
Nota del autor: Análisis detallado del mecanismo TTL de caché de Prompt en Claude Code, diferencias entre las opciones de 5 minutos y 1 hora, comparativa de facturación entre la API de Anthropic y AWS Bedrock, junto con recomendaciones para optimizar costes.
«¿Se puede cambiar el TTL de la caché de Prompt en Claude Code? ¿Qué diferencia hay entre 5 minutos y 1 hora? ¿Cuál es más rentable?» — Estas son las preguntas que más hacen los usuarios de Claude Code al intentar controlar sus costes.
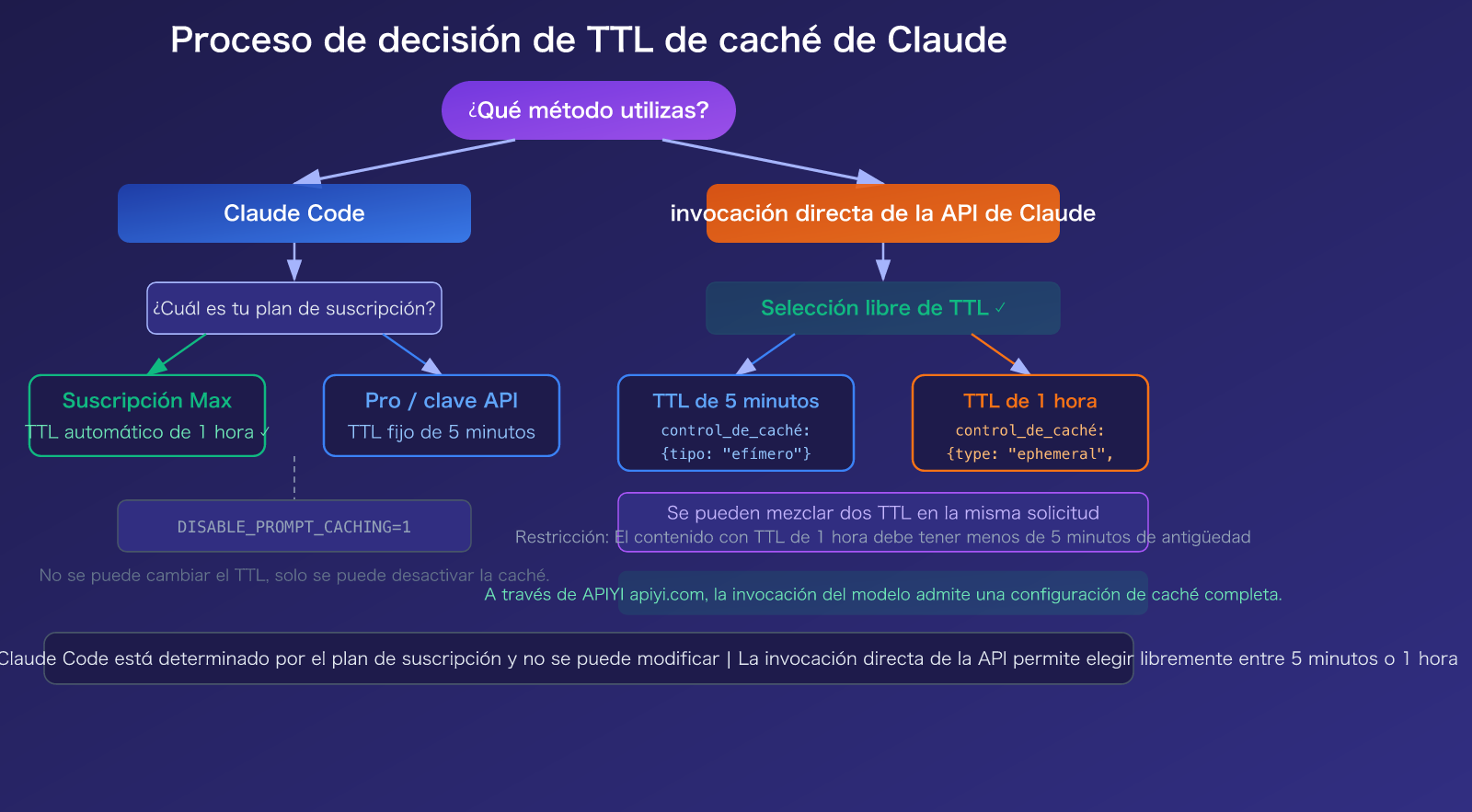
Vayamos directo al grano: El TTL de la caché de Claude Code no puede ser modificado directamente por el usuario; depende de tu plan de suscripción. Los usuarios con suscripción Max obtienen automáticamente un TTL de 1 hora, mientras que los usuarios con suscripción Pro y clave API tienen un TTL predeterminado de 5 minutos. Sin embargo, si invocas la API de Claude directamente, puedes elegir libremente entre 5 minutos o 1 hora mediante el parámetro cache_control.
Valor principal: Al terminar de leer este artículo, comprenderás a fondo el mecanismo TTL de la caché de Prompt de Claude, conocerás las diferencias de facturación entre la API oficial de Anthropic y AWS Bedrock, y aprenderás a elegir la estrategia de caché más económica según tu caso de uso.
Puntos clave del TTL de la caché de Prompt de Claude
La caché de Prompt es uno de los mecanismos de ahorro más importantes de la familia de modelos Claude. Almacena en el servidor el prefijo de tu Prompt enviado anteriormente (instrucciones del sistema, definiciones de herramientas, historial de chat, etc.). Si el prefijo es idéntico en la siguiente solicitud, se lee directamente desde la caché, pagando solo el 10% del precio normal de entrada.
| Punto clave | Descripción | Impacto real |
|---|---|---|
| Dos niveles de TTL | 5 minutos (predeterminado) y 1 hora (opcional) | Elegir el TTL correcto ahorra costes de escritura |
| Lectura de caché al 10% | Tras acertar la caché, esa parte de la entrada cuesta 0.1 veces el precio | Ahorra 80-90% en costes de entrada en chats largos |
| Escritura de 5 min = 1.25 veces | Se paga una prima del 25% al escribir en caché | Se amortiza con una sola lectura de caché |
| Escritura de 1 hora = 2 veces | Se paga el doble al escribir en caché | Requiere dos lecturas de caché para amortizarse |
| Gestión automática en Claude Code | Instrucciones del sistema, herramientas y CLAUDE.md se almacenan automáticamente | No requiere configuración manual |
¿Se puede cambiar el TTL en Claude Code?
Esta es la pregunta que más preocupa a los usuarios. La respuesta depende de dos situaciones:
Claude Code (herramienta CLI interactiva): No se puede modificar manualmente. La caché de Claude Code está controlada por el servidor: los usuarios con suscripción Max obtienen un TTL de 1 hora (controlado por el flag de función del servidor tengu_prompt_cache_1h_config), mientras que los usuarios con suscripción Pro y clave API obtienen 5 minutos. Solo puedes desactivar la caché por completo mediante la variable de entorno DISABLE_PROMPT_CACHING=1, pero no puedes cambiar el nivel de TTL.
Claude API (invocación directa): Se puede elegir libremente. Al invocar mediante la API, puedes especificar el TTL en el parámetro cache_control:
// Caché de 5 minutos (predeterminado)
{ "cache_control": { "type": "ephemeral" } }
// Caché de 1 hora
{ "cache_control": { "type": "ephemeral", "ttl": "1h" } }
🎯 Recomendación: Si utilizas principalmente Claude Code CLI, el TTL depende de tu plan de suscripción. Si realizas invocaciones mediante API (como a través de APIYI apiyi.com), puedes elegir flexiblemente entre 5 minutos o 1 hora según el escenario, logrando un control de costes más preciso.
Explicación detallada de las reglas de facturación del TTL de caché de prompts de Claude
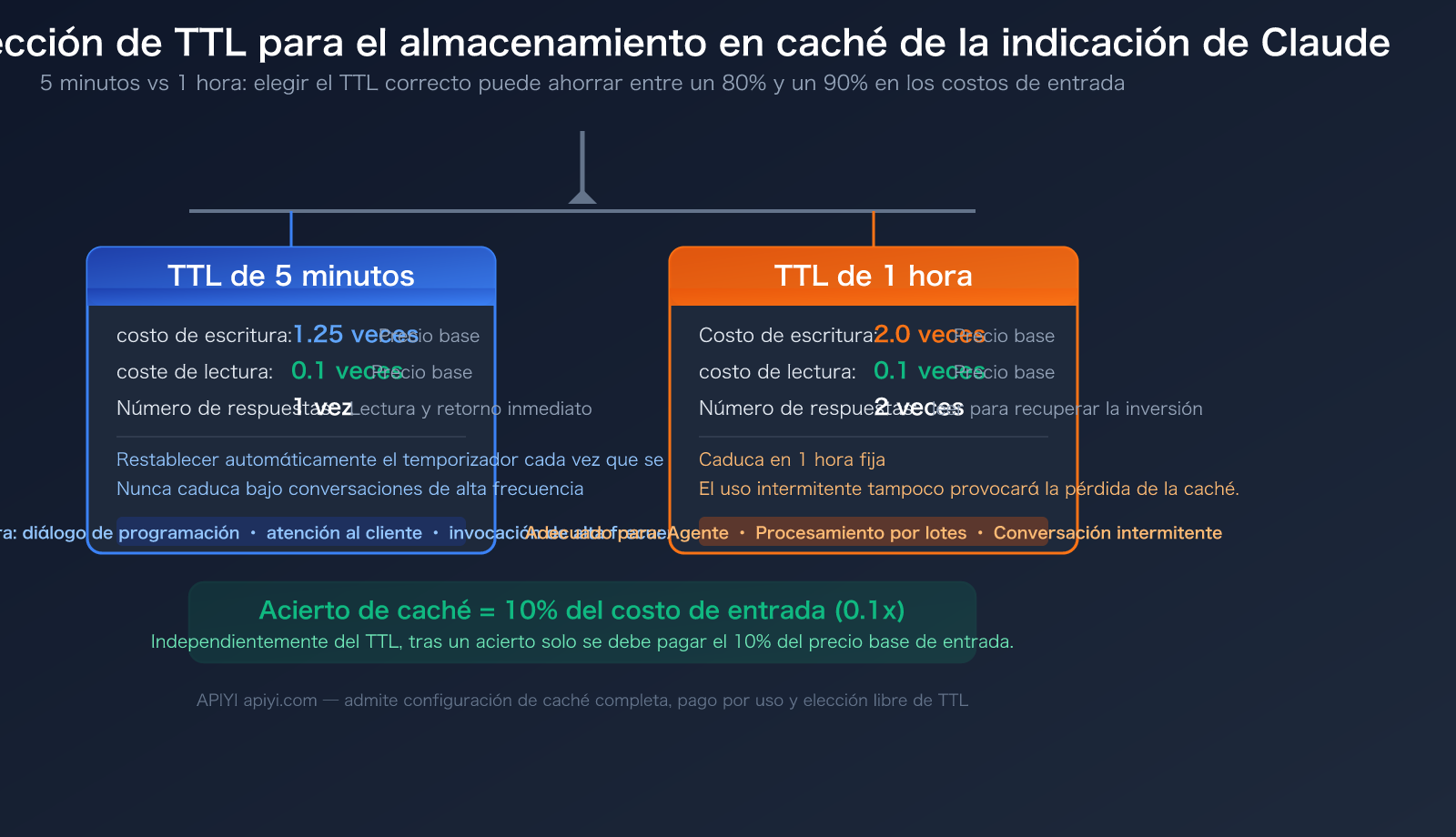
5 minutos vs 1 hora: Comparativa de costes
La diferencia fundamental entre los dos TTL radica en el coste de escritura. El coste de lectura es exactamente el mismo: 0,1 veces el precio base de entrada.
| Operación | TTL de 5 minutos | TTL de 1 hora | Descripción |
|---|---|---|---|
| Escritura en caché | 1,25 veces el precio base | 2,0 veces el precio base | Sobrecarga al escribir en caché por primera vez |
| Lectura de caché | 0,1 veces el precio base | 0,1 veces el precio base | Precio con descuento tras acertar en caché (igual) |
| Punto de equilibrio | 1 lectura para recuperar | 2 lecturas para recuperar | La frecuencia de uso determina cuál es más rentable |
| Renovación automática | Se reinicia a 5 min con cada acierto | Caduca fijo a 1 hora | En chats de alta frecuencia, 5 min puede durar indefinidamente |
Precios específicos de caché de prompts por modelo
A continuación, la tabla completa de facturación de caché para los modelos de la API oficial de Anthropic (marzo de 2026):
| Modelo | Precio base entrada | Escritura 5 min | Escritura 1 hora | Lectura caché | Precio salida |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $6,25/MTok | $10/MTok | $0,50/MTok | $25/MTok |
| Claude Sonnet 4.6 | $3/MTok | $3,75/MTok | $6/MTok | $0,30/MTok | $15/MTok |
| Claude Haiku 4.5 | $1/MTok | $1,25/MTok | $2/MTok | $0,10/MTok | $5/MTok |
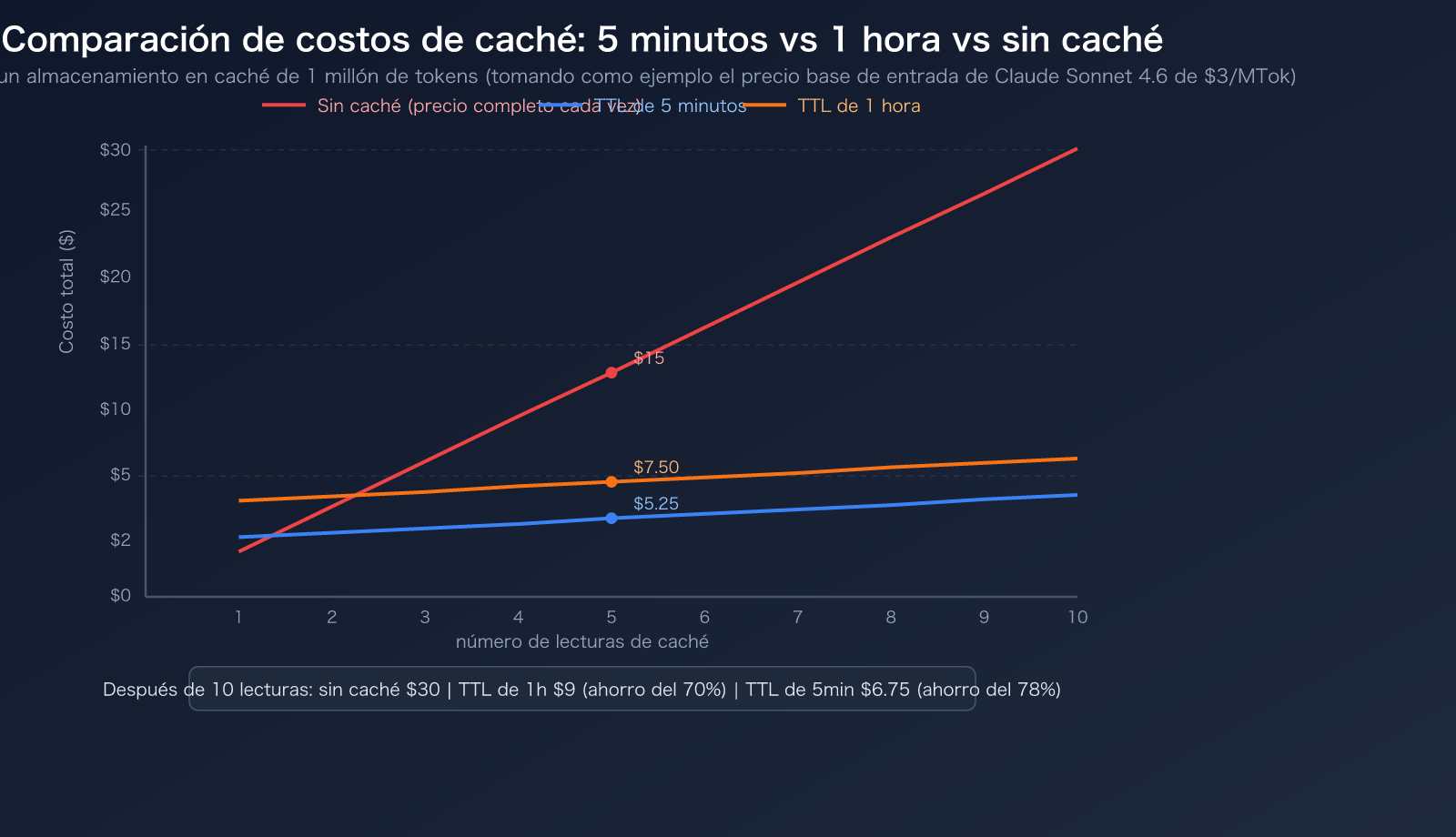
Hallazgo clave: El descuento por lectura de caché es sorprendente. Tomando como ejemplo Claude Opus 4.6:
- Entrada normal de 1 millón de tokens = $5,00
- Lectura de caché de 1 millón de tokens = $0,50 (ahorro de $4,50, 90% de descuento)
- Esta es la razón por la que la suscripción de $20 de Claude Code Pro es económicamente viable: 100 rondas de chat con Opus sin caché podrían costar entre $50 y $100, mientras que con caché solo cuestan entre $10 y $19.
Requisito mínimo de tokens para caché
No todo el contenido puede ser almacenado en caché. Cada modelo tiene un requisito mínimo de tokens; si el contenido no es lo suficientemente largo, no se activará la caché:
| Modelo | Mínimo de tokens para caché |
|---|---|
| Claude Opus 4.6 / 4.5 | 4.096 |
| Claude Sonnet 4.6 | 2.048 |
| Claude Sonnet 4.5 / 4 | 1.024 |
| Claude Haiku 4.5 | 4.096 |
| Claude Haiku 3.5 / 3 | 2.048 |
🎯 Consejo práctico: Si tu indicación del sistema es corta (por ejemplo, menos de 2.048 tokens), no se activará la caché al usar Claude Sonnet 4.6. Puedes alcanzar el umbral mínimo enriqueciendo el contenido de la indicación del sistema o combinando definiciones de herramientas. Al realizar la invocación del modelo a través de APIYI (apiyi.com), también se admite la caché con tarifas aún más competitivas.
Anthropic API vs AWS Bedrock: Comparativa de facturación de caché
Comparativa de soporte de caché entre las tres grandes plataformas
La caché de prompts de Claude es compatible con la API oficial de Anthropic, AWS Bedrock y Google Vertex AI, aunque existen diferencias en los detalles:
| Dimensión de comparación | API oficial de Anthropic | AWS Bedrock | Google Vertex AI |
|---|---|---|---|
| TTL de 5 minutos | ✅ Compatible en todos | ✅ Compatible en todos | ✅ Compatible en todos |
| TTL de 1 hora | ✅ Compatible en todos | ✅ Algunos modelos (Opus 4.5, Sonnet 4.5, Haiku 4.5) | ✅ Compatible |
| Sobrecarga escritura (5 min) | 1,25 veces | ~1,25 veces | 1,25 veces |
| Sobrecarga escritura (1 hora) | 2,0 veces | 2,0 veces | 2,0 veces |
| Descuento de lectura | 0,1 veces | ~0,1 veces | 0,1 veces |
| Máximo de puntos de ruptura | 4 | 4 | 4 |
| Caché automática | ✅ Compatible | ✅ Compatible | ✅ Compatible |
| TTL personalizado | ✅ Opción 5 min/1 hora | ✅ Opción (algunos modelos) | ✅ Opción |
Explicación de las diferencias clave entre plataformas
API oficial de Anthropic: La funcionalidad de caché es la más completa; todos los modelos admiten los dos niveles de TTL (5 minutos y 1 hora). Desde el 5 de febrero de 2026, el aislamiento de la caché cambió del nivel de organización al nivel de espacio de trabajo; la caché de diferentes espacios de trabajo dentro de la misma organización es independiente.
AWS Bedrock: En enero de 2026 se anunció la compatibilidad con el TTL de 1 hora, pero limitado a ciertos modelos como Claude Opus 4.5, Sonnet 4.5 y Haiku 4.5. La compatibilidad con el TTL de 1 hora para los nuevos Claude Sonnet 4.6 y Opus 4.6 en Bedrock aún debe confirmarse. Si conectas Claude Code a Bedrock, ten en cuenta la configuración de compatibilidad CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1.
Google Vertex AI: La funcionalidad de caché es básicamente idéntica a la de la API oficial, pero requiere autenticación y facturación a través de un proyecto de Google Cloud.
🎯 Sugerencia de elección de plataforma: Si no quieres complicarte con las diferencias entre plataformas y configuraciones de compatibilidad, la forma más sencilla es utilizar la interfaz unificada de APIYI (apiyi.com), que admite la funcionalidad completa de caché sin necesidad de configurar por separado AWS IAM o la autenticación de Google Cloud.
Guía rápida de caché de indicaciones para Claude Code
Ejemplo minimalista: Configuración de caché con TTL de 1 hora
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": "Eres un asistente profesor de física profesional, encargado de resolver problemas de física de bachillerato...(aquí va una indicación de sistema larga)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
}],
messages=[{"role": "user", "content": "Explica la tercera ley de Newton"}]
)
print(f"Tokens leídos de caché: {response.usage.cache_read_input_tokens}")
print(f"Tokens escritos en caché: {response.usage.cache_creation_input_tokens}")
Ver código completo: Uso mixto de TTL de 5 minutos y 1 hora
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# TTL mixto: 1 hora para la indicación de sistema (poco frecuente), 5 minutos para el contexto de la conversación (cambia frecuentemente)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "Eres un consultor técnico de IA profesional...(indicación de sistema larga, más de 2000 tokens)",
"cache_control": {"type": "ephemeral", "ttl": "1h"} # 1 hora para la indicación de sistema
},
{
"type": "text",
"text": "A continuación se muestra el contexto del historial de conversación del usuario...(historial de conversación)",
"cache_control": {"type": "ephemeral"} # 5 minutos para el contexto de la conversación (por defecto)
}
],
messages=[{"role": "user", "content": "Compara las capacidades de razonamiento de Claude y GPT"}]
)
# Ver uso de caché
usage = response.usage
print(f"Tokens de entrada normales: {usage.input_tokens}")
print(f"Tokens leídos de caché: {usage.cache_read_input_tokens}")
print(f"Tokens escritos en caché: {usage.cache_creation_input_tokens}")
# Calcular ahorro (usando Sonnet 4.6 como ejemplo)
base_cost = (usage.input_tokens / 1_000_000) * 3
cache_cost = (usage.cache_read_input_tokens / 1_000_000) * 0.3
saved = (usage.cache_read_input_tokens / 1_000_000) * 2.7
print(f"Ahorro en esta sesión: ${saved:.4f}")
Restricción importante: Al mezclar dos tipos de TTL en una misma solicitud, el contenido con caché de 1 hora debe colocarse antes que el contenido con caché de 5 minutos; de lo contrario, se devolverá un error.
Sugerencia: Al invocar la API de Claude a través de APIYI (apiyi.com), se admite completamente la configuración del parámetro
cache_control, permitiendo elegir libremente entre TTL de 5 minutos y 1 hora.
TTL de 5 minutos vs 1 hora: ¿Cuál elegir?
Tabla de decisiones
| Escenario de uso | TTL recomendado | Razón |
|---|---|---|
| Programación de alta frecuencia con Claude Code | 5 minutos | El temporizador se reinicia automáticamente con cada acierto, nunca caduca |
| Chatbot de atención al cliente (intervalo < 5 min) | 5 minutos | Costo de escritura bajo (1.25x), alta frecuencia de aciertos |
| Agente de análisis de documentos (intervalo 5-60 min) | 1 hora | Evita la reescritura por caducidad de caché |
| Tareas de procesamiento por lotes (cada 30 min) | 1 hora | El TTL de 5 min caducaría, 1 hora cubre el ciclo |
| Llamadas a API de baja frecuencia (intervalo > 1 h) | Sin caché | Ambos TTL caducarían, desperdiciando el costo de escritura |
| Indicaciones de sistema (casi estáticas) | 1 hora | Se escribe una vez y se lee múltiples veces |
| Historial de conversación (cambia en cada turno) | 5 minutos | El costo de escritura bajo es más rentable ante cambios frecuentes |
Fórmulas de cálculo de costos
Para determinar si la caché es rentable, la fórmula clave es:
Condición de rentabilidad para TTL de 5 minutos: El contenido se lee al menos 1 vez en 5 minutos.
- Costo de escritura: 1.25x → 0.25x adicional.
- Ahorro por lectura: 0.9x por cada vez.
- Se recupera la inversión con 1 lectura (0.9 > 0.25).
Condición de rentabilidad para TTL de 1 hora: El contenido se lee al menos 2 veces en 1 hora.
- Costo de escritura: 2.0x → 1.0x adicional.
- Ahorro por lectura: 0.9x por cada vez.
- Se recupera la inversión con 2 lecturas (0.9 × 2 = 1.8 > 1.0).
Preguntas frecuentes
Q1: ¿Se puede cambiar el TTL de 5 minutos a 1 hora en Claude Code?
La herramienta CLI de Claude Code no permite que los usuarios modifiquen el TTL manualmente. Los suscriptores de Max obtienen automáticamente un TTL de 1 hora (controlado mediante un feature flag del servidor), mientras que los usuarios de Pro y de clave API tienen un TTL fijo de 5 minutos. Si necesitas un TTL de 1 hora pero no quieres actualizar tu suscripción a Max, puedes realizar la invocación del modelo directamente a través de la API (configurando cache_control.ttl: "1h") utilizando plataformas como APIYI (apiyi.com) con pago por uso.
Q2: ¿El TTL de 5 minutos caduca exactamente a los 5 minutos o se renueva automáticamente?
El TTL de 5 minutos reinicia el temporizador cada vez que se produce un acierto de caché. Si envías un mensaje cada 1 o 2 minutos (por ejemplo, en una sesión de programación con Claude Code), el temporizador se reinicia constantemente y la caché nunca caduca. La caché solo se invalida si dejas de enviar mensajes durante 5 minutos consecutivos. Por lo tanto, para escenarios de uso frecuente, el TTL de 5 minutos es más que suficiente.
Q3: ¿La facturación de caché en AWS Bedrock es igual a la de la API oficial de Anthropic?
Es prácticamente igual, pero con ligeras diferencias:
- La sobrecarga de escritura es de ~1.25x (5 minutos) y ~2.0x (1 hora).
- El descuento por lectura es de ~0.1x.
- Diferencia: El TTL de 1 hora en Bedrock actualmente solo es compatible con algunos modelos como Opus 4.5, Sonnet 4.5 y Haiku 4.5; para la serie 4.6 más reciente, es necesario verificar la disponibilidad.
- Al realizar la invocación del modelo a través de APIYI (apiyi.com), obtienes soporte completo de caché, igual al de la API oficial.
Resumen
Puntos clave sobre el TTL de la caché de indicaciones de Claude:
- Dos niveles de TTL disponibles: 5 minutos (escritura 1.25x, se amortiza con 1 lectura) y 1 hora (escritura 2x, se amortiza con 2 lecturas); en ambos casos, la lectura cuesta 0.1x.
- Claude Code CLI no permite cambiar el TTL: Los suscriptores de Max tienen 1 hora automáticamente, mientras que los de Pro/clave API tienen 5 minutos fijos; solo se puede desactivar, no cambiar.
- La API de Claude permite elegir libremente: Se configura mediante el parámetro
cache_control.ttl, pudiendo incluso mezclar ambos TTL en una misma solicitud. - Para conversaciones frecuentes, elige 5 minutos: Se renueva automáticamente con cada acierto, lo que reduce los costos de escritura; para usos intermitentes, elige 1 hora para evitar la caducidad.
Un acierto de caché significa reducir el costo de entrada al 10%, siendo este el mecanismo de ahorro más importante de Claude. Recomendamos utilizar la interfaz unificada de APIYI (apiyi.com), que ofrece soporte completo para la configuración de caché, permitiéndote probar la diferencia de costos real entre distintas estrategias de TTL con una sola clave API.
📚 Referencias
-
Documentación oficial de Anthropic – Prompt Caching: Fuente autorizada sobre la configuración de TTL, reglas de facturación y sintaxis de
cache_control.- Enlace:
platform.claude.com/docs/en/build-with-claude/prompt-caching - Descripción: Fórmulas de facturación completas y ejemplos de código para TTL de 5 minutos/1 hora.
- Enlace:
-
Documentación oficial de Anthropic – Precios: Precios base y precios de caché para todos los modelos.
- Enlace:
platform.claude.com/docs/en/about-claude/pricing - Descripción: Tarifas de escritura y lectura de caché para los modelos Opus, Sonnet y Haiku.
- Enlace:
-
Documentación oficial de AWS – Bedrock Prompt Caching: Detalles sobre el soporte de caché en la plataforma Bedrock.
- Enlace:
docs.aws.amazon.com/bedrock/latest/userguide/prompt-caching.html - Descripción: Rango de soporte de TTL y estándares de facturación para los modelos en Bedrock.
- Enlace:
-
Claude Code Camp – Cómo funciona el caché de indicaciones: Análisis profundo sobre la implementación de caché en Claude Code.
- Enlace:
claudecodecamp.com/p/how-prompt-caching-actually-works-in-claude-code - Descripción: Entiende cómo Claude Code gestiona automáticamente los puntos de interrupción de caché.
- Enlace:
-
GitHub Issue #19436 – Solicitud de función de TTL de caché multinivel: Discusión de la comunidad sobre configuraciones de TTL más flexibles.
- Enlace:
github.com/anthropics/claude-code/issues/19436 - Descripción: Propuestas de la comunidad sobre esquemas de TTL multinivel basados en la frecuencia de cambio de contenido.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a discutir tus experiencias con la configuración de caché de Claude en la sección de comentarios. Para más tutoriales sobre la invocación del modelo, visita el centro de documentación de APIYI en docs.apiyi.com.