
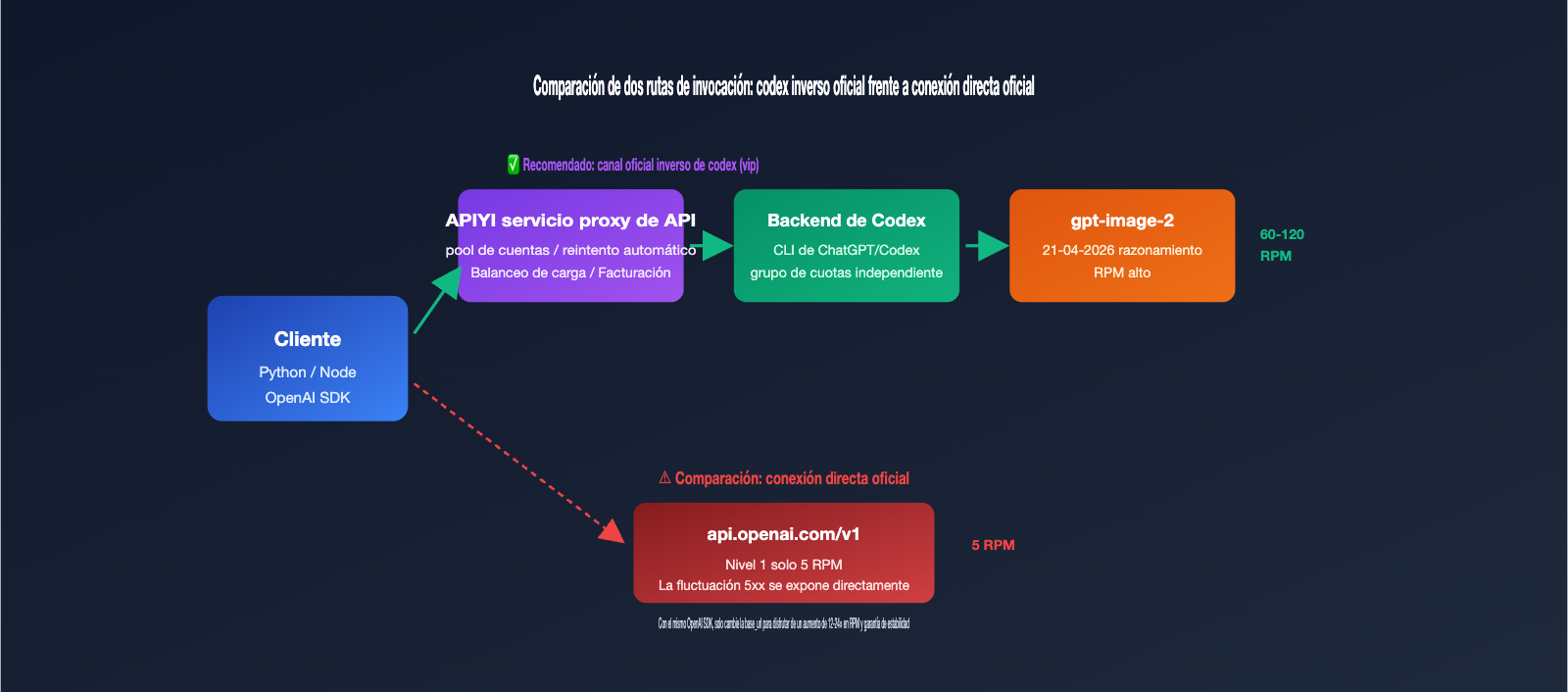
Si acabas de integrar gpt-image-2 en tu entorno de producción, es muy probable que te hayas topado con dos muros: la limitación de tasa (rate limiting) y la estabilidad. Las restricciones oficiales de OpenAI para gpt-image-2 son bastante estrictas; las cuentas de Nivel 1 solo tienen 5 solicitudes por minuto, lo que provoca errores 429 en cuanto intentas procesar un lote. Además, si te encuentras con fluctuaciones 5xx, es común sufrir varios fallos consecutivos. Por eso, muchos equipos recurren a "canales inversos oficiales": realizar ingeniería inversa al backend de gpt-image-2 integrado en ChatGPT Pro/Codex CLI para compartir cuotas de RPM más altas y enlaces mucho más estables.
