
title: "Guia definitivo: Entenda o TTL do cache de prompts do Claude e como economizar"
description: "Entenda o mecanismo de TTL do cache de prompts do Claude, as diferenças entre 5 minutos e 1 hora, e como otimizar custos no Claude Code e na API."
Autor: Nota do autor: Detalhamento do mecanismo de TTL do cache de prompts do Claude, a diferença entre as faixas de 5 minutos e 1 hora, comparação de cobrança entre a API da Anthropic e o AWS Bedrock, com sugestões de configuração para economizar.
"O TTL do cache de prompts do Claude pode ser alterado? Qual a diferença entre 5 minutos e 1 hora? Qual é o mais vantajoso?" — estas são as perguntas mais frequentes de muitos usuários do Claude Code ao tentarem controlar os custos.
Primeiro, a conclusão: O TTL do cache do Claude Code não pode ser alterado diretamente pelo usuário — ele é determinado pelo seu plano de assinatura. Usuários do plano Max recebem automaticamente 1 hora de TTL, enquanto usuários do plano Pro e da chave API têm 5 minutos de TTL por padrão. No entanto, se você chamar a API do Claude diretamente, pode escolher livremente entre 5 minutos ou 1 hora através do parâmetro cache_control.
Valor central: Ao terminar de ler este artigo, você entenderá completamente o mecanismo de TTL do cache de prompts do Claude, terá clareza sobre as diferenças de cobrança entre a API oficial da Anthropic e o AWS Bedrock, e aprenderá a escolher a estratégia de cache mais econômica de acordo com o seu cenário de uso.
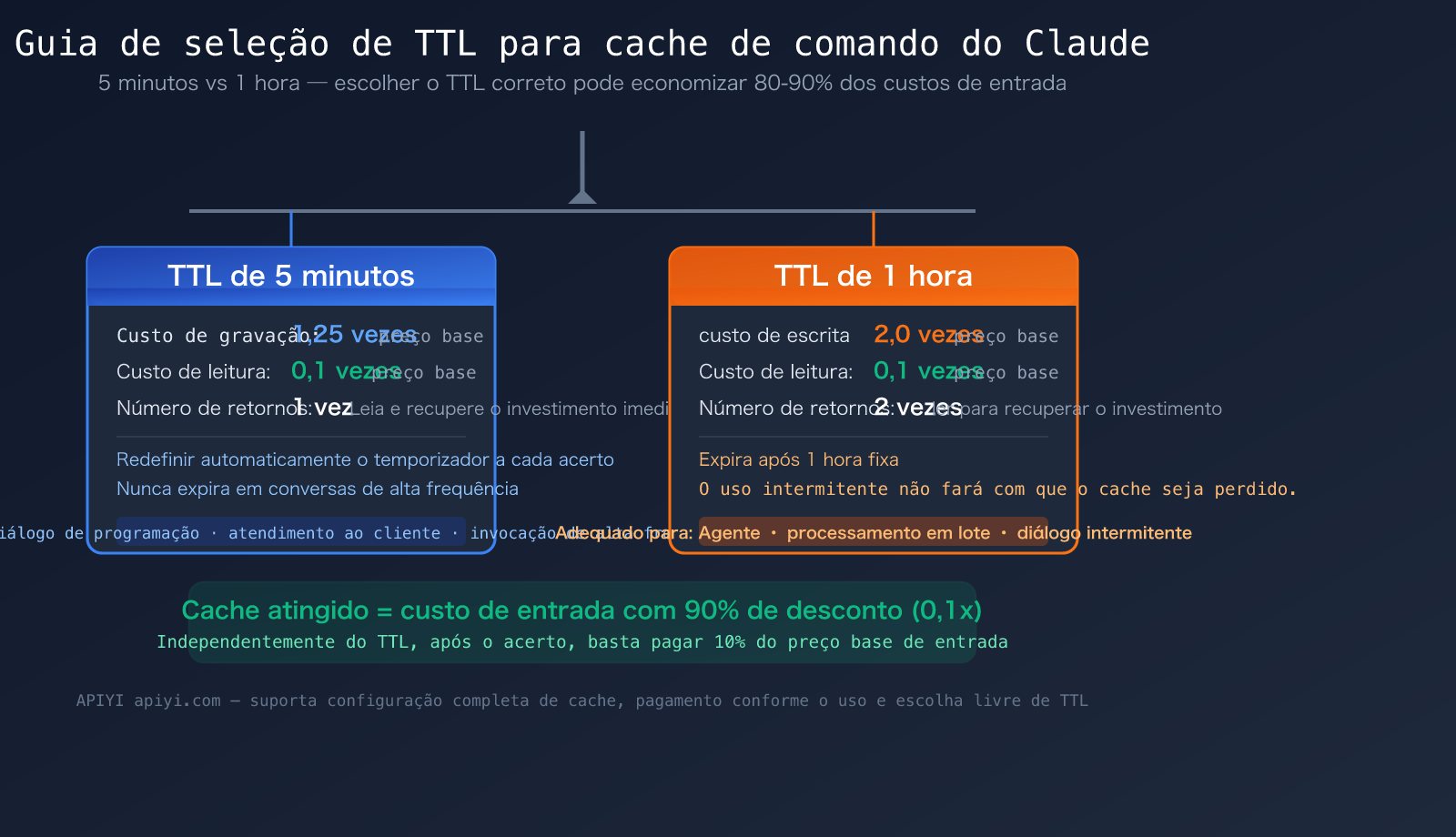
Pontos principais do TTL do cache de prompts do Claude
