
Le 7 avril 2026, au petit matin, un nom inconnu de tous a fait une entrée fracassante dans le classement Video Arena d'Artificial Analysis : HappyHorse-1.0. Il a décroché la première place dans trois des quatre classements principaux et la deuxième dans le quatrième, reléguant le précédent "roi" du secteur, Seedance 2.0 de ByteDance, à 60 points Elo derrière lui. Pourtant, en moins de 72 heures, le modèle a disparu du classement, et aucune équipe n'a revendiqué sa paternité à ce jour. Voici une analyse rapide de l'impact de cet événement sur le domaine de la génération de vidéo par IA.
Valeur ajoutée : 3 minutes pour comprendre les informations clés, les percées techniques, les hypothèses sur l'origine de HappyHorse-1.0 et ce qu'il signifie pour le marché actuel de la génération de vidéo par IA.

Aperçu des informations clés sur HappyHorse-1.0
HappyHorse-1.0 est un modèle de génération de vidéo qui a fait son apparition sur la Video Arena d'Artificial Analysis via une "soumission pseudonyme". Sans GitHub public, sans poids HuggingFace officiels et sans API accessible, ses performances sur les quatre classements principaux ont littéralement écrasé tous les modèles publics, y compris Seedance 2.0 de ByteDance, Veo de Google et Sora d'OpenAI.
| Élément | Détails |
|---|---|
| Nom du modèle | HappyHorse-1.0 (incluant la variante V2) |
| Date d'apparition | 7 avril 2026, au petit matin |
| Plateforme de classement | Artificial Analysis Video Arena |
| Mode de soumission | Pseudonyme |
| Taille du modèle | Environ 15B de paramètres |
| Architecture | Transformer à attention unique (Self-Attention) à 40 couches |
| Modalités combinées | Pré-entraînement combiné texte / vidéo / audio |
| État public | ❌ Pas de code source · Pas de poids · Pas d'API |
