt
- L'adresse e-mail doit être unique, renvoyer une erreur 409 en cas de conflit
- Stockage dans PostgreSQL via SQLAlchemy ORM
- Renvoi d'un jeton JWT
Non requis
- Processus de vérification d'e-mail (itérations ultérieures)
- Connexion via réseaux sociaux
### Étape 2 : Planification par l'IA (Plan)
Utilisez Claude Sonnet 4.6 pour la planification de l'architecture (la phase de planification mérite l'utilisation d'un modèle performant) :
```python
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": "Tu es un architecte logiciel senior. Élabore un plan de mise en œuvre basé sur les besoins, incluant la structure des fichiers, les signatures des fonctions clés et le flux de données. Ne rédige pas le code complet."},
{"role": "user", "content": spec_content}
]
)
print(response.choices[0].message.content)
Étape 3 : Génération de code par l'IA (Generate)
Une fois le plan validé, utilisez GLM-5 pour générer le code d'implémentation :
# Passage à un modèle au rapport coût-efficacité élevé pour la génération de code
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": f"Implémente le code selon le plan d'architecture suivant :\n{plan}"},
{"role": "user", "content": "Veuillez implémenter le code complet de l'API d'inscription utilisateur"}
],
max_tokens=8192
)
Principes clés :
- Générez une seule fonction/module à la fois, ne générez pas tout le projet d'un coup.
- Effectuez un
git commitimmédiatement après la génération pour créer un "point de sauvegarde" en cas de retour arrière. - N'hésitez pas à laisser l'IA générer le code répétitif (CRUD, validation de formulaires).
- Écrivez manuellement ou vérifiez doublement le code sensible à la sécurité (authentification, chiffrement, permissions).
Étape 4 : Revue par l'IA (Review)
Une fois le code généré, passez à Claude Sonnet 4.6 pour la revue :
# Passage au modèle de revue
generated_code = open("app/routes/auth.py").read()
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Veuillez examiner le code suivant :\n\n{generated_code}"}
],
max_tokens=4096
)
Voir le modèle complet de Prompt pour la revue
REVIEW_PROMPT = """Tu es un expert en revue de code. Ce code a été généré par une IA, sois particulièrement attentif aux points suivants :
1. **Problèmes courants de l'IA** : API hallucinées, fonctions de bibliothèque inexistantes, code qui semble correct mais dont la logique est erronée.
2. **Sécurité** : Injections, clés codées en dur, chiffrement non sécurisé, contournement des permissions.
3. **Cas limites** : Valeurs nulles, concurrence, gros volumes de données, délais d'attente réseau.
4. **Cohérence architecturale** : Le code respecte-t-il le style existant du projet ? Nommage, couches, gestion des erreurs.
5. **Testabilité** : Est-il facile d'écrire des tests unitaires ? Les dépendances sont-elles injectables ?
Classe les retours par niveau de gravité :
- 🔴 Correction obligatoire (sécurité/erreur logique)
- 🟡 Correction suggérée (qualité du code)
- 💡 Suggestion d'amélioration (optimisation optionnelle)
S'il n'y a aucun problème, indique clairement "Revue validée". N'invente pas de problèmes inexistants."""
Étape 5 : Validation par les tests (Test)
Une fois la revue validée, générez le code de test (toujours avec GLM-5 pour réduire les coûts) :
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Rédige des tests unitaires pytest pour le code suivant, en couvrant les chemins nominaux et les cas limites."},
{"role": "user", "content": generated_code}
]
)
Étape 6 : Validation humaine finale + Fusion
Après la revue par l'IA et la réussite des tests, l'humain procède à la validation finale :
- Les décisions architecturales sont-elles pertinentes ?
- Le code correspond-il à l'intention métier ?
- Existe-t-il des risques contextuels que l'IA ne peut pas percevoir ?
🚀 Données d'efficacité : L'avantage majeur de ce flux de travail est de concentrer l'attention humaine sur les étapes à plus forte valeur ajoutée. L'IA gère 80 % du travail mécanique (génération, vérification de style, détection de bugs de base), tandis que l'humain se concentre sur les 20 % de jugements critiques (architecture, sécurité, logique métier). Grâce à la plateforme APIYI (apiyi.com), vous gérez les appels API de GLM-5 et Claude 4.6 au même endroit, évitant ainsi la complexité de gérer plusieurs comptes séparément.
Claude Code : la solution ultime pour la programmation IA de bout en bout
Si vous ne souhaitez pas configurer vous-même un flux de travail multi-modèles, Claude Code propose une solution "tout-en-un". Il s'agit d'un agent de programmation IA fonctionnant directement dans votre terminal, capable de lire votre base de code, de modifier des fichiers, d'exécuter des commandes et de résoudre des problèmes de manière autonome.