O cache de prompts é um dos mecanismos de economia mais importantes da família de modelos Claude. Ele armazena o prefixo do prompt que você enviou anteriormente (prompts do sistema, definições de ferramentas, histórico de conversas, etc.) no servidor. Na próxima solicitação, se o prefixo for o mesmo, ele será lido diretamente do cache, pagando apenas 10% do preço normal de entrada.
| Ponto | Explicação | Impacto real |
|---|---|---|
| Duas faixas de TTL | 5 minutos (padrão) e 1 hora (opcional) | Escolher o TTL correto pode economizar muito nos custos de escrita |
| Leitura de cache a 10% | Após atingir o cache, essa parte da entrada custa apenas 0,1x do preço | Pode economizar 80-90% nos custos de entrada em conversas longas |
| Escrita de 5 min = 1,25x | 25% de ágio ao gravar no cache | O custo se paga com uma única leitura de cache |
| Escrita de 1 hora = 2x | Preço dobrado ao gravar no cache | Requer duas leituras de cache para se pagar |
| Gerenciamento automático do Claude Code | Prompts do sistema, ferramentas e CLAUDE.md são armazenados automaticamente | O usuário não precisa configurar manualmente |
O TTL no Claude Code pode ser alterado?
Esta é a pergunta que mais preocupa os usuários. A resposta depende de dois cenários:
Claude Code (ferramenta CLI interativa): Não pode ser alterado manualmente. O cache do Claude Code é controlado pelo servidor — usuários do plano Max recebem 1 hora de TTL (controlado pela flag de recurso do servidor tengu_prompt_cache_1h_config), enquanto usuários do plano Pro e da chave API recebem 5 minutos de TTL. Você só pode desativar o cache completamente através da variável de ambiente DISABLE_PROMPT_CACHING=1, mas não pode alternar entre as faixas de TTL.
Claude API (chamada direta): Pode ser escolhido livremente. Ao chamar via API, você pode especificar o TTL no parâmetro cache_control:
// Cache de 5 minutos (padrão)
{ "cache_control": { "type": "ephemeral" } }
// Cache de 1 hora
{ "cache_control": { "type": "ephemeral", "ttl": "1h" } }
🎯 Sugestão de escolha: Se você usa principalmente o Claude Code CLI, o TTL depende do seu plano de assinatura. Se você faz chamadas via API (como através da APIYI apiyi.com), pode escolher flexivelmente entre 5 minutos ou 1 hora de TTL de acordo com o cenário, alcançando um controle de custos mais refinado.

Detalhes das regras de cobrança do TTL de cache de comandos do Claude
5 minutos vs 1 hora: Comparação de custos
A principal diferença entre os dois TTLs reside no custo de gravação. O custo de leitura é exatamente o mesmo, sendo 0,1 vez o preço base de entrada:
| Operação | TTL de 5 minutos | TTL de 1 hora | Explicação |
|---|---|---|---|
| Gravação em cache | 1,25x o preço base | 2,0x o preço base | Sobretaxa na primeira gravação no cache |
| Leitura do cache | 0,1x o preço base | 0,1x o preço base | Preço com desconto após o acerto (igual) |
| Ponto de equilíbrio | 1 leitura paga o custo | 2 leituras pagam o custo | A frequência de uso define qual é mais vantajoso |
| Renovação automática | Reinicia 5 min a cada acerto | Expira fixo em 1 hora | Em conversas frequentes, 5 min pode durar indefinidamente |
Preços específicos de cache de comandos por modelo
Abaixo está a tabela completa de cobrança de cache para os modelos da API oficial da Anthropic (março de 2026):
