
作者注:本文系统讲解 gpt-image-2 图片分层的真实原理、Python 后台处理现象、API 调用方式和成本优化方案,帮助开发者避免把工具链能力误认为模型原生能力。
如果你最近在使用 gpt-image-2 做海报、科研图、产品图或幻灯片,可能已经看到一个很有意思的现象:有人声称它能“图片分层”,甚至能在后台通过 Python 把一张图拆成可编辑对象。
这件事乍看像模型突然学会了 Photoshop,但实际更接近一个多工具链工作流:gpt-image-2 负责生成或编辑高质量图片,Python 脚本负责 OCR、背景修补、元素分割、SVG/PPTX/PSD 重建等后处理。
这不是又一篇入门科普,而是从 API 能力、图层原理、Python 后处理、成本计算和工程落地角度,完整拆解 gpt-image-2 图片分层到底能做到什么、不能做到什么。
核心价值:读完本文,你将明确 gpt-image-2 图片分层的边界,知道如何用 APIYI apiyi.com 接入 gpt-image-2 官转 API,并设计一套可上线的“图片生成到可编辑素材”流程。
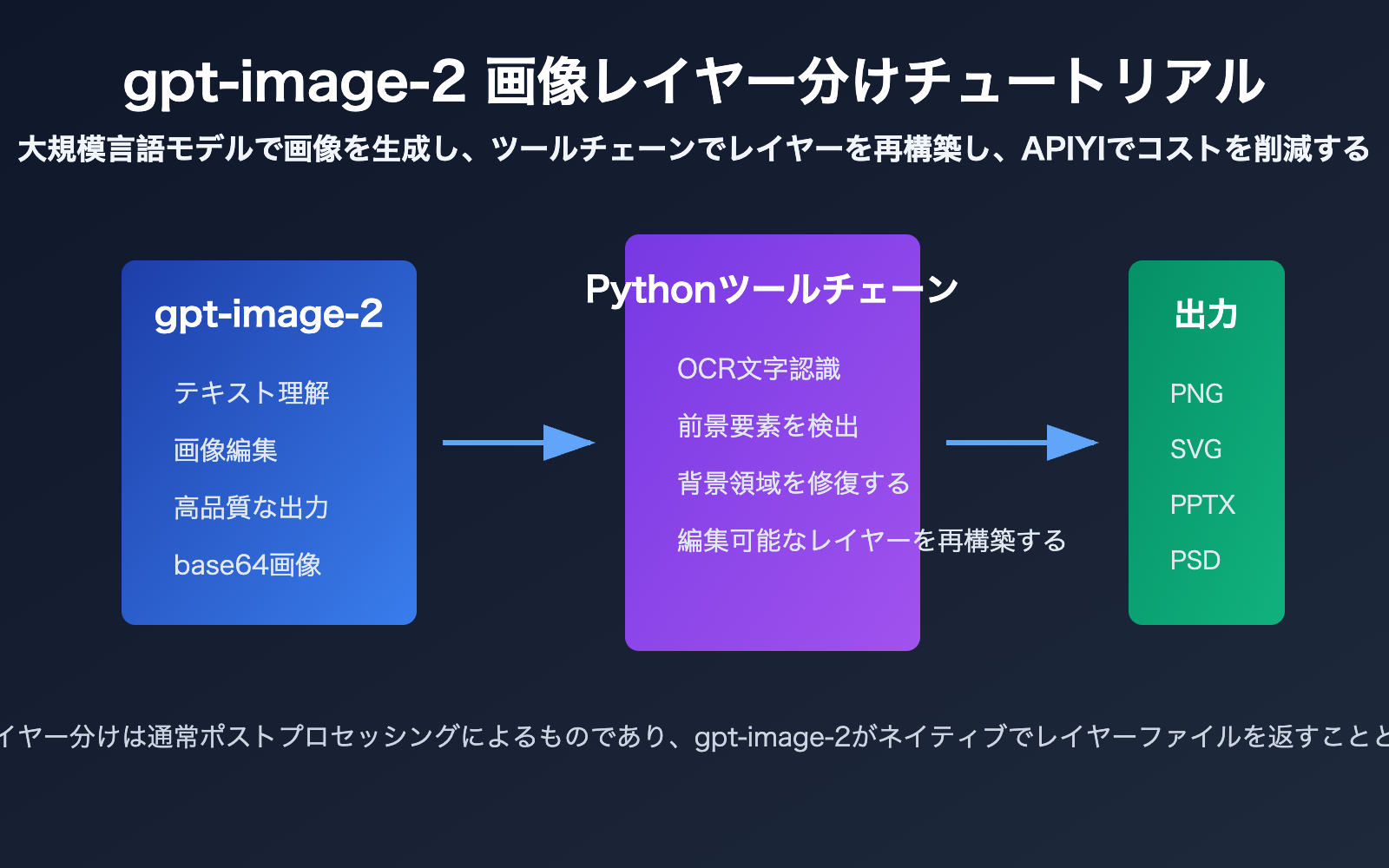
gpt-image-2 图片分层核心要点
gpt-image-2 图片分层的关键,是先区分“模型输出”和“产品工作流输出”。
OpenAI 官方模型页将 gpt-image-2 定义为用于快速、高质量图像生成与编辑的图像模型,支持文本输入、图像输入和图像输出,并可用于 Images API 的生成与编辑端点。
但从当前公开 API 形态看,开发者拿到的核心结果仍是图片数据,而不是 Photoshop 式的多图层工程文件。
| 要点 | 说明 | 对开发者的价值 |
|---|---|---|
| 模型原生能力 | gpt-image-2 负责理解提示词、参考图和编辑意图,输出最终图像 | 适合生成海报、产品图、插画和视觉稿 |
| 接口输出形态 | 官方文档围绕 b64_json、图片格式、尺寸、质量、token 用量等字段展开 |
便于服务端保存、上传、审计和计费 |
| 图片分层来源 | 多数可编辑图层来自 OCR、分割、修补、矢量化、PPTX/PSD 写入等后处理 | 能解释“为什么后台会跑 Python” |
| 成本优化方式 | 官转 API 可按官方原价口径接入,并结合充值赠送降低实际成本 | 适合批量生成、测试和生产集成 |
gpt-image-2 图片分层不是原生 PSD 输出
gpt-image-2 图片分层最容易被误解的一点,是把“最终用户看到的可编辑文件”当成“模型直接吐出的文件”。
在工程上,这两者完全不同。
模型直接输出的是一张图像,通常以 base64 图片数据或图片文件形式被应用接收。
如果某个产品可以把它变成 PPTX、SVG 或 PSD,通常说明产品在模型之后加了一层后处理系统。
这层系统可能由 Python 完成,因为 Python 在图像处理、OCR、深度学习推理和办公文档生成方面生态成熟。
例如,工程师可能先用 OCR 识别文字,再用 inpainting 把原图里的文字区域补干净,然后用 python-pptx 重建文本框和图片层。
这类流程可以让用户感觉“图片被分层了”,但本质上是从扁平图片反推可编辑结构。
这种反推并不总是完美。
文字越清晰、背景越简单、版式越规则,分层效果越好。
如果图片里有复杂纹理、半透明阴影、手写字、细碎装饰或高度重叠对象,后处理就很容易出现误检、漏检和边缘瑕疵。
gpt-image-2 图片分层需要关注模型与工具链边界
开发者做 gpt-image-2 图片分层时,应该把系统拆成两段。
第一段是生成段:让 gpt-image-2 输出视觉质量足够高、结构足够清晰、文本尽量准确的图片。
第二段是结构化段:用 Python 或其他后处理工具把扁平图片转换成可编辑对象。
两段目标不同,评估指标也不同。
生成段重点看提示词遵循、构图、文字准确率、画面一致性和输出成本。
结构化段重点看文字可编辑率、对象拆分准确率、背景修补自然度、导出文件兼容性和人工修正成本。
技术建议:如果你要验证 gpt-image-2 图片分层链路,建议先通过 APIYI apiyi.com 接入 gpt-image-2 官转 API 跑通生成和编辑,再逐步叠加 OCR、分割、修补和导出模块。这样能把模型问题和后处理问题分开排查。
gpt-image-2 画像レイヤー分けの仕組み
gpt-image-2 の画像レイヤー分けは、「フラットな画像から構造化された素材へ」と変換するリバースエンジニアリングと捉えることができます。
これは単なる背景削除(切り抜き)ではなく、視覚的な理解、従来の画像処理、そしてドキュメント生成を組み合わせた包括的なプロセスです。

gpt-image-2 画像レイヤー分けのステップ1:レイヤー分けに適した画像の生成
gpt-image-2 のレイヤー分けをより安定させるには、生成段階から後処理を見据える必要があります。
プロンプトでは、レイアウトが明確であること、要素の境界がはっきりしていること、テキスト領域が独立していること、背景のテクスチャが複雑すぎないことを明示的に要求しましょう。
PPTX や SVG を作成する場合、フラットデザイン、明確な色分け、控えめな影やグラデーションの使用を推奨します。
PSD を作成する場合、主体、背景、テキスト、装飾要素の関係性を明確に記述してください。
よくある誤解として、モデルに非常に複雑な映画ポスターを生成させ、後処理ツールが自動的に完璧なレイヤーに分割してくれることを期待するケースがあります。
しかし、現在の技術環境では、これは現実的ではありません。
レイヤー分けの効果は、入力画像の解析しやすさに大きく依存します。
gpt-image-2 画像レイヤー分けのステップ2:テキストとオブジェクトの検出
Python バックエンドにおける最も一般的な最初のタスクは「検出」です。
テキスト検出では、通常 OCR モデルを使用して文字の内容、位置、フォントサイズ、テキストボックスの境界を識別します。
オブジェクト検出やセグメンテーションでは、人物、製品、アイコン、線、背景領域などの視覚的オブジェクトを識別します。
スライドやインフォグラフィックの場合、タイトル、段落、表、矢印、座標軸、凡例なども識別対象となります。
このレイヤーは、gpt-image-2 自体が「レイヤーを返した」のではなく、後処理モデルがピクセルからレイヤーを推論したものです。
推論が正確であればあるほど、最終的にエクスポートされる PPTX、SVG、または PSD は元のデザイン案に忠実になります。
推論が不正確な場合、テキストボックスの位置ズレ、フォントの不一致、背景補完の痕跡、アイコンの断片化といった問題が発生しやすくなります。
gpt-image-2 画像レイヤー分けのステップ3:背景の補完とファイルの再構築
OCR でテキスト領域が識別された後、テキストを編集可能にするには、通常、元の画像からテキストを消去する必要があります。
テキストを消去すると背景に穴が開くため、インペインティング(画像補完)アルゴリズムを使用して背景を補完します。
その後、システムは識別したテキストを独立したテキストボックスとして PPTX、SVG、または PSD に書き戻します。
より詳細なオブジェクトレイヤーが必要な場合は、前景要素のマスクを生成してオブジェクトを切り抜き、別のレイヤーとして書き込む必要があります。
このプロセスは「モデルがレイヤー分けをしている」ように聞こえますが、正確には「モデルによる画像生成 + Python による画像解析 + ドキュメントライブラリによるレイヤー再構築」という流れになります。
gpt-image-2 画像レイヤー分けのクイックスタート
開発者向けに、gpt-image-2 画像レイヤー分けの最小構成フローを紹介します。
- API を通じて画像を取得する。
- 画像をローカルファイルとして保存する。
- OCR、セグメンテーション、補完、エクスポートモジュールに渡す。
gpt-image-2 画像レイヤー分けの最小限の API サンプル
以下のサンプルは、統一インターフェースを通じて gpt-image-2 の公式転送 API を呼び出す例です。
from openai import OpenAI
import base64
# APIYIのクライアント設定
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 画像生成の呼び出し
result = client.images.generate(
model="gpt-image-2",
prompt="レイヤー分けに適した製品発表ポスターを生成。単色背景、テキスト領域は明確、要素の境界をはっきりとさせる",
size="1024x1024",
quality="medium",
output_format="png"
)
# 画像の保存
image_bytes = base64.b64decode(result.data[0].b64_json)
open("poster.png", "wb").write(image_bytes)
このコードのポイントは「すぐに PSD を手に入れる」ことではなく、後処理に適した鮮明な画像をまず得ることです。
サーバー側で引き続き Python が呼び出される場合、通常は OCR、マスク生成、インペインティング、またはエクスポートの段階に入っています。
gpt-image-2 画像レイヤー分けの処理フレームワーク
以下は、実際のプロジェクトに近い処理の骨組みです。特定の OCR やセグメンテーションモデルには依存せず、モジュールの境界を示しています。
from pathlib import Path
def generate_image(prompt: str) -> Path:
"""gpt-image-2 APIを呼び出し、フラットな画像を保存する"""
# client = OpenAI(api_key="YOUR_APIYI_KEY", base_url="https://vip.apiyi.com/v1")
# response = client.images.generate(model="gpt-image-2", prompt=prompt)
return Path("poster.png")
def detect_layout(image_path: Path) -> dict:
"""OCR、オブジェクト検出、レイアウト認識"""
return {"texts": [], "objects": [], "background_regions": []}
def rebuild_editable_file(image_path: Path, layout: dict) -> Path:
"""背景を補完し、SVG、PPTX、またはPSDとしてエクスポートする"""
return Path("poster-editable.pptx")
# 実行フロー
prompt = "文字が鮮明で要素が分離された、レイヤー編集に適したAI製品ポスター"
image_path = generate_image(prompt)
layout = detect_layout(image_path)
editable_path = rebuild_editable_file(image_path, layout)
print(editable_path)
本番環境では、generate_image と rebuild_editable_file を非同期タスクとして分割することをお勧めします。
画像の生成自体に時間がかかる場合があり、後処理も CPU や GPU を消費するためです。
ポスターや商品画像、研究用図表を大量に生成する必要があるチームの場合、API 呼び出しと後処理タスクをキューに入れ、各ステップの処理時間と失敗原因を記録するのがベストプラクティスです。
クイックスタートのヒント: APIYI (apiyi.com) の gpt-image-2 API は、まず生成段階を確立するのに最適です。その後、独自の Python レイヤー分けモジュールを接続することで、モデルの能力を活かしつつ、編集可能なファイルロジックを自社システムで制御できるようになります。
gpt-image-2 画像レイヤー分けのプロンプトテンプレート
最終的な目標が「レイヤー分け可能」である場合、プロンプトは通常の画像生成よりも抑制的である必要があります。
| 目標 | 推奨されるプロンプトの書き方 | 非推奨の書き方 |
|---|---|---|
| ポスターのレイヤー分け | 背景は単色または単純なグラデーション、タイトルは独立、製品の輪郭を明確に | 複雑な映画風ポスター、テクスチャや煙が多い |
| PPT のレイヤー分け | フラットなインフォグラフィック風、明確なタイトル、アイコン、矢印、3つの説明文 | 芸術性が高く抽象的なビジュアル |
| 商品画像のレイヤー分け | 製品を中央に配置、背景はクリーン、影は柔らかく、境界を明確に | 製品と背景を強く融合させる |
| SVG 再構築 | 幾何学図形、線、色面、少量のテキスト、写真テクスチャを避ける | 細かいテクスチャ、複雑な人物、透明素材 |
優れたプロンプトは、後処理の難易度を大幅に下げます。
エンジニアリングの観点から見ると、「生成に適した画像」と「レイヤー分けに適した画像」は必ずしも同じではありません。
一般ユーザーは視覚的なインパクトを求めますが、レイヤー分けシステムは構造の明瞭さを求めます。
自動化された素材生成を行うのであれば、構造の明瞭さを優先すべきです。
gpt-image-2 画像レイヤー分割におけるPythonバックエンドの現象分析
ユーザーがPythonでgpt-image-2の画像レイヤー分割を処理している様子を目にする場合、通常3つの可能性があります。
1つ目は、APIラッパー(封装)スクリプトです。
開発者はコードの重複を減らすため、gpt-image-2を呼び出し、画像の自動保存、パラメータの記録、エラー処理、再試行を行うPythonスクリプトを作成します。このスクリプトは、モデル内部でPythonが動作していることを意味するわけではありません。
2つ目は、画像後処理スクリプトです。
例えば、出力された画像をOCR、セグメンテーションモデル、背景補完モデル、ベクトル化ツール、またはPPTX/PSD生成ライブラリに渡すケースです。このスクリプトこそが「レイヤー感」の主な源泉です。
3つ目は、エージェントワークフロースクリプトです。
ChatGPT、Codex、Claude Codeなどのエージェントツールを通じて画像生成を呼び出す場合、エージェントが自動的にPythonツールを選択して、ダウンロード、変換、切り抜き、コラージュ、またはファイル生成を行うことがあります。これは製品レベルのツール呼び出しであり、gpt-image-2 APIがネイティブでマルチレイヤーを返しているわけではありません。
なぜgpt-image-2の画像レイヤー分割にPythonがよく使われるのか
Pythonがgpt-image-2の画像レイヤー分割に適しているのは、神秘的だからではなく、エコシステムが完結しているからです。
| 処理フェーズ | 一般的なPythonタスク | 典型的な価値 |
|---|---|---|
| API呼び出し | Images APIの呼び出し、base64画像の保存、リクエストパラメータの記録 | 安定した画像生成 |
| OCR | 文字内容、位置、テキストボックスの認識 | 画像内の文字を編集可能なテキストに変換 |
| セグメンテーション | 主体、背景、アイコン、線のマスク生成 | 視覚オブジェクトの分離 |
| 補完 | 文字やオブジェクトを消去した後の背景補完 | クリーンなベース画像の形成 |
| エクスポート | SVG、PPTX、PSDなどの形式への書き出し | 編集可能なファイルの納品 |
このフローの利点は柔軟性です。開発者はビジネスシナリオに応じて、異なるOCRモデル、セグメンテーションモデル、エクスポート形式を選択できます。
欠点は、結果の安定性がgpt-image-2だけで決まらないことです。OCRが誤字を認識したり、背景補完に失敗したりすると、元の画像の品質が良くても、最終的な編集可能ファイルに問題が生じます。
gpt-image-2の画像レイヤー分割は、セキュリティ戦略の「layers」とは別物
もう一つ混同しやすい言葉に「layers」があります。
OpenAIのセキュリティ資料では、image input layers、image output layers、multiple layers of protectionといった表現が使われます。ここでのlayersは、セキュリティ検出層、入出力検出層、または防御層を指しており、Photoshopのレイヤーではありません。
英語のlayersを見て「画像レイヤー」と直訳してしまうと、誤解を招きやすくなります。技術選定を行う際は、常にAPIフィールドと出力形式に立ち返ることをお勧めします。インターフェースがレイヤーリスト、マスクリスト、オブジェクトツリー、またはPSDファイルを返さない限り、それはネイティブな画像レイヤー分割インターフェースとは見なせません。
gpt-image-2画像レイヤー分割の信頼性判断基準
gpt-image-2の画像レイヤー分割スキームが信頼できるかどうかは、以下の4つの指標で判断できます。
- 原画像出力と後処理出力を明確に区別しているか。
- OCRテキスト層、背景ベース層、前景オブジェクト層など、各レイヤーのソースを提示できるか。
- 人手による修正を許可しているか。
- 同一画像に対するレイヤー分割結果を再現できるか。
システムが「AI自動レイヤー分割」と謳うだけで、OCR、マスク、補完、エクスポートのロジックを説明しない場合、開発者は慎重に評価する必要があります。
提案: 実際のプロジェクトでは、公式転送チャネルを通じてgpt-image-2の安定した生成能力を取得し、Pythonのレイヤー分割能力を内部サービスとして構築することをお勧めします。これにより、公式チャネルの能力を活用しつつ、後処理のブラックボックスを単一ツールに依存させないようにできます。
gpt-image-2 画像レイヤー分割APIのコストと約14%OFF(86折)の考え方
gpt-image-2の画像レイヤー分割コストは分けて計算する必要があります。
モデル生成がコストの一部であり、OCR、セグメンテーション、補完、エクスポート、ストレージがもう一つのコストです。最終的な「編集可能ファイル1つあたりのコスト」だけを見ていると、予算を見誤りやすくなります。
gpt-image-2 画像レイヤー分割の公式価格の目安
OpenAIの公式API価格ページによると、gpt-image-2の公開価格には、画像入力、キャッシュされた画像入力、画像出力、テキスト入力、キャッシュされたテキスト入力が含まれます。
| 課金項目 | 公式価格の目安 | 画像レイヤー分割における意味 |
|---|---|---|
| Image input | 8.00ドル / 100万トークン | 参照画像、編集画像、素材画像の入力時に発生 |
| Cached image input | 2.00ドル / 100万トークン | 再利用可能なキャッシュ画像入力コスト |
| Image output | 30.00ドル / 100万トークン | 出力画像そのものの主要コスト |
| Text input | 5.00ドル / 100万トークン | プロンプト、編集指示、レイアウト説明 |
| Cached text input | 1.25ドル / 100万トークン | キャッシュ可能なプロンプトのコスト最適化余地 |
公式価格は予算の基礎となります。しかし、実際のプロジェクトでは、失敗時の再試行、バッチキュー、後処理の計算リソース、人手による検収、ストレージコストも考慮する必要があります。ポスターのバリエーションを頻繁に生成する必要がある場合は、プロンプト、サイズ、品質、再試行戦略でコスト管理を行うことをお勧めします。
gpt-image-2 画像レイヤー分割で官転(公式転送)APIを使用する場合のコスト
APIYI (apiyi.com) のgpt-image-2官転APIは、公式の価格基準で利用でき、公式モデルのチャネルを維持しつつ、接続の複雑さを軽減したいチームに適しています。
ユーザーが言及しているチャージキャンペーンは「100ドルチャージで10%のボーナス付与」です。厳密に「100ドル支払って110ドルの利用可能残高」と計算すると、実質的な単位コストは公式価格の約90.9%となります。プラットフォームのキャンペーン表示や総合的な割引率を考慮すると、対外的には公式価格の約14%OFF(86折)の割引範囲と理解できます。詳細は実際のチャージ額とプラットフォームの決済ルールに基づきます。
| 接続方法 | 価格基準 | メリット | 注意点 |
|---|---|---|---|
| OpenAI公式API | 公式価格 | ネイティブチャネル、ドキュメント完備 | アカウント、支払い、枠、リスク管理を自前で処理 |
| gpt-image-2官転API | 公式価格基準 | 接続が速く、インターフェースが統一され管理が容易 | プラットフォームのルールに従いチャージ・決済 |
