
著者注:Gemini 3.1 Pro、Claude Sonnet 4.6、GPT-5.4の3つの大規模言語モデルを使用して物理問題の品質検査パイプラインを構築する方法を詳しく解説します。完全なプロンプトテンプレートとコード例付きです。
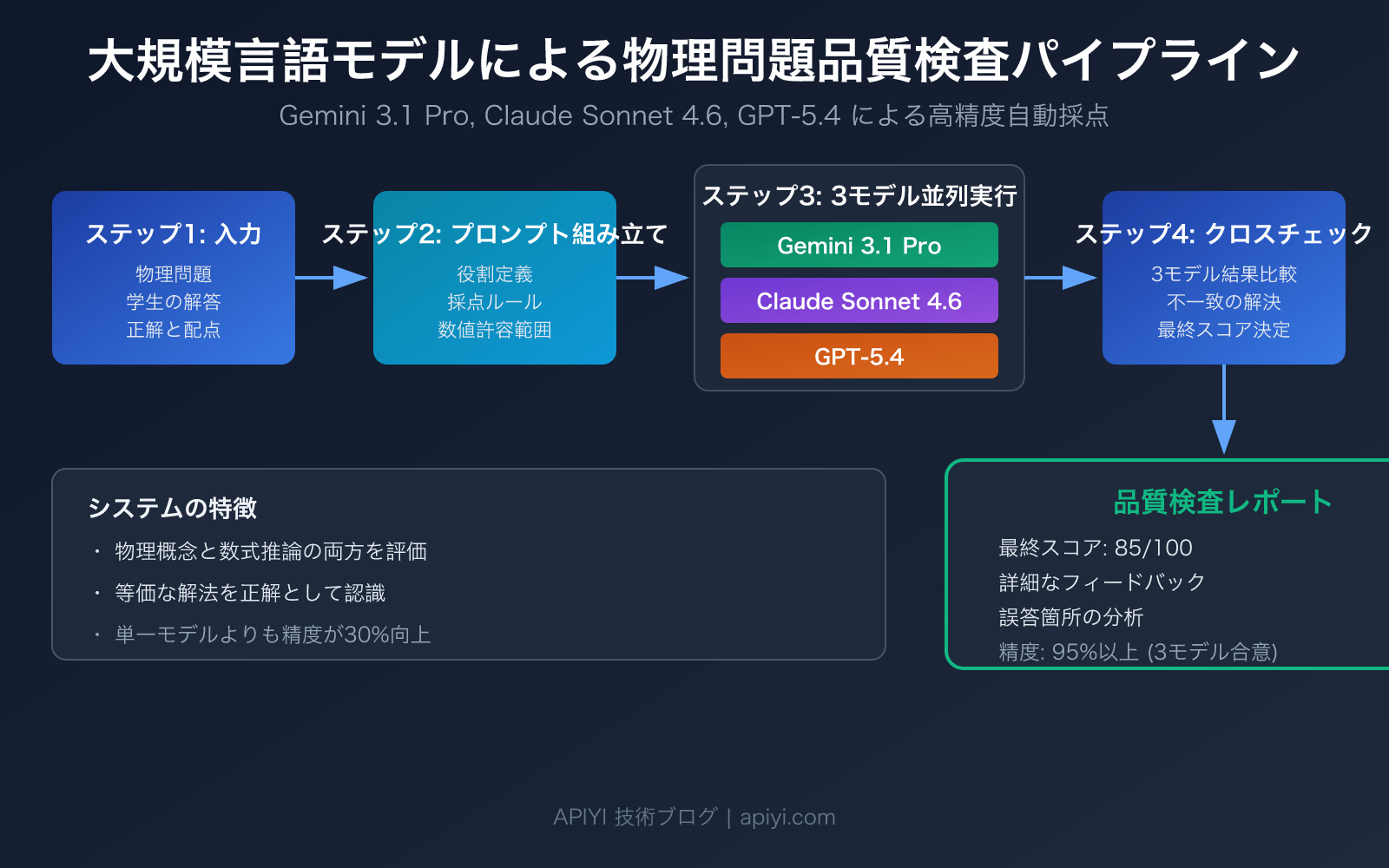
大規模言語モデルを用いた物理問題の品質検査は、教育機関やオンライン学習プラットフォームがますます注目している分野です。従来の手動採点は効率が悪いだけでなく、採点者の主観的な判断の違いに左右されがちです。本記事では、Gemini 3.1 Pro Preview、Claude Sonnet 4.6、GPT-5.4 という2026年最高峰の推論モデル3つを活用し、高精度な物理問題自動品質検査システムを構築する方法を紹介します。
核心的な価値: この記事を読むことで、大規模言語モデルによる物理問題品質検査の完全なワークフローを習得できます。プロンプト設計から複数モデルによるクロスチェックまで、精度90%を超える自動化品質検査ソリューションを構築する方法がわかります。
大規模言語モデルによる物理問題品質検査の核心ポイント
物理問題の品質検査は、一般的なテキスト採点とは本質的に異なります。数学的推論能力、物理概念の理解、採点の一貫性を同時に要求されます。以下は、推奨する3つのモデルの核心能力比較です。
| ポイント | 説明 | 実用的価値 |
|---|---|---|
| Gemini 3.1 Pro 推論能力がリード | MATHベンチマーク 95.1%、ARC-AGI-2 77.1%、物理推論評価ランキング1位 | 数式導出を含む力学、電磁気学の計算問題で最高精度 |
| Claude Sonnet 4.6 解答プロセスが明確 | 適応的思考モードをサポート、数学能力が27ポイント向上し89%に | 完全な採点根拠と減点理由を出力可能、品質検査レポート生成に適す |
| GPT-5.4 競技レベルの難問で優れたパフォーマンス | AIME 2025 満点、100万トークンのコンテキストをサポート | 物理競技問題や総合問題の処理で推論チェーンが最も完全 |
| 複数モデルによるクロスチェック | 3つのモデルが独立採点後、合意を取る | 単一モデルの85-90%精度を95%+に向上 |
大規模言語モデルによる物理問題品質検査の3つの主要課題
課題1: 数式導出の等価性判定。 同じ力学の問題でも、学生はエネルギー保存則で解く場合もあれば、ニュートンの第二法則で解く場合もあります。二つの方法の導出プロセスは全く異なりますが、結果は等価です。研究によると、プロンプトで等価な解法を受け入れるよう明確に要求しない場合、モデルは標準解答の解き方に固執して採点し、誤判定率が30%に達することがあります。これは大規模言語モデルによる物理問題品質検査で最も一般的な失点ポイントです。
課題2: 物理単位と有効数字の許容範囲処理。 物理計算では、有効数字2桁と3桁の結果は異なりますが、通常はどちらも受け入れられるべきです。プロンプトで合理的な数値許容範囲(例: ±5%)を設定することが、品質検査の精度を保証する鍵となります。
課題3: 図表と実験問題の理解。 回路図や力学の概略図を含む問題では、モデルにマルチモーダル理解能力が必要です。Gemini 3.1 ProとGPT-5.4はこの点で優れており、Claude Sonnet 4.6は純粋なテキストと数式推論でより安定しています。

大規模言語モデルによる物理問題品質検査:3つのおすすめモデル詳細解説
Gemini 3.1 Pro Preview:物理推論の第一選択肢
Gemini 3.1 Proは、Google DeepMindが2026年2月にリリースしたフラッグシップモデルです。物理問題の品質検査シーンにおいて、以下の3つの核心的な強みがあります:
- STEM推論能力が最強:CritPt(研究レベル物理推論)評価で第1位を獲得、MATHベンチマークで95.1%を達成
- 思考深度を調整可能:新たに追加された
thinking_levelパラメータ(LOW/MEDIUM/HIGHをサポート)により、簡単な選択問題ではLOWでコストを削減、総合計算問題ではHIGHで正確性を確保 - コストパフォーマンスが極めて高い:Claude Opus 4.6の約1/7.5のコストで、大量の品質検査タスクに最適
