

当你使用 Gemini API 原生格式调用时,突然遇到这个令人困惑的错误:
GenerateContentRequest.contents[0].parts[0].data: required oneof field 'data' must have one initialized field
这意味着你的请求体结构存在问题。本文将深入分析这个 400 Bad Request 错误的 5 种常见原因,并提供可直接使用的修复代码。
理解 Gemini API 原生格式的 Parts 数据结构
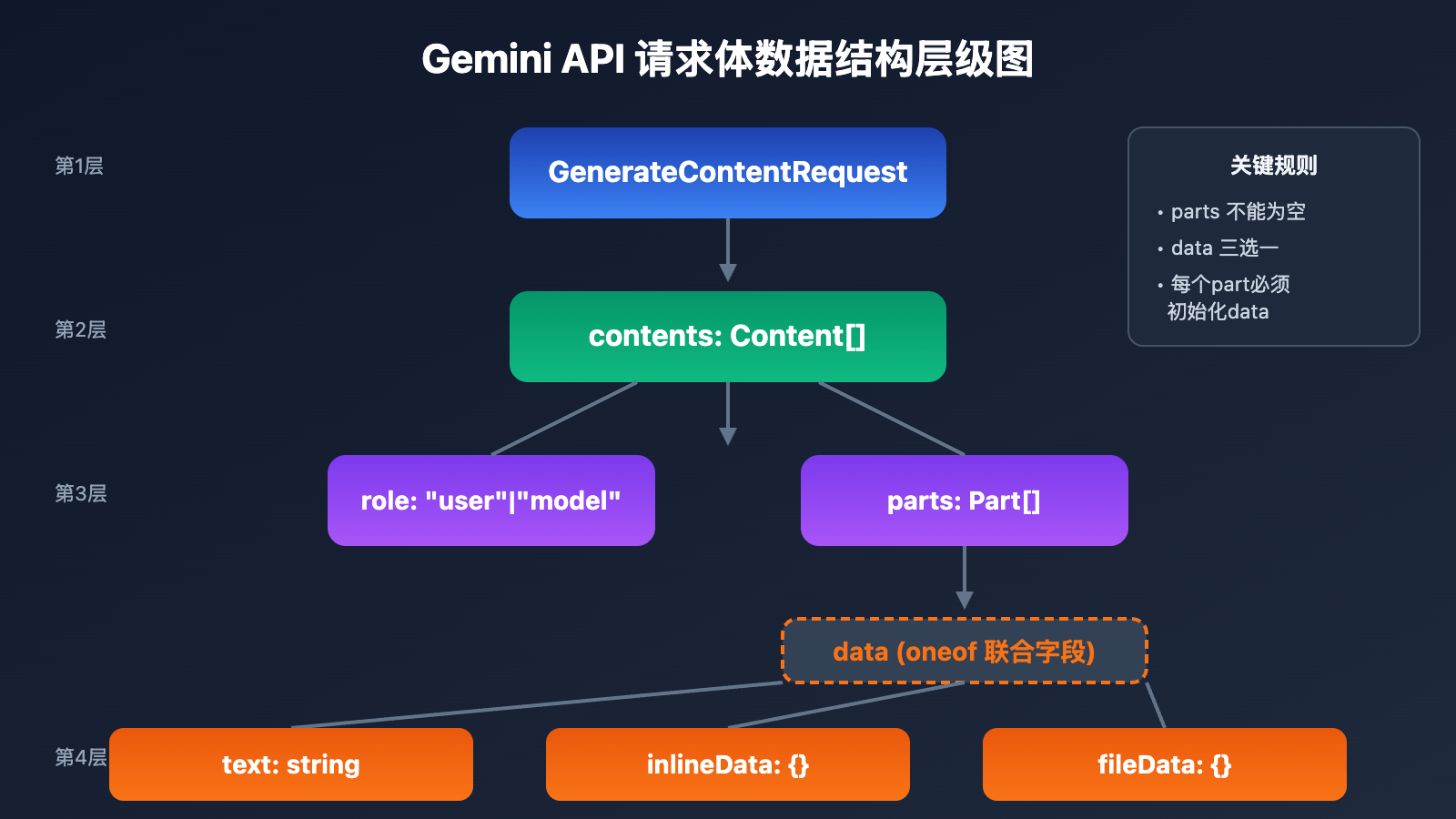
在深入修复之前,我们需要理解 Gemini API 的核心数据结构。与 OpenAI 兼容格式不同,Gemini 原生格式使用独特的 contents → parts 层级结构。
Gemini API 请求体核心结构
| 层级 | 字段名 | 类型 | 说明 |
|---|---|---|---|
| 第1层 | contents |
array | 对话内容数组,每个元素代表一轮对话 |
| 第2层 | role |
string | 角色标识:user 或 model |
| 第2层 | parts |
array | 内容片段数组,包含实际数据 |
| 第3层 | data (oneof) |
union | 联合字段:只能选择其中一种类型 |
Parts 中的 Data 联合字段类型
这是理解报错的关键。data 是一个 oneof 联合字段,意味着每个 part 对象只能包含以下三种类型之一:
| 字段类型 | 用途 | 必需参数 |
|---|---|---|
text |
纯文本内容 | text: string |
inlineData |
Base64 编码的二进制数据 | mimeType, data |
fileData |
Google Cloud Storage 文件引用 | mimeType, fileUri |
🎯 核心要点: 错误
required oneof field 'data' must have one initialized field表示你的parts数组中存在空对象或未正确初始化的 data 字段。
导致 required oneof field data 报错的 5 种原因及修复方案
根据 Google AI 开发者社区和 GitHub 上的大量案例分析,我们总结出 5 种最常见的错误原因。
原因一:Parts 数组包含空对象
这是最常见的错误原因。当 parts 数组中存在 {} 空对象时,Gemini API 无法解析数据类型。
错误示例:
{
"contents": [
{
"role": "user",
"parts": [
{}
]
}
]
}
正确写法:
{
"contents": [
{
"role": "user",
"parts": [
{
"text": "你好,请介绍一下你自己"
}
]
}
]
}
原因二:Function Calling 响应格式错误
当使用 Gemini 的 Function Calling 功能时,函数返回结果的格式必须严格遵循规范。
错误场景:
# 错误:直接添加空的 function response
conversation_history.append({
"role": "function",
"parts": [
{
"functionResponse": {
"name": "get_weather",
"response": None # 空响应导致报错
}
}
]
})
正确写法:
# 正确:确保 function response 包含有效数据
conversation_history.append({
"role": "function",
"parts": [
{
"functionResponse": {
"name": "get_weather",
"response": {
"temperature": 25,
"condition": "sunny"
}
}
}
]
})
原因三:文件上传后直接传递 File 对象
使用 Gemini SDK 上传文件后,不能直接将 File 对象放入 contents 中。
错误示例:
# 错误:直接传递 File 对象
uploaded_file = client.files.upload(path="document.pdf")
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[uploaded_file] # 这会导致报错
)
正确写法:
# 正确:使用 fileData 结构引用已上传的文件
uploaded_file = client.files.upload(path="document.pdf")
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[
{
"role": "user",
"parts": [
{
"text": "请分析这个文档"
},
{
"fileData": {
"mimeType": "application/pdf",
"fileUri": uploaded_file.uri
}
}
]
}
]
)
原因四:多模态请求中 inlineData 格式错误
发送图片或其他二进制数据时,inlineData 的格式必须完整。
错误示例:
{
"contents": [
{
"parts": [
{
"text": "描述这张图片"
},
{
"inlineData": {
"data": ""
}
}
]
}
]
}
正确写法:
{
"contents": [
{
"parts": [
{
"text": "描述这张图片"
},
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "BASE64_ENCODED_IMAGE_DATA_HERE"
}
}
]
}
]
}
原因五:对话历史中存在损坏的 Content 块
在多轮对话场景中,历史消息压缩或序列化可能导致部分 Content 块损坏。
问题场景:
| 场景 | 描述 | 风险等级 |
|---|---|---|
| 历史压缩 | 压缩算法移除了部分内容 | 高 |
| 版本升级 | SDK 版本不兼容 | 中 |
| 缓存损坏 | 本地缓存数据不完整 | 中 |
| 序列化错误 | JSON 解析时丢失字段 | 高 |
修复方案:
def validate_and_clean_history(conversation_history):
"""验证并清理对话历史,移除无效的 Content 块"""
cleaned_history = []
for content in conversation_history:
if not content.get("parts"):
continue # 跳过没有 parts 的内容
valid_parts = []
for part in content["parts"]:
# 检查 part 是否包含有效的 data 字段
if part.get("text") or part.get("inlineData") or part.get("fileData"):
valid_parts.append(part)
elif part.get("functionCall") or part.get("functionResponse"):
valid_parts.append(part)
if valid_parts:
cleaned_history.append({
"role": content.get("role", "user"),
"parts": valid_parts
})
return cleaned_history
Gemini API 原生格式请求的完整代码示例
以下是经过验证的完整请求示例,可直接用于生产环境。
使用 curl 发送纯文本请求
curl "https://api.apiyi.com/v1/models/gemini-2.0-flash:generateContent" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [
{
"role": "user",
"parts": [
{
"text": "请用 3 句话解释量子计算的基本原理"
}
]
}
],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 1024
}
}'
使用 Python 发送多模态请求
import requests
import base64
def call_gemini_multimodal(text_prompt, image_path):
"""
调用 Gemini API 进行多模态内容生成
通过 API易 apiyi.com 统一接口调用
"""
# 读取并编码图片
with open(image_path, "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
# 构建符合规范的请求体
payload = {
"contents": [
{
"role": "user",
"parts": [
{
"text": text_prompt
},
{
"inlineData": {
"mimeType": "image/jpeg",
"data": image_data
}
}
]
}
],
"generationConfig": {
"temperature": 0.4,
"maxOutputTokens": 2048
}
}
response = requests.post(
"https://api.apiyi.com/v1/models/gemini-2.0-flash:generateContent",
headers={
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
},
json=payload
)
return response.json()
# 使用示例
result = call_gemini_multimodal(
text_prompt="请描述这张图片的内容",
image_path="./example.jpg"
)
print(result)

🚀 快速开始: 推荐使用 API易 apiyi.com 平台快速测试 Gemini API 原生格式调用。该平台提供统一的 API 接口,支持 Gemini 全系列模型,5 分钟即可完成集成验证。
调试 Gemini API 原生格式请求的实用技巧
请求验证检查清单
在发送请求前,使用以下清单验证请求体结构:
| 检查项 | 验证方法 | 通过标准 |
|---|---|---|
| contents 非空 | len(contents) > 0 |
至少包含 1 个对话轮次 |
| parts 非空 | len(content["parts"]) > 0 |
每个 content 至少 1 个 part |
| data 字段存在 | 检查 text/inlineData/fileData | 三选一必须存在 |
| mimeType 正确 | 验证 MIME 类型格式 | 符合标准 MIME 格式 |
| Base64 编码有效 | 尝试解码验证 | 解码不报错 |
本地验证脚本
def validate_gemini_request(request_body):
"""验证 Gemini API 请求体结构"""
errors = []
# 检查 contents
if "contents" not in request_body:
errors.append("缺少 contents 字段")
return errors
contents = request_body["contents"]
if not isinstance(contents, list) or len(contents) == 0:
errors.append("contents 必须是非空数组")
return errors
for i, content in enumerate(contents):
# 检查 parts
if "parts" not in content:
errors.append(f"contents[{i}] 缺少 parts 字段")
continue
parts = content["parts"]
if not isinstance(parts, list) or len(parts) == 0:
errors.append(f"contents[{i}].parts 必须是非空数组")
continue
for j, part in enumerate(parts):
# 检查 data 字段 (oneof)
has_data = any([
"text" in part and part["text"],
"inlineData" in part and part["inlineData"],
"fileData" in part and part["fileData"],
"functionCall" in part,
"functionResponse" in part
])
if not has_data:
errors.append(
f"contents[{i}].parts[{j}] 缺少有效的 data 字段 "
f"(text/inlineData/fileData)"
)
return errors
# 使用示例
request = {
"contents": [
{
"role": "user",
"parts": [{}] # 这会被检测到
}
]
}
errors = validate_gemini_request(request)
if errors:
print("请求验证失败:")
for error in errors:
print(f" - {error}")
else:
print("请求验证通过")
Gemini API 原生格式 vs OpenAI 兼容格式对比
理解两种格式的差异,有助于在迁移或混合使用时避免错误。
请求结构对比
| 特性 | Gemini 原生格式 | OpenAI 兼容格式 |
|---|---|---|
| 顶层字段 | contents |
messages |
| 角色标识 | role: user/model |
role: user/assistant/system |
| 内容层级 | parts 数组 |
content 字符串或数组 |
| 多模态数据 | inlineData / fileData |
image_url 结构 |
| 函数调用 | functionCall / functionResponse |
function_call / tool_calls |
| 支持平台 | API易 apiyi.com, Google AI Studio | API易 apiyi.com, OpenAI |
多模态请求格式对比
Gemini 原生格式:
{
"contents": [{
"parts": [
{"text": "描述图片"},
{"inlineData": {"mimeType": "image/jpeg", "data": "BASE64..."}}
]
}]
}
OpenAI 兼容格式:
{
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "描述图片"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}
💡 选择建议: 如果你需要同时使用多种大模型,推荐通过 API易 apiyi.com 平台进行统一接口调用。该平台同时支持 Gemini 原生格式和 OpenAI 兼容格式,便于快速切换和对比不同模型的效果。
常见问题解答 (FAQ)
Q1: 为什么使用 SDK 上传文件后仍然报错?
使用 client.files.upload() 上传文件后,返回的 File 对象不能直接放入 contents 数组。你需要使用 fileData 结构来引用它:
# 正确做法
uploaded_file = client.files.upload(path="doc.pdf")
parts = [
{"text": "分析这个文档"},
{"fileData": {"mimeType": "application/pdf", "fileUri": uploaded_file.uri}}
]
通过 API易 apiyi.com 平台调用时,建议优先使用 inlineData 直接传递 Base64 编码数据,可以减少文件上传的额外步骤。
Q2: 多轮对话时如何避免历史消息损坏?
建议在每次发送请求前验证对话历史的完整性:
def prepare_conversation(history, new_message):
# 过滤掉无效的历史记录
valid_history = [
msg for msg in history
if msg.get("parts") and all(
p.get("text") or p.get("inlineData") or p.get("fileData")
for p in msg["parts"]
)
]
# 添加新消息
valid_history.append({
"role": "user",
"parts": [{"text": new_message}]
})
return valid_history
通过 API易 apiyi.com 进行测试时,可以利用其请求日志功能快速定位问题历史消息。
Q3: inlineData 支持哪些 MIME 类型?
Gemini API 支持的主要 MIME 类型包括:
| 类别 | 支持的 MIME 类型 |
|---|---|
| 图片 | image/jpeg, image/png, image/gif, image/webp |
| 视频 | video/mp4, video/webm, video/quicktime |
| 音频 | audio/mp3, audio/wav, audio/ogg |
| 文档 | application/pdf, text/plain, text/html |
Q4: 如何处理超大文件导致的请求超时?
对于大文件,建议:
- 使用 File API 先上传: 通过
files.upload()上传后使用fileData引用 - 压缩图片: 将图片压缩到合理大小 (建议 < 4MB)
- 分片处理: 将长视频或大文档分片处理
Q5: 如何快速验证请求格式是否正确?
最快的方法是使用最简单的请求进行测试:
# 最简验证请求
curl "https://api.apiyi.com/v1/models/gemini-2.0-flash:generateContent" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{"contents":[{"parts":[{"text":"Hello"}]}]}'
如果这个请求成功,说明 API 连接正常,问题出在你的具体请求结构上。
总结与最佳实践
Gemini API 原生格式调用要点
- parts 数组必须非空: 每个 part 对象必须包含有效的 data 字段
- data 是 oneof 联合字段: text、inlineData、fileData 三选一
- 文件引用使用 fileData: 上传后的 File 对象需要转换格式
- 验证对话历史: 多轮对话时注意清理无效的 Content 块
- 正确使用 mimeType: inlineData 必须包含有效的 MIME 类型
推荐的开发流程
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | 使用最简请求测试连通性 | 确认 API 密钥和网络正常 |
| 2 | 逐步添加复杂度 | 从纯文本到多模态 |
| 3 | 使用验证脚本检查请求 | 发送前预验证 |
| 4 | 记录请求日志 | 便于问题复现和排查 |
| 5 | 处理错误响应 | 解析具体的错误位置 |
推荐通过 API易 apiyi.com 快速验证 Gemini API 原生格式调用。该平台提供完整的请求日志和错误追踪功能,帮助你快速定位和解决 required oneof field data 相关问题。
参考资料
-
Google AI 开发者论坛: Gemini API 错误讨论
- 链接:
discuss.ai.google.dev - 说明: 社区问题和官方解答
- 链接:
-
Google Gemini Cookbook: 官方示例代码仓库
- 链接:
github.com/google-gemini/cookbook - 说明: 包含各种场景的代码示例
- 链接:
-
Gemini API 官方文档: Generate Content API 参考
- 链接:
ai.google.dev/api/generate-content - 说明: 完整的 API 参数说明
- 链接:
-
Vertex AI 文档: 多模态内容生成指南
- 链接:
cloud.google.com/vertex-ai/generative-ai/docs - 说明: 企业级部署最佳实践
- 链接:
本文由 API易技术团队撰写。如需进一步技术支持,欢迎访问 API易 apiyi.com 获取帮助。