
"Por que meu Claude Code consome 400 mil tokens de entrada a cada solicitação? Por que a fatura está tão alta?" — essa é a reação imediata de muitos usuários do Claude Code ao conferir as estatísticas de uso. Na verdade, a grande maioria desses 400 mil tokens provavelmente já foi processada com sucesso pelo cache, e o custo real pode ser apenas 1/10 do valor aparente. No entanto, se o cache não for atingido, a fatura pode, de fato, ser dolorosa.
Valor central: Ao ler este artigo, você entenderá o mecanismo de cache automático do Claude Code, as 8 causas comuns que levam à falha do cache e 6 dicas práticas para reduzir seus tokens de entrada de 400 mil para 50 mil.

Entendendo o mecanismo de cache automático do Prompt Caching no Claude Code
O Claude Code atinge o cache automaticamente?
Sim. O Claude Code ativa automaticamente o Prompt Caching da Anthropic em cada solicitação de API, sem necessidade de configuração. Este é um comportamento nativo, não um recurso opcional.
Sempre que você envia uma mensagem no Claude Code, o conteúdo enviado para a API é montado na seguinte ordem:
| Ordem de montagem | Conteúdo | Estimativa de tamanho | Comportamento de cache |
|---|---|---|---|
| Nível 1 | Definições de ferramentas (Read/Edit/Bash, etc.) | ~5.000 tokens | Quase estático, alta taxa de acerto |
| Nível 2 | Prompt do sistema + CLAUDE.md | ~3.000-10.000 tokens | Estático na sessão, alta taxa de acerto |
| Nível 3 | Histórico da conversa (todas as mensagens anteriores) | Crescimento contínuo | Correspondência de prefixo, acúmulo gradual |
| Nível 4 | Nova mensagem atual | Variável | Nunca atinge o cache |
Mecanismo chave: O cache é baseado em correspondência de prefixo — desde que os primeiros N tokens da solicitação sejam exatamente iguais ao conteúdo armazenado anteriormente, esses N tokens serão recuperados do cache. Em uma conversa contínua, na 20ª rodada, 95%+ dos tokens de entrada geralmente vêm de acertos de cache.
Preços de cache: por que o acerto de cache é tão importante
| Tipo de operação | Preço de entrada base relativo | Preço real Sonnet 4/MTok | Preço real Opus 4/MTok |
|---|---|---|---|
| Entrada comum (sem cache) | 1x | $3,00 | $15,00 |
| Escrita de cache (5 min) | 1,25x | $3,75 | $18,75 |
| Escrita de cache (1 hora) | 2x | $6,00 | $30,00 |
| Acerto/Leitura de cache | 0,1x | $0,30 | $1,50 |
| Saída | — | $15,00 | $75,00 |
Exemplo prático: Se sua solicitação tiver 400 mil tokens de entrada:
Cenário A: Sem cache
├── 400 mil tokens × $3/MTok (Sonnet) = $1,20 por solicitação
Cenário B: 95% de acerto de cache (sessão típica do Claude Code)
├── Acerto de cache 380 mil tokens × $0,30/MTok = $0,114
├── Escrita de cache 10 mil tokens × $3,75/MTok = $0,0375
├── Nova entrada 10 mil tokens × $3/MTok = $0,03
├── Total = $0,18 por solicitação
└── Custo real é apenas 15% do valor sem cache
🎯 Dica técnica: A invocação do modelo Claude via APIYI apiyi.com também suporta o mecanismo de Prompt Caching, reduzindo o custo de entrada em 90% quando o cache é atingido. Se o seu projeto integra o Claude via API, recomendamos projetar a estrutura do comando para maximizar a taxa de acerto de cache.
TTL de cache: o benefício oculto para usuários Max
| Plano de assinatura | TTL de cache | Custo de escrita | Observação |
|---|---|---|---|
| API Pay-as-you-go | 5 minutos | 1,25x | Cache expira após 5 min de inatividade |
| Pro / Team | 5 minutos | 1,25x | O mesmo acima |
| Max 5x / 20x | 1 hora | 2x | Escrita mais cara, mas janela de acerto 12x maior |
Embora o preço de escrita de cache para usuários Max seja 2x (maior que os 1,25x padrão), o TTL de 1 hora significa que você pode tomar um café e o cache ainda estará lá. Para desenvolvedores com uso intermitente, essa diferença é significativa.
Cada acerto de cache redefine o temporizador de TTL, portanto, enquanto você mantiver o uso ativo, o cache dificilmente expirará.
O cache não funcionou? 8 causas comuns e soluções
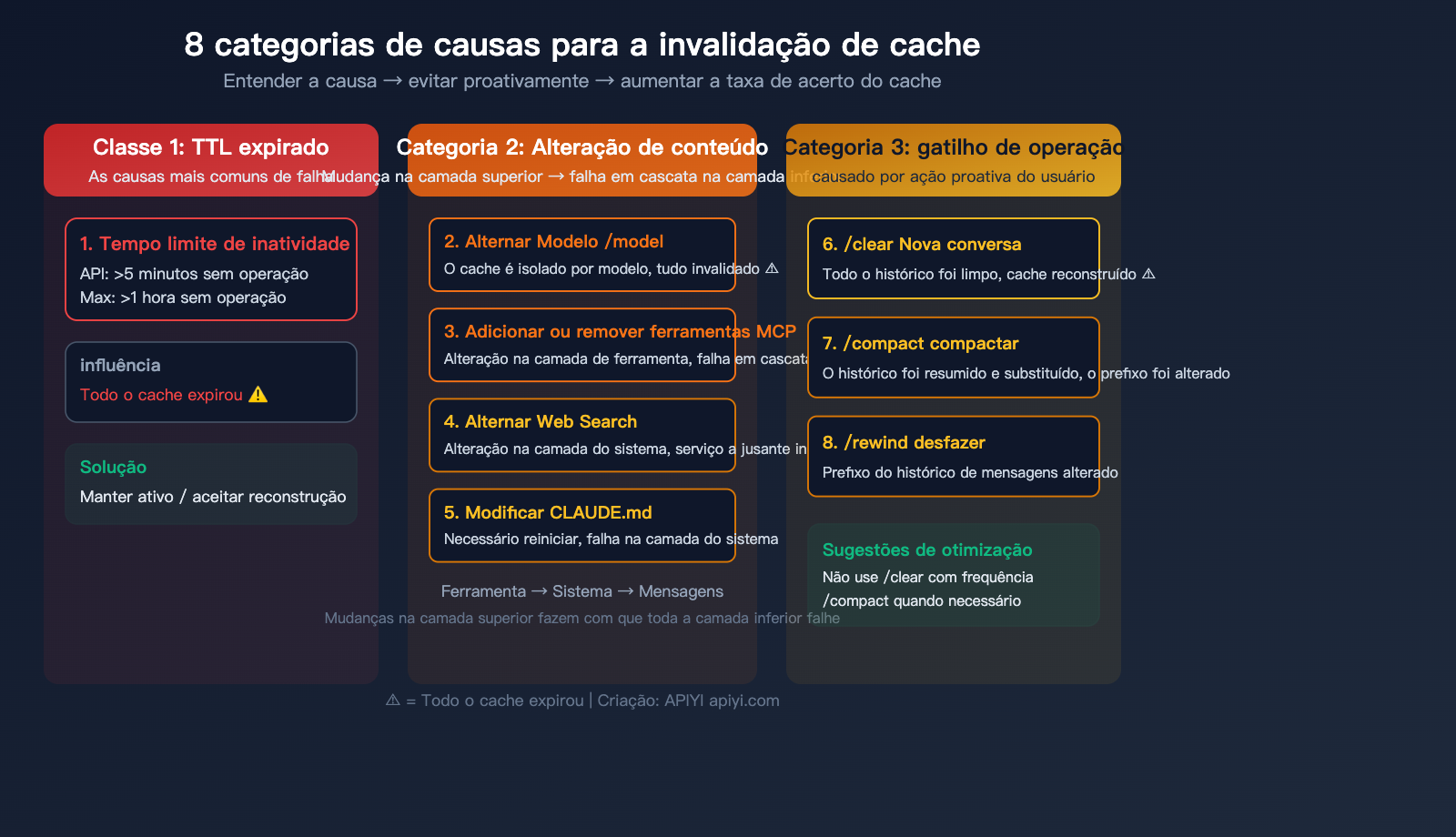
A causa fundamental da falha de cache é apenas uma: o prefixo da solicitação não corresponde ao conteúdo do cache. No Claude Code, as 8 situações a seguir causarão a falha do cache:
Primeira categoria: TTL expirado
| Causa | Condição de disparo | Escopo do impacto | Solução |
|---|---|---|---|
| 1. Timeout de inatividade | Usuário API >5 min sem ação, Usuário Max >1 hora | Todo o cache é invalidado | Mantenha-se ativo ou aceite o custo de reconstrução |
Esta é a causa mais comum de falha de cache. Se você ficar ausente por mais de 5 minutos (usuários API) ou 1 hora (usuários Max) durante a codificação, a próxima solicitação acionará uma reconstrução completa do cache.
Segunda categoria: Falha em cascata por alteração de conteúdo
O cache segue uma estrutura hierárquica rigorosa: Definição de ferramentas → Prompt do sistema → Histórico da conversa. Uma alteração na camada superior invalida todas as camadas inferiores.
| Causa | Condição de disparo | Escopo do impacto | Severidade |
|---|---|---|---|
| 2. Troca de modelo | Comando /model |
Todo o cache (cache isolado por modelo) | ⚠️ Alta |
| 3. Adicionar/remover ferramentas MCP | Instalar ou desinstalar servidor MCP | Camada de ferramentas + tudo abaixo | ⚠️ Alta |
| 4. Alternar Web Search | Ativar ou desativar pesquisa na web | Camada de sistema + tudo abaixo | ⚠️ Média |
| 5. Modificar CLAUDE.md | Reiniciar após editar o arquivo de configuração | Camada de sistema + tudo abaixo | ⚠️ Média |
Terceira categoria: Falhas disparadas por operações
| Causa | Condição de disparo | Escopo do impacto | Severidade |
|---|---|---|---|
| 6. Iniciar nova conversa | /clear ou nova sessão |
Todo o cache (histórico limpo) | ⚠️ Alta |
| 7. Usar /compact | Compactação ativa do histórico | Cache da camada de histórico invalidado | ⚠️ Média |
| 8. Usar /rewind | Desfazer mensagens anteriores | Prefixo do histórico alterado | ⚠️ Média |
Uma limitação técnica fácil de ignorar: comprimento mínimo de cache
Se o seu comando for menor que a quantidade de tokens abaixo, o cache será ignorado silenciosamente, sem qualquer erro:
| Modelo | Comprimento mínimo de cache |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4.096 tokens |
| Claude Sonnet 4.6 | 2.048 tokens |
| Claude Sonnet 4.5 / 4 | 1.024 tokens |
Para o Claude Code, como a definição de ferramentas + prompt do sistema já ultrapassa 5.000 tokens, esse limite quase nunca é atingido. Mas se você estiver construindo aplicações via API, fique atento a esse limite inferior.
💡 Sugestão: Se você estiver criando aplicações próprias via APIYI apiyi.com para chamar a API do Claude, certifique-se de que o comprimento do prompt do sistema exceda o limite mínimo de cache correspondente ao modelo, caso contrário, o cache não entrará em vigor.
Por que você vê 400 mil tokens de entrada: a composição do contexto do Claude Code
Depois de entender o mecanismo de cache, vamos decompor do que exatamente são feitos aqueles "400 mil tokens de entrada" que tanto te assustaram.