| Origine supposée | Alibaba Tongyi Lab (Wan 2.7 ?) |
| État actuel | Disparu du classement |
💡 Pour comprendre rapidement : HappyHorse-1.0 n'est pas un "produit", mais un "test de capacités anonyme". Ce paradigme de publication — tester anonymement dans un classement avant de révéler son identité — est apparu à plusieurs reprises l'année dernière sur LMArena, Image Arena et Code Arena, et cache presque toujours un acteur majeur du secteur. Si vous souhaitez comparer les modèles de génération de vidéo actuellement disponibles, vous pouvez accéder rapidement aux principaux candidats via la plateforme APIYI (apiyi.com).
Résultats de HappyHorse-1.0 dans le classement Arena
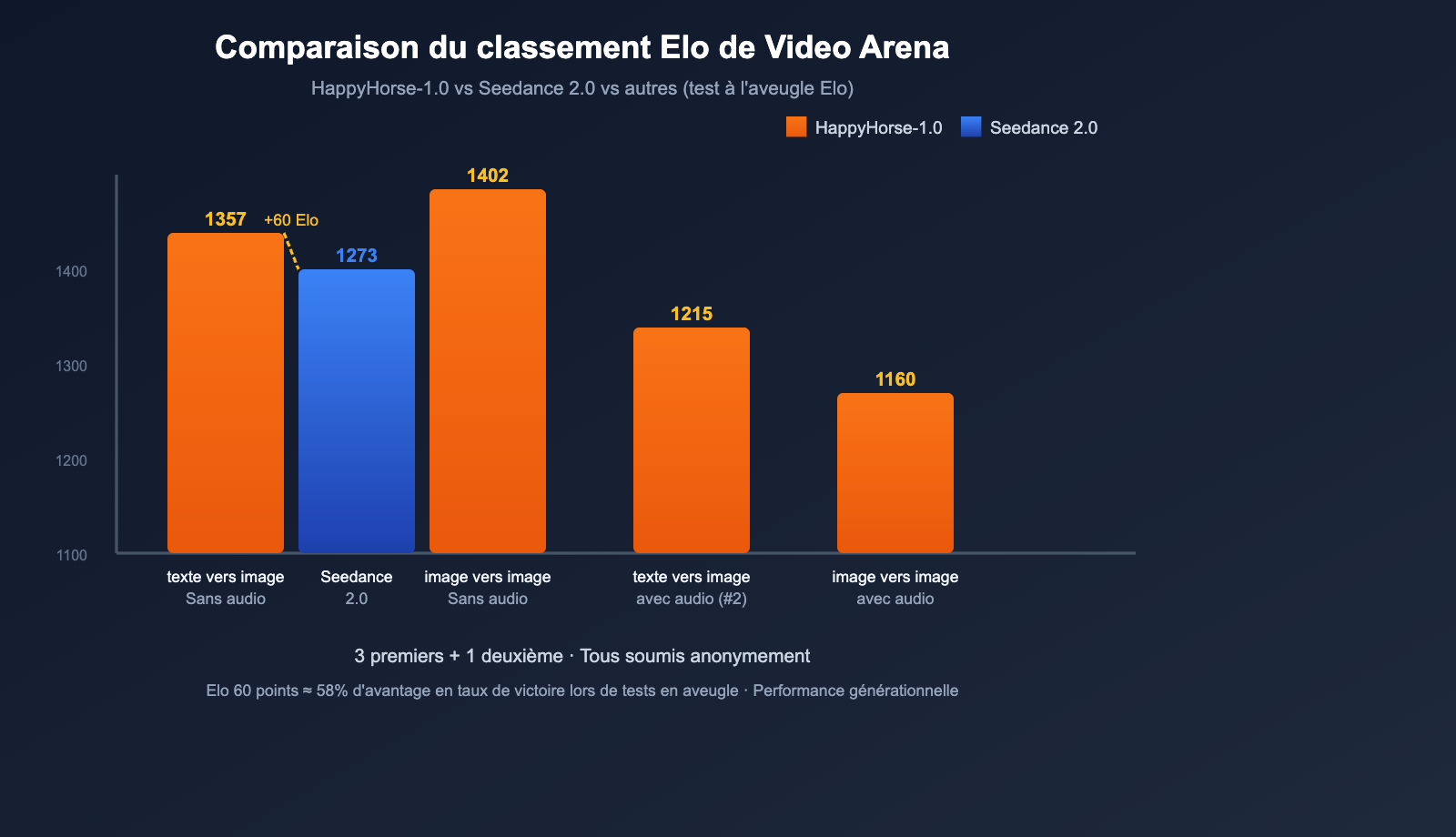
Artificial Analysis est actuellement l'un des classements en aveugle les plus fiables dans le domaine de la génération de vidéo par IA. Il utilise un système de score Elo + votes à l'aveugle des utilisateurs, ce qui évite les biais des constructeurs. Voici les résultats de HappyHorse-1.0 lors de son entrée au classement le 7 avril :
| Catégorie | Elo HappyHorse-1.0 | Rang | Précédent leader |
|---|---|---|---|
| Texte vers vidéo (sans audio) | 1333-1357 | 🥇 #1 | Seedance 2.0 (1273) |
| Image vers vidéo (sans audio) | 1392-1402 | 🥇 #1 | — |
| Texte vers vidéo (avec audio) | 1205-1215 | 🥈 #2 | — |
| Image vers vidéo (avec audio) | 1160 | 🥇 #1 | — |
Le résultat le plus impressionnant concerne la catégorie Texte vers vidéo sans audio : dès son arrivée, HappyHorse-1.0 surpasse le leader précédent, Seedance 2.0 de ByteDance, de 60 points Elo. Dans le système de score Elo, 60 points représentent un avantage de victoire d'environ 58 %, ce qui constitue un écart technologique majeur.
Hypothèses sur l'architecture technique de HappyHorse-1.0
Bien qu'il n'y ait pas de papier de recherche officiel, la page de présentation de HappyHorse-1.0 et des analyses tierces comme celles de WaveSpeedAI ont révélé de nombreux détails architecturaux. Si ces informations sont exactes, il s'agirait de la première réalisation par la communauté open source d'un "pré-entraînement conjoint audio-vidéo de bout en bout".
Transformer unifié à flux unique
HappyHorse-1.0 utilise un Transformer à 40 couches avec Self-Attention, qui regroupe les jetons de texte, les latents de l'image de référence, les jetons de vidéo bruitée et les jetons d'audio bruité dans une même séquence pour un débruitage conjoint. Cela diffère radicalement de l'approche actuelle "double tour + Cross-Attention" (utilisée par Sora ou Seedance) :
- 4 couches au début et à la fin : utilisent des projections spécifiques aux modalités pour traiter les entrées et sorties.
- 32 couches intermédiaires : les paramètres sont entièrement partagés, traitant toutes les modalités de manière égale.
- Pas de Cross-Attention : toutes les modalités interagissent au sein du même mécanisme d'attention.
Cette approche de "flux unique avec Self-Attention complète" est le paradigme que GPT-4o et Gemini 2.x explorent pour le multimodal, mais c'est la première fois qu'elle apparaît dans le domaine de la génération vidéo sous une forme "open source avec des performances de pointe".
Génération conjointe audio-vidéo
HappyHorse-1.0 affirme prendre en charge la génération simultanée en une seule inférence de la vidéo, des dialogues, des sons d'ambiance et des effets sonores Foley, tout en couvrant 6 langues (chinois, anglais, japonais, coréen, allemand, français). Des sites secondaires mentionnent également le cantonais et une "synchronisation labiale avec un taux d'erreur (WER) ultra-faible".
Si ces indicateurs sont confirmés, l'avance de HappyHorse-1.0 en matière de "pré-entraînement audio-vidéo de bout en bout" pourrait être encore plus marquée que ce que suggère le classement.
Vitesse d'inférence
| Configuration | Temps |
|---|---|
| Vidéo 5s 256p | ~2 secondes |
| Vidéo 5s 1080p (H100) | ~38 secondes |
Si ces chiffres sont réels, cette vitesse est particulièrement ambitieuse pour un modèle vidéo de 15 milliards de paramètres, se rapprochant des limites de la génération en temps réel.
title: "Hypothèses sur l'origine de HappyHorse-1.0"
description: "Analyse des spéculations autour du mystérieux modèle HappyHorse-1.0, ses origines probables et sa disparition soudaine des classements."
Hypothèses sur l'origine de HappyHorse-1.0
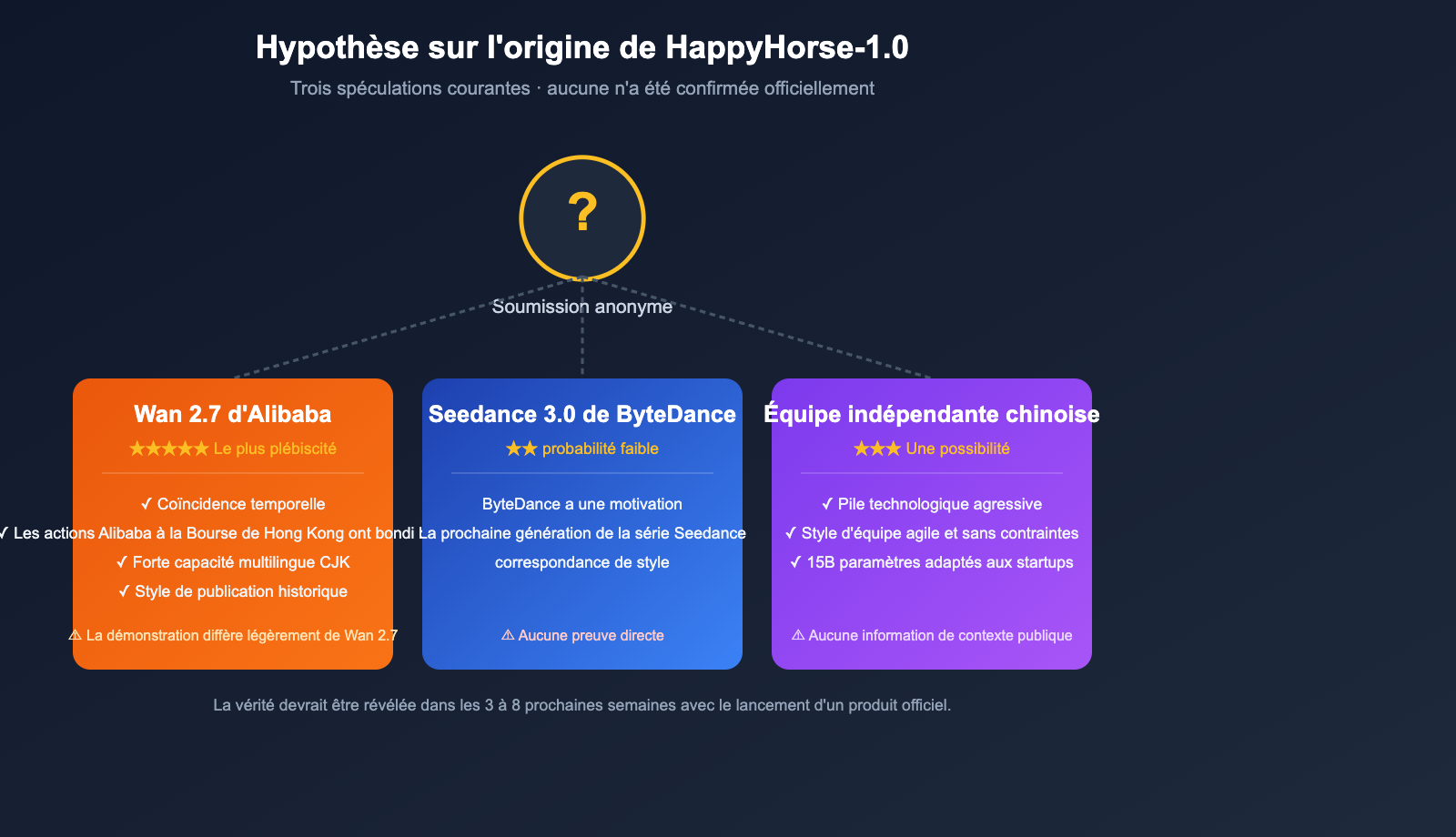
La soumission anonyme signifie qu'Artificial Analysis ne pouvait utiliser qu'un pseudonyme pour décrire ce modèle lors de sa publication. Cependant, la communauté a réussi à dégager quelques hypothèses majeures à partir des indices récoltés.
Hypothèse 1 : Alibaba Tongyi Lab (Wan 2.7)
C'est l'hypothèse la plus populaire au sein de la communauté, pour quatre raisons :
- Coïncidence temporelle : Après la montée en puissance de HappyHorse-1.0 le 7 avril, Alibaba Tongyi Lab a publié Wan 2.6 début avril, et l'industrie s'attendait largement à l'arrivée imminente du Wan 2.7.
- Réaction des marchés financiers : L'action d'Alibaba à la bourse de Hong Kong a grimpé de près de 8 % après l'apparition de HappyHorse, le marché faisant clairement le lien entre les deux.
- Capacités multilingues CJK : Le modèle présente une excellente prise en charge du chinois, du japonais et du coréen, une caractéristique typique des équipes sinophones ou est-asiatiques.
- Style de publication anonyme : Alibaba a déjà utilisé par le passé, pour les séries Qwen / Wan, une stratégie de "lancement restreint suivi d'une annonce officielle".
Cependant, rien n'a été officiellement confirmé et les performances du Wan 2.7, officiellement publié par Alibaba en avril, ne correspondent pas exactement à certaines démonstrations publiques de HappyHorse. Cette hypothèse reste donc à vérifier.
Hypothèse 2 : ByteDance / Autres géants de la tech
Certains pensent que HappyHorse pourrait être une variante de nouvelle génération de la série Seedance de ByteDance, car il a surpassé Seedance 2.0. ByteDance aurait pu avoir intérêt à tester Seedance 3.0 de manière anonyme. Mais aucune preuve ne vient étayer cette théorie pour le moment.
Hypothèse 3 : Une nouvelle équipe indépendante sinophone
D'autres imaginent que HappyHorse provient d'une toute nouvelle startup sinophone, encore inconnue du grand public. La pile technologique présentée — "15B + Self-Attention complet + multimodalité audio-vidéo" — est très audacieuse, ce qui ressemble davantage au travail d'une petite équipe agile, sans contraintes héritées.
🎯 Gardons la tête froide : Tant qu'aucune annonce officielle n'est faite, toutes les théories ("c'est Alibaba", "c'est ByteDance", "c'est une licorne") ne sont que des spéculations. Ce qui compte, ce n'est pas "qui est derrière", mais "quel est le plafond de performance atteint" et quels modèles vidéo ouverts nous pouvons utiliser dès maintenant pour nos applications. Si vous avez besoin d'intégrer rapidement les principaux modèles vidéo pour valider vos produits, vous pouvez utiliser le service proxy API d'APIYI (apiyi.com) pour invoquer facilement plusieurs modèles disponibles.
Les 72 heures mystérieuses de la disparition de HappyHorse-1.0
Le plus dramatique reste la "disparition" de HappyHorse-1.0. Moins de 72 heures après avoir atteint le sommet du classement d'Artificial Analysis le 7 avril, le modèle a été soudainement retiré, ne laissant derrière lui que :
- Quelques captures d'écran circulant sur les réseaux sociaux.
- Une page de destination officielle cryptique (annonçant "GitHub / HuggingFace bientôt disponibles", mais avec des liens inactifs).
- Une note officielle d'Artificial Analysis confirmant le "retrait".
Ce scénario de "classement suivi d'une disparition" s'est déjà produit plusieurs fois sur LMArena : les premières versions anonymes de GPT-4 Turbo, l'aperçu de Claude 3.5 Sonnet ou les variantes précoces de Gemini 2.0 Flash ont suivi un processus similaire. Presque à chaque fois qu'un modèle anonyme disparaît, un lancement officiel a lieu dans les 3 à 8 semaines suivantes.
L'interprétation de l'industrie est unanime : une équipe de premier plan collecte des données de préférences réelles auprès des utilisateurs pour préparer son lancement officiel.
L'impact de HappyHorse-1.0 sur l'industrie de la génération de vidéo par IA

Même sans sortie publique officielle, HappyHorse-1.0 a déjà eu un impact concret sur tout le secteur de la génération de vidéo par IA.
Impact sur les leaders du marché
- La "zone de confort" de Seedance 2.0, Veo 3 et Sora 2 est brisée : Un écart de 60 points Elo démontre que le plafond de performance pour la génération vidéo est encore loin d'être atteint.
- La génération conjointe audio-vidéo devient le nouveau champ de bataille : HappyHorse a raflé la première place dans 3 catégories sur 4, avec une avance marquée sur la partie audio. Cela forcera tous les leaders à accélérer leurs travaux sur le pré-entraînement audio-vidéo.
- Pression sur l'open source / semi-open source : HappyHorse prône le "Everything is open" (bien que rien ne soit encore réellement ouvert), ce qui accroît la pression sur les produits fermés comme Sora.
Impact sur les développeurs et créateurs
- Les attentes en matière de capacités sont revues à la hausse : Avec du 1080p / H100 / 38 secondes, ce rapport coût-performance rend la "génération vidéo en temps réel" beaucoup moins futuriste.
- Multilinguisme + synchronisation labiale : La génération audio-vidéo de bout en bout en 6 langues (chinois, anglais, japonais, coréen, allemand, français) est une aubaine pour les mini-séries, la publicité et les vidéos éducatives.
- Rester pragmatique : En attendant une véritable ouverture de HappyHorse, continuer à maîtriser les modèles déjà disponibles comme Veo 3, Sora 2, Kling 2 ou Wan 2.6 reste la meilleure stratégie pour construire des produits concrets. Vous pouvez les intégrer facilement via APIYI (apiyi.com).
Impact sur les équipes IA chinoises
Si HappyHorse s'avère être le fruit du travail d'Alibaba ou d'une autre équipe chinoise, ce serait la première fois qu'un modèle de génération vidéo chinois décroche trois premières places sur un classement "neutre" comme celui d'Artificial Analysis. Cette portée dépasse largement le cadre du modèle lui-même.
FAQ sur HappyHorse-1.0
Q1 : HappyHorse-1.0 est-il utilisable dès maintenant ?
Non. Il n'est apparu que brièvement pendant environ 72 heures dans l'arène de test en aveugle d'Artificial Analysis. Il n'y a pas d'API publique, pas de poids téléchargeables et pas de dépôt GitHub accessible. Si vous avez besoin d'appeler des modèles de génération vidéo de premier plan immédiatement, vous pouvez passer par APIYI (apiyi.com) pour accéder aux modèles actuels comme Veo 3, Sora 2, Kling 2 ou Wan 2.6.
Q2 : HappyHorse-1.0 est-il vraiment le Wan 2.7 d’Alibaba ?
Il n'y a pas de confirmation officielle pour le moment. La communauté avance quatre arguments (coïncidence temporelle, hausse des actions d'Alibaba à la bourse de Hong Kong, capacités multilingues CJK, historique de publication d'Alibaba). Cependant, les démonstrations de Wan 2.7 après sa sortie officielle en avril ne correspondent pas exactement à HappyHorse. La réponse prudente est donc : probabilité élevée, mais non confirmé.
Q3 : Que signifie réellement cette avance de 60 points Elo ?
Dans le système de notation Elo, une avance de 60 points correspond approximativement à un taux de victoire de 58 % lors des tests en aveugle. C'est un écart très significatif, mais qui reste surmontable. À titre de comparaison, au cours de l'année écoulée, les changements de classement entre Sora, Veo, Kling et Seedance se jouaient généralement dans une fourchette de 20 à 40 points. L'entrée fracassante de HappyHorse avec 60 points marque une véritable rupture technologique.
Q4 : À quel point l’architecture « 15B paramètres + flux unique avec Self-Attention totale » est-elle audacieuse ?
Extrêmement audacieuse. Alors que les modèles vidéo actuels utilisent généralement des approches hybrides ("double tour + Cross-Attention" ou "DiT + projection multimodale"), HappyHorse regroupe l'audio, la vidéo et le texte dans un seul Transformer de 40 couches partageant les mêmes paramètres. C'est la même voie technologique explorée par GPT-4o / Gemini 2.x pour le multimodal, mais c'est une première en termes de performances de haut niveau pour la génération vidéo.
Q5 : Pourquoi a-t-il disparu après 72 heures de classement ?
C'est un "mode de collecte de données" courant pour les modèles anonymes. Les premières versions de GPT-4 Turbo sur LMArena, l'aperçu de Claude 3.5 Sonnet ou les variantes précoces de Gemini 2.0 Flash ont suivi le même processus : mise en ligne → collecte de données de préférences réelles → retrait → sortie officielle quelques semaines plus tard. On s'attend à ce que HappyHorse revienne sous un nom officiel d'ici 3 à 8 semaines.
Q6 : Quels modèles vidéo puis-je utiliser pour remplacer HappyHorse actuellement ?
Parmi les modèles déjà ouverts et les plus performants, on trouve : Google Veo 3 (qualité générale de premier plan), OpenAI Sora 2 (maîtrise du langage cinématographique), Kling 2 (excellent pour les visages et les mouvements), ByteDance Seedance 2.0 (très fort sur les contextes chinois) et Alibaba Wan 2.6 (open source et facile à déployer). Si vous avez besoin d'une interface unifiée pour comparer ces modèles, vous pouvez passer par la plateforme APIYI (apiyi.com) pour tout centraliser sans avoir à jongler entre plusieurs comptes.
Résumé
HappyHorse-1.0 est sans doute l'arrivée "anonyme" la plus spectaculaire dans le domaine de la génération de vidéo par IA en avril 2026. Elle marque trois tournants majeurs :
- Le plafond de performance de la génération vidéo est repoussé : Avec 60 points d'avance au classement Elo et 3 victoires pour 1 seconde place sur 4 catégories, il est clair que nous sommes encore loin des limites des "meilleurs modèles vidéo" actuels.
- La génération conjointe audio-vidéo devient le nouveau champ de bataille : La domination de HappyHorse sur les épreuves incluant de l'audio va pousser l'ensemble de l'industrie à accélérer le pré-entraînement audio-vidéo de bout en bout.
- Le cycle "Anonymat → Retrait → Lancement officiel" devient la norme pour les modèles phares : On s'attend à ce qu'un acteur bien connu du marché revendique officiellement ce modèle d'ici 3 à 8 semaines.
🚀 Conseil pratique : En attendant que HappyHorse soit réellement accessible, la démarche la plus pragmatique n'est pas de spéculer sur ses origines, mais de maîtriser les meilleurs modèles vidéo déjà disponibles. Veo 3, Sora 2, Kling 2, Seedance 2.0 et Wan 2.6 couvrent déjà 90 % des besoins de production réels. Nous vous recommandons d'utiliser APIYI (apiyi.com) pour accéder aux principaux modèles vidéo via une interface unique, avec une facturation à l'usage et une flexibilité totale. Vous pourrez ainsi migrer en toute transparence dès que HappyHorse ou Wan 2.7 seront officiellement ouverts.
Auteur : L'équipe APIYI — Spécialisée dans l'accès stable aux principaux grands modèles de langage pour les développeurs. Visitez apiyi.com pour en savoir plus.
Références
-
Blog WaveSpeedAI – Qu'est-ce que HappyHorse-1.0
- Lien :
wavespeed.ai/blog/posts/what-is-happyhorse-1-0-ai-video-model - Description : Analyse approfondie par un tiers de l'architecture, des paramètres et de la vitesse d'inférence.
- Lien :
-
Artificial Analysis – Classement Video Arena
- Lien :
artificialanalysis.ai/video/leaderboard/text-to-video - Description : Classements originaux pour le texte vers image et l'image vers vidéo.
- Lien :
-
Phemex News – HappyHorse en tête des classements
- Lien :
phemex.com/news/article/happyhorse10-surpasses-seedance-20-in-ai-video-model-rankings-71750 - Description : Données comparatives entre HappyHorse et Seedance 2.0.
- Lien :
-
36Kr – Le mystérieux modèle HappyHorse
- Lien :
eu.36kr.com/en/p/3757826958635781 - Description : Analyse industrielle sur l'apparition de ce modèle anonyme.
- Lien :
-
Futunn – Hausse des actions Alibaba à Hong Kong suite à HappyHorse
- Lien :
news.futunn.com/en/post/71208943 - Description : Réaction du marché financier face aux spéculations sur l'origine du modèle.
- Lien :
-
DEV Community – Qui a développé HappyHorse
- Lien :
dev.to/calvin_claire_451169e1b82 - Description : Diverses théories de la communauté sur l'équipe de développement.
- Lien :