
„Warum verbraucht mein Claude Code bei jeder Anfrage 400.000 Eingabe-Token? Warum ist meine Rechnung so hoch?“ – Das ist die erste Reaktion vieler Claude Code-Nutzer, wenn sie ihre Nutzungsstatistiken prüfen. Tatsächlich ist ein Großteil dieser 400.000 Token wahrscheinlich bereits durch Cache-Treffer abgedeckt; die tatsächlichen Kosten betragen oft nur ein Zehntel der angezeigten Summe. Wenn der Cache jedoch nicht greift, kann die Rechnung in der Tat schmerzhaft sein.
Kernnutzen: Nach dem Lesen dieses Artikels werden Sie den automatischen Cache-Mechanismus von Claude Code verstehen, die 8 häufigsten Ursachen für Cache-Fehler kennen und 6 praktische Tipps anwenden können, um Ihre Eingabe-Token von 400.000 auf 50.000 zu reduzieren.
Detaillierter Leitfaden zum automatischen Prompt Caching in Claude Code
Nutzt Claude Code automatisch das Caching?
Ja. Claude Code aktiviert bei jeder API-Anfrage automatisch das Prompt Caching von Anthropic. Dies ist ein integriertes Standardverhalten und keine optionale Funktion.
Jedes Mal, wenn du eine Nachricht in Claude Code sendest, wird der tatsächliche Inhalt für die API in der folgenden Reihenfolge zusammengestellt:
| Reihenfolge | Inhalt | Geschätzte Größe | Caching-Verhalten |
|---|---|---|---|
| Ebene 1 | Tool-Definitionen (Read/Edit/Bash etc.) | ~5.000 Token | Nahezu statisch, hohe Trefferquote |
| Ebene 2 | System-Prompt + CLAUDE.md | ~3.000-10.000 Token | Konstant innerhalb der Sitzung, hohe Trefferquote |
| Ebene 3 | Dialogverlauf (alle vorherigen Nachrichten) | Kontinuierliches Wachstum | Präfix-Abgleich, schrittweise Akkumulation |
| Ebene 4 | Aktuelle neue Nachricht | Variabel | Wird nie zwischengespeichert |
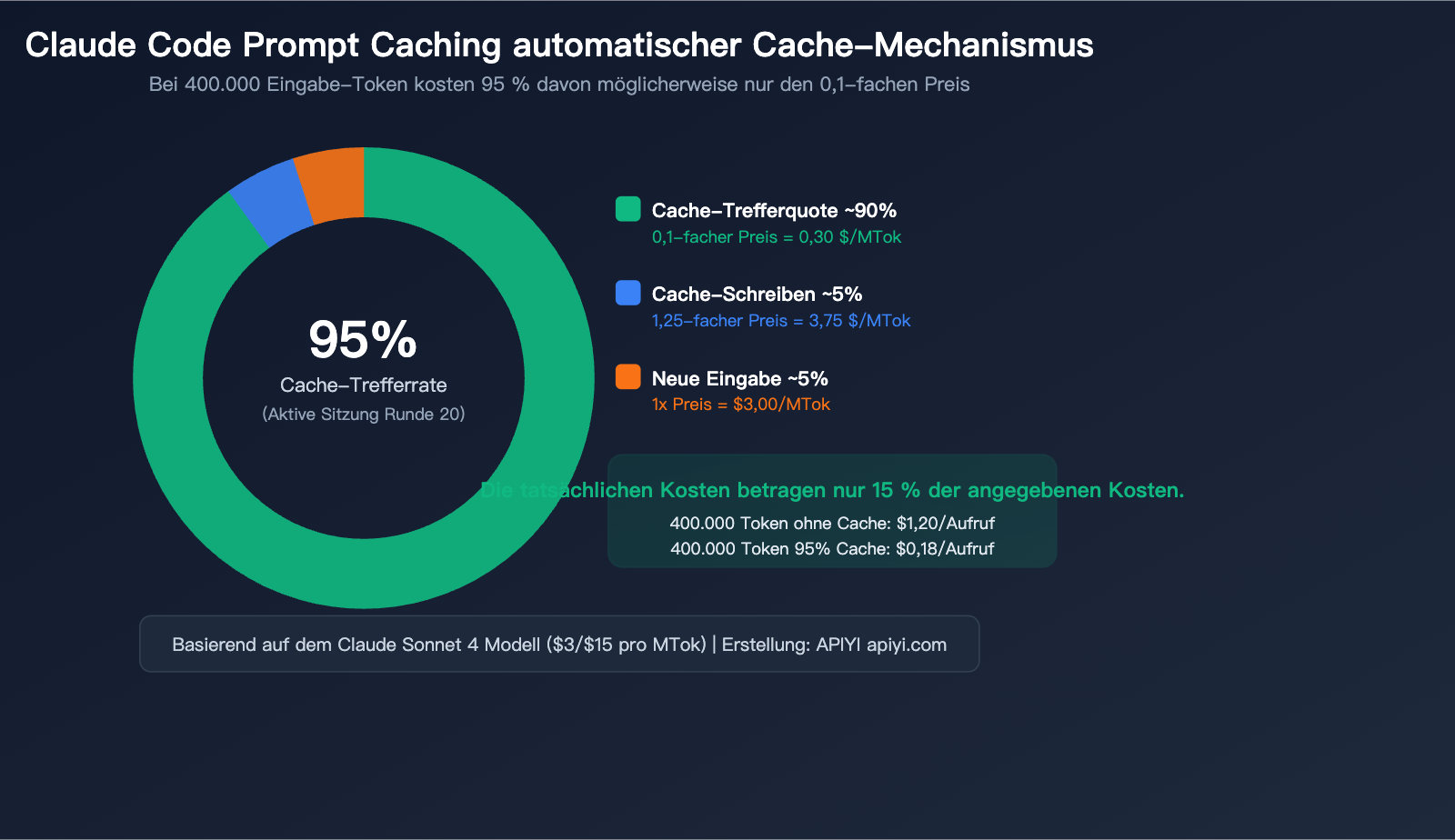
Der entscheidende Mechanismus: Das Caching basiert auf einem Präfix-Abgleich – solange die ersten N Token einer Anfrage exakt mit dem zwischengespeicherten Inhalt übereinstimmen, werden diese N Token aus dem Cache geladen. In einem laufenden Dialog stammen ab der 20. Runde typischerweise über 95 % der Eingabe-Token aus dem Cache.