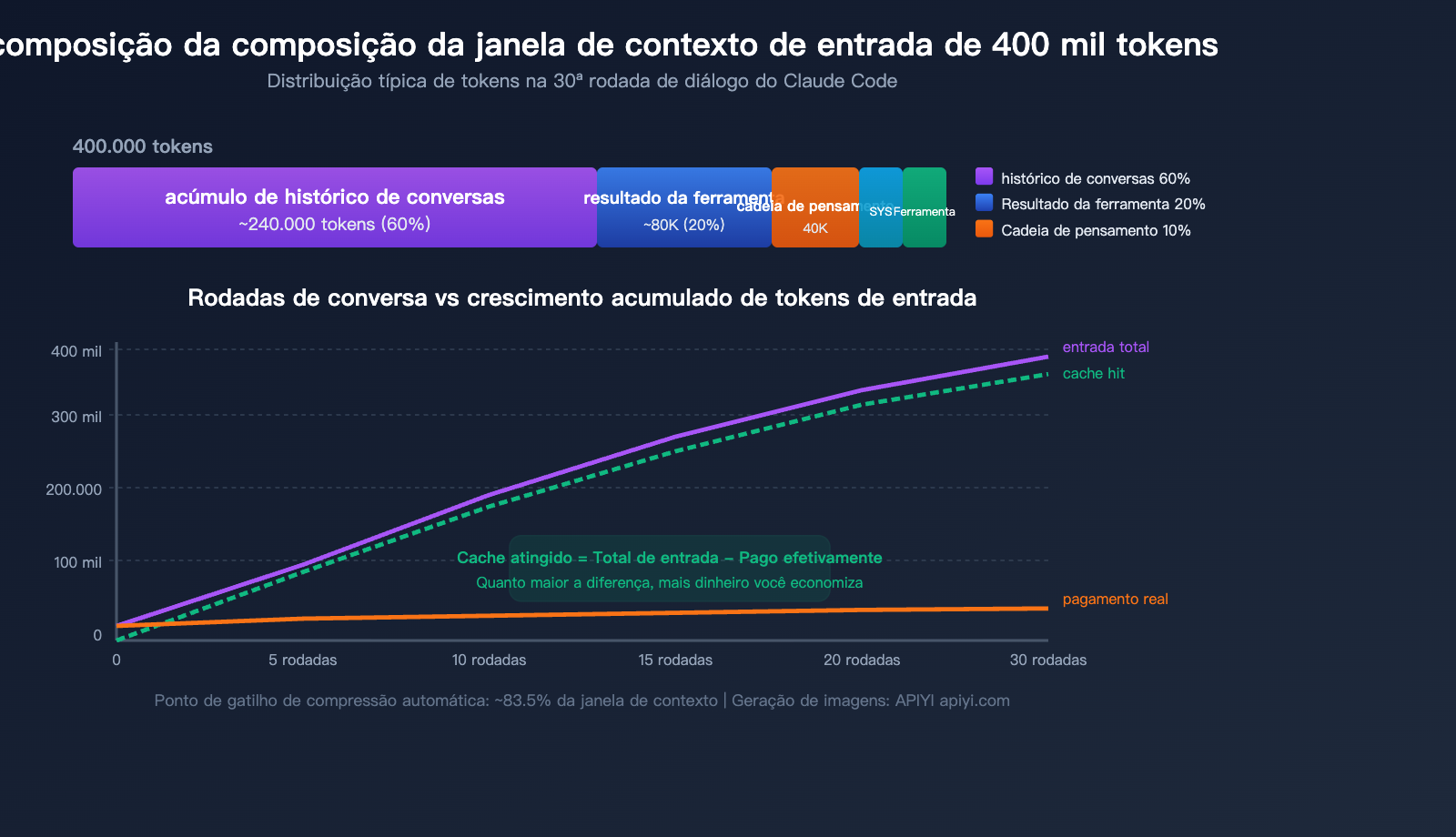
As 5 principais fontes de consumo de tokens
| Fonte | Proporção | Aprox. em 400k | Características |
|---|---|---|---|
| Histórico de conversa acumulado | ~60% | ~240 mil | Todo o histórico é reenviado a cada rodada |
| Resultados de invocação de ferramentas | ~20% | ~80 mil | Leitura de arquivos, resultados de grep permanecem no contexto |
| Cadeia de pensamento estendida | ~10% | ~40 mil | Blocos de pensamento das rodadas anteriores tornam-se entrada |
| System Prompt + CLAUDE.md | ~5% | ~20 mil | Incluído em cada mensagem |
| Definição de ferramentas | ~5% | ~20 mil | Esquema de todas as ferramentas disponíveis |
A verdade central: quanto mais longa a conversa, maior a entrada
O modo de trabalho do Claude Code é reenviar o histórico completo da conversa a cada solicitação. Isso significa que:
- 1ª rodada: entrada de ~20 mil tokens (System Prompt + Definição de ferramentas + sua pergunta)
- 5ª rodada: entrada de ~100 mil tokens (acumulou 4 rodadas de histórico)
- 15ª rodada: entrada de ~250 mil tokens (contém muitos resultados de leitura de arquivos)
- 30ª rodada: entrada de ~400 mil+ tokens (perto do limite de compressão automática)
Mas atenção: a grande maioria dessas entradas tem cache atingido (cache hit). Nos 400 mil tokens da 30ª rodada, talvez apenas 10-20 mil sejam conteúdo novo não armazenado em cache.
O problema específico de grandes bases de código
O Claude Code não carrega automaticamente toda a base de código para o contexto. Ele lê arquivos sob demanda. Contudo, em bases de código grandes:
- Uma busca
greppode retornar muitos resultados, todos entrando no contexto - A leitura exploratória de vários arquivos faz com que o conteúdo de cada um permaneça no histórico da conversa
- No modo Agente, operações autônomas de várias etapas acumulam os resultados de cada invocação de ferramenta
O caso dos seus 400 mil tokens por solicitação provavelmente é uma combinação dos seguintes fatores:
- A base de código é grande e o Claude Code leu muitos arquivos para análise
- Muitas rodadas de conversa, acumulando histórico
- Possível falta de uso dos comandos
/compactou/clear - O arquivo CLAUDE.md pode estar muito extenso
title: "6 dicas práticas: reduza seus tokens de entrada de 400 mil para 50 mil"
description: "Aprenda 6 estratégias eficazes para otimizar o consumo de tokens no Claude Code, economizando custos e mantendo o contexto relevante."
Dica 1: Comandos precisos, evite a varredura global
Esta é a otimização mais importante e a mais fácil de implementar.
❌ Comandos vagos (acionam varredura de arquivos em larga escala):
"Ajude-me a otimizar o desempenho deste projeto"
"Verifique bugs no código"
"Refatore este módulo"
✅ Comandos precisos (leem apenas os arquivos necessários):
"Otimize o tempo de resposta da função processRequest em src/api/handler.ts"
"Corrija a exceção de ponteiro nulo na linha 45 de src/auth/login.ts"
"Migre a função formatDate de moment para dayjs em src/utils/format.ts"
Comandos vagos fazem com que o Claude Code use Glob + Grep + Read em uma enorme quantidade de arquivos para "entender" sua necessidade, e o conteúdo de cada arquivo permanece permanentemente no histórico da conversa. Comandos precisos permitem que ele leia apenas 1 ou 2 arquivos relevantes.
Economia de tokens: Redução de 60-80% nos tokens de resultados de chamadas de ferramentas.
Dica 2: Use /clear e /compact no momento certo
# Limpe a conversa ao mudar para tarefas não relacionadas
/clear
# Comprima o histórico quando a conversa estiver longa, mas a tarefa ainda não terminou
/compact
# Compressão com instruções para preservar informações específicas
/compact preserve exemplos de código e definições de interface de API, o restante pode ser resumido
| Comando | Efeito | Cenário de uso | Observações |
|---|---|---|---|
/clear |
Limpa todo o histórico da conversa | Mudar para uma tarefa completamente diferente | Todo o cache é invalidado |
/compact |
IA resume o histórico e substitui o original | Etapa intermediária de conversas longas | Cache parcialmente invalidado, mas o contexto é drasticamente reduzido |
Efeito prático: Uma conversa de 400 mil tokens geralmente pode ser reduzida para 50-80 mil tokens após um /compact.
Dica 3: Otimize o arquivo CLAUDE.md
O arquivo CLAUDE.md é carregado a cada mensagem. Um CLAUDE.md de 10.000 tokens será enviado 30 vezes em 30 rodadas de conversa (embora o custo seja de apenas 0.1x após o acerto do cache, ele ainda ocupa um espaço valioso no contexto).
Sugestões de otimização:
├── Mantenha o CLAUDE.md com menos de 500 linhas (regras principais)
├── Mova explicações detalhadas de fluxo de trabalho para "Skills" (carregamento sob demanda)
├── Coloque documentos de referência em knowledge-base/ (leia apenas quando necessário)
└── Evite grandes blocos de código de exemplo no CLAUDE.md
🚀 Dica prática: Simplificar o
CLAUDE.mdnão apenas reduz o consumo de tokens,
mas também ajuda o Claude Code a focar nas regras principais.
Se você estiver usando a APIYI (apiyi.com) para construir assistentes de codificação IA semelhantes,
também recomendamos controlar o tamanho do comando do sistema.
Dica 4: Use Subagents para isolar saídas longas
Quando precisar executar operações que geram grandes volumes de saída, use um Subagent em vez de executar diretamente:
❌ Executar diretamente na conversa principal (a saída entra toda no contexto principal):
"Execute a suíte de testes e analise a causa das falhas"
→ A saída do teste pode ter mais de 50.000 tokens, permanecendo permanentemente no histórico
✅ Deixe o Claude Code usar um Subagent (saída isolada em um subprocesso):
"Use uma subtarefa para executar a suíte de testes e resuma para mim apenas os nomes dos testes que falharam e o motivo"
→ O contexto principal aumenta apenas cerca de 500 tokens com o resumo
Economia de tokens: Uma única operação pode evitar que 10.000 a 50.000 tokens entrem no contexto principal.
Dica 5: Escolha o modelo e o nível de esforço adequados
| Tipo de tarefa | Modelo recomendado | Nível de esforço | Explicação |
|---|---|---|---|
| Modificações simples/formatação | Sonnet | low | Não requer raciocínio profundo |
| Desenvolvimento geral | Sonnet | medium | Melhor custo-benefício |
| Design de arquitetura complexa | Opus | high | Requer raciocínio profundo |
| Revisão de código | Sonnet | medium | Custo-benefício superior ao Opus |
# Reduza a profundidade de pensamento para diminuir os tokens de raciocínio (que se tornam entrada depois)
# Defina um esforço menor em tarefas simples
/effort low
# Ou controle o limite de tokens de raciocínio via variáveis de ambiente
MAX_THINKING_TOKENS=8000
A cadeia de pensamento expandida (thinking) torna-se parte dos tokens de entrada nas rodadas subsequentes. Reduzir o nível de esforço pode reduzir significativamente o acúmulo de tokens nas rodadas seguintes.
Dica 6: Use o comando /context para monitorar a distribuição de tokens
# Verifique a distribuição atual de uso de tokens
/context
O comando /context mostrará a proporção de tokens de cada parte no contexto atual, ajudando você a localizar o que está consumindo espaço. Descobertas comuns:
- Uma busca
grepretornou 20.000 tokens, mas apenas 5% eram úteis. - Um arquivo grande lido anteriormente não é mais necessário, mas ainda está no contexto.
- O
CLAUDE.mdestá ocupando um espaço inesperadamente grande.
Após identificar o problema, use /compact ou /clear de forma direcionada.
💰 Dica de custo: Para usuários que pagam por uso de API, essas técnicas de otimização podem reduzir diretamente a fatura.
Através da função de estatísticas de uso da plataforma APIYI (apiyi.com), você pode ver claramente a distribuição de tokens de cada solicitação,
ajudando a identificar os pontos críticos de custo.
Estudo de caso prático: de $60 para $8 por dia
Aqui está um processo de otimização real:
Antes da otimização (Projeto Python grande, usuário intensivo do Claude Code)
Uso diário:
├── Turnos de conversa: ~50 turnos/dia
├── Média de tokens de entrada: 350-450 mil/turno
├── Taxa de acerto de cache: ~70% (devido a /clear frequentes e troca de modelos)
├── Custo diário de API (Opus 4): ~$60
└── Mensal: ~$1.320
Após a otimização (Aplicação de 6 técnicas)
Uso diário:
├── Turnos de conversa: ~40 turnos/dia (mais preciso, menos turnos necessários)
├── Média de tokens de entrada: 80-120 mil/turno (comandos precisos + compactação periódica)
├── Taxa de acerto de cache: ~92% (redução de interrupções desnecessárias no cache)
├── Custo diário de API (foco no Sonnet 4, Opus apenas para tarefas complexas): ~$8
└── Mensal: ~$176
| Item de otimização | Porcentagem de economia | Explicação |
|---|---|---|
| Comandos precisos em vez de varredura vaga | ~35% | Maior ganho |
| Uso oportuno de /compact e /clear | ~25% | Controla o inchaço acumulado |
| Sonnet substituindo Opus (80% das tarefas) | ~20% | Redução de modelo sem perda perceptível |
| Simplificação do CLAUDE.md | ~8% | Reduz o custo fixo por turno |
| Isolamento de saídas longas via Subagent | ~7% | Evita poluir o contexto com blocos grandes |
| Redução do nível de esforço (effort) | ~5% | Reduz o acúmulo de tokens de raciocínio |
Perguntas frequentes
Q1: Os 400 mil tokens exibidos pelo Claude Code são cobrados integralmente?
Não. O Claude Code ativa automaticamente o Prompt Caching. Em uma sessão ativa, mais de 95% dos tokens de entrada geralmente são acertos de cache, custando apenas 0,1x do preço base. Dos 400 mil tokens, talvez apenas 20-40 mil sejam cobrados pelo preço total. Você pode usar /context para verificar a taxa real de acerto de cache. A invocação do modelo via APIYI (apiyi.com) também suporta o mecanismo de cache.
Q2: Preciso me preocupar com o consumo de tokens se uso o plano mensal Max?
Sim, mas por um motivo diferente. O plano mensal Max não cobra por token, mas possui um limite de uso semanal. Um consumo excessivo de tokens fará com que você atinja o limite mais rapidamente. Simplificar o contexto não só prolonga o tempo de uso, mas também ajuda o Claude Code a entender melhor suas necessidades (quanto mais preciso o contexto, melhor a resposta).
Q3: Qual é melhor: /compact ou /clear?
Depende do cenário. Se você vai começar uma tarefa completamente diferente, o /clear é melhor para limpar tudo. Se você ainda está na mesma tarefa, mas a conversa ficou muito longa, use o /compact para manter o contexto essencial enquanto reduz o volume. O /compact suporta comandos personalizados, como /compact manter todo o histórico de modificações de código e definições de interface de API.
Q4: Atualizar para a versão mais recente do Claude Code otimiza automaticamente o uso de tokens?
Sim, recomendo manter sempre a versão mais recente. A Anthropic continua otimizando as estratégias de gerenciamento de contexto do Claude Code, incluindo o momento de disparo da compressão automática (atualmente ocorre quando cerca de 83,5% do contexto está ocupado) e o carregamento tardio de definições de ferramentas MCP (carrega apenas o nome da ferramenta e só busca o esquema completo quando necessário). Versões novas geralmente trazem melhores taxas de acerto de cache e um gerenciamento de contexto mais inteligente.

Resumo: Entender o cache + uso preciso = custos sob controle
O Prompt Caching do Claude Code é um mecanismo de otimização automática extremamente poderoso — você não precisa configurar nada, ele já está economizando dinheiro para você. Mas entender como ele funciona e quais são as condições de invalidação pode ajudar a elevar sua economia de "70% automático" para "95% proativo".
Lembre-se destes 3 princípios fundamentais:
- Mantenha o cache ativo: Evite ações desnecessárias que interrompam o cache (trocar de modelo com frequência, usar /clear sem necessidade).
- Controle a expansão do contexto: Use comandos precisos e o comando /compact regularmente para não deixar o histórico da conversa crescer infinitamente.
- Escolha as ferramentas e modelos certos: O Sonnet é suficiente para 80% das tarefas; deixe o Opus para os cenários que realmente exigem sua capacidade.
Para usuários que pagam pelo uso da API, recomendamos gerenciar as invocações do modelo Claude através da APIYI (apiyi.com), aproveitando os recursos de monitoramento de uso da plataforma para otimizar continuamente o consumo de tokens. Para usuários intensivos de ferramentas interativas, sugerimos o plano mensal Claude Max, combinando-o com as técnicas de otimização deste artigo para obter o melhor custo-benefício.
📝 Autor deste artigo: Equipe técnica da APIYI | APIYI apiyi.com – Plataforma de acesso unificado a mais de 300 APIs de Modelos de Linguagem Grande.
Referências
-
Documentação do Prompt Caching da Anthropic: Detalhes sobre o mecanismo de cache oficial.
- Link:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Descrição: TTL do cache, taxas de precificação e requisitos de comprimento mínimo.
- Link:
-
Guia de gerenciamento de custos do Claude Code: Sugestões oficiais de otimização de tokens.
- Link:
code.claude.com/docs/en/costs - Descrição: Estratégias de controle de custos recomendadas pela Anthropic.
- Link:
-
Melhores práticas do Claude Code: Gerenciamento de contexto e otimização de eficiência.
- Link:
anthropic.com/engineering/claude-code-best-practices - Descrição: Inclui dicas práticas como comandos precisos e o uso do compact.
- Link: