
Anmerkung des Autors: Dieser Artikel erläutert systematisch das tatsächliche Prinzip der Bild-Layering-Funktion von gpt-image-2, die Phänomene bei der Python-Backend-Verarbeitung, die API-Aufrufmethoden und Strategien zur Kostenoptimierung. Ziel ist es, Entwicklern dabei zu helfen, die Fähigkeiten der Toolchain nicht fälschlicherweise als native Modellfähigkeiten zu interpretieren.
Wenn Sie in letzter Zeit gpt-image-2 für Poster, wissenschaftliche Grafiken, Produktbilder oder Präsentationen verwendet haben, ist Ihnen vielleicht ein interessantes Phänomen aufgefallen: Manche behaupten, es könne „Bilder in Ebenen zerlegen“ oder sogar im Backend mittels Python ein Bild in bearbeitbare Objekte aufteilen.
Auf den ersten Blick sieht es so aus, als hätte das Modell plötzlich Photoshop gelernt, aber tatsächlich handelt es sich eher um einen Workflow mit mehreren Toolchains: gpt-image-2 ist für die Erstellung oder Bearbeitung hochwertiger Bilder zuständig, während Python-Skripte die Nachbearbeitung wie OCR, Hintergrundreparatur, Elementsegmentierung sowie die Rekonstruktion von SVG/PPTX/PSD übernehmen.
Dies ist kein weiterer Einführungskurs, sondern eine vollständige Analyse der Bild-Layering-Funktion von gpt-image-2 aus der Perspektive von API-Fähigkeiten, Layer-Prinzipien, Python-Nachbearbeitung, Kostenkalkulation und technischer Implementierung – was möglich ist und was nicht.
Kernnutzen: Nach dem Lesen dieses Artikels kennen Sie die Grenzen der Bild-Layering-Funktion von gpt-image-2, wissen, wie Sie die offizielle gpt-image-2-API über APIYI (apiyi.com) einbinden und einen produktionsreifen Workflow von der „Bilderzeugung bis zum bearbeitbaren Material“ entwerfen.
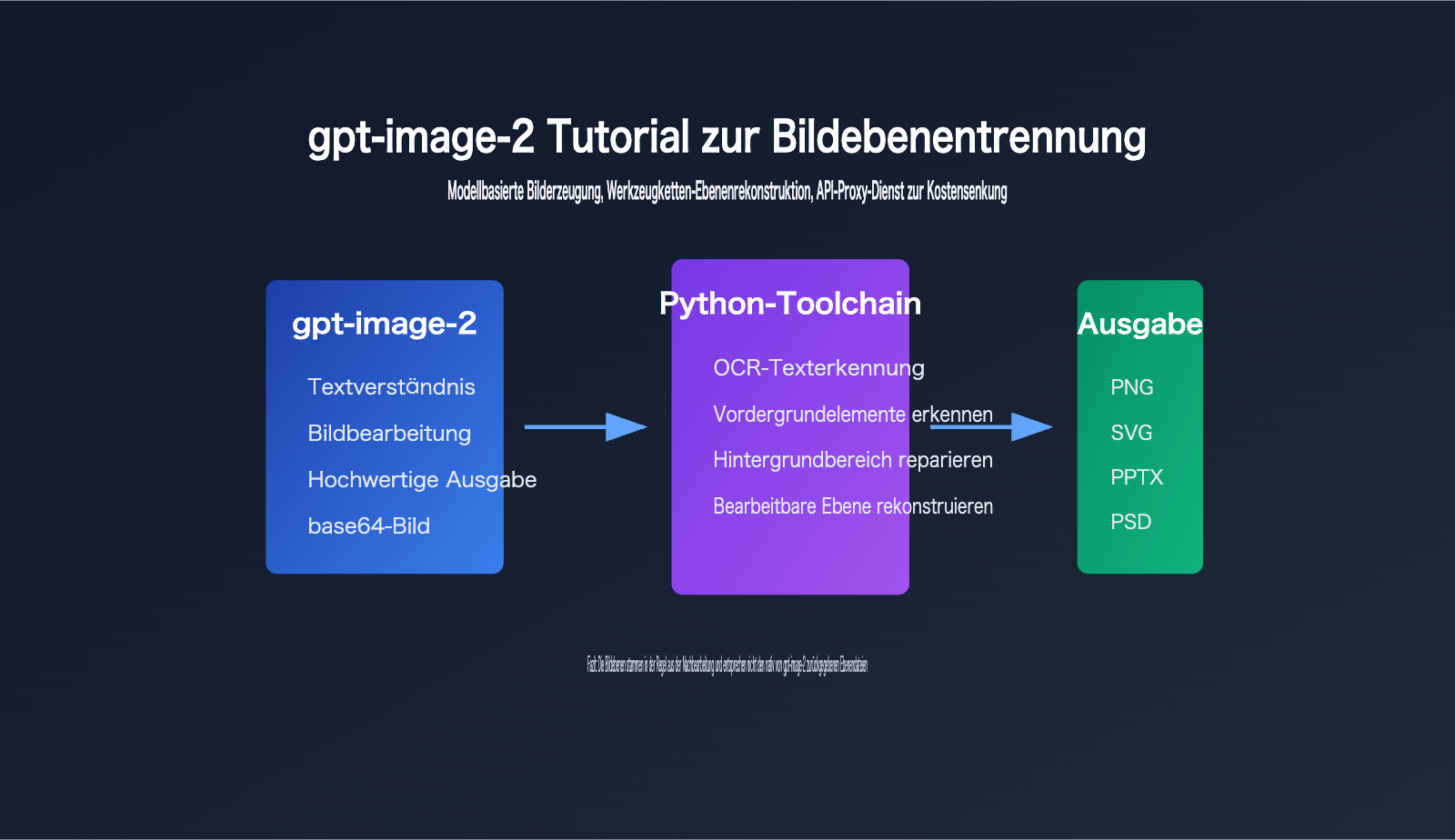
Kernpunkte der Bild-Layering-Funktion von gpt-image-2
Der Schlüssel zum Bild-Layering bei gpt-image-2 liegt in der Unterscheidung zwischen „Modellausgabe“ und „Output des Produkt-Workflows“.
Die offizielle Modellseite von OpenAI definiert gpt-image-2 als Bildmodell für die schnelle, hochwertige Bilderzeugung und -bearbeitung, das Texteingaben, Bildeingaben und Bildausgaben unterstützt und für die Generierungs- und Bearbeitungs-Endpunkte der Images API verwendet werden kann.
