
2026年には、開発者の92%がAIプログラミングツールを利用しており、コードの41%がAIによって生成されています。しかし、ここで一つの厄介な現実があります。それは、「個人の作業時間は30〜60%短縮されたと報告されているにもかかわらず、組織全体の生産性向上はわずか10%程度に留まっている」という点です。このギャップはどこから生まれるのでしょうか?答えは「ワークフロー」にあります。
適切なモデルの組み合わせとワークフローを導入すれば、AIプログラミングは生産性を10倍に引き上げる武器となります。しかし、使い方を誤れば、それは「動いているように見えるが、いつ爆発してもおかしくない」コードを量産するだけのツールになってしまいます。
核心的な価値: 本記事を読み終える頃には、実証済みのマルチモデルAIプログラミングワークフローを習得できます。コストパフォーマンスに優れたモデル(GLM-5など)でコード生成を行い、トップクラスのモデル(Claude Sonnet 4.6など)でコードレビューを行う手法や、Claude Codeを活用した全工程の自動化方法を解説します。
AIプログラミングワークフローの根本的な変革
開発者の役割の変化:「コードを書く人」から「AIを指揮する人」へ
2026年のソフトウェア開発において、開発者の中心的な仕事は、コードを一行ずつ書くことではなく、以下のようになります。
- 仕様の策定 (Specification Engineering) — 要件、制約、アーキテクチャの好みを定義する
- モデル構成の選択 — フェーズごとに最適なモデルを使い分ける
- レビューと品質管理 — AIの出力がエンジニアリング基準を満たしているか確認する
- 最終責任の保持 — AIはあくまでツールであり、人間が責任を負う
Google Chromeチームの技術責任者であるAddy Osmani氏がまとめた核心原則は、**「まず計画を立て、次にコードを書く。計画の修正は安くつくが、コードの修正は高くつく」**というものです。
新しいワークフロー vs 従来のワークフロー
| 項目 | 従来のワークフロー | AI駆動ワークフロー |
|---|---|---|
| 中心的な活動 | コードを一行ずつ書く | 仕様の策定 + AI出力のレビュー |
| 開発者の役割 | コーダー (Coder) | オーケストレーター (Orchestrator) |
| コード生成 | 100% 人力 | 約40% AI生成 + 人力修正 |
| レビューの重点 | ロジックとスタイル | AI出力の品質 + アーキテクチャの一貫性 |
| ツールチェーン | IDE + Git | AIエージェント + IDE + Git + マルチモデル |
| ボトルネック | コーディング速度 | レビュー速度と判断力 |
重要なデータ:AIプログラミングの真の現状
| データ | 出典 |
|---|---|
| 92%の開発者がAIプログラミングツールを使用 | 2026年業界調査 |
| コードコミットの41%がAI支援によるもの | GitHubデータ |
| AIの提案がそのまま採用されるのはわずか30% | CodeRabbitレポート |
| AIの出力を信頼している開発者は29〜46%のみ | 複数調査の総合 |
| 組織の実際の生産性向上は約10% | 6つの独立した研究の合意 |
| AI生成コードの欠陥率は人間より1.7倍高い | 470件のPR分析 |
🎯 核心的な洞察: 生産性向上の鍵は、AIがどれだけコードを生成できるかではなく、効率的なレビューと検証の体制を構築できているかにあります。APIYI (apiyi.com) プラットフォームを活用すれば、複数のモデルを柔軟に組み合わせて、この体制を構築できます。
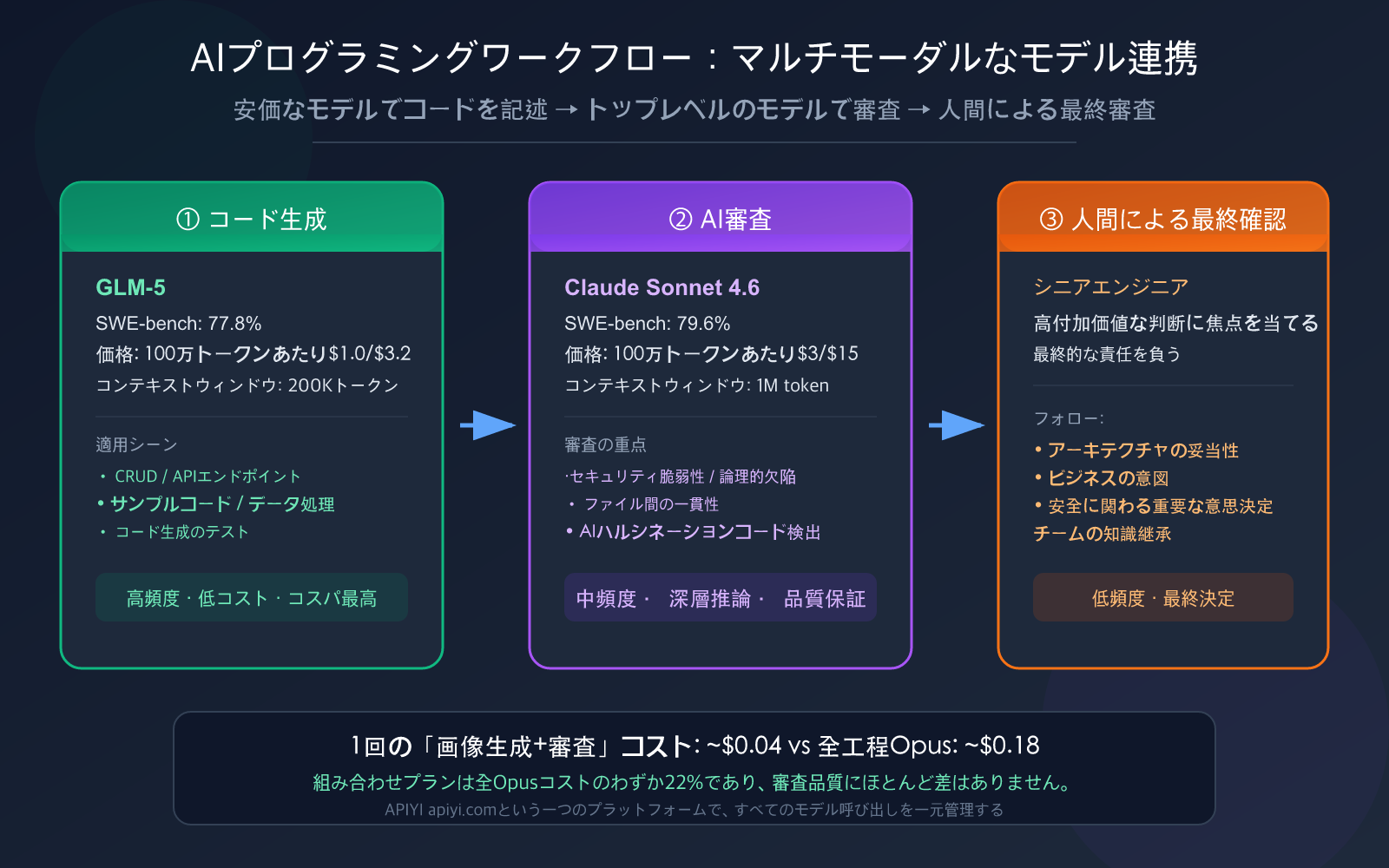
モデル選定戦略:安価なモデルで書き、最高性能のモデルでレビューする
これが本記事の核心的な手法論です。フェーズごとに異なるモデルを使い分けること。レースチームがF1マシンで荷物を運ばないように、あるいはトラックでレースに出ないように、適材適所が重要です。
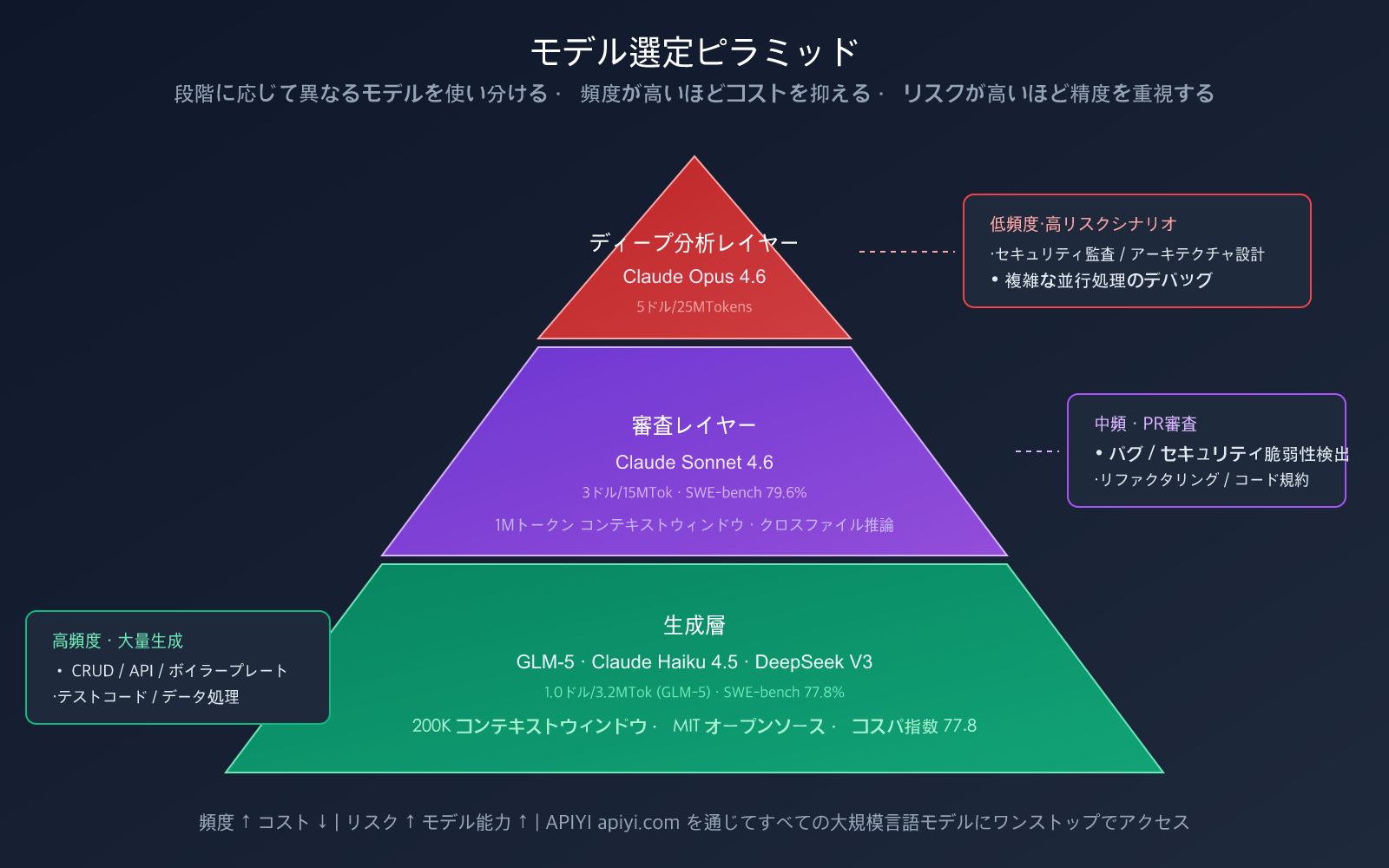
3層モデルピラミッド
| レイヤー | 用途 | 推奨モデル | 入力/出力価格 | 呼び出し頻度 |
|---|---|---|---|---|
| 生成層 | コード記述、CRUD、ボイラープレート | GLM-5, Claude Haiku 4.5 | $1.0/$3.2 (GLM-5) | 高頻度 |
| レビュー層 | PRレビュー、バグ検出、リファクタリング提案 | Claude Sonnet 4.6 | $3/$15 | 中頻度 |
| 深度層 | アーキテクチャ設計、セキュリティ監査、複雑なデバッグ | Claude Opus 4.6 | $5/$25 | 低頻度 |
なぜコード生成にGLM-5を選ぶのか
GLM-5は、智譜AI(Zhipu AI)が2026年2月にリリースしたオープンソースの大規模言語モデルで、コード生成分野において非常に高いコストパフォーマンスを誇ります。
GLM-5の主な仕様:
- パラメータ数: 744B (MoEアーキテクチャ、256エキスパート、毎回8つをアクティブ化、アクティブパラメータは約40B)
- コンテキスト: 200Kトークン
- SWE-bench Verified: 77.8% (オープンソースモデルで1位)
- ライセンス: MIT (完全商用利用可能)
- 入力価格: $1.00/100万トークン — Claude Sonnet 4.6のわずか1/3
GLM-5 vs クローズドモデル SWE-bench比較:
| モデル | SWE-bench Verified | 入力価格 (100万トークンあたり) | コスパ指数 |
|---|---|---|---|
| Claude Opus 4.6 | 81.4% | $5.00 | 16.3 |
| Claude Sonnet 4.6 | 79.6% | $3.00 | 26.5 |
| GPT-5.2 | 80.0% | — | — |
| GLM-5 | 77.8% | $1.00 | 77.8 |
GLM-5のコスパ指数(SWE-benchスコア / 入力価格)は、Claude Sonnet 4.6の約3倍です。コード生成のような高頻度な操作では、呼び出し量に応じてコスト差が急速に拡大します。
なぜコードレビューにClaude Sonnet 4.6を選ぶのか
コードレビューに必要なのは速度ではなく、深い理解と正確な判断です。Sonnet 4.6はこの点で生成層のモデルよりも優れています。
- 100万トークンのコンテキスト: コードベース全体 + PRの差分 + 依存関係を一度に読み込めます
- ファイル横断的な推論: Aファイルの修正がBファイルのロジックに与える影響を特定する能力
- SWE-bench 79.6%: Opus 4.6と比較してもわずか1.8ポイント差
- 開発者の好み: Claude Codeのテストにおいて、開発者の59%が前フラッグシップモデルのOpus 4.5よりもSonnet 4.6を好むと回答
- 過剰なエンジニアリングの抑制: 前世代モデルと比較して、過剰なエンジニアリングや「手抜き」が少ないと評価されています
コスト比較: Sonnet 4.6によるレビューコストはOpus 4.6のわずか1/5ですが、レビュー品質は同等です。ほとんどのPRレビューシーンにおいて、これが最適な選択肢となります。
💡 選定アドバイス: APIYI (apiyi.com) プラットフォームを通じて、GLM-5とClaude Sonnet 4.6のAPIを同時に接続し、1つのキーで複数のモデルを管理できます。生成フェーズではGLM-5を呼び出してコストを抑え、レビューフェーズではSonnet 4.6に切り替えて品質を確保しましょう。
6ステップの実践ワークフロー:要件定義からマージまで
ここでは、実証済みの完全なワークフローを紹介します。核となる理念は、**Explore(探索)→ Plan(計画)→ Generate(生成)→ Review(レビュー)→ Test(テスト)→ Commit(コミット)**です。
ステップ1:仕様書作成 (Specification)
コードを書き始める前に、まずは明確な要件仕様書を作成しましょう。
## 要件
ユーザー登録APIエンドポイントの実装
制約事項
- FastAPI フレームワークを使用すること
- パスワードは bcrypt で暗号化すること
- メールアドレスは一意である必要があり、重複時は 409 Conflict を返すこと
- PostgreSQL に書き込み、SQLAlchemy ORM を使用すること
- JWT トークンを返すこと
不要な機能
- メール認証フロー(今後のイテレーションで対応)
- ソーシャルログイン
ステップ 2:AI による計画策定 (Plan)
Claude Sonnet 4.6 を使用してアーキテクチャの計画を立てます(計画フェーズは高性能なモデルを使う価値があります)。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": "あなたはシニアアーキテクトです。要件に基づいて、ファイル構造、主要な関数シグネチャ、データフローを含む実装計画を出力してください。完全なコードは書かないでください。"},
{"role": "user", "content": spec_content}
]
)
print(response.choices[0].message.content)
ステップ 3:AI によるコード生成 (Generate)
計画を確認後、GLM-5 を使用して実装コードを生成します。
# コストパフォーマンスの高いモデルに切り替えてコード生成
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": f"以下のアーキテクチャ計画に従ってコードを実装してください:\n{plan}"},
{"role": "user", "content": "ユーザー登録 API の完全なコードを実装してください"}
],
max_tokens=8192
)
重要な原則:
- 一度に生成するのは一つの関数やモジュールのみとし、プロジェクト全体を一度に生成しない
- 生成後すぐに
git commitを行い、ロールバック用の「セーブポイント」を作成する - 反復的なコード(CRUD、フォームバリデーションなど)は積極的に AI に生成させる
- セキュリティに関わるコード(認証、暗号化、権限管理)は手動で記述するか、二重にチェックする
ステップ 4:AI によるレビュー (Review)
コード生成後、Claude Sonnet 4.6 に切り替えてレビューを行います。
# レビュー用モデルに切り替え
generated_code = open("app/routes/auth.py").read()
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"以下のコードをレビューしてください:\n\n{generated_code}"}
],
max_tokens=4096
)
完全なレビュー用プロンプトテンプレートを表示
REVIEW_PROMPT = """あなたはシニアコードレビュアーです。このコードは AI によって生成されました。特に以下の点に注意してください:
1. **AI 特有の問題**: 存在しない API やライブラリ関数、一見正しそうだが論理的に誤っているコード
2. **セキュリティ**: インジェクション、ハードコードされたキー、安全でない暗号化、権限バイパス
3. **境界条件**: 空の値、並行処理、大量データ、ネットワークタイムアウト
4. **アーキテクチャの一貫性**: プロジェクトの既存スタイルと一致しているか?命名、階層化、エラー処理
5. **テスト容易性**: ユニットテストが書きやすいか?依存関係は注入可能か?
重大度別に分類して出力してください:
- 🔴 修正必須 (セキュリティ/論理エラー)
- 🟡 修正推奨 (コード品質)
- 💡 改善提案 (オプションの最適化)
問題がない場合は「レビュー通過」と明記してください。存在しない問題を捏造しないでください。"""
ステップ 5:テストと検証 (Test)
レビュー通過後、テストコードを生成します(コスト削減のため、引き続き GLM-5 を使用)。
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "以下のコードに対して、正常系および境界条件を網羅した pytest ユニットテストを作成してください。"},
{"role": "user", "content": generated_code}
]
)
ステップ 6:人間による最終確認とマージ
AI によるレビューとテストが完了した後、人間が最終確認を行います。
- アーキテクチャの決定は合理的か?
- ビジネス上の意図に合致しているか?
- AI が感知できないコンテキスト上のリスクはないか?
🚀 効率化データ: このワークフローの核心的な利点は、人間の注意力を最も価値のある部分に集中させることです。AI が 80% の機械的な作業(生成、スタイルチェック、基本的なバグ検出)を処理し、人間は 20% の高価値な判断(アーキテクチャ、セキュリティ、ビジネスロジック)に集中します。APIYI (apiyi.com) という一つのプラットフォームで GLM-5 と Claude 4.6 の API 呼び出しを管理することで、複数のアカウントを個別に登録・管理する手間を省くことができます。
Claude Code:フルスタック AI プログラミングの究極のソリューション
自分でマルチモデルのワークフローを構築するのが面倒だと感じているなら、Claude Code が「オールインワン」の解決策を提供します。これはターミナル上で動作する AI プログラミングエージェントで、コードベースの読み込み、ファイルの編集、コマンドの実行、問題解決を自律的に行います。

Claude Code の主な強み
| 能力 | Claude Code | Cursor | Windsurf |
|---|---|---|---|
| タイプ | ターミナル自律エージェント | VS Code 拡張版 | VS Code 拡張版 |
| 理念 | AI による自律実行 | AI による編集支援 | AI との協調コーディング |
| コンテキスト | 200K+ トークン | ~120K トークン | ~100K トークン |
| ファイル処理 | 100+ ファイル | 30-50 ファイル | 30-50 ファイル |
| 得意分野 | マルチファイル・アーキテクチャ変更 | 日常のコーディング、集中タスク | 反復的な構築、プロトタイプ |
| 価格 | $100-200/月 または API 従量課金 | $20/月 | $15/月 |
Claude Code のベストプラクティス
1. AI に自身の作業を検証させる
これは公式ドキュメントでも強調されている、最も効果の高いプラクティスです。
# 良いプロンプト
"ユーザー登録機能を実装し、対応する pytest テストを作成してください。テストがパスすることを確認してからコミットしてください"
# 悪いプロンプト
"ユーザー登録機能を実装して"
2. Writer/Reviewer のデュアルセッションモード
Claude Code のセッションを2つ立ち上げます。
- セッション A (Writer): 機能の実装に集中する
- セッション B (Reviewer): まったく新しいコンテキストで Writer の出力をレビューする
この「AI が AI をレビューする」手法は、単一の AI では見落としがちな盲点を発見するのに非常に有効です。
3. CLAUDE.md プロジェクト設定を使いこなす
# CLAUDE.md
プロジェクトの技術スタック
Python 3.12 + FastAPI + SQLAlchemy + PostgreSQL
コーディング規約
- 型ヒント: すべての関数に型ヒントを必須とする
- エラーハンドリング: カスタムの
AppErrorクラスを使用する - ログ出力: 業務イベントは
INFO、デバッグ情報はDEBUGレベルで記録する
禁止事項
print()は使用せず、loggerを使用すること- 設定をハードコードせず、環境変数を使用すること
- ルート関数内に直接 SQL を記述しないこと
**4. 80/15/5 ツール活用ルール**
経験豊富な開発者が推奨するツールの配分は以下の通りです:
- **80%**: 自動補完およびインライン編集 (Cursor/Copilot) — 日常的なコーディング
- **15%**: 中程度の複雑さを持つエージェントタスク (Cursor Agent/Windsurf) — 機能実装
- **5%**: 複雑な複数ファイルにまたがるアーキテクチャ変更 (Claude Code) — 大規模なリファクタリング
> 💰 **コストに関するアドバイス**: Claude Code の API モードはトークン課金制ですが、APIYI (apiyi.com) を経由して接続することで、公式よりもお得な価格で Claude モデルを利用できます。Claude Code の全機能が不要な場合は、API を直接呼び出して Claude Sonnet 4.6 でコードレビューを行うことも可能です。
---
## 実践事例:コード生成からレビューまでの完全フロー
ここでは、GLM-5 を使用して FastAPI のユーザー認証モジュールを生成し、Claude Sonnet 4.6 でレビューを行う実際のシナリオを紹介します。
### ワークフローのコード例
```python
import openai
# ロガーの設定(printの代わりに使用)
import logging
logger = logging.getLogger(__name__)
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース
)
# ===== ステップ1: GLM-5 でコードを生成 =====
gen_response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "あなたは Python バックエンドの専門家です。"},
{"role": "user", "content": """
FastAPI のユーザー登録エンドポイントを実装してください:
- POST /api/v1/register
- email と password を受け取る
- bcrypt でパスワードをハッシュ化する
- PostgreSQL に保存する
- JWT トークンを返す
"""}
],
max_tokens=4096
)
generated_code = gen_response.choices[0].message.content
# ===== ステップ2: Claude Sonnet 4.6 でレビュー =====
review_response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"以下の AI 生成コードをレビューしてください:\n\n{generated_code}"}
],
max_tokens=4096
)
review_result = review_response.choices[0].message.content
logger.info("=== 審査結果 ===")
logger.info(review_result)
コスト分析
| ステップ | モデル | 入力トークン | 出力トークン | コスト |
|---|---|---|---|---|
| コード生成 | GLM-5 | ~500 | ~2000 | ~$0.007 |
| コード審査 | Sonnet 4.6 | ~3000 | ~1500 | ~$0.032 |
| 合計 | — | — | — | ~$0.04 |
「生成+審査」の1回あたりのコストは 0.04 ドル未満です。1日に 50 回このサイクルを繰り返したとしても、月額コストは約 60 ドルに抑えられます。
もしすべてを Claude Opus 4.6 で行った場合、同じワークフローのコストは約 0.18 ドル/回となり、この組み合わせプランの 4.5 倍のコストがかかります。
🎯 重要なポイント: GLM-5 で生成し Sonnet 4.6 で審査する組み合わせは、すべてを Opus 4.6 で行う場合のわずか 22% のコストで済みますが、審査品質にほとんど差はありません。APIYI (apiyi.com) のプラットフォームなら、1つの API キーですべてのモデルを呼び出せます。
よくある質問
Q1: 安価なモデルで書かれたコードの品質は十分ですか?
GLM-5 は SWE-bench Verified で 77.8% のスコアを記録しており、Claude Sonnet 4.6 と比較してもわずか 2 パーセントポイント程度の差ですが、価格は 3 分の 1 です。コード生成タスクの大半(CRUD、API エンドポイント、データ処理など)において、品質は十分実用的です。重要なのは、その後のレビュー工程でしっかりカバーすることです。APIYI (apiyi.com) を通じて 2 つのモデルを同時に接続し、柔軟に切り替えて利用できます。
Q2: 安価なモデルでコード生成すべきではない場面はありますか?
セキュリティに関わる重要なコード(認証、暗号化、権限制御)、並行処理や分散処理のロジック、金融計算に関わる精度が求められるコードなどが挙げられます。これらのシナリオでは、Claude Sonnet 4.6 や Opus 4.6 を直接使用するか、手動で記述した上で AI にレビューさせることをお勧めします。
Q3: Claude Code は誰にでも適していますか?
Claude Code は、経験豊富な開発者が複雑な複数ファイルのアーキテクチャレベルのタスクを処理するのに最適です。もし単一ファイルの修正や日常的なコーディングが中心であれば、Cursor や Windsurf の方が適しているかもしれません(コストも抑えられます)。多くのシニア開発者はこれらを併用しており、日常業務には Cursor、複雑なタスクには Claude Code といった使い分けをしています。
Q4: このワークフローの効果をどのように測定すればよいですか?
以下の 4 つの指標を追跡することをお勧めします。(1) 1 人あたりのコード生産量の変化、(2) バグ率の変化(リリース後の不具合数)、(3) レビュー時間の変化、(4) API 呼び出しコスト。2 週間のパイロット運用を行い、前後でデータを比較してみてください。APIYI (apiyi.com) の利用統計機能を使えば、API コストを簡単に追跡できます。
Q5: GLM-5 以外に、コストパフォーマンスの高いコード生成モデルはありますか?
Claude Haiku 4.5(非常に高速で単純なタスクに最適)、DeepSeek V3(オープンソースで中国語のコンテキストに強い)、GPT-5.3 Codex(コード特化型)などがあります。どれを選ぶかは、使用言語の好みや具体的なシナリオによって異なります。APIYI (apiyi.com) を使えば、これらすべてのモデルを一括で接続できるため、複数のプラットフォームを管理する手間を省けます。
まとめ:AI プログラミングの正しい始め方
AI プログラミングの核心は「AI にすべてのコードを書かせること」ではなく、効率的なマルチモデル連携フローを構築することにあります。2026 年のベストプラクティスは以下の通りです。
モデル選定の公式:
- 🟢 高頻度・低リスク (ボイラープレートコード、CRUD) → GLM-5 などの高コスパモデル
- 🟡 中頻度・中リスク (PR レビュー、リファクタリング) → Claude Sonnet 4.6
- 🔴 低頻度・高リスク (セキュリティ監査、アーキテクチャ設計) → Claude Opus 4.6
ワークフローの公式:
- 仕様策定 → 計画 → 生成 → レビュー → テスト → 最後に人間による最終確認
- AI が 80% の機械的な作業をこなし、人間は 20% の価値の高い判断に集中する
APIYI (apiyi.com) を通じて、GLM-5、Claude Sonnet 4.6、Opus 4.6 などの主要モデルを一括で接続し、一つのプラットフォームで完全なマルチモデル AI プログラミングワークフローを構築することをお勧めします。
参考資料
-
Addy Osmani: LLM プログラミングワークフロー 2026
- リンク:
addyosmani.com/blog/ai-coding-workflow
- リンク:
-
Claude Code 公式ベストプラクティス: エージェント型プログラミングガイド
- リンク:
code.claude.com/docs/en/best-practices
- リンク:
-
GLM-5 技術論文: Vibe Coding からエンジニアリング AI プログラミングへ
- リンク:
arxiv.org
- リンク:
-
Anthropic 公式: Claude Sonnet 4.6 リリースノート
- リンク:
anthropic.com/news/claude-sonnet-4-6
- リンク:
-
MIT Technology Review: 生成的プログラミング 2026 年の画期的技術
- リンク:
technologyreview.com
- リンク:
著者: APIYI Team | AI を活用したソフトウェア開発のベストプラクティスを探求しています。GLM-5 や Claude 4.6 全シリーズモデルの統一 API インターフェースについては、APIYI (apiyi.com) をぜひご覧ください。