
作者注:详解 Gemini 3.1 Flash Image Preview 图像生成 429 限流问题的根因分析,对比 AI Studio、Vertex AI 和第三方平台的限流策略,提供 4 种实测有效的解决方案
用 Gemini 3.1 Flash Image Preview 生成图片时,最让人头疼的不是生成质量,而是刚跑起来就被 429 限流拦住。无论是用 AI Studio 还是 Vertex AI,RPD(每日请求数)和 RPM(每分钟请求数) 的限制都非常严格,批量生图基本跑不动。
本文将从实际使用经验出发,详细分析 429 限流的根因,对比不同平台的限流策略差异,并给出 4 种经过验证的解决方案——包括一个不限并发、价格低至 $0.045/张的方案。
核心价值:读完本文,你将彻底理解 Gemini 图像生成 429 报错的底层逻辑,找到最适合你场景的解决方案。

Gemini 3.1 Flash Image Preview 429 报错是什么
先看一下这个报错长什么样:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
翻译成大白话:你今天的请求次数用完了,或者每分钟请求太频繁了。
和 503 报错不同,429 不是服务器扛不住,而是 Google 主动给你设的配额上限。不管服务器有没有空闲算力,到了限额就直接拒绝。
Gemini 图像生成 429 与 503 报错的区别
| 对比项 | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| 本质原因 | 你的配额用完了 | 服务器算力不足 |
| 触发条件 | 超过 RPD/RPM/TPM 限制 | 全局高负载 |
| 影响范围 | 仅限你的项目 | 所有用户 |
| 能否通过等待解决 | RPM 等 1 分钟,RPD 等到第二天 | 通常几分钟到几小时 |
| 能否通过付费解决 | Vertex AI 可提升配额 | 无法直接解决 |
| 根本解决方案 | 换平台/提升配额 | 等待或换平台 |
Gemini 3.1 Flash Image Preview 各平台限流策略对比
这才是问题的核心——不同平台的限流差异巨大。
Gemini 图像生成 AI Studio 限流参数
AI Studio 是大多数开发者的第一选择,免费好用。但图像生成的限流极其严格:
| 限流维度 | 限制值 | 换算 |
|---|---|---|
| RPM(每分钟请求) | 10 次 | 每 6 秒才能请求 1 次 |
| RPD(每日请求) | 1,500 次 | 跑完约 2.5 小时就到上限 |
| TPM(每分钟 Token) | 4,000,000 | 通常不是瓶颈 |
| 图像输出 TPM | 12,000 tokens/分 | 约 10 张图/分钟 |