| Modelo | Preço base de entrada | Gravação 5 min | Gravação 1 hora | Leitura do cache | Preço de saída |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $6,25/MTok | $10/MTok | $0,50/MTok | $25/MTok |
| Claude Sonnet 4.6 | $3/MTok | $3,75/MTok | $6/MTok | $0,30/MTok | $15/MTok |
| Claude Haiku 4.5 | $1/MTok | $1,25/MTok | $2/MTok | $0,10/MTok | $5/MTok |
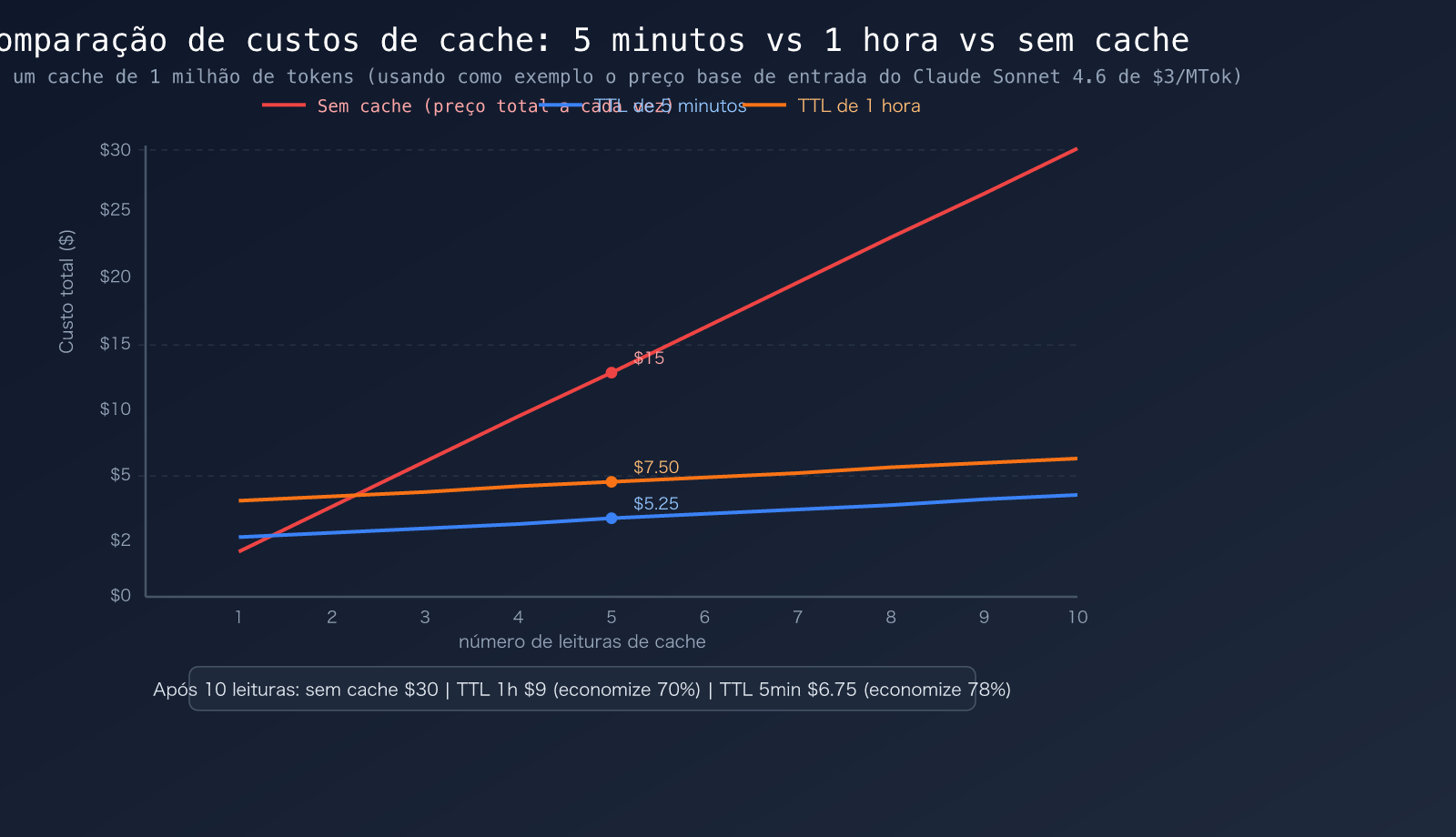
Descoberta importante: O desconto na leitura do cache é impressionante. Tomando o Claude Opus 4.6 como exemplo:
- Entrada normal de 1 milhão de tokens = $5,00
- Leitura do cache de 1 milhão de tokens = $0,50 (economia de $4,50, desconto de 90%)
- É por isso que a assinatura mensal de $20 do Claude Code Pro é economicamente viável — 100 rodadas de conversa com o Opus sem cache poderiam custar de $50 a $100, mas com o cache, custam apenas de $10 a $19.
Requisito mínimo de tokens para cache
Nem todo conteúdo pode ser armazenado em cache. Cada modelo possui um requisito mínimo de tokens; se o conteúdo não for longo o suficiente, o cache não será acionado:
| Modelo | Mínimo de tokens para cache |
|---|---|
| Claude Opus 4.6 / 4.5 | 4.096 |
| Claude Sonnet 4.6 | 2.048 |
| Claude Sonnet 4.5 / 4 | 1.024 |
| Claude Haiku 4.5 | 4.096 |
| Claude Haiku 3.5 / 3 | 2.048 |
🎯 Dica prática: Se o seu comando de sistema for curto (menos de 2.048 tokens), ele não acionará o cache ao usar o Claude Sonnet 4.6. Você pode enriquecer o conteúdo do comando de sistema ou combinar definições de ferramentas para atingir o limite mínimo. Ao realizar a invocação do modelo via APIYI (apiyi.com), o cache também é suportado com taxas ainda melhores.
Anthropic API vs AWS Bedrock: Comparação de cobrança de cache
Comparação de suporte a cache entre as três grandes plataformas
O cache de comandos do Claude é suportado nas plataformas API oficial da Anthropic, AWS Bedrock e Google Vertex AI, mas existem diferenças nos detalhes:
| Dimensão de comparação | API oficial da Anthropic | AWS Bedrock | Google Vertex AI |
|---|---|---|---|
| TTL de 5 minutos | ✅ Suportado em todos | ✅ Suportado em todos | ✅ Suportado em todos |
| TTL de 1 hora | ✅ Suportado em todos | ✅ Alguns modelos (Opus 4.5, Sonnet 4.5, Haiku 4.5) | ✅ Suportado |
| Sobretaxa de gravação (5 min) | 1,25x | ~1,25x | 1,25x |
| Sobretaxa de gravação (1 hora) | 2,0x | 2,0x | 2,0x |
| Desconto de leitura | 0,1x | ~0,1x | 0,1x |
| Máximo de pontos de interrupção | 4 | 4 | 4 |
| Cache automático | ✅ Suportado | ✅ Suportado | ✅ Suportado |
| TTL personalizado | ✅ Opção de 5 min/1 hora | ✅ Opcional (alguns modelos) | ✅ Opcional |
Explicação das principais diferenças entre plataformas
API oficial da Anthropic: A funcionalidade de cache é a mais completa, com suporte para TTL de 5 minutos e 1 hora em todos os modelos. Desde 5 de fevereiro de 2026, o isolamento do cache mudou do nível de organização para o nível de espaço de trabalho; caches de espaços de trabalho diferentes na mesma organização são independentes.
AWS Bedrock: Anunciou suporte para TTL de 1 hora em janeiro de 2026, mas limitado a alguns modelos, como Claude Opus 4.5, Sonnet 4.5 e Haiku 4.5. O suporte para TTL de 1 hora no Claude Sonnet 4.6 e Opus 4.6 mais recentes no Bedrock ainda precisa ser confirmado. Se você estiver conectando o Claude Code ao Bedrock, fique atento à configuração de compatibilidade CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1.
Google Vertex AI: A funcionalidade de cache é basicamente idêntica à da API oficial, mas requer autenticação e cobrança através de um projeto do Google Cloud.
🎯 Sugestão de escolha de plataforma: Se você não quer se preocupar com diferenças de plataforma e configurações de compatibilidade, a invocação via interface unificada da APIYI (apiyi.com) é a solução mais simples — suporta a funcionalidade completa de cache sem a necessidade de configurar separadamente o AWS IAM ou a autenticação do Google Cloud.
title: "Guia Rápido: Cache de Prompts no Claude Code"
description: "Aprenda a otimizar custos e reduzir a latência usando o cache de prompts no Claude Code com exemplos práticos de TTL de 5 minutos e 1 hora."
Guia Rápido: Cache de Prompts no Claude Code
Exemplo Minimalista: Configurando Cache com TTL de 1 hora
import anthropic
client = anthropic.Anthropic(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": "Você é um assistente professor de física profissional, responsável por responder questões de física do ensino médio...(aqui entra o comando de sistema longo)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
}],
messages=[{"role": "user", "content": "Explique a terceira lei de Newton"}]
)
print(f"Tokens lidos do cache: {response.usage.cache_read_input_tokens}")
print(f"Tokens gravados no cache: {response.usage.cache_creation_input_tokens}")
Ver código completo: Uso misto de TTL de 5 minutos e 1 hora
import anthropic
client = anthropic.Anthropic(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# TTL misto: comando de sistema com 1 hora (raramente muda), contexto da conversa com 5 minutos (muda frequentemente)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "Você é um consultor técnico de IA profissional...(comando de sistema longo, 2000+ tokens)",
"cache_control": {"type": "ephemeral", "ttl": "1h"} # Comando de sistema com 1 hora
},
{
"type": "text",
"text": "Abaixo está o contexto do histórico de conversas do usuário...(histórico da conversa)",
"cache_control": {"type": "ephemeral"} # Contexto da conversa com 5 minutos (padrão)
}
],
messages=[{"role": "user", "content": "Compare as capacidades de raciocínio do Claude e do GPT"}]
)
# Verificar uso do cache
usage = response.usage
print(f"Tokens de entrada comuns: {usage.input_tokens}")
print(f"Tokens lidos do cache: {usage.cache_read_input_tokens}")
print(f"Tokens gravados no cache: {usage.cache_creation_input_tokens}")
# Calcular economia (usando o Sonnet 4.6 como exemplo)
base_cost = (usage.input_tokens / 1_000_000) * 3
cache_cost = (usage.cache_read_input_tokens / 1_000_000) * 0.3
saved = (usage.cache_read_input_tokens / 1_000_000) * 2.7
print(f"Economia nesta chamada: ${saved:.4f}")
Restrição importante: Ao misturar dois tipos de TTL na mesma solicitação, o conteúdo com cache de 1 hora deve ser colocado antes do conteúdo com cache de 5 minutos; caso contrário, um erro será retornado.
Dica: Ao realizar a invocação do modelo via APIYI (apiyi.com), o parâmetro
cache_controlé totalmente suportado, permitindo a escolha livre entre TTLs de 5 minutos e 1 hora.
TTL de 5 minutos vs 1 hora: Qual escolher?
Tabela de Decisão
| Cenário de Uso | TTL Recomendado | Motivo |
|---|---|---|
| Programação de alta frequência no Claude Code | 5 minutos | O cronômetro reseta a cada acerto, mantendo o cache ativo |
| Chatbot de atendimento (intervalo < 5 min) | 5 minutos | Custo de gravação baixo (1,25x), alta taxa de acerto |
| Agente de análise de documentos (intervalo 5-60 min) | 1 hora | Evita que o cache expire e precise ser regravado |
| Tarefas de processamento em lote (a cada 30 min) | 1 hora | O TTL de 5 min expiraria, o de 1 hora cobre o período |
| Chamadas de API de baixa frequência (intervalo > 1h) | Sem cache | Ambos expirariam, gerando custo de gravação desnecessário |
| Comando de sistema (quase imutável) | 1 hora | Grava uma vez e lê várias vezes |
| Histórico de conversa (muda a cada rodada) | 5 minutos | Custo de gravação menor compensa em mudanças frequentes |
Fórmulas de Custo
Para saber se o cache vale a pena, use estas fórmulas:
Condição de retorno do investimento (ROI) para TTL de 5 min: O conteúdo deve ser lido pelo menos 1 vez em 5 minutos.
- Custo de gravação: 1,25x → 0,25x extra
- Economia na leitura: 0,9x por leitura
- 1 leitura paga o investimento (0,9 > 0,25)
Condição de retorno do investimento (ROI) para TTL de 1 hora: O conteúdo deve ser lido pelo menos 2 vezes em 1 hora.
- Custo de gravação: 2,0x → 1,0x extra
- Economia na leitura: 0,9x por leitura
- 2 leituras pagam o investimento (0,9 × 2 = 1,8 > 1,0)
Perguntas Frequentes
Q1: É possível alterar o TTL de 5 minutos para 1 hora no Claude Code?
A ferramenta CLI do Claude Code não permite que o usuário altere o TTL manualmente. Assinantes do plano Max recebem automaticamente 1 hora de TTL (controlado por feature flag no servidor), enquanto usuários Pro e de chave API ficam fixos em 5 minutos. Se você precisa de 1 hora de TTL, mas não quer assinar o plano Max, pode realizar a invocação do modelo diretamente via API (definindo cache_control.ttl: "1h") e pagar pelo uso em plataformas como a APIYI (apiyi.com).
Q2: O TTL de 5 minutos expira exatamente após 5 minutos? Ou ele renova automaticamente?
O TTL de 5 minutos reinicia o temporizador a cada vez que o cache é acessado. Se você enviar uma mensagem a cada 1 ou 2 minutos (como em uma conversa de programação no Claude Code), o temporizador é reiniciado constantemente e o cache nunca expira. O cache só perde a validade se você ficar 5 minutos sem enviar nenhuma mensagem. Portanto, para cenários de uso frequente, o TTL de 5 minutos é mais do que suficiente.
