
2026년 4월 7일 새벽, Artificial Analysis의 Video Arena 순위표에 누구도 들어본 적 없는 이름인 HappyHorse-1.0이 갑자기 등장했습니다. 이 모델은 4개의 핵심 순위표 중 3개에서 1위, 1개에서 2위를 차지하며 기존의 "지배자"였던 바이트댄스의 Seedance 2.0을 무려 60점의 Elo 차이로 따돌렸습니다. 하지만 72시간도 채 지나지 않아 이 모델은 순위표에서 사라졌고, 현재까지도 어떤 팀이 개발했는지 밝혀지지 않았습니다. 이번 글에서는 이 사건이 AI 영상 생성 분야에 어떤 의미를 갖는지 빠르게 짚어보겠습니다.
핵심 가치: 3분 만에 HappyHorse-1.0의 핵심 정보, 성능 돌파구, 출처에 대한 추측, 그리고 이것이 현재 AI 영상 생성 시장에 시사하는 바를 확인하세요.

HappyHorse-1.0 핵심 정보 요약
HappyHorse-1.0은 Artificial Analysis Video Arena에 "익명 제출(pseudonymous)" 방식으로 등장한 영상 생성 모델입니다. 공개된 GitHub 저장소나 공식 HuggingFace 가중치, 접근 가능한 API도 없지만, 4개의 핵심 순위표에서 바이트댄스의 Seedance 2.0, 구글 Veo, OpenAI Sora 등 기존의 모든 공개 모델을 압도하는 성능을 보여주었습니다.
| 항목 | 상세 내용 |
|---|---|
| 모델명 | HappyHorse-1.0 (V2 변형 포함) |
| 등장 시기 | 2026년 4월 7일 새벽 |
| 등재 플랫폼 | Artificial Analysis Video Arena |
| 제출 방식 | 익명 (pseudonymous) |
| 모델 규모 | 약 15B 파라미터 |
| 아키텍처 | 40 레이어 단일 스트림 Self-Attention Transformer |
| 멀티모달 | 텍스트 / 영상 / 오디오 통합 사전 학습 |
| 공개 상태 | ❌ 소스 코드 없음 · 가중치 없음 · API 없음 |
| 출처 추측 | 알리바바 통이 연구소 (Wan 2.7?) |
| 현재 상태 | 순위표에서 삭제됨 |
💡 빠른 이해: HappyHorse-1.0은 하나의 "제품"이라기보다는 "익명 성능 공개 테스트"에 가깝습니다. 이러한 "먼저 익명으로 순위를 올린 뒤 나중에 공개하는" 방식은 지난 1년간 LMArena, Image Arena, Code Arena 등에서 여러 번 나타났으며, 대부분 대형 모델 제조사가 배후에 있었습니다. 현재 공개된 영상 생성 모델들을 직접 비교하고 경험해보고 싶다면, APIYI(apiyi.com) 플랫폼을 통해 주요 모델들을 빠르게 이용해 보세요.