实际体验:如果你有 500 张图需要批量生成,按 RPM=10 计算,理论最快需要 50 分钟。但考虑到网络延迟、重试等因素,实际要 1-2 小时。如果一天需要生成超过 1,500 张,直接被 RPD 卡死。
Gemini 图像生成 Vertex AI 限流参数
Vertex AI 是 Google Cloud 的企业级方案,配额更高但也有上限:
| 限流维度 | 默认值 | 可申请提升 |
|---|---|---|
| RPM | 60 次 | 可以,需审批 |
| RPD | 无固定上限 | 但受 RPM 和 TPM 约束 |
| TPM | 4,000,000 | 可以申请 |
| 图像输出 TPM | 24,000 tokens/分 | 可以申请 |
实际体验:RPM 从 10 提升到 60,看起来好很多,但申请提升需要走 Google Cloud 的工单流程,通常 1-3 个工作日。而且 Vertex AI 的配置比 AI Studio 复杂得多(需要创建 GCP 项目、设置服务账号、配置 IAM 权限等),很多个人开发者和小团队直接放弃。
Gemini 图像生成第三方平台限流对比
| 平台 | 并发限制 | RPD 限制 | 单张价格(1K) | 备注 |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1,500/天 | 免费(有限额) | 最严格 |
| Vertex AI | RPM=60 | 无固定上限 | ~$0.067 | 需 GCP 配置 |
| OpenRouter | 取决于套餐 | 取决于套餐 | ~$0.06-0.08 | 通用平台 |
| 稳妥API | 不限并发 | 不限 | $0.045 | 按次计费,不限分辨率 |
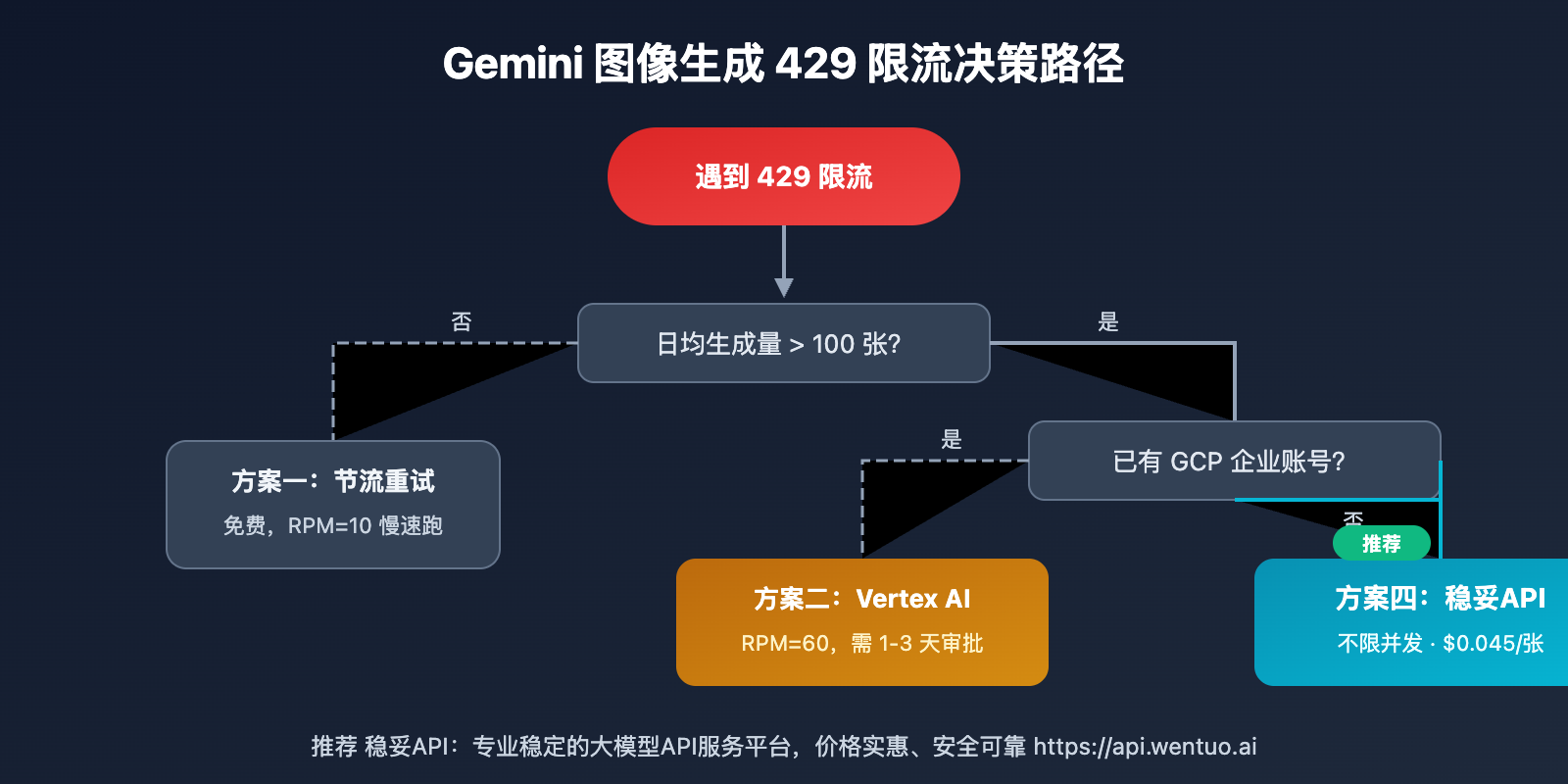
解决 Gemini 3.1 Flash Image Preview 429 限流的 4 种方案
方案一:Gemini 图像生成请求节流 + 自动重试
最基础的方案,不需要换平台,但效率低。
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""带退避重试的图像生成请求"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# 指数退避 + 随机抖动
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 限流,等待 {wait_time:.1f}s 后重试 ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"请求异常: {e}")
time.sleep(2)
raise Exception("超过最大重试次数")
查看完整的批量生成脚本(含速率控制)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""遵守 AI Studio RPM=10 限制的批量生成器"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # 每次请求的最小间隔
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] 等待 {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"异常: {e}")
time.sleep(2)
return False
# 使用示例
gen = RateLimitedGenerator("YOUR_AISTUDIO_KEY", rpm_limit=10)
prompts = ["a sunset over mountains", "a cat in space", "futuristic city"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
优点:零成本,适合小量请求
缺点:速度慢,RPD=1,500 的硬上限无法突破
方案二:Gemini 图像生成迁移到 Vertex AI 提升配额
适合有 Google Cloud 账号的企业用户。
操作步骤:
- 创建 GCP 项目并启用 Vertex AI API
- 设置服务账号和 IAM 权限
- 在 Google Cloud Console → IAM → Quotas 中申请提升 RPM
- 将代码中的端点从 AI Studio 切换到 Vertex AI
优点:RPM 从 10 提升到 60+,企业场景可用
缺点:配置复杂,审批周期 1-3 天,费用按 Google Cloud 标准计费
方案三:Gemini 图像生成多项目轮询
通过创建多个 GCP 项目或 AI Studio API Key,轮流请求来绕过单项目的 RPD/RPM 限制。
import itertools
api_keys = ["KEY_1", "KEY_2", "KEY_3", "KEY_4", "KEY_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""使用 Key 轮询生成图像"""
key = next(key_pool)
# ... 使用当前 key 发送请求
return send_request(prompt, api_key=key)
优点:理论上 N 个 Key 可以获得 N 倍吞吐
缺点:违反 Google 服务条款(TOS),有封号风险;管理多个 Key 增加复杂度
方案四:Gemini 图像生成使用不限并发的第三方平台
这是我最终采用的方案。经过对比多个第三方平台后,选择了 稳妥API wentuo.ai,原因很直接:
| 对比维度 | AI Studio | Vertex AI | 稳妥API |
|---|---|---|---|
| 并发限制 | RPM=10 | RPM=60 | 不限 |
| 每日限制 | 1,500次/天 | 受 RPM 约束 | 不限 |
| 单张价格(含4K) | 免费但有限额 | $0.067-$0.151 | $0.045 |
| 按量计费(1K) | – | $0.067 | 约$0.025 |
| 配置复杂度 | 简单 | 复杂 | 简单 |
| 是否需要翻墙 | 是 | 是 | 否 |
实际使用下来,按次计费 $0.045 一张包含 4K 分辨率,按 Tokens 计费的话大概在 $0.02-$0.05 之间,取决于分辨率。最关键的是不限并发,批量任务可以全速跑,不用再被 429 卡住。
调用方式也很简单,端点换一下就行:
import requests
import base64
API_KEY = "your-wentuo-api-key"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "A cute cat wearing a space helmet"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 使用建议:如果你的日均生成量超过 500 张,或者对并发速度有要求,建议直接使用稳妥API wentuo.ai 的不限并发方案。按次计费 $0.045/张(不限分辨率),按量计费低至 $0.018/张(512px),比 Google 官方节省 33%-70%。
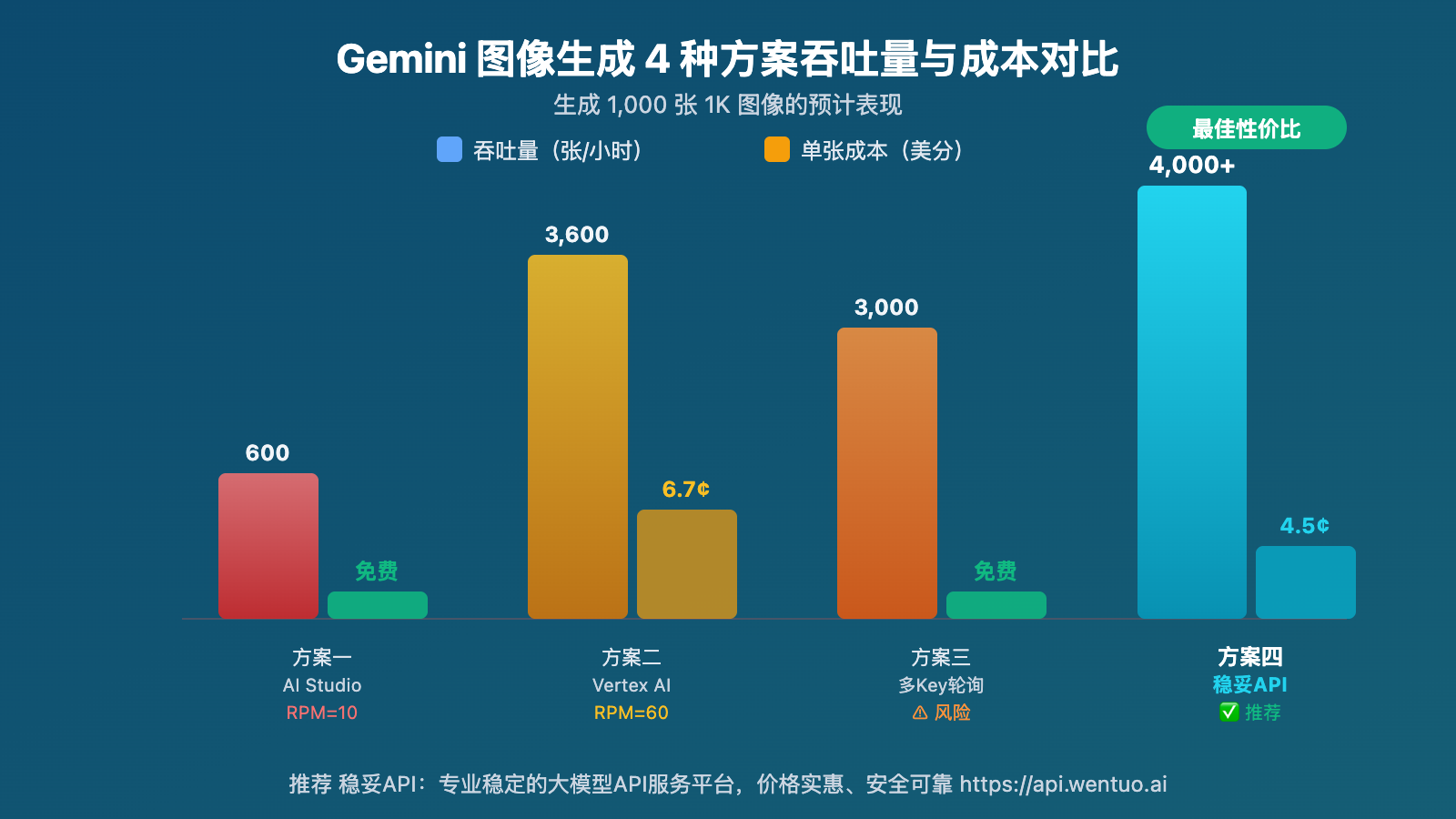
Gemini 3.1 Flash Image Preview 429 限流的 4 种方案选择建议
不同场景适合不同方案:
| 使用场景 | 推荐方案 | 原因 |
|---|---|---|
| 🎨 个人学习/体验 | 方案一(节流重试) | 免费,量小不影响 |
| 🏢 企业已有 GCP | 方案二(Vertex AI) | 合规,可申请高配额 |
| 🔬 临时大量测试 | 方案三(多 Key) | 短期可用,注意风险 |
| 🚀 生产环境/批量生成 | 方案四(稳妥API) | 不限并发,成本最低 |
Gemini 图像生成不同方案的吞吐量对比
假设生成 1,000 张 1K 图像:
| 方案 | 预计耗时 | 总成本 | 可行性 |
|---|---|---|---|
| AI Studio(RPM=10) | ~100 分钟 + RPD 限制可能需要第二天 | 免费 | ⚠️ 受 RPD 限制 |
| Vertex AI(RPM=60) | ~17 分钟 | ~$67 | ✅ 需 GCP |
| 多 Key 轮询(5个 Key) | ~20 分钟 | 免费 | ⚠️ 有封号风险 |
| 稳妥API(不限并发) | ~10-15 分钟 | $45(按次)/ ~$25(按量) | ✅ 推荐 |
常见问题解答
Q1: Gemini 3.1 Flash Image Preview 429 报错后多久能恢复?
取决于触发的是哪种限流:
- RPM 限流:等待 1 分钟后自动恢复
- RPD 限流:需要等到第二天(UTC 时间 0 点)重置
- TPM 限流:等待 1 分钟后恢复
建议在代码中根据 details 字段的 quota_limit 值判断具体是哪种限流,采取对应策略。
Q2: 稳妥API 的图像生成质量和 Google 官方一样吗?
是的,稳妥API wentuo.ai 直接调用的是 Google 官方的 Gemini 3.1 Flash Image Preview 模型,生成质量和官方完全一致。区别仅在于:
- 去掉了 RPD/RPM 限制
- 支持不限并发
- 价格更优惠($0.045/张 vs 官方 $0.067/张@1K)
Q3: 按次计费和按量计费怎么选?
简单的选择逻辑:
- 固定用 2K/4K 分辨率 → 选按次计费($0.045/次,不限分辨率最划算)
- 主要用 512px/1K → 选按量计费(512px 仅 $0.018/次,比按次省 60%)
- 混合分辨率 → 算一下平均成本,通常按量计费更划算
稳妥API wentuo.ai 支持两种计费方式灵活切换。
🎯 总结
Gemini 3.1 Flash Image Preview 的 429 限流问题,本质是 Google 对 AI Studio 和 Vertex AI 设置了严格的配额限制(RPD/RPM)。核心要点:
- 理解限流类型:429 是配额限制(你的问题),503 是服务器过载(Google 的问题),解决方案完全不同
- 评估你的用量:日均 100 张以内用 AI Studio 足够,超过 500 张建议考虑第三方平台
- 选择合适方案:生产环境推荐使用不限并发的方案,避免被限流影响业务
- 成本对比很重要:稳妥API 按次 $0.045/张(含 4K),按量低至 $0.018/张,比官方节省 33%-70%
对于需要批量生成图像的开发者,稳妥API wentuo.ai 是目前综合体验最好的选择——不限并发、价格更低、无需翻墙、接口完全兼容。
📚 参考资料
-
Google Gemini API 官方文档: 图像生成配额和限流说明
- 链接:
ai.google.dev/gemini-api/docs/image-generation - 说明: 官方配额参数和最佳实践
- 链接:
-
Google Cloud 配额管理: Vertex AI 配额申请流程
- 链接:
cloud.google.com/vertex-ai/docs/quotas - 说明: 企业用户提升配额的官方途径
- 链接:
-
稳妥API Nano Banana 2 文档: 不限并发的图像生成接入指南
- 链接:
docs.wentuo.ai - 说明: 按次/按量两种计费方案的详细说明和代码示例
- 链接:
📝 作者简介:技术内容创作团队,专注 AI 图像生成和 API 技术分享。更多技术内容和资源可访问 稳妥API wentuo.ai 了解。
📋 内容说明:本文内容基于实际使用经验整理,具体限流参数可能随 Google 政策调整而变化。如需技术支持,可通过 稳妥API wentuo.ai 获取帮助。