
Quando o Google DeepMind lançou o Nano Banana Pro em 20 de novembro de 2025, eles enfatizaram repetidamente: "áreas intocadas permanecem perfeitas em nível de pixel — sem desvio de geração, sem perda de qualidade em edições iterativas". Se você interpretar literalmente, isso significa que a IA alcançou uma "edição local real estilo Photoshop". Mas, se você conhece a arquitetura do Gemini 3 Pro Image, descobrirá que ela é, essencialmente, um redesenho de imagem completa via Transformer autorregressivo — o mesmo mecanismo usado por modelos de texto para prever o próximo token.
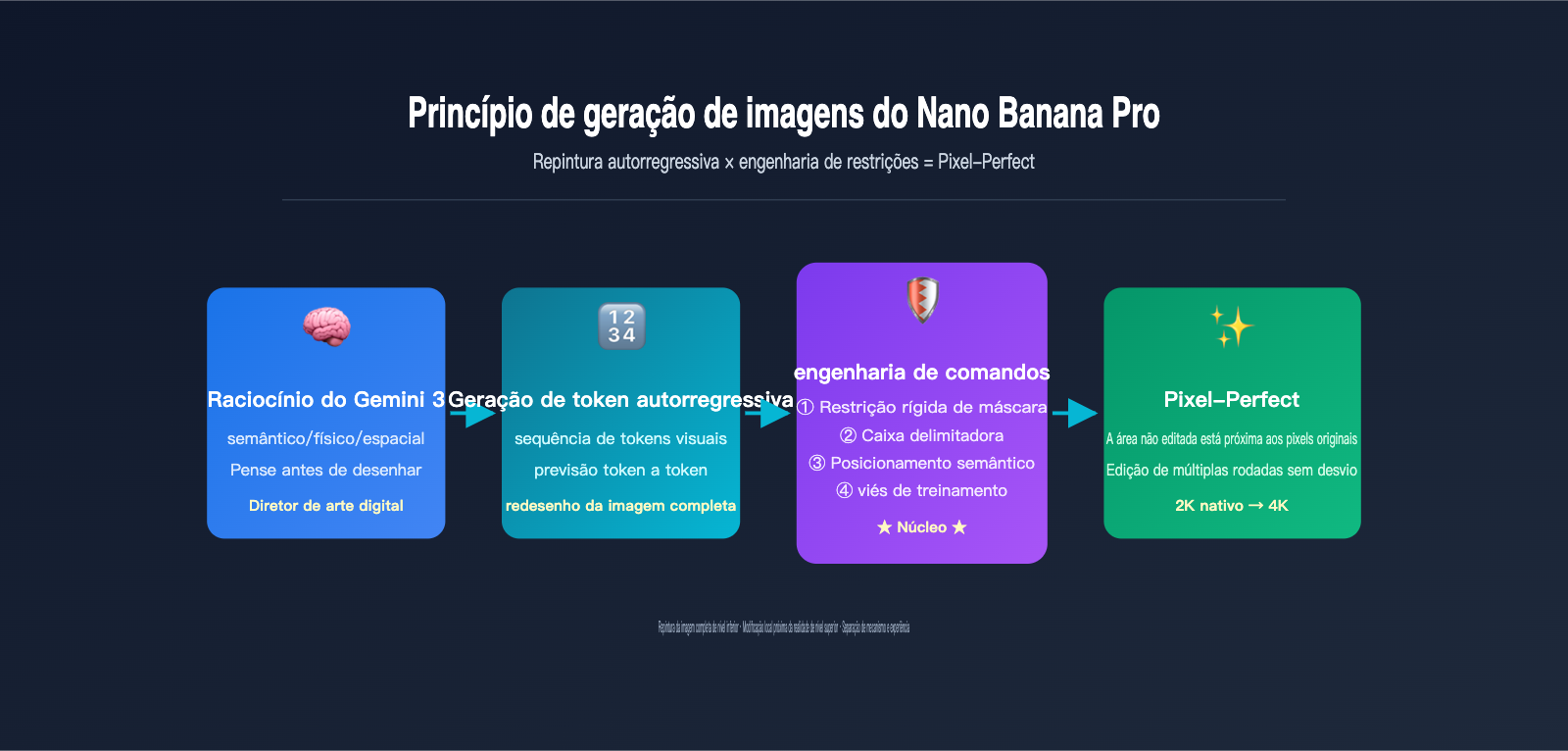
Como essas duas coisas podem ser verdadeiras ao mesmo tempo? Qual é, afinal, o princípio de geração de imagens do Nano Banana Pro: ele redesenha a imagem inteira ou faz uma modificação local real? Este artigo decompõe o processo em quatro níveis: espinha dorsal de inferência do Gemini 3, tokens visuais autorregressivos, restrições rígidas de máscara e posicionamento semântico por Bounding Box, fornecendo uma base técnica que engenheiros realmente podem aproveitar.
