
No dia 19 de maio de 2026, durante a conferência Google I/O 2026, o Google lançou oficialmente a família de modelos multimodais Gemini Omni, com o modelo inicial Gemini Omni Flash sendo disponibilizado aos usuários no mesmo dia. Para quem ouve esse nome pela primeira vez, o termo "Omni" é muito mais importante do que se imagina — ele representa a nova direção do Google para fundir completamente as capacidades de raciocínio inteligente do Gemini com as habilidades de geração de mídia. Neste artigo, explicaremos de forma simples o que é o Google Omni, o que ele pode fazer, como ele difere do antigo Veo e como você, como desenvolvedor ou criador, pode começar a usá-lo.
Valor central: Ao terminar este artigo, você entenderá o posicionamento, os limites de capacidade, os canais de uso e o significado industrial do Google Omni (Gemini Omni), sem se perder nos termos técnicos dos títulos das notícias.
O que é o Google Omni: Resumo das informações principais
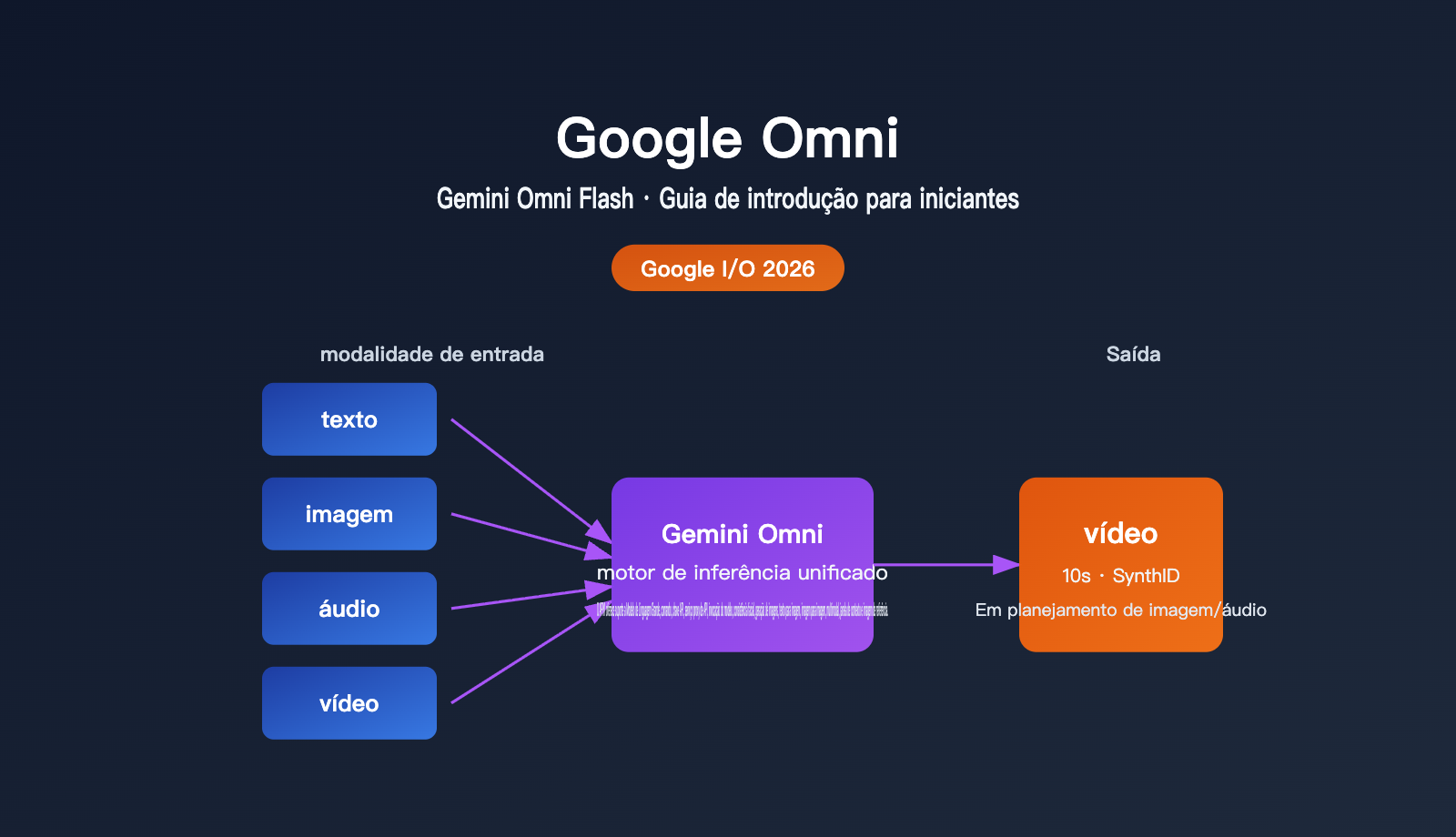
Em uma frase: o Google Omni é uma "família de modelos de geração multimodal" lançada pelo Google, cujo primeiro modelo é o Gemini Omni Flash. Seu maior diferencial não é ser "apenas mais uma IA que gera vídeos", mas sim a capacidade de aceitar qualquer combinação de texto, imagem, áudio e vídeo como entrada, realizar um raciocínio unificado e produzir um vídeo coerente.
O CEO do Google, Sundar Pichai, usou uma frase direta durante a apresentação principal para descrever seu posicionamento: "create anything from any input" (criar qualquer coisa a partir de qualquer entrada). Em outras palavras, antigamente você precisava usar um modelo para gerar uma imagem e outro para transformar essa imagem em vídeo; o Omni tenta realizar o raciocínio e a geração entre diferentes modalidades usando um único modelo.
| Item | Detalhes |
|---|---|
| Data de lançamento | 19 de maio de 2026 (Google I/O 2026) |
| Desenvolvedor | Google (Google DeepMind & Google Labs) |
| Modelo inicial | Gemini Omni Flash |
| Posicionamento | Família de modelos unificados de raciocínio multimodal + geração de mídia |
| Modalidades de entrada | Texto, imagem, vídeo, áudio (qualquer combinação) |
| Modalidades de saída | Vídeo (foco inicial), imagem e áudio serão liberados posteriormente |
| Duração por segmento | Até 10 segundos (limitação de implantação, não do modelo) |
| Identificação de conteúdo | Todos os vídeos incorporam automaticamente a marca d'água invisível SynthID |
| Planejamento futuro | Gemini Omni Pro, maior duração, capacidade de edição de áudio |
💡 Dica para iniciantes: Se você quer experimentar diversos modelos convencionais, incluindo a série Gemini, o quanto antes, pode usar o APIYI (apiyi.com) para realizar invocações rápidas através de uma interface unificada, evitando o incômodo de se registrar em várias plataformas.
Interpretação das principais capacidades do Google Omni: Por que é considerado a "nova geração"
Se olharmos apenas para "o que entra e o que sai", é fácil confundir o Omni com modelos de vídeo como Sora, Veo ou Runway. Mas a diretora de produtos do Google, Nicole Brichtova, deu uma definição mais precisa: "Este é o próximo passo, combinando a inteligência do Gemini com a capacidade de renderização de modelos de mídia." As quatro capacidades abaixo são fundamentais para entender a diferença entre o Omni e os modelos de vídeo tradicionais.
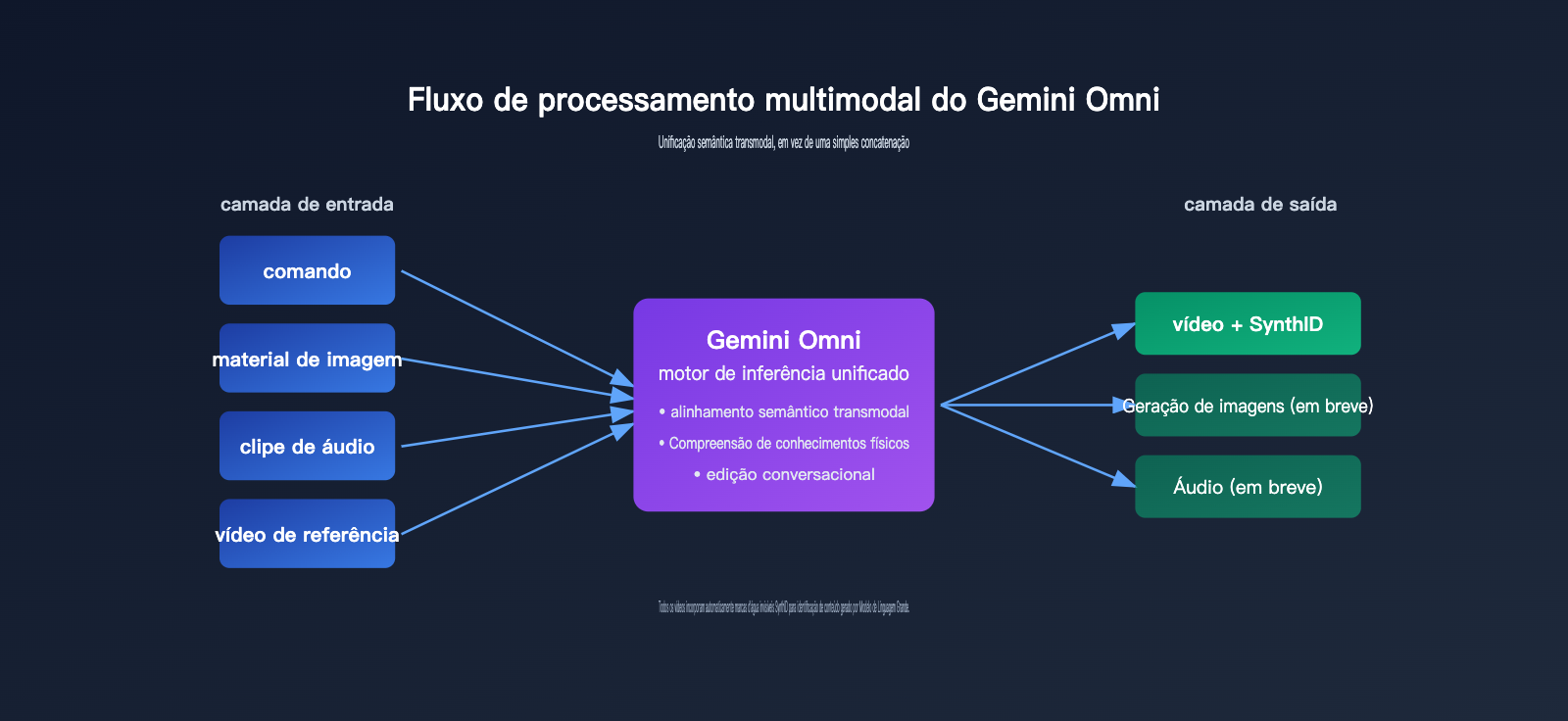
1. Raciocínio multimodal, não apenas concatenação
O fluxo tradicional de geração de vídeo costuma ser um processo de duas etapas: "texto → vídeo" ou "imagem + texto → vídeo". A abordagem do Gemini Omni é colocar todas as entradas no mesmo modelo, permitindo que ele estabeleça uma compreensão semântica unificada internamente e, em seguida, renderize o vídeo de uma só vez.
Por exemplo, se você fornecer ao Omni uma foto de um produto, uma trilha sonora e um roteiro publicitário, ele entenderá que "o produto deve aparecer na mudança de ritmo" e que "o roteiro deve corresponder aos movimentos da tela", em vez de simplesmente sobrepor a música ao vídeo. Essa capacidade de "entender primeiro, gerar depois" vem do DNA de raciocínio do próprio modelo Gemini.
2. Compreensão física e conhecimento de mundo
Em suas demonstrações, o Google destacou dois exemplos: uma cena de uma bola de ágata rolando, onde o rebote, a parada e o som da colisão ao tocar o solo seguem a física real; e uma animação educativa em estilo claymation (massinha) sobre dobramento de proteínas, onde a estrutura geométrica segue princípios básicos da biologia molecular. Embora pareçam simples, esses demos demonstram a compreensão do modelo sobre as "leis do mundo real", indo muito além de uma simples correspondência de pixels.
Para quem está começando, isso significa que os vídeos gerados pelo Omni são menos propensos a falhas típicas de IA, como "objetos que se teletransportam", "iluminação inconsistente" ou "mãos com dedos extras".
3. Edição iterativa conversacional
O Omni suporta o fluxo de "gerar primeiro, editar com linguagem natural depois". Após o modelo gerar um vídeo, você pode dizer "mude o fundo para o pôr do sol" ou "deixe a câmera mais lenta", e o modelo fará ajustes locais mantendo a coerência de personagens, cenários e ações.
Essa forma de interação é mais parecida com conversar com um editor de vídeo do que com escrever um comando longo de uma só vez. É especialmente amigável para iniciantes que não possuem experiência em engenharia de comando.
4. Avatar digital personalizado
O Omni permite que os usuários criem seu próprio avatar digital por meio de autenticação biométrica e o incorporem nos vídeos gerados. O Google enfatiza que esta etapa deve ser realizada pessoalmente para reduzir o risco de uso indevido de deepfakes.
🎯 Resumo das capacidades: O ponto chave do Omni não é a "resolução mais alta" ou a "duração mais longa", mas sim o trio "raciocínio multimodal + senso comum físico + edição por diálogo". Para integrar essas capacidades ao seu produto, sugerimos testar os efeitos de diferentes combinações de modelos através de interfaces agregadas como a APIYI (apiyi.com) antes de decidir pela solução principal.
Qual a diferença entre Gemini Omni e Veo: os dois nomes que mais confundem iniciantes
Muitos iniciantes perguntam: o Google já não tem o Veo? Para que serve o Omni? Essa é uma dúvida muito legítima, pois ambos "podem gerar vídeos", mas seus posicionamentos são completamente diferentes. A tabela abaixo é a maneira mais rápida para um iniciante entender a relação entre os dois.
| Dimensão de comparação | Veo | Gemini Omni |
|---|---|---|
| Tipo de modelo | Modelo de mídia especializado | Modelo unificado de raciocínio multimodal + geração de mídia |
| Suporte de entrada | Texto, imagem | Texto + imagem + áudio + vídeo (qualquer combinação) |
| Profundidade de raciocínio | Focado na renderização | Invoca o raciocínio do Gemini, unificação semântica multimodal |
| Método de edição | Focado em regeneração | Suporta edição incremental conversacional |
| Compreensão física | Comum | Significativamente aprimorada (destaque nos demos oficiais) |
| Público-alvo | Criadores de vídeo profissionais | Criadores + consumidores comuns + desenvolvedores |
| Posicionamento atual | Ferramenta de geração de vídeo de alta qualidade | Modelo base multimodal "crie qualquer coisa" |
Uma analogia simples: o Veo é como uma impressora de alta fidelidade; você dá uma imagem a ele e ele imprime um produto acabado requintado. Já o Omni é como um assistente versátil que entende suas intenções; você fornece alguns materiais e um pedido em uma frase, e ele produz o conteúdo final. É muito provável que ambos coexistam no futuro, mas o Omni representa a rota de "multimodalidade unificada" na qual o Google está apostando.

🧭 Sugestão para iniciantes: Se você quer apenas gerar vídeos curtos e bonitos, o Veo ainda é suficiente; se você deseja criar cenários de aplicação com "entrada mista de texto, imagem, áudio e vídeo", o Omni é a direção mais adequada. Para comparar rapidamente o desempenho real desses dois tipos de modelos, recomendamos usar uma interface como a APIYI (apiyi.com), que suporta a troca entre múltiplos modelos, permitindo que você alterne modelos sem mudar o fluxo de trabalho no mesmo código.
Como usar o Gemini Omni Flash: Guia para iniciantes
Desde o seu lançamento, o Gemini Omni Flash foi disponibilizado para diferentes públicos, mas os canais não são unificados. A tabela de comparação abaixo ajudará os iniciantes a identificar rapidamente "por onde devo começar".
| Tipo de usuário | Canal recomendado | É pago? | Observações |
|---|---|---|---|
| Consumidor comum | App Gemini | Requer assinatura Google AI Plus/Pro/Ultra | Criação pessoal, produção de vídeos curtos |
| Criador de conteúdo | Google Flow | Requer assinatura Google AI | Focado em fluxos de trabalho criativos profissionais |
| Usuário de vídeos curtos | YouTube Shorts, YouTube Create App | Gratuito | Experiência gratuita por tempo limitado, canal de entrada ideal |
| Desenvolvedor / Empresa | Google API (em breve) | Preço ainda não divulgado | Disponível em algumas semanas, fique atento aos anúncios |
| Avaliador de modelos | Plataforma de API agregadora de terceiros | Depende do preço da plataforma | Ideal para equipes de P&D que comparam vários modelos |
O caminho mais simples para iniciantes
- Se você não possui nenhuma ferramenta de IA paga, recomendo começar pelo YouTube Shorts ou pelo aplicativo YouTube Create para experimentar a geração de vídeo gratuita do Omni. Esta é a porta de entrada com menor barreira.
- Se você já é assinante do Google AI Plus ou superior, basta abrir o app Gemini; você verá a opção de geração de vídeo Omni no painel de criação.
- Se você é desenvolvedor, a abordagem mais prática no momento é experimentar os resultados no lado do consumidor enquanto aguarda a abertura da API oficial. Ao mesmo tempo, você pode utilizar o APIYI (apiyi.com) para invocar outros modelos da série Gemini já disponíveis, preparando sua infraestrutura de invocação multimodal.
Um exemplo básico de invocação (para quando a API oficial for lançada)
Embora a API oficial para desenvolvedores do Omni ainda esteja na fase de "lançamento em algumas semanas", podemos projetar a estrutura de invocação com antecedência para que, assim que a interface for aberta, você possa integrá-la imediatamente.
# Exemplo de invocação agregada de múltiplos modelos (estrutura ilustrativa, substitua o modelo após a abertura da API oficial do Omni)
from openai import OpenAI
client = OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1" # Integração unificada de múltiplos modelos via APIYI
)
# Invocação atual de modelos da série Gemini já disponíveis
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[{"role": "user", "content": "Explique em uma frase o valor central dos modelos multimodais"}]
)
print(response.choices[0].message.content)
💡 Dica rápida: Não é preciso esperar que todas as APIs oficiais sejam abertas para começar. Use o APIYI (apiyi.com) para estruturar seu fluxo com outros modelos da série Gemini. Quando a API do Omni for lançada, bastará substituir o nome do modelo, com custo de migração quase zero.
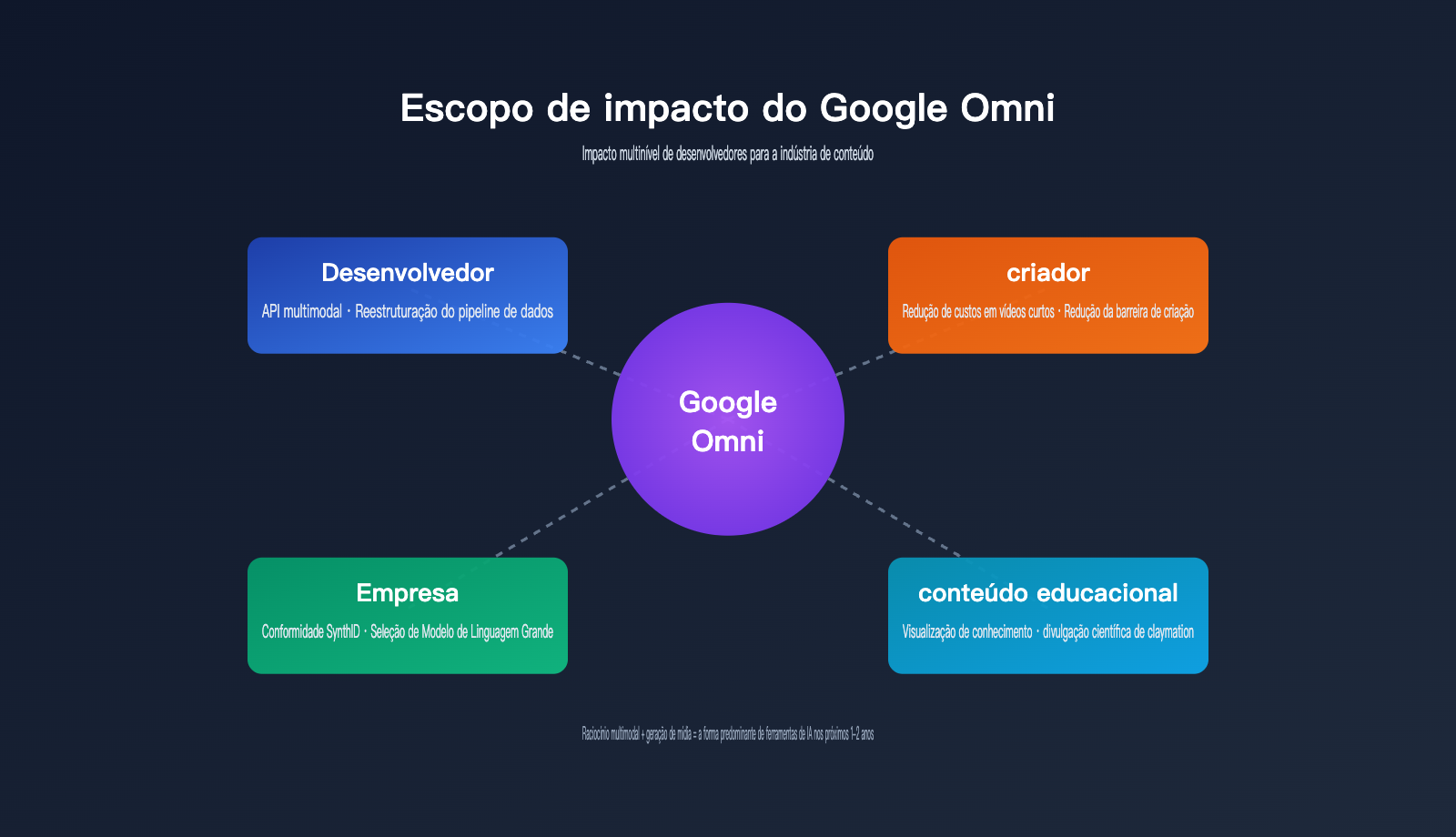
O impacto do Google Omni para desenvolvedores e para a indústria
Muitos iniciantes se perguntam: o que este novo modelo significa para mim? A resposta varia para desenvolvedores, criadores e empresas.
Impacto para desenvolvedores
| Direção do impacto | Manifestação específica |
|---|---|
| Método de invocação | Design de comando multimodal substitui o pipeline "t2i para i2v" |
| Cadeia de ferramentas | SDK precisa se adaptar a "fluxos de entrada de vídeo/áudio" em vez de apenas texto |
| Conformidade de conteúdo | Marca d'água SynthID torna-se requisito padrão; planeje a detecção e exibição |
| Estrutura de custos | O custo por geração pode ser superior à invocação de texto puro; requer gestão precisa |
Para engenheiros que estão construindo aplicações de IA, o Omni envia um sinal claro: as futuras interfaces de IA não serão apenas "entrada de texto, saída de texto", mas sim "entrada multimodal, saída multimodal". Reestruturar seus pipelines de dados e gerenciar materiais por modalidade agora lhe dará uma vantagem competitiva quando a API do Omni for oficialmente aberta.
Impacto para a indústria de conteúdo
Plataformas de vídeos curtos, agências de publicidade e produtores de conteúdo educacional serão os primeiros a se beneficiar. Um vídeo de alta qualidade de 10 segundos que antes levava horas para ser editado pode ter um rascunho utilizável gerado pelo Omni Flash em poucos minutos. Para criadores de nicho, a barreira de "de uma imagem para um vídeo completo" foi significativamente reduzida.
No entanto, é importante notar que a incorporação obrigatória da marca d'água SynthID significa que o "gerado por IA" se tornará cada vez mais transparente. Plataformas, marcas e órgãos reguladores podem ajustar suas estratégias de rotulagem e auditoria de conteúdo com base nessa marca d'água.
Impacto para usuários corporativos
Os usuários corporativos preocupam-se principalmente com duas coisas: conformidade/segurança da marca e custo de escala. A marca d'água SynthID resolve metade do primeiro problema, enquanto o segundo depende do preço da API que o Google divulgará posteriormente. Para equipes sensíveis ao orçamento, usar plataformas agregadoras como o APIYI (apiyi.com) para avaliar simultaneamente as capacidades de vídeo ou multimodais de vários fabricantes (Gemini, GPT, Claude) e, em seguida, selecionar com base em custo e qualidade, é a estratégia mais segura.
Perguntas Frequentes
Q1: Google Omni e Gemini Omni são a mesma coisa?
Sim. Google Omni é uma abreviação não oficial; o nome completo utilizado pelo Google é "Gemini Omni", que pertence ao ramo multimodal da família de modelos Gemini. O Gemini Omni Flash foi o primeiro modelo lançado desta família. Ambos os nomes referem-se ao mesmo tipo de tecnologia.
Q2: Iniciantes podem experimentar o Gemini Omni gratuitamente agora?
Sim. A maneira mais direta é usar a função de geração de vídeo Omni no YouTube Shorts ou no aplicativo YouTube Create, que atualmente está aberta gratuitamente para criadores. Se você quiser usar no aplicativo Gemini, precisará de uma assinatura Google AI Plus, Pro ou Ultra.
Q3: Por que os vídeos do Gemini Omni são limitados a 10 segundos?
Esta é uma limitação da fase de implementação, e não um limite da capacidade do modelo em si. A explicação oficial é que, "durante a fase de alta demanda computacional, priorizamos disponibilizar a capacidade para mais usuários". Modelos futuros, como o Omni Pro, estenderão gradualmente a duração dos vídeos.
Q4: A marca d’água SynthID afeta a qualidade do vídeo ou o uso comercial?
Não. O SynthID é uma marca d'água invisível, imperceptível ao olho humano e que não afeta a qualidade da imagem. Sua função é permitir que plataformas e ferramentas identifiquem que "este vídeo foi gerado por IA" durante a circulação do conteúdo. O uso comercial deve seguir os termos de serviço do Google.
Q5: O que os desenvolvedores devem preparar agora?
Primeiro, familiarize-se com a lógica de design de comandos multimodais, em vez de escrever apenas comandos de texto. Segundo, organize sua biblioteca de ativos, classificando-os por modalidade. Terceiro, prepare o fluxo de invocação do modelo com antecedência; recomendamos usar o APIYI (apiyi.com) para invocar a série Gemini existente através de uma interface unificada, permitindo uma transição perfeita assim que a API Omni for lançada oficialmente.
Q6: O Gemini Omni substituirá o Veo?
Não a curto prazo. O Veo continua sendo a referência para geração de vídeo especializada de alta qualidade, enquanto o Omni representa a direção unificada de "raciocínio multimodal + geração de mídia". É mais provável que ambos coexistam em diferentes cenários.
Resumo: Três coisas que os iniciantes devem lembrar
Primeiro, a essência do Gemini Omni é um modelo unificado de "raciocínio transmodal + geração de mídia", e não apenas "mais uma IA de vídeo". Sua capacidade diferenciada manifesta-se em três dimensões: compreensão física, edição conversacional e raciocínio transmodal.
Segundo, o caminho mais rápido para iniciantes experimentarem é através dos acessos gratuitos no YouTube Shorts ou no aplicativo YouTube Create, seguidos pelos canais de assinatura do aplicativo Gemini; a API para desenvolvedores está na fase de "lançamento nas próximas semanas", então você já pode planejar sua arquitetura.
Terceiro, o Omni não substituirá imediatamente as ferramentas que você já conhece, mas representa a forma predominante da IA multimodal nos próximos 1 a 2 anos. Compreender antecipadamente seus métodos de entrada e saída, os requisitos de conformidade do SynthID e a diferença de posicionamento em relação ao Veo evitará contratempos na nova onda de atualização de ferramentas de IA. Se você deseja invocar modelos convencionais como Gemini, GPT e Claude em uma única interface, o APIYI (apiyi.com) é a solução mais prática atualmente, permitindo que você acesse a API do Gemini Omni assim que ela for oficialmente aberta.
Referências
-
Blog oficial do Google – Anúncio de lançamento do Gemini Omni
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni - Descrição: Apresentação oficial do Google sobre o posicionamento e as capacidades do Gemini Omni.
- Link:
-
TechCrunch – Relatório detalhado sobre o Gemini Omni
- Link:
techcrunch.com/2026/05/19/googles-gemini-omni-turns-images-audio-and-text-into-video-and-thats-just-the-start - Descrição: Cita declarações fundamentais de Sundar Pichai e Nicole Brichtova.
- Link:
-
9to5Google – Relato de experiência com o Gemini Omni Flash
- Link:
9to5google.com/2026/05/19/gemini-omni-create-anything-model-video - Descrição: Inclui descrições das demonstrações oficiais e informações sobre a disponibilidade do canal.
- Link:
Equipe APIYI | Para acompanhar mais novidades sobre Modelos de Linguagem Grande e guias práticos, visite a APIYI em apiyi.com para obter créditos de teste gratuitos e experimentar uma interface unificada para diversos modelos populares, incluindo a série Gemini.