
GPT-5.5 vs Claude Opus 4.7 是 2026 年上半年開發者最關心的旗艦模型對比之一。
兩者都不是單純的聊天模型。
GPT-5.5 更強調 agentic coding、計算機使用、知識工作和科研分析。
Claude Opus 4.7 則強調複雜推理、長期代理任務、高分辨率視覺、記憶能力和更嚴格的指令跟隨。
如果只問「哪個更強」,答案會很粗糙。
更實用的問題應該是:你的任務是代碼修復、知識庫問答、長上下文分析、視覺理解、自動化代理,還是高成本的生產 API 調用?
不同任務下,GPT-5.5 vs Claude Opus 4.7 的選擇會明顯不同。
OpenAI 官方發佈 GPT-5.5 時,直接把 Claude Opus 4.7 放進多項評測表中。
Anthropic 官方也把 Claude Opus 4.7 定位爲其目前最強的通用可用模型,並強調它在 agentic coding、知識工作、視覺任務和記憶任務上的提升。
本文基於英文官方資料進行整理,不引用中文二手資料。
需要特別說明的是,本文討論的「Claude 4.7」準確指 Claude Opus 4.7。
截至本文寫作時,Anthropic 官方資料中並未顯示 Claude Sonnet 4.7 已發佈。

GPT-5.5 vs Claude Opus 4.7 核心結論
GPT-5.5 vs Claude Opus 4.7 的第一層差異,是模型定位不同。
OpenAI 把 GPT-5.5 定義爲更適合真實工作流的模型。
它強調編碼、調試、在線研究、數據分析、文檔和表格生成,以及跨工具完成任務。
Anthropic 把 Claude Opus 4.7 定義爲其最強的通用可用模型。
它強調複雜推理、agentic coding、長程任務、視覺理解、記憶能力和自我校驗。
如果你的任務是 Codex 裏的複雜工程項目、跨文件修改、工具調用和知識工作,GPT-5.5 往往更值得優先測試。
如果你的任務是 Claude Code 長時間代理、視覺截圖理解、文檔排版校驗、文件系統記憶和嚴格指令跟隨,Claude Opus 4.7 更值得優先測試。
如果你需要統一接入兩類模型,建議通過 API易 apiyi.com 做多模型路由和評測,避免把模型選擇寫死在業務代碼裏。
GPT-5.5 vs Claude Opus 4.7 快速對比
| 維度 | GPT-5.5 | Claude Opus 4.7 | 選擇建議 |
|---|---|---|---|
| 官方定位 | 真實工作流和 agentic AI | 最強通用可用 Claude 模型 | 按任務類型選 |
| 編碼能力 | Terminal-Bench 2.0 表現強 | agentic coding 明顯提升 | 都應實測 |
| 長上下文 | API 最高 1M context | 1M context window | 都適合長上下文 |
| 視覺能力 | 多模態與工具協作 | 高分辨率圖像支持 | 視覺重任務偏 Claude |
| 推理控制 | reasoning_effort | effort / adaptive thinking | 參數體系不同 |
| API 成本 | $5 輸入 / $30 輸出每百萬 token | $5 輸入 / $25 輸出每百萬 token | Claude 輸出價更低 |
| 生態入口 | ChatGPT、Codex、API | Claude、Claude Code、API | 取決於工作流 |
選擇建議:如果你無法確定 GPT-5.5 vs Claude Opus 4.7 哪個更適合,建議先準備 30-50 條真實業務樣本,通過 API易 apiyi.com 同時跑兩個模型,對比成功率、響應時間、成本和人工評分。
GPT-5.5 vs Claude Opus 4.7 編碼能力對比
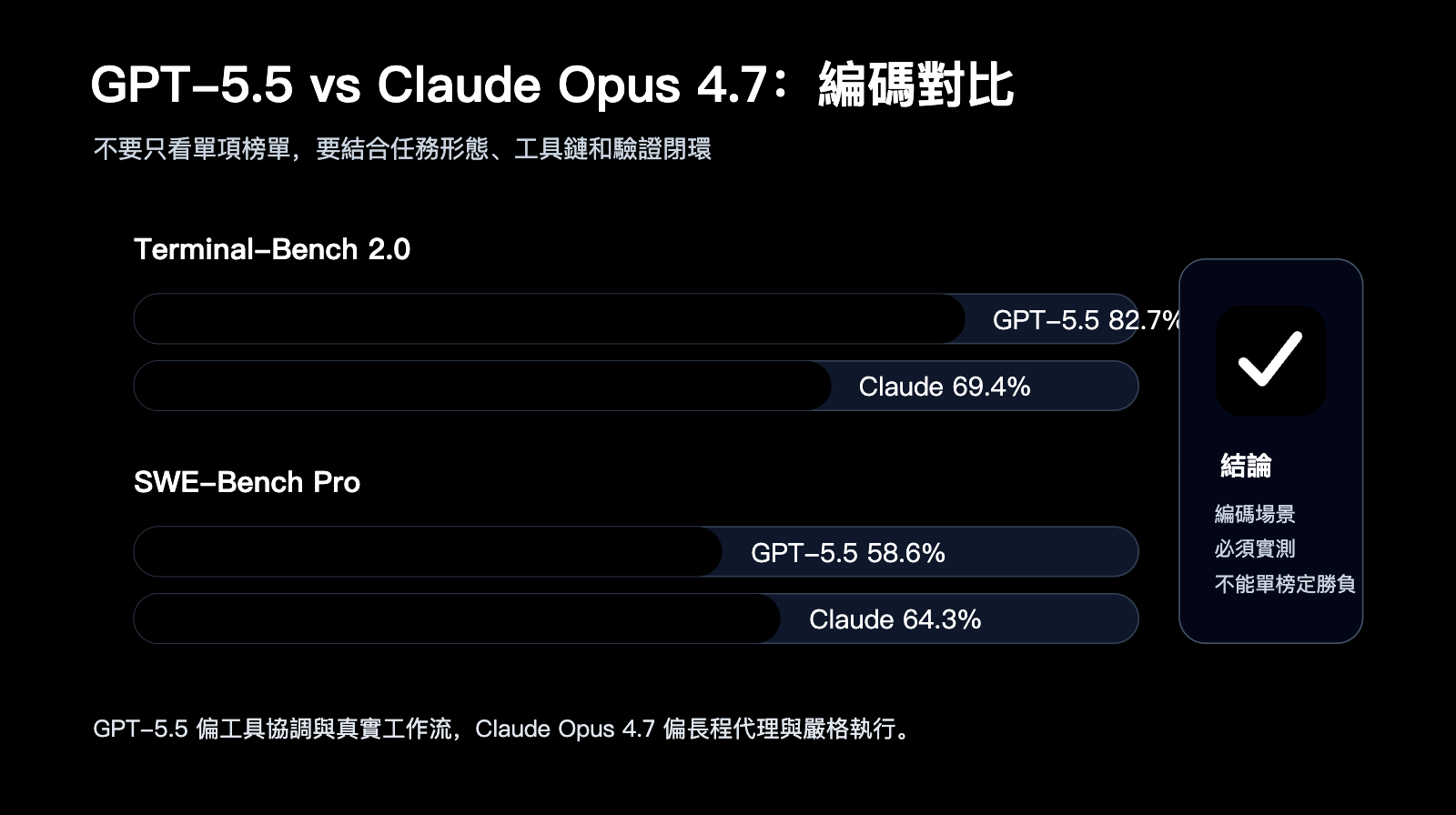
編碼是 GPT-5.5 vs Claude Opus 4.7 最核心的對比場景。
OpenAI 官方數據顯示,GPT-5.5 在 Terminal-Bench 2.0 上達到 82.7%。
同一張表中,Claude Opus 4.7 爲 69.4%。
在 SWE-Bench Pro 公開評測上,GPT-5.5 爲 58.6%,Claude Opus 4.7 爲 64.3%。
這說明兩個模型並不是單邊勝出。
GPT-5.5 在命令行復雜工作流、計劃、迭代和工具協調上表現更突出。
Claude Opus 4.7 在 GitHub issue 解決類任務上也有很強競爭力。
Anthropic 官方材料還強調,Claude Opus 4.7 在其 93-task coding benchmark 上比 Opus 4.6 提升 13%。
這意味着 Claude Opus 4.7 相對上一代的編碼提升是明確的。
但如果只看 GPT-5.5 vs Claude Opus 4.7,不能把某一個 benchmark 當成全部結論。
真實編碼工作還包括:讀懂舊代碼、識別風險、改動範圍控制、測試補齊、運行命令、處理失敗、解釋變更和生成 review notes。
GPT-5.5 在 Codex 場景中強調跨工具執行和更少 token 完成任務。
Claude Opus 4.7 在 Claude Code 場景中強調長程代理、xhigh effort 和更嚴格的指令跟隨。
GPT-5.5 vs Claude Opus 4.7 編碼場景建議
| 編碼任務 | 更推薦優先測試 | 原因 |
|---|---|---|
| 命令行復雜工作流 | GPT-5.5 | Terminal-Bench 2.0 官方分數更高 |
| GitHub issue 修復 | Claude Opus 4.7 / GPT-5.5 都測 | SWE-Bench Pro Claude 更高,GPT-5.5 生態強 |
| 大型代碼庫理解 | GPT-5.5 | Codex 場景強調跨系統上下文 |
| 長時間代理任務 | Claude Opus 4.7 | xhigh effort 與 task budget 更貼合 |
| 代碼審查與驗證 | 兩者都適合 | 重點看測試閉環 |
| 成本敏感批量修復 | 需要實測 | token 使用形態差異大 |
選擇建議:編碼模型不要只看榜單。我們建議把你的真實 issue、失敗測試、PR review 和重構任務放入 API易 apiyi.com 做對比評測,記錄每個模型是否真的跑了測試、是否誤改無關文件、是否能說明風險。
GPT-5.5 vs Claude Opus 4.7 知識工作與研究能力
GPT-5.5 vs Claude Opus 4.7 在知識工作上的對比也很關鍵。
OpenAI 官方材料顯示,GPT-5.5 在 GDPval 上達到 84.9%。
Claude Opus 4.7 在同一表中爲 80.3%。
GPT-5.5 Pro 爲 82.3%。
這說明在 OpenAI 所列的專業知識工作評測中,GPT-5.5 表現非常強。
OpenAI 還強調 GPT-5.5 在生成文檔、表格、演示文稿、處理運營研究和商業輸入方面有明顯提升。
Anthropic 方面,Claude Opus 4.7 的官方資料強調它在 knowledge work、memory、vision 和 long-horizon agentic work 上表現突出。
Claude Opus 4.7 的一個重要特點是更強的數據紀律。
Anthropic 頁面引用 Hex 的評價,認爲它在缺失數據時更願意說明缺失,而不是給出看似合理但錯誤的替代。
這對金融分析、研究報告、合規審查和數據表格處理很重要。
如果你的知識工作任務需要模型寫出漂亮、完整、結構清晰的業務文檔,GPT-5.5 非常值得測試。
如果你的任務需要模型在缺失數據、衝突數據和長上下文中保持謹慎,Claude Opus 4.7 也非常有競爭力。
GPT-5.5 vs Claude Opus 4.7 知識工作選擇
| 場景 | GPT-5.5 優勢 | Claude Opus 4.7 優勢 | 建議 |
|---|---|---|---|
| 商業報告 | 結構化生成強 | 數據紀律強 | 兩者對比 |
| 表格分析 | Codex 文檔表格能力強 | 視覺校驗和圖表分析強 | 看輸入形態 |
| 金融研究 | GDPval 表現強 | General Finance 模塊提升 | 用真實樣本測 |
| 合規審查 | 綜合能力強 | 缺失數據處理謹慎 | Claude 優先測 |
| 多文檔總結 | 長上下文強 | 記憶和嚴格指令強 | 按引用質量選 |
選擇建議:知識工作最怕「看起來很完整,實際有幻覺」。在 API易 apiyi.com 做 GPT-5.5 vs Claude Opus 4.7 對比時,建議把人工評分拆成事實準確性、引用一致性、遺漏率、結構質量和可執行性 5 個維度。
GPT-5.5 vs Claude Opus 4.7 視覺與長上下文能力
GPT-5.5 vs Claude Opus 4.7 都支持長上下文,但細節不同。
OpenAI 官方材料顯示,GPT-5.5 API 具備 1M context window。
Anthropic 模型總覽顯示,Claude Opus 4.7 也支持 1M tokens context window,並支持 128k max output。
在長上下文任務中,兩者都進入了可處理大型文檔、代碼庫和複雜資料包的範圍。
但視覺任務上,Claude Opus 4.7 的官方變化更明確。
Anthropic 文檔顯示,Claude Opus 4.7 是首個支持高分辨率圖像的 Claude 模型,最大圖像分辨率提升到 2576px / 3.75MP。
這對截圖理解、文檔圖像、幻燈片校驗、圖表分析和 computer use 很重要。
Anthropic 還提到,圖像座標現在與真實像素 1:1 對應,減少了座標縮放換算。
GPT-5.5 也有很強的多模態和計算機使用能力,但如果你的輸入核心是高分辨率截圖、圖表、文檔版式或 UI 座標,Claude Opus 4.7 值得優先測試。
如果你的輸入是長文本、代碼庫、業務文檔、結構化資料和工具鏈結果,GPT-5.5 與 Claude Opus 4.7 都需要用同一套樣本評估。
GPT-5.5 vs Claude Opus 4.7 API 參數與遷移差異
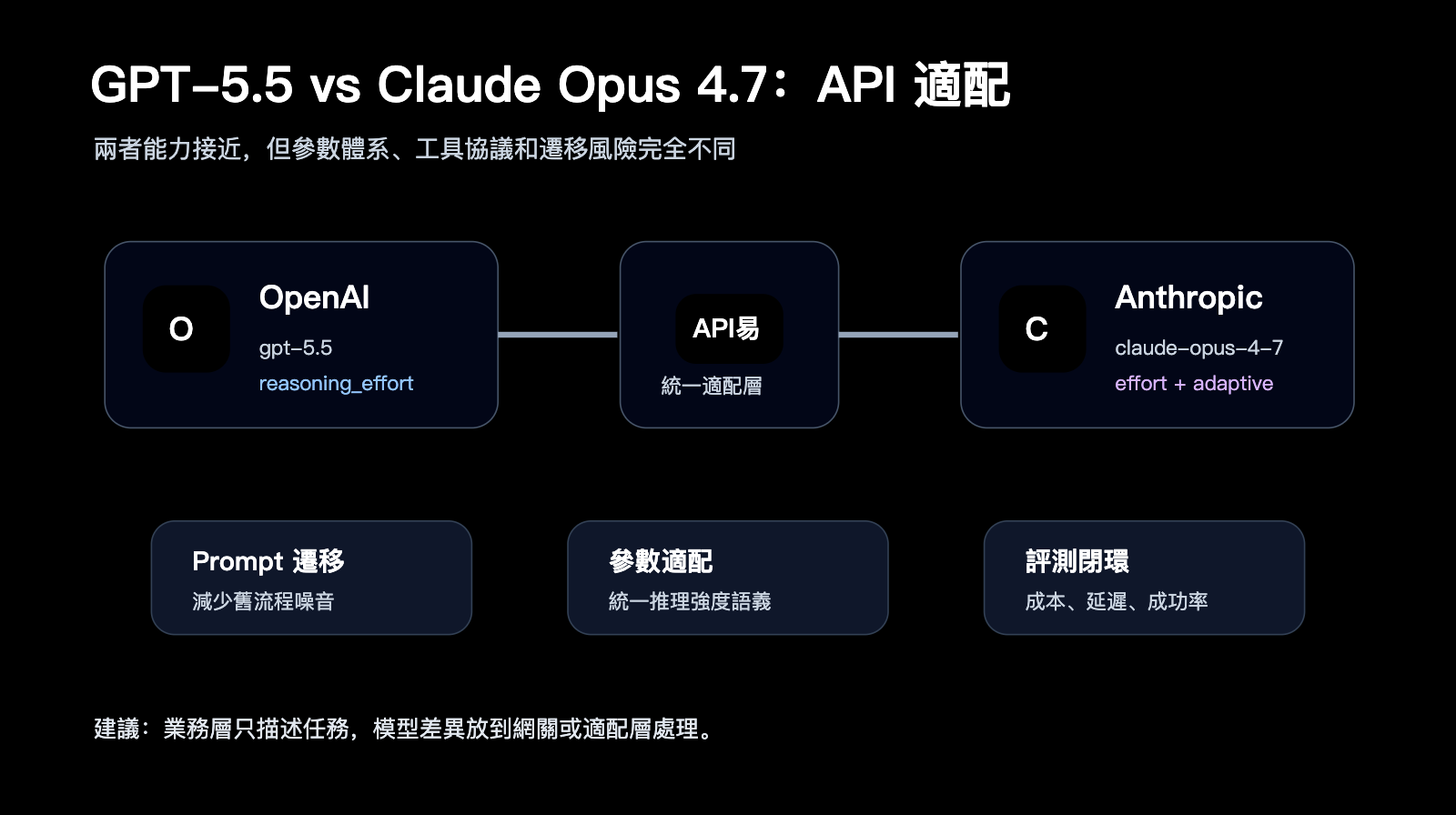
GPT-5.5 vs Claude Opus 4.7 的 API 遷移差異非常大。
GPT-5.5 屬於 OpenAI 模型體系,重點參數包括 model、reasoning_effort、Responses API 工具調用和輸出格式控制。
Claude Opus 4.7 屬於 Anthropic Messages API 體系,重點參數包括 adaptive thinking、effort、task budget、max_tokens 和工具調用。
Anthropic 官方文檔顯示,Claude Opus 4.7 移除了 extended thinking budgets。
舊寫法 thinking: {"type": "enabled", "budget_tokens": N} 會返回 400 錯誤。
新寫法應使用 thinking: {"type": "adaptive"},並通過 output_config 設置 effort。
Anthropic 還說明,從 Claude Opus 4.7 開始,設置非默認 temperature、top_p 或 top_k 會返回 400 錯誤。
這對很多舊項目是重要遷移點。
如果你之前依賴 temperature=0 做確定性輸出,需要重新理解:temperature=0 本來也不保證完全一致。
相比之下,GPT-5.5 的遷移重點更偏 Prompt 重建、reasoning_effort 評估、工具工作流和結果優先提示詞。
GPT-5.5 vs Claude Opus 4.7 API 遷移重點
| 遷移項 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 模型 ID | gpt-5.5 |
claude-opus-4-7 |
| 推理控制 | reasoning_effort | effort + adaptive thinking |
| 長上下文 | 1M context window | 1M context window |
| 輸出上限 | OpenAI API 規格爲準 | 128k max output |
| 溫度參數 | 按 OpenAI API 支持情況配置 | 非默認 temperature/top_p/top_k 會報錯 |
| 工具工作流 | Responses API 工具體系 | Messages API 工具體系 |
| 遷移風險 | 舊 Prompt 過度指定 | thinking budget 和 sampling 舊參數 |
選擇建議:如果你需要同時接入 GPT-5.5 和 Claude Opus 4.7,不建議業務代碼直接寫兩套分散調用邏輯。可以通過 API易 apiyi.com 做統一 OpenAI 兼容入口,再把模型差異、參數差異和錯誤處理放到網關層或適配層管理。
GPT-5.5 vs Claude Opus 4.7 成本與性能選擇
GPT-5.5 vs Claude Opus 4.7 的成本不能只看單價。
OpenAI 官方資料顯示,GPT-5.5 API 價格爲每百萬輸入 token 5 美元、每百萬輸出 token 30 美元。
Anthropic 模型總覽顯示,Claude Opus 4.7 爲每百萬輸入 token 5 美元、每百萬輸出 token 25 美元。
單看輸出價格,Claude Opus 4.7 更低。
但 OpenAI 強調,GPT-5.5 在 Codex 中比 GPT-5.4 更 token efficient。
Anthropic 也強調 Claude Opus 4.7 通過 effort、task budget 和 adaptive thinking 控制成本。
所以真實成本取決於任務形態。
如果 GPT-5.5 用更少輪次完成任務,它的總成本未必更高。
如果 Claude Opus 4.7 在 xhigh 或 max effort 下大量消耗輸出 token,它的總成本也可能上升。
成本評估應看「完成一次合格任務的總成本」,而不是隻看每百萬 token 單價。
GPT-5.5 vs Claude Opus 4.7 成本評估維度
| 成本維度 | 應該記錄什麼 | 爲什麼重要 |
|---|---|---|
| 輸入 token | Prompt、上下文、工具結果 | 長上下文任務成本差異大 |
| 輸出 token | 最終回答、工具參數、推理相關輸出 | 輸出價格通常更貴 |
| 輪次 | 完成任務需要幾輪 | 多輪會放大成本 |
| 成功率 | 一次完成還是反覆修正 | 失敗重試是隱形成本 |
| 延遲 | 用戶等待時間 | 高 effort 會增加等待 |
| 人工複覈 | 是否需要人類修正 | 質量差會轉嫁成本 |
選擇建議:對企業應用來說,模型成本優化不是簡單選擇便宜模型。建議通過 API易 apiyi.com 記錄每次調用的輸入、輸出、延遲、模型、參數和人工評分,以「合格任務成本」作爲最終指標。
GPT-5.5 vs Claude Opus 4.7 適用場景決策
如果你是個人開發者,GPT-5.5 vs Claude Opus 4.7 可以按工具生態選擇。
你常用 Codex,就先測 GPT-5.5。
你常用 Claude Code,就先測 Claude Opus 4.7。
如果你是企業技術負責人,不建議按個人體驗拍板。
你應該建立任務集,把兩者放到同一套輸入、輸出、評分和成本記錄裏比較。
如果你是內容團隊,GPT-5.5 在結構化內容、研究整理、表格和多工具工作中值得優先測試。
Claude Opus 4.7 在謹慎表達、長上下文、視覺資料和文件校驗中值得優先測試。
如果你是 API 平臺或 SaaS 產品,建議做模型路由。
例如普通問答走成本更低的模型,複雜代碼和長代理任務再升級到 GPT-5.5 或 Claude Opus 4.7。
這樣可以避免所有請求都打到旗艦模型。
GPT-5.5 vs Claude Opus 4.7 遷移檢查清單
上線前不要只做一次主觀體驗。
建議至少準備 5 類樣本。
第一類是成功樣本。
第二類是容易誤判的邊界樣本。
第三類是長上下文樣本。
第四類是工具調用樣本。
第五類是失敗恢復樣本。
每條樣本都要記錄模型、參數、輸入 token、輸出 token、耗時、是否一次成功和人工評分。
同時要分別測試低成本檔位和高能力檔位。
GPT-5.5 側可以測試不同 reasoning_effort。
Claude Opus 4.7 側可以測試 medium、high、xhigh 和 max effort。
不要默認把兩個模型都開到最高配置。
最高配置只能說明上限,不能說明生產性價比。
GPT-5.5 vs Claude Opus 4.7 評測數據如何解讀?
GPT-5.5 vs Claude Opus 4.7 的公開 benchmark 很有參考價值,但不能直接等同於你的業務結果。
原因很簡單:公開評測通常有固定任務集、固定提示詞、固定運行環境和固定評分規則。
你的業務系統則會遇到髒數據、上下文缺失、用戶表達不穩定、工具失敗、權限限制和歷史 Prompt 包袱。
因此,看到 GPT-5.5 在某個 benchmark 上領先,不代表所有任務都應該切到 GPT-5.5。
看到 Claude Opus 4.7 在另一個 benchmark 上領先,也不代表所有任務都應該切到 Claude。
更穩妥的方式是把官方 benchmark 當作模型能力方向的提示。
例如 Terminal-Bench 2.0 更能說明覆雜命令行工作流能力。
SWE-Bench Pro 更接近真實 GitHub issue 修復能力。
GDPval 更接近專業知識工作交付能力。
視覺 benchmark 和高分辨率圖像支持,則更適合判斷截圖、圖表、UI、文檔版式相關任務。
落地時,你需要把這些維度映射到自己的產品場景。
如果產品是 IDE 編碼助手,優先看代碼修復成功率、測試通過率、無關改動率和解釋質量。
如果產品是企業知識庫,優先看引用準確率、事實遺漏率、衝突處理和拒答邊界。
如果產品是自動化代理,優先看工具調用次數、失敗恢復、任務完成率和總成本。
如果產品是視覺文檔處理,優先看座標識別、圖表轉錄、版式理解和人工修正成本。
API易 apiyi.com 的價值就在於把這些模型測試放到統一接口下執行。
同樣的輸入、同樣的評分維度、同樣的日誌字段,才能讓 GPT-5.5 vs Claude Opus 4.7 的結論真正可複用。

GPT-5.5 vs Claude Opus 4.7 FAQ
GPT-5.5 vs Claude Opus 4.7 誰更適合寫代碼?
兩者都適合。
GPT-5.5 在 Terminal-Bench 2.0 上更強,適合命令行復雜流程和 Codex 工作流。
Claude Opus 4.7 在 SWE-Bench Pro 表現很強,也適合 Claude Code 長時間代理任務。
真實項目建議用同一組 issue 和測試命令雙測。
GPT-5.5 vs Claude Opus 4.7 誰更適合知識庫問答?
如果重點是結構化生成和多工具整理,優先測試 GPT-5.5。
如果重點是缺失數據識別、謹慎表達和長上下文紀律,優先測試 Claude Opus 4.7。
最終應看引用準確率和人工複覈成本。
GPT-5.5 vs Claude Opus 4.7 誰更適合視覺任務?
Claude Opus 4.7 在官方文檔中明確加入高分辨率圖像支持。
如果任務涉及截圖、座標、文檔版式和視覺校驗,Claude Opus 4.7 值得優先測試。
GPT-5.5 也適合多模態工作流,但視覺重任務需要單獨評測。
GPT-5.5 vs Claude Opus 4.7 誰更便宜?
按官方單價,二者輸入價均爲每百萬 token 5 美元。
Claude Opus 4.7 輸出價爲每百萬 token 25 美元,GPT-5.5 輸出價爲每百萬 token 30 美元。
但實際成本取決於完成任務需要的輪次、輸出長度、失敗率和人工修正成本。
GPT-5.5 vs Claude Opus 4.7 總結
GPT-5.5 vs Claude Opus 4.7 沒有一個適用於所有場景的絕對答案。
GPT-5.5 更適合多工具生產工作流、Codex 編碼、文檔表格生成、知識工作和複雜任務執行。
Claude Opus 4.7 更適合高分辨率視覺、長程代理任務、嚴格指令跟隨、文件記憶和謹慎的數據處理。
如果你是個人用戶,可以按常用工具生態優先選擇。
如果你是企業用戶,必須用真實樣本評測。
如果你是 API 開發者,建議把模型差異放到適配層管理,不要把 GPT-5.5 或 Claude Opus 4.7 綁定死在業務邏輯裏。
API易 apiyi.com 適合承擔統一模型入口、調用記錄、成本觀測和多模型切換的角色。
最終建議是:用 GPT-5.5 處理高複雜度多工具任務,用 Claude Opus 4.7 處理高精度視覺和長代理任務,用低成本模型處理普通請求,再通過評測數據持續調整路由。
參考資料:
- OpenAI Introducing GPT-5.5: openai.com/index/introducing-gpt-5-5
- Anthropic Introducing Claude Opus 4.7: anthropic.com/news/claude-opus-4-7
- Anthropic Claude Opus 4.7 API docs: platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7
- Anthropic Models overview: platform.claude.com/docs/en/about-claude/models/overview
- Anthropic Effort docs: platform.claude.com/docs/en/build-with-claude/effort