
ملاحظة من الكاتب: يشرح هذا المقال بشكل منهجي المبادئ الحقيقية لتقسيم الصور في gpt-image-2، وظواهر المعالجة الخلفية باستخدام Python، وطرق استدعاء واجهة برمجة التطبيقات (API)، وخطط تحسين التكلفة، وذلك لمساعدة المطورين على تجنب الخلط بين قدرات سلسلة الأدوات وقدرات النموذج الأصلية.
إذا كنت تستخدم gpt-image-2 مؤخرًا لإنشاء ملصقات، أو صور علمية، أو صور منتجات، أو شرائح عرض تقديمية، فربما لاحظت ظاهرة مثيرة للاهتمام: يدعي البعض أنه يمكنه "تقسيم الصور إلى طبقات"، بل ويمكنه حتى تفكيك الصورة إلى كائنات قابلة للتحرير في الخلفية باستخدام Python.
للوهلة الأولى، يبدو الأمر وكأن النموذج قد تعلم فجأة استخدام Photoshop، لكنه في الواقع أقرب إلى سير عمل متعدد الأدوات: حيث يتولى gpt-image-2 مسؤولية إنشاء أو تحرير صور عالية الجودة، بينما تتولى نصوص Python البرمجية مسؤولية المعالجة اللاحقة مثل التعرف الضوئي على الحروف (OCR)، وإصلاح الخلفية، وتقسيم العناصر، وإعادة بناء ملفات SVG/PPTX/PSD.
هذه ليست مقالة تعريفية أخرى للمبتدئين، بل هي تفكيك كامل لما يمكن وما لا يمكن لتقسيم طبقات الصور في gpt-image-2 تحقيقه، وذلك من منظور قدرات API، ومبادئ الطبقات، والمعالجة اللاحقة بـ Python، وحساب التكلفة، والتطبيق الهندسي.
القيمة الجوهرية: بعد قراءة هذا المقال، ستحدد بوضوح حدود تقسيم طبقات الصور في gpt-image-2، وستعرف كيفية الوصول إلى API الرسمي لـ gpt-image-2 عبر APIYI (apiyi.com)، وتصميم سير عمل "من إنشاء الصور إلى المواد القابلة للتحرير" جاهز للنشر.
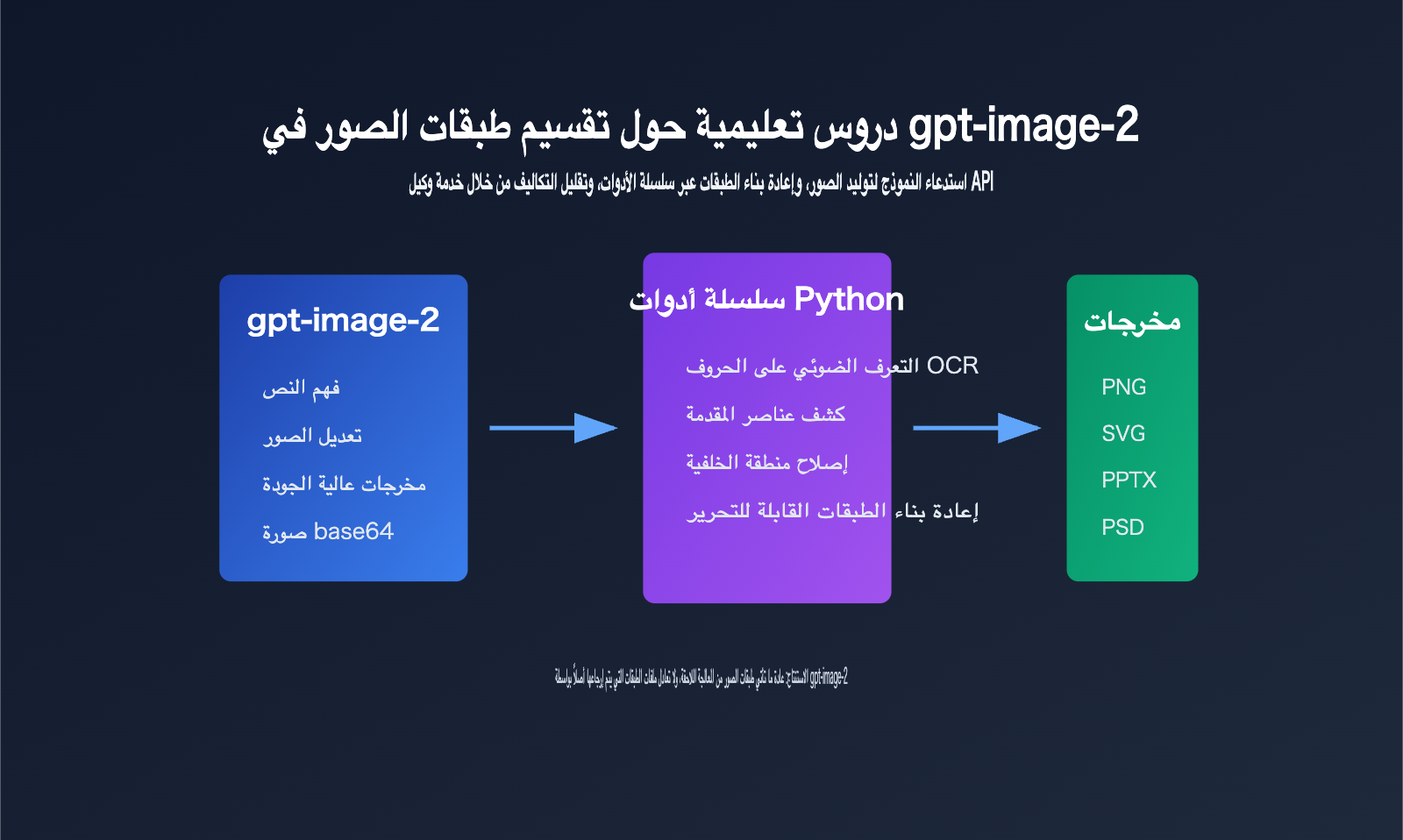
النقاط الجوهرية لتقسيم الصور في gpt-image-2
يكمن مفتاح تقسيم الصور في gpt-image-2 في التمييز أولاً بين "مخرجات النموذج" و"مخرجات سير عمل المنتج".
تُعرّف صفحة النموذج الرسمية من OpenAI نموذج gpt-image-2 كنموذج صور مصمم للإنشاء والتحرير السريع وعالي الجودة، ويدعم إدخال النصوص والصور وإخراج الصور، ويمكن استخدامه مع نقاط نهاية الإنشاء والتحرير في Images API.
ولكن من شكل API المتاح للجمهور حاليًا، تظل النتائج الأساسية التي يحصل عليها المطورون هي بيانات صور، وليست ملفات مشاريع متعددة الطبقات بأسلوب Photoshop.
| النقطة | الشرح | القيمة للمطور |
|---|---|---|
| القدرة الأصلية للنموذج | gpt-image-2 مسؤول عن فهم الموجه، والصورة المرجعية، ونية التحرير، وإخراج الصورة النهائية | مناسب لإنشاء الملصقات، وصور المنتجات، والرسوم التوضيحية، والمسودات المرئية |
| شكل مخرجات الواجهة | تركز الوثائق الرسمية على حقول مثل b64_json، وتنسيق الصورة، والأبعاد، والجودة، واستهلاك التوكنز |
يسهل الحفظ من جانب الخادم، والرفع، والتدقيق، والمحاسبة |
| مصدر تقسيم الصور | تأتي معظم الطبقات القابلة للتحرير من المعالجة اللاحقة مثل OCR، والتقسيم، والإصلاح، والتحويل المتجهي، وكتابة ملفات PPTX/PSD | يفسر "لماذا يتم تشغيل Python في الخلفية" |
| طرق تحسين التكلفة | يمكن الوصول إلى API الرسمي بأسعار التكلفة الأصلية، مع دمج رصيد الشحن لتقليل التكلفة الفعلية | مناسب للإنشاء الجماعي، والاختبار، والتكامل الإنتاجي |
تقسيم الصور في gpt-image-2 ليس إخراجاً أصلياً لملفات PSD
أكثر نقطة يساء فهمها حول تقسيم الصور في gpt-image-2 هي اعتبار "الملف القابل للتحرير الذي يراه المستخدم النهائي" هو "الملف الذي يخرجه النموذج مباشرة".
من الناحية الهندسية، هذان الأمران مختلفان تماماً.
ما يخرجه النموذج مباشرة هو صورة، وعادة ما يتلقاها التطبيق في شكل بيانات صورة base64 أو ملف صورة.
إذا كان بإمكان منتج ما تحويلها إلى PPTX أو SVG أو PSD، فهذا يعني عادةً أن المنتج قد أضاف طبقة نظام معالجة لاحقة بعد النموذج.
قد يتم إنجاز هذه الطبقة بواسطة Python، لأن Python تمتلك نظاماً بيئياً ناضجاً في معالجة الصور، والتعرف الضوئي على الحروف (OCR)، واستنتاج التعلم العميق، وإنشاء مستندات المكتب.
على سبيل المثال، قد يقوم المهندسون أولاً باستخدام OCR للتعرف على النصوص، ثم استخدام inpainting لإصلاح منطقة النص في الصورة الأصلية، ثم استخدام python-pptx لإعادة بناء مربعات النص وطبقات الصور.
هذه الأنواع من العمليات تجعل المستخدم يشعر بأن "الصورة قد تم تقسيمها إلى طبقات"، ولكنها في جوهرها استنتاج عكسي للبنية القابلة للتحرير من صورة مسطحة.
هذا الاستنتاج العكسي ليس مثالياً دائماً.
كلما كانت النصوص أوضح، والخلفية أبسط، والتنسيق أكثر انتظاماً، كان تأثير التقسيم أفضل.
إذا كانت الصورة تحتوي على أنسجة معقدة، أو ظلال شبه شفافة، أو نصوص مكتوبة بخط اليد، أو زخارف دقيقة، أو كائنات متداخلة للغاية، فمن السهل أن تظهر في المعالجة اللاحقة أخطاء في الكشف، أو إغفال، أو عيوب في الحواف.
يتطلب تقسيم الصور في gpt-image-2 الانتباه إلى حدود النموذج وسلسلة الأدوات
عندما يقوم المطورون بتنفيذ تقسيم الصور في gpt-image-2، يجب عليهم تقسيم النظام إلى جزأين.
الجزء الأول هو مرحلة الإنشاء: جعل gpt-image-2 يخرج صوراً ذات جودة بصرية عالية بما يكفي، وبنية واضحة بما يكفي، ونصوص دقيقة قدر الإمكان.
الجزء الثاني هو مرحلة الهيكلة: استخدام Python أو أدوات معالجة لاحقة أخرى لتحويل الصورة المسطحة إلى كائنات قابلة للتحرير.
لكل جزء هدف مختلف، ومؤشرات تقييم مختلفة.
تركز مرحلة الإنشاء على اتباع الموجه، والتكوين، ودقة النص، واتساق الصورة، وتكلفة الإخراج.
تركز مرحلة الهيكلة على معدل قابلية تحرير النص، ودقة تقسيم الكائنات، وطبيعية إصلاح الخلفية، وتوافق ملفات التصدير، وتكلفة التصحيح البشري.
نصيحة تقنية: إذا كنت ترغب في التحقق من سلسلة تقسيم الصور في gpt-image-2، فمن المستحسن الوصول أولاً إلى API الرسمي لـ gpt-image-2 عبر APIYI (apiyi.com) لتشغيل الإنشاء والتحرير، ثم إضافة وحدات OCR، والتقسيم، والإصلاح، والتصدير تدريجياً. هذا يسمح لك باستكشاف أخطاء النموذج ومشاكل المعالجة اللاحقة بشكل منفصل.
كيف تعمل خاصية تقسيم الطبقات في gpt-image-2
يمكن اعتبار تقسيم الطبقات في gpt-image-2 بمثابة "هندسة عكسية" لتحويل الصور المسطحة إلى عناصر هيكلية.
إنها ليست مجرد عملية قص بسيطة، بل هي عملية متكاملة تجمع بين الفهم البصري، ومعالجة الصور التقليدية، وتوليد المستندات.