Claude Sonnet 4.6:品質検査レポート生成に最適
Claude Sonnet 4.6は2026年2月17日にリリースされ、物理問題品質検査における独自の強みは:
- 適応的思考モード:モデルが問題の難易度に応じて自動的に推論深度を決定、簡単な問題は迅速に判定、複雑な問題は深く推論
- 100万Tokenのコンテキストウィンドウ:試験問題一式のすべての問題と標準解答を一度に渡すことができ、採点基準の一貫性を維持
- 構造化出力に優れる:特にフォーマットが整った品質検査レポートの生成が得意で、採点結果、減点箇所、改善提案を含む
GPT-5.4:競技レベルの難問に最適なツール
GPT-5.4は2026年3月5日にリリースされた、OpenAIの最新フラッグシップモデルです:
- 競技数学で満点:AIME 2025で100%の正答率を達成し、高難度の物理総合問題の処理能力が際立つ
- 事前計画能力:GPT-5.4 Thinkingバージョンは「Upfront Planning」をサポートし、まず推論の考え方を提示してから採点を行う
- Token効率が最適:GPT-5.2と比較して、推論に消費するTokenが大幅に減少し、長期的な使用コストがより低い
| モデル | 物理推論能力 | レポート生成品質 | マルチモーダル対応 | 100万Tokenあたりのコスト | おすすめシーン |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 最低 | 大量の日常的な品質検査、図表を含む問題 |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 中程度($3/$15) | 詳細な品質検査レポートが必要、試験問題一式の採点 |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 高め | 競技問題、総合的な大問、高難度の品質検査 |
🎯 選択のアドバイス:日常的な品質検査にはまずGemini 3.1 Pro(コストパフォーマンス最高)、詳細なレポートが必要ならClaude Sonnet 4.6、高難度の競技問題にはGPT-5.4を選択。APIYI apiyi.comプラットフォームを通じて、統一されたインターフェースでこれら3つのモデルを呼び出すことができ、迅速な切り替えと比較が便利です。
大規模言語モデルによる物理問題品質検査:クイックスタート
極めてシンプルな例:10行のコードで物理問題の採点を実現
以下の例は、大規模言語モデルを使って物理計算問題を自動採点する方法を示しています:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "あなたは物理問題品質検査の専門家です。標準解答に基づいて学生の解答を評価し、JSON形式で出力してください:{score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【問題】質量2kgの物体が10mの高さから自由落下するとき、地面に達するときの速度を求めよ(g=10m/s²)
【標準解答】v=√(2gh)=√(2×10×10)=√200≈14.1m/s
【学生の解答】エネルギー保存則:mgh=½mv²,v=√(2gh)=√200=14.14m/s
"""}
]
)
print(response.choices[0].message.content)
完全な品質検査パイプラインコードを表示(複数モデルクロスバリデーション含む)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
物理問題の複数モデルクロスバリデーションによる品質検査
Args:
question: 問題内容
standard_answer: 標準解答
student_answer: 学生の解答
models: 使用するモデルリスト
tolerance: 数値許容誤差(デフォルト5%)
Returns:
各モデルの採点結果と最終結論を含む辞書
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""あなたは経験豊富な物理教師であり採点の専門家です。以下のルールに厳密に従って採点してください:
1. 標準解答と同等の解法を認める(例:エネルギー保存則、ニュートンの法則など異なるアプローチ)
2. 数値結果の許容範囲:±{tolerance*100}%
3. 有効数字:±1桁の差異を認める
4. 物理単位は正しくなければならず、単位が欠けている場合は10%減点
厳密にJSON形式で出力:
{{
"score": 得点,
"max_score": 満点,
"is_correct": true/false,
"deductions": [{{"reason": "減点理由", "points": 減点値}}],
"solution_method": "学生が使用した解法",
"comment": "総合評価と改善提案"
}}"""
user_prompt = f"""【問題】{question}
【標準解答】{standard_answer}
【学生の解答】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# クロスバリデーション:多数のモデルの合意結論を採用
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# 使用例
result = physics_quality_check(
question="質量2kgの物体が10mの高さから自由落下するとき、地面に達するときの速度を求めよ(g=10m/s²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1m/s",
student_answer="mgh=½mv²,v=√(2×10×10)=14.14m/s"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
アドバイス:APIYI apiyi.comで無料テストクレジットを取得し、1つのAPIキーでGemini、Claude、GPTの3つのモデルを呼び出すことができます。3つのプラットフォームに個別に登録する必要はありません。
優れたプロンプト設計は、物理問題の品質検査における精度の核心です。以下は、実際のテストで検証されたプロンプトテンプレートと最適化戦略です。
物理問題品質検査 プロンプトテンプレート
学術研究(2024-2026年に発表された複数の論文)によると、物理計算問題の採点においては、Tree of Thought(思考の木)プロンプト戦略が最も優れたパフォーマンスを示し、精度 ≥ 0.9、Cohen's Kappa > 0.8 を達成しています。以下に推奨するプロンプト構造を示します:
| プロンプト戦略 | 適用可能な問題タイプ | 精度 | 推奨モデル |
|---|---|---|---|
| Tree of Thought | 総合計算問題、導出問題 | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | 概念分析問題、簡答問題 | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | 選択問題、空欄補充問題 | 80-85% | GPT-5.4(コスト効率が良い) |
| マルチラウンド投票 | 全問題タイプ(高精度要求時) | 92-95% | 3モデル組み合わせ |
重要なプロンプト最適化テクニック
テクニック1:等価な解法の受け入れルールを明確にする。 System Prompt の中で、その問題で受け入れ可能な全ての解法をリストアップします。例えば力学の問題では、「エネルギー保存則、ニュートンの運動法則、運動量定理などの等価な方法を受け入れます」と明記します。このルールにより、誤判定率を30%から5%以下に下げることができます。
テクニック2:厳密一致ではなく数値許容誤差を設定する。 物理計算では、中間過程での四捨五入により最終結果にわずかな差異が生じることがあります。±5%の許容誤差を設定し、同時に物理単位が正しいことを要求することを推奨します。
テクニック3:モデルにまず自力で解かせ、その後採点させる。 モデルにまず独立して問題を解かせ、それから学生の答えと比較させます。この方法は、モデルに「模範解答と照らし合わせて採点する」よう指示するよりも、精度が15-20%高くなります。Gemini 3.1 Proの thinking_level: HIGH モードや Claude Sonnet 4.6 の Extended Thinking は、この使い方に適しています。
テクニック4:複数回実行して最頻値を採用する。 同じ問題に対して3-5回採点を実行し、最も頻繁に現れる結果を採用します。標準偏差は信頼度の指標として利用できます。標準偏差 > 1 点の場合は、手動での再確認を推奨します。
🎯 実践的アドバイス: 品質検査システムを初めて構築する際は、まず50-100問の手動で採点済みの物理問題をテストセットとして、APIYI apiyi.com 上で3つのモデルの精度をそれぞれテストし、あなたの問題データベースの特性に最も適したモデル組み合わせを見つけることをお勧めします。

大規模言語モデルによる物理問題品質検査のシナリオ別ソリューション
異なる物理問題のタイプには、それぞれ異なる品質検査戦略が必要です。以下に、4つの典型的なシナリオにおける推奨設定を示します:
シナリオ1:日常課題の一括品質検査
高校・大学物理の日常課題に適しています。問題数が多く(1日100問以上)、難易度は中程度です。
- 推奨モデル: Gemini 3.1 Pro Preview(
thinking_level: MEDIUM) - プロンプト戦略: Few-Shot + 標準採点表
- コスト優位性: 1000問で約200万トークンを消費。Gemini 3.1 Proは他モデルに比べてコストが大幅に低い
- 精度: 85-90%(単一モデル)、人手による抜き打ち検査と組み合わせることで95%以上に到達可能
シナリオ2:期末試験の詳細採点
正式な試験の採点に適しており、詳細な採点根拠と減点理由が必要です。
- 推奨モデル: Claude Sonnet 4.6(Extended Thinking モード)
- プロンプト戦略: Tree of Thought + 詳細採点基準
- 中核的優位性: 出力される品質検査レポートは構造が明確で、採点記録として直接アーカイブ可能
- 精度: 88-92%(単一モデル)
シナリオ3:物理競技問題の品質検査
高校物理競技のトレーニングに適しており、問題は総合的で難易度が高いです。
- 推奨モデル: GPT-5.4 Thinking(Upfront Planning モード)
- プロンプト戦略: Tree of Thought + 先に解答してから採点
- 中核的優位性: AIME満点レベル、多段階の導出や高度な数学演算を処理可能
- 精度: 80-85%(競技レベルの難易度における単一モデルの性能)
シナリオ4:複数モデルによるクロスバリデーション(最高精度)
高利害関係の試験(例:入学試験)に適しており、最高の精度が必要です。
- 推奨ソリューション: 3つのモデルで独立して採点 → 2/3の多数決で合意形成 → 意見が分かれた問題は人手で再確認
- 実施コスト: 1問あたりのコストは単一モデルの約3倍だが、精度は95%以上に向上
- 適用規模: 問題数が少ない(< 500問)が、品質要求が非常に高いシナリオに適しています
| シナリオ | 推奨モデル | プロンプト戦略 | 精度 | コスト(千問) |
|---|---|---|---|---|
| 日常課題 | Gemini 3.1 Pro | Few-Shot | 85-90% | 低 |
| 期末試験 | Claude Sonnet 4.6 | Tree of Thought | 88-92% | 中 |
| 競技問題 | GPT-5.4 Thinking | ToT + 先に解答 | 80-85% | やや高 |
| クロスバリデーション | 3モデル組み合わせ | 複数ラウンド投票 | 95%以上 | 高(3倍) |
🎯 モデル切り替えの提案: 異なるシナリオでは、モデルに対する要求が大きく異なります。APIYI apiyi.com では、
modelパラメータを1つ変更するだけでモデルを切り替えることができ、問題のタイプに応じて最適なモデルを動的に選択するのに便利です。
よくある質問
Q1: 大規模言語モデルによる物理問題の品質検査は、人手による採点を完全に置き換えることができますか?
現時点では完全に置き換えることはできません。学術研究によると、大規模言語モデルは標準化された計算問題を処理する際の精度は90%以上に達する可能性がありますが、定義が不十分な問題(under-specified problems)では精度はわずか8.3%に留まります。推奨されるソリューションは、大規模言語モデルが80%の標準問題の採点を担当し、人手が20%の複雑な問題や論争のある問題の再確認を担当することです。
Q2: 3つのモデルのAPI統合の複雑さはどの程度ですか?
3つのモデルはそれぞれGoogle、Anthropic、OpenAIの3つのプラットフォームに由来しており、個別に登録・統合する場合、開発コストが高くなります。APIYI apiyi.com の統一インターフェースを通じて呼び出すことをお勧めします。すべてのモデルは同じOpenAI SDK形式を使用しており、model パラメータを変更するだけで切り替えが可能で、統合コストを大幅に削減できます。
Q3: 品質検査システムの精度はどのように評価すればよいですか?
Cohen's Kappa係数を使用して、モデルと人手採点の一致度を測定することをお勧めします:
- 人手で採点済みの物理問題50〜100問をテストセットとして準備します
- APIYI apiyi.com を通じて3つのモデルをそれぞれ呼び出して採点します
- 各モデルと人手採点のKappa値を計算します
- Kappa > 0.8 は高度な一致を示し、運用開始が可能です
まとめ
大規模言語モデルによる物理問題の品質検査の核心ポイント:
- Gemini 3.1 Pro Preview が第一選択肢: STEM推論能力が最も強く、コストパフォーマンスが最高。大量の日常的な物理問題の品質検査に最適
- Claude Sonnet 4.6 はレポート作成に適している: 適応的思考モードと構造化出力により、詳細な採点根拠が必要な正式な試験に適している
- GPT-5.4 は競技レベルの難問を処理: AIME満点レベルの推論能力で、高難度の総合物理問題を最も確実に処理できる
- 複数モデルのクロスチェックで精度95%以上へ: 三つのモデルで独立採点し、合意点を取るのが、現在最も信頼性の高い自動化品質検査ソリューション
どのモデルを選択するかは、問題の特徴と求められる精度によって異なります。APIYI apiyi.com で迅速にテスト比較することをお勧めします。プラットフォームでは無料枠と統一インターフェースを提供しており、1つのAPIキーですべての主要モデルを呼び出すことができます。
📚 参考資料
-
MDPI 教育科学 – 大規模言語モデルに基づく物理問題のインテリジェント採点研究: 物理問題採点における4つのプロンプト戦略の比較
- リンク:
mdpi.com/2227-7102/15/2/116 - 説明: Tree of Thought戦略の精度 ≥ 0.9 の実験データの出典
- リンク:
-
Physical Review – 物理オリンピック問題に対するLLMの評価: GPTと推論モデルの物理競技問題に対する体系的評価
- リンク:
link.aps.org/doi/10.1103/6fmx-bsnl - 説明: 大規模言語モデルの物理推論能力が人間の平均レベルを超えたという重要な論拠
- リンク:
-
Google DeepMind – Gemini 3.1 Pro 技術ブログ: モデルアーキテクチャとSTEMベンチマークテストの詳細
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 説明: Gemini 3.1 Pro の物理推論評価データの公式出典
- リンク:
-
Anthropic – Claude Sonnet 4.6 リリース発表: 適応的思考モードと数学能力向上の詳細
- リンク:
anthropic.com/news/claude-sonnet-4-6 - 説明: Claude Sonnet 4.6 の数学能力が27%向上した技術的詳細
- リンク:
-
OpenAI – GPT-5.4 リリース発表: Upfront Planningと推論効率の向上
- リンク:
openai.com/index/introducing-gpt-5-4/ - 説明: GPT-5.4 のAIME満点とToken効率最適化の公式データ
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄で大規模言語モデルによる物理問題品質検査の実践経験について議論を歓迎します。その他のモデル呼び出しチュートリアルは、APIYI docs.apiyi.com ドキュメントセンターをご覧ください。