
"¿Por qué mis solicitudes de Claude Code tienen 400.000 tokens de entrada cada vez? ¿Por qué la factura es tan alta?". Esta es la primera reacción de muchos usuarios de Claude Code al revisar sus estadísticas de uso. En realidad, la gran mayoría de esos 400.000 tokens probablemente ya han sido alcanzados por la caché, y el coste real podría ser solo 1/10 de la cifra aparente. Sin embargo, si la caché no se alcanza, la factura puede ser realmente dolorosa.
Valor central: Al terminar de leer este artículo, comprenderás el mecanismo de caché automática de Claude Code, las 8 causas comunes por las que la caché falla y 6 técnicas prácticas para reducir tus tokens de entrada de 400.000 a 50.000.
title: "Análisis detallado del mecanismo de caché automática Prompt Caching en Claude Code"
description: "Descubre cómo funciona el Prompt Caching en Claude Code, por qué es vital para reducir costes y qué factores provocan la invalidación de la caché."
Análisis detallado del mecanismo de caché automática Prompt Caching en Claude Code
¿Claude Code utiliza la caché automáticamente?
Sí. Claude Code activa automáticamente el Prompt Caching de Anthropic en cada solicitud de API sin necesidad de configuración. Es un comportamiento integrado, no una función opcional.
Cada vez que envías un mensaje en Claude Code, el contenido que se envía realmente a la API se ensambla en el siguiente orden:
| Orden de ensamblaje | Contenido | Estimación de tamaño | Comportamiento de caché |
|---|---|---|---|
| Capa 1 | Definiciones de herramientas (Read/Edit/Bash, etc.) | ~5,000 tokens | Casi estático, alta tasa de aciertos |
| Capa 2 | Prompt del sistema + CLAUDE.md | ~3,000-10,000 tokens | Inmutable en la sesión, alta tasa de aciertos |
| Capa 3 | Historial de chat (todos los mensajes previos) | Crecimiento continuo | Coincidencia de prefijo, acumulación gradual |
| Capa 4 | Mensaje nuevo actual | Variable | Nunca se almacena en caché |
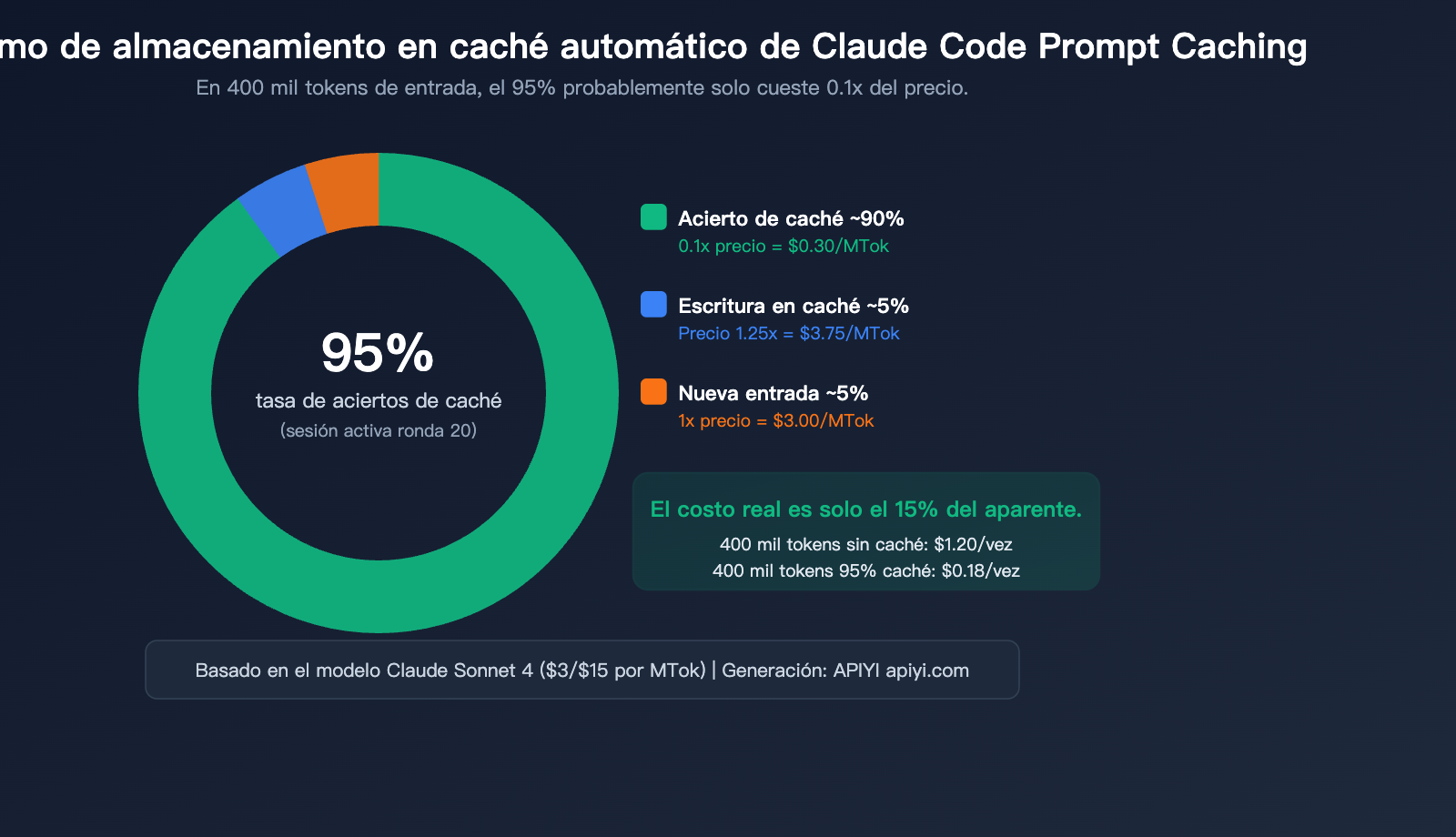
Mecanismo clave: La caché se basa en la coincidencia de prefijos. Siempre que los primeros N tokens de la solicitud sean idénticos al contenido almacenado previamente, esos N tokens se considerarán un acierto de caché. En una conversación continua, para la ronda 20, más del 95% de los tokens de entrada suelen provenir de aciertos de caché.
Precios de caché: Por qué los aciertos son tan importantes
| Tipo de operación | Precio base relativo | Precio real Sonnet 4/MTok | Precio real Opus 4/MTok |
|---|---|---|---|
| Entrada estándar (sin caché) | 1x | $3.00 | $15.00 |
| Escritura de caché (5 min) | 1.25x | $3.75 | $18.75 |
| Escritura de caché (1 hora) | 2x | $6.00 | $30.00 |
| Acierto/Lectura de caché | 0.1x | $0.30 | $1.50 |
| Salida | — | $15.00 | $75.00 |
Un ejemplo concreto: Si tu solicitud tiene 400,000 tokens de entrada:
Escenario A: Sin caché
├── 400k tokens × $3/MTok (Sonnet) = $1.20 por solicitud
Escenario B: 95% de aciertos de caché (sesión típica de Claude Code)
├── Aciertos de caché 380k tokens × $0.30/MTok = $0.114
├── Escritura de caché 10k tokens × $3.75/MTok = $0.0375
├── Nueva entrada 10k tokens × $3/MTok = $0.03
├── Total = $0.18 por solicitud
└── Coste real de solo el 15% comparado con el escenario sin caché
🎯 Consejo técnico: La invocación del modelo Claude a través de APIYI (apiyi.com) también admite el mecanismo de Prompt Caching, reduciendo los costes de entrada en un 90% cuando hay aciertos. Si tu proyecto integra Claude mediante API, te recomendamos diseñar la estructura de la indicación para maximizar la tasa de aciertos de caché.
TTL de caché: El beneficio oculto para usuarios Max
| Plan de suscripción | TTL de caché | Coste de escritura | Nota |
|---|---|---|---|
| API Pago por uso | 5 minutos | 1.25x | La caché expira tras 5 min de inactividad |
| Pro / Team | 5 minutos | 1.25x | Igual que el anterior |
| Max 5x / 20x | 1 hora | 2x | Escritura más cara, pero ventana de acierto 12 veces mayor |
Aunque los usuarios Max pagan 2x por la escritura (frente al 1.25x estándar), un TTL de 1 hora significa que puedes ir a tomar un café y la caché seguirá ahí. Para desarrolladores con uso intermitente, esta diferencia es significativa.
Cada acierto de caché reinicia el temporizador TTL, por lo que mientras te mantengas activo, la caché prácticamente no expirará.
¿La caché no funciona? 8 causas comunes y soluciones
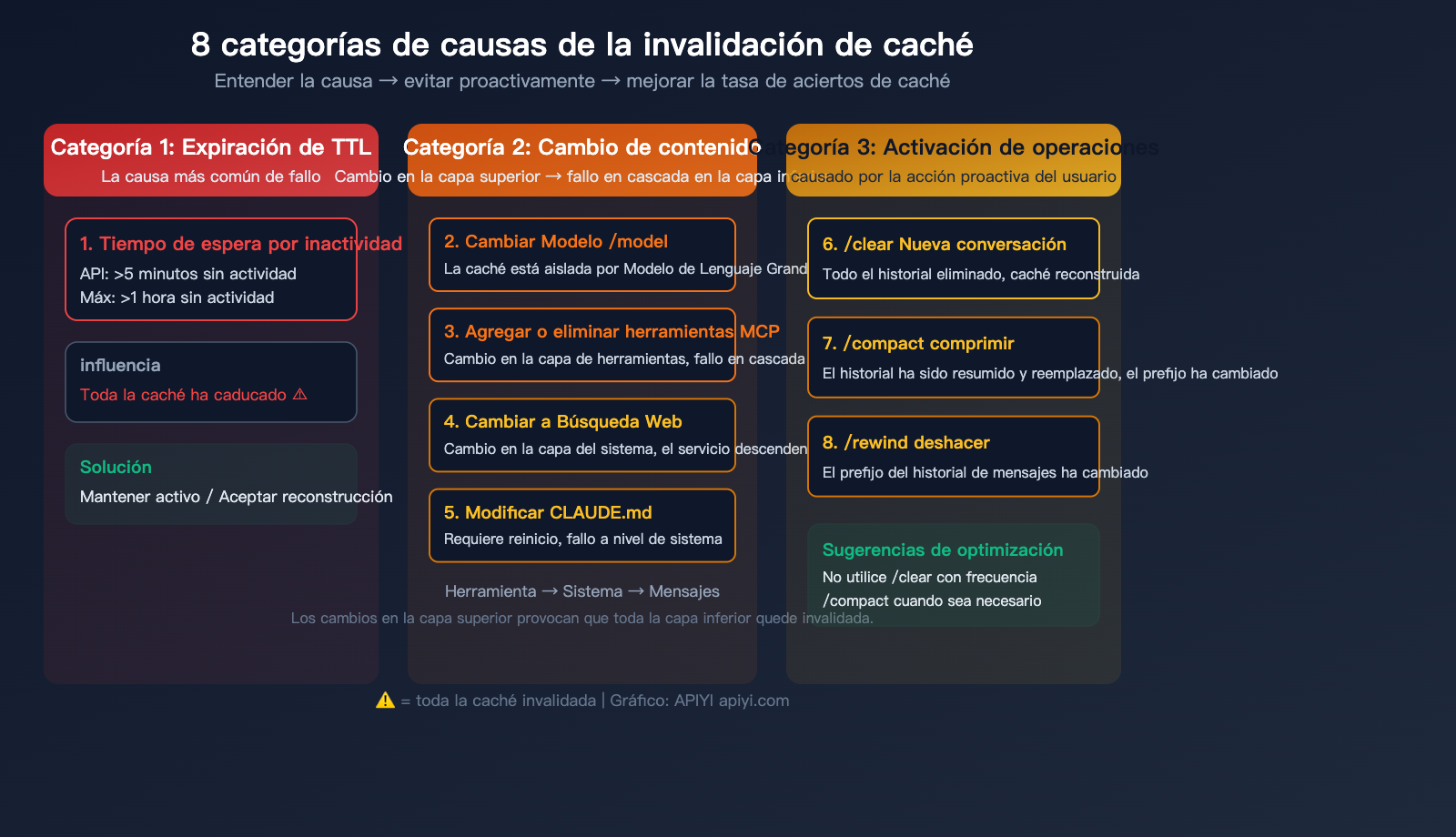
La causa fundamental de la invalidación de la caché es una sola: el prefijo de la solicitud no coincide con el contenido almacenado. Específicamente en Claude Code, las siguientes 8 situaciones causan la invalidación:
Primera categoría: Expiración de TTL
| Causa | Condición de activación | Alcance del impacto | Solución |
|---|---|---|---|
| 1. Tiempo de espera por inactividad | >5 min sin actividad (API), >1 hora (Max) | Toda la caché invalidada | Mantener actividad o aceptar el coste de reconstrucción |
Esta es la causa más común. Si te ausentas durante más de 5 minutos (usuarios API) o 1 hora (usuarios Max) mientras programas, la siguiente solicitud activará una reconstrucción completa de la caché.
Segunda categoría: Invalidación en cascada por cambios de contenido
La caché sigue una estructura jerárquica estricta: Definición de herramientas → Prompt del sistema → Historial de chat. Un cambio en una capa superior invalida todas las capas inferiores.
| Causa | Condición de activación | Alcance del impacto | Gravedad |
|---|---|---|---|
| 2. Cambio de modelo | Comando /model |
Toda la caché (aislada por modelo) | ⚠️ Alta |
| 3. Añadir/Eliminar herramientas MCP | Instalar o desinstalar un servidor MCP | Capa de herramientas + todo lo posterior | ⚠️ Alta |
| 4. Cambio en búsqueda web | Activar o desactivar búsqueda en internet | Capa del sistema + todo lo posterior | ⚠️ Media |
| 5. Modificar CLAUDE.md | Reiniciar tras editar la configuración | Capa del sistema + todo lo posterior | ⚠️ Media |
Tercera categoría: Invalidación por acciones del usuario
| Causa | Condición de activación | Alcance del impacto | Gravedad |
|---|---|---|---|
| 6. Iniciar nuevo chat | /clear o nueva sesión |
Toda la caché (historial borrado) | ⚠️ Alta |
| 7. Usar /compact | Comprimir historial activamente | Caché de la capa de historial invalidada | ⚠️ Media |
| 8. Usar /rewind | Deshacer mensajes previos | Cambio en el prefijo del historial | ⚠️ Media |
Una limitación técnica fácil de ignorar: Longitud mínima de caché
Si tu indicación es inferior a la siguiente cantidad de tokens, la caché se saltará silenciosamente sin mostrar ningún error:
| Modelo | Longitud mínima para caché |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4,096 tokens |
| Claude Sonnet 4.6 | 2,048 tokens |
| Claude Sonnet 4.5 / 4 | 1,024 tokens |
Para Claude Code, dado que las definiciones de herramientas + el prompt del sistema ya superan los 5,000 tokens, este límite casi nunca se alcanza. Sin embargo, si construyes aplicaciones mediante API, ten en cuenta este umbral inferior.
💡 Sugerencia: Si construyes aplicaciones propias llamando a la API de Claude a través de APIYI (apiyi.com), asegúrate de que la longitud del prompt del sistema supere el umbral mínimo de caché del modelo, de lo contrario, la caché no tendrá efecto.
¿Por qué ves 400 mil tokens de entrada? La composición del contexto en Claude Code
Una vez comprendido el mecanismo de caché, desglosemos de qué está compuesto ese "input de 400 mil tokens" que tanto te ha sorprendido.
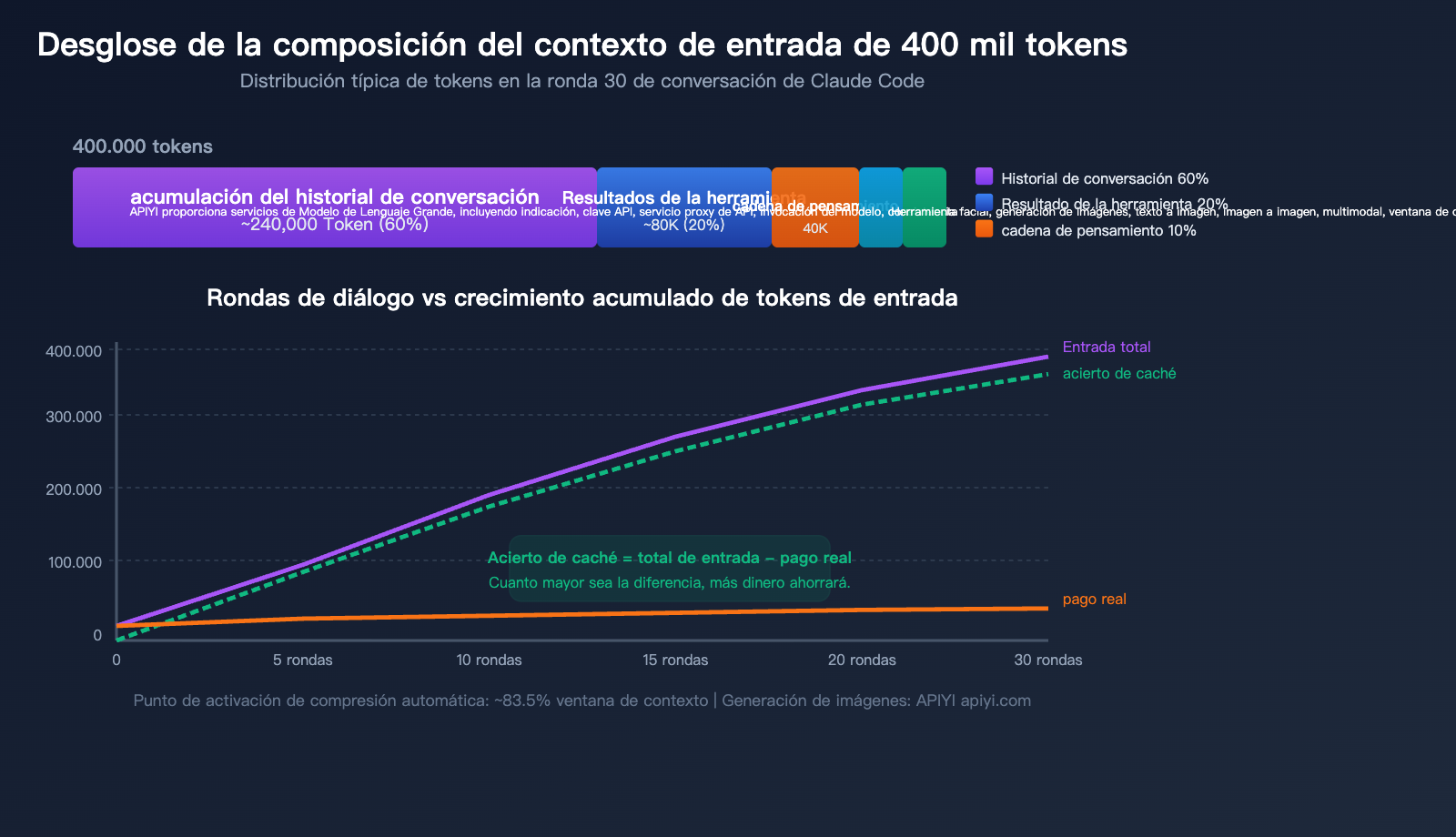
Las 5 fuentes principales de consumo de tokens
| Fuente | Proporción | Aprox. en 400k | Características |
|---|---|---|---|
| Acumulación del historial | ~60% | ~240k | Se reenvía todo el historial en cada turno |
| Resultados de herramientas | ~20% | ~80k | Lectura de archivos, resultados de grep en contexto |
| Cadena de pensamiento | ~10% | ~40k | Los bloques de pensamiento de rondas previas pasan a ser entrada |
| Prompt del sistema + CLAUDE.md | ~5% | ~20k | Se incluye en cada mensaje |
| Definición de herramientas | ~5% | ~20k | Esquema de todas las herramientas disponibles |
La verdad fundamental: a mayor diálogo, mayor entrada
La forma en que trabaja Claude Code es reenviar el historial completo de la conversación en cada solicitud. Esto significa que:
- Ronda 1: Entrada de ~20k tokens (Prompt del sistema + definición de herramientas + tu pregunta)
- Ronda 5: Entrada de ~100k tokens (acumula el historial de 4 rondas)
- Ronda 15: Entrada de ~250k tokens (incluye gran cantidad de resultados de lectura de archivos)
- Ronda 30: Entrada de ~400k+ tokens (cerca del umbral de compresión automática)
Pero ten en cuenta: la gran mayoría de estas entradas provienen de aciertos de caché. En esos 400 mil tokens de la ronda 30, es posible que solo 10-20 mil sean contenido nuevo no cacheado.
El problema particular de los grandes repositorios
Claude Code no carga automáticamente todo el repositorio en el contexto; lee los archivos bajo demanda. Sin embargo, en repositorios grandes:
- Una búsqueda
greppuede devolver una gran cantidad de resultados, todos entrando al contexto. - La lectura exploratoria de múltiples archivos hace que el contenido de cada uno permanezca en el historial.
- En modo Agente, al ejecutar operaciones de varios pasos, los resultados de cada llamada a herramientas se acumulan.
Si tus clientes llegan a 400 mil tokens, probablemente se deba a la combinación de estos factores:
- El repositorio es grande y Claude Code ha leído muchos archivos para analizarlo.
- Hay muchas rondas de diálogo, lo que acumula historial.
- Posiblemente no se han utilizado los comandos
/compacto/cleara tiempo. - El archivo
CLAUDE.mdpodría ser demasiado extenso.
6 consejos prácticos: reduce los Token de entrada de 400k a 50k
Consejo 1: Instrucciones precisas para evitar escaneos globales
Esta es la optimización más importante y fácil de implementar.
❌ Instrucciones vagas (activan escaneos de archivos a gran escala):
"Ayúdame a optimizar el rendimiento de este proyecto"
"Revisa los errores en el código"
"Refactoriza este módulo"
✅ Instrucciones precisas (solo leen los archivos necesarios):
"Optimiza el tiempo de respuesta de la función processRequest en src/api/handler.ts"
"Corrige la excepción de puntero nulo en la línea 45 de src/auth/login.ts"
"Migra la función formatDate de moment a dayjs en src/utils/format.ts"
Las instrucciones vagas provocan que Claude Code utilice Glob + Grep + Read en una gran cantidad de archivos para "entender" tu necesidad, y el contenido de cada archivo permanece permanentemente en el historial de la conversación. Las instrucciones precisas permiten que solo lea 1 o 2 archivos relevantes.
Efecto de ahorro de Token: reduce entre un 60% y 80% los Token de resultados de llamadas a herramientas.
Consejo 2: Usa /clear y /compact a tiempo
# Limpia la conversación al cambiar a tareas no relacionadas
/clear
# Comprime el historial cuando la conversación es larga pero la tarea no ha terminado
/compact
# Compresión con instrucciones, conservando información específica
/compact conserva los ejemplos de código y las definiciones de interfaces API, el resto puede simplificarse
| Comando | Efecto | Escenario de uso | Notas |
|---|---|---|---|
/clear |
Limpia todo el historial | Cambiar a tareas totalmente distintas | La caché se invalida por completo |
/compact |
La IA resume el historial y reemplaza el original | Etapas intermedias de conversaciones largas | La caché se invalida parcialmente, pero el contexto se reduce drásticamente |
Efecto real: una conversación de 400k Token suele reducirse a 50k-80k Token tras usar /compact.
Consejo 3: Optimiza el archivo CLAUDE.md
El archivo CLAUDE.md se carga en cada mensaje. Un CLAUDE.md de 10,000 Token se enviará 30 veces en 30 rondas de conversación (aunque solo se cobre 0.1x tras el acierto de caché, sigue ocupando un espacio valioso en el contexto).
Sugerencias de optimización:
├── Mantén CLAUDE.md por debajo de las 500 líneas (reglas principales)
├── Mueve las explicaciones detalladas de flujo de trabajo a Skills (carga bajo demanda)
├── Coloca la documentación de referencia en knowledge-base/ (Read cuando sea necesario)
└── Evita incluir bloques grandes de código de ejemplo en CLAUDE.md
🚀 Consejo práctico: Simplificar CLAUDE.md no solo reduce el consumo de Token,
sino que ayuda a Claude Code a centrarse en las reglas fundamentales.
Si estás usando APIYI (apiyi.com) para crear asistentes de programación similares,
también te recomendamos controlar la longitud de las indicaciones del sistema.
Consejo 4: Aprovecha los Subagent para aislar salidas extensas
Cuando necesites ejecutar operaciones que generen una gran cantidad de salida, utiliza un Subagent en lugar de ejecutarlo directamente:
❌ Ejecución directa en la conversación principal (la salida entra en el contexto principal):
"Ejecuta la suite de pruebas y analiza las causas de los fallos"
→ La salida de las pruebas puede tener más de 50,000 Token, que permanecerán en el historial
✅ Deja que Claude Code use un Subagent (la salida se aísla en un subproceso):
"Usa una subtarea para ejecutar la suite de pruebas y resúmeme solo los nombres de las pruebas fallidas y la causa"
→ El contexto principal solo aumenta en ~500 Token del resumen
Efecto de ahorro de Token: una sola operación puede evitar que entren entre 10,000 y 50,000 Token al contexto principal.
Consejo 5: Elige el modelo y el nivel de esfuerzo (effort) adecuados
| Tipo de tarea | Modelo recomendado | Nivel de esfuerzo | Nota |
|---|---|---|---|
| Modificaciones simples/formateo | Sonnet | low | No requiere razonamiento profundo |
| Desarrollo convencional | Sonnet | medium | Mejor relación calidad-precio |
| Diseño de arquitectura compleja | Opus | high | Requiere razonamiento profundo |
| Revisión de código | Sonnet | medium | Mejor rendimiento que Opus |
# Reduce la profundidad de pensamiento, disminuye los Token de razonamiento (thinking)
# Configura un esfuerzo menor en tareas sencillas
/effort low
# O controla el límite de Token de pensamiento mediante variables de entorno
MAX_THINKING_TOKENS=8000
La cadena de pensamiento extendida (thinking) se convierte en parte de los Token de entrada en las rondas posteriores. Reducir el nivel de esfuerzo puede disminuir significativamente los Token acumulados en rondas futuras.
Consejo 6: Usa el comando /context para monitorear la distribución de Token
# Ver la distribución actual de uso de Token
/context
El comando /context mostrará la proporción de Token de cada parte en el contexto actual, ayudándote a localizar qué es lo que realmente está consumiendo espacio. Hallazgos comunes:
- Una búsqueda grep devolvió 20,000 Token de resultados, pero solo el 5% era útil.
- Un archivo grande leído anteriormente ya no es necesario, pero sigue en el contexto.
- CLAUDE.md ocupa un espacio inesperadamente grande.
Una vez detectado el problema, usa /compact o /clear de forma dirigida para solucionarlo.
💰 Consejo de costos: Para usuarios que pagan por uso de API, estas técnicas de optimización pueden reducir directamente la factura.
A través de la función de estadísticas de uso de la plataforma APIYI (apiyi.com), puedes ver claramente la distribución de Token de cada solicitud,
ayudándote a identificar los puntos críticos de costos.
Caso práctico: de $60 a $8 diarios
Aquí tienes un proceso de optimización real:
Antes de la optimización (Proyecto grande en Python, usuario intensivo de Claude Code)
Uso diario:
├── Rondas de chat: ~50 rondas/día
├── Promedio de tokens de entrada: 350-450 mil/ronda
├── Tasa de acierto de caché: ~70% (debido a /clear frecuentes y cambios de modelo)
├── Costo diario de API (Opus 4): ~$60
└── Mensual: ~$1,320
Después de la optimización (Aplicando 6 trucos)
Uso diario:
├── Rondas de chat: ~40 rondas/día (más preciso, no requiere tantas rondas)
├── Promedio de tokens de entrada: 80-120 mil/ronda (indicación precisa + compactación periódica)
├── Tasa de acierto de caché: ~92% (reducción de interrupciones de caché innecesarias)
├── Costo diario de API (principalmente Sonnet 4, Opus solo para tareas complejas): ~$8
└── Mensual: ~$176
| Elemento de optimización | Porcentaje de ahorro | Explicación |
|---|---|---|
| Indicaciones precisas vs. escaneo vago | ~35% | El mayor beneficio |
| Uso oportuno de /compact y /clear | ~25% | Controla la expansión acumulada |
| Sonnet en lugar de Opus (80% de tareas) | ~20% | Degradación de modelo imperceptible |
| Simplificación de CLAUDE.md | ~8% | Reduce el costo fijo por ronda |
| Aislamiento de salidas largas con subagentes | ~7% | Evita que bloques grandes contaminen el contexto |
| Reducción del nivel de esfuerzo | ~5% | Reduce la acumulación de tokens de pensamiento |
Preguntas frecuentes
Q1: ¿Los 400 mil tokens que muestra Claude Code son los que se cobran realmente?
No. Claude Code activa automáticamente el almacenamiento en caché de la indicación (Prompt Caching). En una sesión activa, más del 95% de los tokens de entrada suelen ser aciertos de caché, cobrándose solo a 0.1x del precio base. De los 400 mil tokens, es posible que solo 20-40 mil se facturen a precio completo. Puedes usar /context para ver la tasa de acierto de caché real. La invocación del modelo a través de APIYI (apiyi.com) también es compatible con este mecanismo de caché.
Q2: ¿Debo preocuparme por el consumo de tokens si tengo el plan mensual Max?
Sí, pero por una razón distinta. El plan mensual Max no cobra por token, pero tiene un límite de uso semanal. Un consumo excesivo de tokens hará que alcances ese límite más rápido. Simplificar el contexto no solo extiende el tiempo de uso, sino que también ayuda a que Claude Code entienda mejor tus necesidades (cuanto más preciso sea el contexto, mejor será la respuesta).
Q3: ¿Qué es mejor, /compact o /clear?
Depende del escenario. Si vas a comenzar una tarea completamente diferente, es mejor usar /clear para limpiar todo por completo. Si sigues en la misma tarea pero la conversación se ha vuelto muy larga, usa /compact para conservar el contexto clave mientras reduces el volumen. /compact admite instrucciones personalizadas, como /compact conservar todos los registros de cambios de código y definiciones de interfaces API.
Q4: ¿Actualizar a la última versión de Claude Code optimiza automáticamente el uso de tokens?
Sí, se recomienda mantener siempre la última versión. Anthropic optimiza continuamente las estrategias de gestión de contexto de Claude Code, incluyendo el momento en que se activa la compresión automática (actualmente se activa cuando el contexto ocupa aproximadamente el 83.5%), la carga diferida de definiciones de herramientas MCP (solo carga el nombre de la herramienta y carga el esquema completo cuando se usa), entre otras. Las nuevas versiones suelen traer mejores tasas de acierto de caché y una gestión de contexto más inteligente.

Resumen: Entender el caché + uso preciso = control de costos
El Prompt Caching de Claude Code es un mecanismo de optimización automática sumamente potente: no necesitas configurar nada, ya está trabajando para ahorrarte dinero. Sin embargo, entender cómo funciona y bajo qué condiciones se invalida te ayudará a elevar el ahorro de un "70% automático" a un "95% proactivo".
Recuerda estos 3 principios fundamentales:
- Mantén el caché activo: Evita acciones innecesarias que interrumpan el caché (cambiar de modelo frecuentemente, usar
/clearsin necesidad). - Controla la expansión del contexto: Usa indicaciones precisas y ejecuta
/compactperiódicamente para evitar que el historial de la conversación crezca indefinidamente. - Elige las herramientas y modelos adecuados: Para el 80% de las tareas, Sonnet es suficiente; reserva Opus solo para los escenarios que realmente lo requieran.
Para los usuarios que pagan por uso de la API, recomendamos gestionar las invocaciones de la API de Claude de forma unificada a través de APIYI (apiyi.com), aprovechando las funciones de monitoreo de consumo de la plataforma para optimizar continuamente el gasto de tokens. Para usuarios intensivos de la interfaz interactiva, sugerimos optar directamente por el plan mensual Claude Max, combinándolo con los consejos de optimización de este artículo para obtener la mejor relación costo-beneficio.
📝 Autor del artículo: Equipo técnico de APIYI | APIYI (apiyi.com) – Plataforma de acceso unificado para más de 300 APIs de Modelos de Lenguaje Grande.
Referencias
-
Documentación de Prompt Caching de Anthropic: Explicación detallada del mecanismo de caché oficial.
- Enlace:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Nota: TTL del caché, multiplicadores de precios y requisitos de longitud mínima.
- Enlace:
-
Guía de gestión de costos de Claude Code: Sugerencias oficiales de optimización de tokens.
- Enlace:
code.claude.com/docs/en/costs - Nota: Estrategias de control de costos recomendadas oficialmente por Anthropic.
- Enlace:
-
Mejores prácticas de Claude Code: Gestión de contexto y optimización de la eficiencia.
- Enlace:
anthropic.com/engineering/claude-code-best-practices - Nota: Incluye consejos prácticos sobre el uso de indicaciones precisas, la función compact, entre otros.
- Enlace: