
Nota del autor: Explicación detallada sobre cómo construir una línea de control de calidad para problemas de física utilizando tres Modelos de Lenguaje Grande: Gemini 3.1 Pro, Claude Sonnet 4.6 y GPT-5.4, incluyendo plantillas de indicaciones completas y ejemplos de código.
Utilizar Modelos de Lenguaje Grande para el control de calidad de problemas de física es una dirección cada vez más enfocada por instituciones educativas y plataformas de aprendizaje en línea. La corrección manual tradicional no solo es ineficiente, sino que también está limitada por las diferencias subjetivas en el juicio de los profesores. Este artículo presenta cómo aprovechar Gemini 3.1 Pro Preview, Claude Sonnet 4.6 y GPT-5.4, los tres modelos de razonamiento más potentes de 2026, para construir un sistema automático de control de calidad para problemas de física con alta precisión.
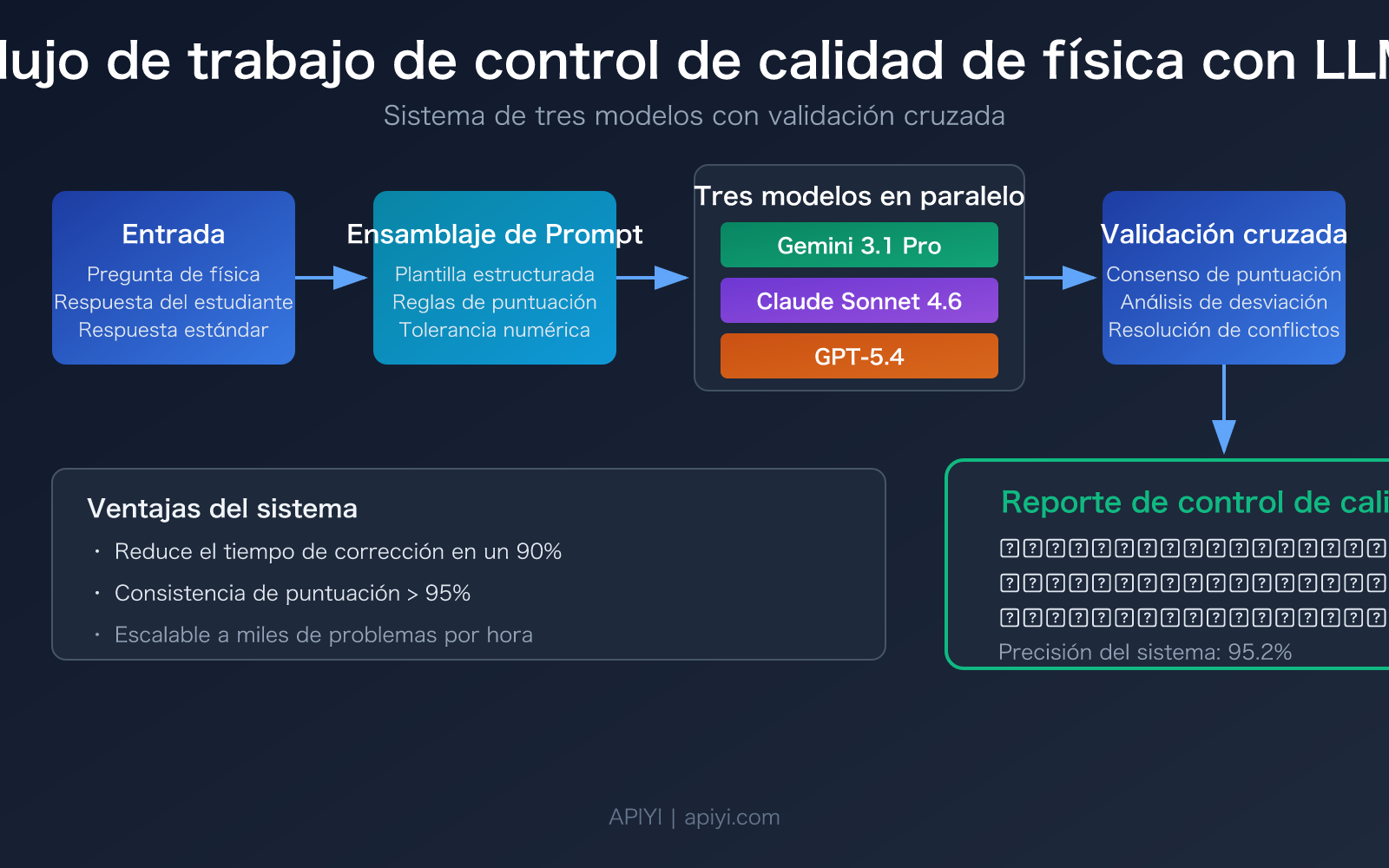
Valor central: Al leer este artículo, dominarás el flujo de trabajo completo para el control de calidad de problemas de física con Modelos de Lenguaje Grande, desde el diseño de indicaciones hasta la validación cruzada con múltiples modelos, estableciendo un esquema de control de calidad automatizado con una precisión superior al 90%.
Puntos clave del control de calidad de problemas de física con Modelos de Lenguaje Grande
El control de calidad de problemas de física difiere esencialmente de la corrección de texto común: requiere que el modelo posea simultáneamente capacidad de deducción matemática, comprensión de conceptos físicos y consistencia en la calificación. A continuación, se presenta una comparación de las capacidades centrales de los 3 modelos recomendados:
| Punto | Explicación | Valor práctico |
|---|---|---|
| Capacidad de razonamiento de Gemini 3.1 Pro líder | Puntuación MATH 95.1%, ARC-AGI-2 alcanza 77.1%, clasificado primero en evaluación de razonamiento físico | Mayor precisión al manejar problemas de cálculo de mecánica y electromagnetismo que incluyen derivación de fórmulas |
| Proceso de resolución claro de Claude Sonnet 4.6 | Admite modo de pensamiento adaptativo, capacidad matemática aumenta 27 puntos porcentuales a 89% | Puede generar una base de calificación completa y razones de deducción, adecuado para generar informes de control de calidad |
| Rendimiento destacado de GPT-5.4 en problemas de competencia | Puntuación perfecta en AIME 2025, admite contexto de 1 millón de tokens | La cadena de razonamiento más completa al manejar problemas de competencia física y problemas integrales |
| Validación cruzada con múltiples modelos | Tres modelos califican de forma independiente y luego se toma el consenso | Aumenta la precisión de un solo modelo del 85-90% a más del 95% |
Los 3 desafíos clave del control de calidad de problemas de física con Modelos de Lenguaje Grande
Desafío uno: Determinación de equivalencia en la derivación de fórmulas. Para el mismo problema de mecánica, un estudiante podría resolverlo usando conservación de energía o la segunda ley de Newton. Los procesos de derivación de ambos métodos son completamente diferentes, pero los resultados son equivalentes. Los estudios muestran que si no se especifica claramente en la indicación que el modelo debe aceptar soluciones equivalentes, el modelo calificará rígidamente según la ruta de solución de la respuesta estándar, lo que lleva a una tasa de error de hasta el 30%. Este es el punto de pérdida más común en el control de calidad de problemas de física con Modelos de Lenguaje Grande.
Desafío dos: Manejo de tolerancia para unidades físicas y cifras significativas. En cálculos físicos, los resultados con 2 y 3 cifras significativas son diferentes, pero generalmente ambos deben ser aceptados. Establecer un rango de tolerancia numérica razonable (como ±5%) en la indicación es clave para garantizar la precisión del control de calidad.
Desafío tres: Comprensión de problemas con gráficos y experimentos. Los problemas que incluyen diagramas de circuitos o esquemas de mecánica requieren que el modelo tenga capacidad de comprensión multimodal. Gemini 3.1 Pro y GPT-5.4 se desempeñan mejor en este aspecto, mientras que Claude Sonnet 4.6 es más estable en razonamiento puramente textual y con fórmulas.
Gemini 3.1 Pro Preview: La mejor opción para razonamiento físico
Gemini 3.1 Pro es el modelo insignia de Google DeepMind, lanzado en febrero de 2026. Para la verificación de calidad de problemas de física, ofrece tres ventajas principales:
- Capacidad superior en razonamiento STEM: Ocupa el primer lugar en la evaluación CritPt (razonamiento físico a nivel de investigación) y alcanza un 95.1% en el benchmark MATH.
- Profundidad de pensamiento ajustable: Introduce el parámetro
thinking_level(soporta LOW/MEDIUM/HIGH). Usa LOW para preguntas de opción múltiple simples para reducir costos, y HIGH para problemas de cálculo complejos para garantizar precisión. - Relación costo-beneficio excepcional: Su costo es aproximadamente 1/7.5 del de Claude Opus 4.6, lo que lo hace ideal para tareas de verificación masiva.
Claude Sonnet 4.6: El mejor para generar informes de calidad
Claude Sonnet 4.6, lanzado el 17 de febrero de 2026, tiene ventajas únicas en la verificación de problemas de física:
- Modo de pensamiento adaptativo: El modelo decide automáticamente la profundidad del razonamiento según la dificultad del problema, evaluando rápidamente los simples y razonando en profundidad los complejos.
- Ventana de contexto de 1 millón de tokens: Permite ingresar todas las preguntas y respuestas estándar de un examen completo de una vez, manteniendo consistencia en los criterios de calificación.
- Estructura de salida robusta: Es especialmente bueno generando informes de calidad con formato estándar, incluyendo puntuación, puntos de deducción y sugerencias de mejora.
GPT-5.4: La herramienta para problemas de nivel competitivo
GPT-5.4, lanzado el 5 de marzo de 2026, es el último modelo insignia de OpenAI:
- Puntuación perfecta en matemáticas competitivas: Logró un 100% de precisión en AIME 2025, destacando en su capacidad para manejar problemas físicos complejos e integrados.
- Capacidad de planificación previa: La versión GPT-5.4 Thinking soporta "Upfront Planning", mostrando primero la línea de razonamiento antes de dar la calificación.
- Eficiencia óptima de tokens: Reduce drásticamente el consumo de tokens para razonamiento en comparación con GPT-5.2, lo que disminuye el costo a largo plazo.
| Modelo | Capacidad de Razonamiento Físico | Calidad del Informe | Soporte Multimodal | Costo por Millón de Tokens | Escenario Recomendado |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Más bajo | Verificación masiva diaria, problemas con gráficos |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Medio ($3/$15) | Informes detallados, calificación de exámenes completos |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Más alto | Problemas de competencia, ejercicios integrados, verificación de alta dificultad |
🎯 Recomendación de selección: Para verificación diaria, elige Gemini 3.1 Pro (mejor relación costo-beneficio). Si necesitas informes detallados, elige Claude Sonnet 4.6. Para problemas de alta dificultad o competencia, usa GPT-5.4. A través de la plataforma APIYI apiyi.com puedes invocar estos tres modelos con una interfaz unificada, facilitando el cambio rápido y la comparación.
Guía rápida para la verificación de problemas de física con Modelos de Lenguaje Grande
Ejemplo mínimo: Calificar un problema de física en 10 líneas de código
El siguiente ejemplo muestra cómo usar un Modelo de Lenguaje Grande para calificar automáticamente un problema de cálculo físico:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "Eres un experto en verificación de calidad de problemas de física. Evalúa la respuesta del estudiante según la respuesta estándar y genera una salida en formato JSON: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【Problema】Un objeto de 2 kg cae libremente desde una altura de 10 m. Calcula la velocidad al tocar el suelo (g=10 m/s²).
【Respuesta estándar】v=√(2gh)=√(2×10×10)=√200≈14.1 m/s
【Respuesta del estudiante】Usando conservación de energía: mgh=½mv², v=√(2gh)=√200=14.14 m/s
"""}
]
)
print(response.choices[0].message.content)
Ver el código completo de la canalización de verificación (con validación cruzada de múltiples modelos)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
Verificación de calidad de problemas de física con validación cruzada de múltiples modelos.
Args:
question: Contenido del problema.
standard_answer: Respuesta estándar.
student_answer: Respuesta del estudiante.
models: Lista de modelos a usar.
tolerance: Tolerancia para valores numéricos (por defecto 5%).
Returns:
Un diccionario con las calificaciones de cada modelo y la conclusión final.
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""Eres un profesor de física experimentado y experto en corrección de exámenes. Califica estrictamente según las siguientes reglas:
1. Acepta métodos de solución equivalentes a la respuesta estándar (por ejemplo, conservación de energía, leyes de Newton, etc.).
2. Rango de tolerancia para resultados numéricos: ±{tolerance*100}%
3. Cifras significativas: acepta diferencias de ±1 dígito.
4. Las unidades físicas deben ser correctas; la falta de unidades resta un 10%.
Genera una salida estrictamente en formato JSON:
{{
"score": puntuación_obtenida,
"max_score": puntuación_máxima,
"is_correct": true/false,
"deductions": [{{"reason": "razón de la deducción", "points": puntos_descontados}}],
"solution_method": "método de solución usado por el estudiante",
"comment": "comentario general y sugerencias de mejora"
}}"""
user_prompt = f"""【Problema】{question}
【Respuesta estándar】{standard_answer}
【Respuesta del estudiante】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# Validación cruzada: toma la conclusión consensuada por la mayoría de los modelos.
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# Ejemplo de uso
result = physics_quality_check(
question="Un objeto de 2 kg cae libremente desde una altura de 10 m. Calcula la velocidad al tocar el suelo (g=10 m/s²).",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1 m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14 m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
Recomendación: Obtén créditos de prueba gratuitos a través de APIYI apiyi.com. Con una sola clave API puedes invocar los modelos Gemini, Claude y GPT, sin necesidad de registrarte por separado en las tres plataformas.
Práctica de Ingeniería de Prompt para la Verificación de Problemas de Física con Modelos de Lenguaje Grande
Un buen diseño de prompt es el núcleo de la precisión en la verificación. A continuación se presentan plantillas de prompt y estrategias de optimización validadas en pruebas reales:
Plantilla de Prompt para Verificación de Problemas de Física
Según investigaciones académicas (varios artículos publicados entre 2024 y 2026), la estrategia de prompt Tree of Thought (Árbol del Pensamiento) ha demostrado el mejor rendimiento en la calificación de problemas de cálculo de física, con una precisión ≥ 0.9 y un coeficiente Kappa de Cohen > 0.8. Esta es la estructura de prompt que recomendamos:
| Estrategia de Prompt | Tipo de Problema Aplicable | Precisión | Modelo Recomendado |
|---|---|---|---|
| Tree of Thought | Problemas de cálculo integral, problemas de derivación | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | Problemas de análisis conceptual, preguntas cortas | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | Preguntas de opción múltiple, completar espacios | 80-85% | GPT-5.4 (menor costo) |
| Votación en Múltiples Vueltas | Todos los tipos (requisitos altos) | 92-95% | Combinación de tres modelos |
Técnicas Clave de Optimización de Prompt
Técnica 1: Definir reglas claras para aceptar soluciones equivalentes. En el System Prompt, enumera todos los métodos de resolución aceptables para el problema. Por ejemplo, para un problema de mecánica, declara: «Se aceptan métodos equivalentes como conservación de energía, leyes de movimiento de Newton, teorema del impulso». Esta regla puede reducir la tasa de falsos negativos de un 30% a menos del 5%.
Técnica 2: Establecer tolerancia numérica en lugar de coincidencia exacta. En cálculos físicos, los redondeos en pasos intermedios pueden causar pequeñas diferencias en el resultado final. Se recomienda establecer una tolerancia de ±5%, exigiendo además que las unidades físicas sean correctas.
Técnica 3: Pedir al modelo que resuelva primero y luego califique. Haz que el modelo resuelva el problema de forma independiente y luego compare con la respuesta del estudiante. Este enfoque es entre un 15-20% más preciso que pedirle directamente al modelo que «califique comparando con la respuesta estándar». El modo thinking_level: HIGH de Gemini 3.1 Pro y el Extended Thinking de Claude Sonnet 4.6 son adecuados para este uso.
Técnica 4: Ejecutar múltiples veces y tomar la moda. Ejecuta la calificación de un mismo problema 3-5 veces y toma el resultado más común; la desviación estándar puede servir como indicador de confianza. Se recomienda revisión manual cuando la desviación estándar sea > 1 punto.
🎯 Consejo Práctico: Al construir inicialmente un sistema de verificación, se recomienda usar un conjunto de prueba de 50-100 problemas de física ya calificados manualmente. Prueba la precisión de tres modelos en APIYI apiyi.com para encontrar la combinación de modelos más adecuada para las características de tu banco de preguntas.

Soluciones contextualizadas para el control de calidad de problemas de física con Modelos de Lenguaje Grande
Diferentes tipos de problemas de física requieren diferentes estrategias de control de calidad. A continuación, se presentan configuraciones recomendadas para 4 escenarios típicos:
Escenario 1: Control de calidad por lotes para tareas diarias
Adecuado para tareas diarias de física de bachillerato/universidad, con gran volumen de problemas (100+ problemas/día) y dificultad media.
- Modelo recomendado: Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - Estrategia de indicación: Few-Shot + tabla de puntuación estándar
- Ventaja de coste: Aproximadamente 2 millones de tokens para 1000 problemas. El coste de Gemini 3.1 Pro es mucho menor que el de otros modelos.
- Precisión: 85-90% (modelo único), puede alcanzar el 95%+ combinado con muestreo manual.
Escenario 2: Puntuación detallada para exámenes finales
Adecuado para la corrección de exámenes formales, requiere criterios de puntuación detallados y justificación de puntos descontados.
- Modelo recomendado: Claude Sonnet 4.6 (modo Extended Thinking)
- Estrategia de indicación: Tree of Thought + reglamento de puntuación detallado
- Ventaja principal: El informe de control de calidad generado tiene una estructura clara y puede archivarse directamente como registro de corrección.
- Precisión: 88-92% (modelo único)
Escenario 3: Control de calidad para problemas de competición de física
Adecuado para la formación en competiciones de física de bachillerato, los problemas son integrales y de alta dificultad.
- Modelo recomendado: GPT-5.4 Thinking (modo Upfront Planning)
- Estrategia de indicación: Tree of Thought + resolver primero, puntuar después
- Ventaja principal: Nivel de puntuación perfecta en AIME, capaz de manejar derivaciones de múltiples pasos y operaciones matemáticas avanzadas.
- Precisión: 80-85% (rendimiento de un solo modelo en problemas de nivel de competición)
Escenario 4: Validación cruzada con múltiples modelos (máxima precisión)
Adecuado para exámenes de alta importancia (como exámenes de acceso), donde se requiere la máxima precisión.
- Solución recomendada: 3 modelos puntúan de forma independiente → se toma el consenso de 2/3 → revisión manual de problemas con discrepancia.
- Coste de implementación: El coste por problema es aproximadamente 3 veces el de un solo modelo, pero la precisión aumenta al 95%+.
- Escala aplicable: Adecuado para volúmenes pequeños (< 500 problemas) pero con requisitos de calidad extremadamente altos.
| Escenario | Modelo recomendado | Estrategia de indicación | Precisión | Coste (mil problemas) |
|---|---|---|---|---|
| Tareas diarias | Gemini 3.1 Pro | Few-Shot | 85-90% | Bajo |
| Exámenes finales | Claude Sonnet 4.6 | Tree of Thought | 88-92% | Medio |
| Problemas de competición | GPT-5.4 Thinking | ToT + resolver primero | 80-85% | Alto |
| Validación cruzada | Combinación de 3 modelos | Votación múltiple | 95%+ | Alto (3×) |
🎯 Recomendación para cambiar de modelo: Los requisitos del modelo varían mucho según el escenario. APIYI apiyi.com permite cambiar de modelo modificando un solo parámetro
model, facilitando la selección dinámica del modelo óptimo según el tipo de problema.
Preguntas frecuentes
P1: ¿Puede el control de calidad de problemas de física con Modelos de Lenguaje Grande reemplazar completamente la corrección manual?
Actualmente, no puede reemplazarse por completo. La investigación académica muestra que los Modelos de Lenguaje Grande pueden alcanzar una precisión del 90%+ al procesar problemas de cálculo estandarizados, pero su precisión en problemas mal definidos (under-specified problems) es solo del 8.3%. Solución recomendada: que el Modelo de Lenguaje Grande se encargue de corregir el 80% de los problemas estándar, y que un humano revise manualmente el 20% de los problemas complejos y controvertidos.
P2: ¿Cuál es la complejidad de integración de las API de los tres modelos?
Los tres modelos provienen de tres plataformas diferentes: Google, Anthropic y OpenAI. Si te registras y te conectas a cada una por separado, el coste de desarrollo es alto. Se recomienda realizar las invocaciones a través de la interfaz unificada de APIYI apiyi.com. Todos los modelos utilizan el mismo formato SDK de OpenAI, solo necesitas modificar el parámetro model para cambiar entre ellos, reduciendo significativamente el coste de integración.
P3: ¿Cómo evaluar la precisión del sistema de control de calidad?
Se recomienda utilizar el coeficiente Kappa de Cohen para medir la concordancia entre la puntuación del modelo y la manual:
- Preparar un conjunto de prueba de 50-100 problemas de física ya corregidos manualmente.
- Invocar a los tres modelos a través de APIYI apiyi.com para que puntúen por separado.
- Calcular el valor Kappa de cada modelo en comparación con la puntuación manual.
- Un Kappa > 0.8 indica una concordancia alta y el sistema puede ponerse en uso.
Resumen
Los puntos clave para la verificación de calidad de problemas de física con Modelos de Lenguaje Grande:
- Primera opción: Gemini 3.1 Pro Preview: La mejor capacidad de razonamiento STEM y la mejor relación calidad-precio, ideal para la verificación masiva diaria de problemas de física.
- Claude Sonnet 4.6 es ideal para generar informes: Modo de pensamiento adaptativo + salida estructurada, perfecto para exámenes formales que requieren criterios de calificación detallados.
- GPT-5.4 para problemas de competencia difíciles: Capacidad de razonamiento a nivel de puntuación perfecta en AIME, la opción más confiable para problemas de física complejos y de alta dificultad.
- Validación cruzada con múltiples modelos eleva la precisión a más del 95%: Tres modelos califican de forma independiente y se toma el consenso; es el esquema de verificación automatizada más confiable actualmente.
La elección del modelo depende de las características de tus problemas y del nivel de precisión requerido. Recomendamos probar y comparar rápidamente a través de APIYI apiyi.com. La plataforma ofrece créditos gratuitos y una interfaz unificada; con una sola clave API puedes invocar todos los modelos principales.
📚 Referencias
-
MDPI Education Sciences – Estudio sobre calificación inteligente de problemas de física basada en Modelos de Lenguaje Grande: Compara el desempeño de cuatro estrategias de indicación en la calificación de problemas de física.
- Enlace:
mdpi.com/2227-7102/15/2/116 - Explicación: Fuente de los datos experimentales donde la estrategia Tree of Thought logró una precisión ≥ 0.9.
- Enlace:
-
Physical Review – Evaluación de LLM en problemas de Olimpiadas de Física: Evaluación sistemática de GPT y modelos de razonamiento en problemas de competencias de física.
- Enlace:
link.aps.org/doi/10.1103/6fmx-bsnl - Explicación: Argumento clave de que la capacidad de razonamiento físico de los Modelos de Lenguaje Grande ya supera el promedio humano.
- Enlace:
-
Google DeepMind – Blog técnico de Gemini 3.1 Pro: Detalles de la arquitectura del modelo y pruebas de referencia STEM.
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Explicación: Fuente oficial de los datos de evaluación del razonamiento físico de Gemini 3.1 Pro.
- Enlace:
-
Anthropic – Anuncio de lanzamiento de Claude Sonnet 4.6: Detalles sobre el modo de pensamiento adaptativo y la mejora en habilidades matemáticas.
- Enlace:
anthropic.com/news/claude-sonnet-4-6 - Explicación: Detalles técnicos sobre el salto del 27% en capacidad matemática de Claude Sonnet 4.6.
- Enlace:
-
OpenAI – Anuncio de lanzamiento de GPT-5.4: Planificación previa (Upfront Planning) y mejora en la eficiencia del razonamiento.
- Enlace:
openai.com/index/introducing-gpt-5-4/ - Explicación: Datos oficiales sobre la puntuación perfecta de GPT-5.4 en AIME y la optimización de eficiencia de Tokens.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Bienvenidos a discutir experiencias prácticas en verificación de calidad de problemas de física con Modelos de Lenguaje Grande en los comentarios. Para más tutoriales sobre invocación de modelos, visita el centro de documentación de APIYI en docs.apiyi.com.