
"爲什麼我的 Claude Code 每次請求都有 40 萬輸入 Token?賬單怎麼這麼高?"——這是很多 Claude Code 用戶在查看用量統計時的第一反應。實際上,這 40 萬 Token 中的絕大部分可能已經被緩存命中,真實成本可能只有表面數字的 1/10。但如果緩存沒命中,那賬單確實會讓人心疼。
核心價值: 讀完本文,你將理解 Claude Code 的自動緩存機制、導致緩存失效的 8 種常見原因,以及 6 個將輸入 Token 從 40 萬降到 5 萬的實戰技巧。
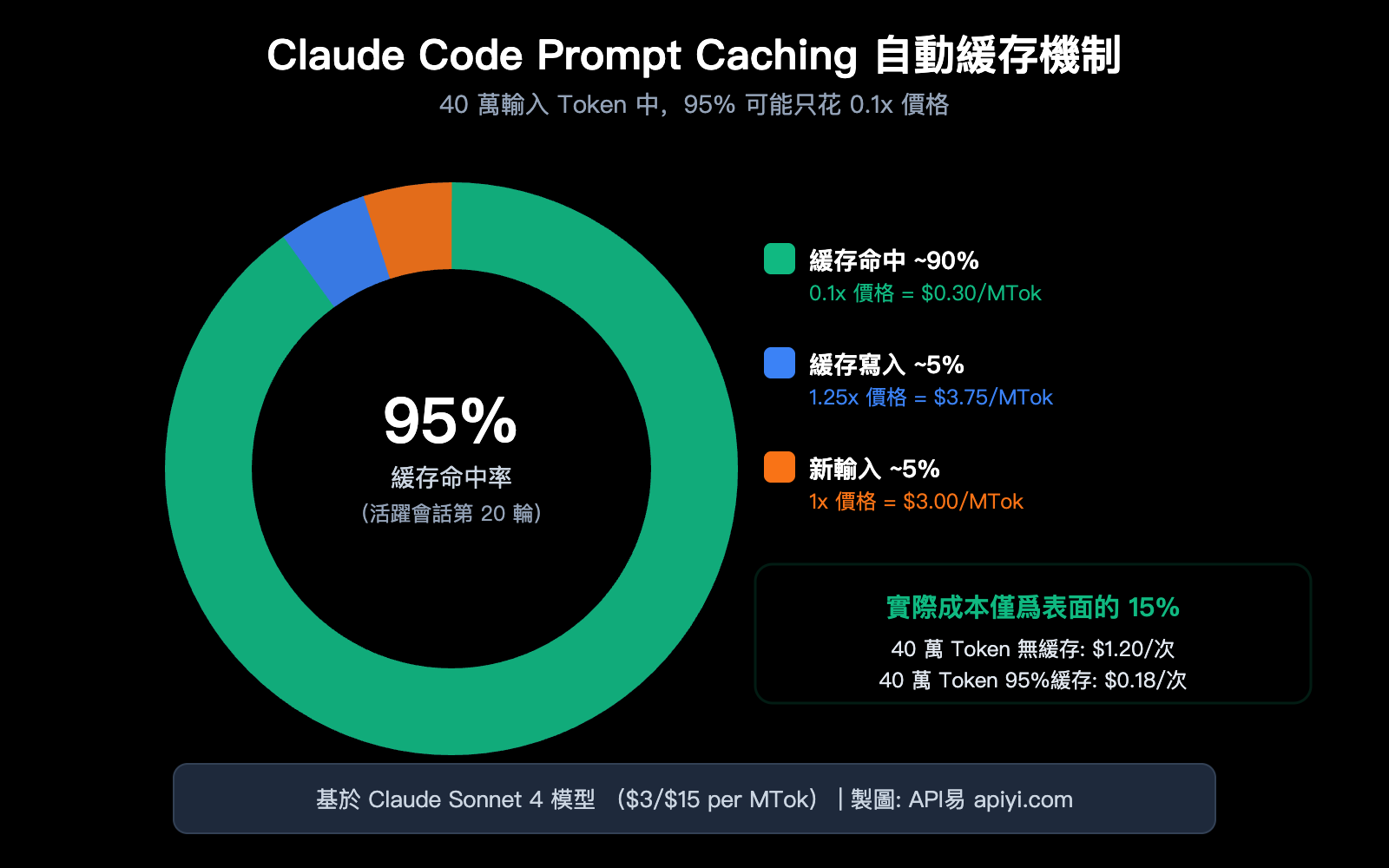
Claude Code 的 Prompt Caching 自動緩存機制詳解
Claude Code 會自動命中緩存嗎?
