
ملاحظة المؤلف: شرح تفصيلي لكيفية بناء خط إنتاج لفحص جودة مسائل الفيزياء باستخدام ثلاثة نماذج لغة كبيرة: Gemini 3.1 Pro، وClaude Sonnet 4.6، وGPT-5.4، مع قوالب موجهات جاهزة وأمثلة كود.
يُعد استخدام النماذج اللغوية الكبيرة لفحص جودة مسائل الفيزياء مجالًا يكتسب اهتمامًا متزايدًا من المؤسسات التعليمية ومنصات التعلم عبر الإنترنت. فالتصحيح اليدوي التقليدي ليس فقط غير فعال، بل يعاني أيضًا من اختلافات ذاتية بين المصححين. تقدم هذه المقالة دليلًا لبناء نظام آلي عالي الدقة لفحص مسائل الفيزياء باستخدام ثلاثة من أقوى نماذج الاستدلال في عام 2026: Gemini 3.1 Pro Preview، وClaude Sonnet 4.6، وGPT-5.4.
القيمة الأساسية: بعد قراءة هذا المقال، ستتمكن من إتقان سير العمل الكامل لفحص مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة – بدءًا من تصميم الموجهات وحتى التحقق المتبادل باستخدام نماذج متعددة، لإنشاء حل آلي تزيد دقته عن 90%.
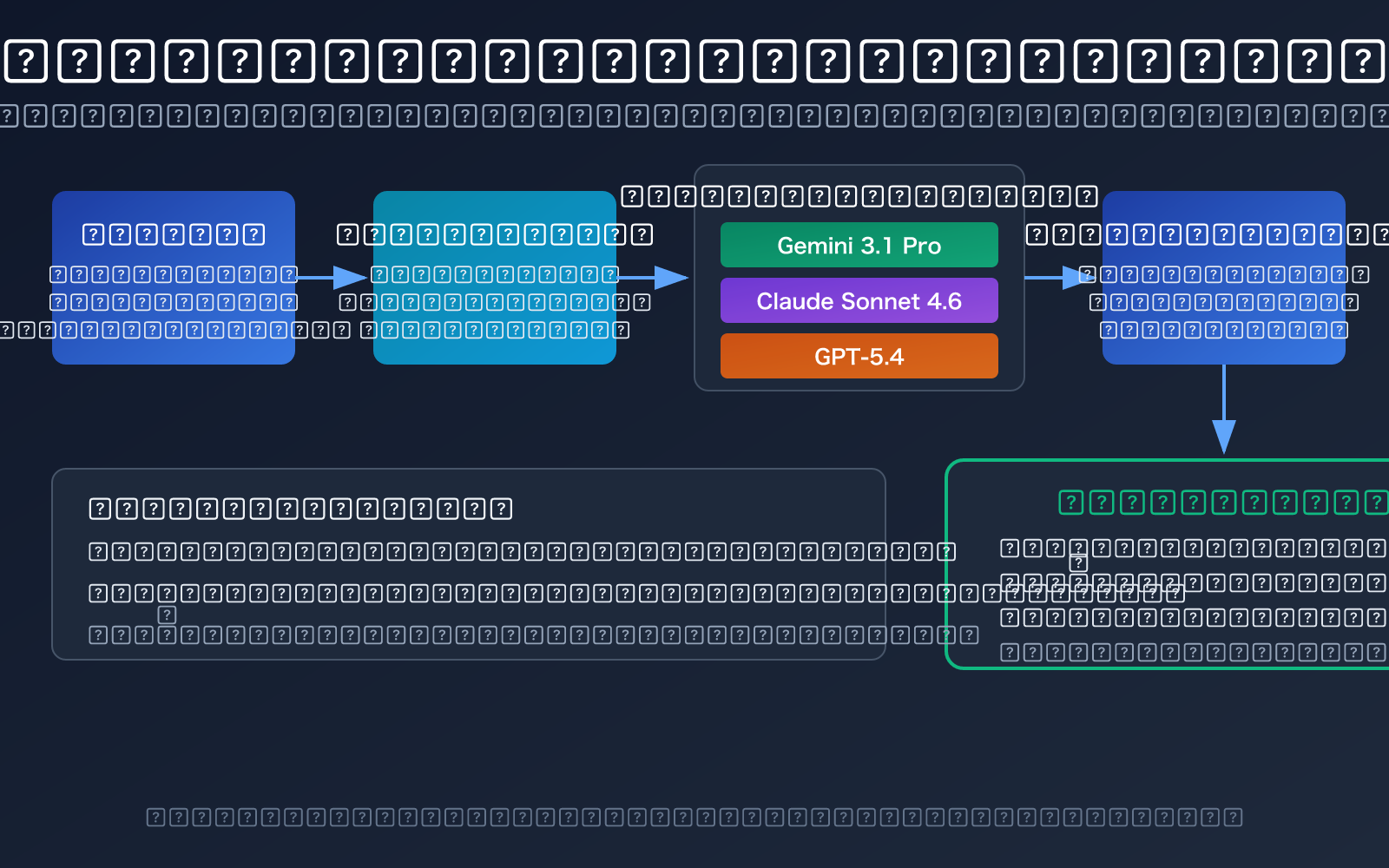
النقاط الأساسية لفحص جودة مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة
يختلف فحص جودة مسائل الفيزياء عن تصحيح النصوص العادية اختلافًا جوهريًا – فهو يتطلب من النموذج أن يمتلك في الوقت نفسه قدرة على الاستنتاج الرياضي، وفهم المفاهيم الفيزيائية، واتساقًا في التقييم. فيما يلي مقارنة للقدرات الأساسية لثلاثة نماذج موصى بها:
| النقطة | الشرح | القيمة العملية |
|---|---|---|
| تفوق قدرة Gemini 3.1 Pro على الاستدلال | حصل على 95.1% في معيار MATH، و77.1% في ARC-AGI-2، ويحتل المرتبة الأولى في تقييم الاستدلال الفيزيائي | أعلى دقة في التعامل مع مسائل الحساب في الميكانيكا والكهرومغناطيسية التي تتضمن استنتاج معادلات |
| وضوح خطوات الحل لدى Claude Sonnet 4.6 | يدعم وضع التفكير التكيفي، مع تحسن قدراته الرياضية بنسبة 27 نقطة مئوية إلى 89% | يمكنه إخراج أساس التقييم الكامل وأسباب خصم الدرجات، مما يجعله مناسبًا لتوليد تقارير فحص الجودة |
| أداء GPT-5.4 المتميز في المسائل التنافسية الصعبة | حصل على الدرجة الكاملة في AIME 2025، ويدعم سياقًا بسعة 1 مليون رمز | يقدم أطول سلسلة استدلالية عند التعامل مع مسابقات الفيزياء والمسائل الشاملة |
| التحقق المتقاطع متعدد النماذج | تقييم مستقل من 3 نماذج ثم أخذ الإجماع | رفع الدقة من 85-90% (نموذج واحد) إلى أكثر من 95% |
3 تحديات رئيسية في فحص جودة مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة
التحدي الأول: تحديد تكافؤ استنتاج المعادلات. لنفس مسألة الميكانيكا، قد يحل الطالب المسألة باستخدام حفظ الطاقة، أو باستخدام قانون نيوتن الثاني. عملية الاستنتاج تختلف تمامًا بين الطريقتين، لكن النتيجة متكافئة. تظهر الدراسات أنه إذا لم يتم توضيح في الموجه (Prompt) مطالبة النموذج بقبول الحلول المكافئة، فسيقوم النموذج بتقييم الحلول بشكل جامد وفقًا لمسار الحل في الإجابة النموذجية، مما يؤدي إلى معدل خطأ في التقييم يصل إلى 30%. هذه هي النقطة الأكثر شيوعًا لفقدان الدقة في فحص جودة مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة.
التحدي الثاني: التعامل مع التسامح في الوحدات الفيزيائية والأرقام المعنوية. في الحسابات الفيزيائية، تختلف النتائج عند الاحتفاظ برقمين معنويين مقابل ثلاثة أرقام معنوية، ولكن يجب قبولها جميعًا عادةً. تحديد نطاق تسامح رقمي معقول في الموجه (Prompt) (مثل ±5%) هو ضمان رئيسي لدقة فحص الجودة.
التحدي الثالث: فهم الأسئلة التي تحتوي على رسوم بيانية وتجارب. الأسئلة التي تتضمن دوائر كهربائية أو رسومًا تخطيطية للميكانيكا تتطلب من النموذج امتلاك قدرة فهم متعددة الوسائط. يظهر أداء Gemini 3.1 Pro و GPT-5.4 أفضل في هذا الجانب، بينما يكون Claude Sonnet 4.6 أكثر استقرارًا في الاستدلال النصي البحت ومع المعادلات.
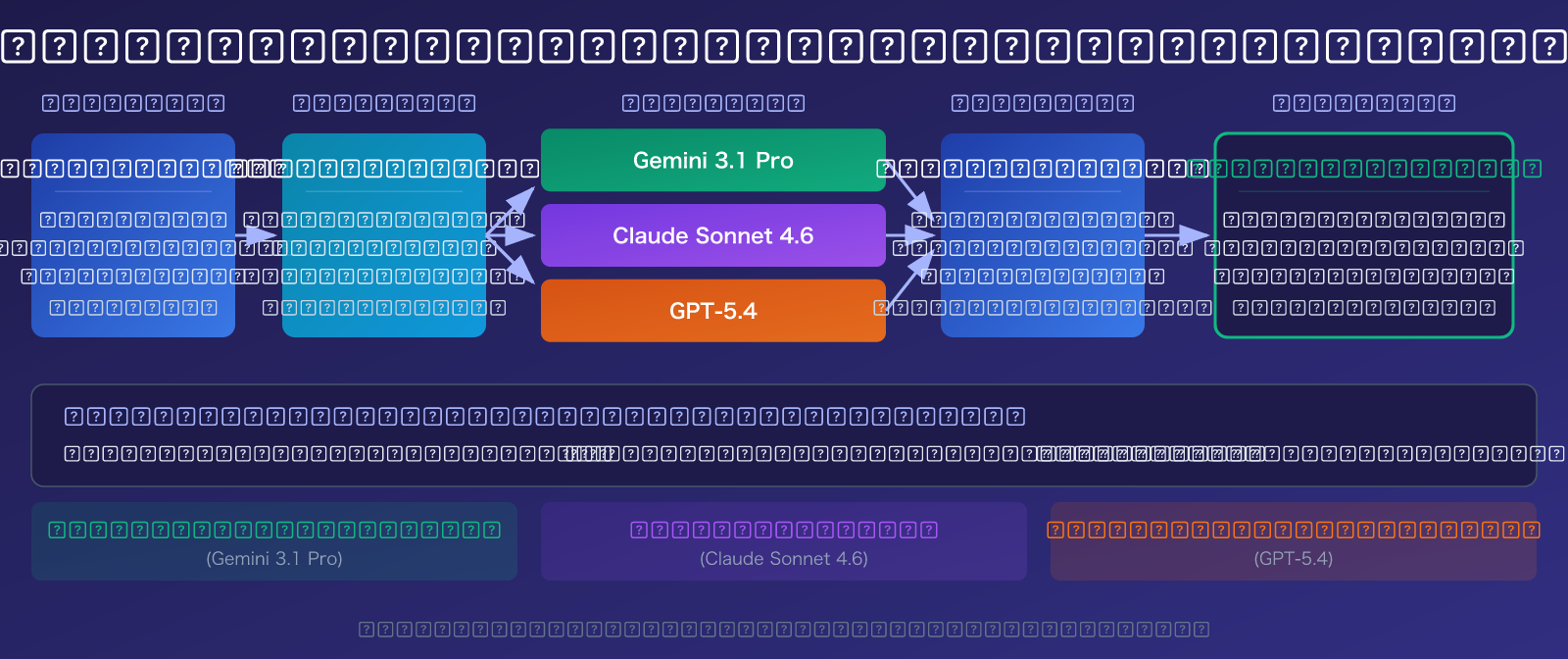
3 نماذج لغة كبيرة موصى بها لفحص جودة المسائل الفيزيائية
Gemini 3.1 Pro Preview: الخيار الأمثل للاستدلال الفيزيائي
Gemini 3.1 Pro هو النموذج الرئيسي الذي أطلقه Google DeepMind في فبراير 2026. في سياق فحص جودة المسائل الفيزيائية، يتمتع بثلاث مزايا أساسية:
- أقوى قدرة على الاستدلال في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM): يحتل المرتبة الأولى في تقييم CritPt (الاستدلال الفيزيائي على مستوى البحث)، ويصل إلى 95.1% في معيار MATH.
- قابلية ضبط عمق التفكير: أضيفت معلمة
thinking_level(تدعم LOW/MEDIUM/HIGH)، يمكن استخدام LOW للمسائل الاختيارية البسيطة لتقليل التكلفة، واستخدام HIGH للمسائل الحسابية المعقدة لضمان الدقة. - قيمة مقابل سعر عالية جداً: التكلفة تبلغ حوالي 1/7.5 من تكلفة Claude Opus 4.6، مما يجعله مناسباً لمهام الفحص بكميات كبيرة.
Claude Sonnet 4.6: الأفضل في إنشاء تقارير الفحص
تم إطلاق Claude Sonnet 4.6 في 17 فبراير 2026، وتكمن ميزته الفريدة في فحص المسائل الفيزيائية في:
- وضع تفكير تكيفي: يقرر النموذج عمق الاستدلال تلقائياً بناءً على صعوبة السؤال، فيصدر أحكاماً سريعة للمسائل البسيطة ويقوم باستدلال عميق للمسائل المعقدة.
- نافذة سياق بسعة 1 مليون رمز (Token): يمكن إدخال جميع أسئلة الامتحان والإجابات النموذجية دفعة واحدة، مما يحافظ على اتساق معايير التقييم.
- قوة عالية في تنظيم المخرجات: يتفوق بشكل خاص في إنشاء تقارير فحص منسقة، تتضمن التقييم ونقاط الخصم واقتراحات التحسين.
GPT-5.4: أداة فعالة للمسائل عالية الصعوبة
تم إطلاق GPT-5.4 في 5 مارس 2026، وهو أحدث نموذج رئيسي من OpenAI:
- درجة كاملة في الرياضيات التنافسية: حقق نسبة صحة 100% في اختبار AIME 2025، وتبرز قدرته على معالجة المسائل الفيزيائية المعقدة عالية الصعوبة.
- قدرة على التخطيط المسبق: تدعم نسخة GPT-5.4 Thinking ميزة "Upfront Planning"، حيث تعرض خطط الاستدلال أولاً ثم تقدم التقييم.
- كفاءة مثلى في استخدام الرموز (Tokens): مقارنةً بـ GPT-5.2، انخفض استهلاك الرموز للاستدلال بشكل كبير، مما يقلل التكلفة على المدى الطويل.
| النموذج | قدرة الاستدلال الفيزيائي | جودة إنشاء التقارير | دعم الوسائط المتعددة | التكلفة لكل مليون رمز (Token) | السيناريو الموصى به |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | الأقل | الفحص اليومي بكميات كبيرة، الأسئلة التي تحتوي على رسوم بيانية |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | متوسط (3 دولارات / 15 دولاراً) | الحاجة إلى تقارير فحص مفصلة، تقييم امتحان كامل |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | أعلى | المسائل التنافسية، المسائل الشاملة الكبيرة، الفحص عالي الصعوبة |
🎯 نصيحة للاختيار: للفحص اليومي، يُفضل اختيار Gemini 3.1 Pro (الأفضل من حيث القيمة مقابل السعر)، وللحاجة إلى تقارير مفصلة اختر Claude Sonnet 4.6، وللمسائل التنافسية عالية الصعوبة استخدم GPT-5.4. من خلال منصة APIYI على apiyi.com، يمكنك استدعاء هذه النماذج الثلاثة عبر واجهة موحدة، مما يسهل التبديل السريع والمقارنة.
بدء سريع مع فحص المسائل الفيزيائية باستخدام النماذج اللغوية الكبيرة
مثال بسيط للغاية: تنفيذ تصحيح المسائل الفيزيائية بـ 10 أسطر برمجية
يعرض المثال التالي كيفية استخدام نموذج لغة كبير لإجراء التقييم التلقائي لمسألة فيزيائية حسابية:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "أنت خبير في فحص جودة المسائل الفيزيائية. قم بتقييم إجابة الطالب بناءً على الإجابة النموذجية، وأخرج النتيجة بتنسيق JSON: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【السؤال】 جسم كتلته 2 كجم يسقط سقوطاً حراً من ارتفاع 10 أمتار، أوجد سرعة وصوله للأرض (g=10 م/ث²)
【الإجابة النموذجية】 v=√(2gh)=√(2×10×10)=√200≈14.1 م/ث
【إجابة الطالب】 باستخدام حفظ الطاقة: mgh=½mv²، v=√(2gh)=√200=14.14 م/ث
"""}
]
)
print(response.choices[0].message.content)
عرض كود خط أنابيب الفحص الكامل (يتضمن التحقق المتقاطع متعدد النماذج)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
فحص جودة فيزيائي متعدد النماذج مع تحقق متقاطع
Args:
question: محتوى السؤال
standard_answer: الإجابة النموذجية
student_answer: إجابة الطالب
models: قائمة النماذج المستخدمة
tolerance: هامش التسامح العددي (الافتراضي 5%)
Returns:
قاموس يحتوي على تقييمات كل نموذج والاستنتاج النهائي
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""أنت مدرس فيزياء خبير ومراجع امتحانات. يرجى التقييم بدقة وفقاً للقواعد التالية:
1. قبول طرق الحل المكافئة للإجابة النموذجية (مثل طرق مختلفة: حفظ الطاقة، قوانين نيوتن، إلخ)
2. نطاق هامش التسامح للنتائج العددية: ±{tolerance*100}%
3. الأرقام المعنوية: قبول اختلاف ±1 رقم معنوي
4. يجب أن تكون الوحدات الفيزيائية صحيحة، نقص الوحدة يخصم 10%
أخرج النتيجة بتنسيق JSON صارم:
{{
"score": النتيجة,
"max_score": الدرجة الكاملة,
"is_correct": صحيح/خطأ,
"deductions": [{{"reason": "سبب الخصم", "points": قيمة الخصم}}],
"solution_method": "طريقة الحل التي استخدمها الطالب",
"comment": "تقييم شامل واقتراحات للتحسين"
}}"""
user_prompt = f"""【السؤال】{question}
【الإجابة النموذجية】{standard_answer}
【إجابة الطالب】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# التحقق المتقاطع: أخذ الاستنتاج الذي يتوافق عليه غالبية النماذج
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# مثال للاستخدام
result = physics_quality_check(
question="جسم كتلته 2 كجم يسقط سقوطاً حراً من ارتفاع 10 أمتار، أوجد سرعة وصوله للأرض (g=10 م/ث²)",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1 م/ث",
student_answer="mgh=½mv²، v=√(2×10×10)=14.14 م/ث"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
اقتراح: احصل على رصيد اختبار مجاني من خلال APIYI على apiyi.com، حيث يمكنك باستخدام مفتاح API واحد استدعاء النماذج الثلاثة: Gemini وClaude وGPT، دون الحاجة إلى التسجيل بشكل منفصل في منصات الشركات الثلاث.
ممارسات هندسة الموجهات لفحص جودة مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة
يعد تصميم الموجهات الجيد هو جوهر دقة الفحص. فيما يلي قوالب موجهات تم التحقق منها عمليًا واستراتيجيات التحسين:
قالب الموجه لفحص مسائل الفيزياء
وفقًا للدراسات الأكاديمية (عدة أوراق بحثية منشورة بين 2024-2026)، أظهرت استراتيجية الموجه Tree of Thought (شجرة التفكير) أفضل أداء في تصحيح مسائل الفيزياء الحسابية، بدقة ≥ 0.9، ومعامل كابا كوهين > 0.8. فيما يلي الهيكل الذي نوصي به:
| استراتيجية الموجه | نوع الأسئلة المناسبة | الدقة | النموذج الموصى به |
|---|---|---|---|
| Tree of Thought | مسائل حسابية واشتقاقية شاملة | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | أسئلة تحليل المفاهيم، أسئلة قصيرة | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | أسئلة الاختيار من متعدد، أسئلة الفراغات | 80-85% | GPT-5.4 (أقل تكلفة) |
| التصويت متعدد الجولات | جميع أنواع الأسئلة (للاحتياجات عالية الدقة) | 92-95% | مجموعة من ثلاثة نماذج |
تقنيات رئيسية لتحسين الموجهات
التقنية الأولى: تحديد قواعد قبول الحلول المكافئة بوضوح. قم بإدراج جميع طرق الحل المقبولة للسؤال في الموجه النظامي. على سبيل المثال، في مسائل الميكانيكا، يجب أن تنص على: «تقبل طرق الحل المكافئة مثل قانون حفظ الطاقة، وقوانين نيوتن للحركة، ونظرية الدفع». هذه القاعدة وحدها يمكنها خفض نسبة الخطأ في الحكم من 30% إلى أقل من 5%.
