
Author's Note: A detailed guide on how to build a physics problem quality inspection pipeline using three Large Language Models—Gemini 3.1 Pro, Claude Sonnet 4.6, and GPT-5.4—including complete prompt templates and code examples.
Using Large Language Models for physics problem quality inspection is an increasingly important direction for educational institutions and online learning platforms. Traditional manual grading is not only inefficient but also limited by the subjective differences among teachers. This article will introduce how to leverage the three most powerful reasoning models of 2026—Gemini 3.1 Pro Preview, Claude Sonnet 4.6, and GPT-5.4—to build a high-accuracy automated physics problem inspection system.
Core Value: After reading this article, you'll master the complete workflow for Large Language Model-based physics problem inspection—from prompt design to multi-model cross-validation—establishing an automated quality inspection solution with over 90% accuracy.
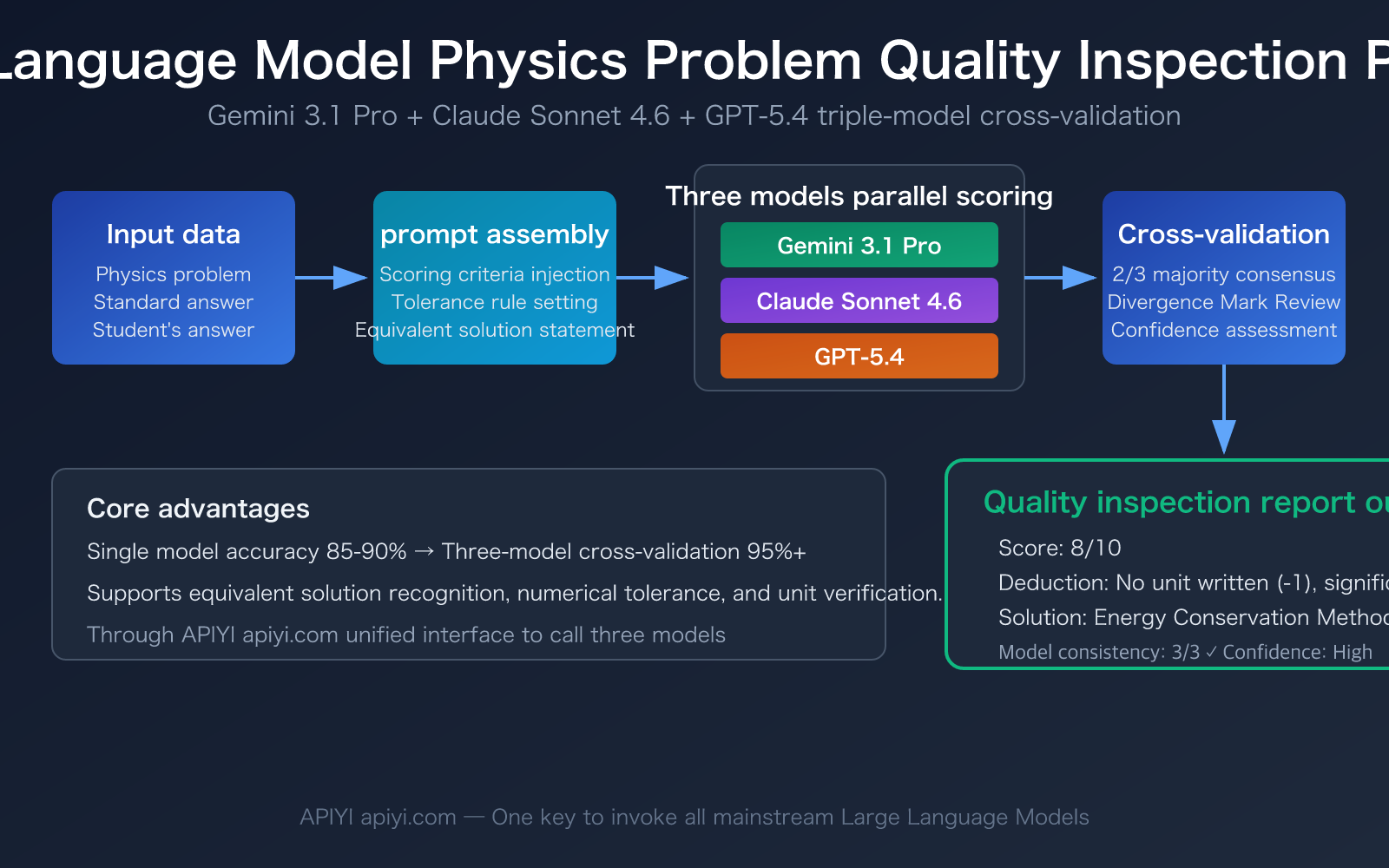
Core Points of Large Language Model Physics Problem Inspection
Physics problem inspection is fundamentally different from ordinary text grading—it requires models to possess mathematical reasoning ability, physics concept understanding, and scoring consistency simultaneously. Here's a core capability comparison of the three recommended models:
| Key Point | Description | Practical Value |
|---|---|---|
| Gemini 3.1 Pro's Leading Reasoning Ability | MATH benchmark 95.1%, ARC-AGI-2 reaches 77.1%, ranks first in physics reasoning evaluation | Highest accuracy for handling mechanics and electromagnetism calculation problems involving formula derivation |
| Claude Sonnet 4.6's Clear Problem-Solving Process | Supports adaptive thinking mode, math ability jumps 27 percentage points to 89% | Can output complete scoring basis and deduction reasons, suitable for generating inspection reports |
| GPT-5.4's Outstanding Performance on Competition-Level Problems | AIME 2025 perfect score, supports 1 million Token context | Most complete reasoning chain when handling physics competition problems and comprehensive questions |
| Multi-Model Cross-Validation | Three models score independently then reach consensus | Increases single-model accuracy from 85-90% to 95%+ |
Three Key Challenges in Large Language Model Physics Problem Inspection
Challenge One: Equivalent Determination of Formula Derivations. For the same mechanics problem, a student might solve it using energy conservation, while another might use Newton's second law. The derivation processes of these two methods are completely different, but the results are equivalent. Research shows that if the prompt doesn't explicitly require the model to accept equivalent solutions, the model will rigidly score according to the standard answer's solution path, leading to a misjudgment rate as high as 30%. This is the most common point of failure in Large Language Model physics problem inspection.
Challenge Two: Tolerance Handling of Physical Units and Significant Figures. In physics calculations, results with 2 significant figures and 3 significant figures are different, but both should generally be accepted. Setting reasonable numerical tolerance ranges (e.g., ±5%) in the prompt is key to ensuring inspection accuracy.
Challenge Three: Understanding of Diagrams and Experimental Questions. Questions containing circuit diagrams or mechanics schematic diagrams require models to have multimodal understanding capabilities. Gemini 3.1 Pro and GPT-5.4 perform better in this area, while Claude Sonnet 4.6 is more stable with pure text and formula reasoning.
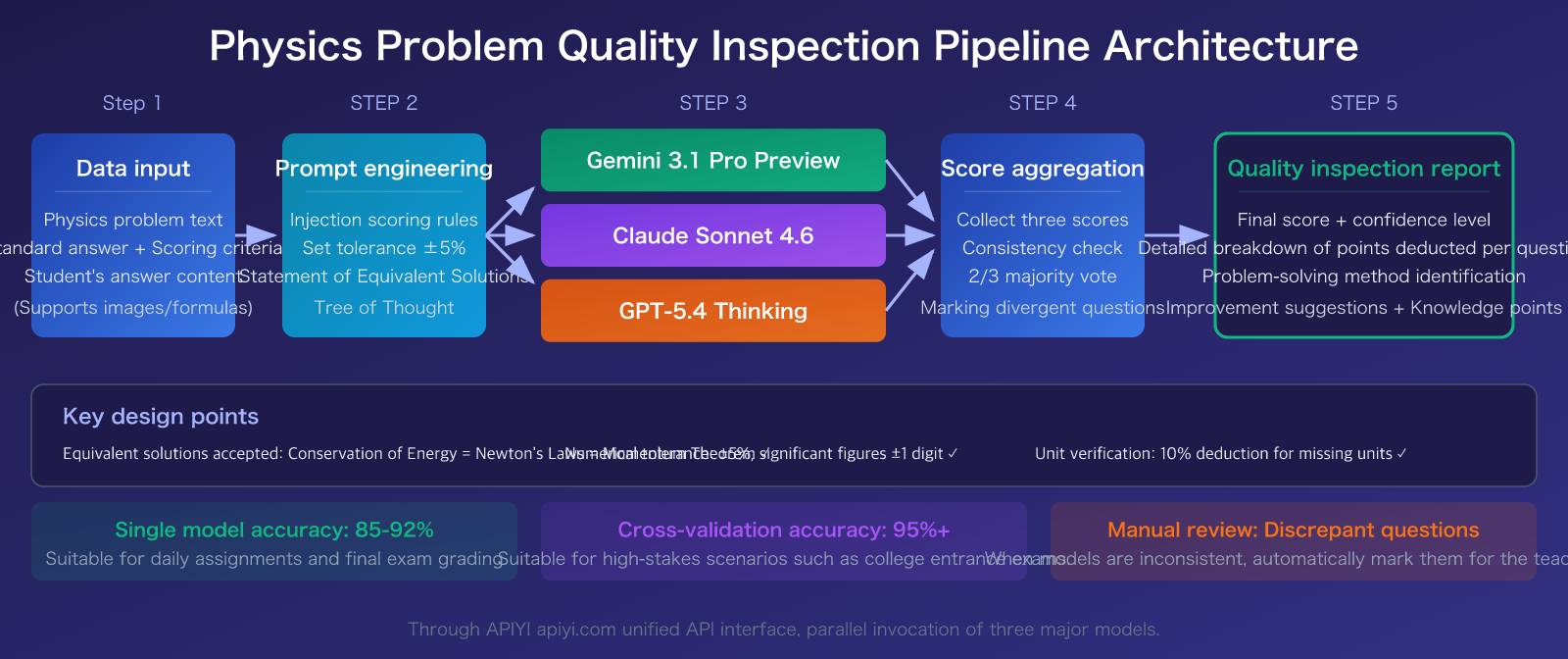
Gemini 3.1 Pro Preview: The Top Choice for Physics Reasoning
Gemini 3.1 Pro is the flagship model released by Google DeepMind in February 2026. For physics question quality inspection, it offers three core advantages:
- Best-in-class STEM reasoning: Ranked #1 in the CritPt (research-level physics reasoning) evaluation, achieving 95.1% on the MATH benchmark.
- Adjustable thinking depth: Introduces a new
thinking_levelparameter (LOW/MEDIUM/HIGH). Use LOW for simple multiple-choice questions to reduce costs, and HIGH for comprehensive calculation problems to ensure accuracy. - Exceptional cost-effectiveness: Costs only about 1/7.5th of Claude Opus 4.6, making it ideal for large-scale quality inspection tasks.
Claude Sonnet 4.6: Best for Generating Inspection Reports
Released on February 17, 2026, Claude Sonnet 4.6 has unique strengths in physics question inspection:
- Adaptive thinking mode: The model automatically determines the depth of reasoning based on the difficulty of the question—quick judgment for simple problems, deep reasoning for complex ones.
- 1 million token context window: Allows you to input all questions and standard answers for an entire test paper at once, ensuring consistent scoring standards.
- Strong structured output: Particularly adept at generating well-formatted inspection reports, including scores, deduction points, and improvement suggestions.
GPT-5.4: The Tool for Competition-Level Difficult Problems
Released on March 5, 2026, GPT-5.4 is OpenAI's latest flagship model:
- Perfect score on competition math: Achieved 100% accuracy on AIME 2025, demonstrating outstanding capability in handling high-difficulty, comprehensive physics problems.
- Upfront planning capability: The GPT-5.4 Thinking version supports "Upfront Planning," where it first displays the reasoning process before giving the final score.
- Optimal token efficiency: Significantly reduces the number of tokens consumed for reasoning compared to GPT-5.2, leading to lower long-term usage costs.
| Model | Physics Reasoning | Report Quality | Multimodal Support | Cost per Million Tokens | Recommended Use Case |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Lowest | High-volume daily inspection, questions containing charts |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Medium ($3/$15) | Detailed inspection reports, scoring entire test papers |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Higher | Competition questions, comprehensive problems, high-difficulty inspection |
🎯 Selection Advice: For daily inspection, Gemini 3.1 Pro is the first choice (best cost-effectiveness). Choose Claude Sonnet 4.6 when you need detailed reports. Use GPT-5.4 for high-difficulty competition questions. Through the APIYI platform at apiyi.com, you can call all three models with a unified interface, making it easy to switch and compare quickly.
Quick Start: Large Language Models for Physics Question Inspection
Minimal Example: 10 Lines of Code for Automatic Physics Question Grading
The following example shows how to use a large language model to automatically score a physics calculation problem:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "You are an expert in physics question quality inspection. Judge the student's answer against the standard answer and output in JSON format: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【Question】A 2kg object falls freely from a height of 10m. Find its velocity upon impact (g=10m/s²).
【Standard Answer】v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【Student Answer】Using energy conservation: mgh=½mv², v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
View Complete Inspection Pipeline Code (with Multi-Model Cross-Validation)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
Multi-model cross-validation for physics question inspection.
Args:
question: The question content.
standard_answer: The standard answer.
student_answer: The student's answer.
models: List of models to use.
tolerance: Numerical tolerance (default 5%).
Returns:
A dictionary containing scores from each model and a final consensus.
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""You are a senior physics teacher and grading expert. Please score strictly according to the following rules:
1. Accept solution methods equivalent to the standard answer (e.g., different approaches like energy conservation, Newton's laws).
2. Numerical result tolerance range: ±{tolerance*100}%
3. Significant figures: Accept differences of ±1 digit.
4. Physical units must be correct. Missing units deduct 10%.
Output strictly in JSON format:
{{
"score": score,
"max_score": maximum_score,
"is_correct": true/false,
"deductions": [{{"reason": "reason for deduction", "points": points_deducted}}],
"solution_method": "solution method used by student",
"comment": "comprehensive evaluation and improvement suggestions"
}}"""
user_prompt = f"""【Question】{question}
【Standard Answer】{standard_answer}
【Student Answer】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# Cross-validation: Take the consensus conclusion from the majority of models.
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# Usage example
result = physics_quality_check(
question="A 2kg object falls freely from a height of 10m. Find its velocity upon impact (g=10m/s²).",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
Suggestion: Get free testing credits through APIYI at apiyi.com. A single API key gives you access to call Gemini, Claude, and GPT models, without needing to register for three separate platform accounts.
Prompt Engineering Practices for Large Language Model Physics Problem Quality Inspection
Good prompt design is the core of inspection accuracy. Here are the prompt templates and optimization strategies that have been proven effective through real-world testing:
Physics Problem Inspection Prompt Template
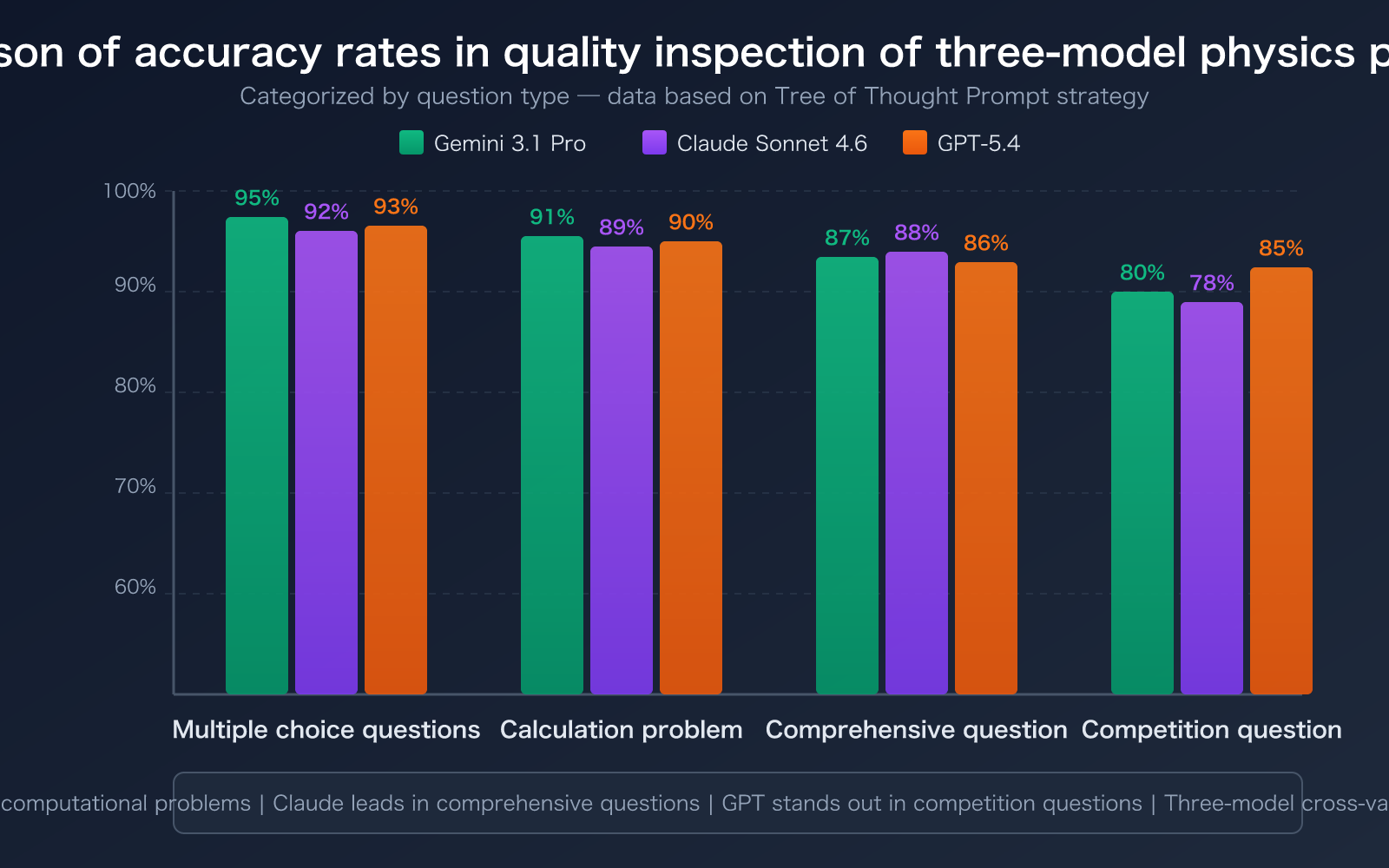
According to academic research (multiple papers published between 2024-2026), the Tree of Thought prompting strategy performs best in scoring physics calculation problems, achieving accuracy ≥ 0.9 and Cohen's Kappa > 0.8. Here's our recommended prompt structure:
| Prompt Strategy | Suitable Question Types | Accuracy | Recommended Model |
|---|---|---|---|
| Tree of Thought | Comprehensive calculation problems, derivation problems | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | Conceptual analysis problems, short answer questions | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | Multiple choice, fill-in-the-blank | 80-85% | GPT-5.4 (lower cost) |
| Multi-round Voting | All question types (high requirements) | 92-95% | Three-model ensemble |
Key Prompt Optimization Techniques
Technique 1: Clearly define acceptable equivalent solution rules. List all acceptable solving methods for the problem in the System Prompt. For example, for a mechanics problem, state: "Accept equivalent methods such as energy conservation, Newton's laws of motion, momentum theorem." This single rule can reduce misjudgment rates from 30% to below 5%.
Technique 2: Set numerical tolerance instead of exact matching. Rounding in intermediate steps of physics calculations can cause minor differences in final results. We recommend setting a ±5% tolerance while requiring physical units to be correct.
Technique 3: Require the model to solve the problem first, then score. Have the model solve the problem independently first, then compare it with the student's answer. This approach is 15-20% more accurate than directly asking the model to "score against the standard answer." Gemini 3.1 Pro's thinking_level: HIGH mode and Claude Sonnet 4.6's Extended Thinking are both suitable for this usage.
Technique 4: Run multiple times and take the mode. Run the scoring 3-5 times for the same problem and take the most common result. The standard deviation can serve as a confidence indicator. When the standard deviation > 1 point, manual review is recommended.
🎯 Practical advice: When initially building your inspection system, we suggest starting with a test set of 50-100 physics problems that have already been manually graded. Test the accuracy of three different models on APIYI apiyi.com to find the model combination that best suits the characteristics of your question bank.
Scenario-Based Solutions for Large Language Model Physics Problem Quality Inspection
Different types of physics problems require different quality inspection strategies. Here are recommended configurations for 4 typical scenarios:
Scenario 1: Batch Quality Inspection for Daily Homework
Suitable for high school/college physics daily homework, with a large volume (100+ problems/day) and medium difficulty.
- Recommended Model: Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - Prompt Strategy: Few-Shot + Standard Scoring Rubric
- Cost Advantage: ~2 million Tokens for 1000 problems, with Gemini 3.1 Pro being significantly cheaper than other models
- Accuracy: 85-90% (single model), can reach 95%+ with manual spot-checking
Scenario 2: Detailed Scoring for Final Exams
Suitable for formal exam grading, requiring detailed scoring rationale and point deduction reasons.
- Recommended Model: Claude Sonnet 4.6 (Extended Thinking mode)
- Prompt Strategy: Tree of Thought + Detailed Scoring Guidelines
- Core Advantage: Outputs structured quality inspection reports that can be directly archived as grading records
- Accuracy: 88-92% (single model)
Scenario 3: Quality Inspection for Physics Competition Problems
Suitable for high school physics competition training, featuring comprehensive and high-difficulty problems.
- Recommended Model: GPT-5.4 Thinking (Upfront Planning mode)
- Prompt Strategy: Tree of Thought + Solve First, Then Score
- Core Advantage: AIME perfect score level, capable of handling multi-step derivations and advanced mathematical operations
- Accuracy: 80-85% (single model performance on competition-level difficulty)
Scenario 4: Multi-Model Cross-Validation (Highest Accuracy)
Suitable for high-stakes exams (e.g., college entrance exams), requiring the highest accuracy.
- Recommended Solution: 3 models score independently → Take 2/3 majority consensus → Manual review for disputed problems
- Implementation Cost: Per-problem cost is about 3x that of a single model, but accuracy increases to 95%+
- Suitable Scale: Ideal for scenarios with a smaller volume (< 500 problems) but extremely high quality requirements
| Scenario | Recommended Model | Prompt Strategy | Accuracy | Cost (per 1000 problems) |
|---|---|---|---|---|
| Daily Homework | Gemini 3.1 Pro | Few-Shot | 85-90% | Low |
| Final Exams | Claude Sonnet 4.6 | Tree of Thought | 88-92% | Medium |
| Competition Problems | GPT-5.4 Thinking | ToT + Solve First | 80-85% | High |
| Cross-Validation | Three-Model Combo | Multi-Round Voting | 95%+ | High (3×) |
🎯 Model Switching Tip: Different scenarios have vastly different requirements for models. APIYI apiyi.com supports switching models by simply modifying a
modelparameter, making it easy to dynamically select the optimal model based on the problem type.
Frequently Asked Questions
Q1: Can Large Language Model physics problem quality inspection completely replace manual grading?
Not yet. Academic research shows that while Large Language Models can achieve 90%+ accuracy on standardized calculation problems, their accuracy drops to just 8.3% on under-specified problems. The recommended approach is to have the Large Language Model handle 80% of standard problem grading, with humans responsible for reviewing the 20% of complex and disputed problems.
Q2: How complex is the API integration for these three models?
The three models come from three different platforms: Google, Anthropic, and OpenAI. Registering and integrating with each one individually involves high development costs. We recommend using the unified interface via APIYI apiyi.com. All models use the same OpenAI SDK format, and you only need to change the model parameter to switch between them, significantly reducing integration costs.
Q3: How do you evaluate the accuracy of the quality inspection system?
We recommend using Cohen's Kappa coefficient to measure the consistency between model and human scoring:
- Prepare a test set of 50-100 physics problems that have already been manually graded.
- Call the three models for scoring via APIYI apiyi.com.
- Calculate the Kappa value for each model compared to human scoring.
- A Kappa > 0.8 indicates high agreement and the system is ready for deployment.
Summary
The key points for Large Language Model physics problem quality inspection:
- Gemini 3.1 Pro Preview is the top choice: Strongest STEM reasoning capabilities and best value for money, ideal for high-volume daily physics problem inspection.
- Claude Sonnet 4.6 is best for report generation: Adaptive thinking mode + structured output, perfect for formal exams requiring detailed scoring rationale.
- GPT-5.4 handles competition-level problems: AIME-perfect-level reasoning ability, most reliable for high-difficulty comprehensive physics problems.
- Multi-model cross-validation boosts accuracy to 95%+: Three models independently score and reach consensus—this is currently the most reliable automated quality inspection solution.
Which model you choose depends on your problem types and accuracy requirements. We recommend quickly testing and comparing through APIYI at apiyi.com. The platform offers free credits and a unified interface—you can call all mainstream models with just one API key.
📚 References
-
MDPI Education Sciences – Research on Intelligent Scoring of Physics Problems Based on Large Language Models: Compares the performance of four Prompt strategies in physics problem scoring.
- Link:
mdpi.com/2227-7102/15/2/116 - Description: Source for experimental data showing Tree of Thought strategy accuracy ≥ 0.9.
- Link:
-
Physical Review – Evaluation of LLMs on Physics Olympiad Problems: Systematic assessment of GPT and reasoning models on physics competition problems.
- Link:
link.aps.org/doi/10.1103/6fmx-bsnl - Description: Key evidence that Large Language Model physics reasoning ability has surpassed the average human level.
- Link:
-
Google DeepMind – Gemini 3.1 Pro Technical Blog: Details on model architecture and STEM benchmark testing.
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Description: Official source for Gemini 3.1 Pro physics reasoning evaluation data.
- Link:
-
Anthropic – Claude Sonnet 4.6 Release Announcement: Details on adaptive thinking mode and mathematical capability improvements.
- Link:
anthropic.com/news/claude-sonnet-4-6 - Description: Technical details on Claude Sonnet 4.6's 27% leap in mathematical ability.
- Link:
-
OpenAI – GPT-5.4 Release Announcement: Upfront Planning and reasoning efficiency improvements.
- Link:
openai.com/index/introducing-gpt-5-4/ - Description: Official data on GPT-5.4's AIME perfect score and Token efficiency optimization.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to discuss practical experiences with Large Language Model physics problem quality inspection in the comments. For more model invocation tutorials, visit the APIYI documentation center at docs.apiyi.com.