會的。 Claude Code 在每次 API 請求中都會自動啓用 Anthropic 的 Prompt Caching,無需任何配置。這是內置行爲,不是可選功能。
每次你在 Claude Code 中發送一條消息,實際發送給 API 的內容按以下順序組裝:
| 組裝順序 | 內容 | 大小估算 | 緩存行爲 |
|---|---|---|---|
| 第 1 層 | Tool 定義(Read/Edit/Bash 等) | ~5,000 Token | 幾乎不變,高命中率 |
| 第 2 層 | 系統提示 + CLAUDE.md | ~3,000-10,000 Token | 會話內不變,高命中率 |
| 第 3 層 | 對話歷史(所有之前的消息) | 持續增長 | 前綴匹配,逐步累積緩存 |
| 第 4 層 | 當前新消息 | 可變 | 永遠不會命中緩存 |
關鍵機制: 緩存是基於前綴匹配的——只要請求的前 N 個 Token 與之前緩存的內容完全一致,這 N 個 Token 就會命中緩存。在一個持續對話中,到第 20 輪時,95%+ 的輸入 Token 通常來自緩存命中。
緩存價格:爲什麼緩存命中如此重要
| 操作類型 | 相對基礎輸入價格 | Sonnet 4 實際價格/MTok | Opus 4 實際價格/MTok |
|---|---|---|---|
| 普通輸入(無緩存) | 1x | $3.00 | $15.00 |
| 5分鐘緩存寫入 | 1.25x | $3.75 | $18.75 |
| 1小時緩存寫入 | 2x | $6.00 | $30.00 |
| 緩存命中/讀取 | 0.1x | $0.30 | $1.50 |
| 輸出 | — | $15.00 | $75.00 |
舉個具體例子:如果你的請求有 40 萬輸入 Token:
場景 A:完全無緩存
├── 40萬 Token × $3/MTok (Sonnet) = $1.20 每次請求
場景 B:95% 緩存命中(典型 Claude Code 會話)
├── 緩存命中 38萬 Token × $0.30/MTok = $0.114
├── 緩存寫入 1萬 Token × $3.75/MTok = $0.0375
├── 新輸入 1萬 Token × $3/MTok = $0.03
├── 合計 = $0.18 每次請求
└── 實際成本僅爲無緩存的 15%
🎯 技術提示: 通過 API易 apiyi.com 調用 Claude API 同樣支持 Prompt Caching 機制,
緩存命中時輸入成本降低 90%。如果你的項目通過 API 集成 Claude,
建議合理設計 Prompt 結構以最大化緩存命中率。
緩存 TTL:Max 用戶的隱藏福利
| 訂閱方案 | 緩存 TTL | 寫入成本 | 說明 |
|---|---|---|---|
| API 按量付費 | 5 分鐘 | 1.25x | 超過 5 分鐘不操作,緩存過期 |
| Pro / Team | 5 分鐘 | 1.25x | 同上 |
| Max 5x / 20x | 1 小時 | 2x | 寫入貴但命中窗口大 12 倍 |
Max 用戶雖然緩存寫入價格是 2x(比標準的 1.25x 高),但 1 小時 TTL 意味着你去喝杯咖啡回來緩存還在。對於間歇性使用的開發者,這個差異非常顯著。
每次緩存命中都會重置 TTL 計時器,所以只要你保持活躍使用,緩存基本不會過期。
緩存沒命中?8 種常見原因及解決方案

緩存失效的根本原因只有一個:請求的前綴與緩存內容不匹配。具體到 Claude Code 中,以下 8 種情況會導致緩存失效:
第一類:TTL 過期
| 原因 | 觸發條件 | 影響範圍 | 解決方案 |
|---|---|---|---|
| 1. 空閒超時 | API 用戶 >5分鐘無操作,Max 用戶 >1小時 | 全部緩存失效 | 保持活躍或接受重建成本 |
這是最常見的緩存失效原因。如果你在編碼過程中離開超過 5 分鐘(API 用戶)或 1 小時(Max 用戶),下一次請求會觸發完整的緩存重建。
第二類:內容變更導致的級聯失效
緩存遵循嚴格的層級結構:Tool 定義 → 系統提示 → 對話歷史。上層變更會導致下層全部失效。
| 原因 | 觸發條件 | 影響範圍 | 嚴重程度 |
|---|---|---|---|
| 2. 切換模型 | 使用 /model 命令 |
全部緩存(緩存按模型隔離) | ⚠️ 高 |
| 3. 添加/刪除 MCP 工具 | 安裝或卸載 MCP Server | Tool 層 + 下游全部失效 | ⚠️ 高 |
| 4. 切換 Web Search | 開啓或關閉聯網搜索 | 系統層 + 下游全部失效 | ⚠️ 中 |
| 5. 修改 CLAUDE.md | 編輯項目配置文件後重啓 | 系統層 + 下游全部失效 | ⚠️ 中 |
第三類:操作觸發的失效
| 原因 | 觸發條件 | 影響範圍 | 嚴重程度 |
|---|---|---|---|
| 6. 開新對話 | /clear 或新建會話 |
全部緩存(對話歷史清空) | ⚠️ 高 |
| 7. 使用 /compact | 主動壓縮對話歷史 | 對話歷史層緩存失效 | ⚠️ 中 |
| 8. 使用 /rewind | 撤銷之前的消息 | 對話歷史前綴改變 | ⚠️ 中 |
一個容易忽略的技術限制:最小緩存長度
如果你的 Prompt 低於以下 Token 數量,緩存會靜默跳過,不會有任何報錯:
| 模型 | 最小可緩存長度 |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4,096 Token |
| Claude Sonnet 4.6 | 2,048 Token |
| Claude Sonnet 4.5 / 4 | 1,024 Token |
對於 Claude Code 來說,由於 Tool 定義 + 系統提示就已經超過 5,000 Token,這個限制幾乎不會觸發。但如果你自己通過 API 構建應用,需要注意這個下限。
💡 建議: 如果你通過 API易 apiyi.com 自建應用調用 Claude API,
確保系統提示詞長度超過模型對應的最小緩存閾值,否則緩存不會生效。
爲什麼你看到 40 萬輸入 Token:Claude Code 的上下文構成
理解了緩存機制後,我們來拆解一下那個讓你震驚的"40 萬輸入 Token"到底由什麼構成。
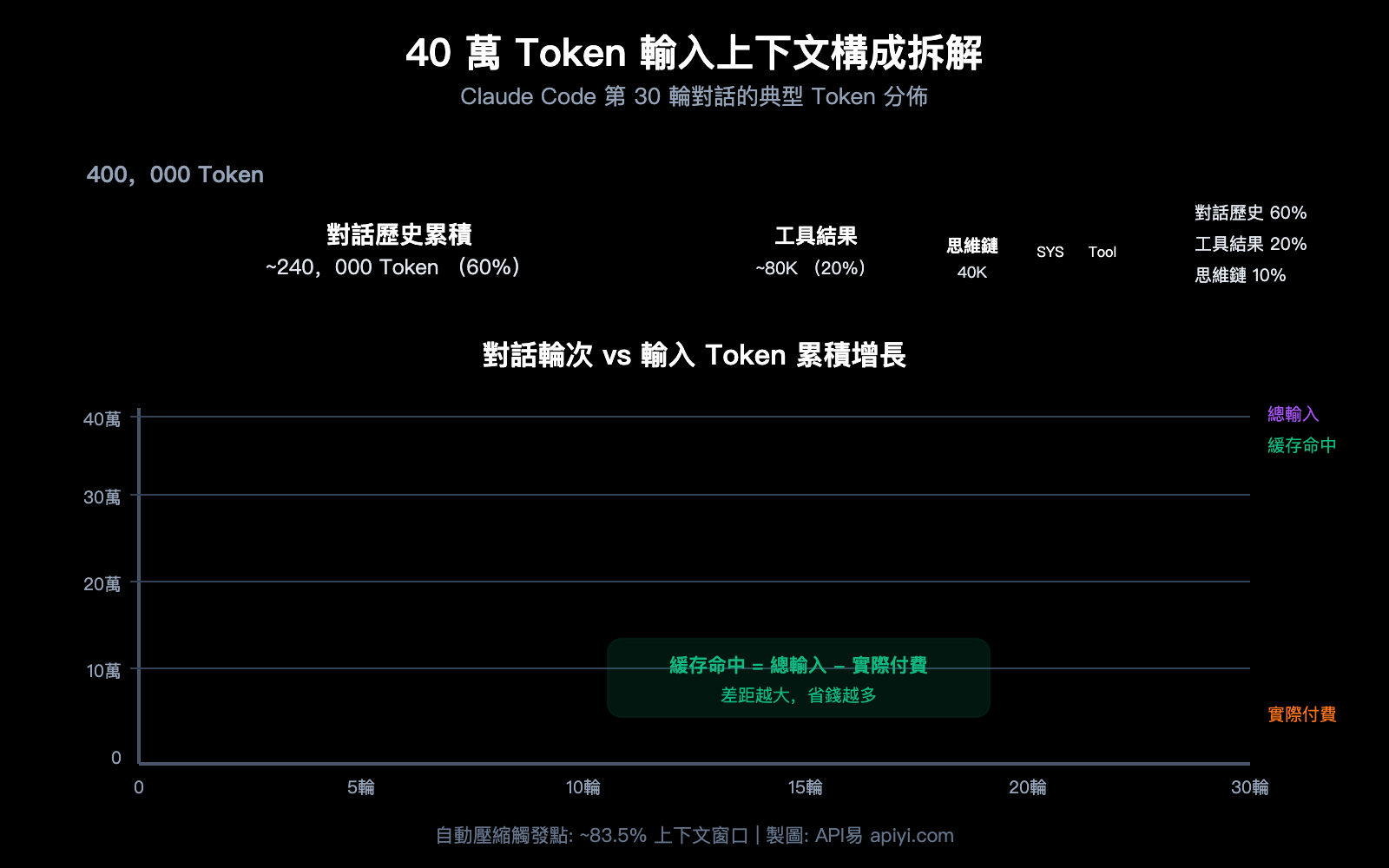
Token 消耗的 5 大來源
| 來源 | 佔比 | 40萬中約佔 | 特點 |
|---|---|---|---|
| 對話歷史累積 | ~60% | ~24萬 | 每輪對話都重新發送全部歷史 |
| 工具調用結果 | ~20% | ~8萬 | 文件讀取、grep 搜索結果駐留上下文 |
| 擴展思維鏈 | ~10% | ~4萬 | 前幾輪的 thinking block 變爲輸入 |
| 系統提示 + CLAUDE.md | ~5% | ~2萬 | 每條消息都攜帶 |
| Tool 定義 | ~5% | ~2萬 | 所有可用工具的 schema |
核心真相:對話越長,輸入越大
Claude Code 的工作方式是每次請求都重新發送完整對話歷史。這意味着:
- 第 1 輪:輸入 ~2萬 Token(系統提示 + Tool 定義 + 你的問題)
- 第 5 輪:輸入 ~10萬 Token(累積了 4 輪的對話歷史)
- 第 15 輪:輸入 ~25萬 Token(包含大量文件讀取結果)
- 第 30 輪:輸入 ~40萬+ Token(接近自動壓縮閾值)
但請注意:這些輸入中的絕大部分都是緩存命中的。第 30 輪的 40 萬 Token 中,可能只有 1-2 萬是新增的非緩存內容。
大代碼庫的特殊問題
Claude Code 不會自動加載整個代碼庫到上下文中。它按需讀取文件。但在大型代碼庫中:
- 一次
grep搜索可能返回大量結果,全部進入上下文 - 探索性地讀取多個文件,每個文件內容都駐留在對話歷史中
- Agent 模式自主執行多步操作,每步的工具調用結果都累積
你的客戶每次 40 萬 Token 的情況,很可能是以下原因疊加:
- 代碼庫很大,Claude Code 讀取了大量文件進行分析
- 對話輪次較多,歷史累積
- 可能沒有及時使用
/compact或/clear - CLAUDE.md 文件可能較長
6 個實戰技巧:將輸入 Token 從 40 萬降到 5 萬
技巧一:精準指令,避免全局掃描
這是最重要也最容易執行的優化。
❌ 模糊指令(觸發大範圍文件掃描):
"幫我優化這個項目的性能"
"檢查代碼中的bug"
"重構這個模塊"
✅ 精準指令(只讀取必要文件):
"優化 src/api/handler.ts 中 processRequest 函數的響應時間"
"修復 src/auth/login.ts 第 45 行的空指針異常"
"將 src/utils/format.ts 中的 formatDate 函數從 moment 遷移到 dayjs"
模糊指令會導致 Claude Code 使用 Glob + Grep + Read 大量文件來"理解"你的需求,每個文件的內容都會永久駐留在對話歷史中。精準指令可以讓它只讀取 1-2 個相關文件。
Token 節省效果:減少 60-80% 的工具調用結果 Token
技巧二:及時使用 /clear 和 /compact
# 切換到不相關的任務時,清空對話
/clear
# 對話較長但任務還沒結束時,壓縮歷史
/compact
# 帶指令的壓縮,保留特定信息
/compact 保留代碼示例和 API 接口定義,其他可以精簡
| 命令 | 效果 | 適用場景 | 注意事項 |
|---|---|---|---|
/clear |
清空全部對話歷史 | 切換到完全不同的任務 | 緩存全部失效 |
/compact |
AI 總結歷史,替換原文 | 長對話中間階段 | 緩存部分失效,但上下文大幅縮小 |
實際效果:一個 40 萬 Token 的對話,/compact 後通常可以壓縮到 5-8 萬 Token。
技巧三:優化 CLAUDE.md 文件
CLAUDE.md 會在每條消息中加載。一個 10,000 Token 的 CLAUDE.md,在 30 輪對話中會被髮送 30 次(雖然緩存命中後只收 0.1x 費用,但仍然佔據寶貴的上下文空間)。
優化建議:
├── CLAUDE.md 控制在 500 行以內(核心規則)
├── 把詳細的工作流說明移到 Skills 中(按需加載)
├── 把參考文檔放到 knowledge-base/ 中(需要時 Read)
└── 避免在 CLAUDE.md 中放大段示例代碼
🚀 實踐建議: 精簡 CLAUDE.md 不僅減少 Token 消耗,
還能讓 Claude Code 更專注於核心規則。
如果你在用 API易 apiyi.com 構建類似的 AI 編碼助手,
同樣建議控制系統提示詞長度。
技巧四:善用 Subagent 隔離冗長輸出
當需要執行會產生大量輸出的操作時,用 Subagent 代替直接執行:
❌ 直接在主對話中執行(輸出全部進入主上下文):
"運行測試套件並分析失敗原因"
→ 測試輸出可能有 50,000+ Token,永久駐留在對話歷史中
✅ 讓 Claude Code 使用 Subagent(輸出隔離在子進程中):
"用一個子任務運行測試套件,只把失敗的測試名和原因總結給我"
→ 主上下文只增加 ~500 Token 的總結
Token 節省效果:單次操作可減少 10,000-50,000 Token 進入主上下文
技巧五:選擇合適的模型和 effort 級別
| 任務類型 | 推薦模型 | effort 級別 | 說明 |
|---|---|---|---|
| 簡單修改/格式化 | Sonnet | low | 不需要深度思考 |
| 常規開發 | Sonnet | medium | 性價比最高 |
| 複雜架構設計 | Opus | high | 需要深度推理 |
| 代碼審查 | Sonnet | medium | 性價比優於 Opus |
# 降低思考深度,減少 thinking Token(後續會變爲輸入)
# 在簡單任務中設置更低的 effort
/effort low
# 或通過環境變量控制思維 Token 上限
MAX_THINKING_TOKENS=8000
擴展思維鏈 (thinking) 會在後續輪次變成輸入 Token 的一部分。降低 effort 級別可以顯著減少後續輪次的累積 Token。
技巧六:使用 /context 命令監控 Token 分佈
# 查看當前 Token 使用分佈
/context
/context 命令會展示當前上下文中各部分的 Token 佔比,幫你定位到底是什麼在消耗空間。常見發現:
- 某次 grep 搜索返回了 20,000 Token 的結果但只有 5% 有用
- 之前讀取的某個大文件已經不需要了但還在上下文中
- CLAUDE.md 佔了意外多的空間
發現問題後,有針對性地使用 /compact 或 /clear 處理。
💰 成本建議: 對於 API 按量付費用戶,這些優化技巧可以直接降低賬單。
通過 API易 apiyi.com 平臺的用量統計功能,可以清晰看到每次請求的 Token 分佈,
幫助你定位成本熱點。
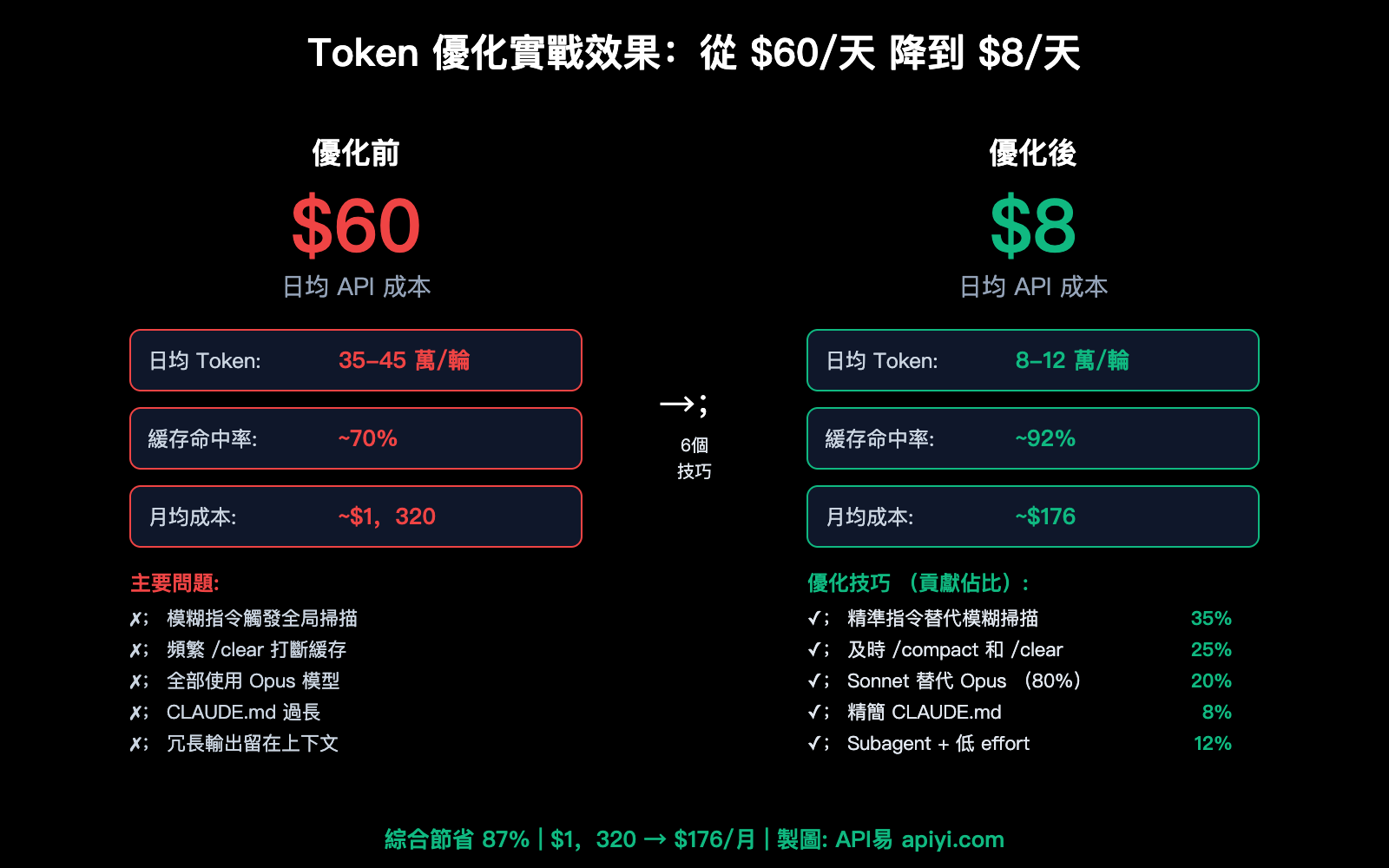
實戰案例:從日均 $60 降到 $8
以下是一個真實的優化過程:
優化前(大型 Python 項目,重度 Claude Code 用戶)
日均使用情況:
├── 對話輪次:~50 輪/天
├── 平均輸入 Token:35-45 萬/輪
├── 緩存命中率:~70%(頻繁 /clear 和切換模型導致)
├── 日均 API 成本(Opus 4):~$60
└── 月均:~$1,320
優化後(應用 6 個技巧)
日均使用情況:
├── 對話輪次:~40 輪/天(更精準,不需要那麼多輪)
├── 平均輸入 Token:8-12 萬/輪(精準指令 + 定期 compact)
├── 緩存命中率:~92%(減少不必要的緩存打斷)
├── 日均 API 成本(Sonnet 4 爲主,Opus 僅用於複雜任務):~$8
└── 月均:~$176
| 優化項 | 節省佔比 | 說明 |
|---|---|---|
| 精準指令替代模糊掃描 | ~35% | 最大收益項 |
| 及時 /compact 和 /clear | ~25% | 控制累積膨脹 |
| Sonnet 替代 Opus(80% 任務) | ~20% | 模型降級零感知 |
| 精簡 CLAUDE.md | ~8% | 減少每輪固定開銷 |
| Subagent 隔離冗長輸出 | ~7% | 避免大塊結果污染上下文 |
| 降低 effort 級別 | ~5% | 減少 thinking Token 累積 |
常見問題
Q1: Claude Code 顯示的 40 萬 Token 是實際收費 40 萬嗎?
不是。Claude Code 會自動啓用 Prompt Caching,在一個活躍會話中,95%+ 的輸入 Token 通常是緩存命中,收費僅爲基礎價格的 0.1x。40 萬 Token 中,可能只有 2-4 萬 Token 按完整價格計費。你可以用 /context 查看實際的緩存命中率。通過 API易 apiyi.com 調用 API 同樣支持緩存機制。
Q2: 我用 Max 包月方案還需要關心 Token 消耗嗎?
需要關心,但原因不同。Max 包月不按 Token 計費,但有每週用量上限。過高的 Token 消耗會讓你更快觸達用量限制。精簡上下文既能延長可用時間,也能讓 Claude Code 更準確地理解你的需求(上下文越精準,回答越好)。
Q3: /compact 和 /clear 哪個更好?
取決於場景。如果你即將開始一個完全不同的任務,用 /clear 徹底清空更好。如果你還在同一個任務中但對話變得很長,用 /compact 保留關鍵上下文同時壓縮體積。/compact 支持自定義指令,比如 /compact 保留所有代碼修改記錄和API接口定義。
Q4: 升級到最新版 Claude Code 會自動優化 Token 使用嗎?
是的,建議始終保持最新版本。Anthropic 持續優化 Claude Code 的上下文管理策略,包括自動壓縮觸發時機(當前約 83.5% 上下文佔用時觸發)、MCP 工具定義延遲加載(只加載工具名,用到時才加載完整 schema)等。新版本通常會帶來更好的緩存命中率和更智能的上下文管理。
總結:理解緩存 + 精準使用 = 成本可控
Claude Code 的 Prompt Caching 是一個非常強大的自動優化機制——你不需要做任何配置,它就在替你省錢。但理解它的工作原理和失效條件,能幫你把省錢效果從"自動 70%"提升到"主動 95%"。
記住這 3 個核心原則:
- 保持緩存活躍: 避免不必要的操作打斷緩存(頻繁切換模型、隨意 /clear)
- 控制上下文膨脹: 精準指令 + 定期 /compact,不讓對話歷史無限增長
- 選對工具和模型: 80% 的任務用 Sonnet 就夠,把 Opus 留給真正需要的場景
對於 API 按量付費用戶,推薦通過 API易 apiyi.com 統一管理 Claude API 調用,利用平臺的用量監控功能持續優化 Token 消耗。對於交互式重度用戶,建議直接上 Claude Max 包月方案,配合本文的優化技巧獲得最佳性價比。
📝 本文作者: APIYI 技術團隊 | API易 apiyi.com – 300+ AI 大模型 API 統一接入平臺
參考資料
-
Anthropic Prompt Caching 文檔: 官方緩存機制詳解
- 鏈接:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - 說明: 緩存 TTL、定價倍率和最小長度要求
- 鏈接:
-
Claude Code 成本管理指南: 官方 Token 優化建議
- 鏈接:
code.claude.com/docs/en/costs - 說明: Anthropic 官方推薦的成本控制策略
- 鏈接:
-
Claude Code 最佳實踐: 上下文管理和效率優化
- 鏈接:
anthropic.com/engineering/claude-code-best-practices - 說明: 包含精準指令、compact 使用等實戰建議
- 鏈接: