
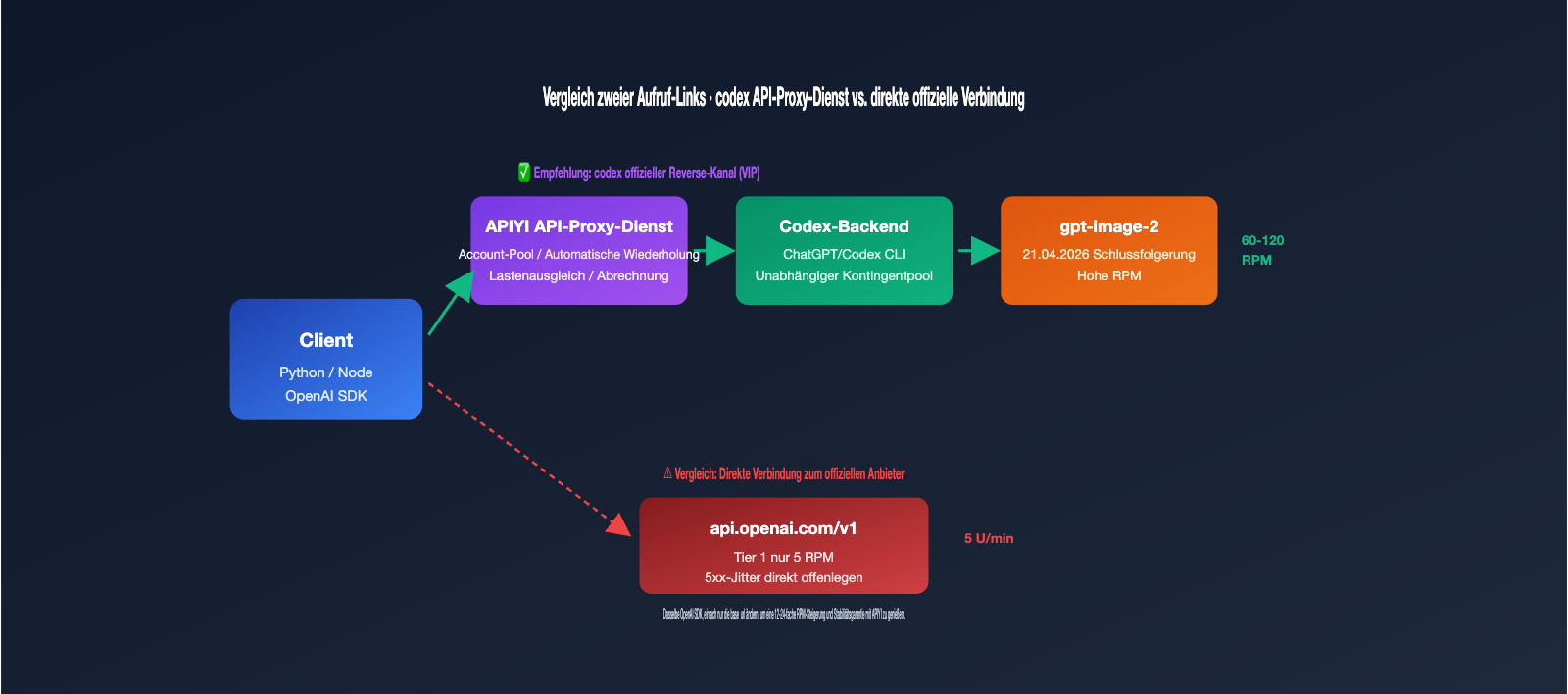
Wer gpt-image-2 in einer Produktionsumgebung einsetzt, stößt meist schnell auf zwei Probleme: Ratenbegrenzungen und Stabilität. Die offiziellen Ratenbegrenzungen von OpenAI für gpt-image-2 sind extrem streng – Tier-1-Konten sind auf nur 5 Anfragen pro Minute limitiert, was bei Batch-Verarbeitung sofort zu 429-Fehlern führt. Zudem führen 5xx-Fehler häufig zu wiederholten Ausfällen. Viele Teams greifen daher auf „offizielle Reverse-Kanäle“ zurück – sie nutzen das Backend von ChatGPT Pro/Codex CLI, um von höheren RPM-Kontingenten und stabileren Verbindungen zu profitieren.
Das auf APIYI (apiyi.com) verfügbare Modell gpt-image-2-vip nutzt genau diesen Reverse-Pfad. Dieser Artikel erläutert die 5 Kernfunktionen, 30 Größenoptionen, 3 kompatiblen Endpunkte und liefert den passenden Code, damit Sie die Schnittstelle direkt produktiv einsetzen können.
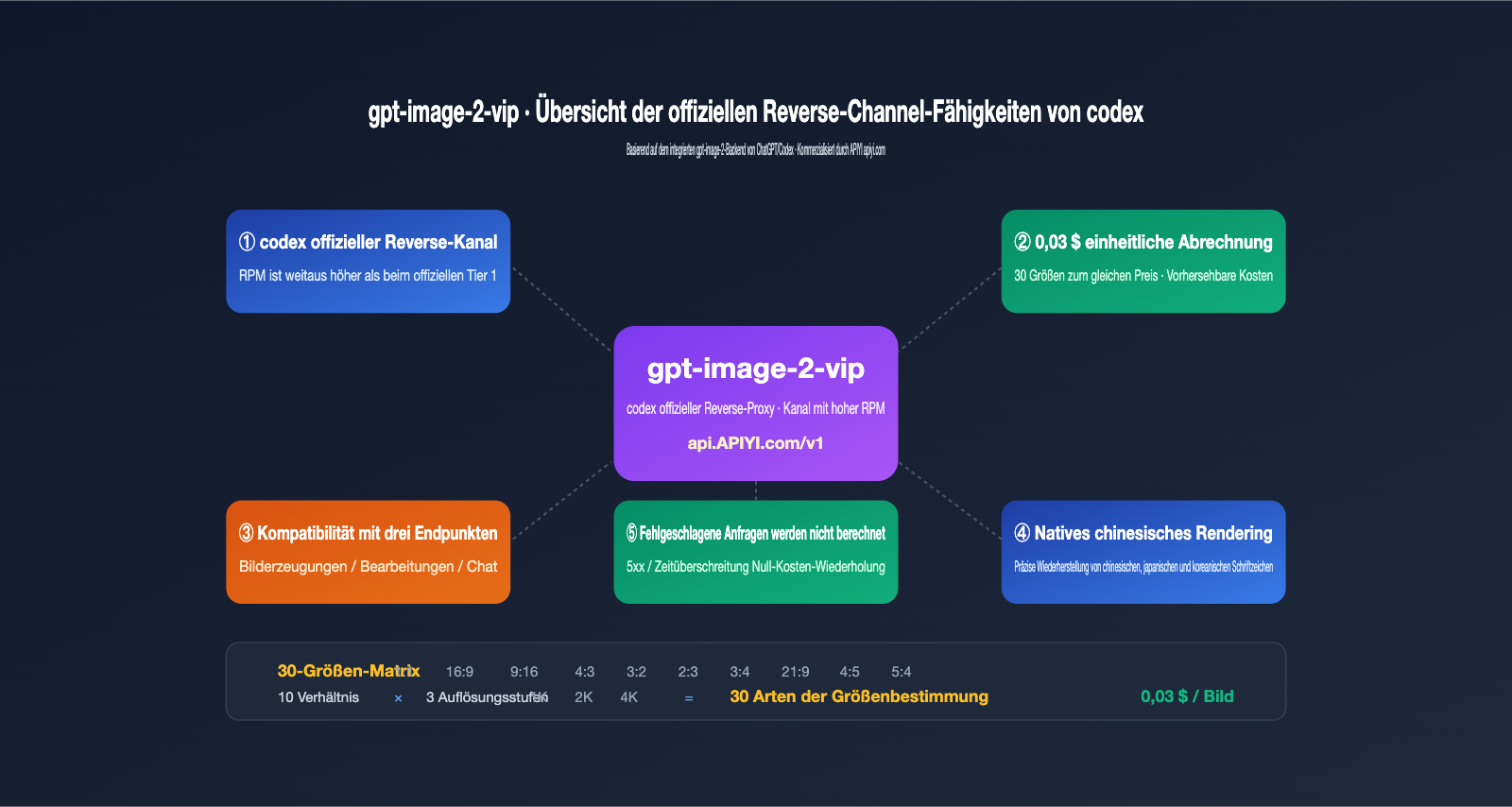
Was ist das "Codex-Offizielle-Reverse-API"? Drei wesentliche Unterschiede zur offiziellen Direktverbindung
Viele Entwickler halten das "Codex-Offizielle-Reverse-API" (Codex 官逆) zunächst für eine illegale Schnittstelle. Tatsächlich bezieht es sich jedoch auf das Reverse-Engineering der internen gpt-image-2-Aufrufkette, die in OpenAIs eigenem Codex CLI und ChatGPT Pro eingebettet ist. Als OpenAI im April 2026 gpt-image-2 veröffentlichte, wurde es gleichzeitig in das Codex CLI (die $imagegen-Funktion) und den ChatGPT-Client integriert. Diese beiden Einstiegspunkte teilen sich einen unabhängigen Ratenbegrenzungspool, der sich von den Drosselungsstrategien der öffentlichen API unterscheidet.
Der "Codex-Offizielle-Reverse-Kanal" macht Folgendes: Er legt den internen Datenstrom von Codex als REST-Schnittstelle offen, sodass Sie gpt-image-2 wie eine normale OpenAI-API verwenden können, während der Aufruf tatsächlich über das Backend von ChatGPT läuft. Das Modell gpt-image-2-vip ist eine solche Implementierung. Im Vergleich zur offiziellen Direktverbindung gibt es drei wesentliche Unterschiede.
| Dimension | OpenAI Offizielle Direktverbindung | Codex-Offizieller-Reverse-Kanal (gpt-image-2-vip) |
|---|---|---|
| Ratenbegrenzung | Tier 1: 5 RPM, erfordert Aufladung zum Freischalten | Nutzt den geteilten Codex-Pool, weit über Tier 1 |
| Abrechnungsmodell | Gestaffelte Abrechnung nach Bildgröße/Qualität | Einheitlich $0,03/Bild, 30 Größen zum gleichen Preis |
| Stabilität | Direkt von offiziellen 5xx-Schwankungen betroffen | Multi-Account-Pool + automatischer Retry, puffert Instabilitäten ab |
quality-Parameter |
Unterstützt low/medium/high/auto | Nicht unterstützt (nutzt interne Codex-Strategie) |
n-Parameter (Batch) |
Unterstützt 1-4 Bilder | Nicht unterstützt, Rückgabe von 1 Bild pro Aufruf |
| URL-Gültigkeit | 60 Minuten | ~24 Stunden |
🎯 Wichtigste Erkenntnis: Bei diesem Reverse-Kanal handelt es sich nicht um ein "Hacking". Es ist lediglich die Bereitstellung der internen Aufrufkette von OpenAIs eigenem Produkt (Codex CLI) als REST-Schnittstelle. APIYI (apiyi.com) macht diesen Kanal zu einem kommerziellen Produkt. Der Kernwert liegt nicht darin, OpenAI zu umgehen, sondern API-Nutzern die stabileren Ratenkontingente der Codex-Seite zur Verfügung zu stellen.
Die 5 Kernmerkmale von gpt-image-2-vip
Nachdem die Unterschiede der Kanäle klar sind, werden die spezifischen Funktionen deutlicher. Die folgenden 5 Punkte sind die wichtigsten Unterschiede zwischen gpt-image-2-vip und den Modellen der gleichen Serie (gpt-image-2-all) sowie dem offiziellen gpt-image-2. Dies sind Details, die in der Dokumentation oft verstreut sind und hier hervorgehoben werden sollen.
Merkmal 1: 30 frei wählbare Größen, einheitliche Abrechnung von $0,03
Der größte technische Mehrwert von gpt-image-2-vip besteht darin, dass die "Größe" zu einem erstklassigen Parameter gemacht wurde. Das Modell unterstützt 10 Seitenverhältnisse × 3 Auflösungsstufen = 30 definierte Größen, die einfach über den size-Parameter festgelegt werden können, ohne dass man die Eingabeaufforderung kompliziert anpassen muss. Die Abrechnung ist noch direkter: Alle 30 Größen kosten einheitlich $0,03 pro Bild, es gibt keine versteckten Kosten für "größere Formate". Für Teams, die vorlagenbasierte Generierungen oder Batch-Vorschaubilder erstellen, bedeutet dies eine enorme Verbesserung der Kostenvorhersehbarkeit.
| Auflösungsstufe | Kurze Seite (Pixel) | Lange Seite (Limit, Pixel) | Anwendungsfall |
|---|---|---|---|
| 1K | ~1024 | ~1820 | Vorschaubilder, Feed-Cover, soziale Medien |
| 2K | ~2048 | ~3640 | Poster, E-Commerce-Hauptbilder, Inhaltskarten |
| 4K | ~2880 | ~3840 | Hochauflösender Druck, Videomaterial, Druckvorlagen |
Die 10 Verhältnisse decken gängige Anforderungen wie 1:1 quadratisch, 16:9 quer, 9:16 hoch, 4:3, 3:2, 21:9 usw. ab, sodass kaum Nachbearbeitungen erforderlich sind. Ein weiterer versteckter Wert der einheitlichen Preisgestaltung ist, dass Sie die Auflösung in Ihrer Produktionspipeline je nach Geschäftsanforderung ändern können, ohne das Finanzmodell zu beeinflussen – zum Beispiel beim A/B-Testen, bei dem Sie dieselbe Eingabeaufforderung in 1K und 4K vergleichen. Die Kosten sind vollständig vorhersehbar und es gibt keine bösen Überraschungen bei der Monatsabrechnung.
Merkmal 2: Volle Kompatibilität mit drei Endpunkten
gpt-image-2-vip unterstützt gleichzeitig die drei Standard-Bild-Endpunkte von OpenAI: /v1/images/generations (reine Text-zu-Bild-Generierung), /v1/images/edits (Bild-zu-Bild und Bearbeitung) sowie /v1/chat/completions (Bilderzeugung über den Chat-Endpunkt). Dies ist entscheidend, da Sie keinen bestehenden SDK-Code umschreiben müssen. Sie müssen lediglich das model von gpt-image-2 auf gpt-image-2-vip ändern und die base_url auf den API-Proxy-Dienst umstellen.
Merkmal 3: Multi-Bild-Fusion und Bild-zu-Bild
Durch das Hochladen von 1-N Bildern über den Endpunkt /v1/images/edits in Kombination mit einer Eingabeaufforderung zur Beschreibung der Syntheseabsicht führt das Modell Stilübertragungen, Inhaltsfusionen und Layout-Neuanordnungen durch. Zum Beispiel können "Produktbild + Modelbild + Hintergrundbild" zu einem einzigen E-Commerce-Hauptbild kombiniert werden. Es wird empfohlen, jedes Bild auf unter 1,5 MB zu komprimieren, da sonst der Verbrauch an Input-Token deutlich ansteigt.
Merkmal 4: Natives Verständnis von Chinesisch
gpt-image-2-vip teilt sich dasselbe Inferenz-Backend wie das offizielle gpt-image-2 und erbt die Fähigkeit zur Darstellung von Texten in Chinesisch, Japanisch, Koreanisch, Hindi und Bengalisch. Chinesische Eingabeaufforderungen müssen nicht ins Englische übersetzt werden; chinesische Titel oder Schaltflächentexte auf Postern können präzise wiedergegeben werden – eine Leistung, die Midjourney oder Stable Diffusion so nicht bieten.
Merkmal 5: Keine Kosten bei fehlgeschlagenen Anfragen
Dies ist ein Detail auf Abrechnungsebene, das jedoch für die Produktion in großem Maßstab enorme Einsparungen bedeutet. Anfragen, die einen 5xx-Fehler zurückgeben, ein Timeout verursachen oder durch Sicherheitsrichtlinien blockiert werden, werden nicht berechnet. Nur erfolgreiche Aufrufe, die ein Bild zurückgeben, werden in Rechnung gestellt. Dies ermöglicht Ihnen, bedenkenlos exponentielle Backoff-Wiederholungsversuche durchzuführen, ohne befürchten zu müssen, dass die Wiederholungen selbst die Rechnung in die Höhe treiben. In Kombination mit der einheitlichen Preisgestaltung von $0,03 pro Bild wird die Kostenschätzung extrem einfach: Wenn Sie 10.000 Bilder planen, kostet das etwa $300 – ohne komplexe Modellierung nach Größe oder Qualität. Das macht die Budgetplanung für Finanz- und Produktteams sehr einfach.
Aufruf-Workflow und Code-Beispiel: Starten Sie mit 5 Zeilen Python
Die Anbindung ist denkbar einfach und entspricht exakt dem offiziellen OpenAI SDK; Sie müssen lediglich base_url und model anpassen. Hier ist ein minimales, ausführbares Beispiel für die Bilderzeugung, bei dem die base_url auf den einheitlichen API-Proxy-Dienst von APIYI (apiyi.com) verweist.
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2-vip",
prompt="Hauptvisualisierung für eine dunkle Tech-Konferenz, zentraler Neon-Titel 『APIYI · gpt-image-2 live』, kleiner Text unten links 2026",
size="2048x1152"
)
img_b64 = resp.data[0].b64_json
with open("poster_2k.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Wenn Sie Bild-zu-Bild-Funktionen oder eine Fusion mehrerer Bilder nutzen möchten, ersetzen Sie einfach client.images.generate durch client.images.edit und fügen Sie image=[open("a.png","rb"), open("b.png","rb")] hinzu. Die Request-Body-Formate aller drei Endpunkte folgen den offiziellen OpenAI-Spezifikationen.
🎯 Tipp für den schnellen Start: Um diesen Workflow in 30 Sekunden zu testen, empfehlen wir, bei APIYI (apiyi.com) einen API-Schlüssel zu erstellen und dann mit
gpt-image-2-vipund einer beliebigen Größe ein Testbild zu generieren. Fehlgeschlagene Anfragen werden nicht berechnet, Sie können also problemlos mit den Parametern experimentieren.
Auswahl der 30 Formate: Schnellübersicht nach Szenario
Viele Nutzer fragen sich bei 30 verfügbaren Größenoptionen, welche sie wählen sollen. Wir haben sie nach Anwendungsfällen kategorisiert. Wichtig zu wissen: Alle Größen kosten gleich viel, wählen Sie also rein nach Ihrem geschäftlichen Bedarf, ohne aus Kostengründen bei der Bildqualität Abstriche machen zu müssen.
| Anwendungsszenario | Empfohlenes Seitenverhältnis | Empfohlene Auflösung | Typische Größe |
|---|---|---|---|
| Artikel-Cover / Social-Media-Header | 16:9 / 3:2 | 2K | 2048×1152 |
| Hochformat (z. B. TikTok/Reels) | 9:16 / 4:5 | 2K | 1152×2048 |
| E-Commerce-Produktbilder | 1:1 | 2K oder 4K | 2048×2048 oder 2880×2880 |
| Website-Hero-Bilder | 21:9 / 16:9 | 4K | 3840×1640 oder 3840×2160 |
| PPT-Präsentationsfolien | 16:9 | 1K oder 2K | 1820×1024 |
| Druckmedien / Poster | 3:4 / 2:3 | 4K | 2880×3840 |
| Feed-Thumbnails | 1:1 | 1K | 1024×1024 |
| Banner-Formate | 21:9 | 1K | 1820×780 |
🎯 Empfehlung zur Größenwahl: Für Produktionsumgebungen empfehlen wir primär die 2K-Stufe. Die Dateigröße pro Bild liegt bei ca. 1-3 MB, was ein optimales Gleichgewicht zwischen Ladegeschwindigkeit und visueller Qualität bietet. Nutzen Sie 4K nur für Drucke oder Großbildschirme und 1K für kleine Szenarien wie Feed-Thumbnails.
Vergleich der drei Kanal-Varianten der gpt-image-2-Serie
Auf APIYI (apiyi.com) stehen derzeit drei verschiedene Modelle für gpt-image-2 zur Verfügung. Es ist leicht, hier die falsche Wahl zu treffen. Damit Sie nach der Implementierung keine unnötige Nacharbeit haben, erläutern wir hier die Unterschiede.
gpt-image-2 (direkte offizielle Anbindung) nutzt die öffentliche OpenAI-API, unterstützt die Parameter quality und n, erfordert jedoch, dass Sie das niedrige Ratenlimit von 5 RPM selbst verwalten. gpt-image-2-all ist ein aggregierter Kanal; er unterstützt zwar alle Parameter, aber die Bildgröße wird über die Eingabeaufforderung gesteuert und ist daher weniger präzise. gpt-image-2-vip ist der Star dieses Artikels: Er nutzt das offizielle Codex-Reverse-Engineering und punktet durch präzise size-Fixierung, einheitliche Preisgestaltung und hohe RPM.
| Modell-ID | Kanaltyp | Rate | Größensteuerung | Parameter 'quality' | Bilder pro Aufruf | Empfohlener Einsatzbereich |
|---|---|---|---|---|---|---|
gpt-image-2 |
Offiziell direkt | Tier-Limit | size präzise |
✅ | 1-4 | Qualitätsstufen-sensibel, seltene Aufrufe |
gpt-image-2-all |
Aggregiert | Mittel | Über Eingabeaufforderung | ✅ | 1-4 | Migration von Alt-Code, benötigt quality |
gpt-image-2-vip |
Codex-Reverse | Hohe RPM | size präzise |
❌ | 1 | Massenproduktion, feste Größe, Stabilität |

Kurze Entscheidungshilfe: Wenn Sie Stabilität bei großen Mengen, feste Größen und eine vorhersehbare Abrechnung benötigen, wählen Sie gpt-image-2-vip. Wenn Sie zwingend quality=high für hohe Wiedergabetreue benötigen, wählen Sie gpt-image-2-all. Nur bei wenigen, seltenen Aufrufen, bei denen Sie den vollen Parameterumfang benötigen, sollten Sie gpt-image-2 in Betracht ziehen.
Best Practices für Stabilität: Timeouts, Retries und URL-Gültigkeit
Die Rate von gpt-image-2-vip ist höher als die des offiziellen Kanals, aber die Generierungsdauer ist länger: Während die offizielle Inferenz etwa 30–60 Sekunden dauert, liegt sie beim VIP-Kanal aufgrund der zusätzlichen Proxy-Schicht und der automatischen Wiederholungsversuche meist bei 90–150 Sekunden. Ihr Produktionscode muss zwingend auf diese Dauer ausgelegt sein, da es sonst zu massiven Timeout-Fehlern kommt.
Praxis-Tipp 1: Timeout auf 300 Sekunden setzen
Das Standard-Timeout des OpenAI-SDKs liegt bei 60 Sekunden, was für gpt-image-2-vip bei weitem nicht ausreicht. Es wird empfohlen, timeout=300 explizit an den Client zu übergeben. Bei sehr komplexen Eingabeaufforderungen kann die Dauer fast 200 Sekunden erreichen, daher sind 300 Sekunden ein sicherer Puffer.
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=300,
max_retries=2
)
Praxis-Tipp 2: Exponentielles Backoff bei 5xx-Fehlern
Obwohl die Proxy-Schicht bereits Wiederholungsversuche durchführt, kann eine zusätzliche Ebene des exponentiellen Backoffs (1s → 2s → 4s) auf Client-Seite die Erfolgsquote weiter steigern. Fehlgeschlagene Anfragen werden nicht berechnet, wodurch Wiederholungsversuche für Sie völlig kostenfrei sind.
Praxis-Tipp 3: Bild-URLs innerhalb von 24 Stunden herunterladen
Die von gpt-image-2-vip zurückgegebenen Bild-URLs sind etwa 24 Stunden lang gültig; danach führen sie zu einem 404-Fehler. Laden Sie das Bild daher sofort nach Erhalt der URL in Ihren eigenen OSS/S3-Speicher hoch. Speichern Sie diese temporären URLs nicht direkt in Ihrer Datenbank. Bei Batch-Aufträgen empfiehlt es sich, den Download innerhalb von 5 Minuten nach der Generierung abzuschließen.
Praxis-Tipp 4: Eingabebilder auf unter 1,5 MB komprimieren
Eingabebilder für die Schnittstelle /v1/images/edits werden mit hoher Wiedergabetreue verarbeitet, wobei die Input-Token direkt von der Pixelanzahl abhängen. Der Token-Verbrauch eines 4K-Referenzbildes kann viermal so hoch sein wie der eines 1024px-Bildes. Skalieren Sie Bilder clientseitig auf eine lange Kante von 1024–2048 Pixeln, bevor Sie sie hochladen – das spart Kosten und beschleunigt die Inferenz.
Praxis-Tipp 5: Keine blockierenden Aufrufe, nutzen Sie asynchrone Warteschlangen
Da eine einzelne Generierung 90–150 Sekunden dauert, dürfen Sie auf keinen Fall synchrone Schleifen für serielle Aufrufe verwenden, da sonst die Verarbeitung von 100 Bildern zwei bis drei Stunden dauern würde. Empfohlen wird der Einsatz von asynchronen Aufgabenwarteschlangen (Celery/asyncio). Der Business-Thread gibt sofort eine Aufgaben-ID zurück, und das Frontend ruft das Ergebnis über Polling oder WebSockets ab. So nutzen Sie die 60 RPM Durchsatzkapazität voll aus und profitieren von den Vorteilen des VIP-Kanals.
Drei praktische Anwendungsszenarien
Nach der Theorie schauen wir uns an, wie gpt-image-2-vip in realen Geschäftsprozessen eingesetzt wird. Die folgenden drei Szenarien werden am häufigsten angefragt:
Szenario 1: Batch-Generierung von E-Commerce-Produktbildern
Eingabe: Ein Produktbild mit weißem Hintergrund + ein chinesischer Werbetext. Ausgabe: 30 Produktbilder in verschiedenen Stilen. Der Prozess nutzt eine feste Vorlage für die Eingabeaufforderung, bei der nur der Platzhalter "Stil" ersetzt wird. Es werden 30 Aufrufe von /v1/images/edits im Batch durchgeführt, wobei die Bildgröße auf 2048x2048 (Standard für E-Commerce) festgelegt ist. Die Kosten für 30 Bilder liegen bei 0,9 $, die Gesamtdauer bei etwa 2 Minuten (bei 60 RPM).
Szenario 2: Lokalisierung von mehrsprachigen Postern
Eingabe: Ein englisches Poster-Basisbild + lokalisierter Text. Ausgabe: Poster in chinesischer, japanischer und koreanischer Sprache. Dank der mehrsprachigen Rendering-Fähigkeiten von gpt-image-2-vip lautet die Eingabeaufforderung einfach: "Ändere den Titel in 'Neuheiten', verwende die Schriftart Source Han Sans und behalte das ursprüngliche Layout bei". Ein Aufruf genügt, um die lokalisierte Version zu erhalten, ohne PSD-Bearbeitung.
Szenario 3: Pipeline für PPT-Folienillustrationen
Eingabe: Eine vom LLM generierte Kapitelbeschreibung. Ausgabe: Eine Illustration pro Seite. Dies ist das Herzstück von "One-Click-PPT"-Tools. Alle Illustrationen werden einheitlich auf 1820x1024 (16:9 Standard) skaliert. Die Qualität ist über den VIP-Kanal standardmäßig hoch. Die Kosten pro Seite betragen 0,03 $, für eine 20-seitige PPT also nur 0,6 $. Zusammen mit den LLM-Textkosten lässt sich eine vollständige PPT für unter 1 $ erstellen.
Die gemeinsame Architektur dieser Szenarien ist: Aufgabenwarteschlange für die Steuerung, Aufruf von gpt-image-2-vip im Hintergrund und sofortige Speicherung im OSS nach der Generierung. Das Frontend verwendet dann die permanenten Links aus dem OSS, nicht die temporären 24-Stunden-URLs des Modells.
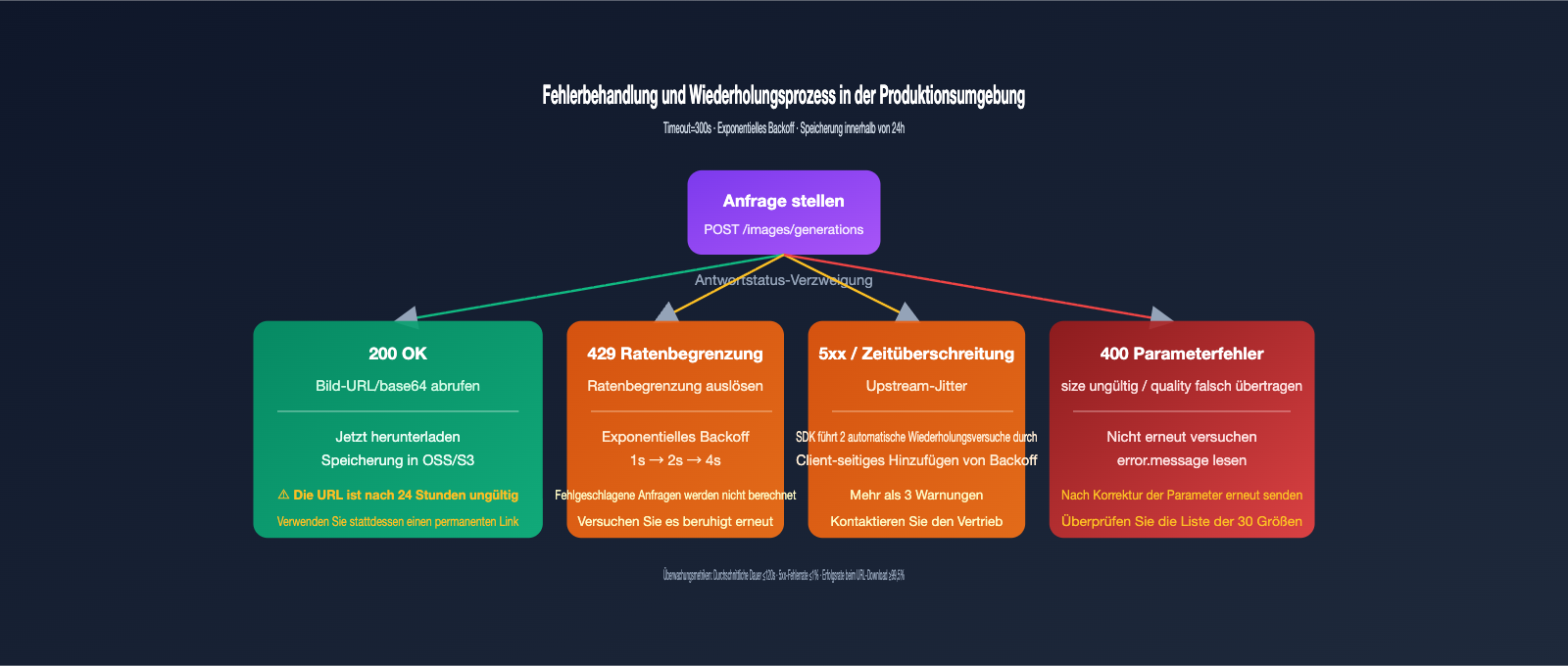
Häufige Fehler und Fehlerbehebung
Die folgende Tabelle deckt die am häufigsten gestellten Fragen aus unserem Support-Chat ab. Mit diesem Abgleich lassen sich 90 % der Integrationsprobleme direkt lösen.
| Fehlererscheinung | Ursache | Lösung |
|---|---|---|
| 408 / 504 Timeout | Timeout-Einstellung zu kurz | Timeout auf 300 Sekunden erhöhen |
| 400 invalid size | Größe ist nicht unter den 30 Standardwerten | Verwenden Sie die in der Dokumentation gelisteten Standardgrößen |
| 400 unsupported_parameter | quality oder n>1 übergeben |
VIP-Kanal unterstützt dies nicht; entfernen Sie diese Felder |
| Bild-URL 404 | URL ist nach 24 Stunden abgelaufen | Laden Sie das Bild direkt nach der Erzeugung in Ihren eigenen Speicher |
| Chinesische Zeichen als Kauderwelsch oder Kästchen | Prompt enthält sehr seltene Zeichen | Verwenden Sie gängige Zeichen oder beschreiben Sie im Prompt: "Verwende Source Han Sans" |
| input_tokens höher als erwartet | Referenzbild zu groß | Clientseitig auf unter 1,5 MB komprimieren |
Häufig gestellte Fragen (FAQ)
Q1: Gibt es Unterschiede in der Bildqualität zwischen gpt-image-2-vip und dem offiziellen Modell?
Das zugrunde liegende Modell ist identisch; beide nutzen den Snapshot gpt-image-2-2026-04-21. Der einzige Unterschied liegt im Routing: Das offizielle Modell nutzt den API-Kontingentpool, während der VIP-Kanal den Codex-Kontingentpool verwendet. Bei der visuellen Qualität gibt es keinen Unterschied; in groß angelegten Blindtests ist kein Unterschied feststellbar.
Q2: Warum wird der quality-Parameter nicht unterstützt?
Die internen Aufrufe des Codex CLI verwenden eine feste quality=high-Strategie. Da der VIP-Kanal diese Route wiederverwendet, kann die Option für die Qualität nicht an die obere Ebene weitergegeben werden. Wenn Ihr Unternehmen zur Kostensenkung low/medium benötigt, verwenden Sie stattdessen gpt-image-2-all.
Q3: Werden fehlgeschlagene Anfragen wirklich nicht berechnet?
Ja, die Abrechnungsstrategie von APIYI (apiyi.com) basiert auf "erfolgreichen Antworten". Fehler mit 4xx-Parametern, 5xx-Serverfehler oder Timeouts werden nicht berechnet. Dies können Sie in Ihrer Abrechnung einzeln überprüfen.
Q4: Kann ich den Dienst direkt von inländischen Servern aufrufen?
Ja. Die Domain api.apiyi.com nutzt eine konforme inländische Route, ohne dass ein VPN erforderlich ist. Dies ist einer der Hauptgründe, warum sich viele Teams für unseren API-Proxy-Dienst entscheiden.
Q5: Wie hoch ist das RPM-Limit des VIP-Kanals?
Es gibt kein öffentlich festgelegtes hartes Limit; es hängt von der Auslastung des Account-Pools ab. In der Praxis erreichen die meisten Unternehmen stabil 60–120 RPM, was weit über den 5 RPM des offiziellen Tier 1 liegt. Für eine höhere Parallelität wenden Sie sich bitte an unseren Vertrieb, um ein Whitelisting zu erhalten.
Q6: Es wird nur ein Bild pro Aufruf zurückgegeben – wie gehe ich bei Stapelverarbeitung vor?
Verwenden Sie einfach eine parallele Schleife im Client. Mit Pythons asyncio.gather oder concurrent.futures.ThreadPoolExecutor lassen sich problemlos 60 RPM erreichen. Da der VIP-Kanal asynchron arbeitet, wird die Parallelität nicht durch die CPU begrenzt; der Flaschenhals liegt lediglich beim RPM des API-Proxy-Dienstes.
Q7: Sind die Ergebnisse bei mehrfachem Aufruf mit demselben Prompt identisch?
Nicht exakt. gpt-image-2-vip nutzt die interne Codex-Strategie und legt den seed-Parameter nicht offen, daher gibt es bei jeder Generierung eine gewisse Zufälligkeit. Wenn Sie reproduzierbare Ergebnisse benötigen, formulieren Sie den Prompt sehr präzise (z. B. mit festen Farbcodes oder detaillierter Bildbeschreibung) oder verwenden Sie das erste zufriedenstellende Bild als Referenzbild für den /v1/images/edits-Endpunkt zur Feinabstimmung.
Q8: Wie überwache ich die Stabilität in der Produktionsumgebung?
Wir empfehlen, clientseitig drei Metriken zu erfassen: durchschnittliche Generierungsdauer, 5xx-Fehlerrate und URL-Download-Erfolgsrate. Unter normalen Bedingungen sollte die durchschnittliche Dauer unter 120 Sekunden liegen, die 5xx-Fehlerrate unter 1 % und die URL-Download-Erfolgsrate über 99,5 %. Sollte einer dieser Werte abweichen, deutet dies auf eine niedrige Auslastung des Account-Pools hin – bitte kontaktieren Sie in diesem Fall unseren Vertrieb für eine Ressourcenanpassung.
Zusammenfassung
gpt-image-2-vip ist ein kommerzielles Produkt zur Bilderzeugung, das auf dem offiziellen Reverse-Channel von Codex basiert. Es löst die Schwachstellen der direkten offiziellen Anbindung durch fünf Kernfunktionen: 30 verschiedene Bildformate + einheitliche Abrechnung von $0,03 + Kompatibilität mit drei Endpunkten + native Unterstützung für Chinesisch + keine Kosten bei fehlerhaften Anfragen. Für Teams, die sich mit Content-Produktion, E-Commerce-Materialien, PPT-Automatisierung oder der Massenerstellung von Postern befassen, ist dies derzeit eine der kosteneffizientesten Lösungen für die Integration von gpt-image-2.
Die Integration erfordert lediglich die Anpassung von base_url und model; der SDK-Code kann vollständig im offiziellen OpenAI-Stil übernommen werden. Für die Produktionsumgebung empfehlen wir, das Timeout auf 300 Sekunden zu setzen, einen exponentiellen Backoff für 5xx-Fehler zu implementieren und die Bild-URLs innerhalb von 24 Stunden lokal zu speichern. Wer diese drei Hürden meistert, kann das System stabil im großen Maßstab betreiben. Wenn Sie derzeit Integrationslösungen für gpt-image-2 für Ihre Produktion evaluieren, können Sie direkt bei APIYI unter apiyi.com ein Konto erstellen und den VIP-Kanal zunächst mit echten Geschäftsdaten testen, bevor Sie eine Entscheidung treffen.
Über den Autor: Das Team von APIYI konzentriert sich auf die aggregierte Integration multimodaler Modelle und eine hochperformante Inferenz-Infrastruktur. Wir bearbeiten täglich zahlreiche Anfragen zur API-Integration für die Bilderzeugung. Dieser Artikel basiert auf realen Produktionsdaten. Detaillierte Parameter zu gpt-image-2-vip finden Sie unter docs.apiyi.com.