
GPT-5.5 と Claude Opus 4.7 は、2026年前半のデベロッパーにとって最も注目すべきフラッグシップモデルの比較対象です。
両者とも、単なるチャットモデルではありません。
GPT-5.5 は、エージェントによるコーディング(agentic coding)、コンピュータ操作、ナレッジワーク、そして科学的分析に重点を置いています。
一方、Claude Opus 4.7 は、複雑な推論、長期的なエージェントタスク、高解像度な視覚理解、記憶能力、そしてより厳格な指示追従性に強みを持っています。
単に「どちらが強いか」と問うのはあまりに単純すぎます。
より実用的な問いは、「あなたのタスクはコード修正なのか、ナレッジベースのQAなのか、長文脈の分析なのか、視覚理解なのか、自動化エージェントなのか、それとも高コストな本番環境でのAPI呼び出しなのか」という点です。
タスクの種類によって、GPT-5.5 と Claude Opus 4.7 のどちらを選択すべきかは明確に異なります。
OpenAI が GPT-5.5 を公式発表した際、比較評価表の中に Claude Opus 4.7 を直接組み込んでいました。
また、Anthropic も Claude Opus 4.7 を現時点で最強の汎用モデルと位置づけ、エージェントによるコーディング、ナレッジワーク、視覚タスク、記憶タスクにおける向上を強調しています。
本記事は、英語の公式資料に基づいて整理したものであり、中国語の二次情報を引用していません。
なお、本記事で言及する「Claude 4.7」は、正確には「Claude Opus 4.7」を指します。本記事執筆時点では、Anthropic の公式資料において「Claude Sonnet 4.7」のリリースは確認されていません。
GPT-5.5 vs Claude Opus 4.7 の核心的な結論
GPT-5.5 と Claude Opus 4.7 の最初の違いは、モデルのポジショニングにあります。
OpenAI は GPT-5.5 を、実際のワークフローにより適したモデルとして定義しています。コーディング、デバッグ、オンラインリサーチ、データ分析、ドキュメントや表の生成、そしてツールを横断したタスク完了に重点を置いています。
一方、Anthropic は Claude Opus 4.7 を、同社最強の汎用モデルとして定義しています。複雑な推論、エージェントによるコーディング、長期的なタスク、視覚理解、記憶能力、そして自己検証に重点を置いています。
もしあなたのタスクが Codex における複雑なエンジニアリングプロジェクト、複数ファイルにわたる修正、ツール呼び出し、ナレッジワークであれば、GPT-5.5 を優先的にテストすることをお勧めします。
もしあなたのタスクが Claude Code による長時間のエージェント実行、スクリーンショットの視覚理解、ドキュメントのレイアウト検証、ファイルシステムの記憶、そして厳格な指示追従であれば、Claude Opus 4.7 を優先的にテストすべきです。
両方のモデルを統合して利用する必要がある場合は、APIYI (apiyi.com) を通じてマルチモデルルーティングや評価を行うことで、モデルの選択をビジネスコードにハードコーディングすることを避けるのが賢明です。
GPT-5.5 vs Claude Opus 4.7 クイック比較
| 項目 | GPT-5.5 | Claude Opus 4.7 | 選択のヒント |
|---|---|---|---|
| 公式ポジショニング | 実際のワークフローとエージェントAI | 最強の汎用 Claude モデル | タスクの種類で選ぶ |
| コーディング能力 | Terminal-Bench 2.0 で強力 | エージェントコーディングが大幅向上 | 両方テストすべき |
| 長文脈 | API 最大 1M コンテキスト | 1M コンテキストウィンドウ | 両方とも長文脈に対応 |
| 視覚能力 | マルチモーダルとツールの連携 | 高解像度画像サポート | 視覚タスク重視なら Claude |
| 推論制御 | reasoning_effort | effort / adaptive thinking | パラメータ体系が異なる |
| API コスト | 5ドル(入力) / 30ドル(出力) / 1Mトークン | 5ドル(入力) / 25ドル(出力) / 1Mトークン | Claude の出力が安価 |
| エコシステム | ChatGPT、Codex、API | Claude、Claude Code、API | ワークフローに依存 |
選択のヒント:GPT-5.5 と Claude Opus 4.7 のどちらが適しているか判断できない場合は、まず30〜50件の実際の業務サンプルを用意し、APIYI (apiyi.com) を通じて両モデルを同時に実行し、成功率、応答時間、コスト、および人間による評価を比較することをお勧めします。
GPT-5.5 vs Claude Opus 4.7 コーディング能力比較
コーディングは、GPT-5.5 と Claude Opus 4.7 の最も重要な比較対象です。
OpenAI の公式データによると、GPT-5.5 は Terminal-Bench 2.0 で 82.7% を記録しました。
同じ表において、Claude Opus 4.7 は 69.4% です。
一方、SWE-Bench Pro の公開評価では、GPT-5.5 が 58.6%、Claude Opus 4.7 が 64.3% となっています。
このことから、どちらか一方が圧倒的に優れているわけではないことがわかります。
GPT-5.5 は、コマンドラインの複雑なワークフロー、計画立案、反復作業、およびツール連携においてより優れたパフォーマンスを発揮します。
Claude Opus 4.7 は、GitHub issue の解決といったタスクにおいて非常に高い競争力を持っています。
Anthropic の公式資料では、Claude Opus 4.7 が同社の 93-task coding benchmark において、Opus 4.6 よりも 13% 向上したことが強調されています。
これは、Claude Opus 4.7 が前世代と比較してコーディング能力が着実に向上していることを示しています。
しかし、GPT-5.5 と Claude Opus 4.7 を比較する際、特定のベンチマーク結果だけで結論を出すことはできません。
実際のコーディング作業には、古いコードの理解、リスクの特定、変更範囲の制御、テストの補完、コマンドの実行、失敗への対処、変更内容の説明、レビューノートの生成などが含まれるからです。
GPT-5.5 は Codex シナリオにおいて、ツールを横断した実行と、より少ないトークン数でのタスク完了を重視しています。
Claude Opus 4.7 は Claude Code シナリオにおいて、長期的なエージェント機能、高い労力(xhigh effort)、そしてより厳格な指示の遵守を重視しています。
GPT-5.5 vs Claude Opus 4.7 コーディングシナリオ別推奨
| コーディングタスク | 推奨される優先テスト | 理由 |
|---|---|---|
| コマンドラインの複雑なワークフロー | GPT-5.5 | Terminal-Bench 2.0 の公式スコアがより高いため |
| GitHub issue の修正 | Claude Opus 4.7 / GPT-5.5 両方 | SWE-Bench Pro では Claude が高いが、GPT-5.5 はエコシステムが強力 |
| 大規模コードベースの理解 | GPT-5.5 | Codex シナリオがシステム横断のコンテキストに強いため |
| 長時間のエージェントタスク | Claude Opus 4.7 | xhigh effort とタスク予算の親和性が高いため |
| コードレビューと検証 | 両方とも適している | テストのループ(閉環)を重視 |
| コスト重視のバッチ修正 | 実測が必要 | トークン使用形態に大きな差があるため |
選択のアドバイス:コーディングモデルはランキングだけで判断しないでください。実際の issue、失敗したテスト、PR レビュー、リファクタリングタスクを APIYI (apiyi.com) に入力して比較評価を行うことをお勧めします。各モデルが実際にテストを実行したか、無関係なファイルを誤って変更しなかったか、リスクを適切に説明できたかを記録してください。

GPT-5.5 vs Claude Opus 4.7 知識労働とリサーチ能力
GPT-5.5 と Claude Opus 4.7 の知識労働における比較も非常に重要です。
OpenAI の公式資料によると、GPT-5.5 は GDPval で 84.9% を達成しました。
Claude Opus 4.7 は同じ表で 80.3% です。
GPT-5.5 Pro は 82.3% となっています。
これは、OpenAI が提示する専門的な知識労働の評価において、GPT-5.5 が非常に強力であることを示しています。
また OpenAI は、GPT-5.5 がドキュメント、表、プレゼンテーション資料の作成、運用リサーチやビジネスインプットの処理において大幅に向上したことを強調しています。
Anthropic 側では、Claude Opus 4.7 の公式資料において、知識労働、記憶力、視覚認識、および長期的なエージェントタスクにおける卓越したパフォーマンスが強調されています。
Claude Opus 4.7 の重要な特徴の一つは、データに対する規律の強さです。
Anthropic のページでは Hex の評価を引用し、データが欠落している場合に、もっともらしいが誤った代替案を提示するのではなく、欠落していることを明示する姿勢を高く評価しています。
これは金融分析、リサーチレポート、コンプライアンス審査、データテーブル処理において非常に重要です。
もしあなたの知識労働タスクで、美しく、完全で、構造が明確なビジネスドキュメントを作成する必要があるなら、GPT-5.5 は試す価値が十分にあります。
一方で、データが欠落していたり、データに矛盾があったり、長いコンテキストの中で慎重さを維持する必要があるタスクであれば、Claude Opus 4.7 も非常に強力な選択肢となります。
GPT-5.5 vs Claude Opus 4.7 知識労働における選択
| シナリオ | GPT-5.5 の強み | Claude Opus 4.7 の強み | 推奨 |
|---|---|---|---|
| ビジネスレポート | 構造化生成が強力 | データ規律が強い | 両方で比較 |
| 表分析 | Codex のドキュメント表処理能力が高い | 視覚的検証とグラフ分析に強い | 入力形式で判断 |
| 金融リサーチ | GDPval のパフォーマンスが高い | General Finance モジュールの向上 | 実際のサンプルでテスト |
| コンプライアンス審査 | 総合能力が高い | 欠落データの処理が慎重 | Claude を優先してテスト |
| 複数ドキュメント要約 | 長いコンテキストに強い | 記憶力と厳格な指示遵守 | 引用の質で選定 |
選択のアドバイス:知識労働で最も怖いのは「一見完璧に見えるが、実際にはハルシネーション(幻覚)が含まれている」ことです。APIYI (apiyi.com) で GPT-5.5 と Claude Opus 4.7 を比較する際は、人間の評価を「事実の正確性」「引用の一貫性」「漏れ率」「構造の質」「実行可能性」の 5 つの次元に分解することをお勧めします。
GPT-5.5 vs Claude Opus 4.7:ビジュアルおよび長文脈処理能力の比較
GPT-5.5 と Claude Opus 4.7 はどちらも長文脈(ロングコンテキスト)に対応していますが、その詳細には違いがあります。
OpenAI の公式資料によると、GPT-5.5 API は 100万トークンのコンテキストウィンドウを備えています。
一方、Anthropic のモデル概要によれば、Claude Opus 4.7 も同様に 100万トークンのコンテキストウィンドウをサポートし、最大 128k トークンの出力が可能です。
長文脈タスクにおいて、両モデルとも大規模なドキュメント、コードベース、複雑な資料セットを処理できるレベルに達しています。
しかし、ビジュアルタスクに関しては、Claude Opus 4.7 の進化がより顕著です。
Anthropic のドキュメントによると、Claude Opus 4.7 は高解像度画像に対応した初の Claude モデルであり、最大画像解像度が 2576px / 3.75MP まで向上しました。
これは、スクリーンショットの理解、ドキュメントの画像化、スライドの検証、グラフ分析、およびコンピュータ操作(computer use)において非常に重要です。
また、Anthropic は画像座標が実際のピクセルと 1:1 で対応するようになったため、座標の拡大縮小変換の手間が軽減されたとも述べています。
GPT-5.5 も強力なマルチモーダルおよびコンピュータ操作能力を持っていますが、高解像度のスクリーンショット、グラフ、ドキュメントのレイアウト、あるいは UI 座標の扱いが入力の核となる場合は、Claude Opus 4.7 を優先的にテストすることをおすすめします。
入力が長文テキスト、コードベース、業務ドキュメント、構造化データ、ツールチェーンの結果である場合は、GPT-5.5 と Claude Opus 4.7 の両方で同じサンプルセットを使用して評価を行う必要があります。
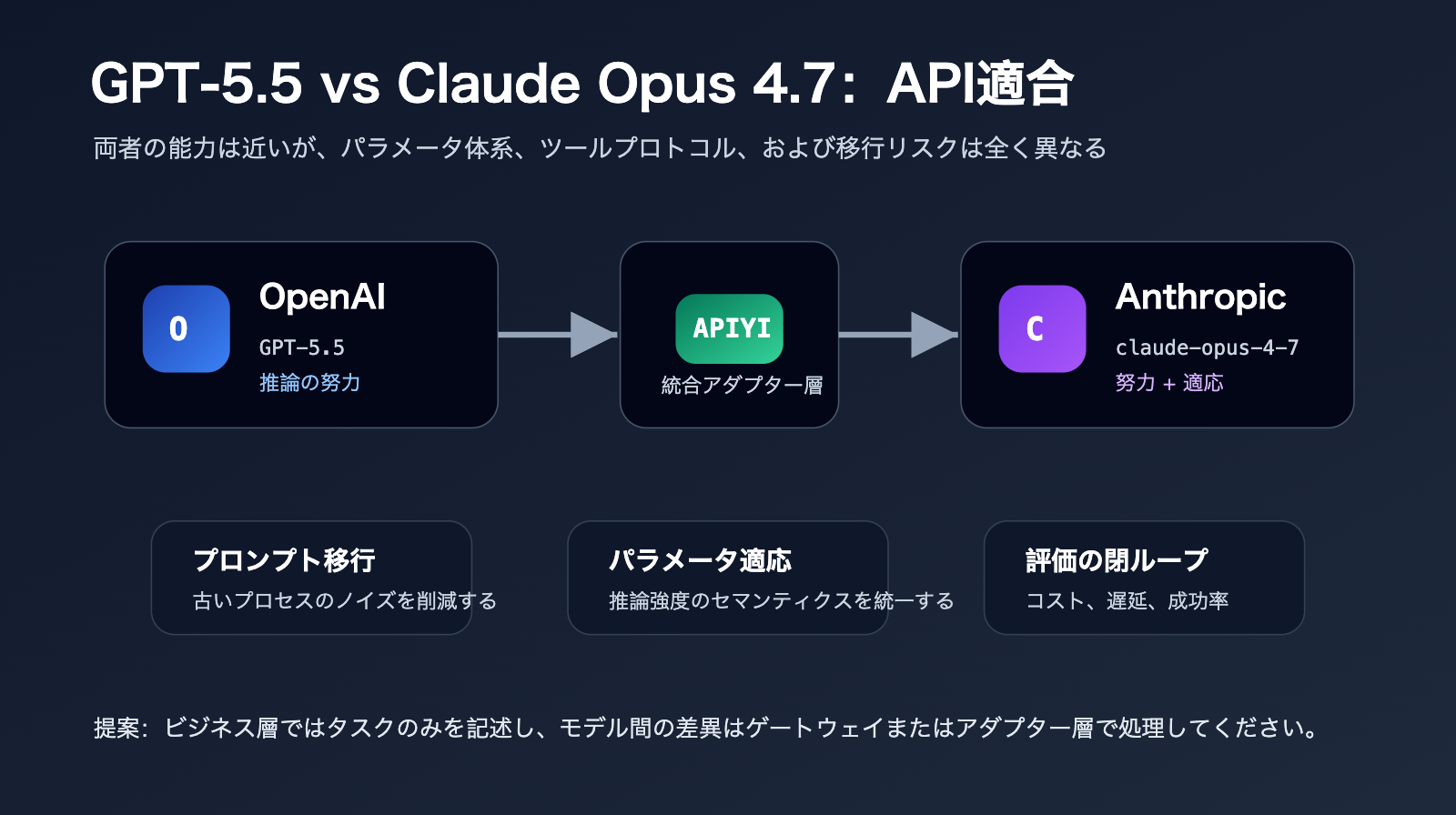
GPT-5.5 vs Claude Opus 4.7:API パラメータと移行の差異
GPT-5.5 と Claude Opus 4.7 の間では、API の移行に伴う差異が非常に大きいです。
GPT-5.5 は OpenAI のモデル体系に属しており、重要なパラメータには model、reasoning_effort、Responses API のツール呼び出し、および出力形式の制御が含まれます。
Claude Opus 4.7 は Anthropic の Messages API 体系に属しており、重要なパラメータには adaptive thinking、effort、task budget、max_tokens、およびツール呼び出しが含まれます。
Anthropic の公式ドキュメントによると、Claude Opus 4.7 では extended thinking budgets が削除されました。
古い記述である thinking: {"type": "enabled", "budget_tokens": N} を使用すると、400 エラーが返されます。
新しい記述では thinking: {"type": "adaptive"} を使用し、output_config を通じて effort を設定する必要があります。
さらに Anthropic は、Claude Opus 4.7 からはデフォルト以外の temperature、top_p、または top_k を設定すると 400 エラーが返されるようになることを明示しています。
これは多くの既存プロジェクトにとって重要な移行ポイントとなります。
もし以前に temperature=0 を使用して決定論的な出力を得ていた場合、temperature=0 であっても完全な一致は保証されないという点を再認識する必要があります。
これに対し、GPT-5.5 への移行における重点は、プロンプトの再構築、reasoning_effort の評価、ツールワークフロー、および結果を優先するプロンプトの設計にあります。
GPT-5.5 vs Claude Opus 4.7 API 移行のポイント
| 移行項目 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| モデル ID | gpt-5.5 |
claude-opus-4-7 |
| 推論制御 | reasoning_effort | effort + adaptive thinking |
| 長文脈 | 1M コンテキストウィンドウ | 1M コンテキストウィンドウ |
| 出力上限 | OpenAI API 仕様に準拠 | 128k 最大出力 |
| 温度パラメータ | OpenAI API のサポート状況に従う | デフォルト以外(temperature/top_p/top_k)はエラー |
| ツールワークフロー | Responses API ツール体系 | Messages API ツール体系 |
| 移行リスク | 古いプロンプトの過剰指定 | thinking budget とサンプリングの旧パラメータ |
選択のアドバイス:GPT-5.5 と Claude Opus 4.7 を同時に導入する場合、業務コード内に2つの異なる呼び出しロジックを直接記述することは推奨されません。APIYI (apiyi.com) を通じて統一された OpenAI 互換のエントリポイントを作成し、モデル間の差異、パラメータの違い、エラー処理をゲートウェイ層やアダプター層で管理するのが賢明です。
GPT-5.5 vs Claude Opus 4.7:コストとパフォーマンスの選択
GPT-5.5 と Claude Opus 4.7 のコストを比較する際、単価だけで判断するのは危険です。
OpenAI の公式資料によると、GPT-5.5 API の価格は入力 100 万トークンあたり 5 ドル、出力 100 万トークンあたり 30 ドルです。
一方、Anthropic のモデル概要によると、Claude Opus 4.7 は入力 100 万トークンあたり 5 ドル、出力 100 万トークンあたり 25 ドルとなっています。
出力単価だけを見れば Claude Opus 4.7 の方が安価です。
しかし、OpenAI は GPT-5.5 が Codex において GPT-5.4 よりもトークン効率が向上していることを強調しています。
同様に Anthropic も、Claude Opus 4.7 が「effort(努力量)」、「task budget(タスク予算)」、「adaptive thinking(適応的思考)」を通じてコストを制御できる点をアピールしています。
つまり、実際のコストはタスクの性質に大きく依存します。
もし GPT-5.5 がより少ないやり取りでタスクを完了できるなら、総コストは必ずしも高くはなりません。
逆に、Claude Opus 4.7 を「xhigh」や「max effort」設定で使用し、大量の出力トークンを消費すれば、総コストは跳ね上がる可能性があります。
コスト評価は「1回の合格タスクを完了させるための総コスト」を見るべきであり、100 万トークンあたりの単価だけで判断してはいけません。
GPT-5.5 vs Claude Opus 4.7 コスト評価の指標
| コスト指標 | 記録すべき内容 | 重要性 |
|---|---|---|
| 入力トークン | プロンプト、コンテキスト、ツール結果 | 長文コンテキストタスクでのコスト差が顕著 |
| 出力トークン | 最終回答、ツールパラメータ、推論関連の出力 | 出力単価は通常高額 |
| やり取り回数 | タスク完了までのターン数 | 多段回数はコストを増幅させる |
| 成功率 | 一発完了か、修正が必要か | 失敗による再試行は隠れたコスト |
| 遅延 | ユーザーの待ち時間 | 高 effort 設定は待ち時間を増加させる |
| 人手による確認 | 人間による修正が必要か | 品質が低いとコストが転嫁される |
選択のアドバイス:企業向けアプリケーションにおいて、モデルのコスト最適化は単に安いモデルを選ぶことではありません。APIYI (apiyi.com) を活用して、呼び出しごとの入力、出力、遅延、モデル、パラメータ、および人手による評価を記録し、「合格タスクあたりのコスト」を最終的な指標にすることをお勧めします。
GPT-5.5 vs Claude Opus 4.7 適用シナリオの決定
個人開発者の場合、GPT-5.5 と Claude Opus 4.7 の選択はツールエコシステムに基づいて決めるのが良いでしょう。
普段から Codex を利用しているなら、まずは GPT-5.5 をテストしてください。
普段から Claude Code を利用しているなら、まずは Claude Opus 4.7 をテストするのが賢明です。
一方で、企業の技術責任者であれば、個人の体験談だけで決定を下すべきではありません。
タスクセットを作成し、両方のモデルを同一の入力、出力、評価基準、コスト記録の下で比較検討すべきです。
コンテンツチームであれば、構造化されたコンテンツ、調査・整理、表作成、マルチツールを活用した業務において、GPT-5.5 を優先的にテストする価値があります。
慎重な表現、長文コンテキスト、視覚資料の分析、ドキュメントの検証が必要な場合は、Claude Opus 4.7 を優先的にテストすることをお勧めします。
API プラットフォームや SaaS 製品を運営している場合は、モデルルーティングの導入を推奨します。
例えば、単純な質問回答はコストの低いモデルに流し、複雑なコード生成や長時間の代理タスクのみを GPT-5.5 や Claude Opus 4.7 にエスカレーションします。
これにより、すべてのリクエストをフラッグシップモデルに投げることを避け、効率的な運用が可能になります。
GPT-5.5 vs Claude Opus 4.7 移行チェックリスト
本番環境へのデプロイ前に、主観的な体験だけで判断するのは避けましょう。
少なくとも以下の5種類のサンプルを用意することをお勧めします。
- 成功サンプル:期待通りに動作するケース。
- 誤判定しやすい境界サンプル:判断が難しいエッジケース。
- 長文コンテキストサンプル:長い入力を伴うケース。
- ツール呼び出しサンプル:外部ツールやAPI連携を行うケース。
- 失敗からの復旧サンプル:エラー発生時の挙動を確認するケース。
各サンプルについて、モデル、パラメータ、入力トークン数、出力トークン数、処理時間、一発で成功したか、そして人間による評価を記録してください。
また、低コスト帯と高性能帯のそれぞれでテストを行うことも重要です。
- GPT-5.5 側では、異なる
reasoning_effortをテストできます。 - Claude Opus 4.7 側では、
medium、high、xhigh、maxの各設定をテストできます。
最初から両方のモデルを最高設定にする必要はありません。最高設定はあくまで上限を示すものであり、運用上のコストパフォーマンスを保証するものではないからです。
GPT-5.5 vs Claude Opus 4.7 の評価データをどう読み解くか?
GPT-5.5 と Claude Opus 4.7 の公開ベンチマークは参考になりますが、そのままあなたのビジネスの結果とイコールにはなりません。
理由は単純です。公開されている評価は、固定されたタスクセット、固定されたプロンプト、固定された実行環境、そして固定された評価ルールに基づいているからです。
一方で、あなたのビジネスシステムでは、ノイズの多いデータ、コンテキストの欠落、ユーザーの曖昧な表現、ツールの失敗、権限制限、そして過去のプロンプトのしがらみなどに直面します。
そのため、GPT-5.5 があるベンチマークでリードしているからといって、すべてのタスクを GPT-5.5 に切り替えるべきだとは限りません。同様に、Claude Opus 4.7 が別のベンチマークで勝っているからといって、すべてを Claude に寄せるのが正解とも限りません。
より確実な方法は、公式のベンチマークを「モデルの能力の方向性を示すヒント」として捉えることです。
- Terminal-Bench 2.0:複雑なコマンドラインワークフローの能力を示します。
- SWE-Bench Pro:実際の GitHub issue を修正する能力に近いものです。
- GDPval:専門知識の提供能力に近いものです。
- 視覚系ベンチマークや高解像度画像サポート:スクリーンショット、グラフ、UI、ドキュメントのレイアウト関連タスクの判断に適しています。
実際に導入する際は、これらの指標を自社の製品シナリオにマッピングする必要があります。
- 製品が IDE コーディングアシスタント なら、コード修正の成功率、テスト通過率、無関係な変更の発生率、解説の質を優先します。
- 製品が 企業向けナレッジベース なら、引用の正確性、事実の欠落率、競合情報の処理、拒否応答の境界を優先します。
- 製品が 自動化エージェント なら、ツール呼び出し回数、失敗からの復旧、タスク完了率、総コストを優先します。
- 製品が 視覚ドキュメント処理 なら、座標認識、グラフの書き起こし、レイアウト理解、人間による修正コストを優先します。
APIYI (apiyi.com) の価値は、これらのモデルテストを統一されたインターフェースで実行できる点にあります。同じ入力、同じ評価指標、同じログ項目を用いることで初めて、GPT-5.5 vs Claude Opus 4.7 の比較結論が真に再利用可能なものとなります。

GPT-5.5 vs Claude Opus 4.7 FAQ
GPT-5.5 と Claude Opus 4.7、コーディングに向いているのは?
どちらも非常に優秀です。
GPT-5.5 は「Terminal-Bench 2.0」で優れたスコアを記録しており、複雑なコマンドライン操作や Codex ワークフローに適しています。
一方、Claude Opus 4.7 は「SWE-Bench Pro」で強力なパフォーマンスを発揮し、Claude Code を活用した長時間のエージェントタスクにも最適です。
実際のプロジェクトで利用する場合は、同じ issue とテストコマンドを使用して両方で比較検証することをお勧めします。
GPT-5.5 と Claude Opus 4.7、ナレッジベースの質疑応答に向いているのは?
構造化された生成や、複数のツールを組み合わせた整理が重要な場合は、まず GPT-5.5 をテストしてみてください。
データの欠落検知や慎重な表現、長いコンテキスト内での厳密なルール遵守が求められる場合は、Claude Opus 4.7 を優先的にテストするのが良いでしょう。
最終的には、引用の正確性と、人間による確認コストを基準に判断してください。
GPT-5.5 と Claude Opus 4.7、視覚タスクに向いているのは?
Claude Opus 4.7 は公式ドキュメントで高解像度画像のサポートを明記しています。
スクリーンショットの解析、座標の特定、ドキュメントのレイアウト確認、視覚的な検証が必要なタスクであれば、Claude Opus 4.7 を優先的にテストする価値があります。
GPT-5.5 もマルチモーダルワークフローに適していますが、視覚処理がメインのタスクについては個別に評価を行うのが賢明です。
GPT-5.5 と Claude Opus 4.7、どちらが安い?
公式の単価では、どちらも入力料金は 100 万トークンあたり 5 ドルです。
出力料金は、Claude Opus 4.7 が 100 万トークンあたり 25 ドル、GPT-5.5 が 100 万トークンあたり 30 ドルとなっています。
ただし、実際のコストはタスク完了までに必要なやり取りの回数、出力の長さ、失敗率、そして人間による修正コストによって変動します。
GPT-5.5 vs Claude Opus 4.7 まとめ
GPT-5.5 と Claude Opus 4.7 のどちらが優れているかという問いに、すべてのシナリオで通用する絶対的な答えはありません。
GPT-5.5 は、複数のツールを駆使した生産ワークフロー、Codex コーディング、ドキュメントや表の生成、ナレッジワーク、複雑なタスクの実行に適しています。
Claude Opus 4.7 は、高解像度な視覚処理、長期的なエージェントタスク、厳格な指示の遵守、ファイル記憶、慎重なデータ処理に適しています。
個人ユーザーであれば、普段利用しているツールエコシステムに合わせて選ぶのが良いでしょう。
企業ユーザーであれば、実際のデータサンプルを用いた評価が不可欠です。
API 開発者であれば、モデルの差異をアダプター層で管理し、特定のビジネスロジックに GPT-5.5 や Claude Opus 4.7 を直接ハードコーディングしないことを推奨します。
APIYI (apiyi.com) は、統一されたモデルの入り口、呼び出しログの記録、コスト監視、およびマルチモデルの切り替えを管理する役割として最適です。
最終的な推奨事項は、高難易度かつツールを多用するタスクには GPT-5.5 を、高精度な視覚処理や長期間のエージェントタスクには Claude Opus 4.7 を使用し、通常のリクエストには低コストモデルを割り当て、評価データに基づいてルーティングを継続的に調整することです。
参考資料:
- OpenAI Introducing GPT-5.5: openai.com/index/introducing-gpt-5-5
- Anthropic Introducing Claude Opus 4.7: anthropic.com/news/claude-opus-4-7
- Anthropic Claude Opus 4.7 API docs: platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7
- Anthropic Models overview: platform.claude.com/docs/en/about-claude/models/overview
- Anthropic Effort docs: platform.claude.com/docs/en/build-with-claude/effort