
저자 주: Gemini 3.1 Pro, Claude Sonnet 4.6, GPT-5.4 세 가지 대규모 언어 모델을 활용한 물리 문제 품질 검사 파이프라인 구축 방법 상세 설명, 완전한 프롬프트 템플릿과 코드 예제 포함
대규모 언어 모델을 사용한 물리 문제 품질 검사는 교육 기관과 온라인 학습 플랫폼이 점점 더 관심을 갖는 분야입니다. 전통적인 수동 채점은 효율성이 낮을 뿐만 아니라 채점 교사의 주관적 판단 차이에 제한을 받습니다. 본 글은 Gemini 3.1 Pro Preview, Claude Sonnet 4.6, GPT-5.4 이 세 가지 2026년 최강 추론 모델을 활용하여 높은 정확도의 물리 문제 자동 품질 검사 시스템을 구축하는 방법을 소개합니다.
핵심 가치: 이 글을 읽고 나면, 여러분은 대규모 언어 모델 물리 문제 품질 검사의 완전한 워크플로우—프롬프트 설계부터 다중 모델 교차 검증까지, 정확도 90% 이상의 자동화된 품질 검사 방안을 구축하는 방법을 익히게 될 것입니다.
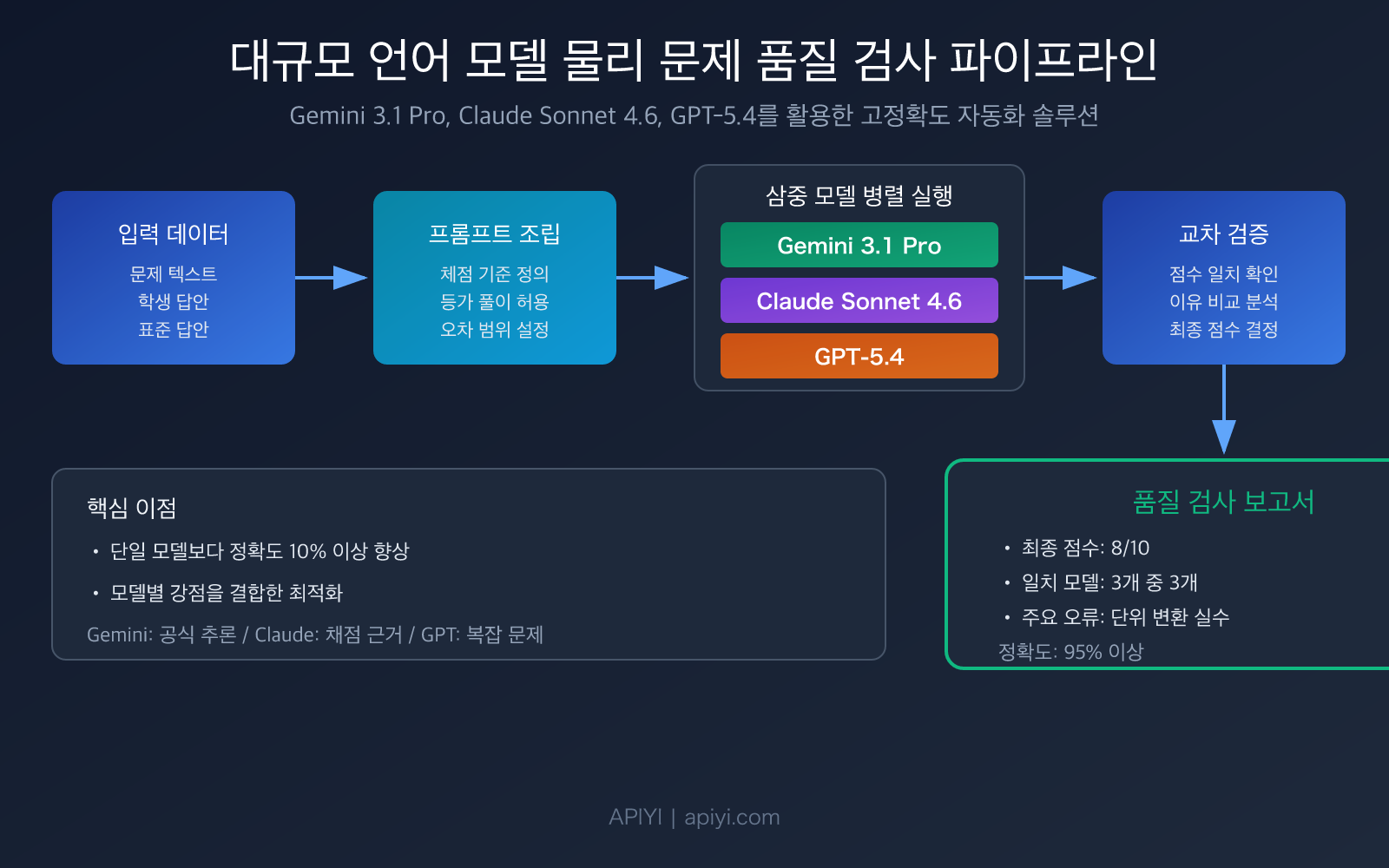
대규모 언어 모델 물리 문제 품질 검사의 핵심 포인트
물리 문제 품질 검사는 일반 텍스트 채점과 근본적인 차이가 있습니다—모델이 수학적 추론 능력, 물리 개념 이해, 그리고 채점 일관성을 동시에 갖추어야 합니다. 다음은 추천하는 3가지 모델의 핵심 능력 비교입니다:
| 포인트 | 설명 | 실제 가치 |
|---|---|---|
| Gemini 3.1 Pro 추론 능력 선도 | MATH 벤치마크 95.1%, ARC-AGI-2 77.1% 달성, 물리 추론 평가 1위 | 공식 추론이 포함된 역학, 전자기학 계산 문제 처리 정확도 최고 |
| Claude Sonnet 4.6 풀이 과정 명확 | 적응형 사고 모드 지원, 수학 능력 27%p 향상하여 89% 달성 | 완전한 채점 근거와 감점 이유를 출력 가능, 품질 검사 보고서 생성에 적합 |
| GPT-5.4 경쟁급 난이도 문제 성능 우수 | AIME 2025 만점, 100만 토큰 컨텍스트 지원 | 물리 경시대회 문제와 종합 대문제 처리 시 추론 체인이 가장 완전함 |
| 다중 모델 교차 검증 | 3개 모델 독립 채점 후 합의 도출 | 단일 모델 85-90% 정확도를 95%+로 향상 |
대규모 언어 모델 물리 문제 품질 검사의 3가지 주요 과제
과제 1: 공식 추론의 등가 판정. 같은 역학 문제라도, 학생이 에너지 보존 법칙으로 풀 수도 있고, 뉴턴 제2법칙으로 풀 수도 있습니다. 두 방법의 추론 과정은 완전히 다르지만 결과는 등가입니다. 연구에 따르면, 프롬프트에서 모델에게 등가 풀이를 허용하도록 명시적으로 요구하지 않으면, 모델은 표준 답안의 풀이 경로에 경직되어 채점하여 오판율이 30%에 달할 수 있습니다. 이는 대규모 언어 모델 물리 문제 품질 검사에서 가장 흔한 실수 포인트입니다.
과제 2: 물리 단위와 유효 숫자의 오차 허용 처리. 물리 계산에서, 유효 숫자 2자리와 3자리를 유지한 결과는 다르지만, 일반적으로 모두 허용되어야 합니다. 프롬프트에서 합리적인 수치 오차 허용 범위(예: ±5%)를 설정하는 것은 품질 검사 정확도의 핵심 보장 요소입니다.
과제 3: 도표와 실험 문제의 이해. 회로도, 역학 개략도를 포함한 문제는 모델이 멀티모달 이해 능력을 필요로 합니다. Gemini 3.1 Pro와 GPT-5.4가 이 분야에서 상대적으로 좋은 성능을 보이며, Claude Sonnet 4.6은 순수 텍스트와 공식 추론에서 더 안정적입니다.
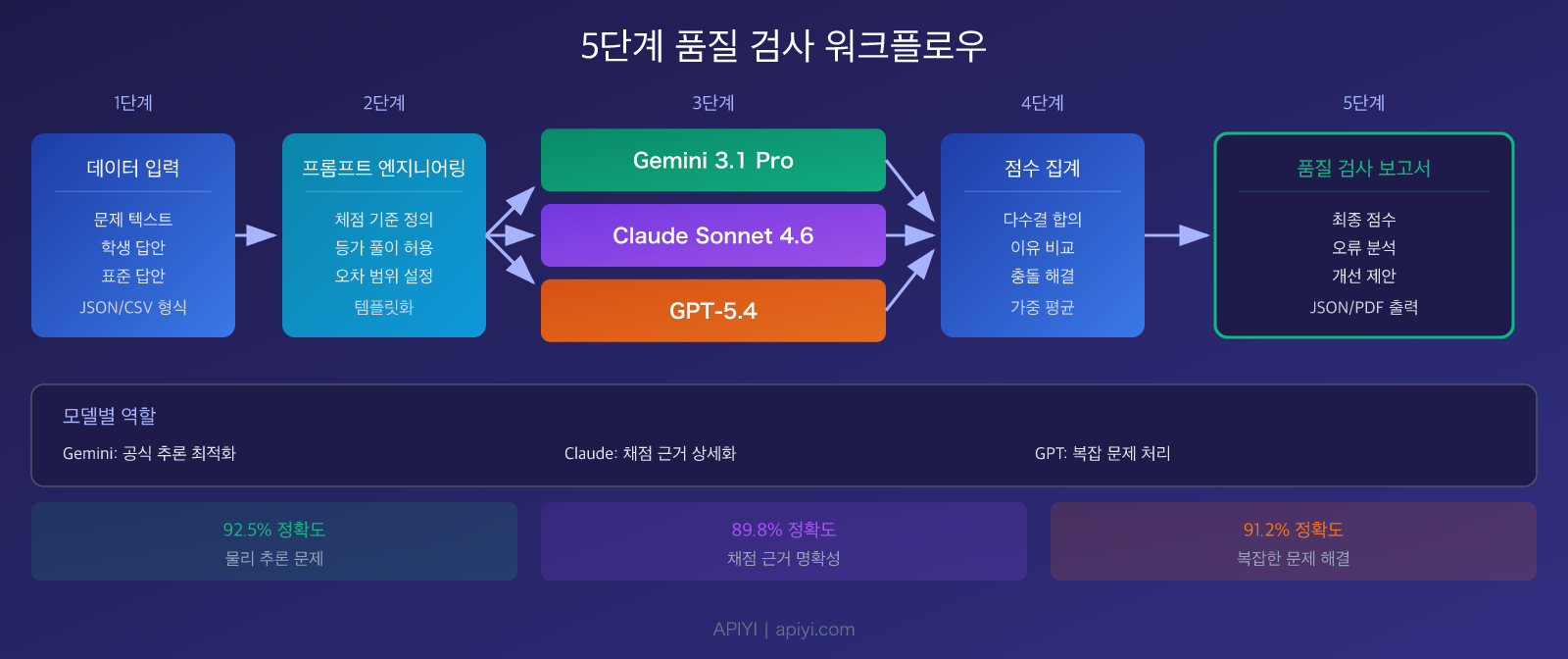
Gemini 3.1 Pro Preview: 물리 추론 최적 선택
Gemini 3.1 Pro는 Google DeepMind가 2026년 2월에 출시한 플래그십 모델입니다. 물리 문제 품질 검사 시나리오에서 세 가지 핵심 강점을 가지고 있어요:
- 최고 수준의 STEM 추론 능력: CritPt(연구 수준 물리 추론) 평가에서 1위를 차지했으며, MATH 벤치마크에서 95.1%의 점수를 기록했어요.
- 조절 가능한 사고 깊이: 새로운
thinking_level파라미터(LOW/MEDIUM/HIGH 지원)가 추가되었어요. 간단한 객관식 문제에는 LOW를 사용해 비용을 절감하고, 종합 계산 문제에는 HIGH를 사용해 정확도를 보장할 수 있죠. - 탁월한 가성비: Claude Opus 4.6 대비 약 1/7.5 수준의 비용으로, 대량의 품질 검사 작업에 적합해요.
Claude Sonnet 4.6: 검사 보고서 생성 최적
Claude Sonnet 4.6는 2026년 2월 17일에 출시되었으며, 물리 문제 품질 검사에서의 독특한 장점은 다음과 같아요:
- 자동 조절 사고 모드: 모델이 문제 난이도에 따라 추론 깊이를 자동으로 결정해요. 쉬운 문제는 빠르게 판단하고, 복잡한 문제는 깊이 있게 추론하죠.
- 100만 토큰 컨텍스트 윈도우: 시험지 전체의 문제와 정답을 한 번에 입력하여 채점 기준을 일관되게 유지할 수 있어요.
- 강력한 구조화 출력: 점수, 감점 사유, 개선 제안을 포함한 형식이 정형화된 품질 검사 보고서를 생성하는 데 특히 능해요.
GPT-5.4: 경시대회 수준 난제 해결의 도구
GPT-5.4는 2026년 3월 5일에 출시된 OpenAI의 최신 플래그십 모델이에요:
- 경시 수학 만점: AIME 2025에서 100% 정답률을 기록하여, 고난도 물리 종합 문제 처리 능력이 뛰어나요.
- 사전 계획 능력: GPT-5.4 Thinking 버전은 'Upfront Planning'을 지원하여, 채점 전에 추론 과정을 먼저 보여줄 수 있어요.
- 최적의 토큰 효율: GPT-5.2 대비 추론에 소모되는 토큰이 크게 감소하여 장기 사용 시 비용이 더 낮아요.
| 모델 | 물리 추론 능력 | 보고서 생성 품질 | 멀티모달 지원 | 백만 토큰당 비용 | 추천 시나리오 |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 최저 | 대량 일상 검사, 차트/그래프 포함 문제 |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 중간 ($3/$15) | 상세 검사 보고서 필요, 전체 시험지 채점 |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 높음 | 경시대회 문제, 종합 서술형 문제, 고난도 검사 |
🎯 선택 가이드: 일상적인 품질 검사에는 Gemini 3.1 Pro(가성비 최고)를, 상세한 보고서가 필요하면 Claude Sonnet 4.6를, 고난도 경시대회 문제에는 GPT-5.4를 사용하세요. APIYI apiyi.com 플랫폼을 통해 하나의 통합 인터페이스로 이 세 모델을 모두 호출할 수 있어 빠르게 전환하고 비교해 볼 수 있어요.
대규모 언어 모델 물리 문제 품질 검사 빠른 시작
초간단 예제: 10줄 코드로 물리 문제 채점 구현하기
다음 예제는 대규모 언어 모델을 사용해 물리 계산 문제를 자동 채점하는 방법을 보여줍니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "당신은 물리 문제 품질 검사 전문가입니다. 표준 정답을 기준으로 학생 답안을 평가하고, JSON 형식으로 출력하세요: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【문제】 질량이 2kg인 물체가 10m 높이에서 자유낙하할 때, 지면에 도달하는 속도를 구하시오 (g=10m/s²)
【표준 정답】 v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【학생 답안】 에너지 보존 법칙 사용: mgh=½mv², v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
전체 품질 검사 파이프라인 코드 보기 (다중 모델 교차 검증 포함)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
물리 문제 다중 모델 교차 품질 검사
Args:
question: 문제 내용
standard_answer: 표준 정답
student_answer: 학생 답안
models: 사용할 모델 목록
tolerance: 수치 허용 오차 (기본값 5%)
Returns:
각 모델의 채점 결과와 최종 결론을 포함한 딕셔너리
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""당신은 경력이 풍부한 물리 교사이자 채점 전문가입니다. 다음 규칙을 엄격히 준수하여 채점하세요:
1. 표준 정답과 동등한 풀이 방법을 인정하세요 (예: 에너지 보존, 뉴턴 법칙 등 다른 접근법)
2. 수치 결과 허용 오차 범위: ±{tolerance*100}%
3. 유효 숫자: ±1자리 차이는 허용
4. 물리 단위는 정확해야 하며, 단위가 없으면 10% 감점
출력은 엄격한 JSON 형식으로:
{{
"score": 점수,
"max_score": 만점,
"is_correct": true/false,
"deductions": [{{"reason": "감점 사유", "points": 감점값}}],
"solution_method": "학생이 사용한 풀이 방법",
"comment": "종합 평가 및 개선 제안"
}}"""
user_prompt = f"""【문제】{question}
【표준 정답】{standard_answer}
【학생 답안】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# 교차 검증: 다수 모델의 합의된 결론을 채택
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# 사용 예시
result = physics_quality_check(
question="질량이 2kg인 물체가 10m 높이에서 자유낙하할 때, 지면에 도달하는 속도를 구하시오 (g=10m/s²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv², v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
추천: APIYI apiyi.com에서 무료 테스트 크레딧을 받아보세요. 하나의 API 키로 Gemini, Claude, GPT 세 모델을 모두 호출할 수 있어, 세 플랫폼에 각각 계정을 만들 필요가 없어요.
대규모 언어 모델 물리 문제 품질 검사의 프롬프트 엔지니어링 실무
효과적인 프롬프트 설계는 검사 정확도의 핵심입니다. 다음은 실제 테스트를 통해 검증된 프롬프트 템플릿과 최적화 전략입니다.
물리 문제 품질 검사 프롬프트 템플릿
학술 연구(2024-2026년 발표된 다수 논문)에 따르면, Tree of Thought(사고 나무) 프롬프트 전략이 물리 계산 문제 채점에서 가장 우수한 성능을 보이며, 정확도 ≥ 0.9, Cohen's Kappa > 0.8을 기록했습니다. 다음은 저희가 권장하는 프롬프트 구조입니다.
| 프롬프트 전략 | 적합한 문제 유형 | 정확도 | 추천 모델 |
|---|---|---|---|
| Tree of Thought | 종합 계산 문제, 유도 문제 | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | 개념 분석 문제, 단답형 문제 | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | 객관식 문제, 빈칸 채우기 문제 | 80-85% | GPT-5.4 (비용 효율적) |
| 다중 투표 | 모든 문제 유형 (높은 요구사항) | 92-95% | 세 가지 모델 조합 |
핵심 프롬프트 최적화 기술
기술 1: 명확한 등가 해법 수용 규칙 설정. System Prompt에 해당 문제에서 허용 가능한 모든 해결 방법을 나열하세요. 예를 들어 역학 문제에서는 다음과 같이 명시합니다: 「에너지 보존 법칙, 뉴턴 운동 법칙, 운동량 정리 등 동등한 방법을 모두 수용합니다.」 이 단일 규칙만으로 오판률을 30%에서 5% 미만으로 낮출 수 있습니다.
기술 2: 정확한 일치 대신 수치적 허용 오차 설정. 물리 계산에서 중간 과정의 반올림은 최종 결과에 미세한 차이를 초래할 수 있습니다. ±5%의 허용 오차를 설정하고, 동시에 물리적 단위가 정확해야 함을 요구하는 것을 권장합니다.
기술 3: 모델에게 먼저 풀고 채점하도록 요구. 모델이 먼저 독립적으로 문제를 풀고, 그 다음 학생 답안과 비교하도록 하세요. 이 방식은 모델에게 "표준 답안과 대조하여 채점하라"고 직접 지시하는 것보다 정확도가 15-20% 높습니다. Gemini 3.1 Pro의 thinking_level: HIGH 모드와 Claude Sonnet 4.6의 Extended Thinking이 이러한 용도에 적합합니다.
기술 4: 다중 실행 후 최빈값 채택. 동일한 문제에 대해 3-5회 채점을 실행한 후 가장 빈번한 결과를 채택하고, 표준편차를 신뢰도 지표로 활용할 수 있습니다. 표준편차 > 1점일 경우 수동 검토를 권장합니다.
🎯 실무 제안: 품질 검사 시스템을 처음 구축할 때는, 먼저 50-100개의 수동 채점된 물리 문제를 테스트 세트로 사용하여 APIYI apiyi.com에서 세 모델의 정확도를 각각 테스트하고, 당신의 문제 은행 특성에 가장 적합한 모델 조합을 찾는 것을 권장합니다.

대규모 언어 모델 물리 문제 품질 검증의 시나리오별 솔루션
다른 유형의 물리 문제는 다른 품질 검증 전략이 필요합니다. 다음은 4가지 대표적인 시나리오에 대한 권장 설정입니다:
시나리오 1: 일상 과제 일괄 품질 검증
고등학교/대학교 물리 일상 과제에 적합하며, 문제량이 많고(하루 100+ 문제), 난이도는 중간 수준입니다.
- 권장 모델: Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - 프롬프트 전략: Few-Shot + 표준 채점표
- 비용 장점: 1000문제 처리 시 약 200만 토큰 소모, Gemini 3.1 Pro 비용이 다른 모델보다 훨씬 저렴
- 정확도: 85-90%(단일 모델), 수동 샘플 검사와 결합 시 95%+ 달성 가능
시나리오 2: 기말고사 상세 채점
공식 시험 채점에 적합하며, 상세한 채점 근거와 감점 사유가 필요합니다.
- 권장 모델: Claude Sonnet 4.6 (Extended Thinking 모드)
- 프롬프트 전략: Tree of Thought + 상세 채점 기준
- 핵심 장점: 출력된 품질 검증 보고서 구조가 명확하여 채점 기록으로 바로 보관 가능
- 정확도: 88-92%(단일 모델)
시나리오 3: 물리 경시대회 문제 품질 검증
고등학교 물리 경시대회 훈련에 적합하며, 문제가 종합적이고 난이도가 높습니다.
- 권장 모델: GPT-5.4 Thinking (Upfront Planning 모드)
- 프롬프트 전략: Tree of Thought + 먼저 풀고 채점
- 핵심 장점: AIME 만점 수준, 다단계 추론 및 고급 수학 연산 처리 가능
- 정확도: 80-85%(경시대회 난이도에서의 단일 모델 성능)
시나리오 4: 다중 모델 교차 검증 (최고 정확도)
고위험 시험(예: 진학 시험)에 적합하며, 최고의 정확도가 필요합니다.
- 권장 솔루션: 3개 모델 독립 채점 → 2/3 다수 합의 → 의견이 다른 문제 수동 재검토
- 구현 비용: 단일 문제 비용이 단일 모델의 약 3배이지만, 정확도는 95%+로 향상
- 적용 규모: 문제량이 적지만(< 500문제) 품질 요구사항이 극히 높은 시나리오에 적합
| 시나리오 | 권장 모델 | 프롬프트 전략 | 정확도 | 비용(천 문제) |
|---|---|---|---|---|
| 일상 과제 | Gemini 3.1 Pro | Few-Shot | 85-90% | 낮음 |
| 기말고사 | Claude Sonnet 4.6 | Tree of Thought | 88-92% | 중간 |
| 경시대회 문제 | GPT-5.4 Thinking | ToT + 먼저 풀기 | 80-85% | 높음 |
| 교차 검증 | 3개 모델 조합 | 다중 투표 | 95%+ | 높음(3×) |
🎯 모델 전환 제안: 다른 시나리오는 모델 요구사항이 크게 다릅니다. APIYI apiyi.com은 하나의
model매개변수를 수정하는 것만으로 모델을 전환할 수 있도록 지원하여, 문제 유형에 따라 동적으로 최적의 모델을 선택하기 쉽게 합니다.
자주 묻는 질문
Q1: 대규모 언어 모델 물리 문제 품질 검증이 수동 채점을 완전히 대체할 수 있나요?
현재는 완전히 대체할 수 없습니다. 학술 연구에 따르면, 대규모 언어 모델은 표준화된 계산 문제 처리 시 정확도가 90%+에 도달할 수 있지만, 불충분하게 정의된 문제(under-specified problems)에서는 정확도가 8.3%에 불과합니다. 권장 솔루션: 대규모 언어 모델이 80%의 표준 문제 채점을 담당하고, 사람이 20%의 복잡한 문제와 논쟁의 여지가 있는 문제 재검토를 담당합니다.
Q2: 세 가지 모델의 API 연동 복잡도는 어떻습니까?
세 가지 모델은 각각 Google, Anthropic, OpenAI 세 플랫폼에서 제공합니다. 각각 개별적으로 등록하고 연동하면 개발 비용이 높아집니다. APIYI apiyi.com의 통합 인터페이스를 통해 호출하는 것을 권장합니다. 모든 모델이 동일한 OpenAI SDK 형식을 사용하며, model 매개변수만 수정하면 전환할 수 있어 연동 비용을 크게 절감합니다.
Q3: 품질 검증 시스템의 정확도를 어떻게 평가하나요?
Cohen's Kappa 계수를 사용하여 모델과 사람 채점 간의 일치도를 측정하는 것을 권장합니다:
- 이미 수동으로 채점된 물리 문제 50-100개를 테스트 세트로 준비
- APIYI apiyi.com을 통해 세 가지 모델을 각각 호출하여 채점
- 각 모델과 사람 채점 간의 Kappa 값 계산
- Kappa > 0.8은 높은 일치도를 의미하며, 사용 가능
요약
대규모 언어 모델을 활용한 물리 문제 품질 검증의 핵심 포인트:
- Gemini 3.1 Pro Preview 우선 선택: STEM 분야 추론 능력이 가장 뛰어나고 가성비가 높아, 대량의 일상적인 물리 문제 검증에 적합합니다.
- Claude Sonnet 4.6은 보고서 작성에 적합: 적응형 사고 모드와 구조화된 출력 덕분에, 상세한 채점 근거가 필요한 공식 시험에 적합합니다.
- GPT-5.4는 경시대회 난제 처리에 적합: AIME 만점 수준의 추론 능력으로, 고난도 복합 물리 문제를 처리하는 데 가장 신뢰할 수 있습니다.
- 다중 모델 교차 검증으로 95%+ 정확도 달성: 세 가지 모델의 독립적인 채점 결과를 합의하는 방식이 현재 가장 신뢰할 수 있는 자동화 검증 솔루션입니다.
어떤 모델을 선택할지는 문제 유형의 특성과 요구되는 정확도에 따라 달라집니다. APIYI(apiyi.com)를 통해 빠르게 테스트하고 비교해 보는 것을 추천합니다. 플랫폼에서 무료 크레딧과 통합 인터페이스를 제공하며, 하나의 API 키로 모든 주요 모델을 호출할 수 있습니다.
📚 참고 자료
-
MDPI 교육 과학 – 대규모 언어 모델 기반 물리 문제 지능형 채점 연구: 물리 문제 채점에서 네 가지 프롬프트 전략의 성능 비교
- 링크:
mdpi.com/2227-7102/15/2/116 - 설명: Tree of Thought 전략의 정확도 ≥ 0.9 실험 데이터 출처
- 링크:
-
Physical Review – 물리 올림피아드 문제에 대한 LLM 평가: 물리 경시대회 문제에 대한 GPT와 추론 모델의 체계적 평가
- 링크:
link.aps.org/doi/10.1103/6fmx-bsnl - 설명: 대규모 언어 모델의 물리 추론 능력이 인간 평균 수준을 넘어섰다는 핵심 근거
- 링크:
-
Google DeepMind – Gemini 3.1 Pro 기술 블로그: 모델 아키텍처 및 STEM 벤치마크 테스트 상세 정보
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 설명: Gemini 3.1 Pro 물리 추론 평가 데이터의 공식 출처
- 링크:
-
Anthropic – Claude Sonnet 4.6 발표 공지: 적응형 사고 모드 및 수학 능력 향상 상세 정보
- 링크:
anthropic.com/news/claude-sonnet-4-6 - 설명: Claude Sonnet 4.6 수학 능력 27% 향상의 기술적 세부사항
- 링크:
-
OpenAI – GPT-5.4 발표 공지: Upfront Planning 및 추론 효율성 향상
- 링크:
openai.com/index/introducing-gpt-5-4/ - 설명: GPT-5.4 AIME 만점 및 토큰 효율 최적화의 공식 데이터
- 링크:
작성자: APIYI 기술팀
기술 교류: 대규모 언어 모델을 활용한 물리 문제 품질 검증의 실무 경험에 대해 댓글로 자유롭게 토론해 주세요. 더 많은 모델 호출 튜토리얼은 APIYI 문서 센터(docs.apiyi.com)에서 확인하실 수 있습니다.