El modelo gpt-image-2-vip disponible en APIYI (apiyi.com) utiliza precisamente esta ruta inversa de Codex. En este artículo, analizaremos a fondo este endpoint a través de sus 5 características principales, 30 opciones de tamaño, 3 endpoints compatibles y código práctico, para que puedas integrarlo directamente en producción al terminar de leer.
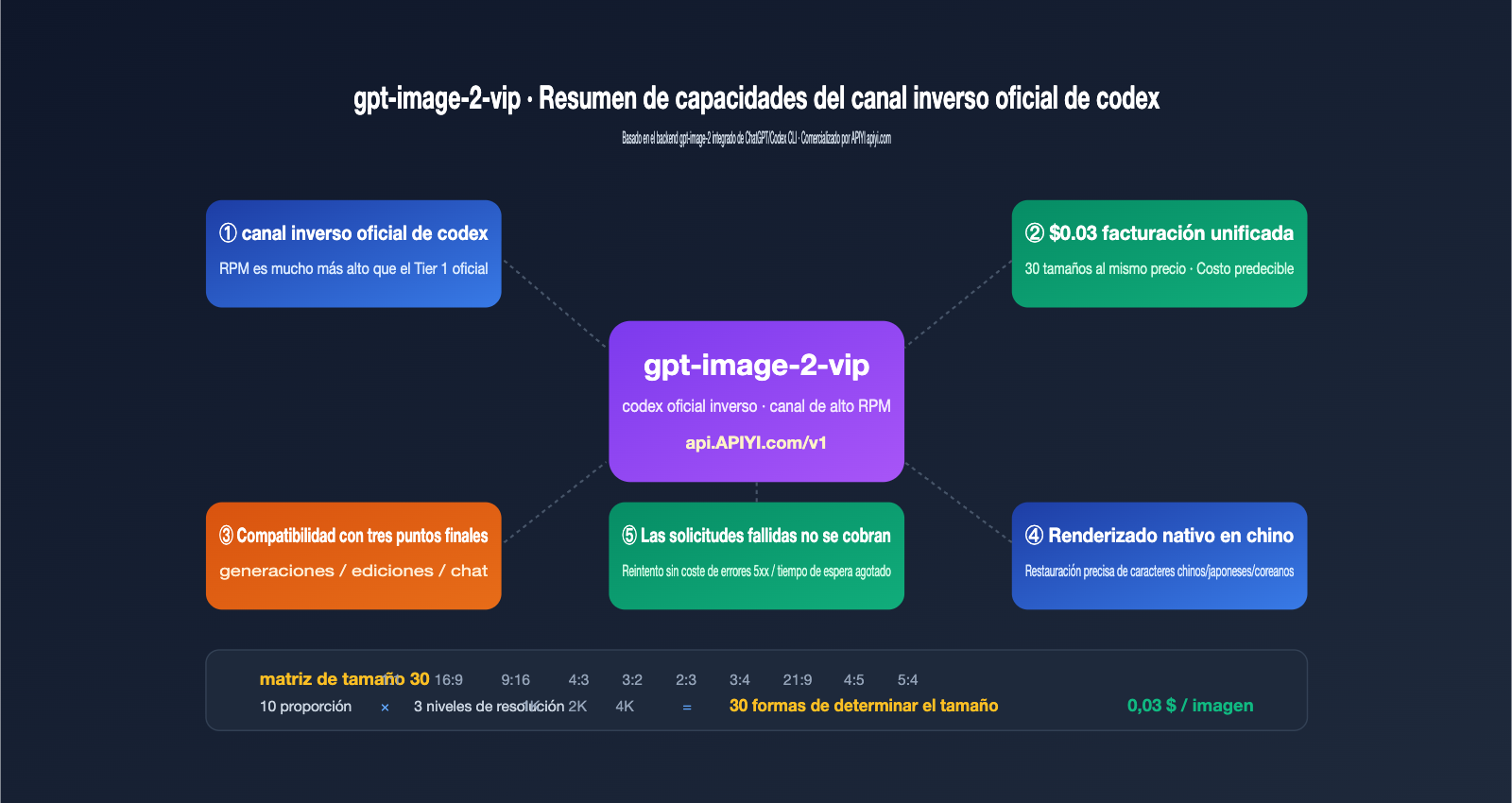
¿Qué es la "API inversa oficial" de Codex? 3 diferencias fundamentales con la conexión directa
Muchos desarrolladores, al escuchar por primera vez el término "Codex oficial inverso" (codex 官逆), podrían pensar que se trata de una interfaz ilegal. En realidad, se refiere a la ingeniería inversa de la cadena de invocación de gpt-image-2 integrada en el CLI de Codex de OpenAI y en ChatGPT Pro. Cuando OpenAI lanzó gpt-image-2 en abril de 2026, lo integró simultáneamente en el CLI de Codex (la función $imagegen) y en el cliente de ChatGPT. Ambos puntos de entrada comparten un grupo de cuotas de velocidad independiente, con políticas de limitación de tasa distintas a las de la API pública.