HappyHorse-1.0의 Arena 랭킹 성적
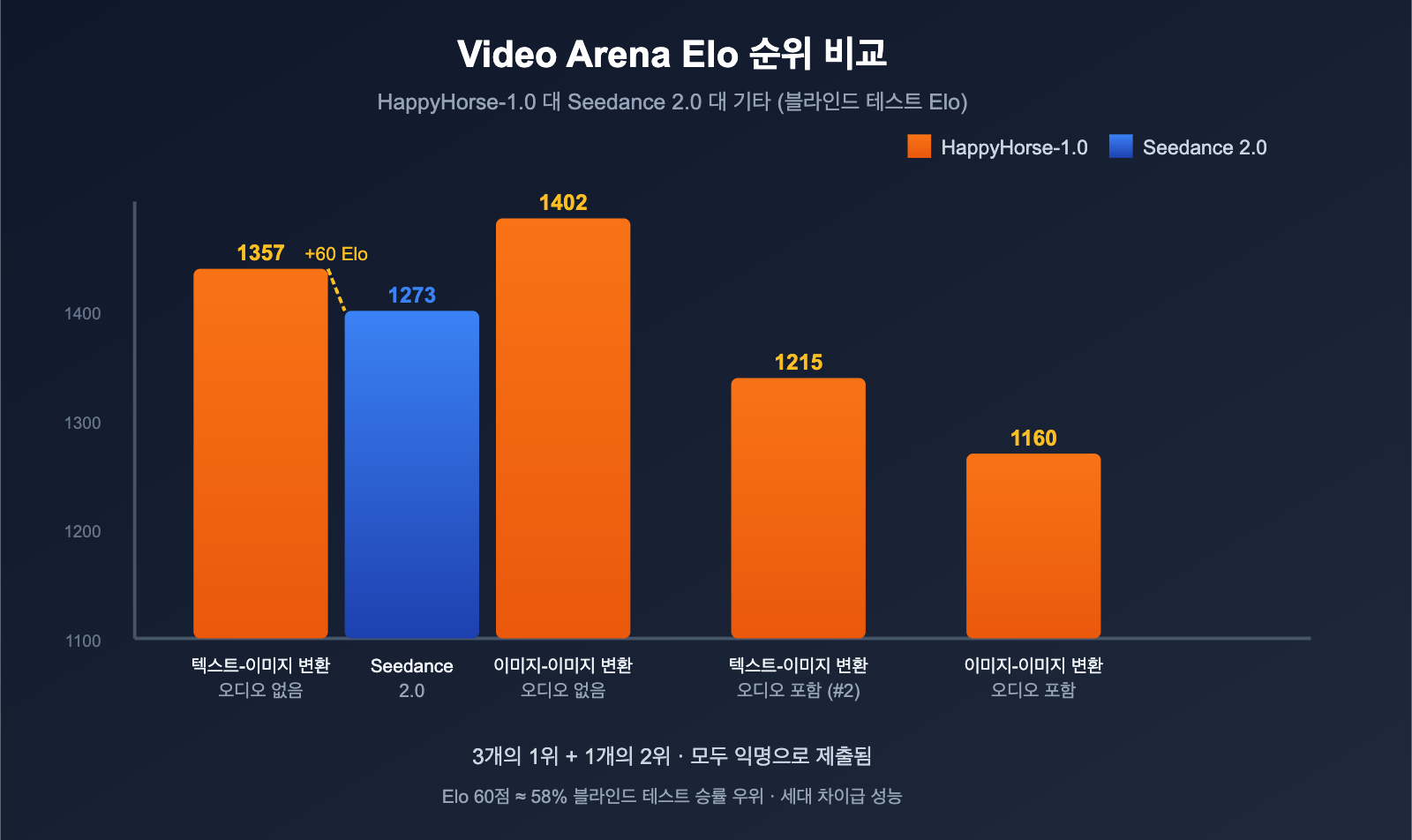
Artificial Analysis는 현재 AI 비디오 생성 분야에서 가장 권위 있는 블라인드 테스트 순위 사이트 중 하나입니다. Elo 점수와 사용자 블라인드 투표 방식을 채택하여 기업의 자화자찬을 배제하죠. 4월 7일, HappyHorse-1.0이 기록한 성적은 다음과 같습니다.
| 랭킹 카테고리 | HappyHorse-1.0 Elo | 순위 | 이전 1위 |
|---|---|---|---|
| 텍스트-이미지 변환 (오디오 없음) | 1333-1357 | 🥇 #1 | Seedance 2.0 (1273) |
| 이미지-이미지 변환 (오디오 없음) | 1392-1402 | 🥇 #1 | — |
| 텍스트-이미지 변환 (오디오 포함) | 1205-1215 | 🥈 #2 | — |
| 이미지-이미지 변환 (오디오 포함) | 1160 | 🥇 #1 | — |
가장 인상적인 부분은 텍스트-이미지 변환(오디오 없음) 부문입니다. HappyHorse-1.0은 등장하자마자 기존 1위였던 바이트댄스의 Seedance 2.0보다 60점 높은 Elo 점수를 기록했습니다. Elo 점수 체계에서 60점 차이는 약 58%의 승률 우위를 의미하며, 이는 상당한 기술적 격차를 보여줍니다.
HappyHorse-1.0의 기술 아키텍처 추측
공식 논문은 없지만, HappyHorse-1.0의 출시 페이지와 WaveSpeedAI 등 제3자 분석을 통해 몇 가지 아키텍처 세부 사항이 드러났습니다. 만약 사실이라면, 오픈소스 커뮤니티 최초로 '엔드 투 엔드 오디오-비디오 통합 사전 학습'을 달성한 사례가 될 것입니다.
단일 스트림 통합 Transformer
HappyHorse-1.0은 40층짜리 Self-Attention Transformer를 사용하여 텍스트 토큰, 참조 이미지 latent, 노이즈가 섞인 비디오 토큰, 노이즈가 섞인 오디오 토큰을 하나의 시퀀스로 묶어 동시에 노이즈를 제거합니다. 이는 Sora나 Seedance처럼 현재 주류인 '듀얼 타워 + Cross-Attention' 방식과는 완전히 다른 접근입니다.
- 시작과 끝 4층: 모달리티별 프로젝션을 사용하여 입력과 출력을 처리
- 중간 32층: 파라미터를 완전히 공유하며 모든 모달리티를 동일하게 처리
- Cross-Attention 없음: 모든 모달리티가 동일한 어텐션 메커니즘 내에서 상호작용
이러한 '전체 Self-Attention 단일 스트림' 방식은 GPT-4o나 Gemini 2.x가 멀티모달 분야에서 시도하고 있는 패러다임인데, 비디오 생성 분야에서 '오픈소스 + 최고 성능'의 형태로 등장한 것은 이번이 처음입니다.
오디오-비디오 통합 생성
HappyHorse-1.0은 한 번의 추론으로 비디오 + 대화 + 환경음 + 폴리(Foley) 효과음을 동시에 생성하며, 6개 언어(중국어, 영어, 일본어, 한국어, 독일어, 프랑스어)를 지원한다고 밝히고 있습니다. 보조 사이트에서는 광둥어 지원과 '초저 WER(단어 오류율) 립싱크' 기능까지 언급하고 있죠.
이 지표들이 모두 사실이라면, '엔드 투 엔드 오디오-비디오 사전 학습' 측면에서 HappyHorse-1.0이 가진 리더십은 순위표에 나타난 것보다 훨씬 더 클 것으로 보입니다.
추론 속도
| 구성 | 시간 |
|---|---|
| 5초 256p 비디오 | ~2초 |
| 5초 1080p 비디오 (H100) | ~38초 |
이 속도가 사실이라면 15B 파라미터급 비디오 모델로서는 매우 공격적인 성능이며, 실시간 생성의 경계에 근접한 수준입니다.
HappyHorse-1.0의 유래에 대한 추측

익명 제출 방식이었기에 Artificial Analysis는 공시할 때 이 모델을 "pseudonymous(가명)"로 표기할 수밖에 없었습니다. 하지만 커뮤니티에서는 여러 단서를 바탕으로 몇 가지 주요 추측을 내놓고 있습니다.
추측 1: 알리바바 통이(Tongyi) 연구소 (Wan 2.7)
현재 커뮤니티에서 가장 유력하게 거론되는 추측입니다. 이유는 네 가지입니다.
- 시기적 우연: 4월 7일 HappyHorse-1.0이 1위를 차지한 후, 4월 초 알리바바 통이 연구소가 Wan 2.6을 발표했습니다. 업계에서는 차세대 모델인 Wan 2.7의 등장을 예견하고 있었습니다.
- 자본 시장 반응: 홍콩 증시의 알리바바 주가가 HappyHorse 등재 이후 한때 8% 가까이 상승했는데, 시장이 이를 알리바바와 연관 지은 것으로 보입니다.
- CJK 다국어 능력: 모델이 중어, 일어, 한국어 3개 국어를 매우 강력하게 지원하는데, 이는 중화권/동아시아 팀의 전형적인 특징입니다.
- 익명 등재 스타일: 알리바바는 이전에 Qwen / Wan 시리즈를 공개할 때 "소규모 선공개 후 정식 발표"하는 방식을 여러 번 사용한 바 있습니다.
하지만 공식적으로 인정된 바는 없으며, 알리바바 통이 연구소가 4월에 정식 발표한 Wan 2.7이 일부 공개 시연에서 HappyHorse와 완전히 일치하지 않는 모습을 보여 이 추측은 아직 검증되지 않았습니다.
추측 2: 바이트댄스 / 기타 대기업
일각에서는 HappyHorse가 바이트댄스 Seedance 시리즈의 차세대 변형일 수 있다고 봅니다. Seedance 2.0이 바로 이 모델에게 1위 자리를 내주었기 때문입니다. 바이트댄스가 익명 방식으로 Seedance 3.0을 미리 테스트하려 했을 가능성이 있다는 분석입니다. 하지만 현재 이를 뒷받침할 증거는 없습니다.
추측 3: 새로운 중화권 독립 팀
HappyHorse가 외부의 주목을 받지 못한 새로운 중화권 스타트업 팀의 작품이라는 의견도 있습니다. 모델이 보여준 "15B + 완전한 Self-Attention + 음성-영상 결합" 기술 스택이 매우 파격적이어서, 기존 관습에 얽매이지 않는 소규모 팀의 결과물 같다는 평가입니다.
🎯 냉정하게 바라보기: 공식적인 발표가 있기 전까지 "알리바바다", "바이트댄스다", "어떤 유니콘 기업이다"라는 말은 모두 추측일 뿐입니다. 우리가 주목해야 할 것은 "그것이 누구인가"가 아니라 "모델의 능력치가 어디까지 도달했는가"입니다. 또한 현재 우리가 바로 사용할 수 있는 영상 생성 모델을 통해 어떤 실질적인 애플리케이션을 구축할 수 있는지도 중요합니다. 주류 영상 모델을 즉시 연동하여 제품 검증을 진행하고 싶다면, **APIYI (apiyi.com)**를 통해 여러 모델을 한 번에 호출해 보세요.
HappyHorse-1.0이 72시간 만에 사라진 이유
가장 극적인 부분은 HappyHorse-1.0의 "실종"입니다. 4월 7일 새벽 Artificial Analysis 순위표 1위에 오른 지 72시간도 채 되지 않아, HappyHorse 시리즈 모델은 목록에서 갑자기 삭제되었습니다. 남은 것은 다음과 같습니다.
- 소셜 미디어에 떠도는 몇 장의 스크린샷
- 암호화된 공식 랜딩 페이지 ("GitHub / HuggingFace 곧 공개"라고 되어 있으나 링크는 모두 작동하지 않음)
- Artificial Analysis가 직접 확인한 "철회됨" 공식 설명
이러한 "등재 → 사라짐" 시나리오는 LMArena에서도 여러 번 반복된 패턴입니다. GPT-4 Turbo의 초기 익명 버전, Claude 3.5 Sonnet의 프리뷰, Gemini 2.0 Flash의 초기 변형 모델들이 모두 비슷한 과정을 거쳤습니다. 거의 모든 경우, 익명 모델이 사라진 후 3~8주 이내에 정식 제품이 출시되었습니다.
업계에서는 HappyHorse를 두고, 특정 대형 팀이 실제 사용자 선호도 데이터를 수집하여 정식 출시를 준비하는 과정으로 해석하고 있습니다.
HappyHorse-1.0이 AI 영상 생성 업계에 미치는 영향

HappyHorse-1.0은 비록 정식으로 공개되지는 않았지만, 이미 AI 영상 생성 분야 전반에 실질적인 영향을 미치고 있습니다.
주요 기업에 미치는 영향
- Seedance 2.0, Veo 3, Sora 2의 '안전지대'가 깨짐: 60점의 Elo 격차는 영상 생성 능력의 상한선이 아직 한참 남았음을 시사합니다.
- 오디오-비디오 통합 생성이 새로운 전장으로: HappyHorse는 4개 분야 중 3개 분야에서 1위를 차지했으며, 특히 오디오 통합 분야에서 압도적인 성능을 보여주었습니다. 이는 모든 주요 기업들이 오디오-비디오 사전 학습(audio-video pretraining) 경로를 가속화하도록 압박할 것입니다.
- 오픈소스/반오픈소스 압박: HappyHorse는 "Everything is open"을 표방하고 있어(아직 실제로 오픈되지는 않았지만), Sora와 같은 폐쇄형 모델들에 상당한 압박이 될 것입니다.
개발자와 크리에이터에게 미치는 영향
- 능력치 기대치 상향: 1080p / H100 / 38초라는 성능은 '실시간 영상 생성'이 더 이상 공상과학이 아님을 증명합니다.
- 다국어 + 립싱크: 한국어, 중국어, 영어, 일본어, 독일어, 프랑스어 등 6개 언어의 엔드투엔드 오디오-비디오 생성은 숏폼 드라마, 광고, 교육용 영상 제작에 큰 기회가 될 것입니다.
- 실용적인 경로 유지: HappyHorse가 실제로 공개되기 전까지는 Veo 3, Sora 2, Kling 2, Wan 2.6 등 이미 사용 가능한 모델들을 능숙하게 다루는 것이 실제 제품을 구축하는 가장 좋은 방법입니다. APIYI(apiyi.com)를 통해 한 번에 연동해 보세요.
중국 AI 팀에 미치는 영향
만약 HappyHorse가 알리바바나 다른 중국계 팀의 작품으로 확인된다면, 이는 중국 AI 영상 생성 기술이 '지역 편향이 없는' 영문 블라인드 테스트 순위인 Artificial Analysis에서 3관왕을 차지한 첫 사례가 됩니다. 이는 모델 그 자체보다 훨씬 더 큰 의미를 갖습니다.
HappyHorse-1.0 자주 묻는 질문(FAQ)
Q1: HappyHorse-1.0을 지금 바로 사용할 수 있나요?
아니요. 이 모델은 Artificial Analysis의 블라인드 테스트 아레나에 약 72시간 동안 잠시 나타났을 뿐, 공개된 API나 다운로드 가능한 가중치, 접근 가능한 GitHub 저장소가 없습니다. 지금 바로 최고 수준의 영상 생성 모델을 사용하고 싶다면, APIYI(apiyi.com)를 통해 현재 공개된 Veo 3, Sora 2, Kling 2, Wan 2.6 등 주요 모델을 연동해 사용하세요.
Q2: HappyHorse-1.0이 정말 알리바바의 Wan 2.7인가요?
현재 공식적으로 확인된 바는 없습니다. 커뮤니티에서는 네 가지 추측(시기적 일치, 알리바바 홍콩 주가 급등, CJK 다국어 능력, 알리바바의 과거 출시 스타일)을 제시하고 있지만, 4월에 정식 출시된 Wan 2.7의 데모와 HappyHorse가 완벽히 일치하지는 않습니다. 따라서 "가능성은 높지만 확인되지 않음"이 정확한 표현입니다.
Q3: 60점의 Elo 격차가 의미하는 바는 무엇인가요?
Elo 점수 체계에서 60점 차이는 대략 58%의 블라인드 테스트 승률을 의미합니다. 이는 매우 유의미하지만 충분히 따라잡을 수 있는 격차입니다. 참고로 지난 1년간 Sora, Veo, Kling, Seedance 사이의 순위 변동은 보통 20~40점 이내였습니다. HappyHorse가 등장하자마자 60점 차이를 낸 것은 확실히 세대 차이가 나는 성능임을 보여줍니다.
Q4: ’15B 파라미터 + 전체 Self-Attention 단일 스트림’ 아키텍처가 왜 혁신적인가요?
매우 파격적입니다. 현재 주류 영상 모델들은 대부분 '듀얼 타워 + Cross-Attention'이나 'DiT + 교차 모달 투영' 같은 혼합 방식을 사용합니다. 반면 HappyHorse는 오디오, 비디오, 텍스트를 모두 40층 Transformer 공유 파라미터에 통합했습니다. 이는 GPT-4o나 Gemini 2.x가 멀티모달 분야에서 시도하는 기술적 경로와 같지만, 영상 생성 분야에서 최고 수준의 성능으로 검증된 것은 이번이 처음입니다.
Q5: 왜 72시간 만에 순위표에서 사라졌나요?
이는 익명 모델들이 흔히 사용하는 '데이터 수집 패턴'입니다. LMArena에 등장했던 초기 GPT-4 Turbo, Claude 3.5 Sonnet 프리뷰, Gemini 2.0 Flash 초기 버전들도 같은 과정을 거쳤습니다. 즉, 출시 → 실제 사용자 선호 데이터 수집 → 비공개 전환 → 몇 주 후 정식 출시 순서입니다. HappyHorse도 3~8주 내에 정식 명칭으로 돌아올 것으로 예상됩니다.
Q6: HappyHorse를 대신해 지금 사용할 수 있는 영상 모델은 무엇인가요?
현재 공개된 모델 중 종합 성능이 가장 뛰어난 모델은 Google Veo 3(범용 품질 최상위), OpenAI Sora 2(카메라 연출력 우수), Kling 2(인물/동작 표현 우수), 바이트댄스 Seedance 2.0(중국어 환경 최적화), 알리바바 Wan 2.6(오픈소스 및 배포 용이성)입니다. 여러 모델을 비교 테스트하고 싶다면 APIYI(apiyi.com) 플랫폼을 통해 통합 인터페이스로 한 번에 연동해 보세요. 여러 계정을 관리할 필요가 없어 매우 편리합니다.
요약
HappyHorse-1.0은 2026년 4월 AI 영상 생성 분야에서 가장 드라마틱하게 등장한 "익명의 강자"입니다. 이 모델은 다음 세 가지를 시사합니다.
- 영상 생성 능력의 상한선 돌파: Elo 점수 60점 차이로 1위, 4개 부문에서 3관왕 1준우승을 차지하며, 현재 우리가 보는 "최강 영상 모델"이 아직 정점에 도달하지 않았음을 증명했습니다.
- 오디오-비디오 통합 생성의 부상: 오디오 포함 부문에서 보여준 HappyHorse의 압도적인 성능은 업계 전체가 엔드투엔드 오디오-비디오 사전 학습(pretraining)을 서두르게 만들 것입니다.
- 익명 등장 → 철회 → 공식 출시가 플래그십 모델의 표준 출시 방식: 3~8주 이내에 우리에게 익숙한 기업이 이 모델을 공식적으로 발표할 것으로 예상됩니다.
🚀 실전 가이드: HappyHorse가 정식으로 공개되기 전, 가장 현실적인 대응은 그 정체를 추측하는 것이 아니라 현재 사용 가능한 최고 수준의 영상 모델들을 능숙하게 다루는 것입니다. Veo 3, Sora 2, Kling 2, Seedance 2.0, Wan 2.6 모델만으로도 실제 프로덕션 환경의 90% 이상을 커버할 수 있습니다. APIYI(apiyi.com)를 통해 주요 영상 모델을 한곳에서 연동해 보세요. 사용량만큼만 지불하고 필요에 따라 자유롭게 모델을 전환하다가, HappyHorse나 Wan 2.7이 정식 출시되면 즉시 원활하게 마이그레이션할 수 있습니다.
작성자: APIYI Team — 개발자들에게 주요 AI 대규모 언어 모델의 안정적인 연동 환경을 제공합니다. apiyi.com에서 더 자세한 내용을 확인하세요.
참고 자료
-
WaveSpeedAI 블로그 – What Is HappyHorse-1.0
- 링크:
wavespeed.ai/blog/posts/what-is-happyhorse-1-0-ai-video-model - 설명: 아키텍처, 파라미터 및 추론 속도에 대한 제3자 심층 분석
- 링크:
-
Artificial Analysis – Video Arena Leaderboard
- 링크:
artificialanalysis.ai/video/leaderboard/text-to-video - 설명: 텍스트-이미지 변환 및 이미지-이미지 변환 부문 통합 순위
- 링크:
-
Phemex News – HappyHorse Tops Rankings
- 링크:
phemex.com/news/article/happyhorse10-surpasses-seedance-20-in-ai-video-model-rankings-71750 - 설명: HappyHorse와 Seedance 2.0의 비교 데이터
- 링크:
-
36Kr – Mysterious Model HappyHorse
- 링크:
eu.36kr.com/en/p/3757826958635781 - 설명: 익명 모델 등장에 대한 업계 해석
- 링크:
-
Futunn – 阿里港股因 HappyHorse 大涨
- 링크:
news.futunn.com/en/post/71208943 - 설명: 모델 출처 추측에 따른 자본 시장의 반응
- 링크:
-
DEV Community – Who Developed HappyHorse
- 링크:
dev.to/calvin_claire_451169e1b82 - 설명: 개발 팀에 대한 커뮤니티의 다양한 추측
- 링크: