
Примечание автора: Подробное руководство по созданию конвейера проверки качества физических задач с использованием трёх больших языковых моделей — Gemini 3.1 Pro, Claude Sonnet 4.6 и GPT-5.4, включая полные шаблоны промптов и примеры кода.
Использование больших языковых моделей для проверки физических задач — это направление, которое всё больше привлекает внимание образовательных учреждений и онлайн-платформ для обучения. Традиционная ручная проверка не только неэффективна, но и подвержена субъективным различиям в оценках преподавателей. В этой статье мы расскажем, как использовать три самые мощные модели для рассуждений 2026 года — Gemini 3.1 Pro Preview, Claude Sonnet 4.6 и GPT-5.4 — для создания системы автоматической проверки физических задач с высокой точностью.
Ключевая ценность: Прочитав эту статью, вы освоите полный рабочий процесс проверки физических задач с помощью больших языковых моделей — от проектирования промптов до перекрёстной проверки несколькими моделями, и сможете создать автоматизированное решение для проверки с точностью свыше 90%.

Ключевые моменты контроля качества физических задач с помощью больших языковых моделей
Контроль качества физических задач принципиально отличается от проверки обычного текста — он требует от модели одновременно математических навыков вывода, понимания физических концепций и согласованности в оценке. Ниже приведено сравнение ключевых возможностей трёх рекомендуемых моделей:
| Ключевой момент | Объяснение | Практическая ценность |
|---|---|---|
| Gemini 3.1 Pro лидирует в логических рассуждениях | 95.1% на бенчмарке MATH, 77.1% на ARC-AGI-2, первое место в оценке физических рассуждений | Наивысшая точность при обработке расчётных задач по механике и электромагнетизму с выводами формул |
| Claude Sonnet 4.6 даёт чёткий ход решения | Поддерживает адаптивный режим мышления, математические способности выросли на 27 процентных пунктов до 89% | Способен выводить полное обоснование оценки и причины снятия баллов, подходит для генерации отчётов о контроле качества |
| GPT-5.4 выделяется на задачах олимпиадного уровня | Максимальный балл на AIME 2025, поддерживает контекстное окно в 1 млн токенов | Наиболее полные цепочки рассуждений при обработке олимпиадных и комплексных задач по физике |
| Кросс-валидация несколькими моделями | Три модели независимо выставляют оценки, затем определяется консенсус | Повышает точность с 85-90% у одной модели до 95%+ |
3 ключевых вызова при контроле качества физических задач с помощью больших языковых моделей
Вызов первый: определение эквивалентности вывода формул. Для одной и той же задачи по механике студент может решить её через закон сохранения энергии, а другой — через второй закон Ньютона. Процессы вывода в этих методах совершенно разные, но результат эквивалентен. Исследования показывают, что если явно не указать в промпте, что модель должна принимать эквивалентные методы решения, она будет жёстко следовать пути решения из стандартного ответа при выставлении оценки, что приводит к уровню ошибок до 30%. Это самая распространённая точка потери точности при контроле качества физических задач большими моделями.
Вызов второй: обработка допусков для физических единиц и значащих цифр. В физических расчётах результат, сохранённый с 2 или 3 значащими цифрами, различается, но обычно оба должны приниматься. Установка разумного диапазона числового допуска (например, ±5%) в промпте является ключевым условием для обеспечения точности контроля качества.
Вызов третий: понимание задач с графиками и экспериментами. Задачи, содержащие схемы электрических цепей, механические диаграммы, требуют от модели способности к мультимодальному пониманию. Gemini 3.1 Pro и GPT-5.4 показывают здесь лучшие результаты, в то время как Claude Sonnet 4.6 более стабилен в чисто текстовых и формульных рассуждениях.

Gemini 3.1 Pro Preview: лучший выбор для физических рассуждений
Gemini 3.1 Pro — это флагманская модель, выпущенная Google DeepMind в феврале 2026 года. В сценарии проверки качества физических задач у неё есть три ключевых преимущества:
- Наилучшие способности к STEM-рассуждениям: занимает первое место в оценке CritPt (исследовательские физические рассуждения), достигает 95.1% на бенчмарке MATH.
- Настраиваемая глубина мышления: добавлен параметр
thinking_level(поддерживает LOW/MEDIUM/HIGH). Для простых вопросов с выбором используйте LOW, чтобы снизить затраты, для комплексных расчётных задач — HIGH, чтобы обеспечить точность. - Высокая экономическая эффективность: стоимость составляет всего около 1/7.5 от стоимости Claude Opus 4.6, что подходит для задач массовой проверки.
Claude Sonnet 4.6: лучший для генерации отчётов о проверке
Claude Sonnet 4.6 был выпущен 17 февраля 2026 года. Его уникальное преимущество при проверке физических задач заключается в следующем:
- Адаптивный режим мышления: модель автоматически определяет глубину рассуждений в зависимости от сложности задачи — быстро оценивает простые задачи и глубоко анализирует сложные.
- Контекстное окно в 1 миллион токенов: позволяет за один раз передать все вопросы и правильные ответы для целого набора тестов, обеспечивая согласованность стандартов оценки.
- Сильная структурированность вывода: особенно хорошо генерирует отчёты о проверке в формализованном виде, включая оценку, пункты снятия баллов и рекомендации по улучшению.
GPT-5.4: инструмент для задач уровня олимпиад
GPT-5.4, выпущенный 5 марта 2026 года, является новейшей флагманской моделью OpenAI:
- Стопроцентный результат в олимпиадной математике: демонстрирует 100% точность в AIME 2025, выдающиеся способности в обработке сложных комплексных физических задач.
- Способность к предварительному планированию: версия GPT-5.4 Thinking поддерживает «Upfront Planning» — сначала показывает ход рассуждений, а затем выставляет оценку.
- Оптимальная эффективность токенов: по сравнению с GPT-5.2, потребление токенов для рассуждений значительно сокращено, что снижает долгосрочные затраты.
| Модель | Способность к физическим рассуждениям | Качество генерации отчёта | Поддержка мультимодальности | Стоимость за миллион токенов | Рекомендуемый сценарий |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Самая низкая | Массовая ежедневная проверка, задачи с графиками и диаграммами |
| Claude Sonnet 4.6 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Средняя ($3/$15) | Требуется подробный отчёт о проверке, оценка целого набора тестов |
| GPT-5.4 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Высокая | Олимпиадные задачи, комплексные задачи, проверка задач высокой сложности |
🎯 Рекомендация по выбору: для ежедневной проверки выбирайте Gemini 3.1 Pro (наиболее экономически эффективна), для подробных отчётов — Claude Sonnet 4.6, для сложных олимпиадных задач — GPT-5.4. Через платформу APIYI apiyi.com можно вызывать все три модели через единый интерфейс, что удобно для быстрого переключения и сравнения.
Быстрый старт: проверка физических задач с помощью больших языковых моделей
Минималистичный пример: оценка физической задачи в 10 строк кода
В следующем примере показано, как использовать большую языковую модель для автоматической оценки расчётной задачи по физике:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[
{"role": "system", "content": "Вы — эксперт по проверке физических задач. Оцените ответ ученика на основе правильного ответа. Выведите результат в формате JSON: {score, max_score, deductions: [{reason, points}], comment}"},
{"role": "user", "content": """
【Задача】Тело массой 2 кг свободно падает с высоты 10 м. Найдите скорость в момент удара о землю (g=10 м/с²).
【Правильный ответ】v=√(2gh)=√(2×10×10)=√200≈14.1 м/с
【Ответ ученика】Используем закон сохранения энергии: mgh=½mv², v=√(2gh)=√200=14.14 м/с
"""}
]
)
print(response.choices[0].message.content)
Посмотреть полный код конвейера проверки (с перекрёстной валидацией несколькими моделями)
import openai
import json
from typing import Optional
def physics_quality_check(
question: str,
standard_answer: str,
student_answer: str,
models: list = None,
tolerance: float = 0.05
) -> dict:
"""
Перекрёстная проверка физической задачи несколькими моделями.
Аргументы:
question: содержание задачи
standard_answer: правильный ответ
student_answer: ответ ученика
models: список используемых моделей
tolerance: числовой допуск (по умолчанию 5%)
Возвращает:
Словарь с оценками от каждой модели и итоговым заключением.
"""
if models is None:
models = ["gemini-3.1-pro-preview", "claude-sonnet-4-6", "gpt-5.4"]
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
system_prompt = f"""Вы — опытный учитель физики и эксперт по проверке работ. Оценивайте строго по следующим правилам:
1. Принимайте эквивалентные методы решения (например, закон сохранения энергии, законы Ньютона и другие подходы).
2. Допустимый диапазон числового результата: ±{tolerance*100}%
3. Значимые цифры: принимайте разницу в ±1 цифру.
4. Физические единицы измерения должны быть указаны верно, отсутствие единиц — штраф 10%.
Выводите строго в формате JSON:
{{
"score": полученные_баллы,
"max_score": максимальный_балл,
"is_correct": true/false,
"deductions": [{{"reason": "причина_снятия_баллов", "points": количество_баллов}}],
"solution_method": "метод_решения_ученика",
"comment": "общая_оценка_и_рекомендации_по_улучшению"
}}"""
user_prompt = f"""【Задача】{question}
【Правильный ответ】{standard_answer}
【Ответ ученика】{student_answer}"""
results = {}
for model in models:
try:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1
)
results[model] = json.loads(resp.choices[0].message.content)
except Exception as e:
results[model] = {"error": str(e)}
# Перекрёстная валидация: берём консенсус большинства моделей.
scores = [r["score"] for r in results.values() if "score" in r]
consensus = {
"model_results": results,
"avg_score": sum(scores) / len(scores) if scores else 0,
"consensus": all(r.get("is_correct") for r in results.values() if "is_correct" in r)
}
return consensus
# Пример использования
result = physics_quality_check(
question="Тело массой 2 кг свободно падает с высоты 10 м. Найдите скорость в момент удара о землю (g=10 м/с²).",
standard_answer="v=√(2gh)=√(2×10×10)=√200≈14.1 м/с",
student_answer="mgh=½mv², v=√(2×10×10)=14.14 м/с"
)
print(json.dumps(result, ensure_ascii=False, indent=2))
Совет: Получите бесплатные тестовые кредиты через APIYI apiyi.com. Один API-ключ позволяет вызывать три модели — Gemini, Claude и GPT — без необходимости регистрировать отдельные аккаунты на трёх разных платформах.
Практика Prompt Engineering для проверки физических задач с помощью больших языковых моделей
Качественный дизайн промптов — это основа высокой точности проверки. Ниже представлены проверенные на практике шаблоны промптов и стратегии оптимизации.
Шаблон промпта для проверки физических задач
Согласно академическим исследованиям (несколько опубликованных работ 2024-2026 гг.), стратегия подсказок Tree of Thought (Дерево мыслей) демонстрирует наилучшие результаты при оценке физических расчётных задач, с точностью ≥ 0.9 и коэффициентом Каппа Коэна > 0.8. Вот рекомендуемая нами структура промпта:
| Стратегия промпта | Подходящие типы задач | Точность | Рекомендуемая модель |
|---|---|---|---|
| Tree of Thought | Комплексные расчётные задачи, задачи на вывод | ≥ 90% | Gemini 3.1 Pro |
| Chain of Thought | Концептуальные задачи на анализ, краткие ответы | 85-90% | Claude Sonnet 4.6 |
| Few-Shot | Задачи с выбором ответа, на заполнение пропусков | 80-85% | GPT-5.4 (ниже стоимость) |
| Многократное голосование | Все типы задач (высокие требования) | 92-95% | Комбинация трёх моделей |
Ключевые приёмы оптимизации промптов
Приём 1: Чётко определите правила принятия эквивалентных решений. В системном промпте перечислите все допустимые методы решения для данной задачи. Например, для задачи по механике укажите: «Принимаются эквивалентные методы: закон сохранения энергии, законы Ньютона, теорема об импульсе и т.д.». Это правило позволяет снизить частоту ошибочных оценок с 30% до менее 5%.
Приём 2: Установите допустимую погрешность вместо точного совпадения. В физических расчётах округление промежуточных результатов может привести к незначительным различиям в итоговом ответе. Рекомендуется устанавливать допуск ±5%, при этом физические единицы измерения должны быть указаны верно.
Приём 3: Требуйте от модели сначала решить задачу, а затем оценить ответ. Попросите модель сначала самостоятельно найти решение, а затем сравнить его с ответом ученика. Такой подход повышает точность на 15-20% по сравнению с прямым указанием модели «оценить по эталонному ответу». Для этого хорошо подходят режим thinking_level: HIGH у Gemini 3.1 Pro и функция Extended Thinking у Claude Sonnet 4.6.
Приём 4: Многократный запуск и выбор наиболее частого результата. Запустите оценку одной и той же задачи 3-5 раз и выберите наиболее часто встречающийся результат. Стандартное отклонение может служить индикатором уверенности. Если стандартное отклонение > 1 балла, рекомендуется ручная проверка.
🎯 Практический совет: При первоначальной настройке системы проверки рекомендуется использовать набор из 50-100 уже проверенных вручную физических задач в качестве тестового набора. Протестируйте точность трёх моделей на платформе APIYI (apiyi.com), чтобы найти оптимальную комбинацию моделей для вашей конкретной базы задач.
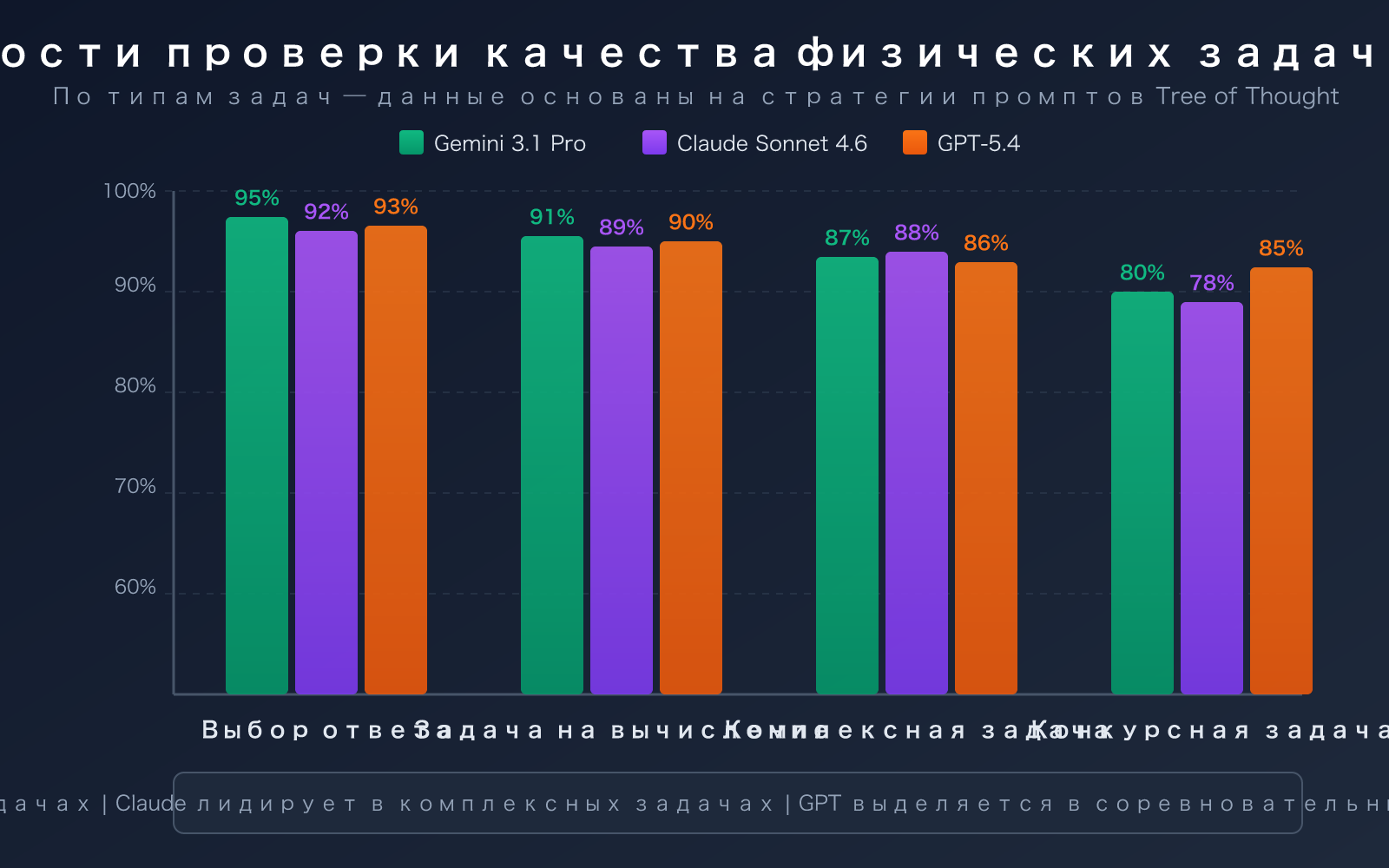
Сценарные решения для проверки физических задач с помощью больших языковых моделей
Разные типы физических задач требуют разных стратегий проверки. Ниже приведены рекомендуемые настройки для 4 типичных сценариев:
Сценарий 1: Пакетная проверка домашних заданий
Подходит для ежедневных домашних заданий по физике в старшей школе/вузе, с большим объёмом задач (100+ в день) и средней сложностью.
- Рекомендуемая модель: Gemini 3.1 Pro Preview (
thinking_level: MEDIUM) - Стратегия промптов: Few-Shot + стандартная оценочная таблица
- Преимущество по стоимости: Проверка ~1000 задач потребует около 2 млн токенов, стоимость Gemini 3.1 Pro значительно ниже других моделей
- Точность: 85-90% (одна модель), в сочетании с выборочной ручной проверкой — до 95%+
Сценарий 2: Детальная оценка итоговых экзаменов
Подходит для проверки официальных экзаменов, где требуются подробные обоснования оценки и причины снятия баллов.
- Рекомендуемая модель: Claude Sonnet 4.6 (режим Extended Thinking)
- Стратегия промптов: Tree of Thought + детальные критерии оценки
- Ключевое преимущество: Отчёт о проверке имеет чёткую структуру и может быть напрямую использован как архивная запись проверки
- Точность: 88-92% (одна модель)
Сценарий 3: Проверка задач для физических олимпиад
Подходит для подготовки к олимпиадам по физике, где задачи комплексные и высокой сложности.
- Рекомендуемая модель: GPT-5.4 Thinking (режим Upfront Planning)
- Стратегия промптов: Tree of Thought + сначала решение, затем оценка
- Ключевое преимущество: Уровень AIME на максимальный балл, способна обрабатывать многошаговые выводы и сложные математические операции
- Точность: 80-85% (результат одной модели для задач олимпиадного уровня)
Сценарий 4: Перекрёстная проверка несколькими моделями (максимальная точность)
Подходит для высокоответственных экзаменов (например, вступительных), где требуется максимальная точность.
- Рекомендуемое решение: 3 модели оценивают независимо → берётся консенсус 2/3 → спорные задачи проверяются вручную
- Стоимость реализации: Стоимость проверки одной задачи примерно в 3 раза выше, чем для одной модели, но точность повышается до 95%+
- Масштаб применения: Подходит для небольших объёмов задач (< 500), но с крайне высокими требованиями к качеству
| Сценарий | Рекомендуемая модель | Стратегия промптов | Точность | Стоимость (1000 задач) |
|---|---|---|---|---|
| Домашние задания | Gemini 3.1 Pro | Few-Shot | 85-90% | Низкая |
| Итоговые экзамены | Claude Sonnet 4.6 | Tree of Thought | 88-92% | Средняя |
| Олимпиадные задачи | GPT-5.4 Thinking | ToT + сначала решение | 80-85% | Выше средней |
| Перекрёстная проверка | Комбинация из 3 моделей | Многораундовое голосование | 95%+ | Высокая (×3) |
🎯 Рекомендация по смене модели: Требования к модели сильно различаются в зависимости от сценария. APIYI apiyi.com позволяет переключаться между моделями, просто изменяя параметр
model, что удобно для динамического выбора оптимальной модели под тип задачи.
Часто задаваемые вопросы
Вопрос 1: Может ли проверка физических задач с помощью больших языковых моделей полностью заменить ручную проверку?
На данный момент — ещё нет. Академические исследования показывают, что точность больших моделей при проверке стандартизированных расчётных задач может достигать 90%+, но для плохо определённых задач (under-specified problems) точность составляет лишь 8.3%. Рекомендуемое решение: большая модель отвечает за проверку 80% стандартных задач, а человек — за проверку 20% сложных и спорных задач.
Вопрос 2: Насколько сложно подключить API этих трёх моделей?
Три модели принадлежат трём разным платформам: Google, Anthropic и OpenAI. Если регистрироваться и подключаться к каждой отдельно, затраты на разработку будут высокими. Рекомендуется использовать единый интерфейс APIYI apiyi.com для вызова всех моделей. Все модели используют одинаковый формат OpenAI SDK, для переключения достаточно изменить параметр model, что значительно снижает затраты на интеграцию.
Вопрос 3: Как оценить точность системы проверки?
Рекомендуется использовать коэффициент Каппа Коэна для измерения согласованности оценок модели и человека:
- Подготовьте набор из 50-100 физических задач, уже проверенных вручную, в качестве тестового набора.
- Через APIYI apiyi.com вызовите три модели для оценки.
- Рассчитайте значение Каппа для каждой модели в сравнении с ручной проверкой.
- Kappa > 0.8 означает высокую согласованность, и систему можно вводить в эксплуатацию.
Итоги
Ключевые моменты проверки качества физических задач с помощью больших языковых моделей:
- Лучший выбор — Gemini 3.1 Pro Preview: Наиболее сильные способности к STEM-рассуждениям и лучшая стоимость, подходит для массовой ежедневной проверки физических задач.
- Claude Sonnet 4.6 подходит для составления отчетов: Адаптивный режим мышления + структурированный вывод, идеален для официальных экзаменов, требующих подробного обоснования оценок.
- GPT-5.4 для олимпиадных задач: Уровень рассуждений, соответствующий высшему баллу AIME, наиболее надежен для обработки сложных комплексных физических задач.
- Перекрестная проверка несколькими моделями повышает точность до 95%+: Независимая оценка тремя моделями с последующим определением консенсуса — на данный момент самая надежная схема автоматизированной проверки качества.
Выбор модели зависит от типа ваших задач и требований к точности. Рекомендуем быстро протестировать и сравнить через APIYI apiyi.com — платформа предоставляет бесплатные квоты и унифицированный интерфейс, один API-ключ дает доступ ко всем основным моделям.
📚 Ссылки и материалы
-
MDPI Education Sciences — Исследование интеллектуальной оценки физических задач на основе больших языковых моделей: Сравнение эффективности четырех стратегий промптов при оценке физических задач.
- Ссылка:
mdpi.com/2227-7102/15/2/116 - Описание: Источник экспериментальных данных, показывающих точность ≥ 0.9 для стратегии Tree of Thought.
- Ссылка:
-
Physical Review — Оценка LLM на задачах физических олимпиад: Систематическая оценка GPT и моделей рассуждений на задачах физических олимпиад.
- Ссылка:
link.aps.org/doi/10.1103/6fmx-bsnl - Описание: Ключевой аргумент о том, что способности больших моделей к физическим рассуждениям уже превзошли средний человеческий уровень.
- Ссылка:
-
Google DeepMind — Технический блог о Gemini 3.1 Pro: Подробности об архитектуре модели и тестах на STEM-бенчмарках.
- Ссылка:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Описание: Официальный источник данных об оценке физических рассуждений Gemini 3.1 Pro.
- Ссылка:
-
Anthropic — Анонс Claude Sonnet 4.6: Подробности об адаптивном режиме мышления и улучшении математических способностей.
- Ссылка:
anthropic.com/news/claude-sonnet-4-6 - Описание: Технические детали о скачке математических способностей Claude Sonnet 4.6 на 27%.
- Ссылка:
-
OpenAI — Анонс GPT-5.4: Upfront Planning и улучшение эффективности рассуждений.
- Ссылка:
openai.com/index/introducing-gpt-5-4/ - Описание: Официальные данные о высшем балле AIME и оптимизации эффективности токенов в GPT-5.4.
- Ссылка:
Автор: Техническая команда APIYI
Технические обсуждения: Делитесь практическим опытом проверки физических задач с помощью больших моделей в комментариях. Больше руководств по вызову моделей можно найти в документации APIYI docs.apiyi.com.