
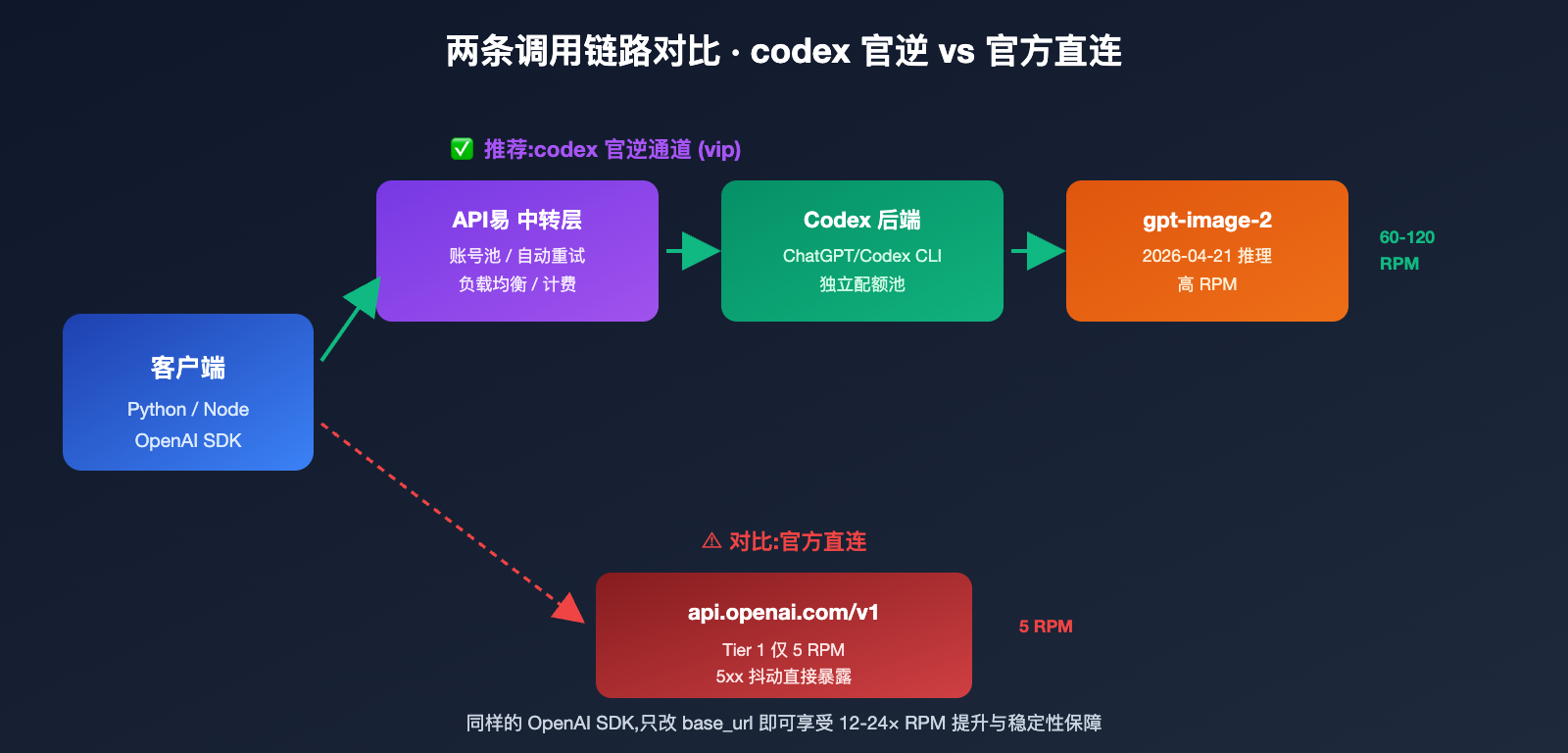
刚把 gpt-image-2 接到生产环境的同学,大概率会被两件事卡住:速率限制和稳定性。OpenAI 官方直连 gpt-image-2 的速率限制非常苛刻,Tier 1 账号每分钟仅 5 次,稍微一批量就触发 429;遇到 5xx 抖动还会一连几次失败。这时候很多团队会去找"官逆通道"——逆向 ChatGPT Pro/Codex CLI 内置的 gpt-image-2 后端,共享更高的 RPM 配额和更稳的链路。
API易 apiyi.com 上线的 gpt-image-2-vip 模型,走的正是这条 codex 官逆线路。本文围绕 5 个核心特性、30 种尺寸选项、3 个兼容端点和实战代码,把这个接口讲透,看完就能直接接入生产。

codex 官逆 API 是什么:与官方直连有 3 个本质区别
很多开发者第一次听到"codex 官逆"会以为是非法接口,其实它指的是逆向 OpenAI 自家 Codex CLI/ChatGPT Pro 内嵌的 gpt-image-2 调用链。OpenAI 在 2026 年 4 月发布 gpt-image-2 时,同时把它内置进了 Codex CLI($imagegen 技能)和 ChatGPT 客户端,这两个入口共享一套独立的速率配额池,且与公开 API 的限流策略不同。
codex 官逆通道做的事情是:把 Codex 内部那条数据流暴露成 REST 接口,让你能像调用普通 OpenAI API 一样用 gpt-image-2,但实际走的是 ChatGPT 一侧的后端。gpt-image-2-vip 模型就是这种实现,它和官方直连相比有 3 个本质差异。
| 维度 | OpenAI 官方直连 | codex 官逆通道 (gpt-image-2-vip) |
|---|---|---|
| 速率限制 | Tier 1: 5 RPM,需充值才能解锁 | 走 Codex 共享池,远高于 Tier 1 |
| 计费模型 | 按图片尺寸/质量阶梯计费 | 统一 $0.03/张,30 种尺寸同价 |
| 稳定性 | 受官方 5xx 波动直接影响 | 多账号池 + 自动重试,屏蔽底层抖动 |
quality 参数 |
支持 low/medium/high/auto | 不支持(走 Codex 内置策略) |
n 参数批量 |
支持 1-4 张 | 不支持,单次返回 1 张 |
| URL 有效期 | 60 分钟 | ~24 小时 |
🎯 首要认知: 官逆不是"破解",它是把 OpenAI 自家产品(Codex CLI)的内部调用链暴露成 REST 接口。API易 apiyi.com 把这条通道做成商业化产品,核心价值不是绕过 OpenAI,而是把 Codex 一侧更稳的速率配额给到 API 用户。
gpt-image-2-vip 的 5 大核心特性
理解了通道差异之后,看具体特性就更清晰。下面 5 点是 gpt-image-2-vip 与同系列模型 gpt-image-2-all、官方 gpt-image-2 最关键的区别,也是文档里写得相对零散、需要重点画出来的内容。
特性一:30 种尺寸自由锁定,$0.03 统一计费
gpt-image-2-vip 最大的工程价值,是把"尺寸"做成了一等参数。模型支持 10 种宽高比 × 3 档分辨率 = 30 种确定尺寸,在 size 参数里指定即可,不需要绕弯路调 prompt。计费层面更直接:所有 30 种尺寸统一 $0.03/张,不再有"大尺寸更贵"的隐性成本。这对做模板化生成、批量缩略图的团队来说是巨大的成本可预测性提升。
| 分辨率档位 | 短边像素 | 长边像素(上限) | 适用场景 |
|---|---|---|---|
| 1K | ~1024 | ~1820 | 缩略图、信息流封面、社交媒体 |
| 2K | ~2048 | ~3640 | 海报、电商主图、内容卡片 |
| 4K | ~2880 | ~3840 | 高清打印、视频素材、印刷物料 |
10 种比例覆盖了 1:1 方图、16:9 横版、9:16 竖版、4:3、3:2、21:9 等主流构图需求,基本不用再做后期裁剪。统一定价的另一个隐性价值是,你可以在生产管线里随业务需要切换分辨率而不影响财务模型——比如 A/B 测试时把同一 prompt 跑 1K 和 4K 各一张做对比,成本完全可预测,不会因为某个分支用了大尺寸而导致月底账单失控。
特性二:三个端点全部兼容
gpt-image-2-vip 同时支持 OpenAI 标准的三个图像端点:/v1/images/generations(纯文生图)、/v1/images/edits(图生图与编辑)、/v1/chat/completions(聊天接口出图)。这一点很关键,意味着你不用重写已有的 SDK 代码,只需要把 model 从 gpt-image-2 换成 gpt-image-2-vip,把 base_url 切到中转入口即可。
特性三:多图融合与图生图
通过 /v1/images/edits 端点上传 1-N 张图,再配合 prompt 描述合成意图,模型会做风格迁移、内容融合、版式重排。比如把"产品图 + 模特图 + 背景图"三张图合成一张电商主图。每张图建议压缩到 1.5MB 以内,否则 input token 消耗会显著上涨。
特性四:中文原生理解
gpt-image-2-vip 与官方 gpt-image-2 共享同一个推理后端,继承了中、日、韩、印地、孟加拉多语言文字渲染能力。中文 prompt 不需要英译,海报里的中文标题、按钮文字都能精确还原,这是 Midjourney、Stable Diffusion 都做不到的。
特性五:失败请求不计费
这是计费层面的细节,但对大规模生产来说省钱意义巨大。任何返回 5xx、超时、被安全策略拦截的请求都不会扣费,只有成功返回图片的调用才计入消耗。这让你可以放心做指数退避重试,不用担心重试本身把账单打爆。配合"统一 $0.03/张"的定价,成本预估变得极其简单:计划生成 10000 张图,就是 $300 上下,不需要再按尺寸/质量分档建模,财务和产品都能直接拍板。
调用流程与代码示例:从 5 行 Python 开始
接入逻辑非常直接,与官方 OpenAI SDK 完全一致,只需切换 base_url 和 model。下面是文生图最小可运行示例,base_url 指向 API易 apiyi.com 的统一中转入口。
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
resp = client.images.generate(
model="gpt-image-2-vip",
prompt="深色科技感发布会主视觉,中央霓虹标题『API易 · gpt-image-2 上线』,左下角小字 2026",
size="2048x1152"
)
img_b64 = resp.data[0].b64_json
with open("poster_2k.png", "wb") as f:
f.write(base64.b64decode(img_b64))
如果你要做图生图或多图融合,把 client.images.generate 换成 client.images.edit,再加 image=[open("a.png","rb"), open("b.png","rb")] 即可。三个端点的请求体格式都遵循 OpenAI 官方规范。
🎯 快速上手建议: 想要 30 秒跑通这条流程,我们推荐先在 API易 apiyi.com 创建一个 API key,然后用
gpt-image-2-vip+ 任意 size 跑一张测试图。失败请求不计费,可以放心调试参数。
30 种尺寸怎么选:按场景速查
很多人面对 30 种 size 选项第一反应是"选哪个",我们按业务场景归类。重要的认知是:所有尺寸价格相同,所以选尺寸完全按业务需求来,不用为了省钱牺牲清晰度。
| 业务场景 | 推荐比例 | 推荐分辨率 | 典型 size |
|---|---|---|---|
| 公众号封面 / 知乎首图 | 16:9 / 3:2 | 2K | 2048×1152 |
| 小红书 / 抖音竖版 | 9:16 / 4:5 | 2K | 1152×2048 |
| 电商主图 / 详情页 | 1:1 | 2K 或 4K | 2048×2048 或 2880×2880 |
| 网站 Hero 大图 | 21:9 / 16:9 | 4K | 3840×1640 或 3840×2160 |
| PPT 内页插图 | 16:9 | 1K 或 2K | 1820×1024 |
| 印刷品 / 海报 | 3:4 / 2:3 | 4K | 2880×3840 |
| 信息流缩略图 | 1:1 | 1K | 1024×1024 |
| Banner 长条 | 21:9 | 1K | 1820×780 |
🎯 尺寸选择建议: 我们推荐生产环境优先用 2K 档,单图体积约 1-3MB,加载速度和视觉效果平衡最好;只在需要印刷或大屏展示时才上 4K,1K 留给信息流缩略图等小图场景。
gpt-image-2 系列三种通道对比:vip / all / 官方
API易 apiyi.com 上其实有三个 gpt-image-2 相关模型,选错很容易踩坑,下面把它们的差异讲清楚,避免接入后还要返工。
gpt-image-2(官方直连)走 OpenAI 公开 API,支持 quality 和 n 参数,但要自己处理 5 RPM 的低速率限制。gpt-image-2-all 是聚合通道,支持所有参数但尺寸由 prompt 控制、不够精准。gpt-image-2-vip 就是本文主角,走 codex 官逆,强项是 size 精准锁定 + 统一定价 + 高 RPM。
| 模型 ID | 通道类型 | 速率 | 尺寸控制 | quality 参数 | 单次张数 | 推荐场景 |
|---|---|---|---|---|---|---|
gpt-image-2 |
官方直连 | Tier 限制 | size 精准 | ✅ | 1-4 | 对质量分档敏感、低频调用 |
gpt-image-2-all |
聚合通道 | 中等 | 靠 prompt 描述 | ✅ | 1-4 | 老代码迁移、需要 quality 参数 |
gpt-image-2-vip |
codex 官逆 | 高 RPM | size 精准 | ❌ | 1 | 批量生产、固定尺寸、稳定优先 |

简单决策:如果你要的是稳定大批量、固定尺寸、可预测计费,选 gpt-image-2-vip;如果你必须用 quality=high 做高保真,选 gpt-image-2-all;只有少量低频调用且想要全套参数,才考虑 gpt-image-2。
稳定性最佳实践:超时、重试、URL 时效
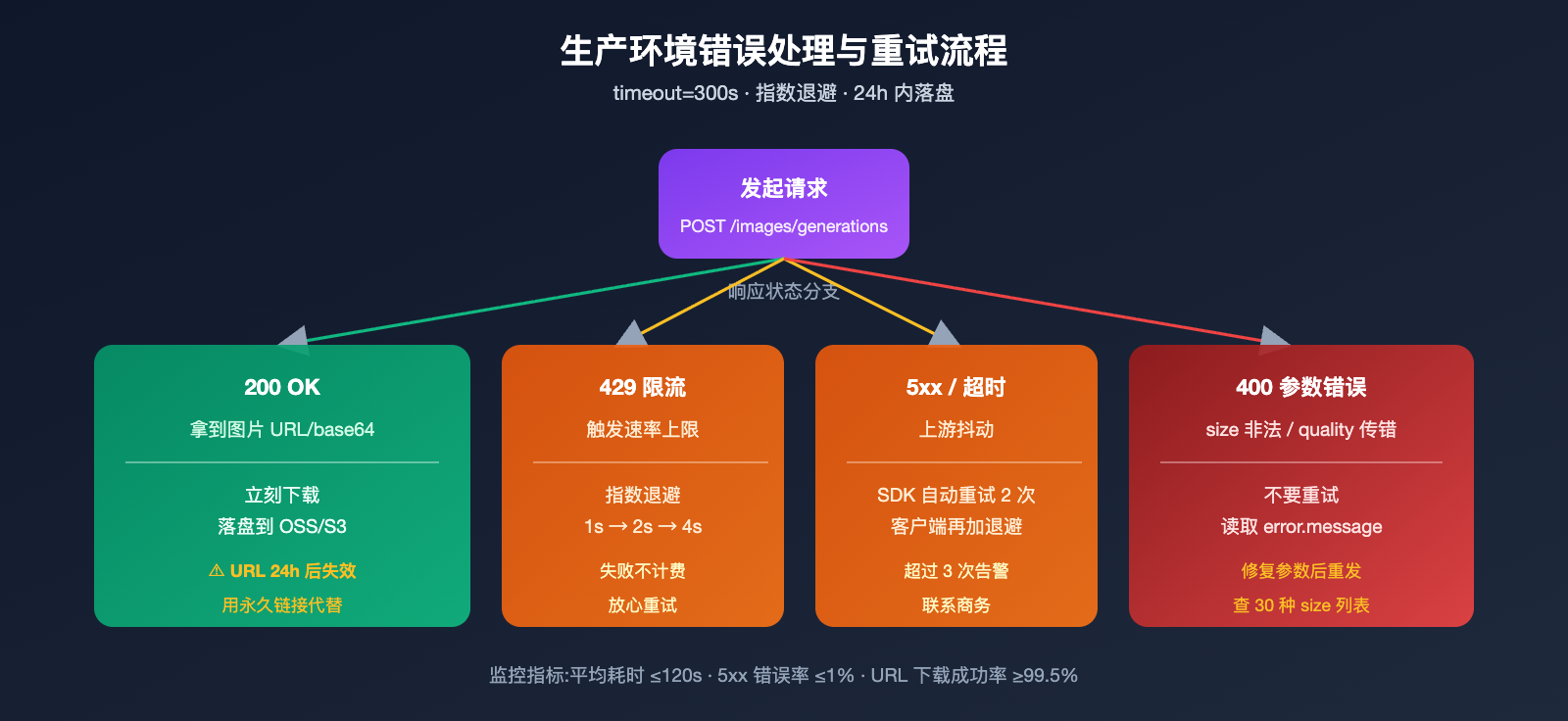
gpt-image-2-vip 的速率比官方高,但出图时长长:官方推理大约 30-60 秒,vip 通道因为多了一层中转和重试,通常 90-150 秒。生产代码必须按这个时长配置,否则会大面积超时失败。
实践一:超时时间设置为 300 秒
OpenAI SDK 默认超时 60 秒,这对 gpt-image-2-vip 远远不够。建议把 timeout=300 显式传给 client。极少数复杂提示词会接近 200 秒,留 300 秒余量更保险。
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=300,
max_retries=2
)
实践二:对 5xx 错误做指数退避
虽然中转层已经做了一道重试,但客户端再加一层指数退避(1s → 2s → 4s)能进一步提升成功率。失败请求不计费,这一点让重试零成本。
实践三:返回 URL 24 小时内下载落盘
gpt-image-2-vip 返回的图片 URL 有效期约 24 小时,过期会 404。所以拿到 URL 后立刻下载到自己的 OSS/S3,不要直接把这个 URL 塞进数据库长期引用。批量任务建议在生成 5 分钟内完成下载。
实践四:输入图压缩到 1.5MB 以内
/v1/images/edits 接口的输入图按高保真度处理,input token 直接与图片像素数挂钩。一张 4K 参考图和一张 1024px 参考图的 token 消耗可能差 4 倍。在客户端先 resize 到 1024-2048 长边再上传,既省钱又能加快推理。
实践五:并发不要单条阻塞,用异步队列
由于单次出图 90-150 秒,绝对不能用同步循环串行调用,否则 100 张图就要跑两到三小时。推荐做法是把生图请求扔进异步任务队列(Celery/asyncio),业务线程立刻返回任务 ID,前端通过轮询或 WebSocket 拿最终结果。这样能把 60 RPM 的吞吐利用满,真正发挥 vip 通道的高并发优势。
三个实战接入场景
理论讲完看一下真实业务怎么把 gpt-image-2-vip 用起来。下面三个场景是客服群里被问得最多的,代码框架都很短。
场景一:电商商品主图批量生成
输入:一张白底产品图 + 一段中文文案。输出:30 张不同风格的主图。流程是用一个固定 prompt 模板,只替换"风格"占位符,batch 跑 30 次 /v1/images/edits,每张图 size 锁定 2048x2048(电商主图标准尺寸)。30 张图成本 $0.9,总耗时约 2 分钟(60 RPM 并发)。
场景二:多语言海报本地化
输入:一张英文海报底图 + 目标语言文案。输出:中文、日文、韩文三个版本的海报。利用 gpt-image-2-vip 的多语言文字渲染能力,prompt 直接写"把标题改成『新品上市』,字体使用思源黑体,保持原版式不变",一次调用就能拿到本地化版本,不需要 PSD 编辑。
场景三:PPT 内页插图流水线
输入:LLM 生成的章节描述。输出:每页一张插图。这是抖音上"一键 PPT"工具的核心环节,把所有插图统一用 1820x1024(16:9 PPT 标准比例),quality 由 vip 通道默认锁高,单页成本 $0.03,20 页 PPT 总插图成本仅 $0.6,加上 LLM 文案不到 $1 就能产出一份完整 PPT。
这三个场景共同的工程结构是:外层用任务队列调度,内层调 gpt-image-2-vip,出图后立刻落盘到 OSS,前端展示用 OSS 的永久链接,不直接使用模型返回的 24 小时临时 URL。
常见错误与排查
下面这张表覆盖了客服群里被问到最多的报错类型,直接对照排查就能解决 90% 的接入问题。
| 错误现象 | 根因 | 解决方法 |
|---|---|---|
| 408 / 504 超时 | timeout 设置太短 | 把 timeout 调到 300 秒 |
| 400 invalid size | size 不在 30 种里 | 改用文档列出的标准 size |
| 400 unsupported_parameter | 传了 quality 或 n>1 |
vip 通道不支持,删掉这两个字段 |
| 图片 URL 404 | URL 已过期 24 小时 | 改成生成后立刻下载到自己存储 |
| 中文渲染成乱码或方框 | prompt 用了非常生僻字 | 改用常见字符,或在 prompt 里描述"使用思源黑体" |
| input_tokens 超预期 | 参考图太大 | 客户端压缩到 1.5MB 以内 |
常见问题 FAQ
Q1: gpt-image-2-vip 的图片质量和官方有差异吗?
底层模型完全相同,都是 gpt-image-2-2026-04-21 快照。差异只在调度链路:官方走 API 配额池,vip 走 Codex 配额池。出图视觉质量没有差别,大批量盲测无法分辨。
Q2: 为什么不支持 quality 参数?
Codex CLI 内置调用走的是固定 quality=high 策略,vip 通道复用这条链路,所以没法暴露 quality 选项给上层。如果业务确实需要 low/medium 档降本,改用 gpt-image-2-all。
Q3: 失败请求真的不扣费吗?
是的,API易 apiyi.com 的计费策略是"按成功响应计费"。返回 4xx 参数错误、5xx 服务错误、超时,统统不计入消耗。这一点在账单里可以逐条核对。
Q4: 能不能在国内服务器直接调用?
可以。api.apiyi.com 域名走国内合规链路,不需要科学上网。这也是很多团队选择中转的核心原因之一。
Q5: vip 通道的 RPM 上限是多少?
没有公开的硬上限,实际取决于账号池水位。一般业务实测可稳定到 60-120 RPM,远高于官方 Tier 1 的 5 RPM。需要更高并发请联系商务开白。
Q6: 单次只返回一张图,批量怎么办?
外层并发循环调用即可,Python 的 asyncio.gather 或 concurrent.futures.ThreadPoolExecutor 都能轻松跑到 60 RPM。因为 vip 通道是异步推理,并发提交不会被 CPU 限制,瓶颈只在中转层 RPM。
Q7: 同一 prompt 多次调用结果会一样吗?
不会完全相同。gpt-image-2-vip 走 Codex 内置策略,未暴露 seed 参数,所以每次出图都有随机性。如果业务需要可复现结果,可以把 prompt 写得非常具体(比如固定颜色码、固定构图描述),或者把第一次满意的图作为参考图传入 /v1/images/edits 端点做微调。
Q8: 如何监控生产环境的稳定性?
建议在客户端埋点统计三个指标:平均出图耗时、5xx 错误率、URL 下载成功率。正常水位下平均耗时应在 120 秒内,5xx 错误率 <1%,URL 下载成功率 >99.5%。任意一项异常都说明账号池水位偏低,需要联系商务侧调度资源。
总结
gpt-image-2-vip 是基于 codex 官逆通道做的图像生成商业化产品,5 个核心特性把官方直连的痛点逐一解决:30 种尺寸 + $0.03 统一计费 + 三端点兼容 + 中文原生 + 失败不计费。对于做内容生产、电商物料、PPT 自动化、海报批量生成的团队,这是目前性价比最好的 gpt-image-2 接入方案之一。
接入只需要切 base_url 和 model 两处,SDK 代码完全复用 OpenAI 官方写法。生产环境建议把 timeout 设到 300 秒、对 5xx 做指数退避、图片 URL 24 小时内落盘,踩过这三个坑就能稳定跑量。如果你正在评估 gpt-image-2 的生产接入方案,可以直接到 API易 apiyi.com 创建账号,先用 vip 通道跑几轮真实业务数据再做决策。
关于作者: APIYI 团队专注多模型聚合接入和高并发推理基础设施,日常处理大量图像生成 API 接入咨询。本文基于真实生产数据整理,如需了解 gpt-image-2-vip 详细参数,可访问 docs.apiyi.com。