
저자 주: Gemini 3.1 Flash Image Preview 이미지 생성 429 속도 제한 문제의 근본 원인 분석, AI Studio, Vertex AI 및 타사 플랫폼의 속도 제한 정책 비교, 4가지 실제 테스트로 효과가 입증된 해결책 제공
Gemini 3.1 Flash Image Preview로 이미지를 생성할 때 가장 골치 아픈 건 생성 품질이 아니라, 막 시작했는데 429 속도 제한에 걸려 막히는 겁니다. AI Studio를 쓰든 Vertex AI를 쓰든, RPD(일일 요청 수)와 RPM(분당 요청 수) 제한이 매우 엄격해서, 배치 이미지 생성은 사실상 돌아가지 않습니다.
이 글은 실제 사용 경험을 바탕으로 429 속도 제한의 근본 원인을 자세히 분석하고, 다양한 플랫폼의 속도 제한 정책 차이를 비교하며, 검증된 4가지 해결책—동시 실행 제한 없고, 가격이 $0.045/장까지 낮은 방법도 포함해서—제시합니다.
핵심 가치: 이 글을 다 읽으시면, Gemini 이미지 생성 429 오류의 내부 동작 방식을 완전히 이해하게 되고, 여러분의 상황에 가장 적합한 해결책을 찾을 수 있게 됩니다.
Gemini 3.1 Flash Image Preview 429 오류란 무엇인가요
먼저 이 오류가 어떻게 생겼는지 보겠습니다.
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
쉽게 말하면: 오늘 사용 가능한 요청 횟수를 다 썼거나, 분당 요청이 너무 빈번하다는 뜻입니다.
503 오류와는 다르게, 429는 서버가 버티지 못해서가 아니라 Google이 여러분에게 직접 설정한 할당량 상한선입니다. 서버에 여유 컴퓨팅 자원이 남아 있어도, 한도에 도달하면 바로 거절합니다.
Gemini 이미지 생성 429와 503 오류의 차이점
| 비교 항목 | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| 근본 원인 | 할당량을 다 씀 | 서버 컴퓨팅 자원 부족 |
| 발생 조건 | RPD/RPM/TPM 제한 초과 | 글로벌 고부하 |
| 영향 범위 | 여러분의 프로젝트만 | 모든 사용자 |
| 대기로 해결 가능 여부 | RPM은 1분, RPD는 다음날까지 기다림 | 보통 수분에서 수시간 |
| 유료로 해결 가능 여부 | Vertex AI에서 할당량 상향 가능 | 직접 해결 불가 |
| 근본 해결책 | 플랫폼 변경/할당량 상향 | 대기 또는 플랫폼 변경 |
Gemini 3.1 Flash Image Preview 각 플랫폼별 제한 정책 비교
이것이 문제의 핵심입니다. 각 플랫폼마다 제한 정책이 크게 다릅니다.
Gemini 이미지 생성 AI Studio 제한 매개변수
AI Studio는 대부분의 개발자가 처음 선택하는 무료이면서도 좋은 플랫폼입니다. 하지만 이미지 생성에 대한 제한은 매우 엄격합니다.
| 제한 차원 | 제한 값 | 환산 |
|---|---|---|
| RPM (분당 요청) | 10회 | 6초에 1번만 요청 가능 |
| RPD (일일 요청) | 1,500회 | 약 2.5시간 사용 시 상한 도달 |
| TPM (분당 토큰) | 4,000,000 | 일반적으로 병목 현상이 아님 |
| 이미지 출력 TPM | 12,000 tokens/분 | 약 10장/분 |
실제 경험: 500장의 이미지를 일괄 생성해야 한다면, RPM=10 기준으로 이론상 최소 50분이 필요합니다. 하지만 네트워크 지연, 재시도 등을 고려하면 실제로는 1-2시간이 소요됩니다. 하루에 1,500장 이상을 생성해야 한다면, RPD 제한에 바로 걸리게 됩니다.
Gemini 이미지 생성 Vertex AI 제한 매개변수
Vertex AI는 Google Cloud의 엔터프라이즈급 솔루션으로, 할당량이 더 높지만 여전히 상한선이 있습니다.
| 제한 차원 | 기본값 | 상향 신청 가능 여부 |
|---|---|---|
| RPM | 60회 | 가능, 승인 필요 |
| RPD | 고정 상한 없음 | RPM 및 TPM에 의해 제약됨 |
| TPM | 4,000,000 | 신청 가능 |
| 이미지 출력 TPM | 24,000 tokens/분 | 신청 가능 |
실제 경험: RPM이 10에서 60으로 증가하면 훨씬 나아 보이지만, 상향 신청에는 Google Cloud 티켓 프로세스를 거쳐야 하며, 일반적으로 1-3 영업일이 소요됩니다. 또한 Vertex AI 구성은 AI Studio보다 훨씬 복잡합니다(GCP 프로젝트 생성, 서비스 계정 설정, IAM 권한 구성 등). 많은 개인 개발자와 소규모 팀은 바로 포기하게 됩니다.
Gemini 이미지 생성 제3자 플랫폼 제한 비교
| 플랫폼 | 동시 처리 제한 | RPD 제한 | 단가 (1K) | 비고 |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1,500/일 | 무료 (할당량 있음) | 가장 엄격함 |
| Vertex AI | RPM=60 | 고정 상한 없음 | ~$0.067 | GCP 구성 필요 |
| OpenRouter | 요금제에 따라 다름 | 요금제에 따라 다름 | ~$0.06-0.08 | 범용 플랫폼 |
| APIYI | 동시 처리 제한 없음 | 제한 없음 | $0.045 | 횟수별 과금, 해상도 제한 없음 |
Gemini 3.1 Flash Image Preview 429 제한 해결을 위한 4가지 방법
방법 1: Gemini 이미지 생성 요청 조절 + 자동 재시도
가장 기본적인 방법으로, 플랫폼을 변경할 필요는 없지만 효율성이 낮습니다.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""백오프 재시도가 포함된 이미지 생성 요청"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# 지수 백오프 + 무작위 지터
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 제한, {wait_time:.1f}s 후 재시도 ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"요청 예외: {e}")
time.sleep(2)
raise Exception("최대 재시도 횟수 초과")
전체 일괄 생성 스크립트 보기 (속도 제어 포함)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""AI Studio RPM=10 제한을 준수하는 일괄 생성기"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # 요청 간 최소 간격
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] {wait:.1f}s 대기 중 ...")
time.sleep(wait)
except Exception as e:
print(f"예외: {e}")
time.sleep(2)
return False
# 사용 예시
gen = RateLimitedGenerator("YOUR_AISTUDIO_KEY", rpm_limit=10)
prompts = ["a sunset over mountains", "a cat in space", "futuristic city"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
장점: 비용 없음, 소량 요청에 적합
단점: 속도 느림, RPD=1,500의 하드 리밋은 극복 불가
방법 2: Gemini 이미지 생성 Vertex AI로 이전하여 할당량 상향
Google Cloud 계정이 있는 기업 사용자에게 적합합니다.
작업 단계:
- GCP 프로젝트 생성 및 Vertex AI API 활성화
- 서비스 계정 및 IAM 권한 설정
- Google Cloud Console → IAM → Quotas에서 RPM 상향 신청
- 코드의 엔드포인트를 AI Studio에서 Vertex AI로 전환
장점: RPM이 10에서 60+로 상향, 기업 시나리오에서 사용 가능
단점: 구성 복잡, 승인 주기 1-3일, Google Cloud 표준 요금 적용
방법 3: Gemini 이미지 생성 다중 프로젝트 순환
여러 GCP 프로젝트나 AI Studio API 키를 생성하여 순환 요청을 보내 단일 프로젝트의 RPD/RPM 제한을 우회합니다.
import itertools
api_keys = ["KEY_1", "KEY_2", "KEY_3", "KEY_4", "KEY_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""키 순환을 사용한 이미지 생성"""
key = next(key_pool)
# ... 현재 키를 사용하여 요청 전송
return send_request(prompt, api_key=key)
장점: 이론적으로 N개의 키는 N배의 처리량을 얻을 수 있음
단점: Google 서비스 약관(TOS) 위반, 계정 정지 위험; 여러 키 관리로 복잡성 증가
방법 4: Gemini 이미지 생성 동시 처리 제한 없는 제3자 플랫폼 사용
이것이 제가 최종적으로 채택한 방법입니다. 여러 제3자 플랫폼을 비교한 후, APIYI wentuo.ai를 선택했습니다. 이유는 간단합니다.
| 비교 차원 | AI Studio | Vertex AI | APIYI |
|---|---|---|---|
| 동시 처리 제한 | RPM=10 | RPM=60 | 제한 없음 |
| 일일 제한 | 1,500회/일 | RPM에 의해 제약 | 제한 없음 |
| 단가 (4K 포함) | 무료지만 할당량 있음 | $0.067-$0.151 | $0.045 |
| 사용량 기반 과금 (1K) | – | $0.067 | 약 $0.025 |
| 구성 복잡도 | 간단 | 복잡 | 간단 |
| VPN 필요 여부 | 예 | 예 | 아니오 |
실제 사용해보니, 횟수별 과금 $0.045/장은 4K 해상도를 포함하며, 토큰 기준 과금의 경우 해상도에 따라 약 $0.02-$0.05 사이입니다. 가장 중요한 점은 동시 처리 제한이 없어 일괄 작업을 전속력으로 실행할 수 있고, 더 이상 429 에러에 막히지 않는다는 것입니다.
호출 방식도 매우 간단합니다. 엔드포인트만 변경하면 됩니다.
import requests
import base64
API_KEY = "your-wentuo-api-key"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "A cute cat wearing a space helmet"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 사용 권장사항: 일일 생성량이 500장을 초과하거나, 동시 처리 속도에 요구사항이 있다면, APIYI wentuo.ai의 동시 처리 제한 없는 솔루션을 직접 사용하는 것을 권장합니다. 횟수별 과금 $0.045/장 (해상도 제한 없음), 사용량 기반 과금은 $0.018/장 (512px)부터 시작하여 Google 공식보다 33%-70% 절약할 수 있습니다.
Gemini 3.1 Flash Image Preview 429 제한 해결을 위한 4가지 방안 선택 가이드
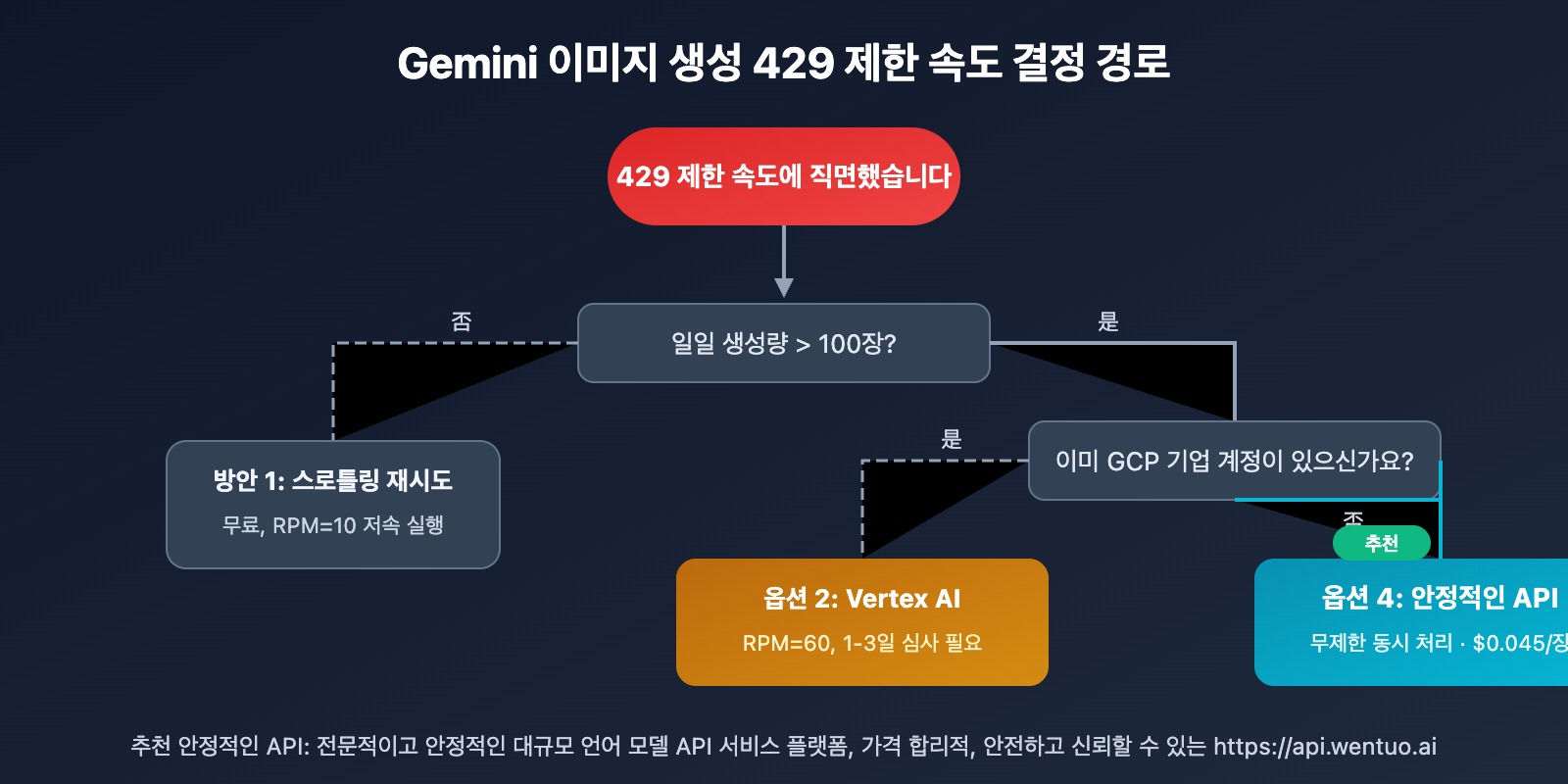
다른 상황에 맞는 다른 방안이 있어요:
| 사용 시나리오 | 추천 방안 | 이유 |
|---|---|---|
| 🎨 개인 학습/체험 | 방안 1 (제한 재시도) | 무료, 양이 적어 영향 없음 |
| 🏢 기업에 GCP 계정 있음 | 방안 2 (Vertex AI) | 규정 준수, 높은 할당량 신청 가능 |
| 🔬 일시적 대량 테스트 | 방안 3 (다중 API 키) | 단기 사용 가능, 주의 필요 |
| 🚀 프로덕션 환경/일괄 생성 | 방안 4 (APIYI) | 동시 호출 제한 없음, 비용 최저 |
Gemini 이미지 생성 각 방안의 처리량 비교
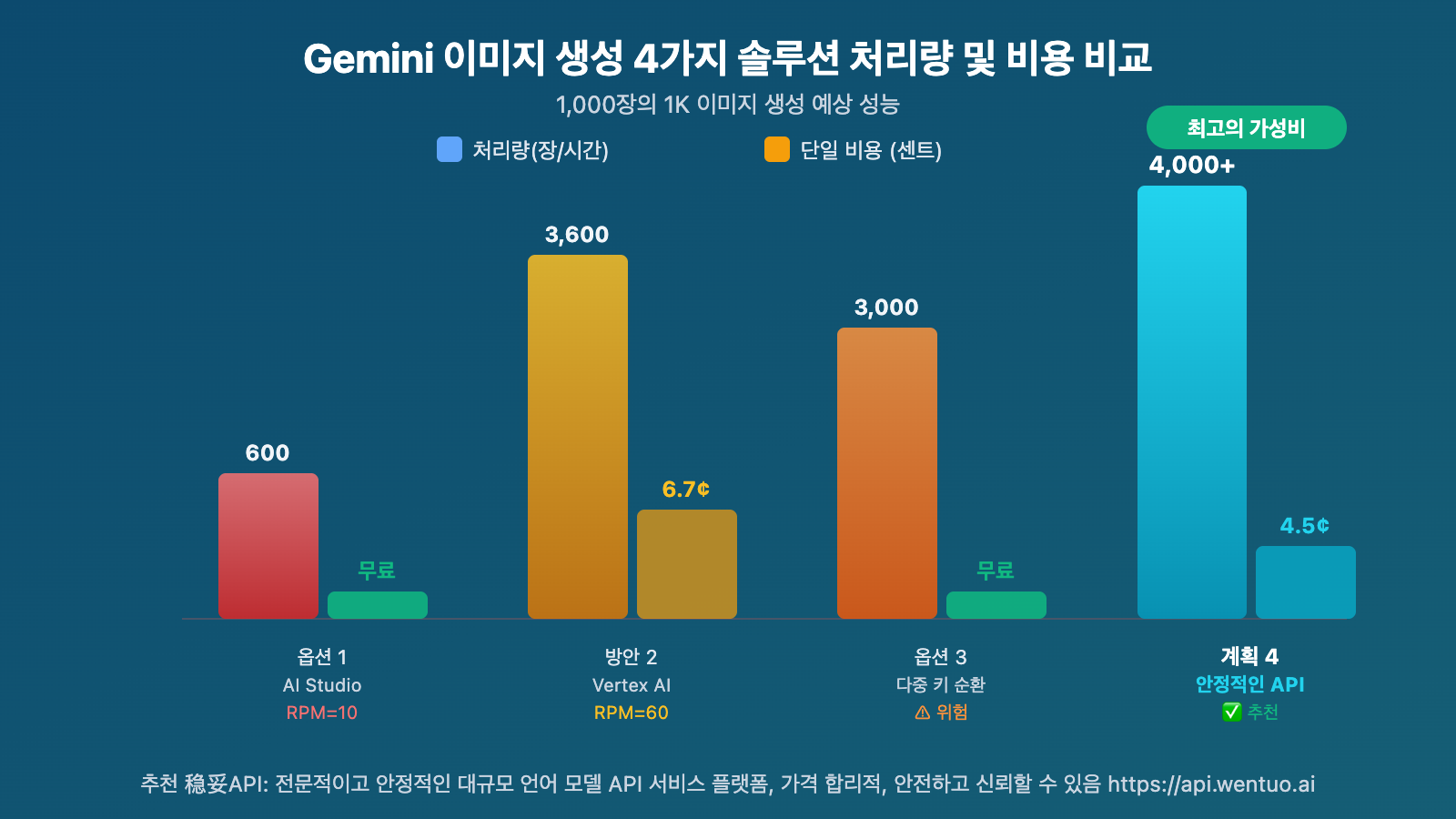
1,000장의 1K 이미지를 생성한다고 가정했을 때:
| 방안 | 예상 소요 시간 | 총 비용 | 실현 가능성 |
|---|---|---|---|
| AI Studio (RPM=10) | ~100분 + RPD 제한으로 다음날까지 걸릴 수 있음 | 무료 | ⚠️ RPD 제한 있음 |
| Vertex AI (RPM=60) | ~17분 | ~$67 | ✅ GCP 필요 |
| 다중 키 순환 (5개 키) | ~20분 | 무료 | ⚠️ 계정 정지 위험 있음 |
| APIYI (동시 호출 제한 없음) | ~10-15분 | $45 (건별) / ~$25 (사용량 기준) | ✅ 추천 |
자주 묻는 질문
Q1: Gemini 3.1 Flash Image Preview 429 오류 발생 후 얼마나 지나야 복구되나요?
어떤 제한을 트리거했는지에 따라 달라요:
- RPM 제한: 1분 후 자동 복구
- RPD 제한: 다음날 (UTC 시간 0시) 초기화될 때까지 대기
- TPM 제한: 1분 후 복구
코드에서 details 필드의 quota_limit 값을 확인해 구체적인 제한 유형을 판단하고, 그에 맞는 전략을 취하는 것을 권장해요.
Q2: APIYI의 이미지 생성 품질은 Google 공식과 동일한가요?
네, 맞아요. APIYI(wentuo.ai)는 Google 공식 Gemini 3.1 Flash Image Preview 모델을 직접 호출하므로, 생성 품질은 공식과 완전히 동일해요. 차이점은 다음과 같아요:
- RPD/RPM 제한이 없어요
- 동시 호출 제한 없이 지원해요
- 가격이 더 저렴해요 ($0.045/장 vs 공식 $0.067/장@1K)
Q3: 건별 과금과 사용량 기준 과금 중 어떤 것을 선택해야 하나요?
간단한 선택 로직은 다음과 같아요:
- 고정적으로 2K/4K 해상도 사용 → 건별 과금 선택 ($0.045/회, 해상도 제한 없어 가장 합리적)
- 주로 512px/1K 사용 → 사용량 기준 과금 선택 (512px 기준 $0.018/회, 건별보다 60% 저렴)
- 혼합 해상도 사용 → 평균 비용을 계산해보세요. 보통 사용량 기준 과금이 더 합리적이에요.
APIYI(wentuo.ai)는 두 가지 과금 방식을 유연하게 전환하며 지원해요.
🎯 요약
Gemini 3.1 Flash Image Preview의 429 제한 문제는 본질적으로 Google이 AI Studio와 Vertex AI에 대해 설정한 엄격한 할당량 제한(RPD/RPM) 때문입니다. 핵심 포인트는 다음과 같습니다:
- 제한 유형 이해하기: 429는 할당량 제한(사용자 문제), 503은 서버 과부하(Google 문제)로, 해결 방법이 완전히 다릅니다.
- 사용량 평가하기: 일일 100장 이내라면 AI Studio로 충분하지만, 500장을 넘어간다면 서드파티 플랫폼을 고려하는 것이 좋습니다.
- 적절한 솔루션 선택하기: 프로덕션 환경에서는 동시 실행 제한이 없는 솔루션을 사용하여 비즈니스에 영향을 미치는 제한을 피하는 것이 좋습니다.
- 비용 비교는 중요합니다: APIYI는 회당 $0.045/장(4K 포함), 볼륨 기준으로는 $0.018/장까지 가능하여 공식 가격보다 33%-70% 절약할 수 있습니다.
이미지를 대량으로 생성해야 하는 개발자에게는 APIYI wentuo.ai가 현재 종합적인 경험 측면에서 가장 좋은 선택입니다—동시 실행 제한 없음, 더 저렴한 가격, VPN 불필요, 인터페이스 완벽 호환.
📚 참고 자료
-
Google Gemini API 공식 문서: 이미지 생성 할당량 및 제한 설명
- 링크:
ai.google.dev/gemini-api/docs/image-generation - 설명: 공식 할당량 매개변수 및 모범 사례
- 링크:
-
Google Cloud 할당량 관리: Vertex AI 할당량 신청 절차
- 링크:
cloud.google.com/vertex-ai/docs/quotas - 설명: 기업 사용자를 위한 할당량 증가 공식 경로
- 링크:
-
APIYI Nano Banana 2 문서: 동시 실행 제한 없는 이미지 생성 연동 가이드
- 링크:
docs.wentuo.ai - 설명: 회당/볼륨 기준 두 가지 과금 방안에 대한 상세 설명 및 코드 예시
- 링크:
📝 저자 소개: 기술 콘텐츠 제작 팀으로, AI 이미지 생성 및 API 기술 공유에 집중합니다. 더 많은 기술 콘텐츠와 리소스는 APIYI wentuo.ai를 방문하여 확인하세요.
📋 콘텐츠 설명: 본문 내용은 실제 사용 경험을 바탕으로 정리되었으며, 구체적인 제한 매개변수는 Google 정책 변경에 따라 달라질 수 있습니다. 기술 지원이 필요하시면 APIYI wentuo.ai를 통해 도움을 받으실 수 있습니다.