
« Pourquoi mes requêtes Claude Code consomment-elles systématiquement 400 000 jetons en entrée ? Pourquoi ma facture est-elle si élevée ? » C'est la première réaction de nombreux utilisateurs de Claude Code lorsqu'ils consultent leurs statistiques d'utilisation. En réalité, la majeure partie de ces 400 000 jetons a probablement déjà été traitée via la mise en cache, et le coût réel ne représente peut-être qu'un dixième du chiffre affiché. Cependant, si le cache n'est pas utilisé, la facture peut effectivement devenir douloureuse.
Valeur ajoutée : En lisant cet article, vous comprendrez le mécanisme de mise en cache automatique de Claude Code, les 8 causes fréquentes d'échec de mise en cache, ainsi que 6 astuces pratiques pour réduire vos jetons en entrée de 400 000 à 50 000.
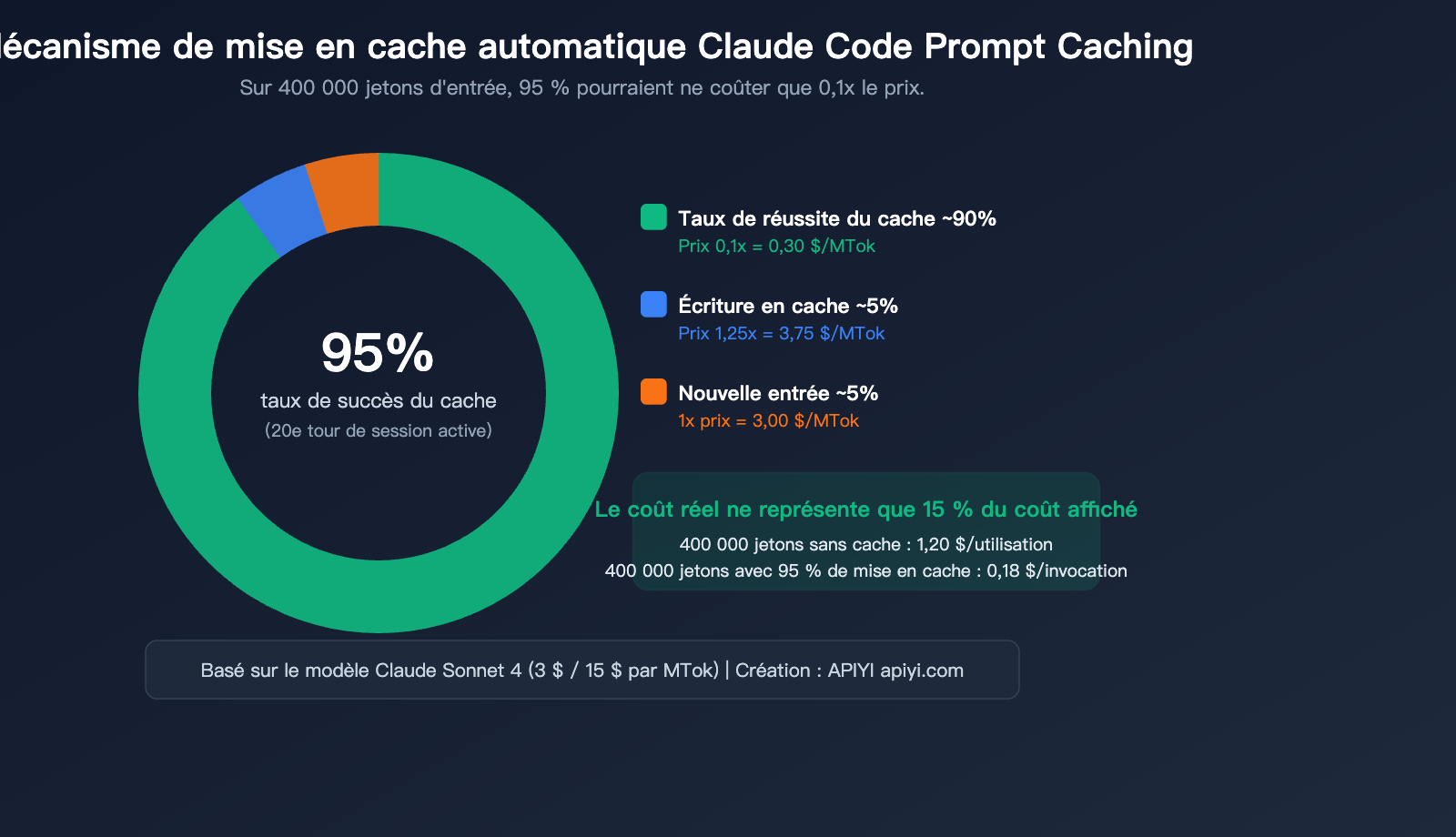
Explication détaillée du mécanisme de mise en cache automatique (Prompt Caching) de Claude Code
Claude Code utilise-t-il automatiquement le cache ?
Oui. Claude Code active automatiquement le Prompt Caching d'Anthropic pour chaque requête API, sans aucune configuration nécessaire. C'est un comportement natif, pas une option.
Chaque fois que vous envoyez un message dans Claude Code, le contenu transmis à l'API est assemblé dans l'ordre suivant :
| Ordre d'assemblage | Contenu | Estimation de taille | Comportement du cache |
|---|---|---|---|
| Niveau 1 | Définitions des outils (Read/Edit/Bash, etc.) | ~5 000 jetons | Quasi statique, taux de réussite élevé |
| Niveau 2 | Invite système + CLAUDE.md | ~3 000-10 000 jetons | Inchangé durant la session, taux élevé |
| Niveau 3 | Historique de la conversation (messages précédents) | Croissance continue | Correspondance de préfixe, accumulation progressive |
| Niveau 4 | Nouveau message actuel | Variable | Jamais mis en cache |
Mécanisme clé : Le cache repose sur la correspondance de préfixe — tant que les N premiers jetons de la requête sont identiques au contenu précédemment mis en cache, ces N jetons seront servis par le cache. Dans une conversation continue, dès le 20e tour, plus de 95 % des jetons d'entrée proviennent généralement du cache.
Prix du cache : pourquoi le taux de réussite est crucial
| Type d'opération | Prix relatif (entrée de base) | Prix réel Sonnet 4 / MTok | Prix réel Opus 4 / MTok |
|---|---|---|---|
| Entrée standard (sans cache) | 1x | 3,00 $ | 15,00 $ |
| Écriture cache 5 min | 1,25x | 3,75 $ | 18,75 $ |
| Écriture cache 1 heure | 2x | 6,00 $ | 30,00 $ |
| Réussite/Lecture cache | 0,1x | 0,30 $ | 1,50 $ |
| Sortie | — | 15,00 $ | 75,00 $ |
Exemple concret : Si votre requête contient 400 000 jetons d'entrée :
Scénario A : Aucune mise en cache
├── 400k jetons × 3 $/MTok (Sonnet) = 1,20 $ par requête
Scénario B : 95 % de réussite au cache (session Claude Code typique)
├── Lecture cache 380k jetons × 0,30 $/MTok = 0,114 $
├── Écriture cache 10k jetons × 3,75 $/MTok = 0,0375 $
├── Nouvelle entrée 10k jetons × 3 $/MTok = 0,03 $
├── Total = 0,18 $ par requête
└── Coût réel réduit à 15 % du coût sans cache
🎯 Conseil technique : L'invocation du modèle via APIYI (apiyi.com) prend également en charge le mécanisme de Prompt Caching, réduisant les coûts d'entrée de 90 % lors des réussites au cache. Si votre projet intègre Claude via API, concevez judicieusement la structure de vos invites pour maximiser le taux de réussite du cache.
TTL du cache : l'avantage caché des utilisateurs Max
| Plan d'abonnement | TTL du cache | Coût d'écriture | Remarques |
|---|---|---|---|
| API Pay-as-you-go | 5 minutes | 1,25x | Le cache expire après 5 min d'inactivité |
| Pro / Team | 5 minutes | 1,25x | Idem |
| Max 5x / 20x | 1 heure | 2x | Écriture plus chère, mais fenêtre 12x plus longue |
Bien que le coût d'écriture soit de 2x pour les utilisateurs Max (contre 1,25x), le TTL d'une heure signifie que votre cache est toujours là après une pause café. Pour les développeurs travaillant par intermittence, cette différence est significative.
Chaque réussite au cache réinitialise le minuteur TTL, donc tant que vous restez actif, le cache n'expire pratiquement jamais.
Cache non utilisé ? 8 causes fréquentes et solutions

La cause fondamentale de l'échec du cache est unique : le préfixe de la requête ne correspond pas au contenu mis en cache. Dans Claude Code, les 8 situations suivantes entraînent une invalidation :
Catégorie 1 : Expiration du TTL
| Cause | Condition de déclenchement | Portée | Solution |
|---|---|---|---|
| 1. Timeout d'inactivité | >5 min sans action (API), >1h (Max) | Tout le cache invalidé | Rester actif ou accepter le coût de reconstruction |
C'est la cause la plus fréquente. Si vous vous absentez plus de 5 minutes (utilisateurs API) ou 1 heure (utilisateurs Max) pendant votre session de codage, la requête suivante déclenchera une reconstruction complète du cache.
Catégorie 2 : Invalidation en cascade due à des changements de contenu
Le cache suit une structure hiérarchique stricte : Définition des outils → Invite système → Historique de la conversation. Une modification au niveau supérieur invalide tout ce qui suit.
| Cause | Condition de déclenchement | Portée | Gravité |
|---|---|---|---|
| 2. Changement de modèle | Commande /model |
Tout le cache (isolé par modèle) | ⚠️ Haute |
| 3. Ajout/suppression d'outils MCP | Installation/désinstallation MCP | Niveau Outils + tout le reste | ⚠️ Haute |
| 4. Bascule Web Search | Activation/désactivation recherche | Niveau Système + tout le reste | ⚠️ Moyenne |
| 5. Modification de CLAUDE.md | Édition du fichier + redémarrage | Niveau Système + tout le reste | ⚠️ Moyenne |
Catégorie 3 : Invalidation par action
| Cause | Condition de déclenchement | Portée | Gravité |
|---|---|---|---|
| 6. Nouvelle conversation | /clear ou nouvelle session |
Tout le cache (historique effacé) | ⚠️ Haute |
| 7. Utilisation de /compact | Compression manuelle de l'historique | Cache de l'historique invalidé | ⚠️ Moyenne |
| 8. Utilisation de /rewind | Annulation de messages précédents | Préfixe de l'historique modifié | ⚠️ Moyenne |
Une limite technique souvent ignorée : la longueur minimale du cache
Si votre invite est inférieure au nombre de jetons suivant, le cache sera silencieusement ignoré sans aucun message d'erreur :
| Modèle | Longueur minimale |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4 096 jetons |
| Claude Sonnet 4.6 | 2 048 jetons |
| Claude Sonnet 4.5 / 4 | 1 024 jetons |
Pour Claude Code, comme la définition des outils + l'invite système dépassent déjà les 5 000 jetons, cette limite n'est pratiquement jamais atteinte. Cependant, si vous construisez votre propre application via API, gardez ce seuil à l'esprit.
💡 Conseil : Si vous développez votre propre application via APIYI (apiyi.com) pour appeler l'API Claude, assurez-vous que la longueur de votre invite système dépasse le seuil minimal de cache du modèle, sinon le cache ne sera jamais activé.
title: "Pourquoi vous voyez 400 000 jetons en entrée : la composition du contexte de Claude Code"
description: "Comprenez la structure des 400 000 jetons de Claude Code : historique, outils et cache."
Pourquoi vous voyez 400 000 jetons en entrée : la composition du contexte de Claude Code
Une fois le mécanisme de mise en cache compris, décortiquons ce qui compose ces fameux "400 000 jetons en entrée" qui vous ont tant surpris.
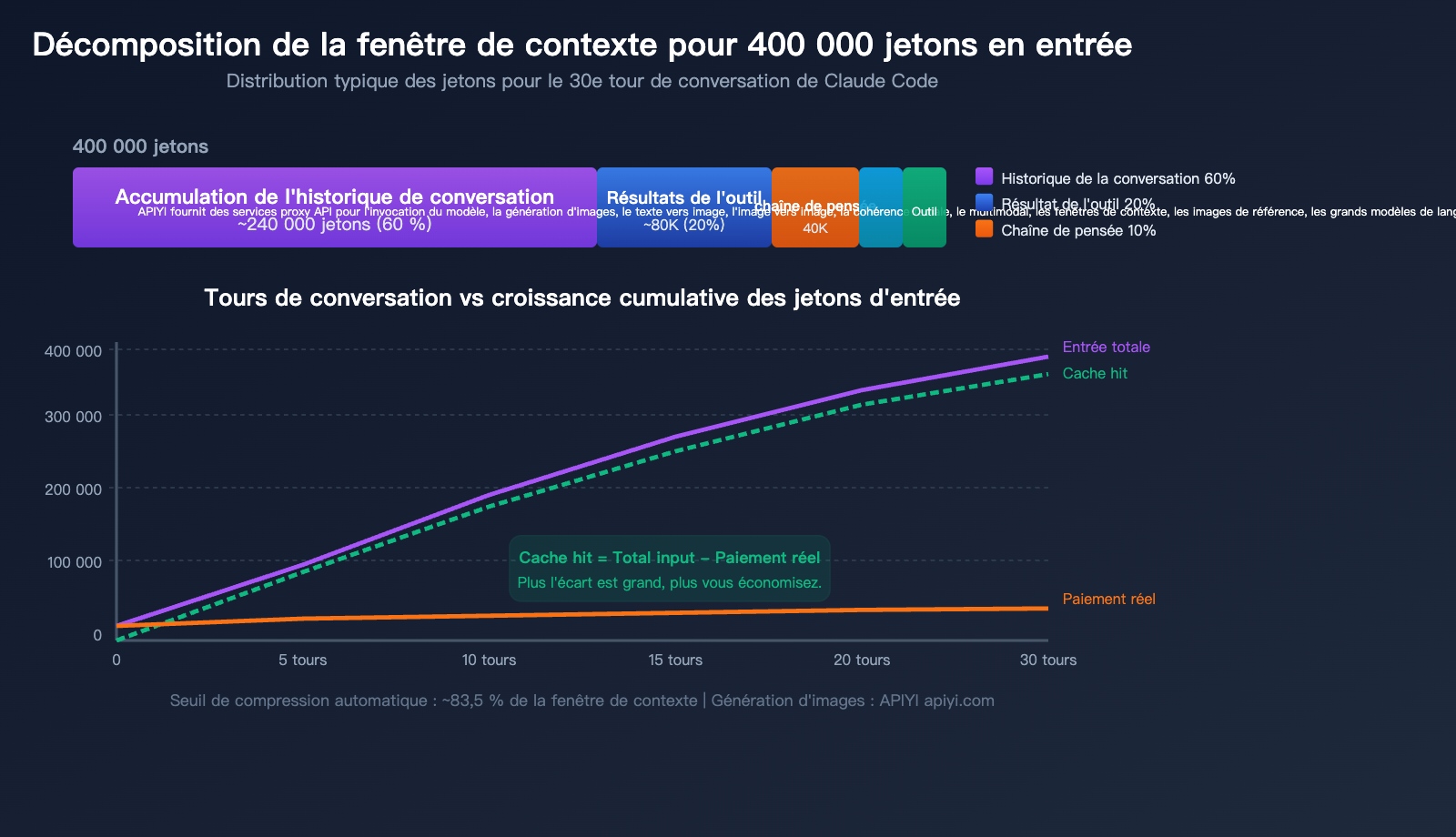
5 sources principales de consommation de jetons
| Source | Proportion | Env. sur 400k | Caractéristiques |
|---|---|---|---|
| Historique cumulé | ~60 % | ~240k | L'historique complet est renvoyé à chaque tour |
| Résultats d'outils | ~20 % | ~80k | Lecture de fichiers, résultats de grep en contexte |
| Chaîne de pensée étendue | ~10 % | ~40k | Les blocs de réflexion des tours précédents deviennent des entrées |
| Invite système + CLAUDE.md | ~5 % | ~20k | Inclus dans chaque message |
| Définition des outils | ~5 % | ~20k | Schéma de tous les outils disponibles |
La vérité fondamentale : plus la conversation est longue, plus l'entrée est grande
Le fonctionnement de Claude Code consiste à renvoyer l'historique complet de la conversation à chaque requête. Cela signifie que :
- 1er tour : ~20 000 jetons en entrée (invite système + définition des outils + votre question)
- 5e tour : ~100 000 jetons en entrée (historique cumulé sur 4 tours)
- 15e tour : ~250 000 jetons en entrée (incluant de nombreux résultats de lecture de fichiers)
- 30e tour : ~400 000+ jetons en entrée (proche du seuil de compression automatique)
Mais attention : la grande majorité de ces entrées sont des succès de cache (cache hits). Sur les 400 000 jetons du 30e tour, seuls 10 000 à 20 000 sont probablement de nouveaux contenus non mis en cache.
Le problème spécifique des grands dépôts de code
Claude Code ne charge pas automatiquement l'intégralité du dépôt de code dans le contexte. Il lit les fichiers à la demande. Cependant, dans les grands dépôts :
- Une recherche
greppeut renvoyer une multitude de résultats, qui entrent tous dans le contexte. - La lecture exploratoire de plusieurs fichiers fait que le contenu de chaque fichier reste dans l'historique de la conversation.
- En mode Agent, l'exécution autonome d'opérations en plusieurs étapes accumule les résultats des appels d'outils à chaque étape.
Si vous atteignez 400 000 jetons par requête, c'est probablement dû à une combinaison des facteurs suivants :
- Le dépôt est volumineux et Claude Code a lu beaucoup de fichiers pour l'analyse.
- Le nombre de tours de conversation est élevé, ce qui alourdit l'historique.
- Vous n'avez peut-être pas utilisé
/compactou/clearassez souvent. - Le fichier
CLAUDE.mdest peut-être trop long.
6 astuces pratiques : réduire vos jetons d'entrée de 400k à 50k
Astuce 1 : Soyez précis dans vos invites pour éviter le scan global
C'est l'optimisation la plus importante et la plus simple à mettre en œuvre.
❌ Invites vagues (déclenchent un scan de fichiers à grande échelle) :
"Aide-moi à optimiser les performances de ce projet"
"Vérifie les bugs dans le code"
"Refactorise ce module"
✅ Invites précises (ne lisent que les fichiers nécessaires) :
"Optimise le temps de réponse de la fonction processRequest dans src/api/handler.ts"
"Corrige l'exception de pointeur nul à la ligne 45 de src/auth/login.ts"
"Migre la fonction formatDate de moment vers dayjs dans src/utils/format.ts"
Les invites vagues poussent Claude Code à utiliser Glob + Grep + Read sur une multitude de fichiers pour "comprendre" votre besoin, et le contenu de chaque fichier reste en permanence dans l'historique de la conversation. Des invites précises lui permettent de ne lire qu'un ou deux fichiers pertinents.
Économie de jetons : réduction de 60 à 80 % des jetons liés aux résultats d'appels d'outils.
Astuce 2 : Utilisez /clear et /compact au bon moment
# Vider la conversation lors du passage à une tâche non liée
/clear
# Compresser l'historique lorsque la conversation est longue mais que la tâche n'est pas terminée
/compact
# Compression avec instructions pour conserver des informations spécifiques
/compact Conserve les exemples de code et les définitions d'interfaces API, le reste peut être résumé
| Commande | Effet | Cas d'utilisation | Remarques |
|---|---|---|---|
/clear |
Vide tout l'historique | Passage à une tâche totalement différente | Tout le cache est invalidé |
/compact |
L'IA résume l'historique et remplace le texte original | Étapes intermédiaires de longues conversations | Cache partiellement invalidé, mais le contexte est fortement réduit |
Résultat concret : Une conversation de 400 000 jetons peut généralement être réduite à 50 000 – 80 000 jetons après un /compact.
Astuce 3 : Optimisez votre fichier CLAUDE.md
Le fichier CLAUDE.md est chargé à chaque message. Un fichier CLAUDE.md de 10 000 jetons sera envoyé 30 fois au cours de 30 échanges (bien que le coût soit réduit à 0,1x après la mise en cache, il occupe toujours un espace précieux dans le contexte).
Conseils d'optimisation :
├── Limitez CLAUDE.md à 500 lignes (règles essentielles uniquement)
├── Déplacez les explications détaillées de workflow vers Skills (chargement à la demande)
├── Placez la documentation de référence dans knowledge-base/ (lecture uniquement si nécessaire)
└── Évitez les longs exemples de code dans CLAUDE.md
🚀 Conseil pratique : Alléger CLAUDE.md réduit non seulement la consommation de jetons,
mais permet aussi à Claude Code de se concentrer sur les règles fondamentales.
Si vous utilisez APIYI (apiyi.com) pour créer des assistants de codage IA similaires,
nous vous recommandons également de limiter la longueur de vos invites système.
Astuce 4 : Utilisez des sous-agents pour isoler les sorties volumineuses
Lorsque vous devez effectuer des opérations générant une grande quantité de texte, utilisez un sous-agent plutôt que de l'exécuter directement :
❌ Exécution directe dans la conversation principale (la sortie sature le contexte principal) :
"Exécute la suite de tests et analyse les causes d'échec"
→ La sortie peut atteindre 50 000+ jetons, restant en permanence dans l'historique
✅ Utilisation d'un sous-agent par Claude Code (sortie isolée dans un sous-processus) :
"Utilise une sous-tâche pour exécuter les tests et résume-moi uniquement les noms des tests échoués et les causes"
→ Le contexte principal n'augmente que d'environ 500 jetons de résumé
Économie de jetons : Une seule opération peut éviter l'injection de 10 000 à 50 000 jetons dans le contexte principal.
Astuce 5 : Choisissez le modèle et le niveau d'effort appropriés
| Type de tâche | Modèle recommandé | Niveau d'effort | Note |
|---|---|---|---|
| Modification simple/formatage | Sonnet | low | Pas besoin de réflexion approfondie |
| Développement courant | Sonnet | medium | Meilleur rapport qualité/prix |
| Architecture complexe | Opus | high | Nécessite un raisonnement poussé |
| Revue de code | Sonnet | medium | Meilleur rapport qualité/prix que Opus |
# Réduire la profondeur de réflexion pour limiter les jetons de réflexion (qui deviennent des jetons d'entrée)
/effort low
# Ou contrôler la limite de jetons de réflexion via les variables d'environnement
MAX_THINKING_TOKENS=8000
La chaîne de pensée étendue (thinking) finit par devenir une partie des jetons d'entrée lors des échanges suivants. Réduire le niveau d'effort peut réduire considérablement l'accumulation de jetons au fil de la conversation.
Astuce 6 : Surveillez la distribution des jetons avec la commande /context
# Voir la distribution actuelle des jetons
/context
La commande /context affiche la répartition des jetons dans votre contexte actuel, vous aidant à identifier ce qui consomme réellement de l'espace. Découvertes fréquentes :
- Une recherche grep a retourné 20 000 jetons dont seulement 5 % sont utiles.
- Un gros fichier lu précédemment n'est plus nécessaire mais occupe toujours de la place.
- Le fichier CLAUDE.md occupe une place anormalement élevée.
Une fois le problème identifié, utilisez /compact ou /clear de manière ciblée.
💰 Conseil financier : Pour les utilisateurs facturés à l'usage, ces astuces réduisent directement votre facture.
Grâce aux statistiques d'utilisation de la plateforme APIYI (apiyi.com), vous pouvez visualiser clairement la distribution des jetons pour chaque requête et identifier vos points chauds de coûts.
Étude de cas pratique : réduire les coûts de 60 $ à 8 $ par jour
Voici un processus d'optimisation réel :
Avant optimisation (Projet Python d'envergure, utilisateur intensif de Claude Code)
Utilisation quotidienne :
├── Cycles de dialogue : ~50 tours/jour
├── Jetons d'entrée moyens : 350-450k/tour
├── Taux de succès du cache : ~70 % (dû aux /clear fréquents et changements de modèles)
├── Coût API quotidien (Opus 4) : ~60 $
└── Coût mensuel : ~1 320 $
Après optimisation (Application de 6 astuces)
Utilisation quotidienne :
├── Cycles de dialogue : ~40 tours/jour (plus précis, moins de tours nécessaires)
├── Jetons d'entrée moyens : 80-120k/tour (instructions précises + compactage régulier)
├── Taux de succès du cache : ~92 % (réduction des interruptions de cache inutiles)
├── Coût API quotidien (principalement Sonnet 4, Opus réservé aux tâches complexes) : ~8 $
└── Coût mensuel : ~176 $
| Optimisation | Part d'économie | Explication |
|---|---|---|
| Instructions précises vs scan flou | ~35 % | Gain le plus important |
| Utilisation opportune de /compact et /clear | ~25 % | Contrôle de l'expansion cumulative |
| Sonnet remplace Opus (80 % des tâches) | ~20 % | Passage au modèle inférieur sans perte de qualité |
| Simplification du CLAUDE.md | ~8 % | Réduction des frais fixes par tour |
| Isolation des sorties longues via Subagent | ~7 % | Évite de polluer le contexte avec de gros blocs |
| Réduction du niveau d'effort | ~5 % | Réduit l'accumulation de jetons de réflexion |
Questions fréquentes
Q1 : Les 400 000 jetons affichés par Claude Code correspondent-ils au coût réel ?
Non. Claude Code active automatiquement la mise en cache des invites (Prompt Caching). Dans une session active, plus de 95 % des jetons d'entrée sont généralement des succès de cache, facturés à seulement 0,1x du prix de base. Sur 400 000 jetons, seuls 20 000 à 40 000 jetons sont probablement facturés au prix fort. Vous pouvez utiliser /context pour vérifier votre taux de succès de cache réel. L'invocation du modèle via APIYI (apiyi.com) prend également en charge ce mécanisme de cache.
Q2 : Dois-je me soucier de la consommation de jetons avec un abonnement Max ?
Oui, mais pour une raison différente. L'abonnement Max n'est pas facturé au jeton, mais il comporte une limite d'utilisation hebdomadaire. Une consommation trop élevée de jetons vous fera atteindre cette limite plus rapidement. Simplifier le contexte permet non seulement de prolonger votre temps d'utilisation, mais aide aussi Claude Code à mieux comprendre vos besoins (plus le contexte est précis, meilleure est la réponse).
Q3 : Vaut-il mieux utiliser /compact ou /clear ?
Tout dépend du scénario. Si vous êtes sur le point de commencer une tâche totalement différente, /clear est préférable pour repartir de zéro. Si vous restez sur la même tâche mais que la conversation devient trop longue, utilisez /compact pour conserver le contexte clé tout en réduisant le volume. /compact prend en charge des instructions personnalisées, par exemple /compact conserver tout l'historique des modifications de code et les définitions d'API.
Q4 : La mise à jour vers la dernière version de Claude Code optimise-t-elle automatiquement l’utilisation des jetons ?
Oui, il est conseillé de toujours garder la version la plus récente. Anthropic améliore continuellement les stratégies de gestion de contexte de Claude Code, notamment le déclenchement automatique de la compression (actuellement activé à environ 83,5 % d'occupation du contexte) et le chargement différé des définitions d'outils MCP (chargement des noms uniquement, le schéma complet n'est chargé qu'en cas de besoin). Les nouvelles versions offrent généralement un meilleur taux de succès de cache et une gestion plus intelligente du contexte.

Résumé : Comprendre la mise en cache + Utilisation précise = Maîtrise des coûts
La mise en cache des invites (Prompt Caching) de Claude Code est un mécanisme d'optimisation automatique extrêmement puissant : vous n'avez aucune configuration à effectuer, il vous fait économiser de l'argent tout seul. Cependant, comprendre son fonctionnement et les conditions qui entraînent son invalidation vous permettra de faire passer vos économies d'un gain "automatique de 70 %" à une optimisation "active de 95 %".
Gardez en tête ces 3 principes fondamentaux :
- Maintenez le cache actif : Évitez les opérations inutiles qui interrompent la mise en cache (changement fréquent de modèle, utilisation abusive de
/clear). - Contrôlez l'expansion du contexte : Utilisez des instructions précises et la commande
/compactrégulièrement pour éviter que l'historique de la conversation ne croisse indéfiniment. - Choisissez les bons outils et modèles : Pour 80 % des tâches, Sonnet suffit amplement ; réservez Opus aux scénarios qui en ont réellement besoin.
Pour les utilisateurs payant à l'usage via API, nous recommandons de gérer vos invocations du modèle Claude via APIYI (apiyi.com), afin de tirer parti des outils de surveillance de la consommation pour optimiser en continu vos dépenses en jetons (tokens). Pour les utilisateurs intensifs, nous conseillons de passer directement à l'abonnement Claude Max, tout en appliquant les techniques d'optimisation décrites dans cet article pour obtenir le meilleur rapport qualité-prix.
📝 Auteur de l'article : Équipe technique APIYI | APIYI apiyi.com – Plateforme d'accès unifié à plus de 300 API de grands modèles de langage.
Références
-
Documentation sur la mise en cache des invites d'Anthropic : Explication détaillée du mécanisme de cache officiel.
- Lien :
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Note : Détails sur le TTL du cache, les ratios de tarification et les exigences de longueur minimale.
- Lien :
-
Guide de gestion des coûts de Claude Code : Conseils officiels pour l'optimisation des jetons.
- Lien :
code.claude.com/docs/en/costs - Note : Stratégies de contrôle des coûts recommandées par Anthropic.
- Lien :
-
Meilleures pratiques pour Claude Code : Gestion du contexte et optimisation de l'efficacité.
- Lien :
anthropic.com/engineering/claude-code-best-practices - Note : Inclut des conseils pratiques sur les instructions précises, l'utilisation de
compact, etc.
- Lien :