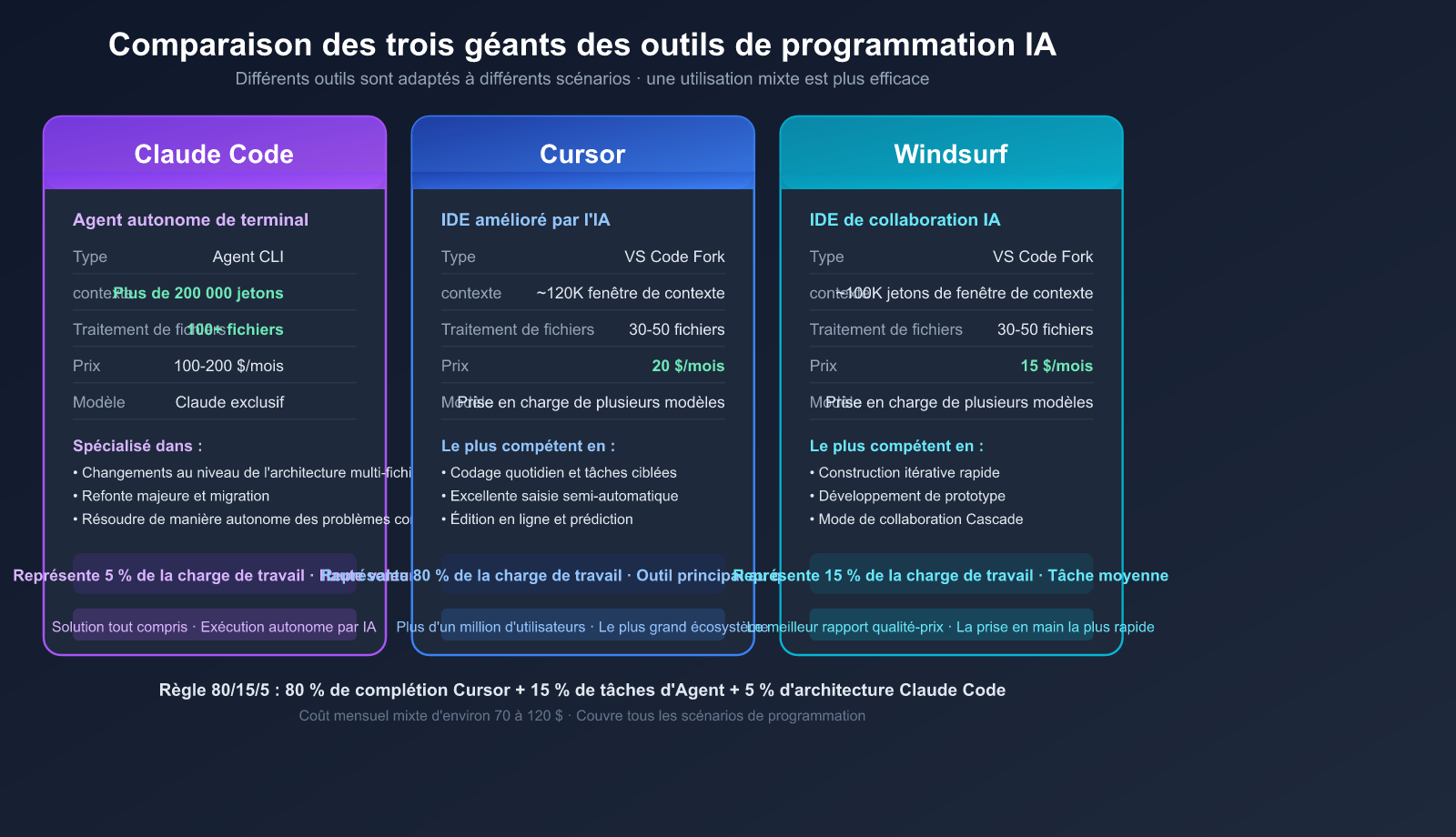
Avantages clés de Claude Code
| Capacité | Claude Code | Cursor | Windsurf |
|---|---|---|---|
| Type | Agent autonome en terminal | VS Code amélioré | VS Code amélioré |
| Philosophie | Exécution autonome par l'IA | Édition assistée par l'IA | Codage collaboratif IA |
| Contexte | 200K+ tokens | ~120K tokens | ~100K tokens |
| Traitement de fichiers | 100+ fichiers | 30-50 fichiers | 30-50 fichiers |
| Points forts | Changements d'architecture multi-fichiers | Codage quotidien, tâches ciblées | Itération, prototypage |
| Prix | 100-200 $/mois ou via API | 20 $/mois | 15 $/mois |
Meilleures pratiques pour Claude Code
1. Donner à l'IA un moyen de vérifier son propre travail
C'est la pratique la plus efficace soulignée par la documentation officielle :
# Bonne instruction
"Implémente la fonctionnalité d'inscription utilisateur, rédige les tests pytest correspondants et assure-toi que les tests passent avant de soumettre."
# Mauvaise instruction
"Implémente la fonctionnalité d'inscription utilisateur."
2. Mode double session : Rédacteur/Réviseur
Ouvrez deux sessions Claude Code :
- Session A (Rédacteur) : se concentre sur l'implémentation de la fonctionnalité.
- Session B (Réviseur) : utilise un contexte vierge pour examiner le résultat du Rédacteur.
Ce mode "IA examinant une IA" permet de détecter efficacement les angles morts d'une seule instance d'IA.
3. Utiliser judicieusement la configuration de projet CLAUDE.md
# CLAUDE.md
Pile technologique du projet
Python 3.12 + FastAPI + SQLAlchemy + PostgreSQL
Normes de codage
- Annotations de type : toutes les fonctions doivent comporter des annotations de type.
- Gestion des erreurs : utilisez la classe personnalisée
AppError. - Journalisation : INFO pour les événements métier, DEBUG pour le débogage.
Interdictions
- N'utilisez pas
print(), utilisezlogger. - Ne codez pas les configurations en dur, utilisez des variables d'environnement.
- N'écrivez pas de SQL directement dans les fonctions de routage.
**4. La règle des 80/15/5 pour la combinaison d'outils**
La répartition des outils recommandée par les développeurs expérimentés :
- **80 %** : Auto-complétion et édition en ligne (Cursor/Copilot) — pour le codage quotidien.
- **15 %** : Tâches d'agent de complexité moyenne (Cursor Agent/Windsurf) — pour l'implémentation de fonctionnalités.
- **5 %** : Changements d'architecture complexes sur plusieurs fichiers (Claude Code) — pour les refactorisations majeures.
> 💰 **Conseil coût** : Le mode API de Claude Code est facturé au jeton (token). En passant par APIYI (apiyi.com), vous pouvez bénéficier de tarifs plus avantageux sur les modèles Claude que via les canaux officiels. Pour les scénarios ne nécessitant pas toutes les fonctionnalités de Claude Code, vous pouvez également appeler directement Claude Sonnet 4.6 via l'API pour effectuer vos revues.
---
## Étude de cas : un processus complet de génération et de revue de code
Voici une démonstration d'un scénario réel : générer un module d'authentification utilisateur FastAPI avec GLM-5, puis le faire réviser par Claude Sonnet 4.6.
### Code du flux de travail complet
```python
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Interface unifiée APIYI
)
# ===== Étape 1 : Générer le code avec GLM-5 =====
gen_response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Tu es un expert en backend Python."},
{"role": "user", "content": """
Implémente un point de terminaison d'inscription utilisateur FastAPI :
- POST /api/v1/register
- Reçoit email et password
- Chiffre le mot de passe avec bcrypt
- Stocke dans PostgreSQL
- Retourne un jeton JWT
"""}
],
max_tokens=4096
)
generated_code = gen_response.choices[0].message.content
# ===== Étape 2 : Revue avec Claude Sonnet 4.6 =====
review_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Révise le code généré par l'IA suivant :\n\n{generated_code}"}
],
max_tokens=4096
)
review_result = review_response.choices[0].message.content
# Utilisation du logger au lieu de print
logger.info(f"=== Résultat de la revue ===\n{review_result}")
Analyse des coûts
| Étape | Modèle | Jetons d'entrée | Jetons de sortie | Coût |
|---|---|---|---|---|
| Génération de code | GLM-5 | ~500 | ~2000 | ~$0,007 |
| Revue de code | Sonnet 4.6 | ~3000 | ~1500 | ~$0,032 |
| Total | — | — | — | ~$0,04 |
Le coût complet d'un cycle "génération + revue" est inférieur à 0,04 $. Même en effectuant 50 cycles de ce type par jour, le coût mensuel ne serait que d'environ 60 $.
Si vous utilisiez uniquement Claude Opus 4.6, le coût du même flux de travail serait d'environ 0,18 $ par cycle, soit 4,5 fois plus cher que la solution combinée.
🎯 Chiffre clé : La solution combinée GLM-5 (génération) + Sonnet 4.6 (revue) ne coûte que 22 % du prix d'une utilisation exclusive de Opus 4.6, pour une qualité de revue quasi identique. Vous pouvez effectuer tous ces appels avec une seule clé API via la plateforme APIYI (apiyi.com).
FAQ
Q1 : La qualité du code généré par des modèles bon marché est-elle suffisante ?
Le GLM-5 obtient un score de 77,8 % sur SWE-bench Verified, soit seulement 2 points de pourcentage de moins que le Claude Sonnet 4.6, pour un prix trois fois inférieur. Pour la plupart des tâches de génération de code (CRUD, points de terminaison API, traitement de données), la qualité est largement suffisante. L'essentiel est de prévoir une étape de revue pour sécuriser le tout. Grâce à APIYI apiyi.com, vous pouvez accéder aux deux modèles simultanément et basculer entre eux en toute flexibilité.
Q2 : Dans quels scénarios faut-il éviter d’utiliser des modèles bon marché pour générer du code ?
Pour le code critique en matière de sécurité (authentification, chiffrement, contrôle des accès), la logique de concurrence et distribuée, ainsi que le code nécessitant une précision élevée pour les calculs financiers. Dans ces cas-là, nous recommandons d'utiliser directement Claude Sonnet 4.6 ou Opus 4.6, ou de procéder à une rédaction manuelle suivie d'une revue par l'IA.
Q3 : Claude Code est-il adapté à tout le monde ?
Claude Code est idéal pour les développeurs expérimentés qui traitent des tâches complexes d'architecture impliquant plusieurs fichiers. Si votre travail se concentre principalement sur la modification de fichiers uniques et le codage quotidien, Cursor ou Windsurf pourraient être plus adaptés (et moins coûteux). De nombreux développeurs seniors utilisent une approche hybride : Cursor pour le quotidien, et Claude Code pour les tâches complexes.
Q4 : Comment mesurer l’efficacité de ce flux de travail ?
Suivez ces 4 indicateurs : (1) évolution de la production de code par personne ; (2) taux de bugs (nombre de défauts après mise en production) ; (3) temps consacré à la revue ; (4) coût de l'invocation du modèle. Nous recommandons de mener un projet pilote de 2 semaines et de comparer les données avant et après. La fonction de statistiques d'utilisation d'APIYI apiyi.com permet de suivre facilement vos coûts d'API.
Q5 : Outre le GLM-5, quels sont les autres modèles de génération de code au bon rapport qualité-prix ?
Claude Haiku 4.5 (très rapide, idéal pour les tâches simples), DeepSeek V3 (open source, performant en chinois), et GPT-5.3 Codex (spécialisé dans le code). Le choix dépend de vos préférences linguistiques et de vos besoins spécifiques. APIYI apiyi.com vous permet d'accéder à tous ces modèles de manière centralisée, vous évitant ainsi la gestion fastidieuse de multiples plateformes.
Conclusion : La bonne approche pour la programmation assistée par IA
Le cœur de la programmation assistée par IA ne consiste pas à "laisser l'IA écrire tout le code", mais à établir un flux de travail efficace basé sur la collaboration entre plusieurs modèles. Voici les meilleures pratiques pour 2026 :
Formule de sélection des modèles :
- 🟢 Haute fréquence, faible risque (code standard, CRUD) → Modèles au bon rapport qualité-prix comme le GLM-5
- 🟡 Fréquence moyenne, risque moyen (revue de PR, refactorisation) → Claude Sonnet 4.6
- 🔴 Basse fréquence, risque élevé (audit de sécurité, conception d'architecture) → Claude Opus 4.6
Formule de flux de travail :
- D'abord les spécifications, puis le plan, la génération, la revue, les tests, et enfin la validation humaine.
- L'IA gère 80 % du travail mécanique, l'humain se concentre sur les 20 % de décisions à haute valeur ajoutée.
Nous vous recommandons d'utiliser APIYI apiyi.com pour accéder en un seul endroit à tous les modèles principaux, tels que GLM-5, Claude Sonnet 4.6 et Opus 4.6, afin de construire un flux de travail complet de programmation IA multi-modèles.
Références
-
Addy Osmani: Flux de travail de programmation LLM 2026
- Lien:
addyosmani.com/blog/ai-coding-workflow
- Lien:
-
Bonnes pratiques officielles de Claude Code: Guide de programmation par agent
- Lien:
code.claude.com/docs/en/best-practices
- Lien:
-
Document technique GLM-5: Du Vibe Coding à la programmation IA industrialisée
- Lien:
arxiv.org
- Lien:
-
Anthropic officiel: Annonce de la sortie de Claude Sonnet 4.6
- Lien:
anthropic.com/news/claude-sonnet-4-6
- Lien:
-
MIT Technology Review: Percée technologique 2026 en programmation générative
- Lien:
technologyreview.com
- Lien:
Auteur: Équipe APIYI | Explorez les meilleures pratiques de développement logiciel assisté par IA. Visitez APIYI sur apiyi.com pour accéder à une interface API unifiée pour toute la gamme de modèles GLM-5 et Claude 4.6.