Cache-Preise: Warum Cache-Treffer so wichtig sind
| Vorgangstyp | Relativer Basis-Eingabepreis | Sonnet 4 Preis/MTok | Opus 4 Preis/MTok |
|---|---|---|---|
| Standard-Eingabe (kein Cache) | 1x | $3,00 | $15,00 |
| 5-Minuten Cache-Schreiben | 1,25x | $3,75 | $18,75 |
| 1-Stunden Cache-Schreiben | 2x | $6,00 | $30,00 |
| Cache-Treffer/Lesen | 0,1x | $0,30 | $1,50 |
| Ausgabe | — | $15,00 | $75,00 |
Ein konkretes Beispiel: Wenn deine Anfrage 400.000 Eingabe-Token umfasst:
Szenario A: Kein Caching
├── 400.000 Token × $3/MTok (Sonnet) = $1,20 pro Anfrage
Szenario B: 95 % Cache-Trefferquote (typische Claude Code-Sitzung)
├── Cache-Treffer 380.000 Token × $0,30/MTok = $0,114
├── Cache-Schreiben 10.000 Token × $3,75/MTok = $0,0375
├── Neue Eingabe 10.000 Token × $3/MTok = $0,03
├── Summe = $0,18 pro Anfrage
└── Tatsächliche Kosten nur 15 % gegenüber ohne Caching
🎯 Technischer Hinweis: Auch bei der Nutzung der Claude API über APIYI (apiyi.com) wird das Prompt Caching unterstützt, wodurch die Eingabekosten bei einem Cache-Treffer um 90 % sinken. Wenn dein Projekt Claude über eine API integriert, empfiehlt es sich, die Prompt-Struktur für eine maximale Trefferquote zu optimieren.
Cache-TTL: Der versteckte Vorteil für Max-Nutzer
| Abo-Modell | Cache-TTL | Schreibkosten | Hinweis |
|---|---|---|---|
| API Pay-as-you-go | 5 Minuten | 1,25x | Cache läuft nach 5 Min. Inaktivität ab |
| Pro / Team | 5 Minuten | 1,25x | Wie oben |
| Max 5x / 20x | 1 Stunde | 2x | Teureres Schreiben, aber 12x längeres Zeitfenster |
Obwohl Max-Nutzer beim Schreiben 2x zahlen (statt 1,25x), bedeutet die 1-stündige TTL, dass der Cache auch nach einer Kaffeepause noch verfügbar ist. Für Entwickler, die nur sporadisch arbeiten, ist dieser Unterschied massiv.
Jeder Cache-Treffer setzt den TTL-Timer zurück, solange du also aktiv bleibst, läuft der Cache praktisch nie ab.
Cache-Treffer bleibt aus? 8 häufige Ursachen und Lösungen
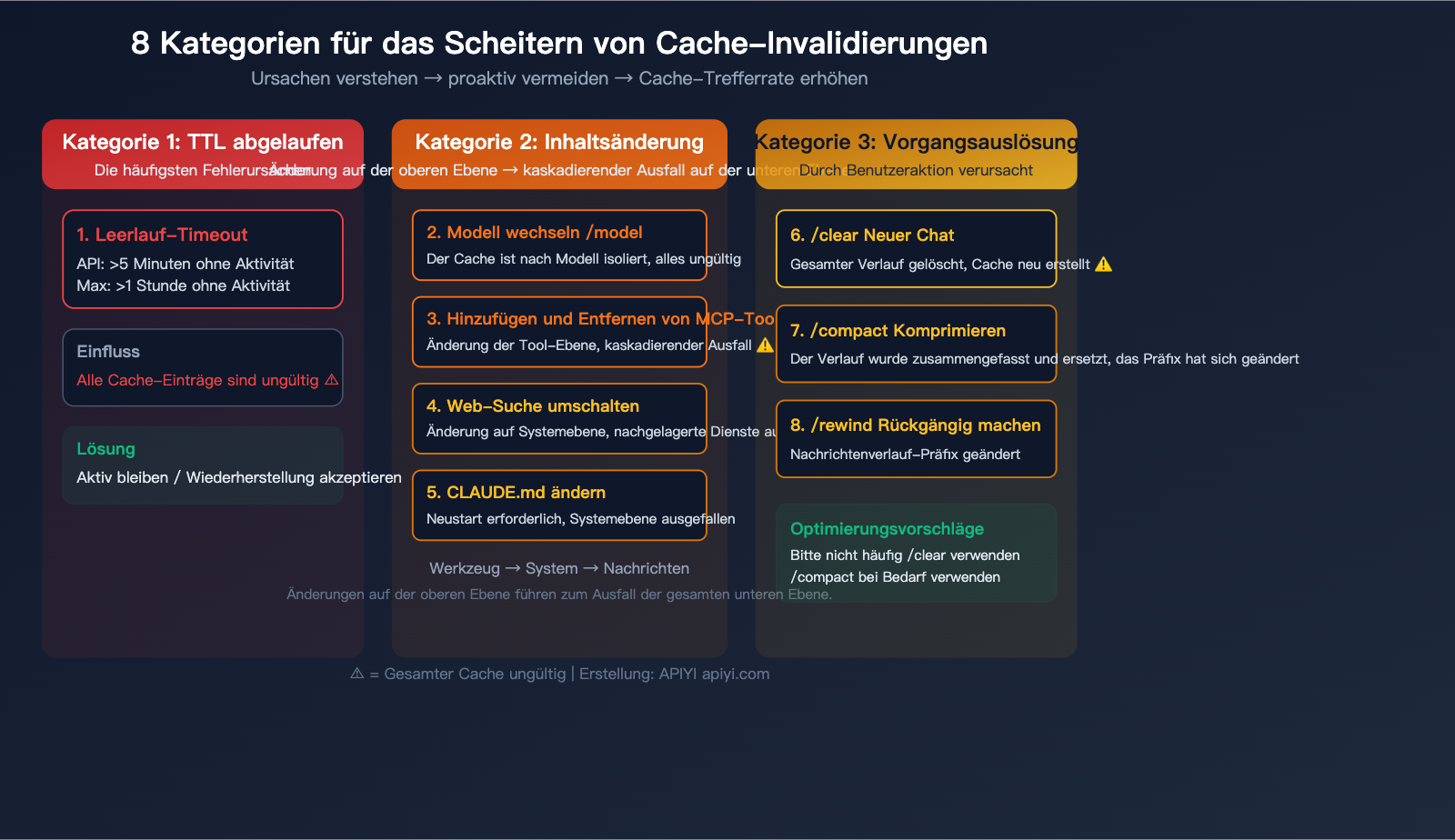
Die grundlegende Ursache für Cache-Verlust ist immer dieselbe: Das Präfix der Anfrage stimmt nicht mit dem zwischengespeicherten Inhalt überein. In Claude Code führen die folgenden 8 Szenarien zum Cache-Verlust:
Kategorie 1: TTL-Ablauf
| Ursache | Auslöser | Auswirkung | Lösung |
|---|---|---|---|
| 1. Leerlauf-Timeout | API-Nutzer >5 Min. inaktiv, Max-Nutzer >1 Std. | Gesamter Cache ungültig | Aktiv bleiben oder Kosten für Neuaufbau akzeptieren |
Dies ist der häufigste Grund. Wenn du während der Arbeit länger als 5 Minuten (API) oder 1 Stunde (Max) pausierst, erzwingt die nächste Anfrage einen vollständigen Cache-Neuaufbau.
Kategorie 2: Kaskadierende Ausfälle durch Inhaltsänderungen
Der Cache folgt einer strikten Hierarchie: Tool-Definitionen → System-Prompt → Dialogverlauf. Änderungen an einer oberen Ebene machen alles darunter ungültig.
| Ursache | Auslöser | Auswirkung | Schweregrad |
|---|---|---|---|
| 2. Modellwechsel | Befehl /model |
Gesamter Cache (isoliert pro Modell) | ⚠️ Hoch |
| 3. MCP-Tools ändern | MCP-Server installieren/deinstallieren | Tool-Ebene + alles Folgende | ⚠️ Hoch |
| 4. Web-Suche umschalten | Websuche aktivieren/deaktivieren | System-Ebene + alles Folgende | ⚠️ Mittel |
| 5. CLAUDE.md bearbeiten | Projekt-Konfig nach Neustart geändert | System-Ebene + alles Folgende | ⚠️ Mittel |
Kategorie 3: Durch Aktionen ausgelöste Ausfälle
| Ursache | Auslöser | Auswirkung | Schweregrad |
|---|---|---|---|
| 6. Neuer Dialog | /clear oder neue Sitzung |
Gesamter Cache (Verlauf gelöscht) | ⚠️ Hoch |
7. /compact nutzen |
Aktive Komprimierung des Verlaufs | Cache des Dialogverlaufs ungültig | ⚠️ Mittel |
8. /rewind nutzen |
Rückgängigmachen von Nachrichten | Präfix des Dialogverlaufs geändert | ⚠️ Mittel |
Ein oft übersehenes technisches Limit: Minimale Cache-Länge
Wenn dein Prompt unter der folgenden Token-Anzahl liegt, wird das Caching stillschweigend übersprungen, ohne Fehlermeldung:
| Modell | Minimale Cache-Länge |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4.096 Token |
| Claude Sonnet 4.6 | 2.048 Token |
| Claude Sonnet 4.5 / 4 | 1.024 Token |
Für Claude Code ist dies kaum relevant, da Tool-Definitionen und System-Prompt bereits über 5.000 Token liegen. Wenn du jedoch eigene Anwendungen über die API baust, solltest du dieses Limit beachten.
💡 Empfehlung: Wenn du eigene Anwendungen über APIYI (apiyi.com) erstellst, stelle sicher, dass die Länge deines System-Prompts den jeweiligen Mindestschwellenwert des Modells überschreitet, da das Caching sonst nicht greift.
Warum du 400.000 Eingabe-Token siehst: Die Kontext-Zusammensetzung von Claude Code
Nachdem wir den Cache-Mechanismus verstanden haben, schauen wir uns an, woraus diese beeindruckenden „400.000 Eingabe-Token“ eigentlich bestehen.
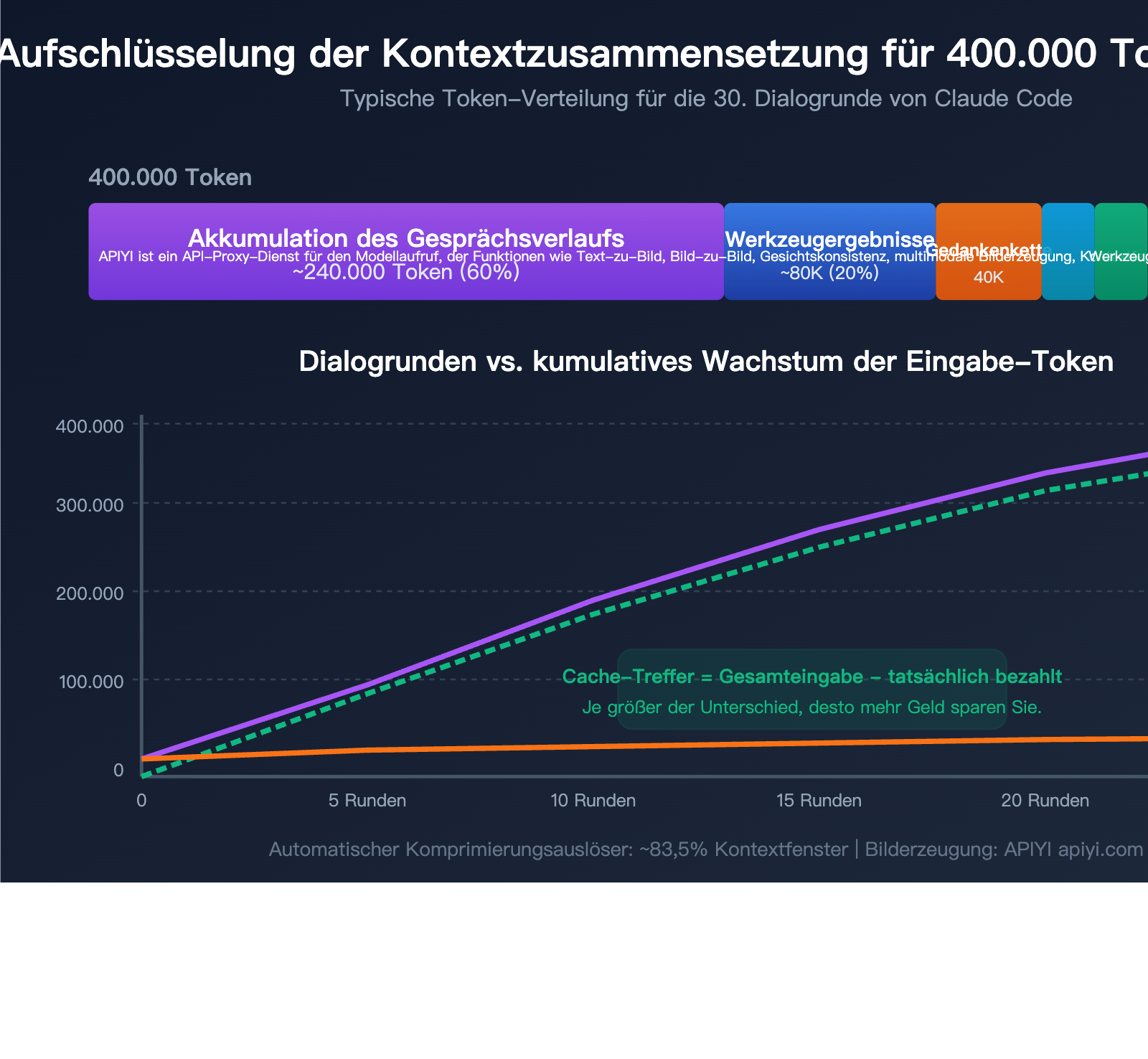
Die 5 Hauptquellen für den Token-Verbrauch
| Quelle | Anteil | Ca. Anteil bei 400k | Besonderheit |
|---|---|---|---|
| Kumulierter Dialogverlauf | ~60% | ~240k | Der gesamte Verlauf wird bei jeder Runde erneut gesendet |
| Ergebnisse von Tool-Aufrufen | ~20% | ~80k | Datei-Lesezugriffe und grep-Suchergebnisse verbleiben im Kontext |
| Erweiterte Gedankenkette | ~10% | ~40k | Thinking-Blöcke der ersten Runden werden zur Eingabe |
| System-Prompt + CLAUDE.md | ~5% | ~20k | Wird jeder Nachricht mitgegeben |
| Tool-Definitionen | ~5% | ~20k | Schema aller verfügbaren Tools |
Der Kern der Sache: Je länger der Dialog, desto größer die Eingabe
Die Arbeitsweise von Claude Code besteht darin, bei jeder Anfrage den vollständigen Dialogverlauf erneut zu senden. Das bedeutet:
- Runde 1: ~20k Token Eingabe (System-Prompt + Tool-Definitionen + deine Frage)
- Runde 5: ~100k Token Eingabe (kumulierter Verlauf aus 4 Runden)
- Runde 15: ~250k Token Eingabe (enthält zahlreiche Datei-Leseergebnisse)
- Runde 30: ~400k+ Token Eingabe (nahe an der automatischen Komprimierungsschwelle)
Aber Achtung: Der Großteil dieser Eingaben ist cache-optimiert. Von den 400.000 Token in Runde 30 sind wahrscheinlich nur 10.000 bis 20.000 neue, nicht zwischengespeicherte Inhalte.
Spezielle Probleme bei großen Codebasen
Claude Code lädt nicht automatisch die gesamte Codebasis in den Kontext. Er liest Dateien bei Bedarf. In großen Projekten passiert jedoch Folgendes:
- Eine einzelne
grep-Suche kann massenhaft Ergebnisse liefern, die alle in den Kontext wandern. - Exploratives Lesen mehrerer Dateien führt dazu, dass jeder Dateiinhalt im Dialogverlauf verbleibt.
- Im Agenten-Modus werden autonom mehrstufige Aktionen ausgeführt, wobei sich die Ergebnisse der Tool-Aufrufe bei jedem Schritt ansammeln.
Dass du bei deinem Kunden 400.000 Token siehst, liegt höchstwahrscheinlich an einer Kombination dieser Faktoren:
- Die Codebasis ist umfangreich und Claude Code hat viele Dateien zur Analyse gelesen.
- Es gab viele Dialogrunden, wodurch sich der Verlauf aufsummiert hat.
- Es wurden möglicherweise keine Befehle wie
/compactoder/clearverwendet. - Die
CLAUDE.md-Datei könnte sehr umfangreich sein.
6 Praxistipps: Reduzieren Sie Ihre Eingabe-Token von 400.000 auf 50.000
Tipp 1: Präzise Anweisungen, um globale Scans zu vermeiden
Dies ist die wichtigste und am einfachsten umzusetzende Optimierung.
❌ Vage Anweisungen (lösen umfangreiche Dateiscans aus):
"Hilf mir, die Performance dieses Projekts zu optimieren"
"Überprüfe den Code auf Bugs"
"Refactore dieses Modul"
✅ Präzise Anweisungen (lesen nur notwendige Dateien):
"Optimiere die Antwortzeit der Funktion processRequest in src/api/handler.ts"
"Behebe die NullPointerException in Zeile 45 von src/auth/login.ts"
"Migriere die Funktion formatDate in src/utils/format.ts von moment zu dayjs"
Vage Anweisungen führen dazu, dass Claude Code eine Kombination aus Glob, Grep und Read verwendet, um eine große Anzahl an Dateien zu "verstehen". Der Inhalt jeder Datei verbleibt dauerhaft im Dialogverlauf. Präzise Anweisungen sorgen dafür, dass nur 1-2 relevante Dateien gelesen werden.
Token-Einsparung: Reduziert die Token für Tool-Aufrufe um 60-80 %.
Tipp 2: Nutzen Sie /clear und /compact rechtzeitig
# Dialog leeren, wenn zu einer anderen Aufgabe gewechselt wird
/clear
# Verlauf komprimieren, wenn der Dialog lang ist, die Aufgabe aber noch läuft
/compact
# Komprimierung mit Anweisung, um spezifische Informationen zu behalten
/compact Behalte Code-Beispiele und API-Schnittstellendefinitionen bei, der Rest kann gekürzt werden
| Befehl | Effekt | Anwendungsszenario | Hinweise |
|---|---|---|---|
/clear |
Löscht den gesamten Dialogverlauf | Wechsel zu einer völlig anderen Aufgabe | Der gesamte Cache wird ungültig |
/compact |
KI fasst den Verlauf zusammen und ersetzt den Originaltext | Mittlere Phase langer Dialoge | Cache teilweise ungültig, aber Kontext massiv reduziert |
Effekt: Ein Dialog mit 400.000 Token kann nach /compact meist auf 50.000 bis 80.000 Token komprimiert werden.
Tipp 3: Optimieren Sie die Datei CLAUDE.md
Die CLAUDE.md wird bei jeder Nachricht geladen. Eine 10.000-Token-CLAUDE.md wird in 30 Dialogrunden 30-mal gesendet (auch wenn nach einem Cache-Treffer nur 0,1x Kosten anfallen, belegt sie dennoch wertvollen Kontextplatz).
Optimierungsvorschläge:
├── CLAUDE.md auf unter 500 Zeilen begrenzen (Kernregeln)
├── Detaillierte Workflow-Beschreibungen in "Skills" verschieben (bei Bedarf laden)
├── Referenzdokumentation in "knowledge-base/" ablegen (bei Bedarf lesen)
└── Lange Beispiel-Codeblöcke in CLAUDE.md vermeiden
🚀 Praxistipp: Eine schlanke CLAUDE.md spart nicht nur Token,
sondern hilft Claude Code, sich auf die Kernregeln zu konzentrieren.
Wenn Sie APIYI (apiyi.com) nutzen, um ähnliche KI-Coding-Assistenten zu erstellen,
empfiehlt es sich ebenfalls, die Länge der System-Eingabeaufforderung zu begrenzen.
Tipp 4: Nutzen Sie Subagents, um redundante Ausgaben zu isolieren
Wenn Sie Operationen ausführen, die große Ausgaben erzeugen, verwenden Sie stattdessen einen Subagent:
❌ Direkte Ausführung im Hauptdialog (Ausgabe landet komplett im Hauptkontext):
"Führe die Testsuite aus und analysiere die Fehlerursachen"
→ Die Testausgabe kann 50.000+ Token umfassen und bleibt dauerhaft im Verlauf
✅ Claude Code einen Subagent nutzen lassen (Ausgabe isoliert im Subprozess):
"Führe die Testsuite in einer Teilaufgabe aus und fasse mir nur die Namen der fehlgeschlagenen Tests und die Ursachen zusammen"
→ Der Hauptkontext wächst nur um ca. 500 Token für die Zusammenfassung
Token-Einsparung: Einsparung von 10.000-50.000 Token pro Vorgang im Hauptkontext.
Tipp 5: Wählen Sie das passende Modell und die "effort"-Stufe
| Aufgabentyp | Empfohlenes Modell | Effort-Stufe | Hinweis |
|---|---|---|---|
| Einfache Änderungen/Formatierung | Sonnet | low | Kein tiefes Nachdenken erforderlich |
| Reguläre Entwicklung | Sonnet | medium | Bestes Preis-Leistungs-Verhältnis |
| Komplexe Architekturplanung | Opus | high | Erfordert tiefes Schlussfolgern |
| Code-Review | Sonnet | medium | Preis-Leistung besser als bei Opus |
# Denktiefe reduzieren, um Thinking-Token zu minimieren
# Bei einfachen Aufgaben niedrigeren Effort einstellen
/effort low
# Oder Steuerung des Limits für Thinking-Token über Umgebungsvariablen
MAX_THINKING_TOKENS=8000
Erweiterte Gedankengänge (Thinking) werden in nachfolgenden Runden zu einem Teil der Eingabe-Token. Eine niedrigere Effort-Stufe kann die kumulierten Token in späteren Runden deutlich reduzieren.
Tipp 6: Überwachen Sie die Token-Verteilung mit dem Befehl /context
# Aktuelle Token-Verteilung anzeigen
/context
Der Befehl /context zeigt den Token-Anteil der verschiedenen Teile Ihres aktuellen Kontexts an und hilft Ihnen zu lokalisieren, was den meisten Platz verbraucht. Häufige Erkenntnisse:
- Ein Grep-Suchergebnis lieferte 20.000 Token, aber nur 5 % waren nützlich.
- Eine zuvor gelesene große Datei wird nicht mehr benötigt, belegt aber weiterhin Kontext.
- Die CLAUDE.md nimmt unerwartet viel Platz ein.
Nachdem Sie das Problem identifiziert haben, können Sie gezielt /compact oder /clear einsetzen.
💰 Kostentipp: Für Nutzer, die nach API-Verbrauch bezahlen, können diese Optimierungen die Rechnung direkt senken.
Über die Nutzungsstatistik der Plattform APIYI (apiyi.com) können Sie die Token-Verteilung pro Anfrage genau einsehen
und so Kostentreiber gezielt identifizieren.
Praxisbeispiel: Von 60 $ auf 8 $ Tageskosten
Hier ist ein echter Optimierungsprozess:
Vor der Optimierung (Großes Python-Projekt, intensiver Claude Code-Nutzer)
Tägliche Nutzung:
├── Dialogrunden: ~50 Runden/Tag
├── Durchschnittliche Eingabe-Token: 350.000-450.000/Runde
├── Cache-Trefferquote: ~70% (durch häufiges /clear und Modellwechsel)
├── Tägliche API-Kosten (Opus 4): ~$60
└── Monatlich: ~$1.320
Nach der Optimierung (Anwendung von 6 Tipps)
Tägliche Nutzung:
├── Dialogrunden: ~40 Runden/Tag (präziser, weniger Runden nötig)
├── Durchschnittliche Eingabe-Token: 80.000-120.000/Runde (präzise Eingabeaufforderung + regelmäßiges Compact)
├── Cache-Trefferquote: ~92% (Reduzierung unnötiger Cache-Unterbrechungen)
├── Tägliche API-Kosten (hauptsächlich Sonnet 4, Opus nur für komplexe Aufgaben): ~$8
└── Monatlich: ~$176
| Optimierungspunkt | Einsparungsanteil | Erläuterung |
|---|---|---|
| Präzise Eingabeaufforderung statt vager Scans | ~35% | Größter Gewinnfaktor |
| Zeitnahes /compact und /clear | ~25% | Kontrolle der kumulativen Ausdehnung |
| Sonnet statt Opus (80% der Aufgaben) | ~20% | Modell-Downgrade ohne spürbaren Qualitätsverlust |
| CLAUDE.md straffen | ~8% | Reduzierung des fixen Overheads pro Runde |
| Subagent zur Isolierung langatmiger Ausgaben | ~7% | Vermeidung von Kontextverschmutzung durch große Blöcke |
| Effort-Level senken | ~5% | Reduzierung der Thinking-Token-Akkumulation |
Häufig gestellte Fragen
Q1: Sind die 400.000 Token, die Claude Code anzeigt, die tatsächlich berechneten 400.000?
Nein. Claude Code aktiviert automatisch das Prompt Caching. In einer aktiven Sitzung sind 95%+ der Eingabe-Token normalerweise Cache-Treffer, die nur mit 0,1x des Basispreises berechnet werden. Von 400.000 Token werden möglicherweise nur 20.000 bis 40.000 zum vollen Preis abgerechnet. Du kannst mit /context die tatsächliche Cache-Trefferquote einsehen. Über APIYI (apiyi.com) aufgerufene APIs unterstützen ebenfalls den Cache-Mechanismus.
