
Note de l'auteur : explications détaillées sur le mécanisme TTL du cache d'invites de Claude Code, les différences entre les paliers de 5 minutes et 1 heure, la comparaison de facturation entre l'API Anthropic et AWS Bedrock, avec des conseils pour optimiser vos coûts.
« Est-il possible de modifier le TTL du cache d'invites de Claude Code ? Quelle est la différence entre 5 minutes et 1 heure ? Quel est le choix le plus rentable ? » — Voici les questions les plus fréquentes posées par les utilisateurs de Claude Code soucieux de maîtriser leurs coûts.
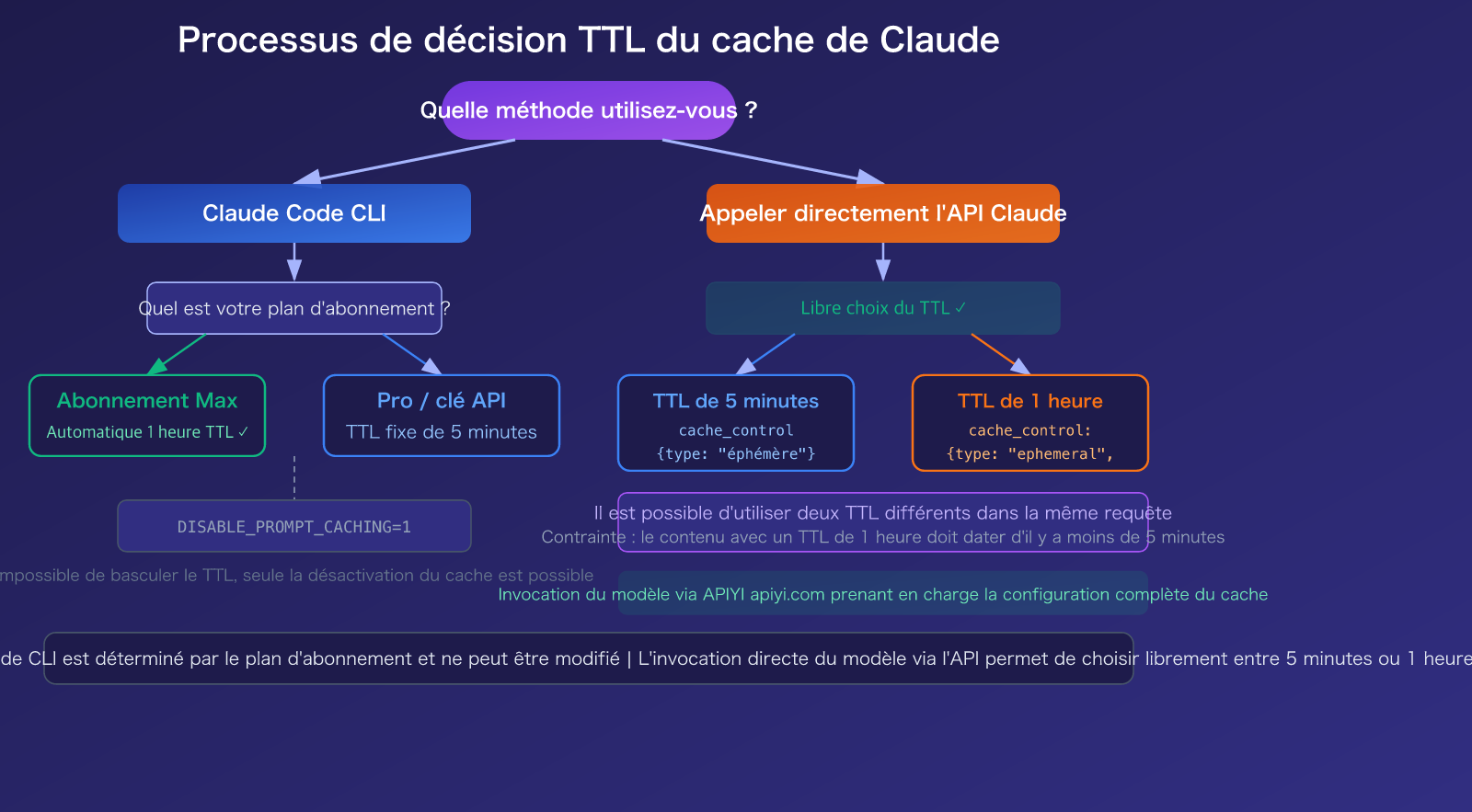
Pour faire court : Le TTL du cache de Claude Code ne peut pas être modifié directement par l'utilisateur — il est déterminé par votre plan d'abonnement. Les utilisateurs de l'abonnement Max bénéficient automatiquement d'un TTL d'une heure, tandis que les abonnés Pro et les utilisateurs de clé API ont un TTL par défaut de 5 minutes. Cependant, si vous utilisez directement l'API Claude, vous pouvez choisir librement entre 5 minutes ou 1 heure via le paramètre cache_control.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez parfaitement le mécanisme TTL du cache d'invites de Claude, les différences de facturation entre l'API officielle d'Anthropic et AWS Bedrock, et vous saurez choisir la stratégie de cache la plus économique selon vos cas d'usage.
Points clés sur le TTL du cache d'invites de Claude
Le cache d'invites est l'un des mécanismes les plus efficaces pour réduire les coûts avec les modèles de la série Claude. Il stocke vos préfixes d'invites (instructions système, définitions d'outils, historique de conversation, etc.) sur le serveur. Lors de la requête suivante, si le préfixe est identique, le modèle lit directement depuis le cache, vous ne payez alors que 10 % du prix d'entrée standard.
| Point clé | Description | Impact réel |
|---|---|---|
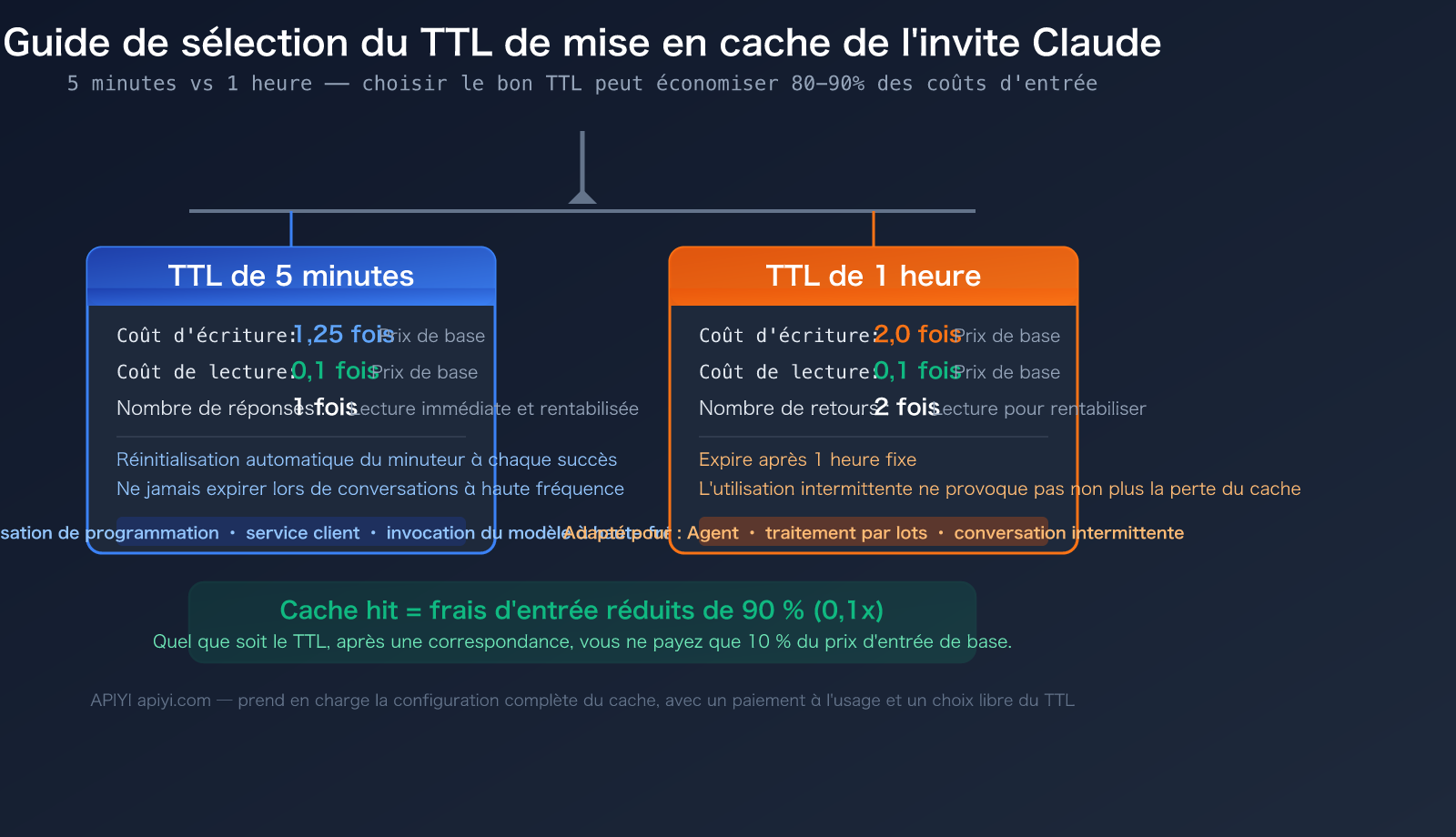
| Deux paliers TTL | 5 minutes (par défaut) et 1 heure (optionnel) | Choisir le bon TTL permet d'économiser sur les coûts d'écriture |
| Lecture cache à 10 % | Après une correspondance, l'entrée ne coûte que 0,1x | Économie de 80 à 90 % sur les frais d'entrée pour les longues conversations |
| Écriture 5 min = 1,25x | 25 % de surcoût lors de l'écriture en cache | Rentabilisé dès la première lecture |
| Écriture 1 h = 2x | Double coût lors de l'écriture en cache | Nécessite deux lectures pour être rentabilisé |
| Gestion auto Claude Code | Instructions système, outils, CLAUDE.md mis en cache automatiquement | Aucune configuration manuelle requise |
Peut-on modifier le TTL dans Claude Code ?
C'est la question qui préoccupe le plus les utilisateurs. La réponse dépend de deux scénarios :
Claude Code (outil CLI interactif) : Modification manuelle impossible. Le cache de Claude Code est contrôlé côté serveur — les abonnés Max bénéficient d'un TTL d'une heure (via le flag de fonctionnalité serveur tengu_prompt_cache_1h_config), tandis que les abonnés Pro et les utilisateurs de clé API ont un TTL de 5 minutes. Vous pouvez uniquement désactiver totalement le cache via la variable d'environnement DISABLE_PROMPT_CACHING=1, mais vous ne pouvez pas basculer entre les paliers TTL.
API Claude (invocation directe) : Choix libre. Lors d'un appel API, vous pouvez spécifier le TTL dans le paramètre cache_control :
// Cache 5 minutes (par défaut)
{ "cache_control": { "type": "ephemeral" } }
// Cache 1 heure
{ "cache_control": { "type": "ephemeral", "ttl": "1h" } }
🎯 Conseil de sélection : Si vous utilisez principalement Claude Code CLI, le TTL dépend de votre abonnement. Si vous passez par une invocation API (via APIYI par exemple), vous pouvez choisir de manière flexible entre 5 minutes ou 1 heure selon votre usage pour un contrôle des coûts plus précis.
Explication détaillée des règles de facturation du cache d'invites Claude
5 minutes vs 1 heure : Comparaison des coûts
La différence fondamentale entre ces deux TTL réside dans le coût d'écriture. Le coût de lecture est identique, fixé à 0,1 fois le tarif de base des entrées :
| Opération | TTL 5 minutes | TTL 1 heure | Remarque |
|---|---|---|---|
| Écriture en cache | 1,25x tarif de base | 2,0x tarif de base | Surcoût lors de la première écriture |
| Lecture du cache | 0,1x tarif de base | 0,1x tarif de base | Tarif réduit après succès (identique) |
| Seuil de rentabilité | 1 lecture suffit | 2 lectures nécessaires | La fréquence d'usage dicte le choix |
| Renouvellement auto | Réinitialise 5 min à chaque accès | Expiration fixe à 1 heure | 5 min peut durer indéfiniment en dialogue fréquent |
Tarifs spécifiques du cache d'invites par modèle
Voici le tableau complet de facturation du cache pour les modèles via l'API officielle d'Anthropic (mars 2026) :
| Modèle | Tarif entrée de base | Écriture 5 min | Écriture 1 heure | Lecture cache | Tarif sortie |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 5 $/MTok | 6,25 $/MTok | 10 $/MTok | 0,50 $/MTok | 25 $/MTok |
| Claude Sonnet 4.6 | 3 $/MTok | 3,75 $/MTok | 6 $/MTok | 0,30 $/MTok | 15 $/MTok |
| Claude Haiku 4.5 | 1 $/MTok | 1,25 $/MTok | 2 $/MTok | 0,10 $/MTok | 5 $/MTok |
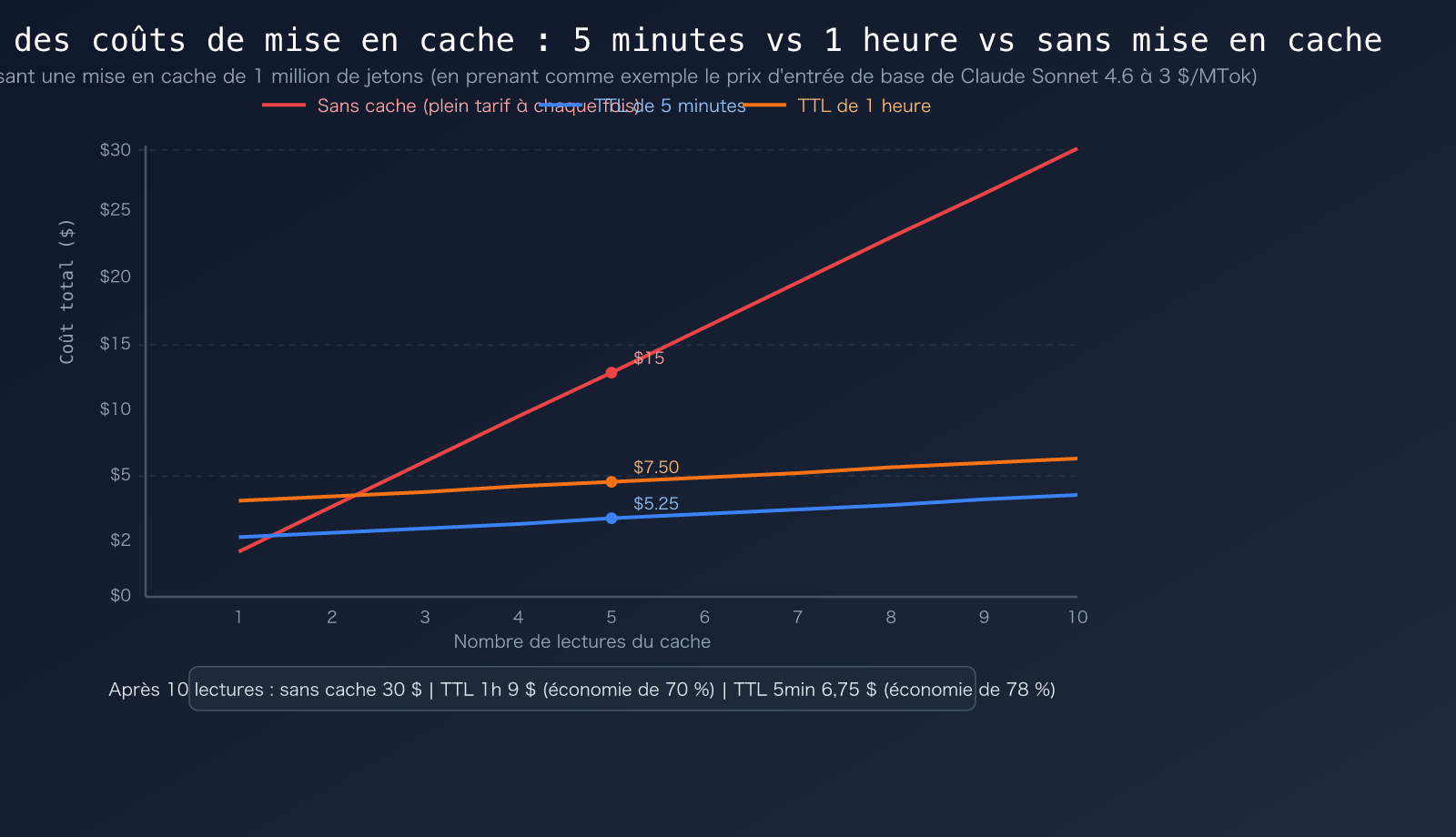
Constat clé : la réduction sur la lecture du cache est impressionnante. Prenons l'exemple de Claude Opus 4.6 :
- Entrée normale de 1 million de jetons = 5,00 $
- Lecture en cache de 1 million de jetons = 0,50 $ (économie de 4,50 $, soit 90 % de réduction)
- C'est ce qui rend l'abonnement Claude Code Pro à 20 $/mois économiquement viable : 100 tours de dialogue avec Opus sans cache pourraient coûter 50 à 100 $, alors qu'avec le cache, cela ne coûte que 10 à 19 $.
Exigences minimales en nombre de jetons pour le cache
Tout ne peut pas être mis en cache. Chaque modèle impose un nombre minimum de jetons ; si le contenu est trop court, le cache ne sera pas déclenché :
| Modèle | Nombre min. de jetons pour le cache |
|---|---|
| Claude Opus 4.6 / 4.5 | 4 096 |
| Claude Sonnet 4.6 | 2 048 |
| Claude Sonnet 4.5 / 4 | 1 024 |
| Claude Haiku 4.5 | 4 096 |
| Claude Haiku 3.5 / 3 | 2 048 |
🎯 Conseil pratique : Si votre invite système est courte (moins de 2 048 jetons), elle ne déclenchera pas le cache avec Claude Sonnet 4.6. Vous pouvez enrichir le contenu de votre invite système ou regrouper les définitions d'outils pour atteindre le seuil minimal. Les invocations via APIYI (apiyi.com) supportent également le cache avec des tarifs avantageux.
API Anthropic vs AWS Bedrock : Comparaison de la facturation du cache
Comparaison du support du cache sur les trois plateformes
Le cache d'invites de Claude est supporté par l'API officielle d'Anthropic, AWS Bedrock et Google Vertex AI, mais avec des nuances :
| Dimension de comparaison | API officielle Anthropic | AWS Bedrock | Google Vertex AI |
|---|---|---|---|
| TTL 5 minutes | ✅ Supporté par tous | ✅ Supporté par tous | ✅ Supporté par tous |
| TTL 1 heure | ✅ Supporté par tous | ✅ Certains modèles (Opus 4.5, Sonnet 4.5, Haiku 4.5) | ✅ Supporté |
| Surcoût écriture (5 min) | 1,25x | ~1,25x | 1,25x |
| Surcoût écriture (1 h) | 2,0x | 2,0x | 2,0x |
| Réduction lecture | 0,1x | ~0,1x | 0,1x |
| Nombre max. de points de rupture | 4 | 4 | 4 |
| Cache automatique | ✅ Supporté | ✅ Supporté | ✅ Supporté |
| TTL personnalisable | ✅ 5 min ou 1 h | ✅ Optionnel (selon modèle) | ✅ Optionnel |
Explications sur les différences clés entre plateformes
API officielle Anthropic : L'expérience de mise en cache est la plus complète, avec les deux options de TTL (5 min et 1 h) disponibles pour tous les modèles. Depuis le 5 février 2026, l'isolation du cache est passée du niveau organisation au niveau espace de travail ; les caches de différents espaces de travail au sein d'une même organisation sont indépendants.
AWS Bedrock : Le support du TTL de 1 heure a été annoncé en janvier 2026, mais est limité à certains modèles comme Claude Opus 4.5, Sonnet 4.5 et Haiku 4.5. Pour les récents Claude Sonnet 4.6 et Opus 4.6, la compatibilité du TTL de 1 heure sur Bedrock reste à confirmer. Si vous utilisez Claude Code avec Bedrock, faites attention au paramètre de compatibilité CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1.
Google Vertex AI : Les fonctionnalités de cache sont globalement identiques à celles de l'API officielle, mais nécessitent une authentification et une facturation via un projet Google Cloud.
🎯 Conseil de choix de plateforme : Si vous voulez éviter les casse-têtes liés aux différences de plateforme et aux configurations de compatibilité, l'utilisation de l'interface unifiée d'APIYI (apiyi.com) est la solution la plus simple : elle prend en charge toutes les fonctionnalités de cache sans nécessiter de configuration séparée pour AWS IAM ou Google Cloud.
Guide rapide de la mise en cache des invites avec Claude Code
Exemple minimaliste : configuration d'un cache TTL de 1 heure
import anthropic
client = anthropic.Anthropic(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": "Vous êtes un assistant professeur de physique professionnel, chargé de répondre aux questions de physique du lycée...(longue invite système ici)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
}],
messages=[{"role": "user", "content": "Expliquez la troisième loi de Newton"}]
)
print(f"Jetons lus depuis le cache : {response.usage.cache_read_input_tokens}")
print(f"Jetons écrits dans le cache : {response.usage.cache_creation_input_tokens}")
Voir le code complet : utilisation mixte de TTL 5 minutes et 1 heure
import anthropic
client = anthropic.Anthropic(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# TTL mixte : 1 heure pour l'invite système (peu fréquent), 5 minutes pour le contexte de conversation (fréquent)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "Vous êtes un consultant technique IA professionnel...(longue invite système, 2000+ jetons)",
"cache_control": {"type": "ephemeral", "ttl": "1h"} # 1 heure pour l'invite système
},
{
"type": "text",
"text": "Voici l'historique de la conversation de l'utilisateur...(historique)",
"cache_control": {"type": "ephemeral"} # 5 minutes pour le contexte (par défaut)
}
],
messages=[{"role": "user", "content": "Comparez les capacités de raisonnement de Claude et GPT"}]
)
# Vérifier l'utilisation du cache
usage = response.usage
print(f"Jetons d'entrée normaux : {usage.input_tokens}")
print(f"Jetons lus depuis le cache : {usage.cache_read_input_tokens}")
print(f"Jetons écrits dans le cache : {usage.cache_creation_input_tokens}")
# Calcul des économies (basé sur Sonnet 4.6)
base_cost = (usage.input_tokens / 1_000_000) * 3
cache_cost = (usage.cache_read_input_tokens / 1_000_000) * 0.3
saved = (usage.cache_read_input_tokens / 1_000_000) * 2.7
print(f"Économies réalisées : ${saved:.4f}")
Contrainte importante : Lorsque vous mélangez deux TTL dans une même requête, le contenu avec un TTL de 1 heure doit être placé avant celui avec un TTL de 5 minutes, sous peine d'erreur.
Conseil : L'utilisation de l'API via APIYI (apiyi.com) prend entièrement en charge la configuration du paramètre
cache_control, vous permettant de choisir librement entre les TTL de 5 minutes et 1 heure.
TTL 5 minutes vs 1 heure : lequel choisir ?
Tableau de décision
| Cas d'utilisation | TTL recommandé | Raison |
|---|---|---|
| Programmation haute fréquence avec Claude Code | 5 minutes | Le compteur est réinitialisé à chaque accès, empêchant l'expiration |
| Chatbot de service client (réponse < 5 min) | 5 minutes | Coût d'écriture faible (1,25x), accès fréquent |
| Agent d'analyse documentaire (intervalle 5-60 min) | 1 heure | Évite la réécriture due à l'expiration du cache |
| Tâches de traitement par lots (toutes les 30 min) | 1 heure | Le TTL de 5 min expirerait, 1 heure couvre parfaitement |
| Appels API basse fréquence (> 1 heure) | Aucun | Les deux TTL expireraient, coût d'écriture inutile |
| Invite système (presque statique) | 1 heure | Une seule écriture pour de multiples lectures |
| Historique de conversation (change à chaque tour) | 5 minutes | Coût d'écriture réduit pour des changements fréquents |
Formule de calcul des coûts
Pour déterminer si la mise en cache est rentable, voici la formule clé :
Rentabilité TTL 5 minutes : Le contenu doit être lu au moins 1 fois en 5 minutes
- Coût d'écriture : 1,25x → 0,25x supplémentaire
- Économie de lecture : 0,9x par lecture
- Rentable dès la 1ère lecture (0,9 > 0,25)
Rentabilité TTL 1 heure : Le contenu doit être lu au moins 2 fois en 1 heure
- Coût d'écriture : 2,0x → 1,0x supplémentaire
- Économie de lecture : 0,9x par lecture
- Rentable à partir de la 2ème lecture (0,9 × 2 = 1,8 > 1,0)
FAQ
Q1 : Est-il possible de passer le TTL de 5 minutes à 1 heure dans Claude Code ?
L'outil CLI Claude Code ne permet pas aux utilisateurs de modifier manuellement le TTL. Les abonnés Max bénéficient automatiquement d'un TTL d'une heure (géré par un indicateur de fonctionnalité côté serveur), tandis que les utilisateurs Pro et ceux utilisant une clé API sont limités à un TTL fixe de 5 minutes. Si vous avez besoin d'un TTL d'une heure sans passer à l'abonnement Max, vous pouvez effectuer des appels directement via l'API (en configurant cache_control.ttl: "1h") et payer à l'usage sur des plateformes comme APIYI (apiyi.com).
Q2 : Le TTL de 5 minutes expire-t-il systématiquement après 5 minutes ? Ou est-il automatiquement renouvelé ?
Le TTL de 5 minutes réinitialise le minuteur à chaque fois que le cache est sollicité. Si vous envoyez un message toutes les 1 à 2 minutes (comme lors d'une session de programmation avec Claude Code), le minuteur est constamment réinitialisé et le cache n'expire jamais. Le cache ne devient invalide que si vous restez inactif pendant 5 minutes consécutives. Pour les scénarios d'utilisation intensive, un TTL de 5 minutes est donc largement suffisant.
Q3 : La facturation du cache sur AWS Bedrock est-elle identique à celle de l’API officielle d’Anthropic ?
Elle est globalement similaire, avec quelques nuances :
- La surprime d'écriture est de ~1,25x (pour 5 minutes) et ~2,0x (pour 1 heure).
- La remise sur lecture est de ~0,1x.
- Différence notable : le TTL d'une heure sur Bedrock ne prend actuellement en charge que certains modèles comme Opus 4.5, Sonnet 4.5 et Haiku 4.5 ; pour les modèles de la série 4.6, il est nécessaire de vérifier la compatibilité.
- En passant par APIYI (apiyi.com), vous bénéficiez d'une prise en charge complète du cache, identique à celle de l'API officielle.
Résumé
Les points clés concernant le TTL du cache des invites Claude :
- Deux options de TTL : 5 minutes (écriture 1,25x, rentabilisé dès la 1ère lecture) et 1 heure (écriture 2x, rentabilisé dès la 2ème lecture), avec une lecture à 0,1x dans les deux cas.
- Le TTL est fixe dans Claude Code CLI : 1 heure pour les abonnés Max, 5 minutes pour les utilisateurs Pro/Clé API ; il ne peut pas être modifié, seulement désactivé.
- Liberté de choix via l'API Claude : Vous pouvez configurer le TTL via le paramètre
cache_control.ttlet même combiner les deux durées au sein d'une même requête. - Privilégiez 5 minutes pour les échanges fréquents : Le renouvellement automatique à chaque accès réduit les coûts d'écriture ; pour une utilisation intermittente, optez pour 1 heure afin d'éviter l'expiration.
Une correspondance dans le cache signifie une réduction de 90 % des coûts d'entrée, ce qui constitue le mécanisme d'économie le plus efficace pour Claude. Nous vous recommandons d'utiliser l'interface unifiée d'APIYI (apiyi.com) pour bénéficier d'une configuration complète du cache et tester les différences de coûts réelles entre les différentes stratégies de TTL avec une seule clé.
📚 Références
-
Documentation officielle d'Anthropic – Prompt Caching : Source faisant autorité sur la configuration TTL, les règles de facturation et la syntaxe
cache_control.- Lien :
platform.claude.com/docs/en/build-with-claude/prompt-caching - Description : Formules de facturation complètes et exemples de code pour les TTL de 5 minutes / 1 heure.
- Lien :
-
Documentation officielle d'Anthropic – Tarification : Prix de base et tarifs de mise en cache pour tous les modèles.
- Lien :
platform.claude.com/docs/en/about-claude/pricing - Description : Taux de facturation pour l'écriture et la lecture en cache pour les modèles Opus, Sonnet et Haiku.
- Lien :
-
Documentation officielle AWS – Bedrock Prompt Caching : Détails sur le support de la mise en cache sur la plateforme Bedrock.
- Lien :
docs.aws.amazon.com/bedrock/latest/userguide/prompt-caching.html - Description : Plages de support TTL et normes de facturation pour chaque modèle sur Bedrock.
- Lien :
-
Claude Code Camp – Fonctionnement du cache d'invites : Analyse approfondie de l'implémentation du cache dans Claude Code.
- Lien :
claudecodecamp.com/p/how-prompt-caching-actually-works-in-claude-code - Description : Découvrez comment Claude Code gère automatiquement les points de rupture du cache.
- Lien :
-
GitHub Issue #19436 – Demande de fonctionnalité TTL multi-niveaux : Discussions de la communauté sur une configuration TTL plus flexible.
- Lien :
github.com/anthropics/claude-code/issues/19436 - Description : Propositions de la communauté pour des solutions TTL multi-niveaux basées sur la fréquence de changement du contenu.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à partager vos expériences sur la configuration du cache Claude dans les commentaires. Pour plus de tutoriels sur l'invocation du modèle, consultez la documentation d'APIYI sur docs.apiyi.com.