Aus der aktuellen öffentlichen API-Form geht jedoch hervor, dass das Hauptergebnis, das Entwickler erhalten, immer noch Bilddaten sind und keine Photoshop-ähnlichen, mehrschichtigen Projektdateien.
| Punkt | Erläuterung | Wert für Entwickler |
|---|---|---|
| Native Modellfähigkeit | gpt-image-2 versteht Eingabeaufforderungen, Referenzbilder und Bearbeitungsabsichten und gibt das finale Bild aus | Geeignet für die Erstellung von Postern, Produktbildern, Illustrationen und Entwürfen |
| API-Output-Format | Die offizielle Dokumentation konzentriert sich auf Felder wie b64_json, Bildformat, Größe, Qualität und Token-Verbrauch |
Erleichtert serverseitiges Speichern, Hochladen, Auditierung und Abrechnung |
| Quelle des Bild-Layering | Die meisten bearbeitbaren Ebenen stammen aus Nachbearbeitungen wie OCR, Segmentierung, Inpainting, Vektorisierung, PPTX/PSD-Schreiben | Erklärt, „warum im Backend Python läuft“ |
| Kostenoptimierung | Die offizielle API-Proxy-Dienst-Anbindung ermöglicht den Zugriff zum offiziellen Originalpreis, kombiniert mit Aufladeboni zur Senkung der tatsächlichen Kosten | Ideal für Batch-Generierung, Tests und Produktionsintegration |
Bild-Layering bei gpt-image-2 ist keine native PSD-Ausgabe
Ein häufiges Missverständnis beim Bild-Layering von gpt-image-2 ist die Annahme, dass die „vom Endbenutzer bearbeitbare Datei“ direkt vom Modell ausgegeben wird.
Technisch gesehen sind dies zwei völlig verschiedene Dinge.
Das Modell gibt direkt ein Bild aus, das der Anwendung normalerweise als Base64-Bilddaten oder Bilddatei übermittelt wird.
Wenn ein Produkt daraus eine PPTX-, SVG- oder PSD-Datei machen kann, deutet dies darauf hin, dass das Produkt eine Nachbearbeitungsschicht hinter dem Modell hinzugefügt hat.
Diese Schicht wird wahrscheinlich mit Python implementiert, da Python über ein ausgereiftes Ökosystem für Bildverarbeitung, OCR, Deep-Learning-Inferenz und die Erstellung von Office-Dokumenten verfügt.
Ingenieure könnten beispielsweise zuerst Text mittels OCR erkennen, dann den Textbereich im Originalbild mittels Inpainting bereinigen und anschließend mit python-pptx Textfelder und Bildebenen rekonstruieren.
Solche Abläufe vermitteln dem Benutzer das Gefühl, dass das „Bild in Ebenen zerlegt wurde“, aber im Wesentlichen wird die bearbeitbare Struktur aus einem flachen Bild zurückentwickelt.
Diese Rückentwicklung ist nicht immer perfekt.
Je klarer der Text, je einfacher der Hintergrund und je regelmäßiger das Layout, desto besser ist das Layering-Ergebnis.
Wenn das Bild komplexe Texturen, halbtransparente Schatten, handschriftlichen Text, feine Dekorationen oder stark überlappende Objekte enthält, kommt es bei der Nachbearbeitung leicht zu Fehlern, Lücken oder Kantenartefakten.
Bild-Layering bei gpt-image-2: Achten Sie auf die Grenze zwischen Modell und Toolchain
Bei der Entwicklung von Bild-Layering-Lösungen für gpt-image-2 sollten Entwickler das System in zwei Teile gliedern.
Der erste Teil ist die Generierungsphase: Hier soll gpt-image-2 Bilder mit ausreichend hoher visueller Qualität, klarer Struktur und möglichst präzisem Text ausgeben.
Der zweite Teil ist die Strukturierungsphase: Hier werden Python oder andere Nachbearbeitungstools verwendet, um das flache Bild in bearbeitbare Objekte umzuwandeln.
Beide Phasen haben unterschiedliche Ziele und erfordern unterschiedliche Bewertungskriterien.
In der Generierungsphase liegt der Fokus auf der Einhaltung der Eingabeaufforderung, der Komposition, der Textgenauigkeit, der Bildkonsistenz und den Kosten.
In der Strukturierungsphase liegt der Fokus auf der Editierbarkeit des Textes, der Genauigkeit der Objekttrennung, der Natürlichkeit der Hintergrundreparatur, der Kompatibilität der Exportdateien und dem Aufwand für manuelle Korrekturen.
Technischer Hinweis: Wenn Sie den Bild-Layering-Workflow von gpt-image-2 validieren möchten, empfiehlt es sich, zunächst über APIYI (apiyi.com) die offizielle gpt-image-2-API für die Generierung und Bearbeitung einzubinden und dann schrittweise OCR-, Segmentierungs-, Reparatur- und Exportmodule hinzuzufügen. Auf diese Weise lassen sich Modellprobleme und Nachbearbeitungsprobleme getrennt voneinander analysieren.
Wie die Bildschichtung bei gpt-image-2 funktioniert
Die Bildschichtung bei gpt-image-2 lässt sich als „Reverse Engineering von flachen Bildern zu strukturierten Assets“ verstehen.
Es handelt sich nicht nur um einfaches Freistellen, sondern um einen vollständigen Prozess, der visuelles Verständnis, klassische Bildverarbeitung und Dokumentengenerierung kombiniert.
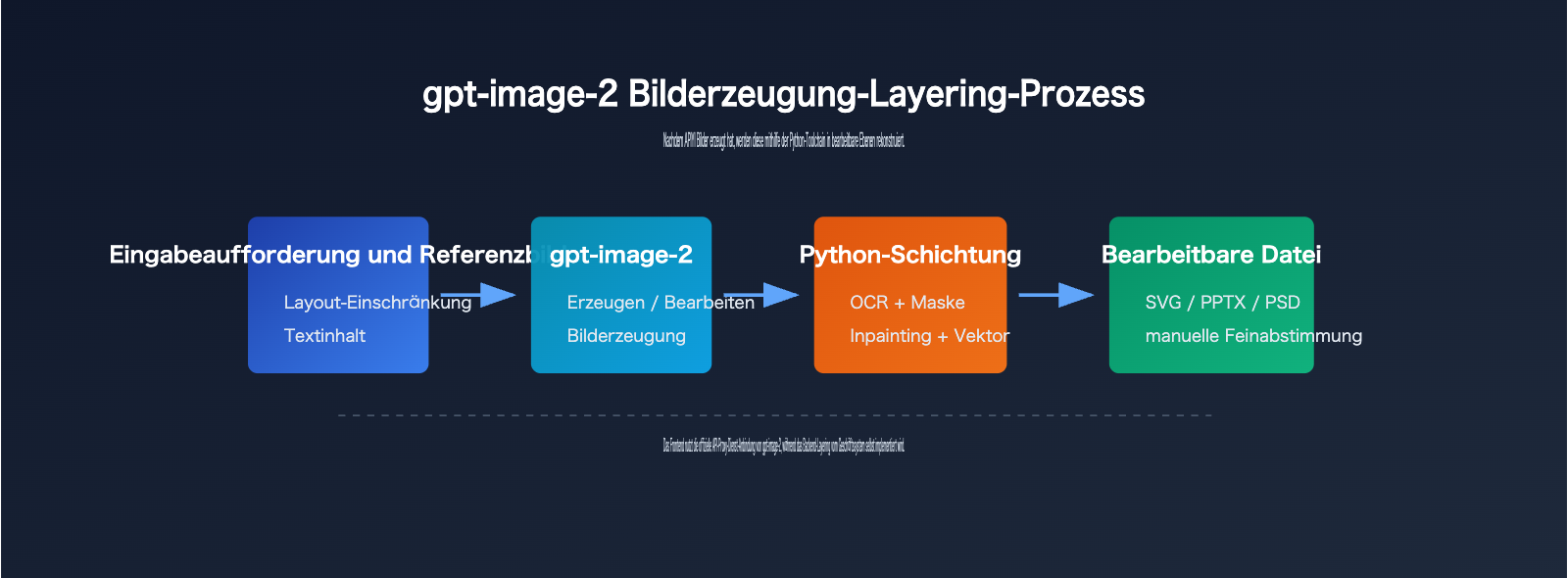
Schritt 1 der gpt-image-2 Bildschichtung: Generierung eines schichtbaren Bildes
Damit die Bildschichtung bei gpt-image-2 stabiler funktioniert, muss die Generierungsphase bereits auf die Nachbearbeitung ausgerichtet sein.
Die Eingabeaufforderung sollte explizit ein klares Layout, definierte Elementgrenzen, separate Textbereiche und keine zu komplexen Hintergrundtexturen fordern.
Wenn das Ziel PPTX oder SVG ist, empfiehlt sich ein flaches Design, klare Farbflächen sowie sparsamer Einsatz von Schatten und Verläufen.
Für PSD-Dateien sollten die Beziehungen zwischen Hauptmotiv, Hintergrund, Text und dekorativen Elementen klar beschrieben werden.
Ein häufiger Fehler ist es, das Modell komplexe Filmplakate generieren zu lassen und dann zu erwarten, dass Nachbearbeitungstools automatisch perfekte Ebenen extrahieren.
Dies ist unter den aktuellen technischen Bedingungen nicht realistisch.
Der Schichtungseffekt hängt stark von der Analysierbarkeit des Eingabebildes ab.
Schritt 2 der gpt-image-2 Bildschichtung: Erkennung von Text und Objekten
Die häufigste erste Aufgabenkategorie im Python-Backend ist die Erkennung.
Die Texterkennung nutzt normalerweise OCR-Modelle, um Zeicheninhalte, Positionen, Schriftgrößen und Textrahmenbegrenzungen zu identifizieren.
Die Objekterkennung oder -segmentierung identifiziert visuelle Objekte wie Personen, Produkte, Symbole, Linien und Hintergrundbereiche.
Bei Folien oder Infografiken können zusätzlich Titel, Absätze, Tabellen, Pfeile, Achsen und Legenden erkannt werden.
Diese Ebene ist nicht etwas, das gpt-image-2 „von sich aus als Ebenen zurückgibt“, sondern das Nachbearbeitungsmodell leitet die Ebenen aus den Pixeln ab.
Je präziser die Schlussfolgerung, desto eher entsprechen die exportierten PPTX-, SVG- oder PSD-Dateien dem ursprünglichen Designentwurf.
Bei ungenauen Schlussfolgerungen treten häufig Probleme wie verschobene Textrahmen, inkonsistente Schriftarten, sichtbare Reparaturspuren im Hintergrund oder zerstückelte Symbole auf.
Schritt 3 der gpt-image-2 Bildschichtung: Hintergrundreparatur und Dateirekonstruktion
Nachdem die OCR Textbereiche identifiziert hat, müssen diese aus dem Originalbild entfernt werden, um den Text bearbeitbar zu machen.
Nach dem Entfernen des Textes entstehen Lücken im Hintergrund.
Hier kommen Inpainting- oder Bildreparaturalgorithmen zum Einsatz, um den Hintergrund zu vervollständigen.
Anschließend schreibt das System den erkannten Text als unabhängige Textrahmen zurück in die PPTX-, SVG- oder PSD-Datei.
Für detailliertere Objektebenen muss zudem eine Maske für die Vordergrundelemente generiert werden, um das Objekt freizustellen und in eine separate Ebene zu schreiben.
Dieser Ablauf klingt, als würde „das Modell schichten“, aber präzise ausgedrückt ist es: „Modell generiert Bild + Python analysiert Bild + Dokumentenbibliothek rekonstruiert Ebenen“.
Schnelleinstieg in die gpt-image-2 Bildschichtung
Hier ist eine minimale Kette für die Bildschichtung mit gpt-image-2 für Entwickler.
Schritt 1: Bild über die API abrufen.
Schritt 2: Bild als lokale Datei speichern.
Schritt 3: An OCR-, Segmentierungs-, Reparatur- und Exportmodule übergeben.
Minimales API-Beispiel für die gpt-image-2 Bildschichtung
Das folgende Beispiel zeigt den Aufruf der gpt-image-2 API über eine einheitliche Schnittstelle.
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
result = client.images.generate(
model="gpt-image-2",
prompt="Generiere ein Produkt-Launch-Plakat, das für die spätere Schichtung geeignet ist, einfarbiger Hintergrund, klarer Textbereich, definierte Elementgrenzen",
size="1024x1024",
quality="medium",
output_format="png"
)
image_bytes = base64.b64decode(result.data[0].b64_json)
open("poster.png", "wb").write(image_bytes)
Der Fokus dieses Codes liegt nicht darauf, „sofort eine PSD zu erhalten“, sondern zunächst ein klares Bild für die Nachbearbeitung zu generieren.
Wenn Sie sehen, dass der Server weiterhin Python-Skripte aufruft, bedeutet dies meist, dass die OCR-, Maskierungs-, Inpainting- oder Exportphase begonnen hat.
Grundgerüst für die vollständige gpt-image-2 Bildschichtung
Hier ist ein Gerüst, das einem realen Projekt näher kommt.
Es ist nicht an ein spezifisches OCR- oder Segmentierungsmodell gebunden und zeigt lediglich die Modulgrenzen.
from pathlib import Path
def generate_image(prompt: str) -> Path:
"""Aufruf der gpt-image-2 API, Speichern des flachen Bildes."""
# client = OpenAI(api_key="YOUR_APIYI_KEY", base_url="https://vip.apiyi.com/v1")
# response = client.images.generate(model="gpt-image-2", prompt=prompt)
return Path("poster.png")
def detect_layout(image_path: Path) -> dict:
"""OCR, Objekterkennung, Layout-Erkennung."""
return {"texts": [], "objects": [], "background_regions": []}
def rebuild_editable_file(image_path: Path, layout: dict) -> Path:
"""Hintergrund reparieren und als SVG, PPTX oder PSD exportieren."""
return Path("poster-editable.pptx")
prompt = "Generiere ein KI-Produktplakat mit klarem Text, getrennten Elementen, geeignet für die schichtweise Bearbeitung"
image_path = generate_image(prompt)
layout = detect_layout(image_path)
editable_path = rebuild_editable_file(image_path, layout)
print(editable_path)
In Produktionsumgebungen empfiehlt es sich, generate_image und rebuild_editable_file als asynchrone Aufgaben zu trennen.
Die Bildgenerierung selbst kann Zeit in Anspruch nehmen, und die Nachbearbeitung verbraucht CPU- oder GPU-Ressourcen.
Für Teams, die massenhaft Plakate, Produktbilder oder wissenschaftliche Grafiken erstellen, sollten API-Aufrufe und Nachbearbeitungsaufgaben in eine Warteschlange eingereiht werden, wobei Zeitaufwand und Fehlerursachen für jeden Schritt protokolliert werden sollten.
Tipp für den Schnelleinstieg: Die gpt-image-2 API von APIYI (apiyi.com) eignet sich hervorragend, um die Generierungsphase zu durchlaufen, bevor Sie Ihre eigenen Python-Schichtungsmodule anschließen. So behalten Sie die volle Leistung des offiziellen Modells und gleichzeitig die Kontrolle über die Logik der bearbeitbaren Dateien in Ihrem eigenen System.
Prompt-Vorlage für die gpt-image-2 Bildschichtung
Wenn das Endziel „schichtbar“ ist, sollten die Eingabeaufforderungen zurückhaltender sein als bei normaler Text-zu-Bild-Generierung.
| Ziel | Empfohlene Prompt-Schreibweise | Nicht empfohlene Schreibweise |
|---|---|---|
| Plakatschichtung | Hintergrund einfarbig oder einfacher Verlauf, Titeltext isoliert, Produktkanten klar | Komplexe filmreife Plakate mit vielen Texturen und Rauch |
| PPT-Schichtung | Flacher Infografik-Stil, klare Titel, Symbole, Pfeile und dreiteilige Erklärungen | Künstlerisch abstrakte Visualisierungen |
| Produktschichtung | Produkt in der Bildmitte, sauberer Hintergrund, weicher Schatten, klare Grenzen | Produkt stark mit dem Hintergrund verschmolzen |
| SVG-Rekonstruktion | Geometrische Formen, Linien, Farbflächen, wenig Text, keine Fototexturen | Viele feine Texturen, komplexe Personen und transparente Materialien |
Gute Eingabeaufforderungen reduzieren den Aufwand der Nachbearbeitung erheblich.
Aus technischer Sicht sind „geeignet für die Generierung“ und „geeignet für die Schichtung“ nicht dasselbe Ziel.
Normale Nutzer wollen visuelle Wirkung, Schichtungssysteme benötigen eine klare Struktur.
Wenn Sie eine automatisierte Asset-Produktion aufbauen, sollten Sie der klaren Struktur den Vorzug geben.
Analyse des Python-Backends bei der Bildschichtung von gpt-image-2
Wenn Benutzer sehen, dass Python im Hintergrund die Bildschichtung von gpt-image-2 verarbeitet, gibt es dafür meist drei Gründe.
Der erste Grund sind API-Wrapper-Skripte.
Um redundanten Code zu vermeiden, schreiben Entwickler Python-Skripte, die gpt-image-2 aufrufen, Bilder automatisch speichern, Parameter protokollieren sowie Fehler und Wiederholungsversuche verwalten.
Diese Skripte bedeuten nicht, dass das Modell intern mit Python läuft.
Der zweite Grund sind Skripte zur Bildnachbearbeitung.
Hierbei wird das ausgegebene Bild beispielsweise an OCR-Tools, Segmentierungsmodelle, Hintergrund-Inpainting-Modelle, Vektorisierungstools oder Bibliotheken zur Erstellung von PPTX/PSD-Dateien übergeben.
Solche Skripte sind die eigentliche Quelle für den „Schichtungseffekt“.
Der dritte Grund sind Agent-Workflow-Skripte.
Wenn Benutzer die Bilderzeugung über ChatGPT, Codex, Claude Code oder andere Agent-Tools aufrufen, wählt der Agent möglicherweise automatisch ein Python-Tool aus, um Downloads, Konvertierungen, Zuschnitte, Collagen oder Dateigenerierungen durchzuführen.
Dies ist jedoch weiterhin ein Tool-Aufruf auf Produktebene und keine native Rückgabe mehrerer Ebenen durch die gpt-image-2-API.
Warum Python für die gpt-image-2-Bildschichtung so beliebt ist
Python eignet sich hervorragend für die gpt-image-2-Bildschichtung – nicht weil es mysteriös wäre, sondern wegen seines vollständigen Ökosystems.
| Verarbeitungsschritt | Typische Python-Aufgabe | Nutzen |
|---|---|---|
| API-Aufruf | Images-API aufrufen, Base64-Bilder speichern, Anfrageparameter protokollieren | Stabile Bilderzeugung |
| OCR | Textinhalt, Position und Textfelder erkennen | Bildtext in editierbaren Text umwandeln |
| Segmentierung | Masken für Subjekt, Hintergrund, Symbole und Linien erstellen | Visuelle Objekte trennen |
| Inpainting | Hintergrund nach dem Löschen von Text oder Objekten vervollständigen | Saubere Basisebene erzeugen |
| Export | In SVG, PPTX, PSD oder andere Formate schreiben | Bereitstellung editierbarer Dateien |
Der Vorteil dieser Kette ist die Flexibilität.
Entwickler können je nach Geschäftsszenario verschiedene OCR-Modelle, Segmentierungsmodelle und Exportformate wählen.
Der Nachteil ist, dass die Ergebnisstabilität nicht allein von gpt-image-2 abhängt.
Wenn die OCR Zeichen falsch erkennt oder das Inpainting des Hintergrunds fehlschlägt, wird die endgültige editierbare Datei fehlerhaft sein, selbst wenn die Qualität des Originalbildes hervorragend war.
gpt-image-2-Bildschichtung ist nicht mit „Layers“ in Sicherheitsrichtlinien zu verwechseln
Ein weiterer Begriff, der oft für Verwirrung sorgt, ist „Layers“.
In den Sicherheitsunterlagen von OpenAI ist häufig von image input layers, image output layers oder multiple layers of protection die Rede.
Diese „Layers“ beziehen sich auf Sicherheitsebenen, Eingabe-/Ausgabeprüfungen oder Schutzschichten, nicht auf Photoshop-Ebenen.
Wenn man im Englischen nur das Wort „layers“ sieht und es direkt als „Bildebene“ übersetzt, führt dies leicht zu Fehlinterpretationen.
Bei der technischen Auswahl empfiehlt es sich, immer auf die API-Felder und das Ausgabeformat zu schauen.
Wenn die Schnittstelle keine Ebenenliste, Maskenliste, Objektstruktur oder PSD-Datei zurückgibt, kann sie nicht als native Schnittstelle für Bildschichtung betrachtet werden.
Kriterien für die Zuverlässigkeit der gpt-image-2-Bildschichtung
Um zu beurteilen, ob eine Lösung zur gpt-image-2-Bildschichtung zuverlässig ist, können vier Indikatoren herangezogen werden:
Erstens: Wird klar zwischen der Ausgabe des Originalbildes und der Ausgabe der Nachbearbeitung unterschieden?
Zweitens: Kann die Herkunft jeder Ebene nachgewiesen werden, z. B. OCR-Textebene, Hintergrundebene, Vordergrundobjektebene?
Drittens: Erlaubt das System manuelle Korrekturen?
Viertens: Kann das Schichtungsergebnis für dasselbe Bild reproduziert werden?
Wenn ein System nur von „automatischer KI-Schichtung“ spricht, ohne die Logik für OCR, Masken, Inpainting und Export zu erläutern, sollten Entwickler vorsichtig sein.
Empfehlung: In realen Projekten können Sie die stabile Generierungsleistung von gpt-image-2 über offizielle Kanäle beziehen und die Python-Schichtungslogik als internen Dienst implementieren. So nutzen Sie die offizielle Leistung, ohne die Nachbearbeitung als Blackbox an ein einzelnes Tool zu binden.
Kosten der gpt-image-2-Bildschichtungs-API und Rabattkalkulation
Die Kosten für die gpt-image-2-Bildschichtung müssen differenziert betrachtet werden.
Die Modellgenerierung ist nur ein Teil der Kosten.
OCR, Segmentierung, Inpainting, Export und Speicherung bilden einen weiteren Teil.
Wer nur auf die Kosten pro „generierter editierbarer Datei“ schaut, verschätzt sich leicht beim Budget.
Offizielle Preisreferenz für gpt-image-2
Laut der offiziellen API-Preisliste von OpenAI umfasst die Preisstruktur für gpt-image-2 Bildeingaben, zwischengespeicherte Bildeingaben, Bildausgaben, Texteingaben und zwischengespeicherte Texteingaben.
| Kostenpunkt | Offizielle Preisstruktur | Bedeutung bei der Bildschichtung |
|---|---|---|
| Image input | 8,00 USD / 1 Mio. Token | Entsteht bei Eingabe von Referenz-, Bearbeitungs- oder Materialbildern |
| Cached image input | 2,00 USD / 1 Mio. Token | Kosten für wiederverwendbare, zwischengespeicherte Bildeingaben |
| Image output | 30,00 USD / 1 Mio. Token | Hauptkosten für die Bildausgabe selbst |
| Text input | 5,00 USD / 1 Mio. Token | Eingabeaufforderung, Bearbeitungsanweisungen, Layout-Vorgaben |
| Cached text input | 1,25 USD / 1 Mio. Token | Optimierungspotenzial für zwischengespeicherte Eingabeaufforderungen |
Die offiziellen Preise bilden die Grundlage für die Budgetierung.
In realen Projekten müssen jedoch auch Fehlerwiederholungen, Batch-Warteschlangen, Rechenleistung für die Nachbearbeitung, manuelle Abnahmen und Speicherkosten berücksichtigt werden.
Wenn Sie häufig verschiedene Posterversionen generieren müssen, sollten Sie die Kosten durch Optimierung der Eingabeaufforderung, Größe, Qualität und Wiederholungsstrategien kontrollieren.
Kostenkalkulation bei Nutzung der offiziellen API-Proxy-Dienste für gpt-image-2
Der API-Proxy-Dienst von APIYI (apiyi.com) für gpt-image-2 ermöglicht den Zugriff zum offiziellen Preismodell. Dies ist ideal für Teams, die den offiziellen Modellkanal beibehalten und gleichzeitig die Komplexität der Anbindung reduzieren möchten.
Die vom Benutzer erwähnte Aufladeaktion lautet: Bei einer Aufladung von 100 USD gibt es 10 % Guthaben dazu.
Bei einer strengen Berechnung von „100 USD einzahlen, 110 USD verfügbares Guthaben erhalten“ entsprechen die effektiven Stückkosten etwa 90,9 % des offiziellen Preises.
Unter Berücksichtigung der Plattformaktionen und der kombinierten Rabattstruktur kann dies nach außen hin als ein Rabattbereich von etwa 14 % (entspricht ca. 86 % des Preises) verstanden werden, wobei die tatsächliche Gutschrift und die Abrechnungsregeln der Plattform maßgeblich sind.
| Anbindungsmethode | Preisbasis | Vorteile | Hinweise |
|---|---|---|---|
| Offizielle OpenAI-API | Offizieller Preis | Nativer Kanal, vollständige Dokumentation | Kontoverwaltung, Zahlung, Limits und Risikomanagement in Eigenregie |
| gpt-image-2 API-Proxy | Offizieller Preis | Schnelle Anbindung, einheitliche Schnittstelle, einfache Verwaltung | Aufladung und Abrechnung gemäß Plattformregeln |
| Aufladeaktion | 100 USD laden, 10 % dazu | Senkt die tatsächlichen Stückkosten | Rabatt hängt von der tatsächlichen Gutschrift ab |
| Selbstgebaute Lösung | Variabel | Hohe Flexibilität | Höhere Anforderungen an Compliance, Stabilität und Wartung |
Kostentipp: Wenn Sie einen Produkttest für die gpt-image-2-Bildschichtung durchführen, empfiehlt es sich, zunächst 50 bis 100 Testbilder über den API-Proxy von APIYI (apiyi.com) zu generieren. Protokollieren Sie die Generierungskosten, die Erfolgsquote der Schichtung und den Zeitaufwand für manuelle Korrekturen, bevor Sie über eine Skalierung entscheiden.
Checkliste zur Kostenoptimierung bei der Bildschichtung
Bei der Kostenoptimierung sollte man sich nicht nur auf den Einzelpreis konzentrieren.
Wichtiger ist die Vermeidung ineffizienter Generierungen.
Erstens: Verwenden Sie strukturierte Eingabeaufforderungen, um Wiederholungen aufgrund unklarer Kompositionen zu reduzieren.
Zweitens: Nutzen Sie für die Layout-Validierung zunächst eine mittlere Qualität und erhöhen Sie diese erst für die finale Version.
Drittens: Cachen Sie Vorlagen für Eingabeaufforderungen, um Kosten für wiederholte Texteingaben zu senken.
Viertens: Verwenden Sie für dasselbe Produktbild einheitliche Referenzbilder und Layout-Vorgaben, um die Nachbearbeitung zu vereinfachen.
Fünftens: Klassifizieren Sie fehlerhafte Beispiele, um zu unterscheiden, ob der Fehler bei der Modellgenerierung oder bei der Python-Schichtung lag.
Sechstens: Bevorzugen Sie für Szenarien, die eine editierbare Lieferung erfordern, einen flachen Infografik-Stil.
Diese Maßnahmen sind oft effektiver als die reine Jagd nach niedrigeren Stückpreisen.
Vergleich der Ebenen-Strategien für gpt-image-2
Die Anforderungen an die Bildebenen bei gpt-image-2 variieren je nach Team.
Manche möchten nur den Titel ändern, andere benötigen einen PPTX-Export, wieder andere ein vollständiges PSD oder einfach nur eine übersichtlich strukturierte SVG-Datei.
Der folgende Vergleich hilft Ihnen bei der Auswahl des richtigen Ansatzes.
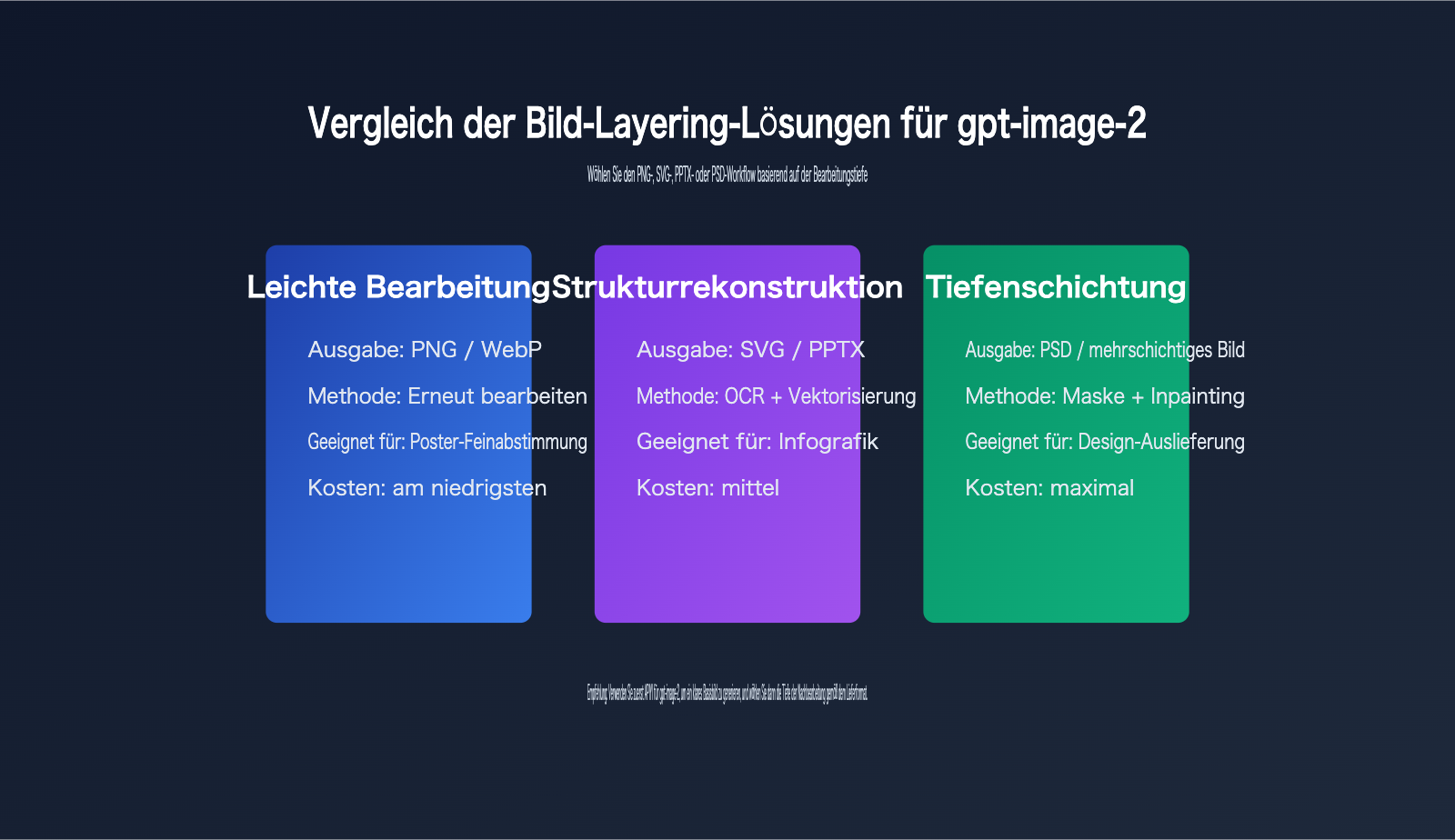
gpt-image-2 Ebenen-Route 1: Weiterhin mit Bildbearbeitung arbeiten
Wenn Sie nur lokale Inhalte ändern möchten, ist die einfachste Methode nicht die Ebenentrennung, sondern die weitere Bearbeitung mit gpt-image-2.
Beispielsweise können Titel, Farben, Hintergründe, Produktbilder oder kleine Icons problemlos über die Bildbearbeitungs-Schnittstelle angepasst werden.
Dieser Weg ist am kostengünstigsten und weist die geringste Systemkomplexität auf.
Der Nachteil: Bei jeder Bearbeitung muss der Teilbereich oder das gesamte Bild neu generiert werden; eine präzise Auswahl einzelner Ebenen wie in Design-Software ist nicht möglich.
Geeignet für Content-Management, Social-Media-Bilder und schnelle Poster-Erstellung.
gpt-image-2 Ebenen-Route 2: Export als SVG oder PPTX
Wenn es sich bei den Bildern um Diagramme, Flussdiagramme, wissenschaftliche Poster oder Infografiken handelt, ist eine SVG/PPTX-Rekonstruktion oft praktischer als ein PSD.
Der Grund: Solche Bilder bestehen meist aus Texten, Icons, Linien, Rechtecken, Pfeilen und wenigen dekorativen Elementen.
OCR kann Text erkennen, Vektorisierung kann Linien und Farbflächen rekonstruieren, und PPTX-Bibliotheken können editierbare Textfelder erstellen.
Dieser Weg eignet sich für Unternehmenswissensdatenbanken, wissenschaftliche Präsentationen, Verkaufsunterlagen und Schulungsmaterialien.
Hier geht es nicht um eine 100-prozentige Pixel-Rekonstruktion, sondern um „Editierbarkeit“ und eine „ausreichende Ähnlichkeit“.
gpt-image-2 Ebenen-Route 3: Generierung von PSD oder mehrschichtigen Asset-Paketen
Die PSD-Ebenentrennung ist am komplexesten.
Wenn Personen, Produkte, Hintergründe, Texte, Schatten und Dekorationen in separate Ebenen zerlegt werden sollen, benötigt das System stärkere Segmentierungs- und Inpainting-Fähigkeiten.
Bei komplexen Fotos ist eine automatische PSD-Erstellung auf Designer-Niveau schwer zu erreichen.
Eine realistischere Strategie ist die Erstellung eines „semi-automatischen PSD“: Das System trennt zunächst Hintergrund, Hauptobjekt, Text und einige Schlüsselelemente, die dann vom Designer manuell nachbearbeitet werden.
Dieser Weg eignet sich für Brand-Design, E-Commerce-Hauptbilder, Werbekreativmaterialien und hochwertige Assets, die langfristig wiederverwendet werden sollen.
Häufig gestellte Fragen zur gpt-image-2 Ebenentrennung
Kann gpt-image-2 direkt PSD-Dateien ausgeben?
Nach aktuellem Stand der öffentlichen API kann man es nicht als „direkte Ausgabe von PSD-Ebenendateien“ verstehen.
Die offizielle Dokumentation konzentriert sich auf Bilderzeugung, Bildbearbeitung, Base64-Bilddaten, Ausgabeformate, Dimensionen, Qualität und Token-Verbrauch.
Wenn ein Produkt PSDs exportieren kann, ist meist eine zusätzliche Anbindung an Photoshop, eine PSD-Schreibbibliothek oder ein selbst entwickeltes Nachbearbeitungsmodul integriert.
Ist das Python in der gpt-image-2 Ebenentrennung Teil des Modell-Codes?
Normalerweise nicht.
Das Python, das Benutzer sehen, ist eher ein externes Workflow-Skript.
Es ist wahrscheinlich für den API-Aufruf, das Speichern von Bildern, die Ausführung von OCR, die Generierung von Masken, das Inpainting von Hintergründen, die Vektorisierung von Grafiken oder das Schreiben von PPTX/PSD-Dateien zuständig.
Diese Skripte gehören zur Anwendungsebene, nicht zum Modell selbst.
Warum sieht die gpt-image-2 Ebenentrennung so aus wie echte Ebenen?
Weil das Nachbearbeitungssystem die Struktur aus den Pixeln rekonstruieren kann.
Beispielsweise kann erkannter Text in editierbare Textfelder umgewandelt werden.
Das Hauptobjekt kann durch eine Maske zu einer eigenständigen Bildebene werden.
Der Hintergrund kann nach dem Inpainting zu einer sauberen Basisgrafik werden.
Wenn diese Ebenen übereinandergelegt werden, sieht es aus wie eine Projektdatei aus einer Design-Software.
Ist die gpt-image-2 Ebenentrennung für alle Bilder geeignet?
Nein.
Geeignet sind Bilder mit klarem Layout, definierten Grenzen, wenig Text, unkompliziertem Hintergrund und Objekten, die sich nicht stark überlappen.
Nicht geeignet sind komplexe Fotografien, Illustrationen mit starken Texturen, transparente Materialien, viele kleine Dekorationen und hochgradig künstlerische Kompositionen.
Wie lässt sich die Erfolgsrate der gpt-image-2 Ebenentrennung erhöhen?
Beginnen Sie mit der Optimierung der Eingabeaufforderung.
Verlangen Sie vom Modell eine klare Struktur, definierte Grenzen, unabhängige Textbereiche und einen Hintergrund mit geringer Komplexität.
Begrenzen Sie dann Bildgröße und Stil, um das Nachbearbeitungssystem nicht mit zu vielen Details zu überfordern.
Bewerten Sie abschließend mit einem Testdatensatz die OCR-Genauigkeit, die Präzision der Objekttrennung und den Zeitaufwand für manuelle Korrekturen.
Auf API-Ebene empfiehlt es sich, die Anfragen an die gpt-image-2 API-Proxy-Dienste zentral zu verwalten, um Kosten und fehlerhafte Beispiele besser nachverfolgen zu können.
Muss man für die gpt-image-2 Ebenentrennung zwingend eine API nutzen?
Wenn Sie nur gelegentlich privat Bilder generieren, reicht die grafische Benutzeroberfläche aus.
Für Massengenerierung, automatische Prüfung, Archivierung von Assets, Export editierbarer Dateien oder Teamarbeit sollten Sie die API verwenden.
Die API macht jeden Schritt nachvollziehbar, wiederholbar und abrechenbar und lässt sich leicht mit internen Python-Nachbearbeitungsdiensten verknüpfen.
Wie ist der „14% Rabatt“ (86-fache Preis) bei der gpt-image-2 Ebenentrennung zu verstehen?
Die vom Benutzer erwähnte Kalkulation bezieht sich auf die Nutzung der offiziellen gpt-image-2 API über diese Plattform, bei der nach offiziellem Preis abgerechnet wird, während bei einer Aufladung von 100 USD ein Bonus von 10 % gewährt wird.
Rein mathematisch betrachtet erhält man für 100 USD ein Guthaben von 110 USD, was effektiv etwa 90,9 % der Stückkosten entspricht.
Sollte die Plattform in Aktionsanzeigen oder bei bestimmten Abrechnungswegen von „14 % Rabatt auf den offiziellen Preis“ sprechen, ist dies gemäß der tatsächlichen Gutschrift, der Abrechnung im Backend und den Aktionsbedingungen zu prüfen.
Bei der Budgetplanung empfiehlt es sich, die Spalten „Offizieller Preis“, „Kalkulation nach Bonus-Aufladung“ und „Plattform-Rabatt“ getrennt zu führen, um Verwirrung in der Finanzplanung zu vermeiden.
Wichtige Erkenntnisse zur Ebenentrennung bei gpt-image-2
- Die zentrale Erkenntnis bei der Ebenentrennung von gpt-image-2 ist: Das Modell liefert in der Regel flache Bilder; die Ebenenstruktur entsteht meist durch nachgelagerte Toolchains.
- Die Python-Backend-Verarbeitung ist kein Hexenwerk; sie wird typischerweise für Modellaufrufe, OCR, Maskierung, Inpainting, Vektorisierung und den Dateiexport eingesetzt.
- Wenn eine Schnittstelle keine PSD-Dateien, Objektbäume, Ebenenlisten oder Maskenlisten zurückgibt, sollte sie nicht als Modell mit nativer Ebenentrennungsfunktion beworben werden.
- Um die Erfolgsrate bei der Ebenentrennung zu erhöhen, muss die Eingabeaufforderung auf die Nachbearbeitung ausgerichtet sein – sorgen Sie für eine klare Bildstruktur und eindeutige Elementgrenzen.
- Für einfache Bearbeitungen kann gpt-image-2 weiterhin genutzt werden, für strukturierte Ausgaben eignen sich SVG/PPTX besser, und für professionelles Design sollte man PSD in Betracht ziehen.
- Die offizielle API von gpt-image-2 eignet sich gut für die Anbindung der Bilderzeugung, während die Python-Ebenentrennung besser vom eigenen Geschäftssystem gesteuert werden sollte.
- Bei der Kostenkalkulation müssen der offizielle Modellpreis, Auflade-Boni, Rechenleistung für die Nachbearbeitung, Wiederholungsversuche bei Fehlern und der Zeitaufwand für manuelle Korrekturen berücksichtigt werden.
Referenzmaterialien zur Ebenentrennung bei gpt-image-2
Dieser Artikel basiert auf englischsprachigen Online-Ressourcen sowie einer Analyse der öffentlichen API-Dokumentation.
- OpenAI GPT Image 2 Modellseite: developers.openai.com/api/docs/models/gpt-image-2
- OpenAI Images and Vision Dokumentation: developers.openai.com/api/docs/guides/images-vision
- OpenAI Images API Referenz: developers.openai.com/api/reference/resources/images
- OpenAI API Preisgestaltung: openai.com/api/pricing
- Reddit-Diskussion zu Python-Fähigkeiten bei GPT Image 2: reddit.com/r/ClaudeCode/comments/1stokpq
- Reddit-Diskussion zu GPT Image 2 für bearbeitbare Folien: reddit.com/r/ChatGPT/comments/1suwjp8
Diese Quellen führen zu einem gemeinsamen Schluss: Die Generierungs- und Bearbeitungsfähigkeiten von gpt-image-2 sind beeindruckend, aber bearbeitbare Ebenen sind in der Regel das Ergebnis von Workflows auf Anwendungsebene.
gpt-image-2 Bild-Layering-Zusammenfassung
Beim Bild-Layering mit gpt-image-2 geht es weniger um die isolierte Frage nach einem „nativen PSD-Format“, sondern vielmehr darum, die richtigen Systemgrenzen zu definieren.
Auf der Generierungsseite ist gpt-image-2 dafür zuständig, Eingabeaufforderungen und Referenzbilder in hochwertige Grafiken umzuwandeln.
Auf der technischen Seite übernimmt die Python-Toolchain die Aufgabe, das flache Bild in Text, Objekte, Hintergründe und editierbare Dateien zu zerlegen.
Wenn Sie diese beiden Bereiche klar voneinander trennen, können Sie Ergebnisse, Kosten und Wartbarkeit deutlich präziser bewerten.
Falls Ihr Ziel die Automatisierung von Massen-Postern, PPT-Diagrammen, Produktvisualisierungen oder Design-Assets ist, empfehle ich, zunächst mit gpt-image-2 eine strukturell klare Basisgrafik zu erstellen und diese anschließend je nach gewünschtem Ausgabeformat in SVG, PPTX oder PSD weiterzuverarbeiten.
Für die Anbindung empfiehlt sich der offizielle gpt-image-2 API-Proxy-Dienst von APIYI (apiyi.com). Sie können Modellaufrufe zum offiziellen Listenpreis tätigen und zusätzlich von der Aktion profitieren, bei der Sie bei einer Aufladung von 100 USD einen Bonus von 10 % erhalten, um die tatsächlichen Kosten zu senken.
Sobald Sie „Modellfähigkeiten“, „Nachbearbeitung“, „Ausgabeformate“ und „Kostenstruktur“ getrennt voneinander verwalten, ist das Bild-Layering mit gpt-image-2 kein mysteriöses Feature mehr, sondern ein validierbarer, erweiterbarer und produktionsreifer visueller Workflow.
Für technischen Austausch und Tests zur Modellanbindung besuchen Sie APIYI (apiyi.com) – ideal für Entwicklerteams, die eine einheitliche Schnittstelle für gpt-image-2, die GPT-Serie und weitere multimodale APIs benötigen.