| チャージキャンペーン | 100ドルで10%還元 | 実質的な単位コストを削減可能 | 割引率は実際の付与額に基づく |
| 自前リバースエンジニアリング | 不定 | 柔軟性が高い | コンプライアンス、安定性、保守コストが高い |
コストに関するアドバイス: gpt-image-2の画像レイヤー分割の製品化テストを行う場合は、まずAPIYI (apiyi.com) の官転APIを使用して50〜100枚のサンプルを実行し、各画像の生成コスト、レイヤー分割の成功率、人手による修正時間を記録してから、バッチ呼び出しを拡大するかどうかを決定することをお勧めします。
gpt-image-2 画像レイヤー分割のコスト最適化リスト
コスト最適化は単価だけを見てはいけません。無駄な生成を減らすことがより重要です。
- 構造化プロンプトを使用して、構図の不明瞭さによる再試行を減らす。
- まず中品質でレイアウト検証を行い、最終バージョンで品質を上げる。
- テンプレートプロンプトをキャッシュして、重複するテキスト入力コストを削減する。
- 同一製品画像に対して統一された参照画像とレイアウト仕様を使用し、後処理の難易度を下げる。
- 失敗サンプルを分類し、モデル生成の失敗か、Pythonレイヤー分割の失敗かを区別する。
- 編集可能な納品が必要なシナリオでは、フラットなインフォグラフィック形式を優先する。
これらの手法は、単に単価を追求するよりもはるかに効果的です。
gpt-image-2 画像レイヤー化ソリューションの比較
gpt-image-2 に対する画像レイヤー化の要求は、チームや用途によって異なります。
タイトルだけを変更したいという人もいれば、PPTX形式でエクスポートしたい人、完全なPSDファイルを求める人、あるいは単に構造が明確なSVGが欲しいという人もいます。
以下の比較表を参考に、最適なルートを選択してください。

gpt-image-2 画像レイヤー化ルート1:画像編集を継続する
部分的な修正のみが必要な場合、最も簡単な方法はレイヤー化ではなく、gpt-image-2 で引き続き編集を行うことです。
例えば、タイトルの変更、色の調整、背景の入れ替え、製品画像の差し替え、小さなアイコンの追加などは、画像編集APIを通じてすべて完結できます。
このルートはコストが最も低く、システムの複雑さも最小限に抑えられます。
デメリットは、編集のたびに部分または画像全体を再生成する必要があり、デザインソフトのように個別のレイヤーを正確に選択できない点です。
コンテンツ運用、SNS用画像、簡易的なポスター作成などのシーンに適しています。
gpt-image-2 画像レイヤー化ルート2:SVGまたはPPTXへのエクスポート
画像がグラフ、フローチャート、研究用ポスター、インフォグラフィックである場合、SVG/PPTXへの再構築はPSDよりも実用的です。
なぜなら、これらの画像要素は通常、テキスト、アイコン、線、矩形、矢印、および少数の装飾で構成されているからです。
OCRでテキストを認識し、ベクトル化で線や色面を再構築し、PPTXライブラリで編集可能なテキストボックスを作成できます。
このルートは、企業のナレッジベース、研究発表、営業資料、研修用教材に適しています。
すべてのピクセルを100%再現するのではなく、「編集可能」で「見た目が十分に近い」ことを目指します。
gpt-image-2 画像レイヤー化ルート3:PSDまたはマルチレイヤー素材パッケージの生成
PSDのレイヤー化は最も複雑です。
人物、製品、背景、テキスト、影、装飾をそれぞれ別々のレイヤーに分割するには、システムに高度な分割および補完能力が求められます。
複雑な写真スタイルの画像において、自動PSD生成でデザイナーレベルの品質を実現するのは困難です。
より現実的な戦略は「半自動PSD」の生成です。システムが背景、被写体、テキスト、およびいくつかの主要なオブジェクトを分割し、デザイナーが手動で修正を加えるという手法です。
このルートは、ブランドデザイン、ECサイトのメイン画像、広告クリエイティブ、および長期的に再利用が必要な高価値素材に適しています。
gpt-image-2 画像レイヤー化に関するよくある質問
gpt-image-2 の画像レイヤー化で直接PSDを出力できますか?
現在の公開APIの形態から見ると、「直接PSDレイヤーファイルを出力する」ものとして理解すべきではありません。
公式ドキュメントで強調されているのは、画像生成、画像編集、base64画像データ、出力形式、サイズ、品質、およびトークン消費量です。
もし特定の製品でPSDエクスポートが可能であれば、それは通常、Photoshop、PSD書き込みライブラリ、または独自の後処理モジュールを別途組み込んでいるためです。
gpt-image-2 画像レイヤー化のPythonはモデル内部のコードですか?
一般的には違います。
ユーザーが目にするPythonは、外部のワークフロー用スクリプトである可能性が高いです。
APIの呼び出し、画像の保存、OCRの実行、マスク生成、背景の補完、図形のベクトル化、またはPPTX/PSDへの書き込みなどを担当している可能性があります。
これらのスクリプトはアプリケーション層に属するものであり、モデル本体ではありません。
gpt-image-2 の画像レイヤー化が本物のレイヤーのように見えるのはなぜですか?
後処理システムがピクセルから構造を再構築できるからです。
例えば、テキスト認識後に編集可能なテキストボックスに変換したり、製品主体をマスクによって独立した画像レイヤーにしたり、背景を補完してきれいな下地にしたりできます。
これらを重ね合わせることで、デザインソフトからエクスポートしたプロジェクトファイルのように見せることができます。
gpt-image-2 の画像レイヤー化はすべての画像に適していますか?
適していません。
レイヤー化に適した画像は、通常、明確なレイアウト、はっきりとした境界線、少量のテキスト、複雑ではない背景、要素が過度に重なっていないといった特徴を持っています。
複雑な写真、テクスチャの強いイラスト、透明な素材、大量の細かい装飾、高度に芸術的な構図の画像は、レイヤー化には向きません。
gpt-image-2 の画像レイヤー化の成功率を高めるには?
まずはプロンプトの最適化から始めましょう。
モデルに対し、構造が明確で境界がはっきりしており、テキスト領域が独立し、背景の複雑さが低い出力を要求します。
また、画像サイズやスタイルを制限し、後処理システムが過剰な詳細に直面しないようにします。
最後に、サンプルセットを使用してOCRの精度、オブジェクト分割の精度、および手動修正にかかる時間を評価します。
API呼び出し層では、gpt-image-2 のAPI中継サービスを一元管理し、コストや失敗サンプルを記録しやすくすることをお勧めします。
gpt-image-2 の画像レイヤー化は必ずAPIを使う必要がありますか?
個人の生成がたまに行われる程度であれば、グラフィカルインターフェース(GUI)で十分です。
しかし、大量生成、自動審査、素材のデータベース化、編集可能なファイルのエクスポート、チームでの共同作業を行う場合は、APIを利用すべきです。
APIを利用すれば、すべてのステップが追跡可能、再試行可能、課金可能になり、内部のPython後処理サービスとの連携も容易になります。
gpt-image-2 画像レイヤー化の「86%割引(14%OFF)」はどう解釈すべきですか?
ユーザーが言及しているのは、当該プラットフォームを通じて gpt-image-2 のAPI中継サービスを利用し、公式価格で課金しつつ、100ドルのチャージで10%のボーナスが付与されるという仕組みです。
純粋な数学的観点から言えば、100ドルで110ドル分の残高が得られるため、実質的な単位コストは約90.9%となります。
もしプラットフォームがキャンペーン表示や総合決済などで「公式サイトの86%(14%OFF)」という表現を用いている場合は、実際の入金額、管理画面の課金状況、およびキャンペーン規約を優先してください。
予算表に記入する際は、「公式原価」「チャージボーナス後の換算価格」「プラットフォームのキャンペーン割引」の3列を保持しておくことをお勧めします。これにより、財務上の混乱を避けることができます。
gpt-image-2 画像レイヤー化の重要ポイント
- gpt-image-2 における画像レイヤー化の核心的な判断基準:モデルは通常フラットな画像を出力するため、レイヤー構造の多くは後処理ツールチェーンによって生成されます。
- Python によるバックエンド処理は決して難解なものではなく、API 呼び出し、OCR、マスク処理、インペインティング、ベクトル化、ファイルエクスポートなどに広く活用されています。
- インターフェースが PSD、オブジェクトツリー、レイヤーリスト、あるいはマスクリストを返さない限り、それを「モデルネイティブなレイヤー化機能」として宣伝すべきではありません。
- レイヤー化の成功率を高めるには、プロンプトが後処理を前提としている必要があります。画面の構造を整理し、各要素の境界を明確にすることが重要です。
- 軽微な編集であれば gpt-image-2 をそのまま呼び出すのが適していますが、構造化された成果物が必要な場合は SVG や PPTX が適しており、本格的なデザイン成果物が必要な場合にのみ PSD を検討してください。
- gpt-image-2 の公式 API は生成側の接続に適しており、Python によるレイヤー化サービスは業務システム側で制御するのが最適です。
- コスト計算を行う際は、公式モデルの利用料金だけでなく、チャージ時のボーナス、後処理の計算リソース、失敗時の再試行コスト、そして人手による修正時間を総合的に考慮する必要があります。
gpt-image-2 画像レイヤー化の参考資料
本記事の執筆にあたっては、英語圏のオンライン資料を参考にし、公開されている API ドキュメントと照らし合わせて検証を行いました。
- OpenAI GPT Image 2 モデルページ:developers.openai.com/api/docs/models/gpt-image-2
- OpenAI Images and vision ドキュメント:developers.openai.com/api/docs/guides/images-vision
- OpenAI Images API リファレンス:developers.openai.com/api/reference/resources/images
- OpenAI API 料金体系:openai.com/api/pricing
- Reddit GPT Image 2 Python スキルに関する議論:reddit.com/r/ClaudeCode/comments/1stokpq
- Reddit GPT Image 2 から編集可能なスライドへの変換に関する議論:reddit.com/r/ChatGPT/comments/1suwjp8
これらの資料は、「gpt-image-2 の生成・編集能力は非常に強力だが、編集可能なレイヤー構造はアプリケーション層のワークフローによって実現される結果である」という結論を裏付けています。
gpt-image-2 の画像レイヤー化に関するまとめ
gpt-image-2 における画像レイヤー化で最も重要なのは、「ネイティブPSD形式かどうか」という単一の答えを追い求めることではなく、適切なシステム境界を定義することです。
生成側では、gpt-image-2 がプロンプトと参照画像をもとに高品質な画像を生成する役割を担います。
エンジニアリング側では、Pythonツールチェーンがフラットな画像を解析し、テキスト、オブジェクト、背景、そして編集可能なファイルへと変換します。
これら二つのフェーズを明確に切り分けることで、開発者は効果、コスト、保守性をより正確に評価できるようになります。
ポスターの大量生成、PPTの図表作成、製品ビジュアル、あるいはデザイン素材の自動化を目指すのであれば、まずは gpt-image-2 で構造が明確なベース画像を生成し、その後に納品形式に応じて SVG、PPTX、または PSD へと後処理を行うことをお勧めします。
接続層については、APIYI (apiyi.com) が提供する gpt-image-2 公式変換 API を優先的に利用することをお勧めします。公式の定価ベースでモデル呼び出しが可能であり、さらに100ドルのチャージで10%分が還元されるキャンペーンを併用することで、実質的な利用コストを抑えることができます。
「モデルの能力」「後処理能力」「納品形式」「コスト管理」を個別に管理できるようになれば、gpt-image-2 の画像レイヤー化はもはや「謎の機能」ではなく、検証可能で拡張性があり、本番環境にも導入可能なビジュアル制作フローへと進化します。
技術的な交流やモデル接続のテストについては、APIYI (apiyi.com) をフォローしてください。gpt-image-2、GPTシリーズ、およびマルチモデルAPIを統合的に呼び出したい開発者チームに最適です。