
Google secara resmi meluncurkan keluarga model multimodal Gemini Omni pada ajang Google I/O 2026, tanggal 19 Mei 2026. Model perdana, Gemini Omni Flash, langsung dirilis untuk pengguna pada hari yang sama. Bagi pendatang baru yang baru mendengar nama ini, kata "Omni" jauh lebih penting daripada yang dibayangkan—ini merepresentasikan arah baru Google dalam mengintegrasikan kemampuan penalaran cerdas Gemini dengan kemampuan pembuatan media secara menyeluruh. Artikel ini akan menjelaskan dengan cara yang paling sederhana dalam 5 menit tentang apa itu Google Omni, apa kemampuannya, perbedaannya dengan Veo, serta bagaimana cara memulainya bagi pengembang atau kreator.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami posisi, batasan kemampuan, saluran penggunaan, dan signifikansi industri dari Google Omni (Gemini Omni), sehingga tidak lagi bingung dengan istilah-istilah dalam berbagai judul berita.
Apa itu Google Omni: Ringkasan Informasi Inti
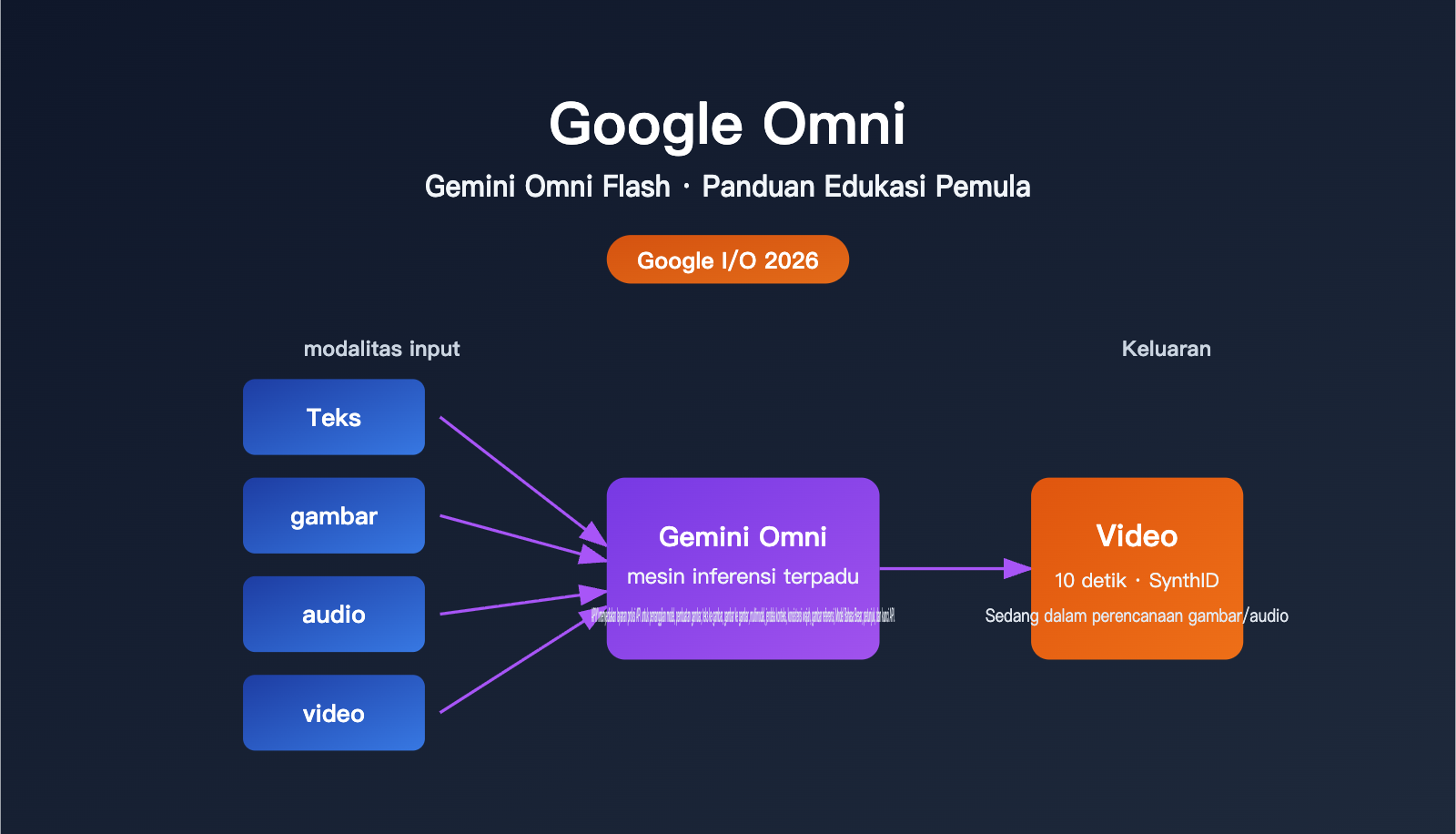
Singkatnya: Google Omni adalah "keluarga model generatif multimodal" yang diluncurkan oleh Google, dengan model perdana Gemini Omni Flash. Nilai jual utamanya bukan sekadar "AI lain yang bisa membuat video", melainkan kemampuannya untuk mengambil teks, gambar, audio, dan video dalam kombinasi apa pun sebagai input, lalu melakukan penalaran terpadu untuk menghasilkan video yang koheren.
CEO Google, Sundar Pichai, menggunakan kalimat yang sangat lugas dalam pidato utamanya untuk menggambarkan posisinya: "create anything from any input". Dengan kata lain, jika dulu Anda harus menggunakan satu model untuk membuat gambar, lalu menggunakan model lain untuk mengubah gambar tersebut menjadi video; Omni mencoba menyelesaikan penalaran dan pembuatan lintas modal dalam satu model saja.
| Informasi | Detail |
|---|---|
| Tanggal Rilis | 19 Mei 2026 (Google I/O 2026) |
| Penerbit | Google (Google DeepMind & Google Labs) |
| Model Perdana | Gemini Omni Flash |
| Posisi Model | Keluarga model terpadu untuk penalaran multimodal + pembuatan media |
| Modalitas Input | Teks, gambar, video, audio (kombinasi apa pun) |
| Modalitas Output | Video (fokus utama saat peluncuran), gambar dan audio akan dibuka kemudian |
| Durasi per Segmen | Maksimal 10 detik (batasan tahap deployment, bukan batas model) |
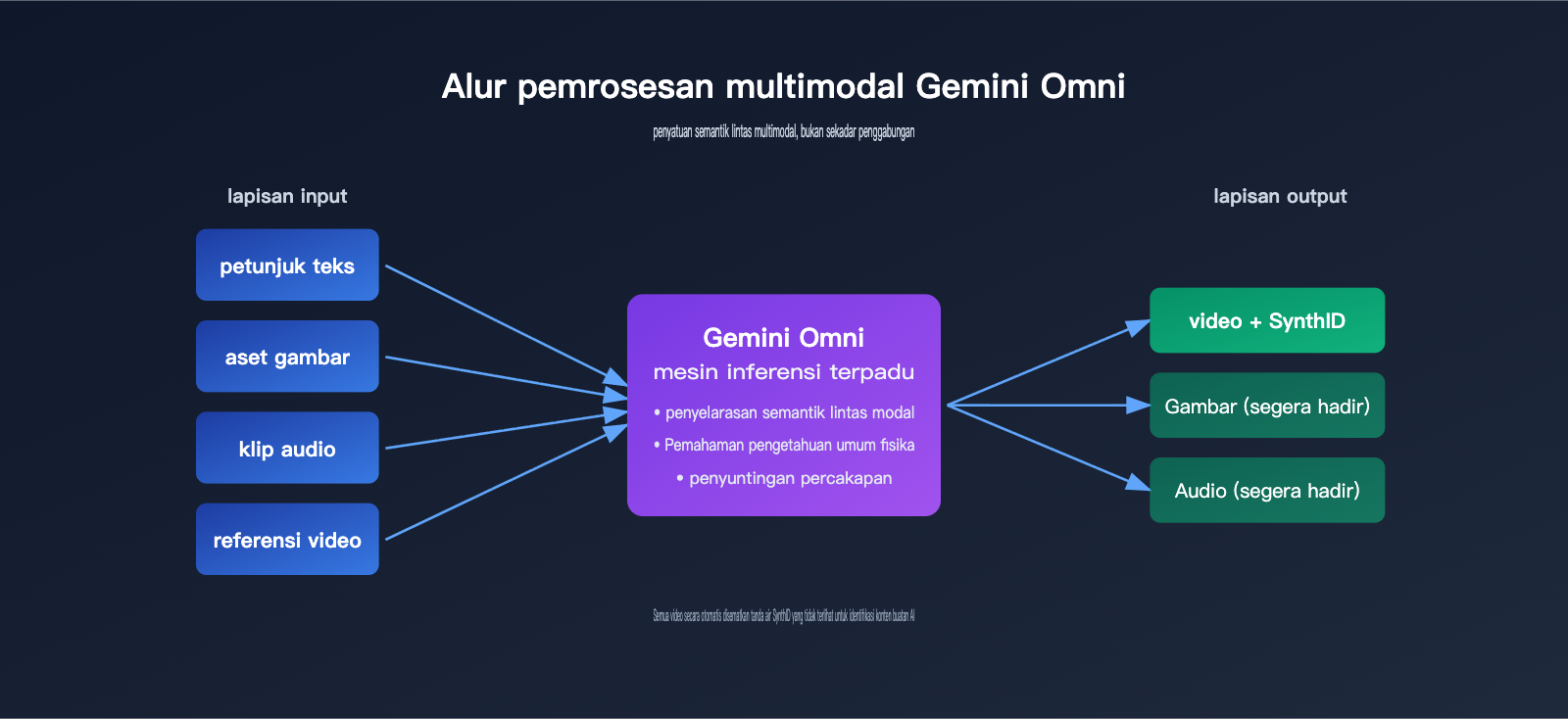
| Identifikasi Konten | Semua video secara otomatis disematkan tanda air tersembunyi SynthID |
| Rencana Mendatang | Gemini Omni Pro, durasi lebih panjang, kemampuan pengeditan audio |
💡 Tips untuk Pemula: Jika ingin mencoba berbagai model utama termasuk seri Gemini secara langsung, Anda bisa menggunakan APIYI (apiyi.com) untuk melakukan pemanggilan model dengan antarmuka terpadu, sehingga Anda tidak perlu repot mendaftar di banyak platform.
Interpretasi Kemampuan Utama Google Omni: Mengapa Disebut "Generasi Baru"
Jika kita hanya melihat "apa inputnya, apa outputnya", mudah untuk menganggap Omni sebagai model yang setara dengan Sora, Veo, atau Runway. Namun, Direktur Produk Google, Nicole Brichtova, memberikan pernyataan yang lebih akurat: "Ini adalah langkah selanjutnya yang menggabungkan kecerdasan Gemini dengan kemampuan rendering model media." Empat kemampuan berikut adalah kunci bagi pemula untuk memahami perbedaan antara Omni dan model video tradisional.
1. Penalaran Multimodal, Bukan Sekadar Penggabungan
Proses pembuatan video tradisional biasanya berupa alur dua langkah: "Teks → Video" atau "Gambar + Teks → Video". Pendekatan Gemini Omni adalah memasukkan semua input ke dalam satu model yang sama, membiarkannya membangun pemahaman semantik terpadu secara internal, lalu merender video dalam satu kali proses.
Sebagai contoh, jika Anda memberikan foto produk, musik latar, dan naskah iklan kepada Omni secara bersamaan, ia akan memahami bahwa "produk harus muncul saat transisi ketukan musik" dan "naskah harus selaras dengan gerakan visual", alih-alih sekadar menumpuk musik di atas video. Kemampuan "memahami dulu, baru menghasilkan" ini berasal dari gen penalaran model Gemini itu sendiri.
2. Pemahaman Fisika dan Pengetahuan Dunia
Dalam demonya, Google menyoroti dua contoh: bidikan bola batu akik yang menggelinding, di mana pantulan, perhentian, dan suara benturan saat bola jatuh sesuai dengan fisika nyata; dan animasi edukasi gaya claymation tentang pelipatan protein, di mana struktur geometrisnya secara mendasar sesuai dengan pengetahuan biologi molekuler. Kedua demo ini terlihat sederhana, namun sebenarnya mencerminkan pemahaman model terhadap "hukum dunia nyata", bukan sekadar pencocokan tingkat piksel.
Bagi pemula, ini berarti video yang dihasilkan Omni lebih jarang mengalami cacat video AI yang umum seperti "objek berpindah secara instan", "cahaya yang kacau", atau "jari tangan yang berlebih".
3. Pengeditan Iteratif Berbasis Percakapan
Omni mendukung "hasilkan dulu, lalu ubah menggunakan bahasa alami". Setelah model menghasilkan video, Anda bisa berkata, "Ubah latar belakangnya menjadi suasana senja" atau "Buat gerakan kameranya lebih lambat". Model akan melakukan penyesuaian parsial sambil tetap menjaga konsistensi karakter, adegan, dan gerakan.
Cara interaksi ini lebih mirip seperti berbicara dengan seorang editor video, daripada menulis petunjuk panjang sekaligus. Ini sangat ramah bagi pemula yang belum memiliki pengalaman dalam teknik petunjuk.
4. Avatar Digital yang Dapat Disesuaikan
Omni memungkinkan pengguna membuat avatar digital mereka sendiri melalui verifikasi biometrik, lalu menyematkan avatar tersebut ke dalam video yang dihasilkan. Google menekankan bahwa langkah ini harus diselesaikan oleh orang yang bersangkutan melalui verifikasi biometrik untuk mengurangi risiko penyalahgunaan wajah.
🎯 Ringkasan Kemampuan: Kunci dari Omni bukanlah "resolusi lebih tinggi" atau "durasi lebih panjang", melainkan tiga serangkai "penalaran multimodal + pengetahuan fisika + pengeditan percakapan". Untuk menerapkan kemampuan ini ke dalam produk Anda, kami menyarankan untuk menguji efek kombinasi model yang berbeda melalui antarmuka agregasi APIYI apiyi.com sebelum memutuskan solusi utama.
Apa Perbedaan Gemini Omni dan Veo: Dua Nama yang Paling Membingungkan bagi Pemula
Banyak pemula bertanya: Bukankah Google sudah memiliki Veo? Lalu untuk apa Omni? Ini adalah pertanyaan yang sangat wajar, karena keduanya "dapat menghasilkan video", tetapi posisinya benar-benar berbeda. Tabel di bawah ini adalah cara tercepat bagi pemula untuk memahami hubungan keduanya.
| Dimensi Perbandingan | Veo | Gemini Omni |
|---|---|---|
| Tipe Model | Model media khusus | Model terpadu penalaran multimodal + pembuatan media |
| Dukungan Input | Teks, gambar | Teks + gambar + audio + video (kombinasi apa pun) |
| Kedalaman Penalaran | Terutama pada tingkat rendering | Menggunakan penalaran Gemini, penyatuan semantik multimodal |
| Metode Pengeditan | Terutama pembuatan ulang | Mendukung pengeditan inkremental berbasis percakapan |
| Pemahaman Fisika | Biasa | Ditingkatkan secara signifikan (ditekankan dalam demo resmi) |
| Target Pengguna | Kreator video profesional | Kreator + konsumen umum + pengembang |
| Posisi Saat Ini | Alat pembuatan video berkualitas tinggi | Model dasar "create anything" multimodal |
Analogi sederhana: Veo seperti printer fidelitas tinggi; Anda memberinya gambar, ia mencetak hasil yang indah. Sedangkan Omni lebih seperti asisten serba bisa yang memahami niat Anda; Anda cukup memberikan beberapa materi dan satu kalimat permintaan, ia bisa menghasilkan video jadi. Keduanya kemungkinan besar akan hidup berdampingan di masa depan, tetapi Omni mewakili rute "multimodal terpadu" yang dipertaruhkan oleh Google.

🧭 Saran Pilihan bagi Pemula: Jika Anda hanya ingin menghasilkan film pendek yang indah, Veo masih cukup. Jika Anda ingin melakukan skenario aplikasi "input campuran teks, gambar, audio, dan video", Omni adalah arah yang lebih tepat. Untuk membandingkan kinerja aktual kedua jenis model ini dengan cepat, disarankan untuk melakukan pengujian A/B melalui antarmuka seperti APIYI apiyi.com yang mendukung peralihan antar model, sehingga Anda dapat mengganti model dalam rangkaian kode yang sama tanpa mengubah alur kerja.
Panduan Memulai Gemini Omni Flash untuk Pemula
Sejak dirilis, Gemini Omni Flash telah dibuka untuk berbagai kalangan, namun melalui saluran yang berbeda-beda. Tabel perbandingan di bawah ini dapat membantu Anda sebagai pemula untuk menentukan "dari mana saya harus mulai".
| Tipe Pengguna | Saluran yang Direkomendasikan | Berbayar? | Catatan |
|---|---|---|---|
| Konsumen Umum | Aplikasi Gemini | Perlu berlangganan Google AI Plus/Pro/Ultra | Kreativitas pribadi, pembuatan video pendek |
| Kreator Konten | Google Flow | Perlu berlangganan paket Google AI | Alur kerja kreatif profesional |
| Pengguna Video Pendek | YouTube Shorts, YouTube Create App | Gratis | Uji coba gratis terbatas, saluran masuk utama |
| Pengembang / Perusahaan | Google API (segera hadir) | Harga belum diumumkan | Akan dibuka dalam beberapa minggu |
| Evaluator Multi-model | Platform API agregator pihak ketiga | Tergantung harga platform | Cocok untuk tim R&D yang membandingkan banyak model |
Jalur Memulai Paling Mudah bagi Pemula
- Jika Anda belum pernah menggunakan alat AI berbayar, disarankan untuk mencoba pembuatan video Omni gratis di YouTube Shorts atau aplikasi YouTube Create. Ini adalah pintu masuk dengan hambatan terendah.
- Jika Anda sudah berlangganan Google AI Plus atau paket yang lebih tinggi, buka langsung aplikasi Gemini. Anda akan melihat pintu masuk pembuatan video Omni di panel kreasi.
- Jika Anda seorang pengembang, langkah paling pragmatis saat ini adalah mencoba efeknya di sisi konsumen sambil menunggu API resmi dirilis. Anda juga bisa menggunakan APIYI (apiyi.com) untuk memanggil model Gemini lain yang sudah tersedia guna menyiapkan alur pemanggilan multimodal Anda sejak dini.
Ide Pemanggilan Paling Sederhana (Setelah API Resmi Tersedia)
Meskipun API pengembang resmi untuk Omni masih dalam tahap "akan diluncurkan dalam beberapa minggu", kita bisa merancang struktur pemanggilan terlebih dahulu agar siap digunakan saat antarmuka sudah dibuka.
# Contoh pemanggilan agregasi multi-model (struktur ilustrasi, ganti model setelah API resmi Omni tersedia)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Akses terpadu ke berbagai model melalui APIYI
)
# Saat ini dapat langsung memanggil model seri Gemini yang sudah terbuka
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "Jelaskan nilai inti dari model multimodal dalam satu kalimat"}]
)
print(response.choices[0].message.content)
💡 Saran Memulai Cepat: Pemula tidak perlu menunggu semua API resmi terbuka. Gunakan APIYI (apiyi.com) untuk membangun alur kerja dengan model Gemini lainnya terlebih dahulu. Setelah API Omni resmi diluncurkan, Anda hanya perlu mengganti nama model dengan biaya migrasi yang hampir nol.
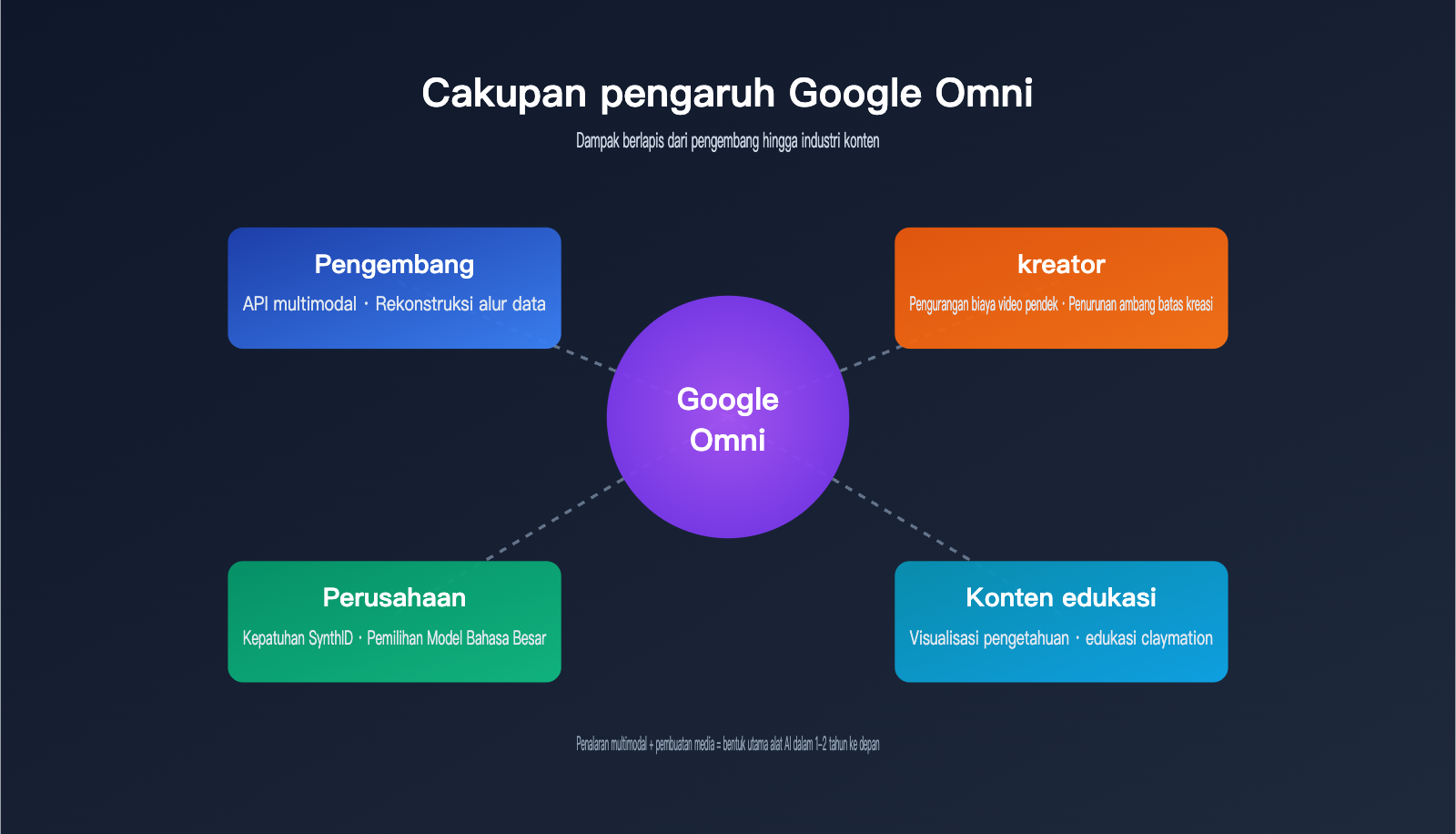
Dampak Google Omni bagi Pengembang dan Industri
Banyak pemula yang bertanya: Apa arti model baru ini bagi saya? Jawabannya berbeda bagi pengembang, kreator, dan perusahaan.
Dampak bagi Pengembang
| Arah Dampak | Perwujudan Spesifik |
|---|---|
| Cara Pemanggilan | Desain petunjuk multimodal menggantikan alur "t2i lalu i2v" |
| Rantai Alat | SDK perlu beradaptasi dengan "aliran input video/audio" bukan sekadar teks |
| Kepatuhan Konten | Tanda air SynthID menjadi persyaratan standar, perlu perencanaan deteksi dan tampilan |
| Struktur Biaya | Biaya per generasi mungkin lebih tinggi daripada pemanggilan teks murni, perlu manajemen penggunaan yang cermat |
Bagi insinyur yang sedang membangun aplikasi AI, Omni memberikan sinyal yang jelas: antarmuka AI masa depan bukan lagi "teks masuk, teks keluar", melainkan "multimodal masuk, multimodal keluar". Membangun ulang jalur data dan mengelola aset berdasarkan modalitas akan memberi Anda keunggulan saat API Omni resmi dibuka.
Dampak bagi Industri Konten
Platform video pendek, agensi iklan, dan produsen konten pendidikan akan menjadi yang pertama diuntungkan. Video berkualitas tinggi berdurasi 10 detik yang biasanya membutuhkan waktu berjam-jam untuk diedit, kini dapat menghasilkan draf awal yang layak dalam hitungan menit melalui Omni Flash. Bagi kreator long-tail, hambatan "dari satu gambar menjadi satu video utuh" telah diturunkan secara signifikan.
Namun, perlu dicatat bahwa penyematan tanda air SynthID secara paksa berarti "generasi AI" akan menjadi semakin transparan. Platform, pemilik merek, dan regulator mungkin akan menyesuaikan strategi pelabelan dan audit konten berdasarkan tanda air ini.
Dampak bagi Pengguna Perusahaan
Pengguna perusahaan paling peduli dengan dua hal: kepatuhan/keamanan merek dan biaya skala besar. Tanda air SynthID menyelesaikan separuh masalah pertama, sementara masalah kedua bergantung pada harga API yang akan diumumkan Google nantinya. Bagi tim yang sensitif terhadap anggaran, strategi yang lebih aman adalah menggunakan platform agregator seperti APIYI (apiyi.com) untuk mengevaluasi kemampuan video atau multimodal dari berbagai vendor seperti Gemini, GPT, dan Claude secara bersamaan, lalu memilih berdasarkan biaya dan kualitas.
Pertanyaan Umum
Q1: Apakah Google Omni dan Gemini Omni adalah hal yang sama?
Ya. Google Omni adalah singkatan tidak resmi, sedangkan nama lengkap yang digunakan secara resmi oleh Google adalah "Gemini Omni", yang merupakan bagian dari cabang multimodal dalam keluarga model Gemini. Gemini Omni Flash adalah model pertama yang dirilis dari keluarga ini. Kedua nama tersebut merujuk pada jenis teknologi yang sama.
Q2: Bisakah pengguna baru mencoba Gemini Omni secara gratis sekarang?
Bisa. Cara paling langsung adalah dengan menggunakan fitur pembuatan video Omni di YouTube Shorts atau aplikasi YouTube Create, yang saat ini dibuka gratis untuk para kreator. Jika Anda ingin menggunakannya di aplikasi Gemini, Anda memerlukan langganan Google AI Plus, Pro, atau Ultra.
Q3: Mengapa durasi video tunggal Gemini Omni hanya 10 detik?
Ini adalah batasan pada tahap penerapan, bukan batas kemampuan model itu sendiri. Penjelasan resminya adalah "pada tahap keterbatasan daya komputasi, kemampuan ini dibuka terlebih dahulu agar bisa diakses oleh lebih banyak pengguna". Nantinya, model seperti Omni Pro akan memperpanjang durasi video secara bertahap.
Q4: Apakah tanda air SynthID akan memengaruhi kualitas video atau penggunaan komersial?
Tidak. SynthID adalah tanda air tak terlihat yang tidak dapat dideteksi oleh mata manusia dan tidak akan memengaruhi kualitas gambar. Fungsinya adalah agar platform dan alat dapat mengidentifikasi bahwa "video ini dibuat oleh AI" selama proses distribusi konten. Penggunaan komersial harus mengikuti ketentuan layanan Google.
Q5: Apa yang harus dipersiapkan oleh pengembang sekarang?
Pertama, pahami logika desain petunjuk multimodal, bukan hanya menulis petunjuk berbasis teks. Kedua, rapikan pustaka aset Anda dan klasifikasikan berdasarkan modalitas. Ketiga, jalankan alur pemanggilan model lebih awal. Kami merekomendasikan penggunaan APIYI (apiyi.com) untuk memanggil model seri Gemini yang ada melalui antarmuka terpadu, sehingga Anda dapat beralih dengan mulus saat API Omni resmi diluncurkan.
Q6: Apakah Gemini Omni akan menggantikan Veo?
Dalam jangka pendek, tidak. Veo tetap menjadi representasi pembuatan video khusus berkualitas tinggi, sementara Omni mewakili arah terpadu dari "penalaran multimodal + pembuatan media". Keduanya kemungkinan besar akan hidup berdampingan dalam skenario yang berbeda.
Kesimpulan: Tiga Hal yang Harus Diingat Pengguna Baru
Pertama, esensi dari Gemini Omni adalah model terpadu untuk "penalaran lintas modal + pembuatan media", bukan sekadar "satu lagi AI video". Kemampuan pembedanya terletak pada tiga dimensi: pemahaman fisik, penyuntingan berbasis percakapan, dan penalaran lintas modal.
Kedua, jalur tercepat bagi pengguna baru untuk mencobanya adalah melalui akses gratis di YouTube Shorts atau aplikasi YouTube Create, baru kemudian melalui saluran langganan aplikasi Gemini. API untuk pengembang saat ini sedang dalam tahap "peluncuran dalam beberapa minggu ke depan", jadi Anda bisa mulai merencanakan arsitekturnya sekarang.
Ketiga, Omni tidak akan langsung menggantikan alat yang sudah Anda kenal, tetapi ia mewakili bentuk utama AI multimodal dalam 1-2 tahun ke depan. Memahami cara input-output-nya, persyaratan kepatuhan SynthID, serta perbedaan posisinya dengan Veo sejak dini akan membantu Anda menghindari hambatan dalam peningkatan alat AI berikutnya. Jika Anda ingin memanggil model utama seperti Gemini, GPT, dan Claude dalam satu antarmuka, APIYI (apiyi.com) adalah solusi paling praktis saat ini, dan Anda juga bisa langsung mengakses API Gemini Omni begitu resmi dirilis.
Referensi
-
Blog Resmi Google – Pengumuman Rilis Gemini Omni
- Tautan:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - Penjelasan: Pengenalan otoritatif dari Google mengenai posisi dan kemampuan Gemini Omni.
- Tautan:
-
TechCrunch – Laporan Mendalam Gemini Omni
- Tautan:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - Penjelasan: Mengutip pernyataan kunci dari Sundar Pichai dan Nicole Brichtova.
- Tautan:
-
9to5Google – Laporan Pengalaman Gemini Omni Flash
- Tautan:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - Penjelasan: Berisi deskripsi demo resmi dan ketersediaan akses saluran.
- Tautan:
Tim APIYI | Untuk mengikuti perkembangan terbaru seputar Model Bahasa Besar dan panduan praktis, kunjungi APIYI di apiyi.com untuk mendapatkan kuota uji coba gratis dan mencoba antarmuka terpadu untuk berbagai model utama, termasuk seri Gemini.