Lo que hace el canal de "Codex oficial inverso" es: exponer ese flujo de datos interno de Codex como una interfaz REST, permitiéndote usar gpt-image-2 como si fuera una API de OpenAI normal, pero ejecutándose a través del backend de ChatGPT. El modelo gpt-image-2-vip es una implementación de este tipo, y presenta 3 diferencias fundamentales frente a la conexión directa oficial.
| Dimensión | Conexión directa oficial de OpenAI | Canal de Codex oficial inverso (gpt-image-2-vip) |
|---|---|---|
| Límite de tasa | Nivel 1: 5 RPM, requiere recarga para desbloquear | Utiliza el grupo compartido de Codex, mucho mayor que el Nivel 1 |
| Modelo de facturación | Facturación escalonada por tamaño/calidad | Unificado a $0.03/imagen, 30 tamaños al mismo precio |
| Estabilidad | Afectada directamente por fluctuaciones 5xx oficiales | Grupo de cuentas múltiples + reintento automático, oculta inestabilidad |
Parámetro quality |
Soporta low/medium/high/auto | No soportado (usa la estrategia interna de Codex) |
Lote n |
Soporta 1-4 imágenes | No soportado, devuelve 1 imagen por vez |
| Validez de URL | 60 minutos | ~24 horas |
🎯 Concepto clave: La "inversa oficial" no es un "hackeo"; es exponer la cadena de invocación interna de un producto propio de OpenAI (Codex CLI) como una interfaz REST. APIYI (apiyi.com) convierte este canal en un producto comercial, cuyo valor principal no es saltarse a OpenAI, sino ofrecer a los usuarios de la API las cuotas de velocidad más estables del lado de Codex.
5 características principales de gpt-image-2-vip
Una vez comprendidas las diferencias del canal, sus características son más claras. Los siguientes 5 puntos son las diferencias más críticas entre gpt-image-2-vip y los modelos de la misma serie gpt-image-2-all o el gpt-image-2 oficial, además de ser detalles clave que suelen estar dispersos en la documentación.
Característica 1: 30 tamaños personalizables y facturación unificada de $0.03
El mayor valor de ingeniería de gpt-image-2-vip es convertir el "tamaño" en un parámetro de primer nivel. El modelo admite 10 relaciones de aspecto × 3 niveles de resolución = 30 tamaños definidos, los cuales se especifican en el parámetro size sin necesidad de ajustar la indicación (prompt). En cuanto a la facturación, es más directo: los 30 tamaños tienen un precio unificado de $0.03 por imagen, eliminando los costos ocultos de "tamaños grandes más caros". Para equipos que realizan generación basada en plantillas o miniaturas por lotes, esto mejora enormemente la previsibilidad de los costos.
| Nivel de resolución | Píxeles lado corto | Píxeles lado largo (límite) | Escenarios de uso |
|---|---|---|---|
| 1K | ~1024 | ~1820 | Miniaturas, portadas de feeds, redes sociales |
| 2K | ~2048 | ~3640 | Pósteres, imágenes principales de e-commerce, tarjetas |
| 4K | ~2880 | ~3840 | Impresión HD, material de video, materiales impresos |
Las 10 proporciones cubren necesidades comunes como 1:1, 16:9, 9:16, 4:3, 3:2, 21:9, etc., eliminando casi por completo la necesidad de recortes posteriores. Otro valor implícito del precio unificado es que puedes cambiar la resolución según las necesidades del negocio en tu flujo de producción sin afectar el modelo financiero; por ejemplo, al realizar pruebas A/B, puedes ejecutar la misma indicación en 1K y 4K para comparar, con costos totalmente predecibles.
Característica 2: Compatibilidad total con tres puntos finales
gpt-image-2-vip admite simultáneamente los tres puntos finales de imagen estándar de OpenAI: /v1/images/generations (texto a imagen), /v1/images/edits (imagen a imagen y edición) y /v1/chat/completions (generación mediante chat). Esto es fundamental, ya que significa que no necesitas reescribir tu código SDK existente; solo cambia el model de gpt-image-2 a gpt-image-2-vip y apunta la base_url al servicio proxy de API.
Característica 3: Fusión de múltiples imágenes e imagen a imagen
A través del punto final /v1/images/edits, puedes cargar de 1 a N imágenes y, junto con una indicación que describa la intención, el modelo realizará transferencia de estilo, fusión de contenido y reorganización de diseño. Por ejemplo, combinar una "imagen de producto + imagen de modelo + imagen de fondo" en una sola imagen principal para e-commerce. Se recomienda comprimir cada imagen a menos de 1.5 MB para evitar un aumento significativo en el consumo de tokens de entrada.
Característica 4: Comprensión nativa de chino
gpt-image-2-vip comparte el mismo backend de inferencia que el gpt-image-2 oficial, heredando la capacidad de renderizado de texto en chino, japonés, coreano, hindi y bengalí. No es necesario traducir las indicaciones al inglés; los títulos en chino y el texto de los botones en los pósteres se pueden recrear con precisión, algo que Midjourney o Stable Diffusion no logran hacer.
Característica 5: Las solicitudes fallidas no se cobran
Este es un detalle de facturación, pero tiene un gran impacto en el ahorro para la producción a gran escala. Cualquier solicitud que devuelva un error 5xx, tiempo de espera agotado o que sea interceptada por políticas de seguridad no se cobrará; solo se contabilizan las invocaciones que devuelven imágenes con éxito. Esto te permite implementar reintentos con retroceso exponencial sin miedo a que el costo de los reintentos dispare tu factura. Junto con el precio unificado de $0.03, la estimación de costos se vuelve extremadamente sencilla: si planeas generar 10,000 imágenes, el costo será de aproximadamente $300, sin necesidad de modelar por tamaño o calidad.
Flujo de invocación y ejemplo de código: empieza con 5 líneas de Python
La lógica de integración es muy directa y totalmente compatible con el SDK oficial de OpenAI; solo necesitas cambiar la base_url y el model. A continuación, presento un ejemplo mínimo ejecutable para la generación de imágenes, donde la base_url apunta al punto de entrada unificado del servicio proxy de API de APIYI (apiyi.com).
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2-vip",
prompt="Visual principal de una conferencia de tecnología en tonos oscuros, título central en neón 『APIYI · gpt-image-2 disponible』, texto pequeño en la esquina inferior izquierda 2026",
size="2048x1152"
)
img_b64 = resp.data[0].b64_json
with open("poster_2k.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Si deseas realizar una tarea de imagen a imagen o fusión de múltiples imágenes, simplemente cambia client.images.generate por client.images.edit y añade image=[open("a.png","rb"), open("b.png","rb")]. El formato del cuerpo de la solicitud para los tres endpoints sigue las especificaciones oficiales de OpenAI.
🎯 Consejo de inicio rápido: Si quieres probar este flujo en 30 segundos, te recomendamos crear primero una clave API en APIYI (apiyi.com) y luego generar una imagen de prueba usando
gpt-image-2-vipcon cualquier tamaño. Las solicitudes fallidas no se cobran, así que puedes depurar los parámetros con total tranquilidad.
Cómo elegir entre 30 tamaños: guía rápida por escenario
La primera reacción de muchos al ver 30 opciones de tamaño es "¿cuál elijo?". Hemos clasificado las opciones según el escenario de negocio. Un punto clave a tener en cuenta es: todos los tamaños tienen el mismo precio, por lo que puedes elegir según tus necesidades sin sacrificar la calidad por ahorrar costes.
| Escenario de negocio | Relación de aspecto | Resolución recomendada | Tamaño típico |
|---|---|---|---|
| Portada de artículo / Imagen destacada | 16:9 / 3:2 | 2K | 2048×1152 |
| Vertical para redes sociales | 9:16 / 4:5 | 2K | 1152×2048 |
| Imagen de producto / Página de detalles | 1:1 | 2K o 4K | 2048×2048 o 2880×2880 |
| Imagen Hero para web | 21:9 / 16:9 | 4K | 3840×1640 o 3840×2160 |
| Ilustración para diapositivas | 16:9 | 1K o 2K | 1820×1024 |
| Impresión / Póster | 3:4 / 2:3 | 4K | 2880×3840 |
| Miniatura de feed | 1:1 | 1K | 1024×1024 |
| Banner alargado | 21:9 | 1K | 1820×780 |
🎯 Consejo de selección de tamaño: Recomendamos priorizar el nivel 2K para entornos de producción; el peso de cada imagen es de aproximadamente 1-3 MB, logrando el mejor equilibrio entre velocidad de carga y efecto visual. Reserva el 4K solo para impresiones o pantallas grandes, y utiliza el 1K para miniaturas o escenarios de imágenes pequeñas.
Comparativa de los tres canales de la serie gpt-image-2: VIP / ALL / Oficial
En APIYI (apiyi.com) existen tres modelos relacionados con gpt-image-2. Es muy fácil equivocarse al elegir, así que vamos a aclarar las diferencias para evitar que tengas que rehacer tu integración más adelante.
gpt-image-2 (conexión directa oficial) utiliza la API pública de OpenAI, admite los parámetros quality y n, pero debes gestionar tú mismo el límite de velocidad de 5 RPM. gpt-image-2-all es un canal agregado que admite todos los parámetros, pero el tamaño se controla mediante la indicación (prompt) y es menos preciso. gpt-image-2-vip es el protagonista de este artículo; utiliza una ingeniería inversa oficial de codex y sus puntos fuertes son el bloqueo preciso de size + precios unificados + alto RPM.
| ID del modelo | Tipo de canal | Velocidad | Control de tamaño | Parámetro quality | Imágenes por solicitud | Escenario recomendado |
|---|---|---|---|---|---|---|
gpt-image-2 |
Conexión directa | Límite Tier | size preciso |
✅ | 1-4 | Sensible a niveles de calidad, llamadas de baja frecuencia |
gpt-image-2-all |
Canal agregado | Medio | Vía descripción prompt | ✅ | 1-4 | Migración de código antiguo, requiere parámetro quality |
gpt-image-2-vip |
Codex (inv. oficial) | Alto RPM | size preciso |
❌ | 1 | Producción masiva, tamaño fijo, prioridad estabilidad |

Decisión sencilla: Si buscas estabilidad a gran escala, tamaños fijos y facturación predecible, elige gpt-image-2-vip. Si necesitas usar quality=high para alta fidelidad, elige gpt-image-2-all. Solo considera gpt-image-2 si tienes llamadas de baja frecuencia y necesitas el conjunto completo de parámetros.
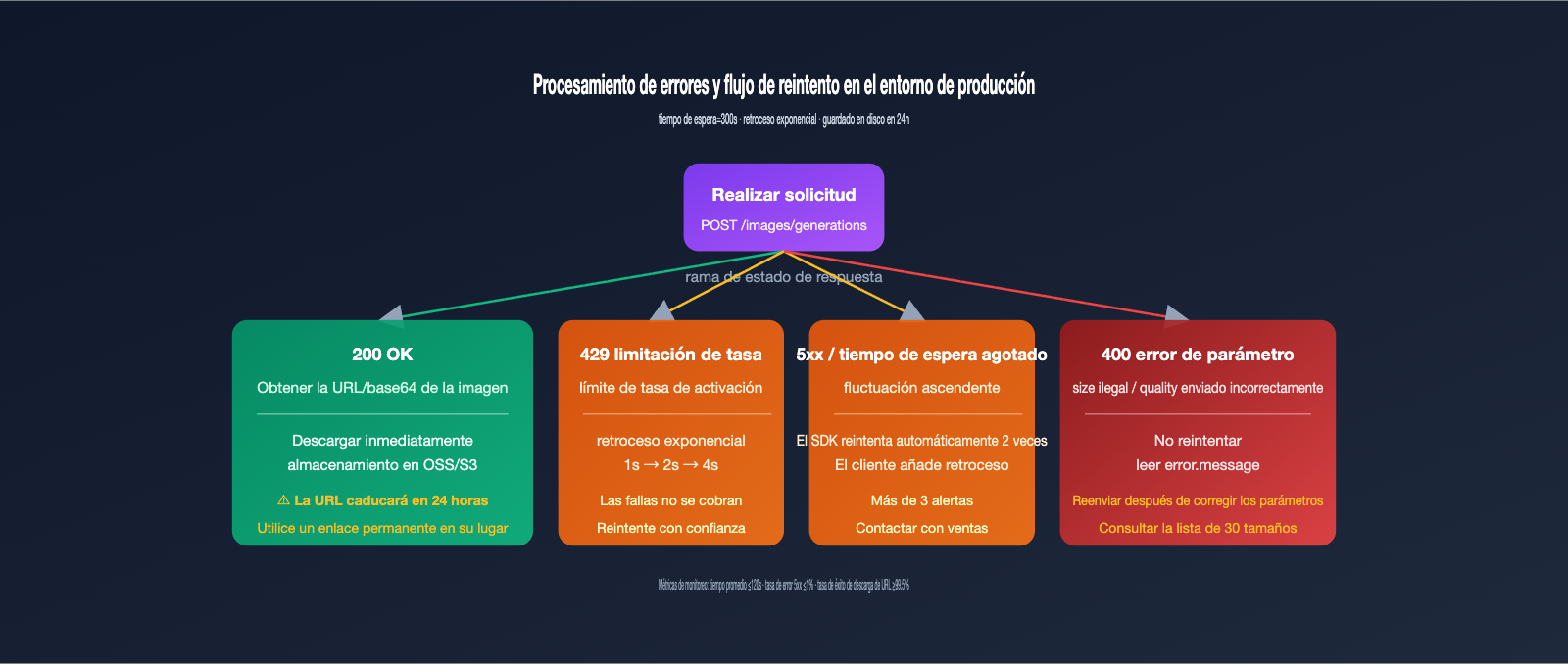
Mejores prácticas de estabilidad: tiempos de espera, reintentos y caducidad de URL
Aunque gpt-image-2-vip tiene una velocidad mayor que la oficial, el tiempo de generación es más largo: la inferencia oficial tarda entre 30 y 60 segundos, mientras que el canal VIP, al incluir una capa de proxy y reintentos, suele tardar entre 90 y 150 segundos. Tu código de producción debe configurarse considerando este tiempo, de lo contrario, sufrirás fallos masivos por tiempo de espera (timeout).
Práctica 1: Configurar el tiempo de espera en 300 segundos
El tiempo de espera predeterminado del SDK de OpenAI es de 60 segundos, lo cual es insuficiente para gpt-image-2-vip. Se recomienda pasar explícitamente timeout=300 al cliente. Algunas indicaciones complejas pueden acercarse a los 200 segundos, por lo que dejar un margen de 300 segundos es más seguro.
client = OpenAI(
api_key="tu-clave-apiyi",
base_url="https://api.apiyi.com/v1",
timeout=300,
max_retries=2
)
Práctica 2: Implementar retroceso exponencial para errores 5xx
Aunque la capa de proxy ya gestiona un reintento, añadir una capa adicional de retroceso exponencial (1s → 2s → 4s) en el cliente puede mejorar aún más la tasa de éxito. Las solicitudes fallidas no se cobran, lo que hace que los reintentos no tengan costo adicional.
Práctica 3: Descargar y guardar la URL devuelta en menos de 24 horas
La URL de la imagen devuelta por gpt-image-2-vip tiene una validez de aproximadamente 24 horas; después de eso, devolverá un error 404. Por lo tanto, una vez que obtengas la URL, descárgala inmediatamente a tu propio OSS/S3; no guardes esta URL directamente en tu base de datos para referencias a largo plazo. Para tareas por lotes, se recomienda completar la descarga dentro de los 5 minutos posteriores a la generación.
Práctica 4: Comprimir la imagen de entrada a menos de 1.5 MB
La interfaz /v1/images/edits procesa la imagen de entrada según su fidelidad, y los tokens de entrada están directamente relacionados con la cantidad de píxeles de la imagen. El consumo de tokens entre una imagen de referencia 4K y una de 1024px puede variar hasta 4 veces. Redimensiona en el cliente a un lado largo de 1024-2048 píxeles antes de subirla; esto ahorra dinero y acelera la inferencia.
Práctica 5: No bloquees con llamadas individuales, usa colas asíncronas
Dado que cada generación tarda entre 90 y 150 segundos, nunca utilices bucles síncronos para llamadas en serie, o 100 imágenes podrían tardar de dos a tres horas en procesarse. La práctica recomendada es enviar las solicitudes de generación a una cola de tareas asíncronas (Celery/asyncio); el hilo de negocio devuelve inmediatamente un ID de tarea, y el frontend consulta el resultado final mediante sondeo (polling) o WebSocket. Esto permite aprovechar al máximo el rendimiento de 60 RPM y explotar la alta concurrencia del canal VIP.
Tres escenarios prácticos de integración
Una vez explicada la teoría, veamos cómo poner en marcha gpt-image-2-vip en entornos de producción reales. Los siguientes tres escenarios son los que más nos consultan en el grupo de soporte, y verás que la estructura del código es bastante sencilla.
Escenario 1: Generación masiva de imágenes principales para e-commerce
Entrada: una imagen de producto con fondo blanco + un texto descriptivo. Salida: 30 imágenes principales con diferentes estilos. El flujo consiste en utilizar una plantilla de indicación fija, sustituyendo únicamente el marcador de posición de "estilo", y ejecutar 30 llamadas en lote a /v1/images/edits, fijando el tamaño de cada imagen en 2048x2048 (el estándar para e-commerce). El coste por 30 imágenes es de $0.9, con un tiempo total de ejecución de unos 2 minutos (con una concurrencia de 60 RPM).
Escenario 2: Localización de carteles multilingües
Entrada: una imagen base de un cartel en inglés + el texto en el idioma objetivo. Salida: versiones del cartel en chino, japonés y coreano. Aprovechando la capacidad de renderizado de texto multilingüe de gpt-image-2-vip, la indicación simplemente dice: "Cambia el título a 'Novedades', usa la fuente Source Han Sans y mantén el diseño original". Con una sola llamada obtienes la versión localizada, sin necesidad de editar en PSD.
Escenario 3: Pipeline de ilustraciones para diapositivas de PPT
Entrada: descripción de capítulos generada por un Modelo de Lenguaje Grande. Salida: una ilustración por página. Este es el núcleo de las herramientas de "PPT en un clic" que ves en TikTok. Se estandarizan todas las ilustraciones a 1820x1024 (proporción 16:9 estándar para PPT), la calidad se bloquea automáticamente en el canal VIP, y el coste por página es de $0.03; el coste total de ilustraciones para un PPT de 20 páginas es de solo $0.6. Sumando el coste del texto del Modelo de Lenguaje Grande, puedes producir un PPT completo por menos de $1.
La estructura técnica común para estos tres escenarios es: utilizar una cola de tareas para la programación en la capa externa, invocar gpt-image-2-vip en la capa interna y, una vez generada la imagen, guardarla inmediatamente en OSS. Para la visualización en el frontend, utiliza los enlaces permanentes de OSS en lugar de las URL temporales de 24 horas que devuelve el modelo.
Errores comunes y solución de problemas
La siguiente tabla cubre los tipos de errores más frecuentes reportados en nuestros grupos de soporte. Si la consultas, podrás resolver el 90% de los problemas de integración directamente.
| Fenómeno de error | Causa raíz | Solución |
|---|---|---|
| Tiempo de espera 408 / 504 | El timeout es demasiado corto | Ajusta el timeout a 300 segundos |
| 400 invalid size | El size no está entre los 30 permitidos | Usa los tamaños estándar listados en la documentación |
| 400 unsupported_parameter | Se enviaron quality o n>1 |
El canal VIP no los admite; elimina estos campos |
| URL de imagen 404 | La URL expiró tras 24 horas | Descarga la imagen a tu propio almacenamiento inmediatamente después de generarla |
| Caracteres chinos ilegibles o cuadros | La indicación contiene caracteres muy raros | Usa caracteres comunes o especifica en la indicación "usar fuente Source Han Sans" |
| input_tokens mayor a lo esperado | La imagen de referencia es muy pesada | Comprime la imagen en el cliente a menos de 1.5 MB |
Preguntas frecuentes (FAQ)
P1: ¿Hay diferencia en la calidad de imagen entre gpt-image-2-vip y la oficial?
El modelo subyacente es exactamente el mismo, ambos usan la instantánea gpt-image-2-2026-04-21. La única diferencia radica en la ruta de enrutamiento: la oficial utiliza el pool de cuotas de API, mientras que la VIP utiliza el pool de cuotas de Codex. No hay diferencia en la calidad visual de las imágenes; en pruebas ciegas a gran escala, es imposible distinguirlas.
P2: ¿Por qué no se admite el parámetro quality?
La llamada interna de la CLI de Codex utiliza una estrategia fija de quality=high. El canal VIP reutiliza esta ruta, por lo que no es posible exponer la opción de calidad a la capa superior. Si tu negocio realmente necesita reducir costos con niveles low/medium, utiliza gpt-image-2-all.
P3: ¿Realmente no se cobra por las solicitudes fallidas?
Así es. La política de facturación de APIYI (apiyi.com) es "cobro por respuesta exitosa". Los errores de parámetros 4xx, los errores de servicio 5xx y los tiempos de espera no se contabilizan en el consumo. Puedes verificar esto punto por punto en tu factura.
P4: ¿Se puede invocar directamente desde servidores en China?
Sí. El dominio api.apiyi.com utiliza una ruta de cumplimiento local, por lo que no necesitas una VPN. Esta es una de las razones principales por las que muchos equipos eligen nuestro servicio proxy de API.
P5: ¿Cuál es el límite de RPM del canal VIP?
No hay un límite estricto publicado; en la práctica, depende del nivel de saturación del pool de cuentas. Por lo general, las empresas pueden alcanzar de forma estable entre 60 y 120 RPM, mucho más que los 5 RPM del nivel Tier 1 oficial. Si necesitas una concurrencia mayor, contacta con ventas para habilitar el acceso.
P6: Solo devuelve una imagen por vez, ¿qué hago para procesar por lotes?
Simplemente realiza llamadas concurrentes en un bucle desde el lado del cliente. Con asyncio.gather o concurrent.futures.ThreadPoolExecutor de Python, puedes alcanzar fácilmente los 60 RPM. Dado que el canal VIP utiliza inferencia asíncrona, la concurrencia no está limitada por la CPU, el cuello de botella es únicamente el RPM de la capa de proxy.
P7: ¿Los resultados serán iguales si uso la misma indicación varias veces?
No serán exactamente iguales. gpt-image-2-vip utiliza la estrategia interna de Codex y no expone el parámetro seed, por lo que cada generación tiene un componente de aleatoriedad. Si tu negocio requiere resultados reproducibles, puedes hacer que la indicación sea muy específica (por ejemplo, fijando códigos de color o descripciones de composición precisas), o bien, tomar la primera imagen satisfactoria y pasarla como imagen de referencia al endpoint /v1/images/edits para realizar ajustes.
P8: ¿Cómo monitorear la estabilidad en el entorno de producción?
Recomendamos realizar un seguimiento de tres métricas en el cliente: tiempo promedio de generación, tasa de error 5xx y tasa de éxito en la descarga de URLs. En condiciones normales, el tiempo promedio debe ser inferior a 120 segundos, la tasa de error 5xx debe ser <1% y la tasa de éxito de descarga de URLs >99.5%. Si alguna de estas métricas es anormal, indica que el nivel del pool de cuentas es bajo y debes contactar con el equipo de ventas para asignar más recursos.
Resumen
gpt-image-2-vip es un producto comercial de generación de imágenes basado en el canal inverso oficial de Codex. Sus 5 características principales resuelven uno a uno los puntos de dolor de la conexión directa oficial: 30 tipos de dimensiones + facturación unificada de $0.03 + compatibilidad con tres endpoints + soporte nativo para chino + sin cargos por fallos. Para equipos dedicados a la creación de contenido, materiales de comercio electrónico, automatización de presentaciones (PPT) y generación masiva de carteles, esta es actualmente una de las soluciones de acceso a gpt-image-2 con mejor relación calidad-precio.
Para realizar la integración, solo necesitas modificar base_url y model; el código del SDK reutiliza completamente la sintaxis oficial de OpenAI. Para entornos de producción, recomendamos establecer el timeout en 300 segundos, implementar retroceso exponencial para errores 5xx y guardar las URLs de las imágenes en disco dentro de las primeras 24 horas. Si evitas estos tres errores comunes, podrás escalar el volumen de forma estable. Si estás evaluando una solución de acceso a gpt-image-2 para producción, puedes crear una cuenta directamente en APIYI (apiyi.com) y probar el canal VIP con datos reales de tu negocio antes de tomar una decisión.
Sobre el autor: El equipo de APIYI se especializa en la integración de modelos agregados y en infraestructura de inferencia de alta concurrencia, gestionando diariamente numerosas consultas sobre la integración de API de generación de imágenes. Este artículo ha sido elaborado basándose en datos de producción reales. Si deseas conocer los parámetros detallados de gpt-image-2-vip, puedes visitar docs.apiyi.com.