
Autorennotiz: Detaillierte Analyse der Ursachen für 429-Rate-Limiting bei Gemini 3.1 Flash Image Preview, Vergleich der Limitierungsstrategien von AI Studio, Vertex AI und Drittanbieter-Plattformen, mit 4 praktisch getesteten Lösungen.
Beim Erzeugen von Bildern mit Gemini 3.1 Flash Image Preview ist nicht die Qualität das größte Problem, sondern dass man sofort von einer 429-Rate-Limitierung gestoppt wird. Egal ob man AI Studio oder Vertex AI nutzt, die Limits für RPD (Anfragen pro Tag) und RPM (Anfragen pro Minute) sind extrem streng, sodass Batch-Bilderzeugung praktisch unmöglich ist.
Dieser Artikel basiert auf praktischer Erfahrung, analysiert detailliert die Ursachen der 429-Limitierung, vergleicht die Unterschiede in den Limitierungsstrategien der verschiedenen Plattformen und bietet 4 validierte Lösungen – inklusive einer Option ohne Limitierung der Parallelität und Kosten von nur $0,045 pro Bild.
Kernwert: Nach dem Lesen dieses Artikels verstehen Sie die zugrundeliegende Logik hinter dem 429-Fehler bei der Gemini-Bilderzeugung und finden die für Ihr Szenario passendste Lösung.
Was ist der Gemini 3.1 Flash Image Preview 429-Fehler?
Schauen wir uns zunächst an, wie dieser Fehler aussieht:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
In einfachen Worten: Sie haben Ihr tägliches Anfragelimit erreicht oder senden Anfragen zu häufig pro Minute.
Im Gegensatz zum 503-Fehler ist 429 kein Problem der Serverkapazität, sondern ein von Google aktiv gesetztes Kontingentlimit. Unabhängig davon, ob freie Rechenleistung verfügbar ist, werden Anfragen abgelehnt, sobald das Limit erreicht ist.
Unterschied zwischen 429- und 503-Fehlern bei der Gemini-Bilderzeugung
| Vergleichspunkt | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| Ursache | Ihr Kontingent ist aufgebraucht | Server-Rechenleistung unzureichend |
| Auslöser | Überschreitung von RPD/RPM/TPM-Limits | Globale hohe Auslastung |
| Betroffener Bereich | Nur Ihr Projekt | Alle Nutzer |
| Lösbar durch Warten? | RPM: 1 Minute, RPD: bis zum nächsten Tag | Normalerweise Minuten bis Stunden |
| Lösbar durch Bezahlung? | Vertex AI: Kontingenterhöhung möglich | Nicht direkt lösbar |
| Grundlösung | Plattformwechsel / Kontingenterhöhung | Warten oder Plattform wechseln |
Vergleich der Drosselungsstrategien für Gemini 3.1 Flash Image Preview auf verschiedenen Plattformen
Das ist der Kern des Problems – die Drosselungslimits unterscheiden sich enorm zwischen den Plattformen.
Drosselungsparameter für Gemini Bilderzeugung in AI Studio
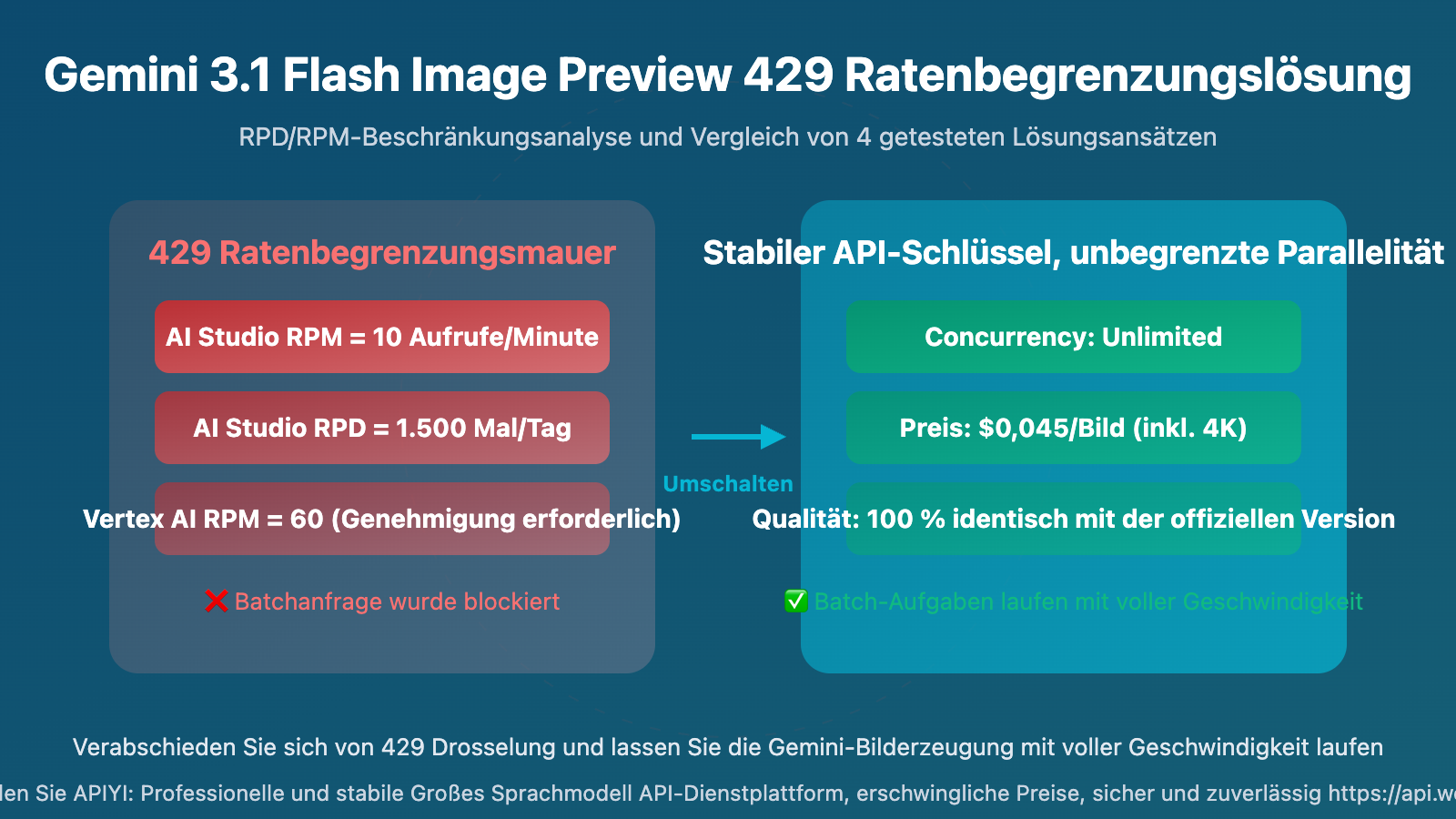
AI Studio ist die erste Wahl für die meisten Entwickler, kostenlos und gut nutzbar. Aber die Limits für die Bilderzeugung sind extrem streng:
| Drosselungsdimension | Limit | Umrechnung |
|---|---|---|
| RPM (Requests pro Minute) | 10 | Nur 1 Anfrage alle 6 Sekunden möglich |
| RPD (Requests pro Tag) | 1.500 | Nach ca. 2,5 Stunden Laufzeit erreicht |
| TPM (Tokens pro Minute) | 4.000.000 | Normalerweise kein Engpass |
| Bildausgabe TPM | 12.000 tokens/min | Ca. 10 Bilder/Minute |
Praktische Erfahrung: Wenn Sie 500 Bilder im Batch erzeugen müssen, sind bei RPM=10 theoretisch mindestens 50 Minuten nötig. Unter Berücksichtigung von Netzwerklatenz und Wiederholungsversuchen dauert es in der Praxis 1-2 Stunden. Wenn Sie mehr als 1.500 Bilder pro Tag benötigen, stoßen Sie direkt an die RPD-Grenze.
Drosselungsparameter für Gemini Bilderzeugung in Vertex AI
Vertex AI ist die Enterprise-Lösung von Google Cloud mit höheren Kontingenten, aber auch hier gibt es Obergrenzen:
| Drosselungsdimension | Standardwert | Kann erhöht werden |
|---|---|---|
| RPM | 60 | Ja, mit Genehmigung |
| RPD | Kein festes Limit | Aber durch RPM und TPM eingeschränkt |
| TPM | 4.000.000 | Kann beantragt werden |
| Bildausgabe TPM | 24.000 tokens/min | Kann beantragt werden |
Praktische Erfahrung: RPM steigt von 10 auf 60, was viel besser aussieht. Die Erhöhung muss aber über den Google Cloud Support-Ticket-Prozess beantragt werden und dauert in der Regel 1-3 Werktage. Zudem ist die Konfiguration von Vertex AI viel komplexer als bei AI Studio (GCP-Projekt erstellen, Service Account einrichten, IAM-Berechtigungen konfigurieren usw.). Viele Einzelentwickler und kleine Teams geben deshalb direkt auf.
Vergleich der Drosselung für Gemini Bilderzeugung auf Drittanbieter-Plattformen
| Plattform | Parallelitätslimit | RPD-Limit | Preis pro Bild (1K) | Anmerkung |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1.500/Tag | Kostenlos (begrenztes Kontingent) | Am strengsten |
| Vertex AI | RPM=60 | Kein festes Limit | ~$0,067 | GCP-Konfiguration nötig |
| OpenRouter | Abhängig vom Tarif | Abhängig vom Tarif | ~$0,06-0,08 | Generische Plattform |
| Wentuo.ai | Kein Parallelitätslimit | Kein Limit | $0,045 | Nutzungsbasierte Abrechnung, Auflösung unbegrenzt |
4 Lösungen für das 429-Drosselungsproblem von Gemini 3.1 Flash Image Preview
Lösung 1: Drosselung und automatische Wiederholung für Gemini Bilderzeugungsanfragen
Die grundlegendste Lösung, kein Plattformwechsel nötig, aber ineffizient.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""Bilderzeugungsanfrage mit Backoff-Wiederholung"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# Exponentielles Backoff + zufälliges Jitter
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 Drosselung, warte {wait_time:.1f}s vor Wiederholung ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"Anfragefehler: {e}")
time.sleep(2)
raise Exception("Maximale Anzahl an Wiederholungsversuchen überschritten")
Vollständiges Batch-Erzeugungsskript anzeigen (mit Ratenkontrolle)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""Batch-Generator, der das AI Studio RPM=10-Limit einhält"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # Minimaler Abstand zwischen Anfragen
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] Warte {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"Fehler: {e}")
time.sleep(2)
return False
# Verwendungsbeispiel
gen = RateLimitedGenerator("DEIN_AISTUDIO_SCHLÜSSEL", rpm_limit=10)
prompts = ["ein Sonnenuntergang über Bergen", "eine Katze im Weltraum", "futuristische Stadt"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
Vorteile: Kostenlos, geeignet für kleine Anfragemengen
Nachteile: Langsam, die harte RPD=1.500-Grenze kann nicht überschritten werden
Lösung 2: Gemini Bilderzeugung zu Vertex AI migrieren, um Kontingent zu erhöhen
Geeignet für Unternehmensnutzer mit Google Cloud-Konto.
Vorgehensweise:
- GCP-Projekt erstellen und Vertex AI API aktivieren
- Service Account und IAM-Berechtigungen einrichten
- In Google Cloud Console → IAM → Quotas die RPM-Erhöhung beantragen
- Endpunkt im Code von AI Studio auf Vertex AI umstellen
Vorteile: RPM steigt von 10 auf 60+, für Unternehmensszenarien nutzbar
Nachteile: Komplexe Konfiguration, Genehmigungszyklus 1-3 Tage, Abrechnung nach Google Cloud-Standardsätzen
Lösung 3: Mehrere Projekte für Gemini Bilderzeugung rotieren lassen
Durch Erstellen mehrerer GCP-Projekte oder AI Studio API-Schlüssel können Anfragen abwechselnd gesendet werden, um die RPD/RPM-Limits eines einzelnen Projekts zu umgehen.
import itertools
api_keys = ["SCHLÜSSEL_1", "SCHLÜSSEL_2", "SCHLÜSSEL_3", "SCHLÜSSEL_4", "SCHLÜSSEL_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""Bilderzeugung mit Schlüssel-Rotation"""
key = next(key_pool)
# ... Anfrage mit aktuellem Schlüssel senden
return send_request(prompt, api_key=key)
Vorteile: Theoretisch N-facher Durchsatz mit N Schlüsseln möglich
Nachteile: Verstößt gegen die Google Nutzungsbedingungen (TOS), Kontosperrungsrisiko; Verwaltung mehrerer Schlüssel erhöht die Komplexität
Lösung 4: Gemini Bilderzeugung über Drittanbieter-Plattform ohne Parallelitätslimit nutzen
Das ist die Lösung, die ich letztendlich gewählt habe. Nach dem Vergleich mehrerer Drittanbieter-Plattformen habe ich mich für Wentuo.ai entschieden, aus einem einfachen Grund:
| Vergleichsdimension | AI Studio | Vertex AI | Wentuo.ai |
|---|---|---|---|
| Parallelitätslimit | RPM=10 | RPM=60 | Kein Limit |
| Tägliches Limit | 1.500/Tag | Durch RPM eingeschränkt | Kein Limit |
| Preis pro Bild (inkl. 4K) | Kostenlos, aber begrenzt | $0,067-$0,151 | $0,045 |
| Nutzungsbasierte Abrechnung (1K) | – | $0,067 | ca. $0,025 |
| Konfigurationskomplexität | Einfach | Komplex | Einfach |
| VPN/Proxy nötig? | Ja | Ja | Nein |
In der Praxis kostet die nutzungsbasierte Abrechnung $0,045 pro Bild inklusive 4K-Auflösung. Bei Abrechnung nach Tokens liegt der Preis zwischen $0,02 und $0,05, abhängig von der Auflösung. Das Wichtigste ist jedoch das fehlende Parallelitätslimit – Batch-Aufgaben können mit voller Geschwindigkeit laufen, ohne durch 429-Fehler blockiert zu werden.
Der Aufruf ist ebenfalls einfach, nur der Endpunkt muss geändert werden:
import requests
import base64
API_KEY = "dein-wentuo-api-schluessel"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "Eine süße Katze mit einem Raumanzughelm"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 Nutzungsempfehlung: Wenn Sie täglich mehr als 500 Bilder erzeugen oder hohe Parallelität benötigen, empfehle ich direkt die Lösung ohne Parallelitätslimit von Wentuo.ai. Die nutzungsbasierte Abrechnung kostet $0,045/Bild (Auflösung unbegrenzt), die tokenbasierte Abrechnung ab $0,018/Bild (512px). Das spart 33%-70% gegenüber den offiziellen Google-Preisen.
4 Lösungsvorschläge für Gemini 3.1 Flash Image Preview 429 Rate Limiting
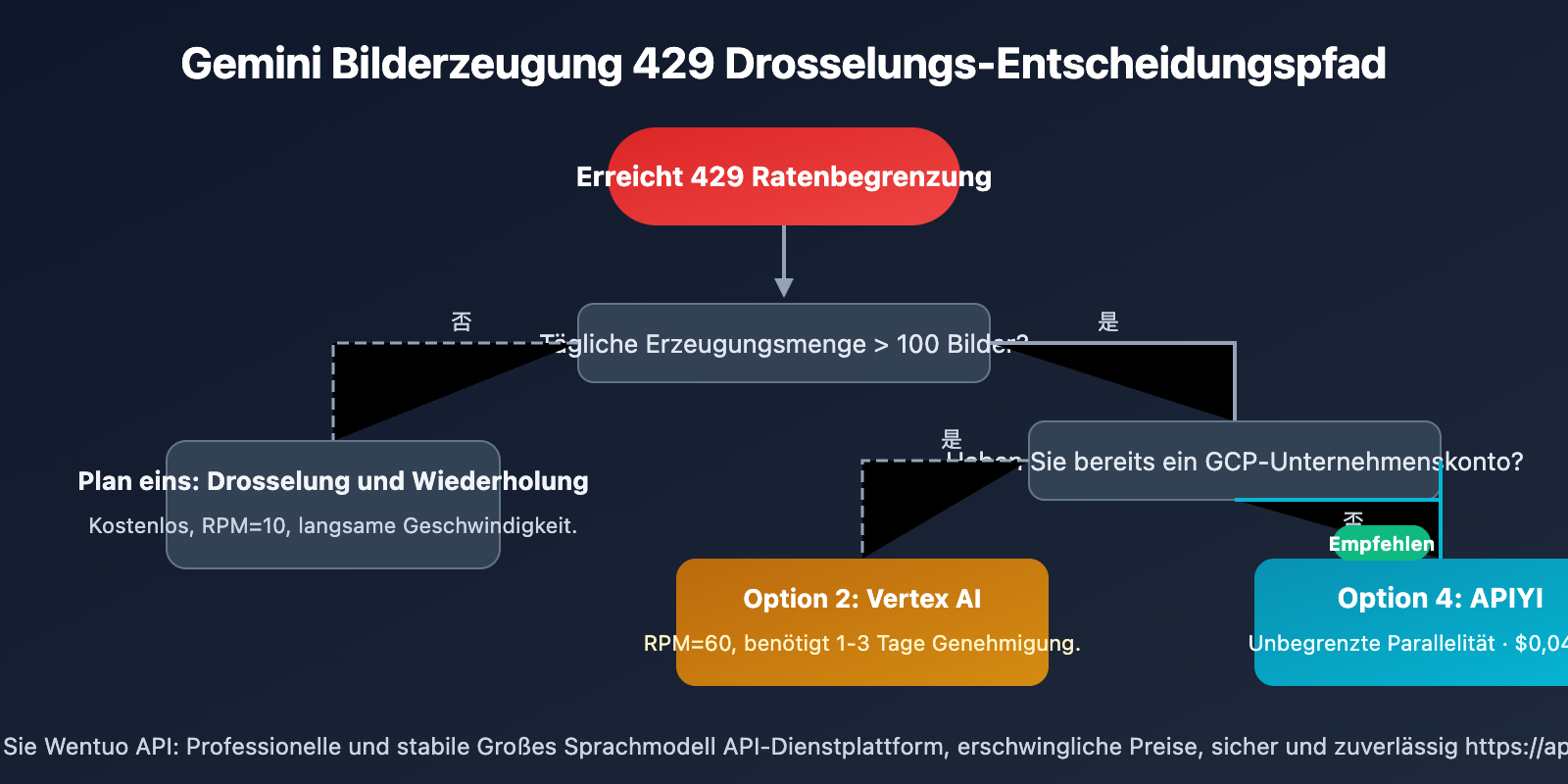
Für verschiedene Szenarien eignen sich unterschiedliche Ansätze:
| Anwendungsszenario | Empfohlene Lösung | Begründung |
|---|---|---|
| 🎨 Persönliches Lernen/Testen | Lösung 1 (Throttling & Retry) | Kostenlos, bei geringem Volumen unkritisch |
| 🏢 Unternehmen mit bestehender GCP-Nutzung | Lösung 2 (Vertex AI) | Compliance-konform, höhere Kontingente beantragbar |
| 🔬 Temporäre, umfangreiche Tests | Lösung 3 (Mehrere API-Schlüssel) | Kurzfristig nutzbar, Risiken beachten |
| 🚀 Produktivumgebung/Batch-Generierung | Lösung 4 (Wentuo.ai API) | Keine Concurrency-Limits, kostengünstigster Ansatz |
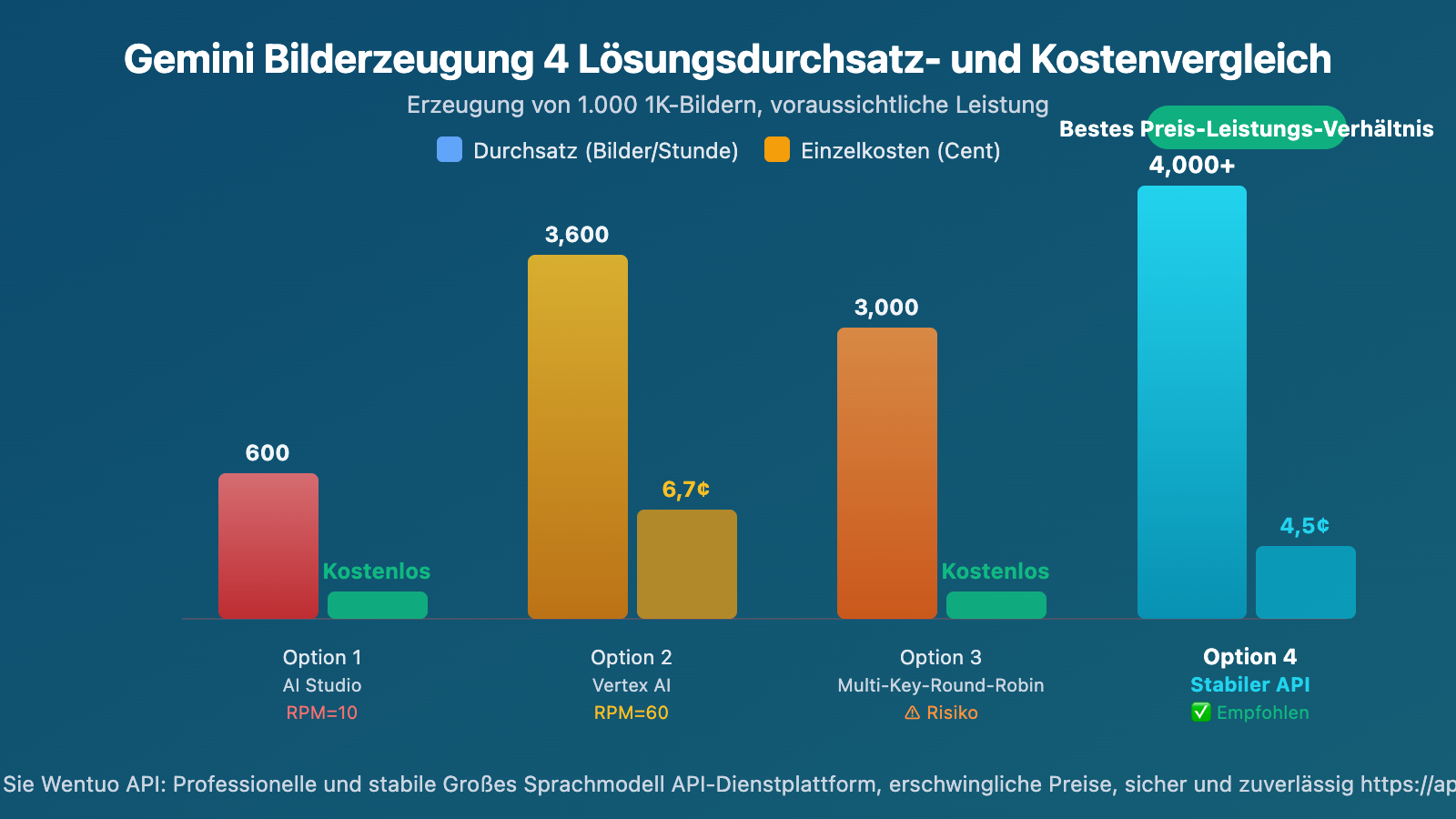
Durchsatzvergleich der verschiedenen Ansätze für Gemini-Bilderzeugung
Annahme: Erzeugung von 1.000 Bildern in 1K-Auflösung:
| Lösung | Geschätzte Dauer | Gesamtkosten | Machbarkeit |
|---|---|---|---|
| AI Studio (RPM=10) | ~100 Min. + RPD-Limit kann Verzögerung auf nächsten Tag bedeuten | Kostenlos | ⚠️ Durch RPD limitiert |
| Vertex AI (RPM=60) | ~17 Minuten | ~$67 | ✅ GCP-Account erforderlich |
| Multi-Key Rotation (5 Schlüssel) | ~20 Minuten | Kostenlos | ⚠️ Risiko der Account-Sperrung |
| Wentuo.ai API (Keine Concurrency-Limits) | ~10-15 Minuten | $45 (Pay-per-Use) / ~$25 (Volumenbasiert) | ✅ Empfohlen |
Häufig gestellte Fragen (FAQ)
F1: Wie lange dauert es, bis die Gemini 3.1 Flash Image Preview 429-Fehler wieder verschwinden?
Das hängt davon ab, welche Art von Rate Limit ausgelöst wurde:
- RPM-Limit: Wartezeit von 1 Minute, dann automatische Wiederherstellung
- RPD-Limit: Wartezeit bis zur täglichen Zurücksetzung (UTC 0 Uhr)
- TPM-Limit: Wartezeit von 1 Minute, dann Wiederherstellung
Empfehlung: Im Code anhand des quota_limit-Werts im details-Feld das spezifische Limit identifizieren und entsprechende Maßnahmen ergreifen.
F2: Ist die Bildqualität bei der Wentuo.ai API genauso gut wie bei Google direkt?
Ja, die Wentuo.ai API (wentuo.ai) nutzt direkt das offizielle Google Gemini 3.1 Flash Image Preview Modell. Die Bildqualität ist daher identisch. Der Unterschied liegt in:
- Entfernung der RPD/RPM-Limits
- Unterstützung unbegrenzter gleichzeitiger Anfragen
- Günstigeren Preisen ($0.045/Bild vs. offiziell $0.067/Bild@1K)
F3: Wann wähle ich Pay-per-Use und wann Volumen-basierte Abrechnung?
Eine einfache Entscheidungslogik:
- Feste Nutzung von 2K/4K Auflösung → Wähle Pay-per-Use ($0.045/Anfrage, unabhängig von der Auflösung am günstigsten)
- Hauptsächliche Nutzung von 512px/1K → Wähle Volumen-basierte Abrechnung (512px nur $0.018/Anfrage, 60% günstiger als Pay-per-Use)
- Gemischte Auflösungen → Berechne die durchschnittlichen Kosten, meist ist Volumen-basierte Abrechnung günstiger
Die Wentuo.ai API (wentuo.ai) unterstützt einen flexiblen Wechsel zwischen beiden Abrechnungsmodellen.
🎯 Zusammenfassung
Das 429-Ratelimit-Problem bei Gemini 3.1 Flash Image Preview ist im Wesentlichen auf die strengen Kontingentgrenzen (RPD/RPM) zurückzuführen, die Google für AI Studio und Vertex AI festgelegt hat. Die Kernpunkte sind:
- Limitierungstyp verstehen: 429 ist ein Kontingentlimit (Ihr Problem), 503 ist eine Serverüberlastung (Googles Problem) – die Lösungsansätze sind völlig unterschiedlich.
- Ihre Nutzung bewerten: Bis zu 100 Bilder pro Tag sind mit AI Studio ausreichend. Bei über 500 Bildern sollten Sie eine Drittplattform in Betracht ziehen.
- Passende Lösung wählen: Für Produktionsumgebungen wird eine Lösung ohne Parallelitätsbeschränkung empfohlen, um Geschäftsprozesse vor Limitierungseffekten zu schützen.
- Kostenvergleich ist entscheidend: Die API von APIYI kostet pro Anfrage $0.045/Bild (inkl. 4K), bei Volumenabrechnung sogar nur $0.018/Bild – das sind 33 % bis 70 % Ersparnis gegenüber den offiziellen Preisen.
Für Entwickler, die Bilder in großen Mengen generieren müssen, ist die API von APIYI (wentuo.ai) derzeit die beste Wahl in puncto Gesamterfahrung – keine Parallelitätsbeschränkungen, niedrigere Kosten, keine Firewall-Umgehung nötig und vollständig kompatible Schnittstellen.
📚 Referenzen
-
Offizielle Google Gemini API-Dokumentation: Erläuterungen zu Kontingenten und Ratelimits bei der Bilderzeugung
- Link:
ai.google.dev/gemini-api/docs/image-generation - Beschreibung: Offizielle Kontingentparameter und Best Practices
- Link:
-
Google Cloud Kontingentverwaltung: Prozess zur Kontingenterhöhung für Vertex AI
- Link:
cloud.google.com/vertex-ai/docs/quotas - Beschreibung: Offizieller Weg für Unternehmenskunden, ihre Kontingente zu erhöhen
- Link:
-
APIYI Nano Banana 2 Dokumentation: Anleitung zur Integration der Bilderzeugung ohne Parallelitätsbeschränkung
- Link:
docs.wentuo.ai - Beschreibung: Detaillierte Erläuterungen und Codebeispiele für die beiden Abrechnungsmodelle (pro Anfrage/volumenbasiert)
- Link:
📝 Über den Autor: Das Technische Content-Team, spezialisiert auf AI-Bilderzeugung und API-Technologie. Weitere technische Inhalte und Ressourcen finden Sie auf APIYI wentuo.ai.
📋 Hinweis zum Inhalt: Dieser Artikel basiert auf praktischen Erfahrungen. Die genauen Limitierungsparameter können sich mit Googles Richtlinien ändern. Für technischen Support kontaktieren Sie uns bitte über APIYI wentuo.ai.