Q3: A cobrança de cache no AWS Bedrock é igual à da API oficial da Anthropic?
É praticamente igual, mas com pequenas diferenças:
- O ágio na escrita é de ~1,25x (5 minutos) e ~2,0x (1 hora) em ambos.
- O desconto na leitura é de ~0,1x em ambos.
- Diferença: O TTL de 1 hora no Bedrock atualmente suporta apenas modelos como Opus 4.5, Sonnet 4.5 e Haiku 4.5; para a série 4.6 mais recente, é necessário verificar a compatibilidade.
- Ao utilizar a APIYI (apiyi.com), você obtém suporte completo ao cache, de forma idêntica à API oficial.
Resumo
Pontos principais sobre o TTL de cache de comandos do Claude:
- Duas opções de TTL: 5 minutos (escrita 1,25x, recupera o custo com 1 leitura) e 1 hora (escrita 2x, recupera o custo com 2 leituras); em ambos, a leitura custa 0,1x.
- CLI do Claude Code não permite alterar o TTL: Assinantes Max têm 1 hora automaticamente, Pro/chave API ficam fixos em 5 minutos; não é possível alternar, apenas desativar.
- Liberdade na API do Claude: Você pode definir o TTL via parâmetro
cache_control.ttle até misturar os dois tipos de TTL na mesma requisição. - Escolha 5 minutos para conversas frequentes: O cache é renovado a cada acesso, reduzindo o custo de escrita; escolha 1 hora para usos esporádicos para evitar expiração.
Cache atingido = 90% de desconto no custo de entrada, sendo este o principal mecanismo de economia do Claude. Recomendamos utilizar a APIYI (apiyi.com) para uma interface unificada, com suporte completo às configurações de cache, permitindo testar a diferença de custos entre diferentes estratégias de TTL com uma única chave.
📚 Referências
-
Documentação oficial da Anthropic – Prompt Caching: Fonte autoritativa sobre configuração de TTL, regras de cobrança e sintaxe
cache_control.- Link:
platform.claude.com/docs/en/build-with-claude/prompt-caching - Descrição: Fórmulas de cobrança completas e exemplos de código para TTL de 5 minutos/1 hora.
- Link:
-
Documentação oficial da Anthropic – Preços: Preços base e preços de cache para todos os modelos.
- Link:
platform.claude.com/docs/en/about-claude/pricing - Descrição: Taxas de escrita e leitura de cache para os modelos Opus, Sonnet e Haiku.
- Link:
-
Documentação oficial da AWS – Bedrock Prompt Caching: Detalhes sobre o suporte a cache na plataforma Bedrock.
- Link:
docs.aws.amazon.com/bedrock/latest/userguide/prompt-caching.html - Descrição: Intervalos de suporte a TTL e padrões de cobrança para cada modelo no Bedrock.
- Link:
-
Claude Code Camp – Como funciona o cache de comandos: Análise profunda sobre a implementação de cache no Claude Code.
- Link:
claudecodecamp.com/p/how-prompt-caching-actually-works-in-claude-code - Descrição: Entenda como o Claude Code gerencia automaticamente os pontos de interrupção de cache.
- Link:
-
GitHub Issue #19436 – Solicitação de recurso de TTL de cache em várias camadas: Discussão da comunidade sobre configurações de TTL mais flexíveis.
- Link:
github.com/anthropics/claude-code/issues/19436 - Descrição: Proposta da comunidade para um esquema de TTL em várias camadas baseado na frequência de alteração do conteúdo.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir suas experiências com a configuração de cache do Claude na seção de comentários. Para mais tutoriais sobre invocação do modelo, visite a central de documentação da APIYI em docs.apiyi.com.