Q2: Muss ich mich bei einem Max-Monatsabo noch um den Token-Verbrauch kümmern?
Ja, aber aus einem anderen Grund. Das Max-Abo wird nicht nach Token abgerechnet, hat aber ein wöchentliches Nutzungslimit. Ein zu hoher Token-Verbrauch führt dazu, dass du das Limit schneller erreichst. Die Straffung des Kontexts verlängert nicht nur die Nutzungsdauer, sondern hilft Claude Code auch, deine Anforderungen präziser zu verstehen (je präziser der Kontext, desto besser die Antwort).
Q3: Was ist besser: /compact oder /clear?
Das hängt vom Szenario ab. Wenn du eine völlig neue Aufgabe beginnst, ist /clear besser, um alles vollständig zu löschen. Wenn du dich noch in derselben Aufgabe befindest, das Gespräch aber sehr lang geworden ist, verwende /compact, um den wichtigen Kontext beizubehalten und gleichzeitig das Volumen zu komprimieren. /compact unterstützt benutzerdefinierte Anweisungen, z. B. /compact Alle Code-Änderungsprotokolle und API-Schnittstellendefinitionen beibehalten.
Q4: Optimiert ein Upgrade auf die neueste Claude Code-Version den Token-Verbrauch automatisch?
Ja, es ist ratsam, immer die neueste Version zu verwenden. Anthropic optimiert kontinuierlich die Kontextverwaltungsstrategien von Claude Code, einschließlich der Zeitpunkte für die automatische Komprimierung (derzeit bei ca. 83,5% Kontextauslastung), das verzögerte Laden von MCP-Tool-Definitionen (nur Tool-Namen werden geladen, das vollständige Schema erst bei Bedarf) usw. Neue Versionen führen in der Regel zu besseren Cache-Trefferquoten und einer intelligenteren Kontextverwaltung.

Zusammenfassung: Cache verstehen + präzise Nutzung = kontrollierbare Kosten
Das Prompt Caching von Claude Code ist ein äußerst leistungsfähiger Mechanismus zur automatischen Optimierung – Sie müssen nichts konfigurieren, es spart bereits Geld für Sie. Wenn Sie jedoch die Funktionsweise und die Bedingungen für Cache-Fehlschläge verstehen, können Sie die Ersparnis von „automatischen 70 %“ auf „aktive 95 %“ steigern.
Beachten Sie diese 3 Kernprinzipien:
- Cache aktiv halten: Vermeiden Sie unnötige Aktionen, die den Cache unterbrechen (häufiges Wechseln des Modells, willkürliches
/clear). - Kontext-Aufblähung kontrollieren: Präzise Anweisungen + regelmäßiges
/compact, damit der Gesprächsverlauf nicht unendlich wächst. - Die richtigen Werkzeuge und Modelle wählen: Für 80 % der Aufgaben reicht Sonnet völlig aus; sparen Sie Opus für Szenarien auf, in denen es wirklich benötigt wird.
Für Nutzer, die nach Verbrauch bezahlen, empfehlen wir, die Claude-Modellaufrufe zentral über APIYI (apiyi.com) zu verwalten und die Nutzungsüberwachungsfunktionen der Plattform zu verwenden, um den Token-Verbrauch kontinuierlich zu optimieren. Für intensive interaktive Nutzer empfehlen wir den direkten Wechsel zum Claude Max-Abonnement, um in Kombination mit den hier genannten Optimierungstipps das beste Preis-Leistungs-Verhältnis zu erzielen.
📝 Autor dieses Artikels: APIYI Technical Team | APIYI apiyi.com – Die einheitliche Plattform für den Zugriff auf über 300 KI-Große Sprachmodelle
Referenzen
-
Anthropic Prompt Caching Dokumentation: Detaillierte Erläuterung des offiziellen Cache-Mechanismus
- Link:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Hinweis: Cache-TTL, Preis-Multiplikatoren und Mindestlängenanforderungen.
- Link:
-
Claude Code Kostenmanagement-Leitfaden: Offizielle Empfehlungen zur Token-Optimierung
- Link:
code.claude.com/docs/en/costs - Hinweis: Von Anthropic offiziell empfohlene Strategien zur Kostenkontrolle.
- Link:
-
Claude Code Best Practices: Kontextmanagement und Effizienzoptimierung
- Link:
anthropic.com/engineering/claude-code-best-practices - Hinweis: Enthält praktische Tipps wie präzise Eingabeaufforderungen und die Verwendung von
/compact.
- Link: