
Cuando Google DeepMind lanzó Nano Banana Pro el 20 de noviembre de 2025, hicieron hincapié en una frase: "las áreas intactas permanecen perfectas a nivel de píxel; sin deriva en la generación, sin pérdida de calidad en ediciones iterativas". Si lo tomas al pie de la letra, parece que la IA ha logrado una "modificación local real al estilo Photoshop". Pero si conoces la arquitectura de Gemini 3 Pro Image, descubrirás que, en esencia, es un redibujado completo mediante un Transformer autorregresivo, el mismo mecanismo que usan los modelos de texto para predecir el siguiente token.
¿Cómo pueden ser ciertas ambas cosas? ¿El principio de generación de imágenes de Nano Banana Pro está redibujando toda la imagen o realizando una modificación local real? Este artículo desglosa el funcionamiento desde cuatro niveles: el núcleo de inferencia de Gemini 3, la autorregresión de tokens visuales, las restricciones rígidas de máscara y el posicionamiento semántico mediante Bounding Box, ofreciendo una comprensión técnica que realmente podrás aplicar.
| Pregunta clave | Respuesta intuitiva | Realidad |
|---|---|---|
| ¿Es una modificación local tipo PS? | Sí | No, el núcleo sigue siendo redibujado de tokens |
| ¿Por qué es pixel-perfect? | El modelo es inteligente | Tres restricciones: Máscara + Posicionamiento semántico + BBox |
| ¿Es del mismo origen que GPT-Image-2? | Similar | Ambos son autorregresivos, pero Gemini 3 añade inferencia explícita |
| ¿Habrá deriva en ediciones múltiples? | Sí | Casi nula, es el punto fuerte de Pro |
Al comprender esta lógica subyacente, podrás redactar indicaciones que realmente activen la inferencia de Gemini 3, elegir modos de máscara razonables y evitar la trampa de "parece local pero es un redibujado". Recomendamos a los lectores probar esto combinando la plataforma APIYI (apiyi.com) con la interfaz de Nano Banana Pro, mapeando cada principio con los resultados reales.
Principio de generación de imágenes de Nano Banana Pro: ¿Redibujado completo o modificación local real?
Antes de responder, debemos distinguir dos conceptos que suelen confundirse: el mecanismo de generación y la experiencia de uso.
Desde el mecanismo de generación, Nano Banana Pro y sus predecesores, así como el GPT-Image-2 de OpenAI, siguen la misma ruta: redibujado de tokens de imagen mediante un Transformer autorregresivo. En otras palabras, incluso si solo pides a la IA que cambie el color de la corbata de alguien, el modelo comprime internamente toda la imagen en tokens visuales, vuelve a predecir toda la secuencia de tokens de principio a fin y, finalmente, decodifica de nuevo a píxeles. No existe una ruta física de "mover solo un pequeño grupo de píxeles y dejar el resto intacto".
Sin embargo, desde la experiencia de uso, Nano Banana Pro ofrece al usuario una sensación de "modificación casi local". Google afirma explícitamente: en modo máscara o posicionamiento semántico, las áreas no editadas se conservan casi a nivel de píxel, sin deriva de generación y sin pérdida de calidad en ediciones múltiples. ¿Cómo se logra esta experiencia desde una arquitectura de "redibujado completo"?
La respuesta es: ingeniería de restricciones (constraint engineering). Google ha superpuesto tres capas de restricciones rígidas sobre el flujo de generación autorregresiva: bloqueo de tokens de máscara, especificación de áreas mediante Bounding Box y una "lista de reserva" semántica de Gemini 3. Estas tres capas obligan al modelo a "elegir activamente" reproducir los tokens de las áreas no editadas durante el redibujado. Ese es el verdadero trabajo del equipo de ingeniería de Nano Banana Pro.
Relación entre la lógica de redibujado y la experiencia de modificación local
| Perspectiva | Situación real | Percepción del usuario |
|---|---|---|
| Arquitectura base | Redibujado de tokens de toda la imagen | Parece una modificación local |
| Áreas no editadas | Tokens regenerados | Casi idénticos a los píxeles originales |
| Bordes de edición | Generación continua autorregresiva | Transición natural sin artefactos |
| Instrucciones de edición | Pasadas mediante restricciones | Coincidencia automática de luces/perspectiva |
Al entender esta separación entre "mecanismo y experiencia", podrás explicar por qué a veces las áreas no editadas de una imagen editada con Nano Banana Pro presentan cambios mínimos; es el precio inevitable del redibujado de tokens, pero Google ha logrado reducir ese cambio a un nivel casi imperceptible. Recomendamos usar la plataforma APIYI (apiyi.com) para editar repetidamente la misma imagen con Nano Banana Pro y observar la magnitud de la deriva en los detalles; esta comparación hará que el principio sea mucho más claro.
Principio de funcionamiento de Nano Banana Pro: El backbone autorregresivo de Gemini 3 Pro Image
Para comprender a fondo el principio de funcionamiento de Nano Banana Pro, es imposible pasar por alto su nombre oficial: Gemini 3 Pro Image. Este nombre revela sus dos linajes fundamentales: el backbone de razonamiento Gemini 3 y el decodificador de generación de imágenes.
Gemini 3 es el Modelo de Lenguaje Grande multimodal insignia que Google lanzó apenas dos días antes de Nano Banana Pro, famoso por su "capacidad de razonamiento". Nano Banana Pro reutiliza directamente el backbone Transformer de Gemini 3 Pro, simplemente añadiendo tokens visuales al vocabulario y conectando un decodificador de imágenes en la salida. En otras palabras, no es un modelo de imagen independiente, sino una variante de la familia multimodal Gemini 3 especializada en la generación de imágenes.
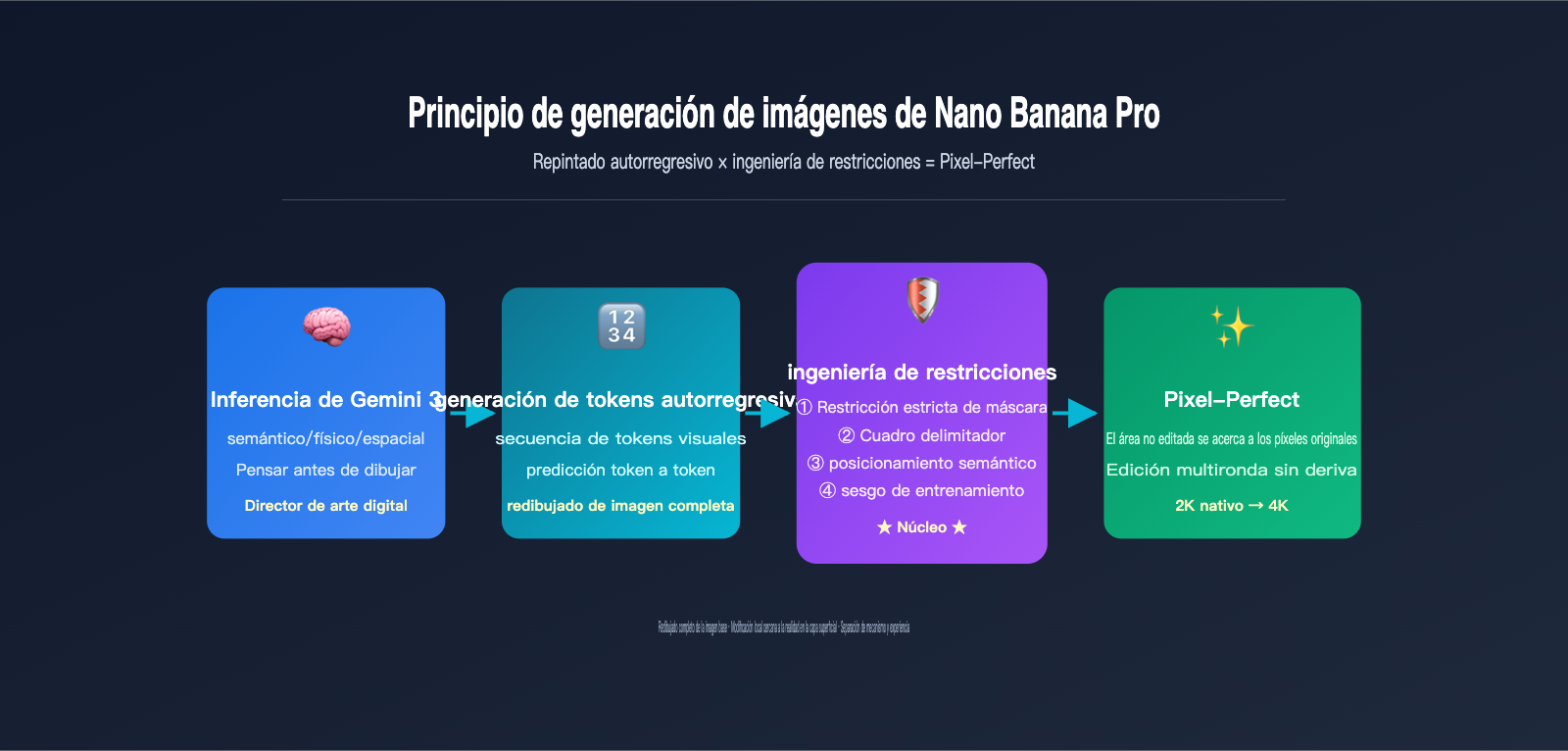
Esto conlleva un cambio fundamental: antes de dibujar el primer píxel, Nano Banana Pro utiliza el razonamiento de Gemini 3 para determinar "qué debe dibujar". Como dice Google, "funciona menos como un modelo de difusión tradicional y más como un director de arte digital": primero analiza la lógica semántica, la causalidad física y las relaciones espaciales de la indicación, y solo después entra en la fase de generación de tokens visuales.
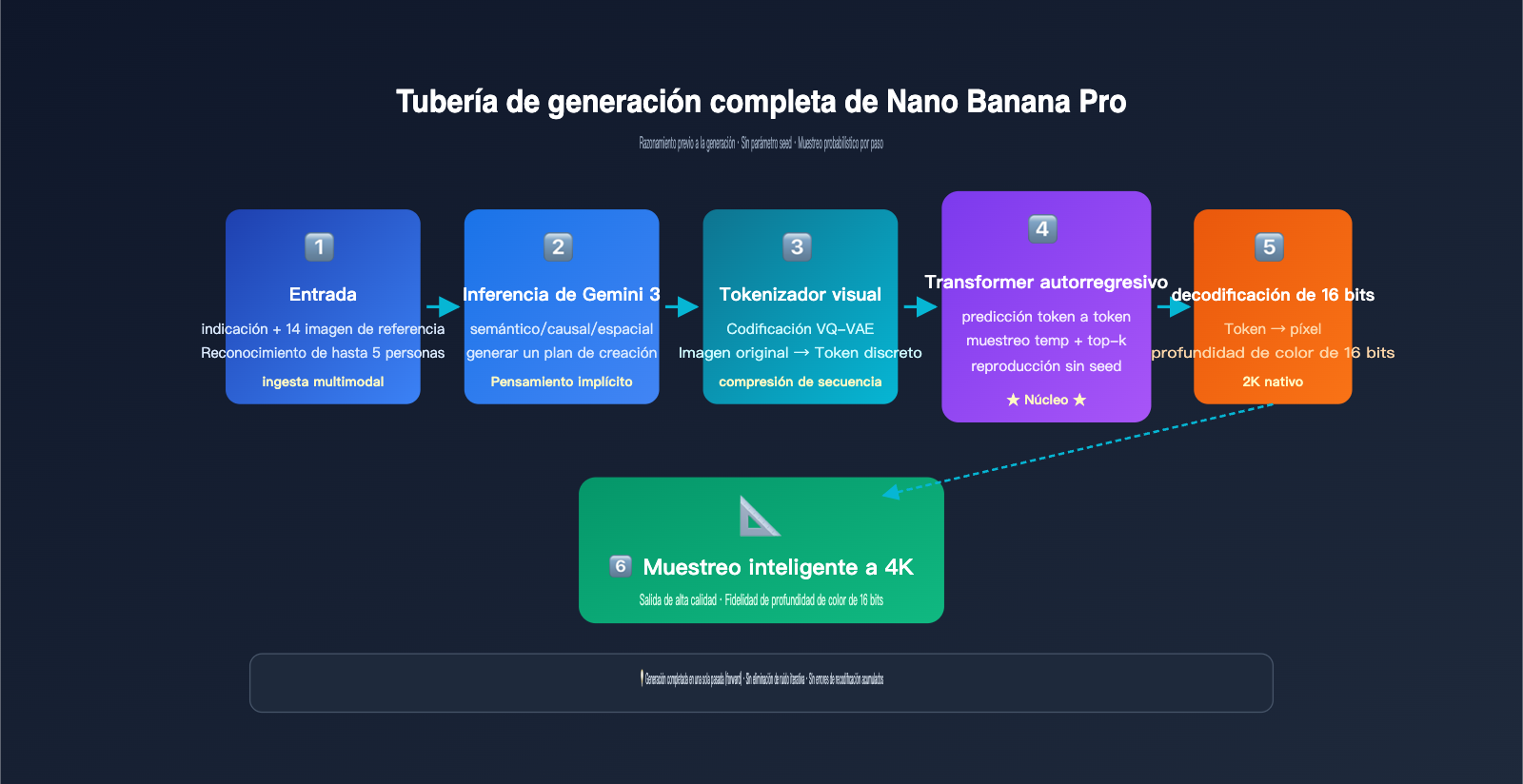
El flujo de trabajo específico se puede dividir en cinco etapas:
- Análisis de entrada multimodal: El backbone de razonamiento de Gemini 3 ingiere simultáneamente la indicación de texto del usuario y hasta 14 imágenes de referencia para comprender el contexto completo de la tarea.
- Razonamiento estructurado (plano interno): El modelo primero "reflexiona" internamente sobre la disposición espacial de la escena, la identidad de los personajes, la configuración de la iluminación y qué partes deben conservarse o modificarse, generando un "plano creativo" invisible.
- Codificación de tokens visuales de la imagen original: Las imágenes de referencia se comprimen en una secuencia de tokens visuales mediante un mecanismo de discretización similar a VQ-VAE.
- Predicción de tokens autorregresivos: Bajo el mecanismo de atención del backbone de Gemini 3, el modelo predice uno a uno los tokens visuales de la imagen de salida de izquierda a derecha, pudiendo "ver" la indicación completa y los tokens de la imagen original en cada paso.
- Decodificación y sobremuestreo: Los tokens de salida se restauran a una imagen 2K nativa mediante un decodificador de 16 bits de profundidad de color, y luego se realiza un sobremuestreo inteligente a 4K.
Dos capacidades únicas del backbone de razonamiento de Gemini 3
La primera es "pensar antes de dibujar". Esto no es un truco publicitario: la capacidad de razonamiento de Gemini 3 en tareas de texto se transfiere directamente a la generación de imágenes. Si le das una instrucción compleja como "cambia la ropa de esta persona por una que se ajuste a su profesión", un modelo de imagen convencional se confundiría, mientras que Nano Banana Pro razonará primero: "esta persona parece médico → debería llevar una bata blanca", y luego procederá a dibujarla.
La segunda es Grounding con la Búsqueda de Google. Nano Banana Pro puede invocar herramientas de búsqueda de Google durante el proceso de generación para verificar hechos; por ejemplo, si le pides que dibuje "el producto más reciente lanzado por una marca", puede conectarse a Internet para obtener referencias visuales reales. Es el único modelo de generación de imágenes que admite grounding con búsqueda nativa, lo cual es una de las mayores capacidades diferenciadoras entre Nano Banana Pro y GPT-Image-2. Si necesitas probar la capacidad de Grounding en un entorno de producción, puedes acceder a Nano Banana Pro a través de APIYI (apiyi.com), plataforma que ofrece especificaciones de interfaz consistentes con las oficiales de Google.
Cabe mencionar que Nano Banana Pro no admite el parámetro seed. Debido a que es una generación autorregresiva, cada paso de muestreo se toma de una distribución de probabilidad (controlada por temperatura y top-k), a diferencia de los modelos de difusión que pueden reproducir resultados exactamente fijando el ruido inicial. Esta característica es tanto una restricción como una elección de diseño, permitiendo que el modelo mantenga su creatividad.
Las 4 restricciones clave para la edición parcial de imágenes con IA: ¿Cómo lograr la perfección a nivel de píxel?
Dado que el proceso subyacente es un redibujado de la imagen completa, ¿cómo logra Nano Banana Pro garantizar que las áreas no editadas sean prácticamente perfectas a nivel de píxel? La respuesta reside en las cuatro capas de mecanismos de restricción que Google ha superado en sus escenarios de edición parcial de imágenes con IA. Esta es la innovación de ingeniería más destacable de la versión Pro frente a la versión básica de Nano Banana.
Primera capa: Restricción rígida de máscara (Mask). Es el método más directo: el usuario proporciona una máscara en blanco y negro del mismo tamaño; las áreas blancas permiten que la IA genere nuevos tokens, mientras que las áreas negras fuerzan al modelo a copiar los tokens originales de la imagen. Esto equivale a añadir una "regla de copia rígida" durante la generación autorregresiva. Es la fuente técnica fundamental de lo que Google denomina "áreas intactas perfectas a nivel de píxel".
Segunda capa: Posicionamiento mediante cuadro delimitador (Bounding Box). Nano Banana Pro admite parámetros de cuadro delimitador con coordenadas normalizadas de 0 a 1000. Puedes indicarle al modelo: "modifica solo dentro del rectángulo de (200, 300) a (600, 500)". El sistema convierte automáticamente el BBox en una restricción de máscara interna, lo cual es mucho más ágil que dibujar una máscara manualmente.
Tercera capa: Posicionamiento semántico con Gemini 3. Esta es la capa más "mágica". Solo necesitas usar lenguaje natural como "cambia el fondo por una playa", y el motor de razonamiento de Gemini 3 identifica automáticamente qué tokens corresponden al "fondo" en la imagen, generando una máscara implícita. Este modo de edición sin máscaras cubre la mayoría de los escenarios de edición mencionados oficialmente por Google.
Cuarta capa: Sesgo de "lo no mencionado se conserva" en los datos de entrenamiento. Google utilizó una enorme cantidad de datos emparejados de "imagen original-imagen editada", permitiendo que el modelo aprendiera una regla implícita durante el entrenamiento: a menos que la indicación solicite explícitamente un cambio, las demás áreas deben copiar la imagen original token por token tanto como sea posible. Este sesgo está consolidado en los pesos y se aplica automáticamente durante la inferencia.
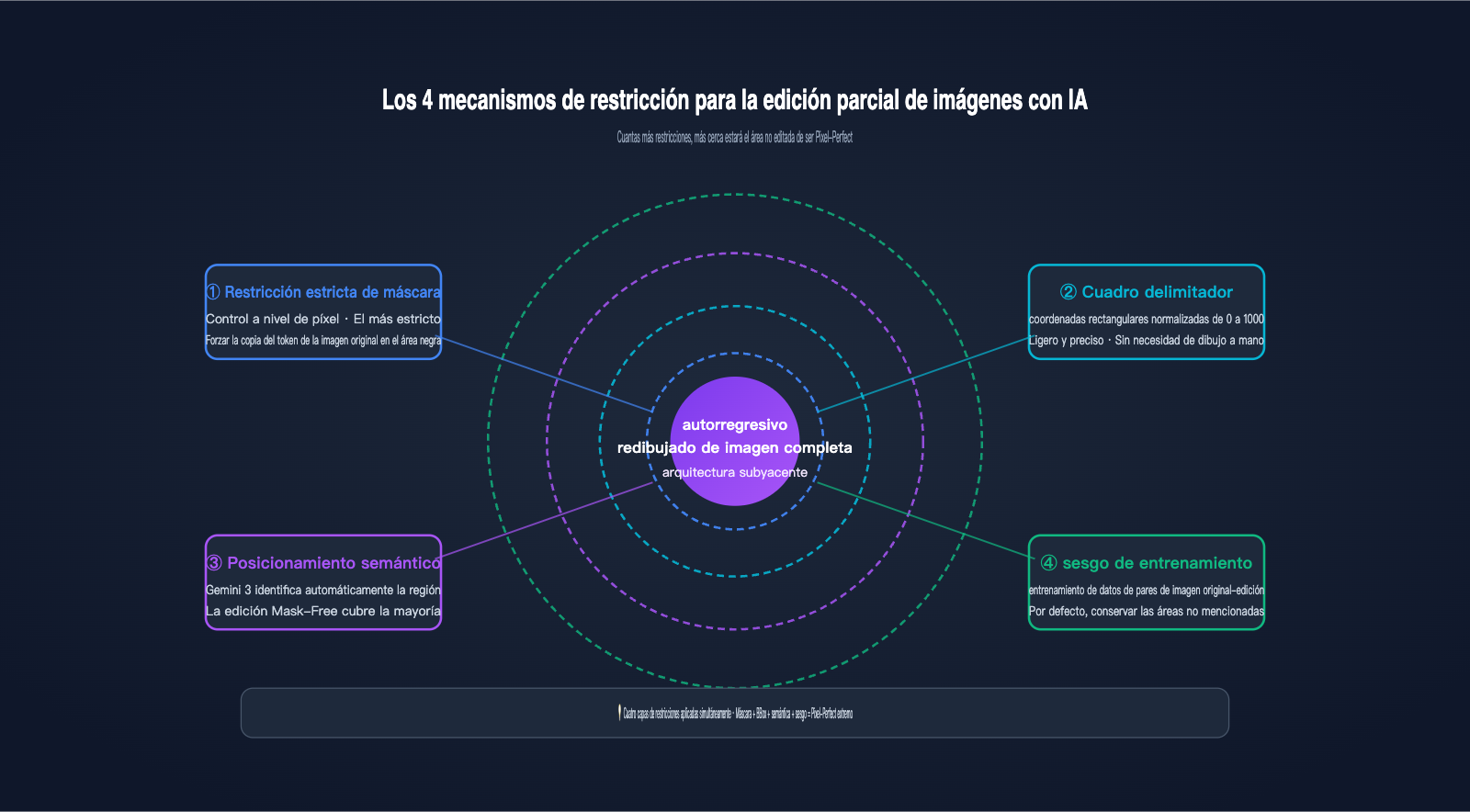
Comparativa de los 4 mecanismos de restricción
| Mecanismo de restricción | Granularidad de control | Coste para el usuario | Escenario de aplicación |
|---|---|---|---|
| Restricción rígida de máscara | Nivel de píxel | Requiere dibujar máscara | Reparación precisa/sustitución |
| Cuadro delimitador | Área rectangular | Solo transmitir coordenadas | Edición en áreas rectangulares conocidas |
| Posicionamiento semántico | Objeto semántico | Solo instrucciones de texto | La mayoría de ediciones cotidianas |
| Sesgo de entrenamiento | Global | Sin configuración | Activado por defecto en todos los escenarios |
Las cuatro capas de restricción no son excluyentes, sino que se aplican de forma superpuesta. La combinación más estricta es "Máscara + Cuadro delimitador + Instrucción semántica", lo que lleva la experiencia de perfección a nivel de píxel de Nano Banana Pro al límite. En nuestras pruebas en APIYI (apiyi.com), descubrimos que incluso utilizando solo el posicionamiento semántico y el sesgo de entrenamiento, se puede lograr una consistencia casi indistinguible a simple vista en la mayoría de las ediciones diarias.
Razones técnicas para la ausencia de deriva en ediciones multironda
Uno de los puntos clave de marketing de Nano Banana Pro es la "ausencia de pérdida de calidad acumulada en ediciones multironda". Hay dos razones: primero, la arquitectura autorregresiva en sí misma no requiere que el modelo de difusión codifique y decodifique repetidamente mediante VAE; solo hay una conversión de token a píxel, por lo que no se acumulan errores de recodificación. Segundo, la restricción rígida de máscara permite que las áreas no editadas copien la imagen original token por token, lo que apenas introduce aleatoriedad incluso tras múltiples iteraciones.
Esto contrasta fuertemente con el inpainting repetido de Stable Diffusion, que se vuelve "borroso" tras varios intentos. Si tu flujo de trabajo requiere de 5 a 10 rondas de edición sobre la misma imagen base, Nano Banana Pro es casi el único modelo capaz de soportarlo actualmente.
Gemini 3 Pro Image vs GPT-Image-2: Diferenciación de rutas
Muchos equipos siguen de cerca tanto a Gemini 3 Pro Image (Nano Banana Pro) como a GPT-Image-2 de OpenAI. Aunque ambos son autorregresivos en su base, tienen enfoques y capacidades distintos.
GPT-Image-2 enfatiza el "modo de razonamiento" (Thinking) y la precisión en el renderizado de texto (aprox. 99% según datos oficiales), destacando en diseños de múltiples objetos y escenas con mucho texto. Nano Banana Pro apuesta por el motor de razonamiento de Gemini 3, salida 4K, fusión de hasta 14 imágenes, mantenimiento de identidad de hasta 5 personas y su exclusiva función de Grounding con la Búsqueda de Google.

Las diferencias clave entre el principio de generación de imágenes de Nano Banana Pro y la ruta de implementación de GPT-Image-2 se resumen en la siguiente tabla:
| Dimensión | Nano Banana Pro | GPT-Image-2 |
|---|---|---|
| Modelo subyacente | Gemini 3 Pro | GPT-4o multimodal |
| Mejora de inferencia | Razonamiento implícito de Gemini 3 | Modo de razonamiento explícito |
| Resolución máxima | 4K (escalado desde 2K) | 4K nativo |
| Límite de entrada de imágenes | 14 imágenes | Múltiples (límite no público) |
| Consistencia facial | Hasta 5 personas simultáneas | Fuerte, límite no público |
| Renderizado de texto | Líder en la industria, multilingüe | 99% de precisión |
| Información en tiempo real | ✅ Grounding con Búsqueda de Google | ❌ |
| Parámetro Seed | ❌ No compatible | Parcialmente controlado |
| Venta de edición parcial | Áreas no editadas perfectas a nivel de píxel | Sin deriva en múltiples rondas |
| Precio por imagen | 2K $0.139 / 4K $0.24 | Alta calidad 1024 $0.211 |
Recomendación de selección: Considera principalmente dos puntos: si necesitas crear materiales de marca, imágenes de producto o composiciones de escenas con múltiples personajes, la fusión de imágenes y la consistencia facial de Nano Banana Pro son más adecuadas. Si tu escenario principal son carteles con mucho texto, diseños complejos o composiciones con más de 100 objetos, el modo de razonamiento de GPT-Image-2 podría ser más estable. Recomendamos acceder a ambos modelos a través de la plataforma APIYI (apiyi.com) para realizar pruebas A/B a pequeña escala basadas en tus escenarios reales antes de decidir cuál utilizar como modelo principal.
Práctica con la API de Nano Banana Pro: De máscaras a cuadros delimitadores (bounding box) en todos los escenarios
Una vez comprendidos los principios, veamos cómo aplicar la capacidad de edición local de imágenes con IA de Nano Banana Pro en un entorno real. A continuación, presento un ejemplo mínimo ejecutable en Python que utiliza el punto de conexión compatible de APIYI para invocar a Gemini 3 Pro Image:
from google import genai
from PIL import Image
client = genai.Client(
api_key="your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1"}
)
original = Image.open("portrait.png")
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Mantén la identidad del personaje y el fondo sin cambios, cambia solo la camiseta blanca por una chaqueta de traje azul oscuro, manteniendo la dirección de la luz y las sombras originales",
original
]
)
for part in response.candidates[0].content.parts:
if part.inline_data:
with open("edited.png", "wb") as f:
f.write(part.inline_data.data)
Presta atención a cómo redactar la indicación (prompt): declara explícitamente "qué mantener sin cambios", "qué modificar" y "conservar la iluminación original"; esto activa directamente la capacidad de localización semántica del motor de razonamiento de Gemini 3. Si necesitas un control de área más preciso, puedes añadir una indicación de cuadro delimitador (bounding box):
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Dentro del cuadro delimitador [200, 150, 600, 700] de la imagen, reemplaza la ropa por una chaqueta de traje azul oscuro. El resto de las áreas deben mantener los píxeles originales sin cambios.",
original
]
)
Las coordenadas utilizan un rango normalizado de 0 a 1000, que se mapea según las dimensiones de la imagen durante el procesamiento real. Si requieres un control más estricto, puedes añadir una imagen de máscara como entrada.
5 consejos para la optimización en la práctica
Basándonos en la implementación de los principios de Nano Banana Pro en proyectos reales, resumimos 5 recomendaciones:
- La indicación siempre debe incluir una lista de elementos a conservar: "Mantener la identidad, el fondo y la iluminación sin cambios" es la clave para activar las cuatro capas de restricciones.
- Prioriza la localización semántica: A menos que la edición requiera una precisión a nivel de píxel en los bordes, el modo sin máscara (mask-free) es mucho más eficiente.
- No superes las 14 imágenes en la fusión: Exceder el límite oficial provocará un truncamiento, lo que afectará la consistencia entre imágenes.
- Elige entre 2K y 4K según el uso: 2K ($0.139) es suficiente para web o dispositivos móviles; reserva 4K ($0.24) para impresiones o pantallas grandes.
- No intentes usar semillas (seed) para la replicación: Nano Banana Pro no admite semillas. Para una replicación estable, utiliza la ponderación de la indicación y una imagen de referencia fija.
Precios y escenarios de uso
| Configuración | Costo por imagen | Escenario recomendado |
|---|---|---|
| Imagen única 2K | $0.139 | Redes sociales / Imágenes para web |
| Imagen única 4K | $0.24 | Impresos / Pantallas grandes / Visuales de marketing |
| 4K + Fusión de 14 imágenes | $0.24 + tokens de entrada | Composición de escenas con múltiples personajes |
| 4K + Grounding | $0.24 + tokens de búsqueda | Imágenes de productos reales / Eventos |
Recomendamos utilizar la API Batch de APIYI (apiyi.com) en entornos de producción para procesar tareas masivas; esto reduce significativamente los costos manteniendo la calidad, ideal para la creación de bibliotecas de materiales.
Preguntas frecuentes y consejos de decisión sobre Nano Banana Pro
P1: ¿Nano Banana Pro dibuja o modifica localmente?
R: La base es el "redibujado de tokens de imagen completa autorregresivo", es decir, "dibuja". Sin embargo, mediante cuatro capas de restricciones (máscaras, cuadros delimitadores, localización semántica de Gemini 3 y sesgo de entrenamiento), logra una experiencia de usuario cercana a una "edición local real". No son contradictorios: la arquitectura redibuja, pero la ingeniería bloquea.
P2: ¿Por qué dicen que las áreas no editadas son perfectas a nivel de píxel?
R: En el modo de máscara, los tokens de salida en las áreas negras se fuerzan a ser iguales a los tokens correspondientes de la imagen original, por lo que, tras la decodificación, los píxeles son casi idénticos. Técnicamente, la codificación/decodificación VQ-VAE tiene una pérdida mínima, por lo que es "casi" perfecto, no matemáticamente idéntico. A simple vista, es indistinguible.
P3: ¿Por qué Nano Banana Pro no admite semillas?
R: La generación autorregresiva muestrea desde una distribución de probabilidad en cada paso, lo cual es muy distinto a los modelos de difusión que fijan el ruido inicial. Google decidió no exponer el parámetro de semilla para mantener la diversidad creativa del modelo. Si necesitas resultados estables, usa una indicación detallada junto con una imagen de referencia. Sugerimos probar la estabilidad de diferentes plantillas de indicación en APIYI (apiyi.com) para encontrar una combinación "casi determinista".
P4: ¿Cómo elegir entre Nano Banana Pro y GPT-Image-2?
R: Escenarios con múltiples personajes, materiales de marca o necesidad de información en tiempo real (Grounding) → elige Nano Banana Pro. Diseños complejos, carteles con mucho texto o disposiciones de más de 100 objetos → elige GPT-Image-2. Ambos son autorregresivos, la diferencia radica en cómo Google y OpenAI gestionan la ingeniería de restricciones.
P5: ¿Puedo localizar el área de edición sin una máscara?
R: Sí, hay dos formas. Una es usando el parámetro de cuadro delimitador (coordenadas normalizadas 0-1000); la otra es confiar en la localización semántica de Gemini 3, simplemente diciendo en la indicación: "modifica el objeto rojo en la parte inferior derecha". Lo segundo cubre la mayoría de los casos; lo primero es para áreas rectangulares claras.
P6: ¿Cómo se usa realmente el Grounding con la Búsqueda de Google?
R: Especifica en la indicación los elementos que requieren verificación de hechos, por ejemplo: "Dibuja un Tesla Cybertruck 2025 en la superficie lunar". El modelo buscará automáticamente en Google para obtener referencias visuales reales antes de generar la imagen. Esta es una capacidad exclusiva de Nano Banana Pro; GPT-Image-2 no cuenta con ella.
Conclusión: Entender la ingeniería de restricciones es clave
Nano Banana Pro es un producto técnicamente refinado. No inventó un nuevo paradigma de generación de imágenes, sino que, sobre la base autorregresiva de Gemini 3, envolvió la arquitectura de "redibujado de imagen completa" en una experiencia de "edición local real" mediante cuatro capas de restricciones.
Comprender esta "separación entre mecanismo y experiencia" es fundamental para redactar indicaciones que activen estas restricciones, elegir el modo de edición correcto y planificar flujos de trabajo iterativos. El núcleo de los principios de generación de imágenes de Nano Banana Pro no es una tecnología oculta, sino la sinergia total de la ingeniería de restricciones.
Recomendamos realizar pruebas y comparaciones a través de la plataforma APIYI (apiyi.com), que admite llamadas a múltiples modelos principales como Nano Banana Pro, GPT-Image-2 y Stable Diffusion, facilitando la validación rápida de todos los principios y técnicas de optimización mencionados aquí.
Este artículo fue redactado por el equipo de APIYI, basado en materiales oficiales de Google DeepMind, Vertex AI y pruebas de campo. Si necesitas invocar Gemini 3 Pro Image (Nano Banana Pro) en producción, visita el sitio web oficial de APIYI: apiyi.com para obtener la documentación de integración.