التقنية الثانية: تعيين هامش تسامح عددي بدلاً من المطابقة التامة. في الحسابات الفيزيائية، قد يؤدي التقريب في الخطوات الوسيطة إلى اختلافات طفيفة في النتيجة النهائية. نوصي بتعيين هامش تسامح ±5%، مع التأكيد على ضرورة صحة الوحدات الفيزيائية.
التقنية الثالثة: مطالبة النموذج بحل المسألة أولاً ثم التصحيح. اطلب من النموذج حل المسألة بشكل مستقل أولاً، ثم يقارن إجابته بإجابة الطالب. هذه الطريقة تزيد الدقة بنسبة 15-20% مقارنة بطلب التصحيح مباشرة مقابل «الإجابة النموذجية». كلا الوضعين thinking_level: HIGH في Gemini 3.1 Pro و Extended Thinking في Claude Sonnet 4.6 مناسبان لهذا الاستخدام.
التقنية الرابعة: تشغيل متعدد واعتماد القيمة الأكثر تكرارًا. قم بتشغيل عملية التصحيح لنفس السؤال من 3 إلى 5 مرات واعتمد النتيجة الأكثر شيوعًا. يمكن استخدام الانحراف المعياري كمؤشر للثقة. يُنصح بالمراجعة اليدوية عندما يكون الانحراف المعياري > 1 درجة.
🎯 نصيحة عملية: عند بناء نظام الفحص لأول مرة، نوصي باستخدام مجموعة من 50-100 سؤال فيزياء تم تصحيحها يدويًا كمجموعة اختبار. اختبر دقة ثلاثة نماذج مختلفة على منصة APIYI (apiyi.com) للعثور على المزيج الأنسب لخصائص بنك الأسئلة الخاص بك.

حلول مخصصة لفحص جودة المسائل الفيزيائية بواسطة النماذج اللغوية الكبيرة
تتطلب أنواع المسائل الفيزيائية المختلفة استراتيجيات مختلفة لفحص الجودة. فيما يلي التكوينات الموصى بها لأربعة سيناريوهات نموذجية:
السيناريو الأول: فحص جودة دفعات الواجبات اليومية
مناسب للواجبات اليومية في الفيزياء للمرحلة الثانوية/الجامعية، حيث يكون حجم الأسئلة كبيرًا (100+ سؤال/يوم) ومستوى الصعوبة متوسطًا.
- النموذج الموصى به: Gemini 3.1 Pro Preview (مع
thinking_level: MEDIUM) - استراتيجية الموجه: Few-Shot + نموذج تقييم قياسي
- ميزة التكلفة: فحص 1000 سؤال يستهلك حوالي 2 مليون رمز (Token)، وتكلفة Gemini 3.1 Pro أقل بكثير من النماذج الأخرى
- معدل الدقة: 85-90% (بنموذج واحد)، ويمكن أن يصل إلى 95%+ مع أخذ عينات يدوية للتدقيق
السيناريو الثاني: التقييم الدقيق لامتحانات نهاية الفصل
مناسب لتصحيح أوراق الامتحانات الرسمية، ويتطلب معايير تقييم مفصلة وأسبابًا للخصم.
- النموذج الموصى به: Claude Sonnet 4.6 (وضع التفكير الممتد – Extended Thinking)
- استراتيجية الموجه: Tree of Thought + قواعد تقييم مفصلة
- الميزة الأساسية: تقرير فحص الجودة الناتج يكون هيكله واضحًا ويمكن أرشفته مباشرةً كسجل للتصحيح
- معدل الدقة: 88-92% (بنموذج واحد)
السيناريو الثالث: فحص جودة مسائل المسابقات الفيزيائية
مناسب للتدريب على مسابقات الفيزياء للمرحلة الثانوية، حيث تكون الأسئلة شاملة ومعقدة ومستوى صعوبتها عالٍ.
- النموذج الموصى به: GPT-5.4 Thinking (وضع التخطيط المسبق – Upfront Planning)
- استراتيجية الموجه: Tree of Thought + حل المسألة أولاً ثم التقييم
- الميزة الأساسية: مستوى إتقان (AIME) كامل، قادر على معالجة الاستنتاجات متعددة الخطوات والعمليات الرياضية المتقدمة
- معدل الدقة: 80-85% (أداء النموذج الواحد تحت مستوى صعوبة المسابقة)
السيناريو الرابع: التحقق المتقاطع متعدد النماذج (لأعلى دقة)
مناسب للامتحانات عالية الأهمية (مثل امتحانات القبول)، والتي تتطلب أعلى معدل دقة.
- الحل الموصى به: 3 نماذج تقوم بالتقييم بشكل مستقل → أخذ إجماع الأغلبية (2/3) → مراجعة يدوية للأسئلة المختلف عليها
- تكلفة التنفيذ: تكلفة السؤال الواحد حوالي 3 أضعاف تكلفة النموذج الواحد، ولكن معدل الدقة يرتفع إلى 95%+
- حجم الملاءمة: مناسب للحالات ذات حجم أسئلة صغير (<500 سؤال) ولكن بمتطلبات جودة عالية للغاية
| السيناريو | النموذج الموصى به | استراتيجية الموجه | معدل الدقة | التكلفة (لكل ألف سؤال) |
|---|---|---|---|---|
| الواجبات اليومية | Gemini 3.1 Pro | Few-Shot | 85-90% | منخفضة |
| امتحانات نهاية الفصل | Claude Sonnet 4.6 | Tree of Thought | 88-92% | متوسطة |
| مسائل المسابقات | GPT-5.4 Thinking | ToT + حل أولاً | 80-85% | مرتفعة نسبيًا |
| التحقق المتقاطع | مجموعة من ثلاثة نماذج | تصويت متعدد الجولات | 95%+ | مرتفعة (3×) |
🎯 نصيحة لتبديل النماذج: تختلف متطلبات النماذج بشكل كبير بين السيناريوهات المختلفة. تدعم APIYI (apiyi.com) تبديل النماذج من خلال تعديل معلمة
modelواحدة فقط، مما يسهل اختيار النموذج الأمثل ديناميكيًا بناءً على نوع الأسئلة.
الأسئلة الشائعة
س1: هل يمكن لفحص جودة المسائل الفيزيائية بواسطة النماذج اللغوية الكبيرة أن يحل محل التصحيح اليدوي بالكامل؟
لا يمكن الاستغناء عنه بالكامل حتى الآن. تظهر الأبحاث الأكاديمية أن النماذج اللغوية الكبيرة يمكن أن تصل دقتها إلى 90%+ عند معالجة المسائل الحسابية الموحدة، ولكن دقتها على المسائل غير المحددة جيدًا (under-specified problems) تبلغ 8.3% فقط. الحل الموصى به: النماذج الكبيرة مسؤولة عن تصحيح 80% من الأسئلة القياسية، والبشر مسؤولون عن مراجعة 20% من الأسئلة المعقدة والمثيرة للجدل.
س2: ما مدى تعقيد دمج واجهات برمجة التطبيقات (APIs) للنماذج الثلاثة؟
النماذج الثلاثة تأتي من ثلاث منصات مختلفة: Google و Anthropic و OpenAI. إذا قمت بالتسجيل والربط مع كل منها على حدة، ستكون تكلفة التطوير عالية. يُوصى بالاستدعاء من خلال الواجهة الموحدة لـ APIYI (apiyi.com)، حيث تستخدم جميع النماذج نفس تنسيق حزمة تطوير البرمجيات (SDK) الخاص بـ OpenAI، وتحتاج فقط إلى تعديل معلمة model للتبديل بينها، مما يقلل بشكل كبير من تكلفة الدمج.
س3: كيف يمكن تقييم دقة نظام فحص الجودة؟
يُوصى باستخدام معامل كابا (Cohen's Kappa) لقياس مدى توافق تقييم النموذج مع التقييم البشري:
- إعداد 50-100 سؤال فيزيائي تم تصحيحها يدويًا كمجموعة اختبار
- استدعاء النماذج الثلاثة للتقييم عبر APIYI (apiyi.com)
- حساب قيمة كابا لكل نموذج مقارنة بالتصحيح البشري
- تشير قيمة كابا > 0.8 إلى توافق عالٍ، ويمكن عندها استخدام النظام
الخلاصة
النقاط الأساسية لفحص جودة مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة:
- Gemini 3.1 Pro Preview هو الخيار الأول: يتمتع بأقوى قدرة استدلالية في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM) وأفضل نسبة سعر/أداء، وهو مناسب للفحص اليومي بكميات كبيرة لمسائل الفيزياء.
- Claude Sonnet 4.6 مناسب لإعداد التقارير: نمط التفكير التكيفي + المخرجات المنظمة، مناسب للامتحانات الرسمية التي تتطلب معايير تقييم مفصلة.
- GPT-5.4 لمعالجة المسائل الصعبة في المسابقات: قدرة استدلالية بمستوى الدرجة الكاملة في اختبار AIME، وهو الأكثر موثوقية لمعالجة مسائل الفيزياء المعقدة عالية الصعوبة.
- التحقق المتقاطع متعدد النماذج يرفع الدقة إلى 95%+: أخذ إجماع من خلال تقييم مستقل من ثلاثة نماذج، هو الحل الأكثر موثوقية حاليًا لأتمتة فحص الجودة.
اختيار النموذج المناسب يعتمد على خصائص نوع المسألة ومتطلبات الدقة. نوصي بالاختبار والمقارنة السريعة عبر منصة APIYI على apiyi.com، حيث توفر المنصة رصيدًا مجانيًا وواجهة موحدة، حيث يمكنك باستخدام مفتاح API واحد استدعاء جميع النماذج الرئيسية.
📚 المراجع
-
MDPI العلوم التربوية – دراسة حول التقييم الذكي لمسائل الفيزياء باستخدام النماذج اللغوية الكبيرة: مقارنة أداء أربع استراتيجيات للموجهات في تقييم مسائل الفيزياء.
- الرابط:
mdpi.com/2227-7102/15/2/116 - الشرح: مصدر البيانات التجريبية التي تشير إلى أن دقة استراتيجية "شجرة الفكر" (Tree of Thought) ≥ 0.9.
- الرابط:
-
Physical Review – تقييم النماذج اللغوية الكبيرة على مسائل أولمبياد الفيزياء: تقييم منهجي للنماذج الاستدلالية وGPT على مسابقات الفيزياء.
- الرابط:
link.aps.org/doi/10.1103/6fmx-bsnl - الشرح: الحجة الرئيسية التي تشير إلى أن قدرة النماذج اللغوية الكبيرة على الاستدلال الفيزيائي قد تجاوزت متوسط المستوى البشري.
- الرابط:
-
Google DeepMind – المدونة التقنية لـ Gemini 3.1 Pro: تفاصيل بنية النموذج واختبارات المعايير في مجالات العلوم والتكنولوجيا والهندسة والرياضيات (STEM).
- الرابط:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - الشرح: المصدر الرسمي لبيانات تقييم الاستدلال الفيزيائي لـ Gemini 3.1 Pro.
- الرابط:
-
Anthropic – إعلان إصدار Claude Sonnet 4.6: تفاصيل تحسين نمط التفكير التكيفي والقدرات الرياضية.
- الرابط:
anthropic.com/news/claude-sonnet-4-6 - الشرح: التفاصيل التقنية للقفزة بنسبة 27% في القدرات الرياضية لـ Claude Sonnet 4.6.
- الرابط:
-
OpenAI – إعلان إصدار GPT-5.4: تحسينات "التخطيط المسبق" (Upfront Planning) وكفاءة الاستدلال.
- الرابط:
openai.com/index/introducing-gpt-5-4/ - الشرح: البيانات الرسمية حول تحقيق GPT-5.4 الدرجة الكاملة في اختبار AIME وتحسين كفاءة الرموز (Token).
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بمناقشة الخبرات العملية لفحص جودة مسائل الفيزياء باستخدام النماذج اللغوية الكبيرة في قسم التعليقات. يمكن زيارة مركز وثائق APIYI على docs.apiyi.com للمزيد من دروس استدعاء النماذج.