
في عام 2026، أصبح 92% من المطورين يستخدمون أدوات البرمجة المدعومة بالذكاء الاصطناعي، حيث يتم توليد 41% من الأكواد بمساعدة هذه الأدوات. لكن الواقع المحبط هو: بينما يزعم المطورون توفير 30-60% من الوقت، لا تتجاوز زيادة الإنتاجية الفعلية للمؤسسات 10%. أين تكمن الفجوة؟ إنها في "سير العمل" (Workflow).
إذا استخدمت مزيجاً صحيحاً من النماذج وسير العمل، فسيصبح الذكاء الاصطناعي في البرمجة أداة لمضاعفة الكفاءة 10 مرات؛ أما إذا استخدمته بشكل خاطئ، فسيكون مجرد مولد أكواد "يبدو أنه يعمل، لكنه قد ينهار في أي لحظة".
القيمة الجوهرية: بعد قراءة هذا المقال، ستتقن سير عمل برمجياً يعتمد على نماذج متعددة ومجربة، حيث تستخدم نماذج فعالة من حيث التكلفة (مثل GLM-5) لتوليد الأكواد، ونماذج متطورة (مثل Claude Sonnet 4.6) لمراجعة الأكواد، بالإضافة إلى كيفية تحقيق أتمتة كاملة للسلسلة باستخدام Claude Code.
تحول جذري في سير عمل برمجة الذكاء الاصطناعي
تحول دور المطور: من "كاتب كود" إلى "موجه للذكاء الاصطناعي"
في عام 2026، لم يعد العمل الأساسي للمطور هو كتابة الكود سطرًا بسطر، بل أصبح يتمحور حول:
- هندسة المواصفات (Specification Engineering) — تحديد المتطلبات، والقيود، وتفضيلات البنية البرمجية.
- اختيار مزيج النماذج — استخدام نماذج مختلفة في مراحل مختلفة.
- المراجعة والتدقيق — ضمان توافق مخرجات الذكاء الاصطناعي مع المعايير الهندسية.
- تحمل المسؤولية النهائية — الذكاء الاصطناعي مجرد أداة، والإنسان هو المسؤول.
لخص "آدي عثماني" (قائد تقني في فريق Google Chrome) المبادئ الأساسية بقوله: "خطط أولاً، ثم اكتب الكود. تعديل الخطط رخيص، بينما تعديل الكود مكلف."
سير العمل الجديد مقابل سير العمل التقليدي
| البعد | سير العمل التقليدي | سير العمل المدعوم بالذكاء الاصطناعي |
|---|---|---|
| النشاط الأساسي | كتابة الكود سطرًا بسطر | كتابة المواصفات + مراجعة مخرجات الذكاء الاصطناعي |
| دور المطور | مبرمج (Coder) | منسق (Orchestrator) |
| توليد الكود | 100% يدوي | ~40% توليد بواسطة الذكاء الاصطناعي + تعديل بشري |
| تركيز المراجعة | المنطق والأسلوب | جودة مخرجات الذكاء الاصطناعي + اتساق البنية |
| سلسلة الأدوات | IDE + Git | وكيل ذكاء اصطناعي + IDE + Git + نماذج متعددة |
| عنق الزجاجة | سرعة البرمجة | سرعة المراجعة والقدرة على الحكم |
بيانات أساسية: الواقع الحالي لبرمجة الذكاء الاصطناعي
| البيانات | المصدر |
|---|---|
| 92% من المطورين يستخدمون أدوات برمجة الذكاء الاصطناعي | استطلاع الصناعة لعام 2026 |
| 41% من عمليات رفع الكود (Commits) مدعومة بالذكاء الاصطناعي | بيانات GitHub |
| 30% فقط من اقتراحات الذكاء الاصطناعي يتم قبولها مباشرة | تقرير CodeRabbit |
| 29-46% فقط من المطورين يثقون في مخرجات الذكاء الاصطناعي | دراسات متعددة |
| زيادة إنتاجية المؤسسات فعليًا بنحو 10% | إجماع 6 دراسات مستقلة |
| معدل أخطاء الكود المولد بالذكاء الاصطناعي أعلى بـ 1.7 مرة من البشر | تحليل 470 طلب سحب (PR) |
🎯 رؤية جوهرية: مفتاح زيادة الإنتاجية لا يكمن في كمية الكود التي يمكن للذكاء الاصطناعي توليدها، بل في امتلاكك لنظام مراجعة وتحقق فعال. من خلال منصة APIYI (apiyi.com)، يمكنك دمج نماذج مختلفة بمرونة لبناء هذا النظام.
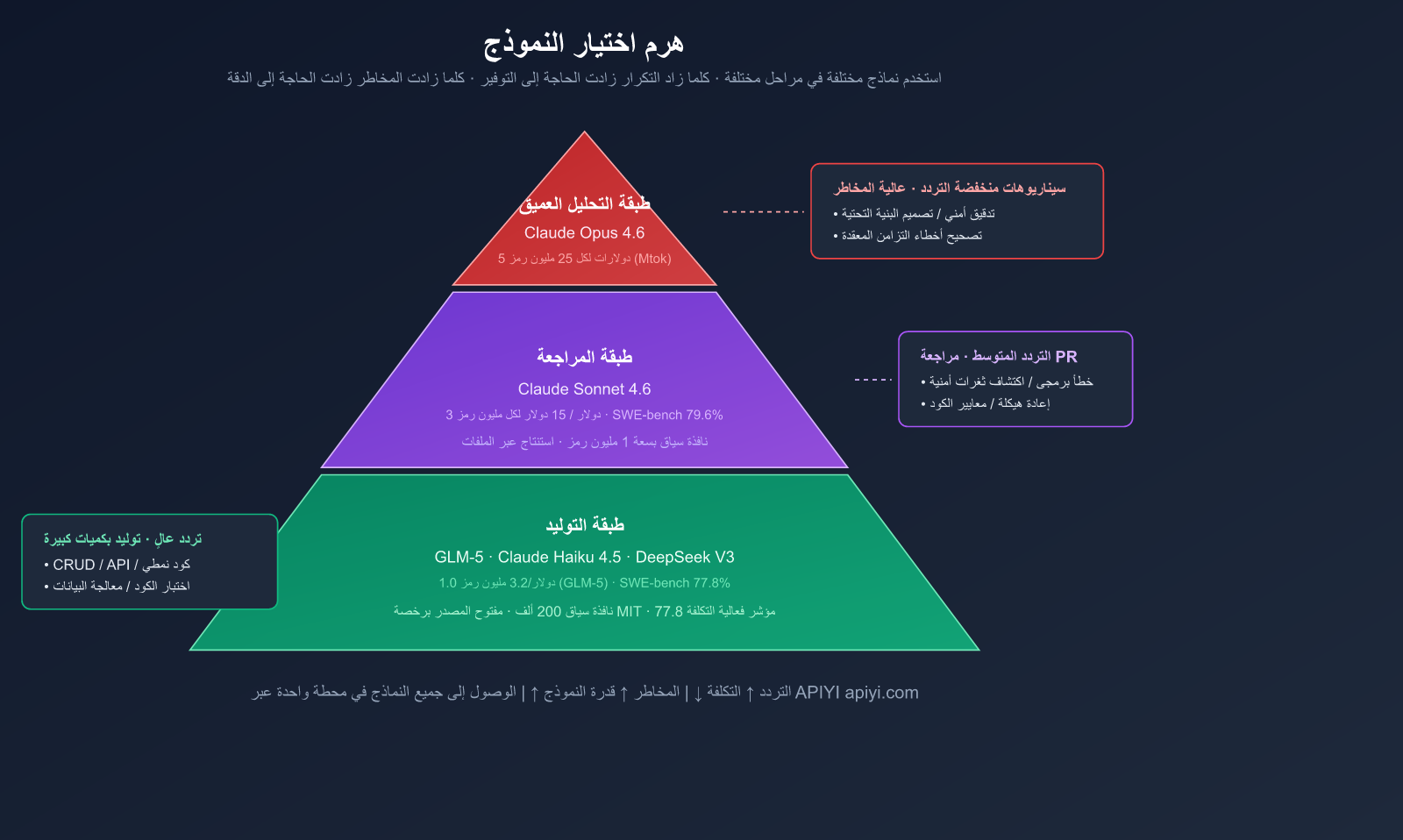
استراتيجية اختيار النماذج: نماذج اقتصادية للكتابة، ونماذج متطورة للمراجعة
هذه هي المنهجية الأساسية لهذا المقال — استخدام نماذج مختلفة لكل مرحلة. تمامًا كما لا تستخدم فرق سباقات السيارات سيارات "الفورمولا 1" لنقل البضائع، ولا تستخدم شاحنات النقل في السباقات.
هرم النماذج ثلاثي الطبقات
| الطبقة | الاستخدام | النموذج الموصى به | سعر الإدخال/الإخراج | وتيرة الاستدعاء |
|---|---|---|---|---|
| طبقة التوليد | كتابة الكود، CRUD، الكود النمطي | GLM-5, Claude Haiku 4.5 | $1.0/$3.2 (GLM-5) | عالية |
| طبقة المراجعة | مراجعة PR، اكتشاف الأخطاء، اقتراحات إعادة الهيكلة | Claude Sonnet 4.6 | $3/$15 | متوسطة |
| الطبقة العميقة | تصميم البنية، التدقيق الأمني، التصحيح المعقد | Claude Opus 4.6 | $5/$25 | منخفضة |
لماذا اخترنا GLM-5 لتوليد الكود؟
نموذج GLM-5 هو نموذج لغة كبير مفتوح المصدر أطلقته شركة Zhipu AI في فبراير 2026، ويتمتع بفعالية عالية من حيث التكلفة في مجال توليد الكود.
المواصفات الأساسية لـ GLM-5:
- عدد المعلمات: 744 مليار (بنية MoE، 256 خبيرًا، يتم تفعيل 8 في كل مرة، حوالي 40 مليار معلمة نشطة).
- نافذة السياق: 200 ألف توكن.
- SWE-bench Verified: 77.8% (الأول بين النماذج مفتوحة المصدر).
- الترخيص: MIT (تجاري بالكامل).
- سعر الإدخال: 1.00 دولار لكل مليون توكن — أي ثلث سعر Claude Sonnet 4.6.
مقارنة GLM-5 مع النماذج مغلقة المصدر في اختبار SWE-bench:
| النموذج | SWE-bench Verified | سعر الإدخال (لكل مليون توكن) | مؤشر الفعالية |
|---|---|---|---|
| Claude Opus 4.6 | 81.4% | $5.00 | 16.3 |
| Claude Sonnet 4.6 | 79.6% | $3.00 | 26.5 |
| GPT-5.2 | 80.0% | — | — |
| GLM-5 | 77.8% | $1.00 | 77.8 |
مؤشر الفعالية لـ GLM-5 (نتيجة SWE-bench / سعر الإدخال) يقارب 3 أضعاف مؤشر Claude Sonnet 4.6. بالنسبة لعمليات توليد الكود عالية التكرار، تتضخم فروق التكلفة بسرعة مع زيادة حجم الاستدعاءات.
لماذا اخترنا Claude Sonnet 4.6 لمراجعة الكود؟
مراجعة الكود لا تتطلب السرعة بقدر ما تتطلب الفهم العميق والحكم الدقيق. يتفوق Sonnet 4.6 في هذا الجانب على نماذج طبقة التوليد:
- نافذة سياق تصل إلى مليون توكن: يمكنه تحميل كامل قاعدة الكود + فروق PR + العلاقات بين التبعيات دفعة واحدة.
- الاستدلال عبر الملفات: القدرة على اكتشاف أن تعديل الملف "أ" يؤدي إلى كسر المنطق في الملف "ب".
- SWE-bench 79.6%: أقل بـ 1.8 نقطة مئوية فقط من Opus 4.6.
- تفضيلات المطورين: في اختبارات Claude Code، فضل المطورون Sonnet 4.6 على النموذج الرائد السابق Opus 4.5 بنسبة 59%.
- تجنب الهندسة المفرطة: مقارنة بالنماذج السابقة، وُصف Sonnet 4.6 بأنه أقل عرضة لـ "الهندسة المفرطة" أو "الكسل".
مقارنة التكلفة: تكلفة استخدام Sonnet 4.6 للمراجعة تعادل خُمس تكلفة Opus 4.6، لكن جودة المراجعة متقاربة جدًا. بالنسبة لمعظم سيناريوهات مراجعة PR، يعد هذا الخيار الأمثل.
💡 نصيحة للاختيار: من خلال منصة APIYI (apiyi.com)، يمكنك الوصول إلى واجهات برمجة التطبيقات (API) لكل من GLM-5 وClaude Sonnet 4.6، وإدارة نماذج متعددة باستخدام مفتاح API واحد. استخدم GLM-5 في مرحلة التوليد لتقليل التكاليف، وانتقل إلى Sonnet 4.6 في مرحلة المراجعة لضمان الجودة.
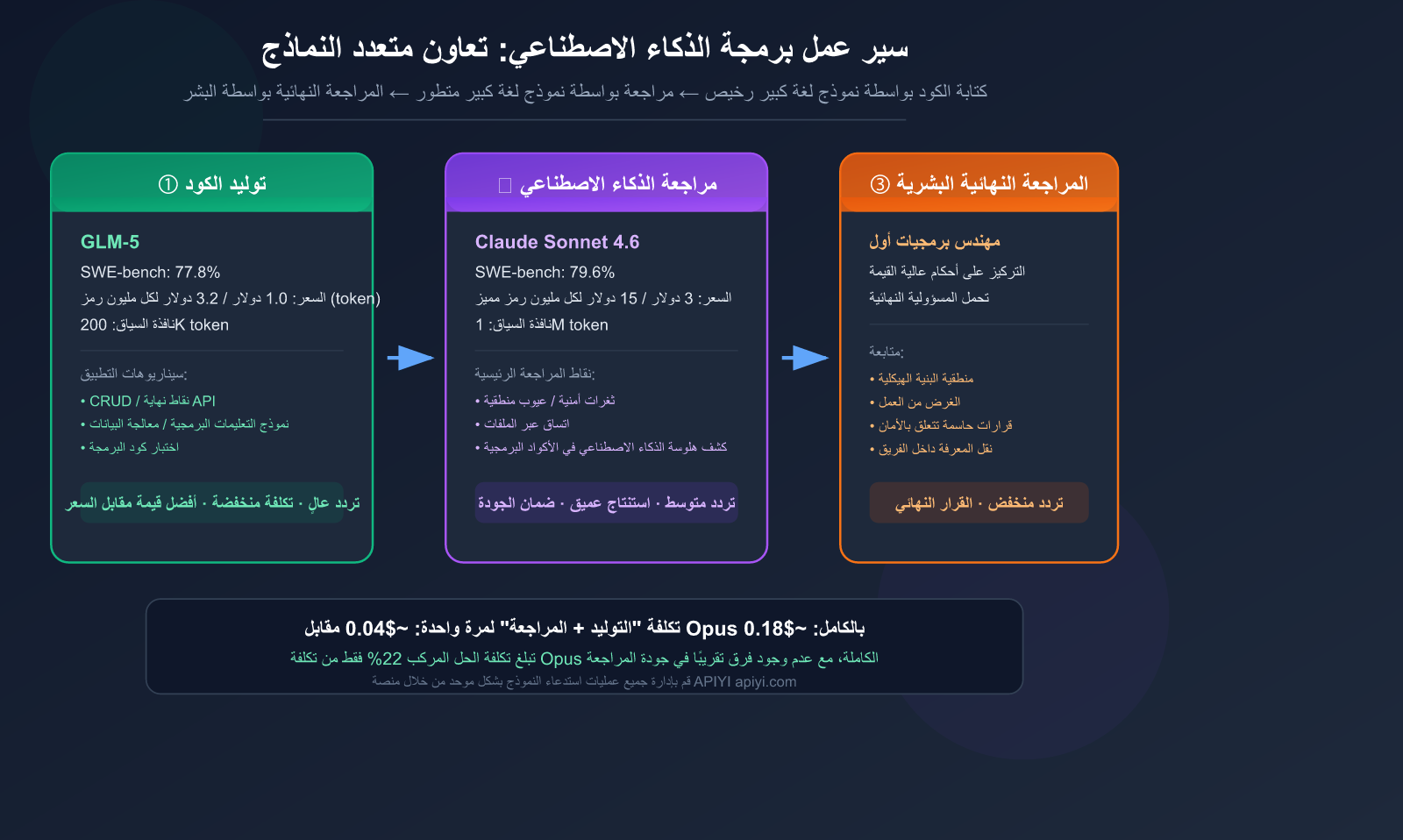
6 خطوات عملية لسير العمل: من المتطلبات إلى الدمج
إليك سير عمل كامل ومجرب. المبدأ الأساسي هو: الاستكشاف (Explore) ← التخطيط (Plan) ← التوليد (Generate) ← المراجعة (Review) ← الاختبار (Test) ← الالتزام/الدمج (Commit).
الخطوة الأولى: تحديد المواصفات (Specification)
قبل كتابة أي كود، قم بكتابة مواصفات واضحة للمتطلبات:
## المتطلبات
تنفيذ نقطة نهاية (API endpoint) لتسجيل المستخدمين
القيود
- استخدام إطار العمل FastAPI.
- تشفير كلمات المرور باستخدام bcrypt.
- يجب أن يكون البريد الإلكتروني فريداً، وإرجاع خطأ 409 عند التعارض.
- الكتابة في قاعدة بيانات PostgreSQL باستخدام SQLAlchemy ORM.
- إرجاع رمز JWT.
غير مطلوب
- عملية التحقق من البريد الإلكتروني (في التحديثات اللاحقة).
- تسجيل الدخول عبر وسائل التواصل الاجتماعي.
### الخطوة الثانية: التخطيط بواسطة الذكاء الاصطناعي (Plan)
استخدم نموذج Claude Sonnet 4.6 لتخطيط البنية الهيكلية (مرحلة التخطيط تستحق استخدام نموذج قوي):
```python
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # خدمة وكيل API من APIYI
)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": "أنت مهندس معماري برمجيات خبير. بناءً على المتطلبات، قم بإنشاء خطة تنفيذ تشمل هيكل الملفات، وتوقيعات الدوال الرئيسية، وتدفق البيانات. لا تكتب الكود كاملاً."},
{"role": "user", "content": spec_content}
]
)
print(response.choices[0].message.content)
الخطوة الثالثة: توليد الكود بواسطة الذكاء الاصطناعي (Generate)
بعد تأكيد الخطة، استخدم نموذج GLM-5 لتوليد كود التنفيذ:
# التبديل إلى نموذج ذو كفاءة عالية من حيث التكلفة لتوليد الكود
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": f"قم بتنفيذ الكود وفقاً لخطة البنية التالية:\n{plan}"},
{"role": "user", "content": "يرجى تنفيذ الكود الكامل لواجهة برمجة تطبيقات تسجيل المستخدم"}
],
max_tokens=8192
)
المبادئ الأساسية:
- قم بتوليد دالة أو وحدة برمجية واحدة في كل مرة، لا تقم بتوليد المشروع بالكامل دفعة واحدة.
- بعد التوليد، قم بإجراء
git commitفوراً كـ "نقطة استعادة". - لا تتردد في جعل الذكاء الاصطناعي يكتب الكود المتكرر (مثل عمليات CRUD والتحقق من النماذج).
- الكود الحساس أمنياً (المصادقة، التشفير، الصلاحيات) يجب كتابته يدوياً أو مراجعته بدقة مضاعفة.
الخطوة الرابعة: المراجعة بواسطة الذكاء الاصطناعي (Review)
بعد توليد الكود، انتقل إلى نموذج Claude Sonnet 4.6 للمراجعة:
# التبديل إلى نموذج المراجعة
generated_code = open("app/routes/auth.py").read()
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"يرجى مراجعة الكود التالي:\n\n{generated_code}"}
],
max_tokens=4096
)
عرض قالب المراجعة (Prompt) الكامل
REVIEW_PROMPT = """أنت خبير مراجعة كود محترف. هذا الكود تم توليده بواسطة الذكاء الاصطناعي، يرجى الانتباه بشكل خاص إلى:
1. **مشاكل الذكاء الاصطناعي الشائعة**: استدعاءات API وهمية، مكتبات غير موجودة، كود يبدو صحيحاً ولكن منطقه خاطئ.
2. **الأمان**: الحقن (Injection)، مفاتيح مشفرة داخل الكود (Hardcoded)، تشفير غير آمن، تجاوز الصلاحيات.
3. **الحالات الحدية**: القيم الفارغة، التزامن (Concurrency)، البيانات الضخمة، مهلة الشبكة.
4. **اتساق البنية**: هل يتوافق مع نمط المشروع الحالي؟ التسمية، الطبقات، معالجة الأخطاء.
5. **قابلية الاختبار**: هل من السهل كتابة اختبارات الوحدة؟ هل التبعيات قابلة للحقن؟
صنف المخرجات حسب مستوى الخطورة:
- 🔴 يجب إصلاحه (أخطاء أمنية/منطقية)
- 🟡 يُنصح بإصلاحه (جودة الكود)
- 💡 اقتراحات للتحسين (تحسينات اختيارية)
إذا لم تكن هناك مشاكل، قل بوضوح "تمت المراجعة بنجاح". لا تخترع مشاكل غير موجودة."""
الخطوة الخامسة: الاختبار والتحقق (Test)
بعد اجتياز المراجعة، قم بتوليد كود الاختبار (استخدم GLM-5 لتقليل التكاليف):
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "اكتب اختبارات وحدة باستخدام pytest للكود التالي، مع تغطية المسارات الطبيعية والحالات الحدية."},
{"role": "user", "content": generated_code}
]
)
الخطوة السادسة: المراجعة النهائية البشرية + الدمج
بعد اجتياز مراجعة الذكاء الاصطناعي والاختبارات، يقوم الإنسان بالتأكيد النهائي:
- هل قرارات البنية الهيكلية معقولة؟
- هل يتوافق الكود مع الغرض التجاري؟
- هل هناك مخاطر في السياق لا يستطيع الذكاء الاصطناعي إدراكها؟
🚀 بيانات الكفاءة: الميزة الأساسية لسير العمل هذا هي تركيز انتباه الإنسان على المهام الأكثر قيمة. يقوم الذكاء الاصطناعي بمعالجة 80% من الأعمال الميكانيكية (التوليد، فحص الأسلوب، اكتشاف الأخطاء الأساسية)، بينما يركز الإنسان على 20% من القرارات عالية القيمة (البنية، الأمان، منطق الأعمال). من خلال منصة APIYI (apiyi.com)، يمكنك إدارة استدعاءات API لكل من GLM-5 وClaude 4.6 في مكان واحد، مما يوفر عناء التسجيل وإدارة حسابات متعددة.
Claude Code: الحل الأمثل للبرمجة المدعومة بالذكاء الاصطناعي المتكامل
إذا كنت لا ترغب في بناء سير عمل متعدد النماذج بنفسك، فإن Claude Code يقدم لك حلاً "شاملاً"؛ فهو وكيل برمجة يعمل بالذكاء الاصطناعي داخل الطرفية (Terminal)، قادر على قراءة مستودع الأكواد، وتعديل الملفات، وتشغيل الأوامر، وحل المشكلات بشكل مستقل.

المزايا الجوهرية لـ Claude Code
| القدرة | Claude Code | Cursor | Windsurf |
|---|---|---|---|
| النوع | وكيل مستقل في الطرفية | محرر VS Code معزز | محرر VS Code معزز |
| الفلسفة | تنفيذ ذاتي بواسطة الذكاء الاصطناعي | تحرير بمساعدة الذكاء الاصطناعي | برمجة تعاونية مع الذكاء الاصطناعي |
| السياق | أكثر من 200 ألف رمز (Token) | حوالي 120 ألف رمز | حوالي 100 ألف رمز |
| معالجة الملفات | أكثر من 100 ملف | 30-50 ملف | 30-50 ملف |
| أفضل استخدام | تغييرات معمارية عبر ملفات متعددة | البرمجة اليومية، المهام المركزة | التطوير التكراري، النماذج الأولية |
| السعر | 100-200 دولار/شهر أو حسب الاستهلاك | 20 دولار/شهر | 15 دولار/شهر |
أفضل الممارسات لاستخدام Claude Code
1. امنح الذكاء الاصطناعي طريقة للتحقق من عمله
هذه هي الممارسة الأكثر فعالية التي تؤكد عليها الوثائق الرسمية:
# توجيه جيد
"نفذ ميزة تسجيل المستخدم، واكتب اختبارات pytest المقابلة، وتأكد من نجاح الاختبارات قبل الإرسال"
# توجيه سيئ
"نفذ ميزة تسجيل المستخدم"
2. وضع الجلسة المزدوجة (الكاتب/المراجع)
افتح جلستين من Claude Code:
- الجلسة أ (الكاتب): للتركيز على تنفيذ الميزة.
- الجلسة ب (المراجع): لاستخدام سياق جديد تماماً لمراجعة مخرجات "الكاتب".
هذا النمط الذي يعتمد على "ذكاء اصطناعي يراجع ذكاء اصطناعي آخر" يمكنه اكتشاف النقاط العمياء بفعالية.
3. الاستفادة من إعدادات المشروع CLAUDE.md
# CLAUDE.md
مكدس تقنيات المشروع
Python 3.12 + FastAPI + SQLAlchemy + PostgreSQL
معايير الكود
- تلميحات النوع (Type Hints): يجب أن تحتوي جميع الدوال على تلميحات للنوع.
- معالجة الأخطاء: استخدام فئة
AppErrorمخصصة. - السجلات (Logging): تُستخدم مستوى INFO لأحداث الأعمال، ومستوى DEBUG لأغراض التصحيح.
المحظورات
- لا تستخدم
print()، بل استخدمloggerبدلاً منها. - لا تضع الإعدادات بشكل ثابت (Hard-coding) داخل الكود، استخدم متغيرات البيئة.
- لا تكتب استعلامات SQL مباشرة داخل دوال المسارات (Routes).
**4. قاعدة توزيع الأدوات 80/15/5**
توزيع الأدوات الموصى به من قبل المطورين ذوي الخبرة:
- **80%**: الإكمال التلقائي والتحرير المضمن (Cursor/Copilot) — للبرمجة اليومية.
- **15%**: مهام الوكيل متوسطة التعقيد (Cursor Agent/Windsurf) — لتنفيذ الميزات.
- **5%**: تغييرات بنية الملفات المعقدة (Claude Code) — لإعادة الهيكلة الكبرى.
> 💰 **نصيحة بشأن التكلفة**: يتم احتساب تكلفة نمط API لـ Claude Code بناءً على الرموز (Tokens). إذا قمت بالاتصال عبر APIYI (apiyi.com)، يمكنك الاستمتاع بأسعار نماذج Claude أكثر تنافسية من الأسعار الرسمية. بالنسبة للسيناريوهات التي لا تتطلب الميزات الكاملة لـ Claude Code، يمكنك أيضاً استدعاء Claude Sonnet 4.6 مباشرة عبر API لإجراء المراجعة.
---
## حالة عملية: عملية كاملة لتوليد الكود + المراجعة
يوضح ما يلي سيناريو حقيقياً: استخدام GLM-5 لتوليد وحدة مصادقة مستخدم FastAPI، ثم مراجعتها باستخدام Claude Sonnet 4.6.
### كود سير العمل الكامل
```python
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # واجهة APIYI الموحدة
)
# ===== الخطوة 1: توليد الكود باستخدام GLM-5 =====
gen_response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "أنت خبير في تطوير الواجهات الخلفية بلغة Python."},
{"role": "user", "content": """
قم بتنفيذ نقطة نهاية لتسجيل مستخدم في FastAPI:
- POST /api/v1/register
- استقبال البريد الإلكتروني وكلمة المرور
- تشفير كلمة المرور باستخدام bcrypt
- الحفظ في قاعدة بيانات PostgreSQL
- إرجاع رمز JWT
"""}
],
max_tokens=4096
)
generated_code = gen_response.choices[0].message.content
# ===== الخطوة 2: المراجعة باستخدام Claude Sonnet 4.6 =====
review_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"راجع الكود التالي الذي تم توليده بواسطة الذكاء الاصطناعي:\n\n{generated_code}"}
],
max_tokens=4096
)
review_result = review_response.choices[0].message.content
# استخدام logger بدلاً من print كما هو موصى به في المحظورات
import logging
logging.info(f"=== نتائج المراجعة ===\n{review_result}")
تحليل التكلفة
| الخطوة | النموذج | رموز الإدخال | رموز الإخراج | التكلفة |
|---|---|---|---|---|
| توليد الكود | GLM-5 | ~500 | ~2000 | ~$0.007 |
| مراجعة الكود | Sonnet 4.6 | ~3000 | ~1500 | ~$0.032 |
| الإجمالي | — | — | — | ~$0.04 |
التكلفة الإجمالية لعملية "توليد + مراجعة" واحدة تقل عن 0.04 دولار. حتى لو قمت بـ 50 دورة من هذا النوع يومياً، ستكون التكلفة الشهرية حوالي 60 دولاراً فقط.
إذا استخدمت Claude Opus 4.6 بالكامل، فستكون تكلفة سير العمل نفسه حوالي 0.18 دولار لكل عملية — أي 4.5 ضعف تكلفة الحل المدمج.
🎯 أرقام مفتاحية: باستخدام مزيج GLM-5 للتوليد + Sonnet 4.6 للمراجعة، تبلغ التكلفة 22% فقط من تكلفة استخدام Opus 4.6 بالكامل، بينما جودة المراجعة متطابقة تقريباً. يمكنك إتمام جميع الاستدعاءات باستخدام مفتاح API واحد من منصة APIYI (apiyi.com).
الأسئلة الشائعة
س1: هل جودة الكود الذي تنتجه النماذج الرخيصة كافية للاستخدام؟
حقق نموذج GLM-5 درجة 77.8% في اختبار SWE-bench Verified، وهو أقل بنقطتين مئويتين فقط من Claude Sonnet 4.6، لكن بتكلفة تعادل ثلث السعر فقط. بالنسبة لمعظم مهام توليد الكود (مثل عمليات CRUD، نقاط نهاية API، ومعالجة البيانات)، فإن الجودة كافية تماماً. المفتاح هو وجود مرحلة مراجعة لاحقة لضمان الجودة. يمكنك عبر APIYI (apiyi.com) الوصول إلى كلا النموذجين والتبديل بينهما بمرونة.
س2: في أي سيناريوهات لا ينبغي استخدام النماذج الرخيصة لتوليد الكود؟
في الأكواد الحساسة أمنياً (المصادقة، التشفير، التحكم في الصلاحيات)، ومنطق التزامن والأنظمة الموزعة، والأكواد التي تتطلب دقة عالية في الحسابات المالية. في هذه الحالات، نوصي باستخدام Claude Sonnet 4.6 أو Opus 4.6 مباشرة، أو كتابة الكود يدوياً مع مراجعته بواسطة الذكاء الاصطناعي.
س3: هل Claude Code مناسب للجميع؟
يعد Claude Code الأنسب للمطورين ذوي الخبرة الذين يتعاملون مع مهام معمارية معقدة ومتعددة الملفات. إذا كان عملك يتركز على تعديل ملف واحد والبرمجة اليومية، فقد تكون أدوات مثل Cursor أو Windsurf أكثر ملاءمة (وأقل تكلفة). يستخدم العديد من المطورين المحترفين مزيجاً من الأدوات: Cursor للمهام اليومية، وClaude Code للمهام المعقدة.
س4: كيف يمكن قياس فعالية سير العمل هذا؟
تتبع 4 مؤشرات: (1) التغير في إنتاجية الكود لكل فرد؛ (2) التغير في معدل الأخطاء (عدد العيوب بعد النشر)؛ (3) التغير في وقت المراجعة؛ (4) تكلفة استدعاء النموذج. نوصي بإجراء تجربة لمدة أسبوعين ومقارنة البيانات قبل وبعد التجربة. يمكنك تتبع تكاليف API بسهولة عبر ميزة إحصائيات الاستخدام في APIYI (apiyi.com).
س5: إلى جانب GLM-5، ما هي النماذج الأخرى ذات التكلفة الفعالة لتوليد الكود؟
Claude Haiku 4.5 (سريع جداً، مناسب للمهام البسيطة)، DeepSeek V3 (مفتوح المصدر، قوي في السياق الصيني)، وGPT-5.3 Codex (متخصص في الكود). يعتمد اختيار النموذج على تفضيلاتك اللغوية والسيناريو المحدد. يمكنك عبر APIYI (apiyi.com) الوصول إلى جميع هذه النماذج في مكان واحد، مما يوفر عليك عناء إدارة منصات متعددة.
الخلاصة: الطريقة الصحيحة للبرمجة باستخدام الذكاء الاصطناعي
جوهر البرمجة بالذكاء الاصطناعي ليس "جعل الذكاء الاصطناعي يكتب كل الكود"، بل بناء سير عمل فعال يعتمد على التعاون بين نماذج متعددة. أفضل الممارسات لعام 2026 هي:
معادلة اختيار النموذج:
- 🟢 تردد عالٍ ومخاطر منخفضة (أكواد نمطية، CRUD) ← نماذج ذات تكلفة فعالة مثل GLM-5.
- 🟡 تردد متوسط ومخاطر متوسطة (مراجعة طلبات السحب PR، إعادة الهيكلة) ← Claude Sonnet 4.6.
- 🔴 تردد منخفض ومخاطر عالية (تدقيق أمني، تصميم معماري) ← Claude Opus 4.6.
معادلة سير العمل:
- تحديد المواصفات أولاً، ثم التخطيط، ثم التوليد، ثم المراجعة، ثم الاختبار، وأخيراً المراجعة النهائية من قبل البشر.
- الذكاء الاصطناعي يتولى 80% من المهام الميكانيكية، بينما يركز البشر على 20% من القرارات عالية القيمة.
نوصي بالوصول إلى جميع النماذج الرئيسية مثل GLM-5 وClaude Sonnet 4.6 وOpus 4.6 عبر منصة APIYI (apiyi.com) لبناء سير عمل برمجي متكامل يعتمد على نماذج متعددة.
المراجع
-
Addy Osmani: سير عمل البرمجة باستخدام نماذج اللغة الكبيرة لعام 2026
- الرابط:
addyosmani.com/blog/ai-coding-workflow
- الرابط:
-
أفضل الممارسات الرسمية لـ Claude Code: دليل البرمجة الوكيلة
- الرابط:
code.claude.com/docs/en/best-practices
- الرابط:
-
ورقة GLM-5 التقنية: من "Vibe Coding" إلى البرمجة المدعومة بالذكاء الاصطناعي الهندسي
- الرابط:
arxiv.org
- الرابط:
-
إعلان Anthropic الرسمي: إطلاق Claude Sonnet 4.6
- الرابط:
anthropic.com/news/claude-sonnet-4-6
- الرابط:
-
MIT Technology Review: تقنيات البرمجة التوليدية الرائدة لعام 2026
- الرابط:
technologyreview.com
- الرابط:
المؤلف: فريق APIYI | نستكشف أفضل الممارسات لتمكين تطوير البرمجيات بواسطة الذكاء الاصطناعي، تفضل بزيارة APIYI عبر apiyi.com للحصول على واجهة API موحدة لسلسلة نماذج GLM-5 وClaude 4.6 الكاملة.