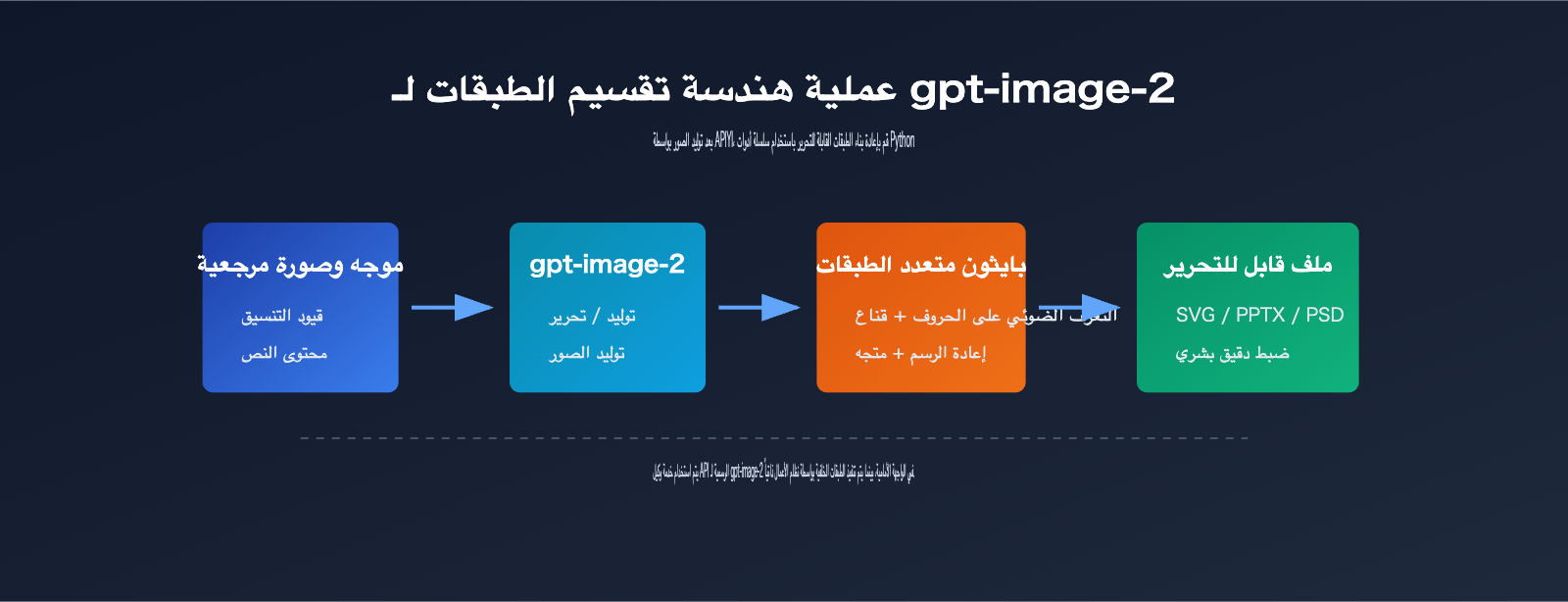
الخطوة الأولى: توليد صورة مناسبة للتقسيم
لجعل تقسيم الطبقات في gpt-image-2 أكثر استقراراً، يجب أن تخدم مرحلة التوليد عملية المعالجة اللاحقة.
يجب أن يطلب الموجه (Prompt) بوضوح تنسيقاً منظماً، وحدوداً واضحة للعناصر، ومناطق نصية مستقلة، مع تجنب التعقيد المفرط في خلفية الصورة.
إذا كان الهدف هو إنشاء ملف PPTX أو SVG، يُنصح باستخدام تصميم مسطح، وكتل لونية واضحة، مع استخدام محدود للظلال والتدرجات اللونية.
أما إذا كان الهدف هو إنشاء ملف PSD، فيُفضل وصف العلاقة بين العنصر الأساسي، والخلفية، والنصوص، والعناصر الزخرفية بوضوح.
من الأخطاء الشائعة طلب توليد ملصقات سينمائية معقدة للغاية من النموذج، ثم توقع أن تقوم أدوات المعالجة اللاحقة بتقسيمها إلى طبقات مثالية تلقائياً.
هذا الأمر غير واقعي في ظل الظروف الهندسية الحالية؛ فنتائج التقسيم تعتمد بشكل كبير على مدى قابلية الصورة المدخلة للتحليل.
الخطوة الثانية: اكتشاف النصوص والكائنات
تعتبر مهام الاكتشاف (Detection) النوع الأكثر شيوعاً للمهام في خلفية Python.
عادةً ما يستخدم اكتشاف النصوص نماذج OCR لتحديد محتوى الأحرف، ومواقعها، وحجم الخط، وحدود مربع النص.
أما اكتشاف الكائنات أو التجزئة (Segmentation) فيقوم بتحديد الكائنات البصرية مثل الأشخاص، والمنتجات، والأيقونات، والخطوط، ومناطق الخلفية.
وفي حال كانت الصورة عبارة عن عرض تقديمي أو مخطط معلوماتي، فقد يتم التعرف أيضاً على العناوين، والفقرات، والجداول، والأسهم، والمحاور، ووسائل الإيضاح.
هذه الطبقة لا تعني أن gpt-image-2 "أعاد الطبقات" بنفسه، بل إن نموذج المعالجة اللاحقة هو من استنتج الطبقات من وحدات البكسل.
كلما كانت عملية الاستنتاج أدق، كانت ملفات PPTX أو SVG أو PSD الناتجة أكثر شبهاً بالتصميم الأصلي.
وعندما لا تكون دقيقة، تظهر المشاكل الأكثر شيوعاً مثل انحراف مواقع مربعات النص، وعدم تطابق الخطوط، ووجود آثار لترميم الخلفية، أو تفتت الأيقونات.
الخطوة الثالثة: ترميم الخلفية وإعادة بناء الملف
بعد أن يحدد نظام OCR مناطق النص، ولجعل النصوص قابلة للتعديل، نحتاج عادةً إلى مسح النص من الصورة الأصلية.
بعد مسح النص، ستظهر فجوات في الخلفية، وهنا يأتي دور خوارزميات الترميم (Inpainting) لملء تلك الفراغات.
بعد ذلك، يقوم النظام بإعادة كتابة النصوص التي تم التعرف عليها في مربعات نص مستقلة داخل ملف PPTX أو SVG أو PSD.
إذا كنت ترغب في الحصول على طبقات كائنات أكثر دقة، فستحتاج أيضاً إلى إنشاء قناع (Mask) لعناصر المقدمة، وقص الكائن، ثم وضعه في طبقة منفصلة.
قد تبدو هذه العملية وكأن "النموذج يقوم بالتقسيم"، ولكن بدقة أكبر، هي عملية: "توليد الصورة بواسطة النموذج + تحليل الصورة بواسطة Python + إعادة بناء الطبقات عبر مكتبات المستندات".
دليل البدء السريع لتقسيم الصور باستخدام gpt-image-2
فيما يلي الحد الأدنى من المسار التقني للمطورين للبدء في تقسيم الصور باستخدام gpt-image-2.
الخطوة الأولى: الحصول على الصورة عبر API.
الخطوة الثانية: حفظ الصورة كملف محلي.
الخطوة الثالثة: تمرير الصورة إلى وحدات التعرف الضوئي على الحروف (OCR)، والتقسيم، والترميم، والتصدير.
مثال برمجي بسيط لواجهة API لتقسيم الصور في gpt-image-2
يوضح المثال التالي كيفية استدعاء خدمة وكيل API الرسمية لنموذج gpt-image-2.
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
result = client.images.generate(
model="gpt-image-2",
prompt="生成一张适合后续分层的产品发布海报,纯色背景,文字区域清晰,元素边界明确",
size="1024x1024",
quality="medium",
output_format="png"
)
# فك تشفير الصورة وحفظها محلياً
image_bytes = base64.b64decode(result.data[0].b64_json)
open("poster.png", "wb").write(image_bytes)
الهدف من هذا الكود ليس "الحصول على ملف PSD فوراً"، بل الحصول على صورة واضحة ومناسبة للمعالجة اللاحقة.
إذا رأيت أن الخادم يواصل تنفيذ كود Python، فهذا يعني عادةً أنه دخل في مرحلة التعرف الضوئي على الحروف (OCR)، أو إنشاء القناع (mask)، أو الترميم (inpainting)، أو التصدير.
هيكل المعالجة الكامل لتقسيم الصور في gpt-image-2
فيما يلي هيكل معالجة أقرب إلى المشاريع الحقيقية.
هذا الهيكل لا يرتبط بنموذج OCR أو تقسيم محدد، بل يوضح فقط حدود الوحدات البرمجية.
from pathlib import Path
def generate_image(prompt: str) -> Path:
"""استدعاء خدمة وكيل API لنموذج gpt-image-2 وحفظ الصورة المسطحة."""
# client = OpenAI(api_key="YOUR_APIYI_KEY", base_url="https://vip.apiyi.com/v1")
# response = client.images.generate(model="gpt-image-2", prompt=prompt)
return Path("poster.png")
def detect_layout(image_path: Path) -> dict:
"""التعرف الضوئي على الحروف (OCR)، كشف الكائنات، وتحديد التخطيط."""
return {"texts": [], "objects": [], "background_regions": []}
def rebuild_editable_file(image_path: Path, layout: dict) -> Path:
"""ترميم الخلفية وتصدير الملف بصيغة SVG أو PPTX أو PSD."""
return Path("poster-editable.pptx")
prompt = "生成一张文字清晰、元素分离、适合分层编辑的 AI 产品海报"
image_path = generate_image(prompt)
layout = detect_layout(image_path)
editable_path = rebuild_editable_file(image_path, layout)
print(editable_path)
في بيئات الإنتاج، يُنصح بفصل generate_image و rebuild_editable_file إلى مهام غير متزامنة (Async Tasks).
عملية توليد الصورة قد تستغرق وقتاً، كما أن المعالجة اللاحقة قد تستهلك موارد المعالج (CPU) أو بطاقة الرسوميات (GPU).
بالنسبة للفرق التي تحتاج إلى توليد ملصقات أو صور منتجات أو رسوم بيانية علمية بكميات كبيرة، يفضل وضع استدعاءات API ومهام المعالجة اللاحقة في طابور انتظار (Queue) مع تسجيل الوقت المستغرق وسبب الفشل في كل خطوة.
نصيحة للبدء السريع: خدمة وكيل API من APIYI (apiyi.com) لنموذج gpt-image-2 مناسبة جداً لتشغيل مرحلة التوليد أولاً، ثم دمج وحدات تقسيم الصور الخاصة بك لاحقاً. هذا يضمن الاستفادة من قدرات النموذج الرسمية مع الاحتفاظ بمنطق الملفات القابلة للتعديل ضمن نظامك الخاص.
قالب الموجه (Prompt) لتقسيم الصور في gpt-image-2
إذا كان هدفك النهائي هو "القدرة على التقسيم"، يجب أن يكون الموجه أكثر انضباطاً مقارنة بتوليد الصور العادي.
| الهدف | طريقة كتابة الموجه الموصى بها | طريقة غير موصى بها |
|---|---|---|
| تقسيم الملصقات | خلفية بلون موحد أو تدرج بسيط، عنوان نصي مستقل، حدود واضحة للمنتج | توليد ملصق سينمائي معقد، الكثير من الأنسجة والدخان |
| تقسيم PPT | استخدام نمط رسوم بيانية مسطحة، عناوين واضحة، أيقونات، أسهم، وثلاث فقرات شرح | توليد صور ذات طابع فني تجريدي قوي |
| تقسيم صور المنتجات | المنتج في مركز الصورة، خلفية نظيفة، ظلال ناعمة، حدود واضحة | دمج المنتج مع الخلفية بشكل قوي |
| إعادة بناء SVG | أشكال هندسية، خطوط، كتل لونية، نصوص قليلة، تجنب أنسجة الصور الواقعية | أنسجة دقيقة كثيرة، شخصيات معقدة، ومواد شفافة |
الموجه الجيد يقلل بشكل كبير من صعوبة المعالجة اللاحقة.
من منظور هندسي، "مناسب للتوليد" و "مناسب للتقسيم" ليسا نفس الهدف.
المستخدم العادي يريد تأثيراً بصرياً، بينما نظام التقسيم يريد هيكلاً واضحاً.
إذا كنت تقوم بأتمتة إنتاج المواد، يجب أن تعطي الأولوية للهيكل الواضح.
تحليل ظاهرة المعالجة الخلفية بـ Python في تقسيم صور gpt-image-2
عندما يرى المستخدم أن Python يعمل في الخلفية لمعالجة تقسيم صور gpt-image-2، فهناك عادةً ثلاثة احتمالات:
الاحتمال الأول: سكريبتات تغليف API.
يقوم المطورون بكتابة سكريبتات Python لاستدعاء gpt-image-2 لتقليل تكرار الكود، وحفظ الصور تلقائياً، وتسجيل المعاملات، ومعالجة الأخطاء وإعادة المحاولة. هذه السكريبتات لا تعني أن النموذج يعمل داخلياً بواسطة Python.
الاحتمال الثاني: سكريبتات المعالجة اللاحقة للصور.
على سبيل المثال، تمرير الصورة الناتجة إلى نماذج OCR، أو نماذج التقسيم، أو نماذج ترميم الخلفية، أو أدوات التحويل المتجهي، أو مكتبات توليد ملفات PPTX/PSD. هذه السكريبتات هي المصدر الرئيسي لـ "إحساس التقسيم".
الاحتمال الثالث: سكريبتات سير عمل الوكلاء (Agent Workflows).
إذا كان المستخدم يستدعي توليد الصور عبر ChatGPT أو أدوات وكيل أخرى، فقد يختار الوكيل تلقائياً أداة Python لإكمال التنزيل أو التحويل أو القص أو التجميع. هذا لا يزال استدعاء أداة على مستوى المنتج، وليس عودة طبقات متعددة أصلياً من API الخاص بـ gpt-image-2.
لماذا يُستخدم Python بكثرة في تقسيم صور gpt-image-2؟
Python مناسب لتقسيم صور gpt-image-2 ليس لأنه غامض، بل لأن النظام البيئي الخاص به متكامل.
| مرحلة المعالجة | مهام Python الشائعة | القيمة النموذجية |
|---|---|---|
| استدعاء API | استدعاء API الصور، حفظ صور base64، تسجيل معاملات الطلب | توليد مستقر للصور |
| OCR | التعرف على محتوى النص، موقعه، ومربعات النص | تحويل نص الصورة إلى نص قابل للتعديل |
| التقسيم | توليد قناع (mask) للموضوع، الخلفية، الأيقونات، والخطوط | فصل الكائنات البصرية |
| الترميم | مسح النصوص أو الكائنات وتكملة الخلفية | تشكيل خلفية نظيفة |
| التصدير | الكتابة بصيغة SVG أو PPTX أو PSD أو غيرها | تسليم ملفات قابلة للتعديل |
ميزة هذا المسار هي المرونة. يمكن للمطورين اختيار نماذج OCR ونماذج تقسيم وتنسيقات تصدير مختلفة بناءً على سيناريو العمل. العيب هو أن استقرار النتائج لا يعتمد كلياً على gpt-image-2. إذا أخطأ OCR في التعرف على حرف، أو فشل ترميم الخلفية، فستتأثر جودة الملف القابل للتعديل النهائي حتى لو كانت الصورة الأصلية ممتازة.
تقسيم صور gpt-image-2 ليس هو "الطبقات" (layers) في استراتيجيات الأمان
هناك مصطلح آخر يسهل الخلط معه وهو "layers".
في مواد الأمان الخاصة بـ OpenAI، قد يتم ذكر تعبيرات مثل image input layers أو image output layers أو multiple layers of protection. هنا تشير كلمة layers إلى طبقات الكشف الأمني أو طبقات فحص المدخلات والمخرجات، وليس طبقات Photoshop.
إذا رأيت كلمة layers في النصوص الإنجليزية، فلا تترجمها مباشرة إلى "طبقات صور" (Image Layers)، فقد يؤدي ذلك إلى سوء فهم.
عند اختيار التقنيات، يُنصح دائماً بالعودة إلى حقول API وتنسيقات المخرجات. إذا لم ترجع الواجهة قائمة بالطبقات، أو قائمة بالأقنعة (masks)، أو شجرة كائنات، أو ملف PSD، فلا يمكن اعتبارها واجهة تقسيم صور أصلية.
معايير الحكم على موثوقية تقسيم صور gpt-image-2
للحكم على ما إذا كان حل تقسيم صور gpt-image-2 موثوقاً، يمكن النظر في أربعة مؤشرات:
أولاً: هل يميز بوضوح بين مخرجات الصورة الأصلية ومخرجات المعالجة اللاحقة؟
ثانياً: هل يمكنه عرض مصدر كل طبقة، مثل طبقة نص OCR، طبقة خلفية، وطبقة كائنات أمامية؟
ثالثاً: هل يسمح بالتصحيح اليدوي؟
رابعاً: هل يمكنه إعادة إنتاج نفس نتائج التقسيم لنفس الصورة؟
إذا كان النظام يقول فقط "تقسيم AI تلقائي" دون توضيح منطق OCR، والقناع، والترميم، والتصدير، فيجب على المطورين تقييم الأمر بحذر.
اقتراح للحلول: في المشاريع الفعلية، يمكنك الحصول على قدرات التوليد المستقرة لـ gpt-image-2 عبر قنوات الوكيل الرسمية، ثم بناء قدرات تقسيم Python كخدمة داخلية. بهذه الطريقة، يمكنك الاستفادة من قدرات القناة الرسمية دون ربط الصندوق الأسود للمعالجة اللاحقة بأداة واحدة فقط.
تكلفة واجهة برمجة تطبيقات (API) تقسيم الصور في gpt-image-2 ومعيار الخصم بنسبة 14%
يجب حساب تكلفة تقسيم الصور في gpt-image-2 بشكل مجزأ.
توليد النموذج هو جزء من التكلفة.
أما التعرف الضوئي على الحروف (OCR)، والتقسيم، والترميم، والتصدير، والتخزين فهي تشكل جزءاً آخر من التكلفة.
إذا نظرت فقط إلى "تكلفة إنتاج ملف قابل للتحرير"، فمن السهل أن تخطئ في تقدير الميزانية.
مرجع الأسعار الرسمية لتقسيم الصور في gpt-image-2
وفقاً لصفحة تسعير API الرسمية من OpenAI، تتضمن معايير الأسعار المعلنة لـ gpt-image-2 مدخلات الصور، ومدخلات الصور المخزنة مؤقتاً، ومخرجات الصور، ومدخلات النصوص، ومدخلات النصوص المخزنة مؤقتاً.
| بند الفوترة | معيار السعر الرسمي | المعنى في تقسيم الصور |
|---|---|---|
| مدخلات الصور (Image input) | 8.00 دولار / مليون رمز | تُحتسب عند إدخال الصور المرجعية، صور التعديل، وصور المواد |
| مدخلات الصور المخزنة (Cached image input) | 2.00 دولار / مليون رمز | تكلفة إدخال الصور المخزنة مؤقتاً والقابلة لإعادة الاستخدام |
| مخرجات الصور (Image output) | 30.00 دولار / مليون رمز | التكلفة الرئيسية للصورة الناتجة نفسها |
| مدخلات النصوص (Text input) | 5.00 دولار / مليون رمز | الموجهات، تعليمات التعديل، وشروحات التنسيق |
| مدخلات النصوص المخزنة (Cached text input) | 1.25 دولار / مليون رمز | مساحة تحسين التكلفة للموجهات القابلة للتخزين المؤقت |
الأسعار الرسمية هي الأساس لبناء الميزانية.
ولكن في المشاريع الحقيقية، يجب أيضاً مراعاة إعادة المحاولة عند الفشل، وطوابير المعالجة الجماعية، وقوة الحوسبة للمعالجة اللاحقة، والتدقيق البشري، وتكاليف التخزين.
إذا كنت بحاجة إلى توليد نسخ متعددة من الملصقات بشكل متكرر، يُنصح بالتحكم في التكلفة من خلال الموجهات، والأبعاد، والجودة، واستراتيجيات إعادة المحاولة.
معيار تكلفة استخدام خدمة وكيل API لتقسيم الصور في gpt-image-2
تسمح خدمة وكيل API لـ gpt-image-2 من APIYI (apiyi.com) بالاتصال وفقاً لمعايير الأسعار الرسمية، وهي مناسبة للفرق التي ترغب في الحفاظ على قناة النموذج الرسمية مع تقليل تعقيدات الربط.
نشاط الشحن الذي يذكره المستخدم هو: اشحن 100 دولار واحصل على 10% إضافية كرصيد.
بالحساب الدقيق "100 دولار تعطي 110 دولار كرصيد متاح"، تكون التكلفة الوحدة المكافئة حوالي 90.9% من السعر الرسمي.
إذا تم حسابها بناءً على عرض المنصة ومعيار الخصم الشامل، يمكن اعتبارها خارجياً في نطاق خصم يقارب 14% (أي 86% من السعر الأصلي)، مع مراعاة أن القيمة الفعلية تعتمد على الرصيد المشحون وقواعد تسوية المنصة.
| طريقة الربط | معيار السعر | المميزات | ملاحظات |
|---|---|---|---|
| OpenAI API الرسمي | السعر الرسمي | قناة أصلية، وثائق كاملة | يتطلب إدارة الحساب، الدفع، الحصص، والمخاطر بنفسك |
| خدمة وكيل API لـ gpt-image-2 | معيار السعر الرسمي | ربط سريع، واجهة موحدة، سهولة إدارة الفريق | يتطلب الشحن والتسوية وفق قواعد المنصة |
| نشاط الشحن | اشحن 100 دولار واحصل على 10% | يقلل التكلفة الفعلية للوحدة | معيار الخصم يعتمد على الرصيد الفعلي |
| حلول البناء الذاتي العكسي | غير ثابت | مرونة عالية | تكاليف أعلى في الامتثال، الاستقرار، والصيانة |
نصيحة حول التكلفة: إذا كنت تقوم باختبار منتج لتقسيم الصور باستخدام gpt-image-2، نوصي باستخدام خدمة وكيل API من APIYI (apiyi.com) لتشغيل 50 إلى 100 عينة، وتسجيل تكلفة توليد كل صورة، ومعدل نجاح التقسيم، ووقت التصحيح البشري، قبل اتخاذ قرار بشأن توسيع نطاق الاستدعاءات الجماعية.
قائمة تحسين تكلفة تقسيم الصور في gpt-image-2
لا تركز فقط على سعر الوحدة عند تحسين التكلفة.
الأهم هو تقليل التوليد غير الفعال.
أولاً، استخدم موجهات مهيكلة لتقليل عمليات إعادة المحاولة الناتجة عن عدم وضوح التكوين.
ثانياً، استخدم جودة متوسطة للتحقق من التنسيق أولاً، ثم ارفع الجودة للنسخة النهائية.
ثالثاً، قم بتخزين موجهات القوالب مؤقتاً لتقليل تكاليف إدخال النصوص المتكررة.
رابعاً، استخدم صوراً مرجعية موحدة ومعايير تخطيط ثابتة لنفس المنتج لتقليل صعوبة المعالجة اللاحقة.
خامساً، صنف العينات الفاشلة للتمييز بين فشل توليد النموذج وفشل التقسيم البرمجي (Python).
سادساً، استخدم أسلوب الرسوم البيانية المسطحة (Flat Infographics) للسيناريوهات التي تتطلب تسليم ملفات قابلة للتحرير.
هذه الممارسات غالباً ما تكون أكثر فعالية من مجرد السعي وراء سعر وحدة أقل.
مقارنة حلول تقسيم الصور في gpt-image-2
تختلف متطلبات الفرق لتقسيم الصور في gpt-image-2.
البعض يريد فقط تعديل العنوان، والبعض يريد تصدير ملفات PPTX، والبعض يريد الحصول على ملف PSD كامل، بينما يريد البعض الآخر مجرد توليد ملفات SVG بهيكل واضح.
المقارنة أدناه ستساعدك على اختيار المسار المناسب.

مسار تقسيم الصور في gpt-image-2 الأول: الاستمرار في استخدام تحرير الصور
إذا كان الأمر يتعلق فقط بتعديل محتوى جزئي، فإن أسهل طريقة ليست التقسيم، بل الاستمرار في استخدام تحرير الصور في gpt-image-2.
على سبيل المثال، تعديل العناوين، تغيير الألوان، تبديل الخلفيات، استبدال صور المنتجات، أو إضافة أيقونات صغيرة، يمكن إنجاز كل ذلك عبر واجهة تحرير الصور.
هذا المسار هو الأقل تكلفة والأقل تعقيداً من حيث النظام.
العيب هو أن كل تعديل يتطلب إعادة توليد جزء من الصورة أو الصورة بأكملها، ولا يمكنك اختيار طبقة واحدة بدقة كما في برامج التصميم.
مناسب لسيناريوهات إدارة المحتوى، صور وسائل التواصل الاجتماعي، والملصقات السريعة.
مسار تقسيم الصور في gpt-image-2 الثاني: التصدير إلى SVG أو PPTX
إذا كانت الصورة عبارة عن مخطط بياني، أو مخطط تدفق، أو ملصق علمي، أو رسوم بيانية معلوماتية، فإن إعادة بناء SVG/PPTX غالباً ما تكون أكثر عملية من PSD.
لأن عناصر هذه الصور عادة ما تكون نصوصاً، وأيقونات، وخطوطاً، ومستطيلات، وأسهماً، وبعض الزخارف.
يمكن للتعرف الضوئي على الحروف (OCR) التعرف على النصوص، ويمكن للتحويل المتجهي إعادة بناء الخطوط والكتل اللونية، ويمكن لمكتبات PPTX إنشاء مربعات نصوص قابلة للتحرير.
هذا المسار مناسب لقواعد المعرفة المؤسسية، العروض العلمية، مواد المبيعات، ومواد التدريب.
فهو لا يسعى إلى استعادة جميع البكسلات بنسبة 100%، بل يسعى إلى "القابلية للتحرير" وأن يكون "شبيهاً بما يكفي".
مسار تقسيم الصور في gpt-image-2 الثالث: توليد PSD أو حزمة مواد متعددة الطبقات
تقسيم PSD هو الأكثر تعقيداً.
إذا كنت ترغب في فصل الأشخاص، والمنتجات، والخلفيات، والنصوص، والظلال، والزخارف إلى طبقات منفصلة، يحتاج النظام إلى قدرات أقوى في التقسيم والترميم.
بالنسبة للصور الفوتوغرافية المعقدة، يصعب على التقسيم التلقائي لـ PSD الوصول إلى مستوى المصممين المحترفين.
الاستراتيجية الأكثر واقعية هي توليد "PSD شبه تلقائي": يقوم النظام أولاً بفصل الخلفية، والعنصر الرئيسي، والنصوص، وعدد من الكائنات الرئيسية، ثم يقوم المصمم بالتصحيح اليدوي.
هذا المسار مناسب لتصميم العلامات التجارية، الصور الرئيسية للتجارة الإلكترونية، الإبداع الإعلاني، والمواد عالية القيمة التي تتطلب إعادة استخدام طويلة الأمد.
الأسئلة الشائعة حول تقسيم الطبقات في gpt-image-2
هل يمكن لتقسيم الطبقات في gpt-image-2 إخراج ملفات PSD مباشرة؟
بناءً على واجهات برمجة التطبيقات (API) المتاحة حالياً، لا يمكن اعتبارها "مُصدراً مباشراً لملفات طبقات PSD".
تركز الوثائق الرسمية على توليد الصور، وتعديل الصور، وبيانات الصور بصيغة base64، وتنسيقات المخرجات، والأبعاد، والجودة، واستهلاك الرموز (Tokens).
إذا كان هناك منتج ما قادر على تصدير ملفات PSD، فعادةً ما يكون ذلك نتيجة لدمج إضافي مع Photoshop، أو مكتبات كتابة ملفات PSD، أو وحدات معالجة لاحقة مطورة ذاتياً.
هل كود Python في تقسيم طبقات gpt-image-2 جزء من كود النموذج الداخلي؟
غالباً لا.
كود Python الذي يراه المستخدم هو على الأرجح سكربت عمل خارجي.
قد يكون هذا السكربت مسؤولاً عن استدعاء الـ API، وحفظ الصور، وتشغيل التعرف الضوئي على الحروف (OCR)، وتوليد الأقنعة (Masks)، وإصلاح الخلفيات، وتحويل الرسومات إلى متجهات (Vectorization)، أو الكتابة في ملفات PPTX/PSD. هذه السكربتات تنتمي إلى طبقة التطبيق، وليست جزءاً من النموذج نفسه.
لماذا تبدو طبقات gpt-image-2 وكأنها طبقات حقيقية؟
لأن أنظمة المعالجة اللاحقة يمكنها إعادة بناء الهيكل من البكسلات.
على سبيل المثال، بعد التعرف على النص، يمكن تحويله إلى مربع نص قابل للتعديل.
يمكن تحويل العناصر الرئيسية للمنتج إلى طبقة صورة مستقلة من خلال الأقنعة (Masks).
وبعد إصلاح الخلفية، يمكن تحويلها إلى خلفية نظيفة.
عند تكديس هذه الطبقات، تبدو النتيجة مشابهة جداً لملفات العمل المصدرة من برامج التصميم.
هل تقسيم الطبقات في gpt-image-2 مناسب لجميع الصور؟
لا، ليس للجميع.
الصور المناسبة للتقسيم هي التي تتمتع بتخطيط واضح، وحدود محددة، وكمية قليلة من النصوص، وخلفية غير معقدة، وعناصر غير متداخلة بشكل كبير.
أما الصور غير المناسبة للتقسيم فتشمل الصور الفوتوغرافية المعقدة، والرسوم التوضيحية ذات الأنسجة القوية، والمواد الشفافة، والزخارف الدقيقة الكثيرة، والتكوينات الفنية العالية.
كيف يمكن تحسين نسبة نجاح تقسيم الطبقات في gpt-image-2؟
ابدأ بتحسين الموجه (Prompt).
اطلب من النموذج إخراج هيكل واضح، بحدود محددة، ومناطق نصية مستقلة، وخلفية ذات تعقيد منخفض.
ثم قم بتقييد أبعاد الصورة وأسلوبها لتجنب إرهاق نظام المعالجة اللاحقة بالكثير من التفاصيل.
وأخيراً، استخدم مجموعة عينات لتقييم دقة الـ OCR، ودقة فصل الكائنات، والوقت المستغرق في التصحيح اليدوي.
على مستوى استدعاء الـ API، يُنصح بإدارة طلبات الـ API لـ gpt-image-2 بشكل موحد عبر خدمة وكيل API، لتسهيل تسجيل التكاليف وتتبع العينات الفاشلة.
هل يجب استخدام الـ API لتقسيم طبقات gpt-image-2؟
إذا كنت تولد الصور بشكل فردي وعرضي، يمكنك استخدام الواجهة الرسومية.
أما إذا كنت تنوي القيام بتوليد دفعي، أو مراجعة تلقائية، أو أرشفة مواد، أو تصدير ملفات قابلة للتعديل، أو العمل ضمن فريق، فيجب عليك استخدام الـ API.
تتيح لك الـ API تتبع كل خطوة، وإعادة المحاولة، وحساب التكاليف، كما تسهل الربط مع خدمات المعالجة اللاحقة بلغة Python الخاصة بك.
كيف نفهم خصم الـ 14% (86%) على تقسيم طبقات gpt-image-2؟
الآلية التي يشير إليها المستخدمون هي الوصول إلى الـ API الخاص بـ gpt-image-2 عبر منصة وسيطة، حيث يتم المحاسبة وفقاً للسعر الرسمي، مع الحصول على مكافأة 10% عند شحن 100 دولار.
من الناحية الحسابية البحتة، الحصول على رصيد 110 دولارات مقابل 100 دولار يعني أن التكلفة الفعلية تعادل حوالي 90.9%.
إذا كانت المنصة تعلن عن "خصم 14% من السعر الرسمي" في العروض الترويجية أو قنوات معينة، فيجب الاعتماد على الرصيد الفعلي المضاف، وفواتير النظام الخلفي، وشروط العرض.
عند إعداد جدول الميزانية، يُنصح بالاحتفاظ بثلاثة أعمدة: "السعر الرسمي"، "السعر بعد خصم المكافأة"، و"الخصم المعلن في المنصة"، لتجنب التضارب في الحسابات المالية.
النقاط الرئيسية حول تقسيم الطبقات في gpt-image-2
- الحكم الأساسي على تقسيم طبقات gpt-image-2 هو: النموذج يخرج صوراً مسطحة عادةً، وتأتي الطبقات من سلسلة أدوات المعالجة اللاحقة.
- معالجة Python الخلفية ليست سراً، فهي تُستخدم عادةً لاستدعاء الـ API، والـ OCR، والأقنعة (Masks)، والترميم (Inpainting)، والتحويل المتجهي، وتصدير الملفات.
- إذا لم تُرجع الواجهة ملفات PSD، أو شجرة كائنات، أو قائمة طبقات، أو قائمة أقنعة، فلا ينبغي الترويج لها كقدرة أصلية للنموذج على تقسيم الطبقات.
- لتحسين نجاح التقسيم، يجب أن يخدم الموجه (Prompt) عملية المعالجة اللاحقة، بجعل هيكل الصورة واضحاً وحدود العناصر محددة.
- يمكن الاستمرار في استدعاء gpt-image-2 للتعديلات الخفيفة، بينما يُفضل استخدام SVG/PPTX للتسليم الهيكلي، وتُترك ملفات PSD للتصاميم العميقة.
- خدمة APIYI لـ gpt-image-2 مناسبة للربط في جانب التوليد، بينما يفضل أن تتحكم أنظمة العمل الخاصة بك في خدمة تقسيم الطبقات بلغة Python.
- يجب أن تشمل حسابات التكلفة سعر النموذج الرسمي، ومكافآت الشحن، وقوة الحوسبة للمعالجة اللاحقة، وإعادة المحاولات عند الفشل، ووقت التصحيح اليدوي.
مراجع طبقات الصور في gpt-image-2
تمت كتابة هذا المقال بالرجوع إلى مصادر تقنية باللغة الإنجليزية، مع إجراء تقاطع للمعلومات استناداً إلى وثائق API العامة.
- صفحة نموذج OpenAI GPT Image 2: developers.openai.com/api/docs/models/gpt-image-2
- وثائق الصور والرؤية من OpenAI: developers.openai.com/api/docs/guides/images-vision
- مرجع API الصور من OpenAI: developers.openai.com/api/reference/resources/images
- تسعير OpenAI API: openai.com/api/pricing
- نقاش حول مهارات Python لـ GPT Image 2 على Reddit: reddit.com/r/ClaudeCode/comments/1stokpq
- نقاش حول تحويل GPT Image 2 إلى شرائح قابلة للتعديل على Reddit: reddit.com/r/ChatGPT/comments/1suwjp8
تشير هذه المصادر مجتمعة إلى استنتاج واحد: قدرات التوليد والتحرير في gpt-image-2 قوية للغاية، ولكن الطبقات القابلة للتعديل هي عادةً نتيجة لسير عمل في طبقة التطبيق.
ملخص طبقات الصور في gpt-image-2
الأمر الأكثر أهمية في طبقات صور gpt-image-2 ليس البحث عن إجابة أحادية حول "هل هي ملفات PSD أصلية أم لا"، بل بناء حدود واضحة للنظام.
في جانب التوليد، يتولى gpt-image-2 مسؤولية تحويل الموجه (Prompt) والصورة المرجعية إلى صور عالية الجودة.
في الجانب الهندسي، تتولى سلسلة أدوات Python مسؤولية تحليل الصور المسطحة إلى نصوص، وكائنات، وخلفيات، وملفات قابلة للتعديل.
من خلال فصل هاتين المرحلتين بوضوح، يمكن للمطورين تقييم النتائج والتكاليف وقابلية الصيانة بدقة أكبر.
إذا كان هدفك هو إنشاء ملصقات جماعية، أو مخططات PPT، أو مرئيات للمنتجات، أو أتمتة مواد التصميم، فمن المستحسن استخدام gpt-image-2 أولاً لإنشاء صورة أساسية ذات هيكل واضح، ثم إجراء معالجة لاحقة لاختيار تنسيق التسليم سواء كان SVG أو PPTX أو PSD.
بالنسبة لطبقة الربط، يمكنك إعطاء الأولوية لاستخدام خدمة وكيل API الخاص بـ gpt-image-2 عبر APIYI (apiyi.com)، حيث يتم استدعاء النموذج وفقاً للتسعير الرسمي، مع الاستفادة من عرض شحن 100 دولار والحصول على 10% إضافية لتقليل التكاليف الفعلية.
عندما تقوم بإدارة "قدرات النموذج"، و"قدرات المعالجة اللاحقة"، و"تنسيق التسليم"، و"حساب التكاليف" بشكل منفصل، لن تعود طبقات صور gpt-image-2 مجرد ميزة غامضة، بل ستصبح عملية إنتاج مرئي قابلة للتحقق والتوسع والتنفيذ.
للمناقشات التقنية واختبارات ربط النماذج، تابع APIYI (apiyi.com)، وهي منصة مناسبة لفرق المطورين التي تحتاج إلى استدعاء موحد لـ gpt-image-2، وسلسلة GPT، ونماذج API متعددة.