
Примечание автора: Подробный анализ причин ограничения скорости 429 при генерации изображений Gemini 3.1 Flash Image Preview, сравнение политик ограничения в AI Studio, Vertex AI и сторонних платформах, а также 4 проверенных на практике решения.
При использовании Gemini 3.1 Flash Image Preview для генерации изображений самая большая проблема — не качество, а то, что процесс прерывается ошибкой 429 (ограничение скорости). И в AI Studio, и в Vertex AI ограничения на RPD (запросов в день) и RPM (запросов в минуту) очень строгие, что делает пакетную генерацию практически невозможной.
Эта статья основана на практическом опыте и подробно разбирает коренные причины ошибки 429, сравнивает различия в политиках ограничения на разных платформах и предлагает 4 проверенных решения — включая вариант без ограничений на параллелизм и стоимостью всего $0.045 за изображение.
Ключевая ценность: Прочитав эту статью, вы полностью поймёте логику ошибки 429 при генерации изображений Gemini и найдёте оптимальное решение для вашего сценария.

Что такое ошибка 429 в Gemini 3.1 Flash Image Preview
Для начала посмотрим, как выглядит эта ошибка:
{
"error": {
"code": 429,
"message": "Resource has been exhausted (e.g. check quota).",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"reason": "RATE_LIMIT_EXCEEDED",
"metadata": {
"quota_limit": "GenerateContentRequestsPerDayPerProjectPerModel",
"quota_limit_value": "1500"
}
}
]
}
}
Простыми словами: Вы исчерпали лимит запросов на сегодня или отправляете запросы слишком часто.
В отличие от ошибки 503, 429 — это не проблема с сервером, а установленный Google лимит для вашего проекта. Независимо от доступных вычислительных мощностей сервера, при достижении лимита запросы просто отклоняются.
Разница между ошибками 429 и 503 при генерации изображений Gemini
| Параметр сравнения | 429 RESOURCE_EXHAUSTED | 503 UNAVAILABLE |
|---|---|---|
| Основная причина | Исчерпан ваш лимит | Недостаточно вычислительных мощностей на сервере |
| Условие срабатывания | Превышение лимитов RPD/RPM/TPM | Высокая общая нагрузка |
| Область влияния | Только ваш проект | Все пользователи |
| Можно ли решить ожиданием | RPM — подождать минуту, RPD — до следующего дня | Обычно от нескольких минут до нескольких часов |
| Можно ли решить оплатой | В Vertex AI можно увеличить квоту | Не решается напрямую |
| Кардинальное решение | Сменить платформу/увеличить квоту | Ждать или сменить платформу |
Сравнение стратегий ограничения скорости для Gemini 3.1 Flash Image Preview на разных платформах
Вот в чём суть проблемы — ограничения скорости на разных платформах отличаются кардинально.
Параметры ограничений для генерации изображений в AI Studio
AI Studio — это первый выбор для большинства разработчиков, бесплатно и удобно. Но ограничения на генерацию изображений крайне строгие:
| Параметр ограничения | Значение | Перевод |
|---|---|---|
| RPM (запросов в минуту) | 10 | 1 запрос каждые 6 секунд |
| RPD (запросов в день) | 1,500 | Лимит исчерпывается примерно за 2.5 часа |
| TPM (токенов в минуту) | 4,000,000 | Обычно не является узким местом |
| TPM для вывода изображений | 12,000 токенов/мин | ~10 изображений в минуту |
Практический опыт: Если вам нужно сгенерировать 500 изображений пакетно, при RPM=10 теоретически потребуется минимум 50 минут. Но с учётом сетевых задержек, повторных попыток и т.д., на практике уходит 1-2 часа. Если в день нужно сгенерировать больше 1500 изображений, вы упрётесь в жёсткий лимит RPD.
Параметры ограничений для генерации изображений в Vertex AI
Vertex AI — это корпоративное решение от Google Cloud, с более высокими квотами, но тоже с ограничениями:
| Параметр ограничения | Значение по умолчанию | Можно увеличить |
|---|---|---|
| RPM | 60 | Да, требуется одобрение |
| RPD | Нет фиксированного лимита | Но ограничено RPM и TPM |
| TPM | 4,000,000 | Можно запросить |
| TPM для вывода изображений | 24,000 токенов/мин | Можно запросить |
Практический опыт: RPM увеличивается с 10 до 60, что выглядит намного лучше, но для увеличения нужно пройти процесс подачи заявки в Google Cloud, что обычно занимает 1-3 рабочих дня. К тому же, настройка Vertex AI гораздо сложнее, чем AI Studio (нужно создать проект GCP, настроить сервисный аккаунт, права IAM и т.д.), из-за чего многие индивидуальные разработчики и небольшие команды просто отказываются от этой идеи.
Сравнение ограничений для генерации изображений на сторонних платформах
| Платформа | Ограничение на параллелизм | Ограничение RPD | Цена за изображение (1K) | Примечание |
|---|---|---|---|---|
| AI Studio | RPM=10 | 1,500/день | Бесплатно (с лимитом) | Самые строгие |
| Vertex AI | RPM=60 | Нет фиксированного лимита | ~$0.067 | Требуется настройка GCP |
| OpenRouter | Зависит от тарифа | Зависит от тарифа | ~$0.06-0.08 | Универсальная платформа |
| 稳妥API | Без ограничений | Без ограничений | $0.045 | Оплата за запрос, без ограничений по разрешению |
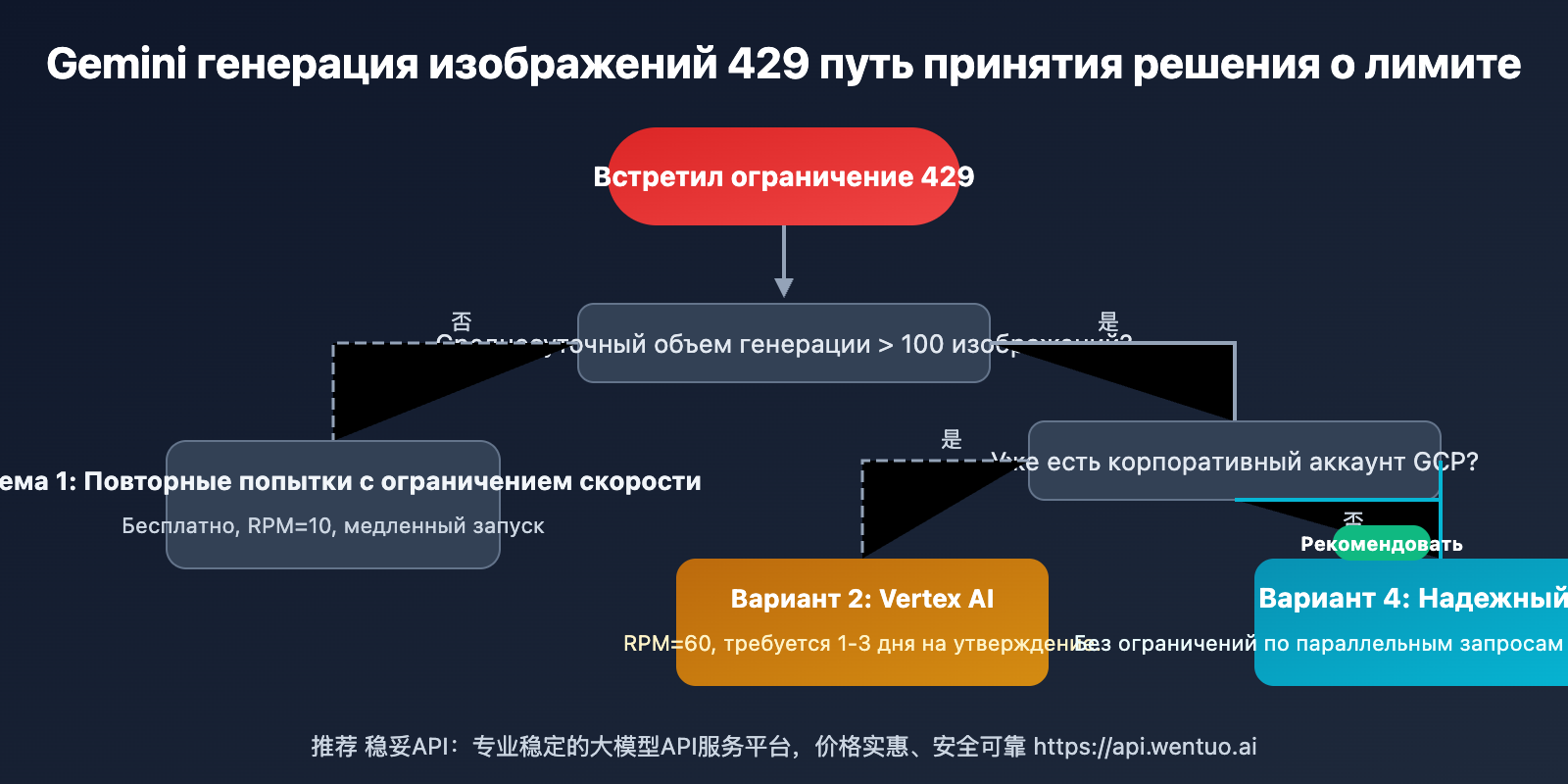
4 способа решения проблемы ограничения скорости 429 для Gemini 3.1 Flash Image Preview
Способ 1: Ограничение скорости запросов + автоматические повторные попытки
Самый базовый способ, не требует смены платформы, но неэффективен.
import time
import random
import requests
def generate_with_retry(prompt, max_retries=5):
"""Запрос на генерацию изображения с повторными попытками и экспоненциальной задержкой"""
for attempt in range(max_retries):
try:
response = requests.post(endpoint, json=payload, headers=headers, timeout=120)
if response.status_code == 200:
return response.json()
elif response.status_code == 429:
# Экспоненциальная задержка + случайное дрожание
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Ограничение скорости 429, ждём {wait_time:.1f}s перед повторной попыткой ({attempt+1}/{max_retries})")
time.sleep(wait_time)
else:
response.raise_for_status()
except Exception as e:
print(f"Ошибка запроса: {e}")
time.sleep(2)
raise Exception("Превышено максимальное количество попыток")
Посмотреть полный скрипт для пакетной генерации (с контролем скорости)
import time
import random
import requests
import base64
from pathlib import Path
from concurrent.futures import ThreadPoolExecutor
class RateLimitedGenerator:
"""Генератор для пакетной обработки, соблюдающий ограничение AI Studio RPM=10"""
def __init__(self, api_key, rpm_limit=10):
self.api_key = api_key
self.interval = 60.0 / rpm_limit # Минимальный интервал между запросами
self.last_request_time = 0
self.endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
def _wait_for_rate_limit(self):
elapsed = time.time() - self.last_request_time
if elapsed < self.interval:
time.sleep(self.interval - elapsed)
self.last_request_time = time.time()
def generate(self, prompt, output_path, retries=3):
for attempt in range(retries):
self._wait_for_rate_limit()
try:
response = requests.post(
f"{self.endpoint}?key={self.api_key}",
json={
"contents": [{"parts": [{"text": prompt}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "1K"}
}
},
timeout=120
)
if response.status_code == 200:
data = response.json()
img = data["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
Path(output_path).write_bytes(base64.b64decode(img))
return True
elif response.status_code == 429:
wait = (2 ** attempt) + random.uniform(0, 2)
print(f"[429] Ждём {wait:.1f}s ...")
time.sleep(wait)
except Exception as e:
print(f"Ошибка: {e}")
time.sleep(2)
return False
# Пример использования
gen = RateLimitedGenerator("YOUR_AISTUDIO_KEY", rpm_limit=10)
prompts = ["a sunset over mountains", "a cat in space", "futuristic city"]
for i, p in enumerate(prompts):
success = gen.generate(p, f"output_{i}.png")
print(f"{'✅' if success else '❌'} {p}")
Плюсы: Нулевая стоимость, подходит для небольшого количества запросов.
Минусы: Низкая скорость, нельзя обойти жёсткий лимит RPD=1,500.
Способ 2: Переход на Vertex AI для увеличения квоты
Подходит для корпоративных пользователей с аккаунтом Google Cloud.
Шаги:
- Создайте проект GCP и включите Vertex AI API.
- Настройте сервисный аккаунт и права IAM.
- В Google Cloud Console → IAM → Quotas запросите увеличение RPM.
- Переключите конечную точку в коде с AI Studio на Vertex AI.
Плюсы: RPM увеличивается с 10 до 60+, подходит для корпоративных сценариев.
Минусы: Сложная настройка, процесс согласования занимает 1-3 дня, тарификация по стандартным тарифам Google Cloud.
Способ 3: Ротация по нескольким проектам
Создание нескольких проектов GCP или API-ключей AI Studio для циклического переключения между ними и обхода ограничений RPD/RPM одного проекта.
import itertools
api_keys = ["KEY_1", "KEY_2", "KEY_3", "KEY_4", "KEY_5"]
key_pool = itertools.cycle(api_keys)
def generate_with_rotation(prompt):
"""Генерация изображения с ротацией ключей"""
key = next(key_pool)
# ... Отправляем запрос с текущим ключом
return send_request(prompt, api_key=key)
Плюсы: Теоретически N ключей дают N-кратную пропускную способность.
Минусы: Нарушает условия предоставления услуг Google (TOS), есть риск блокировки аккаунта; управление несколькими ключами увеличивает сложность.
Способ 4: Использование сторонней платформы без ограничений на параллелизм
Этот способ я выбрал в итоге. После сравнения нескольких сторонних платформ я остановился на 稳妥API wentuo.ai, и причина проста:
| Критерий сравнения | AI Studio | Vertex AI | 稳妥API |
|---|---|---|---|
| Ограничение параллелизма | RPM=10 | RPM=60 | Без ограничений |
| Дневной лимит | 1,500/день | Ограничено RPM | Без ограничений |
| Цена за изображение (включая 4K) | Бесплатно, но с лимитом | $0.067-$0.151 | $0.045 |
| Оплата по объёму (1K) | — | $0.067 | ~$0.025 |
| Сложность настройки | Просто | Сложно | Просто |
| Нужен ли VPN | Да | Да | Нет |
На практике, цена $0.045 за запрос включает 4K разрешение, а при оплате по токенам стоимость составляет примерно $0.02-$0.05 в зависимости от разрешения. Самое главное — нет ограничений на параллелизм, пакетные задачи можно выполнять на полной скорости, не упираясь в ошибку 429.
Вызов тоже прост — достаточно поменять конечную точку:
import requests
import base64
API_KEY = "your-wentuo-api-key"
ENDPOINT = "https://api.wentuo.ai/v1beta/models/gemini-3.1-flash-image-preview:generateContent"
headers = {
"Content-Type": "application/json",
"x-goog-api-key": API_KEY
}
payload = {
"contents": [{"parts": [{"text": "A cute cat wearing a space helmet"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"imageConfig": {"aspectRatio": "1:1", "imageSize": "2K"}
}
}
response = requests.post(ENDPOINT, headers=headers, json=payload, timeout=120)
result = response.json()
image_data = result["candidates"][0]["content"]["parts"][0]["inlineData"]["data"]
with open("output.png", "wb") as f:
f.write(base64.b64decode(image_data))
💡 Рекомендация: Если ваш ежедневный объём генерации превышает 500 изображений или вам важна скорость параллельной обработки, советую сразу использовать вариант без ограничений на параллелизм от 稳妥API wentuo.ai. Оплата за запрос $0.045/изображение (без ограничений по разрешению), оплата по объёму от $0.018/изображение (512px) — это на 33%-70% дешевле, чем официальные тарифы Google.
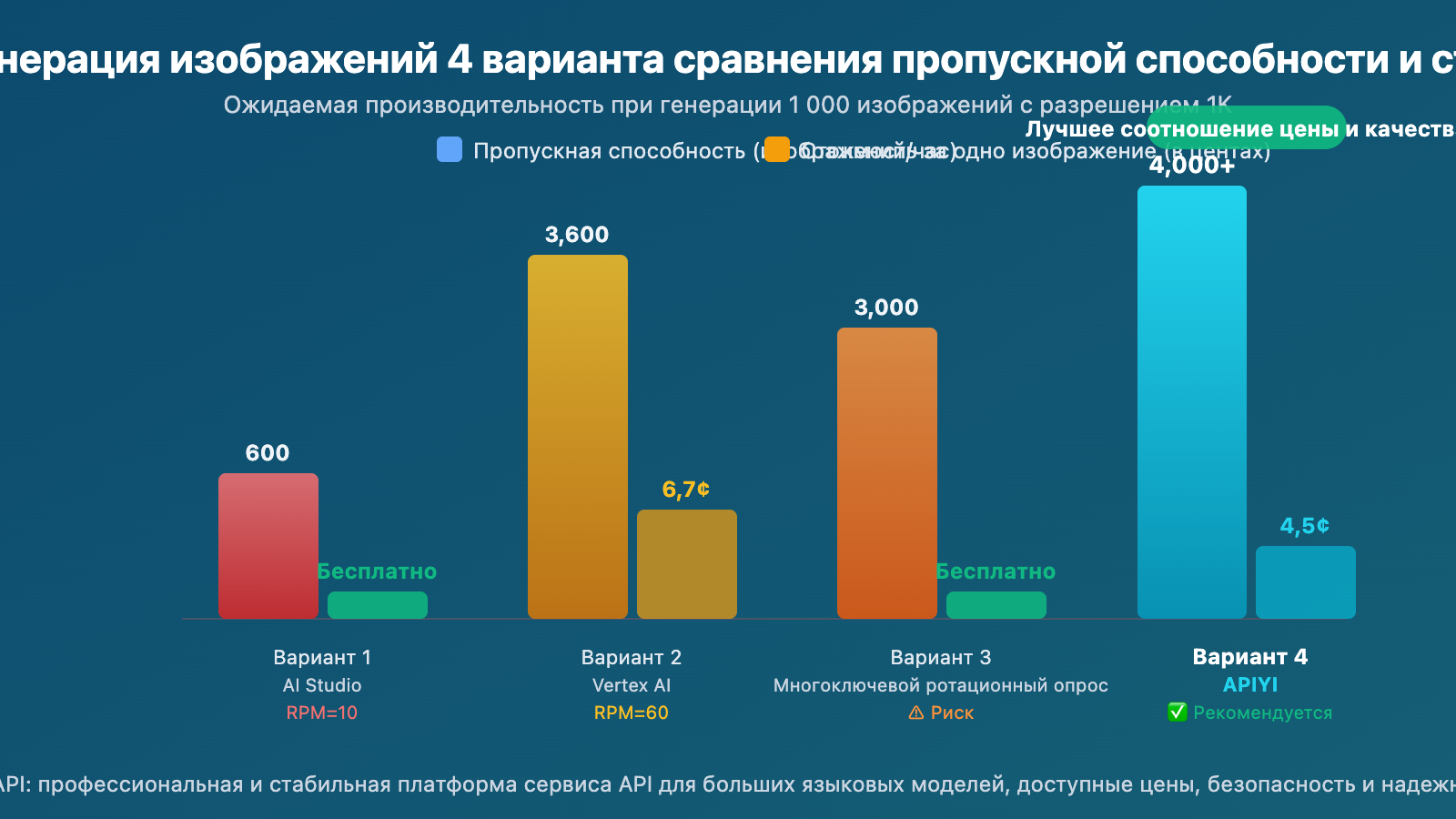
Рекомендации по выбору из 4 вариантов решения проблемы лимита 429 в Gemini 3.1 Flash Image Preview
Для разных сценариев подходят разные решения:
| Сценарий использования | Рекомендуемое решение | Причина |
|---|---|---|
| 🎨 Личное обучение/тестирование | Вариант 1 (Throttling & Retry) | Бесплатно, при малых объемах не критично |
| 🏢 В компании уже есть GCP | Вариант 2 (Vertex AI) | Соответствие требованиям, можно запросить высокие квоты |
| 🔬 Временное массовое тестирование | Вариант 3 (Множество ключей) | Краткосрочное решение, обратите внимание на риски |
| 🚀 Продакшен/пакетная генерация | Вариант 4 (Wentuo API) | Без ограничений на параллелизм, самая низкая стоимость |
Сравнение пропускной способности разных вариантов генерации изображений Gemini
Предположим, нужно сгенерировать 1,000 изображений в 1K разрешении:
| Вариант | Оценочное время | Общая стоимость | Практичность |
|---|---|---|---|
| AI Studio (RPM=10) | ~100 минут + ограничения RPD могут потребовать продолжения на следующий день | Бесплатно | ⚠️ Ограничения RPD |
| Vertex AI (RPM=60) | ~17 минут | ~$67 | ✅ Требуется GCP |
| Ротация множества ключей (5 ключей) | ~20 минут | Бесплатно | ⚠️ Риск блокировки аккаунта |
| Wentuo API (без ограничений на параллелизм) | ~10-15 минут | $45 (поштучно) / ~$25 (по объему) | ✅ Рекомендуется |
Часто задаваемые вопросы
Вопрос 1: Через какое время восстановится работа после ошибки 429 в Gemini 3.1 Flash Image Preview?
Зависит от того, какой именно лимит был превышен:
- Лимит RPM: Автоматическое восстановление через 1 минуту
- Лимит RPD: Нужно ждать сброса на следующий день (в 00:00 по UTC)
- Лимит TPM: Восстановление через 1 минуту
Рекомендуется в коде определять конкретный тип лимита по значению quota_limit в поле details и применять соответствующую стратегию.
Вопрос 2: Качество генерации изображений через Wentuo API такое же, как у официального Google?
Да, Wentuo API (wentuo.ai) напрямую использует официальную модель Google Gemini 3.1 Flash Image Preview, поэтому качество генерации полностью идентично. Отличия заключаются только в следующем:
- Убраны ограничения RPD/RPM
- Поддержка неограниченного параллелизма
- Более выгодная цена ($0.045/изображение против $0.067/изображение@1K у официального сервиса)
Вопрос 3: Как выбрать между поштучной и объемной оплатой?
Простая логика выбора:
- Постоянно используете разрешение 2K/4K → Выбирайте поштучную оплату ($0.045/раз, наиболее выгодно без ограничений по разрешению)
- В основном используете 512px/1K → Выбирайте объемную оплату (512px всего $0.018/раз, экономия 60% по сравнению с поштучной)
- Смешанные разрешения → Посчитайте среднюю стоимость, обычно объемная оплата выгоднее
Wentuo API (wentuo.ai) поддерживает гибкое переключение между двумя способами оплаты.
🎯 Итог
Проблема ограничения скорости 429 в Gemini 3.1 Flash Image Preview по сути связана со строгими квотами (RPD/RPM), установленными Google для AI Studio и Vertex AI. Ключевые моменты:
- Поймите тип ограничения: 429 — это ограничение по квоте (ваша проблема), 503 — это перегрузка сервера (проблема Google), решения совершенно разные.
- Оцените свой объем использования: AI Studio достаточно для менее 100 изображений в день, для более 500 изображений рекомендуется рассмотреть сторонние платформы.
- Выберите подходящее решение: Для производственной среды рекомендуется использовать решения без ограничения параллелизма, чтобы избежать влияния ограничений скорости на бизнес.
- Сравнение стоимости важно: APIYI предлагает $0.045 за изображение (включая 4K) при поштучной оплате и до $0.018 при оплате за объем, что на 33%-70% дешевле официальных тарифов.
Для разработчиков, которым требуется пакетная генерация изображений, APIYI wentuo.ai в настоящее время является лучшим выбором по совокупному опыту — без ограничений на параллелизм, более низкие цены, не требует VPN, интерфейс полностью совместим.
📚 Справочные материалы
-
Официальная документация Google Gemini API: Квоты и ограничения скорости для генерации изображений
- Ссылка:
ai.google.dev/gemini-api/docs/image-generation - Описание: Официальные параметры квот и лучшие практики
- Ссылка:
-
Управление квотами Google Cloud: Процесс запроса квот для Vertex AI
- Ссылка:
cloud.google.com/vertex-ai/docs/quotas - Описание: Официальный способ увеличения квот для корпоративных пользователей
- Ссылка:
-
Документация APIYI Nano Banana 2: Руководство по подключению генерации изображений без ограничения параллелизма
- Ссылка:
docs.wentuo.ai - Описание: Подробное описание и примеры кода для двух схем оплаты: поштучной и за объем
- Ссылка:
📝 Об авторе: Команда по созданию технического контента, специализирующаяся на генерации изображений ИИ и обмене знаниями об API. Больше технических материалов и ресурсов можно найти на APIYI wentuo.ai.
📋 Примечание: Содержание этой статьи основано на практическом опыте использования, конкретные параметры ограничения скорости могут меняться в соответствии с политикой Google. Для технической поддержки обращайтесь на APIYI wentuo.ai.