| Pergunta Principal | Resposta Intuitiva | Realidade |
|---|---|---|
| É uma edição local estilo PS? | Sim | Não, a base ainda é o redesenho de tokens da imagem toda |
| Então por que é pixel-perfect? | O modelo é muito inteligente | Três camadas de restrições rígidas: Máscara + Posicionamento Semântico + BBox |
| É da mesma origem que o GPT-Image-2? | Similar | Ambos são autorregressivos, mas o Gemini 3 tem inferência explícita adicional |
| Múltiplas edições causam desvio? | Sim | Quase nunca, este é o principal diferencial do Pro |
Ao compreender essa lógica subjacente, você conseguirá escrever comandos que realmente ativem a inferência do Gemini 3, escolher modos de máscara de forma racional e evitar a armadilha do "parece local, mas na verdade é um redesenho". Recomendamos que os leitores testem a interface do Nano Banana Pro na plataforma APIYI (apiyi.com) enquanto leem, mapeando cada princípio para o resultado real.
Princípio de geração de imagens do Nano Banana Pro: redesenho total ou modificação local real?
Antes de responder a essa pergunta, precisamos distinguir duas coisas que costumam ser confundidas: mecanismo de geração e experiência de uso.
Do ponto de vista do mecanismo de geração, o Nano Banana Pro e seus antecessores, assim como o GPT-Image-2 da OpenAI, seguem a mesma rota — redesenho de tokens da imagem inteira via Transformer autorregressivo. Em outras palavras, mesmo que você peça à IA para mudar apenas a cor da gravata de uma pessoa, internamente o modelo ainda precisa comprimir a imagem inteira em tokens visuais, prever a sequência de tokens de saída do início ao fim e, finalmente, decodificá-la de volta em pixels. Não existe um caminho físico de "mover apenas uma pequena parte dos pixels e deixar o resto intacto".
Mas, do ponto de vista da experiência de uso, o Nano Banana Pro oferece ao usuário uma sensação de "modificação quase local real". O Google afirma explicitamente: no modo de máscara ou posicionamento semântico, as áreas não editadas são preservadas quase em nível de pixel, sem desvio de geração e sem perda de qualidade em edições múltiplas. Como essa experiência é extraída da arquitetura de "redesenho total"?
A resposta é: engenharia de restrições (constraint engineering). O Google sobrepôs três camadas de restrições rígidas ao fluxo de geração autorregressiva: bloqueio de tokens de máscara, especificação de área por Bounding Box e uma "lista de preservação" semântica do Gemini 3. Essas três restrições fazem com que o modelo "escolha ativamente" reproduzir os tokens das áreas não editadas durante o redesenho. Este é o verdadeiro trabalho da equipe de engenharia do Nano Banana Pro.
Relação entre a lógica de redesenho e a experiência de modificação local
| Perspectiva | Situação Real | Percepção do Usuário |
|---|---|---|
| Arquitetura base | Redesenho de tokens da imagem toda | Parece uma modificação local |
| Áreas não editadas | Tokens gerados novamente | Quase idêntico aos pixels originais |
| Fronteiras de edição | Geração contínua autorregressiva | Transição natural sem artefatos |
| Comando de edição | Passado via restrições | Combinação automática de luz/perspectiva |
Ao entender essa separação entre "mecanismo e experiência", você entenderá por que, às vezes, as áreas não editadas de uma imagem editada pelo Nano Banana Pro apresentam mudanças levíssimas — esse é o preço inevitável do redesenho de tokens, mas o Google, através de restrições, reduziu essa mudança a um nível quase imperceptível a olho nu. Recomendamos usar a API do Nano Banana Pro na APIYI (apiyi.com) para editar a mesma imagem repetidamente e observar a magnitude do desvio nos detalhes; esse tipo de comparação ajudará a consolidar a compreensão do princípio.
Princípio de funcionamento do Nano Banana Pro: O backbone autorregressivo do Gemini 3 Pro Image
Para entender a fundo o princípio de funcionamento do Nano Banana Pro, é impossível ignorar seu nome oficial: Gemini 3 Pro Image. Esse nome revela suas duas linhagens principais: o backbone de raciocínio do Gemini 3 e o decodificador de geração de imagens.
O Gemini 3 é o Modelo de Linguagem Grande multimodal emblemático que o Google lançou apenas dois dias antes do Nano Banana Pro, famoso por sua "capacidade de raciocínio". O Nano Banana Pro reutiliza diretamente o backbone Transformer do Gemini 3 Pro, apenas adicionando tokens visuais ao vocabulário e conectando um decodificador de imagem na saída. Em outras palavras, ele não é um modelo de imagem independente, mas sim uma forma especializada do ecossistema multimodal Gemini 3 focada na geração de imagens.
Isso traz uma mudança fundamental: antes de desenhar o primeiro pixel, o Nano Banana Pro usa o raciocínio do Gemini 3 para determinar "o que deve ser desenhado". Nas palavras do próprio Google, ele "funciona menos como um modelo de difusão tradicional e mais como um diretor de arte digital" — ele analisa primeiro a lógica semântica, a causalidade física e as relações espaciais do comando, para só então entrar na fase de geração de tokens visuais.
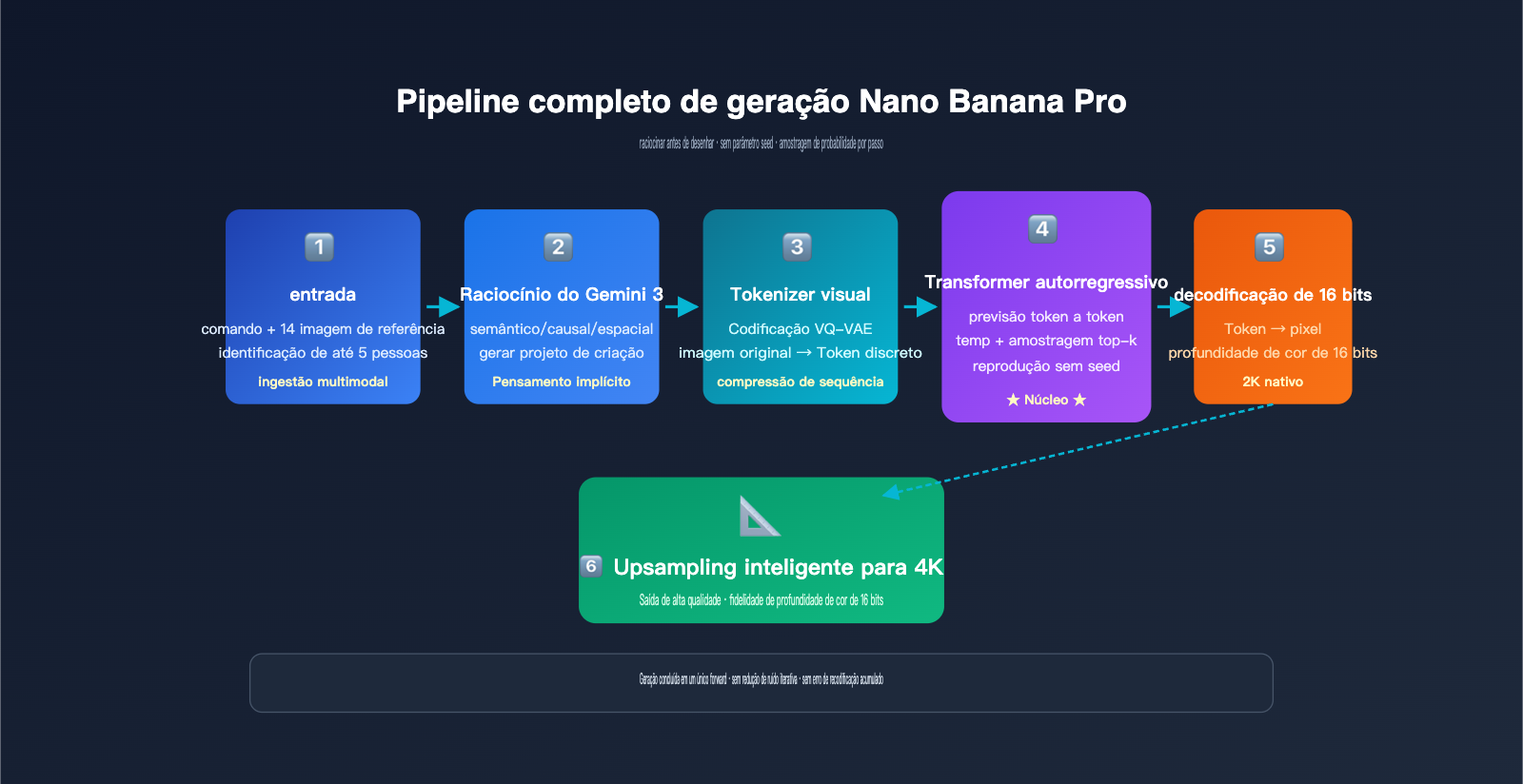
O fluxo de trabalho específico pode ser dividido em cinco etapas:
- Análise de entrada multimodal: O backbone de raciocínio do Gemini 3 processa simultaneamente o comando de texto do usuário e até 14 imagens de referência, compreendendo todo o contexto da tarefa.
- Raciocínio estruturado (blueprint interno): O modelo primeiro "pensa" internamente no layout espacial da cena, na identidade dos personagens, nas configurações de iluminação e no que precisa ser mantido ou modificado, gerando um "blueprint de criação" invisível.
- Codificação de tokens visuais da imagem original: As imagens de referência são comprimidas em uma sequência de tokens visuais através de um mecanismo de discretização semelhante ao VQ-VAE.
- Previsão de token autorregressiva: Sob o mecanismo de atenção do backbone Gemini 3, o modelo prevê um a um, da esquerda para a direita, cada token visual da imagem de saída, conseguindo "ver" o comando completo e os tokens da imagem original a cada passo.
- Decodificação e upsampling: Os tokens de saída são restaurados em uma imagem 2K nativa através de um decodificador de 16 bits de profundidade de cor, sendo então inteligentemente redimensionados para 4K.
Duas capacidades únicas do backbone de raciocínio do Gemini 3
A primeira é "pensar antes de desenhar". Isso não é apenas marketing — a capacidade de raciocínio do Gemini 3 em tarefas de texto é transferida diretamente para a geração de imagens. Se você der um comando complexo como "mude a roupa desta pessoa para algo que combine com sua profissão", modelos de imagem comuns podem se confundir, mas o Nano Banana Pro raciocinará primeiro: "esta pessoa parece um médico → deve ser um jaleco branco", e só então desenhará.
A segunda é o Grounding com a Pesquisa do Google. O Nano Banana Pro pode utilizar a ferramenta de busca do Google durante o processo de geração para verificar fatos — por exemplo, ao pedir para desenhar "o produto mais recente de uma marca", ele pode se conectar à internet para obter referências visuais reais. Este é o único modelo de geração de imagens que suporta grounding de busca nativo atualmente, sendo um dos maiores diferenciais entre o Nano Banana Pro e o GPT-Image-2. Se você precisar testar a capacidade de Grounding em um ambiente de produção, pode acessar o Nano Banana Pro através da APIYI (apiyi.com), que oferece especificações de interface consistentes com as oficiais do Google.
Vale ressaltar que o Nano Banana Pro não suporta o parâmetro seed. Como se trata de uma geração autorregressiva, cada etapa de amostragem é retirada de uma distribuição de probabilidade (controlada por temperature e top-k), diferentemente dos modelos de difusão que podem reproduzir resultados exatamente através de um ruído inicial fixo. Essa característica é tanto uma restrição quanto uma escolha de design, permitindo que o modelo mantenha sua criatividade.
As 4 Mecanismos de Restrição na Edição Local de Imagens por IA: Como se alcança o Pixel-Perfect
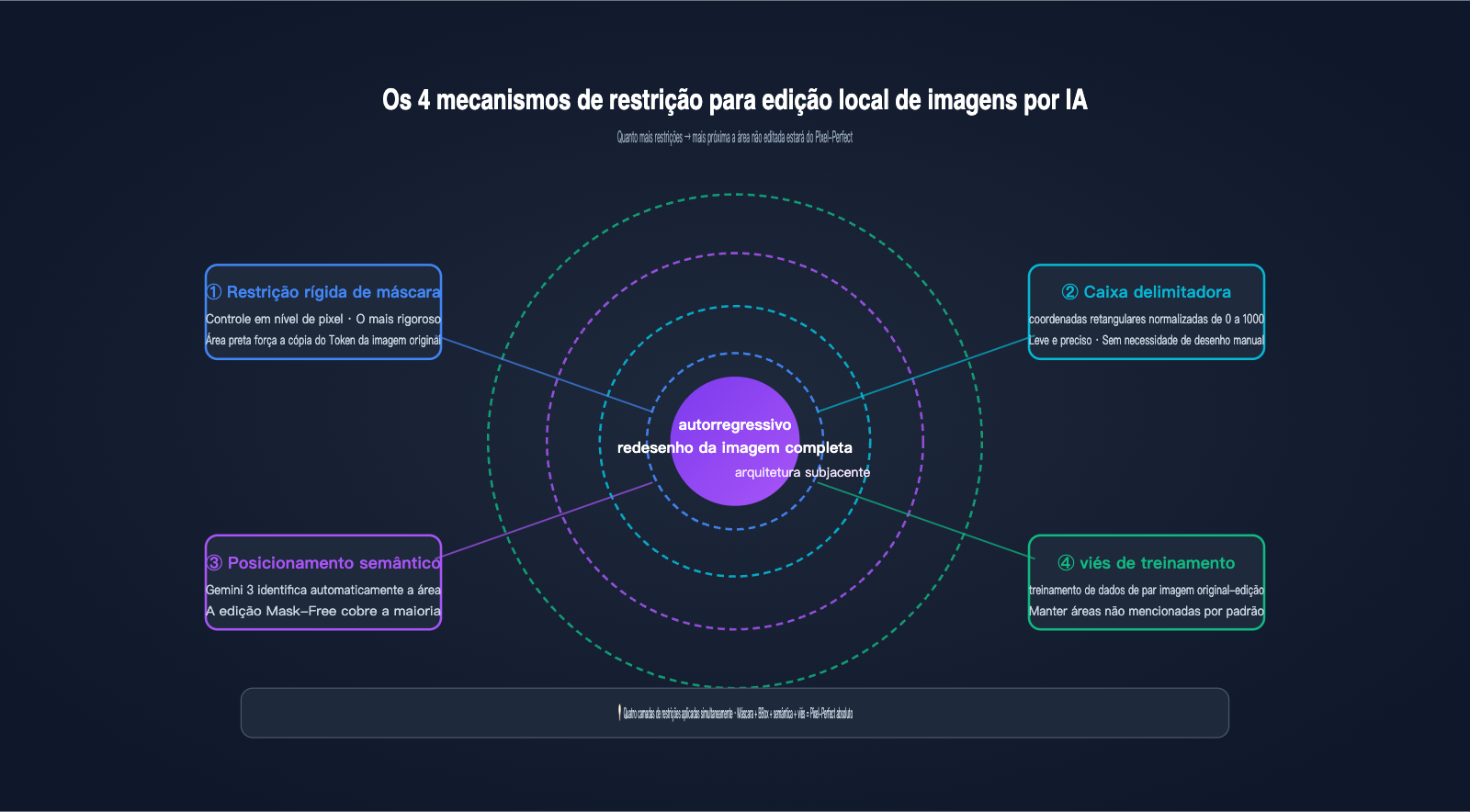
Já que a base é a reinterpretação da imagem completa, como o Nano Banana Pro garante que as áreas não editadas permaneçam próximas ao pixel-perfect? A resposta é que o Google sobrepôs quatro camadas de mecanismos de restrição no cenário de edição local de imagens por IA. Esta é a inovação de engenharia mais digna de análise na versão Pro em comparação com a versão básica do Nano Banana.
Primeira camada: Restrição rígida de máscara (Mask). Esta é a forma mais direta: o usuário fornece uma máscara em preto e branco com as mesmas dimensões; as áreas brancas permitem que a IA gere novos tokens, enquanto as áreas pretas forçam a saída de tokens que devem copiar exatamente os tokens correspondentes da imagem original. Isso equivale a adicionar uma "regra de cópia rígida" ao modelo durante a geração autorregressiva. Esta é a fonte técnica central do que o Google chama de "áreas intocadas pixel-perfect".
Segunda camada: Posicionamento de área por Bounding Box. O Nano Banana Pro suporta parâmetros de bounding box com coordenadas normalizadas de 0 a 1000. Você pode dizer ao modelo: "modifique apenas dentro deste retângulo de (200, 300) a (600, 500)". O sistema converte automaticamente o BBox em uma restrição de máscara interna, sendo mais prático do que desenhar uma máscara manualmente.
Terceira camada: Posicionamento semântico com Gemini 3. Esta é a camada mais "mágica". Você só precisa dizer em linguagem natural: "mude o fundo para uma praia", e o motor de raciocínio do Gemini 3 identifica automaticamente quais tokens na imagem representam o "fundo", gerando uma máscara implícita. Esse modo de edição mask-free cobre a "maioria dos cenários de edição" mencionados oficialmente pelo Google.
Quarta camada: Viés de "manter se não mencionado" nos dados de treinamento. O Google utilizou uma enorme quantidade de dados pareados de "imagem original-imagem editada", permitindo que o modelo aprendesse uma regra implícita durante o treinamento: a menos que o comando peça explicitamente para alterar, as outras áreas devem, tanto quanto possível, copiar os tokens da imagem original. Esse viés é consolidado nos pesos e entra em vigor automaticamente durante a inferência.
Comparação dos 4 mecanismos de restrição
| Mecanismo de Restrição | Granularidade de Controle | Custo para o Usuário | Cenário de Aplicação |
|---|---|---|---|
| Restrição rígida de máscara | Nível de pixel | Requer desenhar máscara | Reparo preciso/substituição |
| Bounding Box | Área retangular | Apenas coordenadas | Edição de área retangular conhecida |
| Posicionamento semântico | Objeto semântico | Apenas comando de texto | Maioria das edições diárias |
| Viés de treinamento | Global | Sem configuração | Padrão em todos os cenários |
As quatro camadas de restrição não são excludentes, mas sim cumulativas. A combinação mais rigorosa é "Máscara + Bounding Box + Comando semântico", o que leva a experiência pixel-perfect do Nano Banana Pro ao extremo. Em nossos testes na APIYI (apiyi.com), descobrimos que, mesmo usando apenas posicionamento semântico + viés de treinamento, é possível alcançar uma consistência quase indistinguível a olho nu na maioria das edições diárias.
Razões técnicas para a ausência de deriva em edições múltiplas
Um dos destaques de marketing do Nano Banana Pro é a "ausência de perda de qualidade acumulada em edições de múltiplas rodadas". Existem dois motivos: primeiro, a própria arquitetura autorregressiva não requer codificação/decodificação repetida por VAE como os modelos de difusão; há apenas uma conversão token-pixel, o que não acumula erros de re-codificação. Segundo, a restrição rígida da máscara faz com que as áreas não editadas copiem os tokens originais, o que quase não introduz nova aleatoriedade, mesmo após várias iterações.
Isso contrasta fortemente com o inpainting repetido do Stable Diffusion tradicional, que se torna "borrado" após algumas passagens. Se o seu fluxo de trabalho exige de 5 a 10 rodadas de edição na mesma imagem base, o Nano Banana Pro é quase o único modelo capaz de sustentar isso atualmente.
Gemini 3 Pro Image vs GPT-Image-2: Diferenciação entre duas rotas
Muitas equipes acompanham simultaneamente o Gemini 3 Pro Image (Nano Banana Pro) e o GPT-Image-2 da OpenAI. Ambos são baseados em autorregressão, mas possuem focos diferentes em posicionamento e capacidade.
O GPT-Image-2 enfatiza o "modo Thinking" e a precisão na renderização de texto (cerca de 99% oficialmente), sendo excelente em layouts com múltiplos objetos e cenas com muito texto. O Nano Banana Pro aposta no motor de raciocínio do Gemini 3, saída 4K, fusão de até 14 imagens, manutenção de identidade de 5 pessoas e o exclusivo Grounding com a Pesquisa Google.

As principais diferenças entre o princípio de geração de imagens do Nano Banana Pro e o caminho de implementação do GPT-Image-2 podem ser vistas nesta tabela:
| Dimensão | Nano Banana Pro | GPT-Image-2 |
|---|---|---|
| Modelo base | Gemini 3 Pro | GPT-4o Multimodal |
| Reforço de inferência | Raciocínio implícito Gemini 3 | Modo Thinking explícito |
| Resolução máxima | 4K (upsampling de 2K) | 4K nativo |
| Limite de entrada de imagens | 14 imagens | Múltiplas (limite não público) |
| Consistência facial | Até 5 pessoas simultâneas | Forte, limite não público |
| Renderização de texto | Líder da indústria, multilíngue | 99% de precisão |
| Informação em tempo real | ✅ Grounding com Pesquisa Google | ❌ |
| Parâmetro Seed | ❌ Não suportado | Parcialmente controlado |
| Destaque em edição local | Áreas não editadas Pixel-perfect | Sem deriva em múltiplas rodadas |
| Preço por imagem | 2K $0.139 / 4K $0.24 | Alta qualidade 1024 $0.211 |
Sugestão de seleção: depende principalmente de dois pontos: se você precisa criar materiais de marca, fotos de produtos ou síntese de cenas com múltiplos personagens, a fusão de imagens e a consistência facial do Nano Banana Pro são mais adequadas; se o seu cenário principal envolve pôsteres com textos longos, layouts complexos ou mais de 100 objetos, o modo Thinking do GPT-Image-2 pode ser mais estável. Recomendamos acessar ambos os modelos através da plataforma APIYI (apiyi.com) e realizar pequenos testes A/B baseados no seu cenário real antes de decidir qual será o seu modelo principal.
Prática com a API do Nano Banana Pro: Do mask ao bounding box em todos os cenários
Depois de entender os princípios, vamos ver como aplicar a capacidade de edição local de imagens por IA do Nano Banana Pro na prática. Abaixo está um exemplo mínimo e funcional em Python, utilizando o serviço proxy de API da APIYI para invocar o Gemini 3 Pro Image:
from google import genai
from PIL import Image
client = genai.Client(
api_key="your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1"}
)
original = Image.open("portrait.png")
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Mantenha a identidade da pessoa e o fundo inalterados, apenas troque a camiseta branca por um paletó azul-marinho, mantendo a direção original da luz e das sombras",
original
]
)
for part in response.candidates[0].content.parts:
if part.inline_data:
with open("edited.png", "wb") as f:
f.write(part.inline_data.data)
Observe a escrita do comando: declare explicitamente "o que manter inalterado", "o que modificar" e "preserve a iluminação original". Isso ativa diretamente a capacidade de localização semântica do núcleo de inferência do Gemini 3. Se precisar de um controle de área mais preciso, você pode adicionar um comando de bounding box:
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
"Dentro da área do bounding box [200, 150, 600, 700] da imagem, substitua a roupa por um paletó azul-marinho. As demais áreas devem manter os pixels originais inalterados.",
original
]
)
As coordenadas utilizam um intervalo normalizado de 0 a 1000, mapeadas de acordo com as dimensões da imagem durante o processamento. Se precisar de um controle mais rigoroso, você pode adicionar uma imagem de máscara como entrada.
5 Dicas de Otimização Prática
Com base no princípio de implementação do Nano Banana Pro, resumimos 5 sugestões para o uso em engenharia:
- O comando deve sempre listar o que deve ser preservado: "Manter identidade, fundo e iluminação inalterados" é a chave para ativar as quatro camadas de restrição.
- Priorize a localização semântica: A menos que as bordas da edição exijam precisão em nível de pixel, o modo sem máscara (mask-free) é mais eficiente.
- Fusão de múltiplas imagens limitada a 14: Exceder o limite oficial causará truncamento, afetando a consistência entre as imagens.
- Escolha entre 2K e 4K conforme o uso: 2K ($0,139) é suficiente para exibição em web/mobile; use 4K ($0,24) apenas para impressão ou telas grandes.
- Não tente reproduzir resultados via seed: O Nano Banana Pro não suporta seed. Para uma reprodução estável, utilize ponderação de comando e imagens de referência fixas.
Preços e Correspondência de Cenários
| Configuração | Custo por Imagem | Cenário Recomendado |
|---|---|---|
| 2K (imagem única) | $0,139 | Redes sociais/imagens para web |
| 4K (imagem única) | $0,24 | Impressos/telas grandes/visual de marketing |
| 4K + fusão de 14 imagens | $0,24 + tokens de entrada | Composição de cenas com múltiplos personagens |
| 4K + Grounding | $0,24 + tokens de busca | Imagens de produtos reais/eventos |
Recomendamos usar a Batch API da APIYI (apiyi.com) em ambientes de produção para tarefas em lote, o que reduz significativamente os custos mantendo a qualidade, ideal para produção em massa de bibliotecas de ativos.
FAQ sobre o Princípio de Geração de Imagens do Nano Banana Pro e Recomendações de Decisão
Q1: O Nano Banana Pro faz desenho ou modificação local?
R: A base é a 【redesenho de tokens da imagem inteira via autorregressão】, ou seja, "desenho". No entanto, através de quatro camadas de restrição — máscara rígida, Bounding Box, localização semântica do Gemini 3 e viés de treinamento — ele alcança uma experiência de uso próxima a uma "edição local real". As duas coisas não são contraditórias: a arquitetura redesenha, a engenharia bloqueia.
Q2: Por que o oficial diz que as áreas não editadas são pixel-perfect?
R: No modo máscara, os tokens de saída nas áreas pretas são forçados a serem iguais aos tokens correspondentes da imagem original, resultando em pixels quase idênticos após a decodificação. Tecnicamente, há uma pequena perda na codificação/decodificação VQ-VAE, por isso é "quase" perfeito, não matematicamente idêntico. No uso diário, é imperceptível a olho nu.
Q3: Por que o Nano Banana Pro não suporta seed?
R: A geração autorregressiva amostra a partir de uma distribuição de probabilidade a cada passo, o que é completamente diferente do mecanismo de ruído inicial fixo dos modelos de difusão. O Google optou por não expor o parâmetro seed para manter a criatividade e diversidade do modelo. Se precisar de resultados estáveis, use uma combinação de comando detalhado + imagem de referência. Sugerimos testar a estabilidade de saída de diferentes modelos de comando na APIYI (apiyi.com) para encontrar uma combinação "quase determinística" para seu fluxo de trabalho.
Q4: Como escolher entre o Nano Banana Pro e o GPT-Image-2?
R: Cenas com múltiplos personagens, ativos de marca, necessidade de informações em tempo real (Grounding) → escolha Nano Banana Pro; layouts complexos, pôsteres com textos longos, layout com mais de 100 objetos → escolha GPT-Image-2. Ambos são autorregressivos na base; a diferença de experiência vem das escolhas de engenharia de restrição do Google e da OpenAI.
Q5: Posso localizar a área de edição com precisão sem uma máscara?
R: Sim, de duas formas. Primeiro, usando o parâmetro Bounding Box (coordenadas normalizadas de 0-1000); segundo, contando com a localização semântica do núcleo de inferência do Gemini 3, bastando dizer no comando "modifique o objeto vermelho no canto inferior direito da imagem". O último cobre a maioria dos cenários, enquanto o primeiro é usado para áreas retangulares claras.
Q6: Como usar o Grounding com a Pesquisa do Google na prática?
R: Especifique claramente no comando os elementos que precisam de verificação factual, como "desenhe uma imagem da mais recente Tesla Cybertruck de 2025 na superfície da lua". O modelo chamará automaticamente a busca do Google para obter referências visuais reais antes de iniciar a geração. Esta é uma capacidade exclusiva do Nano Banana Pro; o GPT-Image-2 não possui funcionalidade equivalente.
Conclusão: Entenda a engenharia de restrição para usar bem o Nano Banana Pro
O Nano Banana Pro é um produto extremamente refinado em termos de engenharia. Ele não inventou um novo paradigma de geração de imagens, mas, sobre a base autorregressiva do Gemini 3, empacotou a arquitetura de "redesenho da imagem inteira" em uma experiência de "edição local quase real" através de quatro camadas de restrição.
Entender essa "separação entre mecanismo e experiência" é essencial para escrever comandos que ativem essas quatro camadas, escolher o modo de edição correto e planejar fluxos de trabalho iterativos. O núcleo do princípio de geração de imagens do Nano Banana Pro não é uma tecnologia secreta, mas a colaboração full-stack da engenharia de restrição.
Recomendamos realizar testes e comparações reais através da plataforma APIYI (apiyi.com), que suporta a invocação via interface unificada de vários modelos principais, como Nano Banana Pro, GPT-Image-2 e Stable Diffusion, facilitando a validação rápida de todos os princípios e técnicas de otimização mencionados neste artigo para encontrar a melhor escolha para seus cenários de produção.
Este artigo foi escrito pela equipe da APIYI, baseado em materiais oficiais do Google DeepMind, Vertex AI e testes práticos. Para invocar o Gemini 3 Pro Image (Nano Banana Pro) em ambiente de produção, acesse o site oficial da APIYI: apiyi.com para obter a documentação de integração.