
作者注:详解 Claude Code Prompt 缓存的 TTL 机制、5 分钟和 1 小时两档区别、Anthropic API 与 AWS Bedrock 缓存计费对比,附省钱配置建议
「Claude Code 的 Prompt 缓存 TTL 能改吗?5 分钟和 1 小时有什么区别?到底用哪个更划算?」——这是许多 Claude Code 用户在控制成本时最常问的问题。
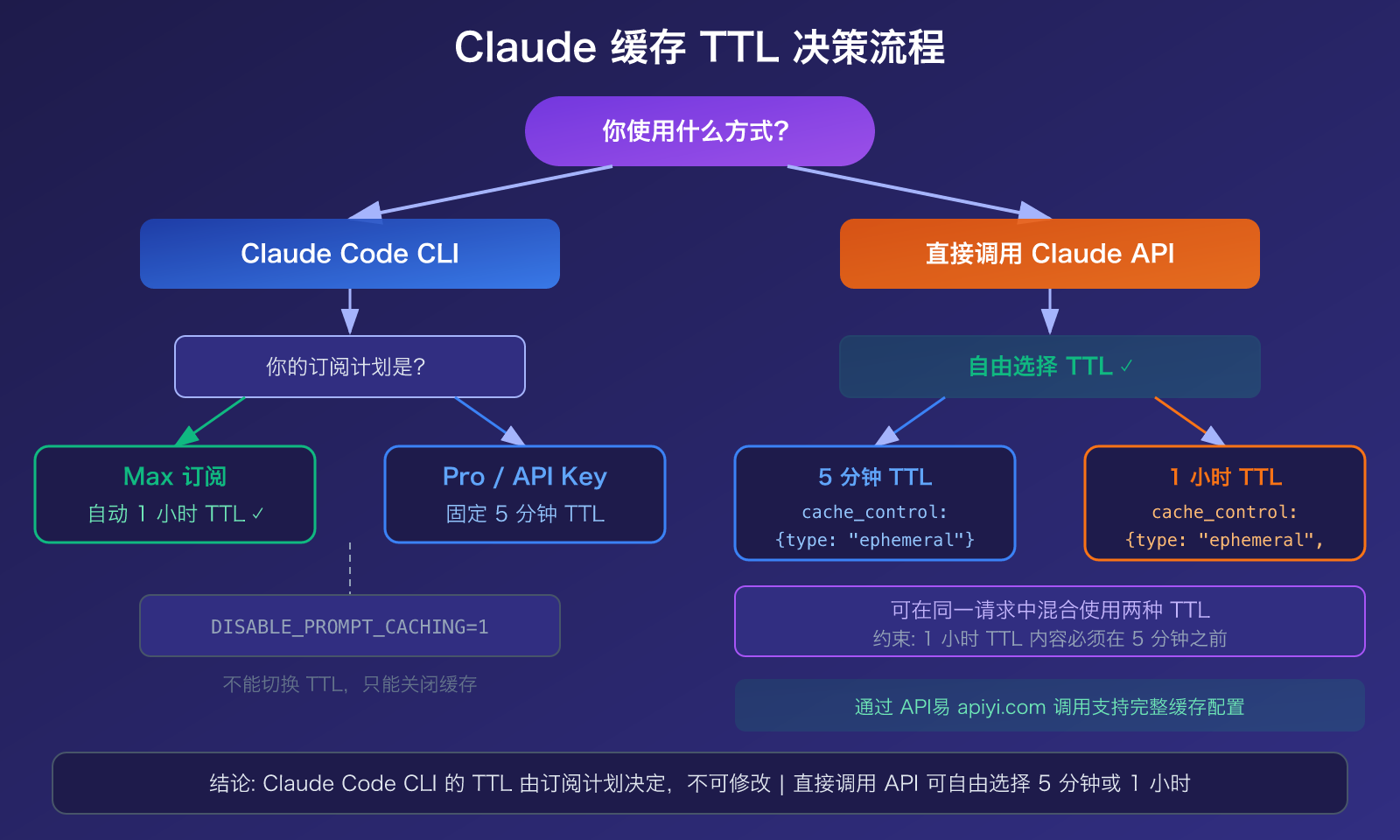
先说结论:Claude Code 的缓存 TTL 目前不能由用户直接修改——它由你的订阅计划决定。Max 订阅用户自动获得 1 小时 TTL,Pro 订阅和 API Key 用户默认 5 分钟 TTL。但如果你直接调用 Claude API,则可以通过 cache_control 参数自由选择 5 分钟或 1 小时。
核心价值: 读完本文,你将彻底搞懂 Claude Prompt 缓存的 TTL 机制,清楚 Anthropic 官方 API 和 AWS Bedrock 的缓存计费差异,学会根据使用场景选择最省钱的缓存策略。

Claude Prompt 缓存 TTL 核心要点
Prompt 缓存是 Claude 系列模型最重要的省钱机制之一。它将你之前发送过的 Prompt 前缀(系统提示、工具定义、对话历史等)存储在服务端,下次请求如果前缀相同,就直接从缓存读取,只需支付正常输入价格的 10%。
| 要点 | 说明 | 实际影响 |
|---|---|---|
| 两档 TTL | 5 分钟(默认)和 1 小时(可选) | 选对 TTL 可节省大量写入成本 |
| 缓存读取只需 10% | 命中缓存后,该部分输入只收 0.1 倍价格 | 长对话场景可省 80-90% 输入费用 |
| 5 分钟写入 = 1.25 倍 | 写入缓存时额外付 25% 溢价 | 一次缓存读取即可回本 |
| 1 小时写入 = 2 倍 | 写入缓存时付双倍价格 | 需要两次缓存读取才能回本 |
| Claude Code 缓存自动管理 | 系统提示、工具定义、CLAUDE.md 自动缓存 | 用户无需手动配置 |
Claude Code 中的 TTL 能不能改?
这是用户最关心的问题。答案分两种情况:
Claude Code(交互式 CLI 工具):不能手动修改。 Claude Code 的缓存由服务端控制——Max 订阅用户获得 1 小时 TTL(通过服务端 feature flag tengu_prompt_cache_1h_config 控制),Pro 订阅和 API Key 用户获得 5 分钟 TTL。你只能通过环境变量 DISABLE_PROMPT_CACHING=1 完全关闭缓存,但不能切换 TTL 档位。
Claude API(直接调用):可以自由选择。 通过 API 调用时,你可以在 cache_control 参数中指定 TTL:
// 5 分钟缓存(默认)
{ "cache_control": { "type": "ephemeral" } }
// 1 小时缓存
{ "cache_control": { "type": "ephemeral", "ttl": "1h" } }
🎯 选择建议: 如果你主要通过 Claude Code CLI 使用,TTL 取决于订阅计划。如果你通过 API 调用(如通过 API易 apiyi.com),则可以根据场景灵活选择 5 分钟或 1 小时 TTL,实现更精细的成本控制。
Claude Prompt 缓存 TTL 的计费规则详解
5 分钟 vs 1 小时:计费对比
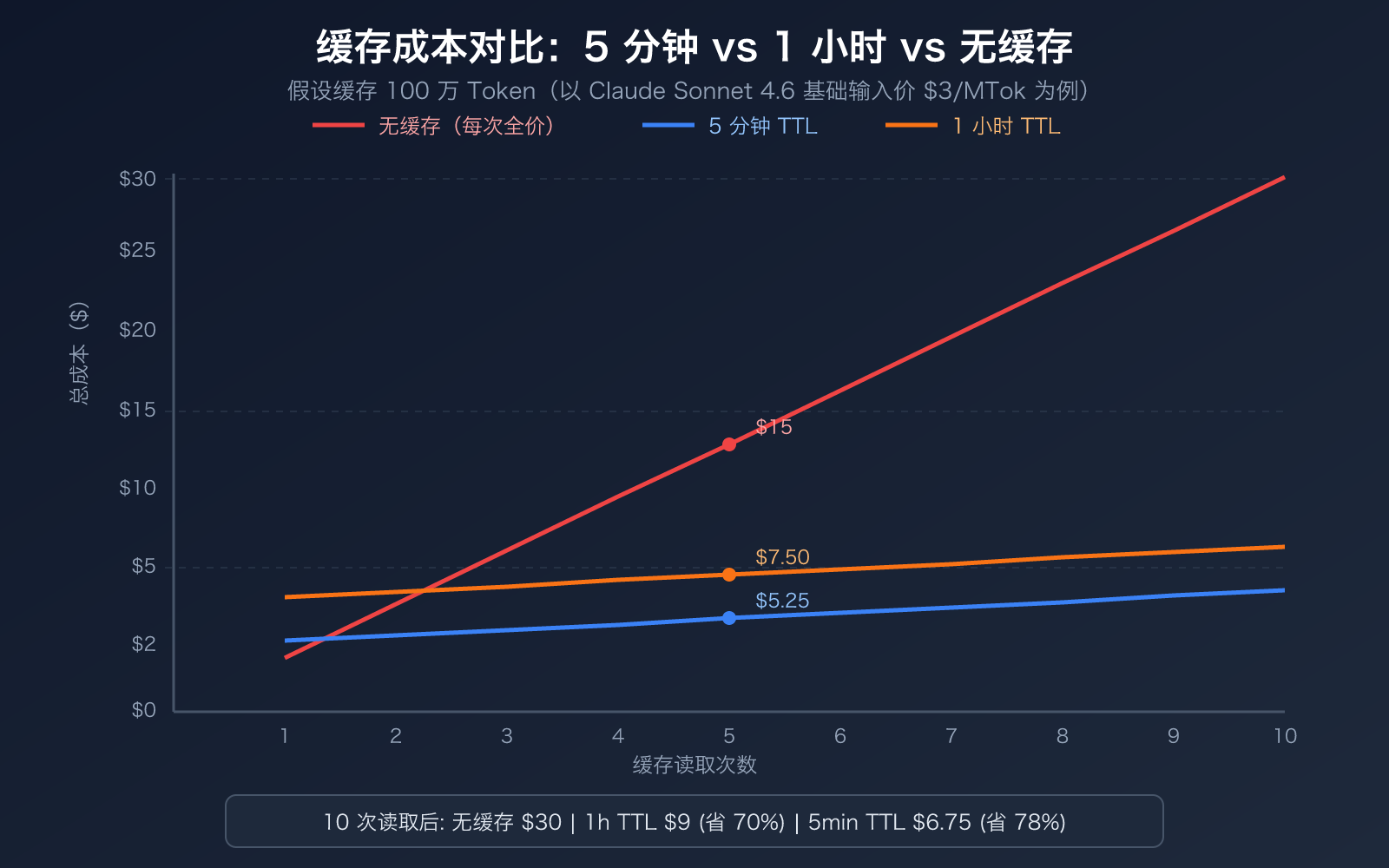
两种 TTL 的核心差异在于写入成本。读取成本完全一样,都是基础输入价格的 0.1 倍:
| 操作 | 5 分钟 TTL | 1 小时 TTL | 说明 |
|---|---|---|---|
| 缓存写入 | 1.25 倍基础价 | 2.0 倍基础价 | 首次写入缓存时的溢价 |
| 缓存读取 | 0.1 倍基础价 | 0.1 倍基础价 | 命中缓存后的折扣价(相同) |
| 回本次数 | 1 次读取即回本 | 2 次读取才回本 | 使用频率决定哪个更划算 |
| 自动续期 | 每次命中重置 5 分钟 | 固定 1 小时过期 | 高频对话下 5 分钟可一直不过期 |
各模型的 Prompt 缓存具体价格
以下是 Anthropic 官方 API 各模型的完整缓存计费表(2026 年 3 月):
| 模型 | 基础输入价 | 5 分钟写入 | 1 小时写入 | 缓存读取 | 输出价 |
|---|---|---|---|---|---|
| Claude Opus 4.6 | $5/MTok | $6.25/MTok | $10/MTok | $0.50/MTok | $25/MTok |
| Claude Sonnet 4.6 | $3/MTok | $3.75/MTok | $6/MTok | $0.30/MTok | $15/MTok |
| Claude Haiku 4.5 | $1/MTok | $1.25/MTok | $2/MTok | $0.10/MTok | $5/MTok |
关键发现:缓存读取的折扣惊人。 以 Claude Opus 4.6 为例:
- 正常输入 100 万 Token = $5.00
- 缓存读取 100 万 Token = $0.50(省了 $4.50,折扣 90%)
- 这就是为什么 Claude Code Pro 月费 $20 能做到经济可行——100 轮 Opus 对话不用缓存可能花 $50-100,用了缓存只需 $10-19
最低缓存 Token 数要求
不是所有内容都能被缓存。各模型有最低 Token 数要求,内容不够长则无法触发缓存:
| 模型 | 最低缓存 Token 数 |
|---|---|
| Claude Opus 4.6 / 4.5 | 4,096 |
| Claude Sonnet 4.6 | 2,048 |
| Claude Sonnet 4.5 / 4 | 1,024 |
| Claude Haiku 4.5 | 4,096 |
| Claude Haiku 3.5 / 3 | 2,048 |
🎯 实用提示: 如果你的系统提示词较短(如少于 2,048 Token),在使用 Claude Sonnet 4.6 时是不会触发缓存的。可以通过丰富系统提示内容或合并工具定义来达到最低阈值。通过 API易 apiyi.com 调用时同样支持缓存,且费率更优。
Anthropic API vs AWS Bedrock:缓存计费对比
三大平台缓存支持对比
Claude 的 Prompt 缓存在 Anthropic 官方 API、AWS Bedrock、Google Vertex AI 三个平台上都有支持,但细节存在差异:
| 对比维度 | Anthropic 官方 API | AWS Bedrock | Google Vertex AI |
|---|---|---|---|
| 5 分钟 TTL | ✅ 所有模型支持 | ✅ 所有模型支持 | ✅ 所有模型支持 |
| 1 小时 TTL | ✅ 所有模型支持 | ✅ 部分模型(Opus 4.5、Sonnet 4.5、Haiku 4.5) | ✅ 支持 |
| 写入溢价(5 分钟) | 1.25 倍 | ~1.25 倍 | 1.25 倍 |
| 写入溢价(1 小时) | 2.0 倍 | 2.0 倍 | 2.0 倍 |
| 读取折扣 | 0.1 倍 | ~0.1 倍 | 0.1 倍 |
| 最大断点数 | 4 个 | 4 个 | 4 个 |
| 自动缓存 | ✅ 支持 | ✅ 支持 | ✅ 支持 |
| TTL 自定义 | ✅ 可选 5 分钟/1 小时 | ✅ 可选(部分模型) | ✅ 可选 |
各平台的关键差异说明
Anthropic 官方 API: 缓存功能最完整,所有模型都支持 5 分钟和 1 小时两档 TTL。2026 年 2 月 5 日起,缓存隔离从组织级别改为工作区级别,同一组织的不同工作区缓存互相独立。
AWS Bedrock: 2026 年 1 月宣布支持 1 小时 TTL,但仅限 Claude Opus 4.5、Sonnet 4.5、Haiku 4.5 等部分模型。最新的 Claude Sonnet 4.6 和 Opus 4.6 在 Bedrock 上的 1 小时 TTL 支持需确认。如果你通过 Claude Code 连接 Bedrock,还需要注意 CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1 的兼容性设置。
Google Vertex AI: 缓存功能与官方 API 基本一致,但需要通过 Google Cloud 项目进行认证和计费。
🎯 平台选择建议: 如果你不想纠结平台差异和兼容性配置,通过 API易 apiyi.com 统一接口调用是最简单的方案——支持完整的缓存功能,无需分别配置 AWS IAM 或 Google Cloud 认证。
Claude Code Prompt 缓存快速上手
极简示例:设置 1 小时 TTL 缓存
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": "你是一个专业的物理教师助手,负责解答高中物理问题...(此处为长系统提示)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
}],
messages=[{"role": "user", "content": "解释牛顿第三定律"}]
)
print(f"缓存读取 Token: {response.usage.cache_read_input_tokens}")
print(f"缓存写入 Token: {response.usage.cache_creation_input_tokens}")
查看完整代码:混合使用 5 分钟和 1 小时 TTL
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 混合 TTL:系统提示用 1 小时(不常变),对话上下文用 5 分钟(频繁变化)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "你是一个专业的AI技术顾问...(长系统提示,2000+ Token)",
"cache_control": {"type": "ephemeral", "ttl": "1h"} # 系统提示用1小时
},
{
"type": "text",
"text": "以下是用户的历史对话上下文...(对话历史)",
"cache_control": {"type": "ephemeral"} # 对话上下文用5分钟(默认)
}
],
messages=[{"role": "user", "content": "对比 Claude 和 GPT 的推理能力"}]
)
# 查看缓存使用情况
usage = response.usage
print(f"普通输入 Token: {usage.input_tokens}")
print(f"缓存读取 Token: {usage.cache_read_input_tokens}")
print(f"缓存写入 Token: {usage.cache_creation_input_tokens}")
# 计算节省金额(以 Sonnet 4.6 为例)
base_cost = (usage.input_tokens / 1_000_000) * 3
cache_cost = (usage.cache_read_input_tokens / 1_000_000) * 0.3
saved = (usage.cache_read_input_tokens / 1_000_000) * 2.7
print(f"本次节省: ${saved:.4f}")
重要约束: 在同一个请求中混合使用两种 TTL 时,1 小时缓存的内容必须放在 5 分钟缓存内容之前,否则会返回错误。
建议: 通过 API易 apiyi.com 调用 Claude API 时完整支持
cache_control参数配置,包括 5 分钟和 1 小时 TTL 的自由选择。
5 分钟 vs 1 小时 TTL:该选哪个?
选择决策表
| 使用场景 | 推荐 TTL | 原因 |
|---|---|---|
| Claude Code 高频编程(每分钟发消息) | 5 分钟 | 每次命中自动重置计时器,一直不会过期 |
| 客服机器人(用户回复间隔 < 5 分钟) | 5 分钟 | 写入成本低(1.25 倍),高频命中 |
| 文档分析 Agent(处理间隔 5-60 分钟) | 1 小时 | 避免缓存过期导致重新写入 |
| 定时批处理任务(每 30 分钟一批) | 1 小时 | 5 分钟 TTL 肯定过期,1 小时刚好覆盖 |
| 低频 API 调用(间隔 > 1 小时) | 不缓存 | 两种 TTL 都会过期,写入成本浪费 |
| 系统提示词(几乎不变) | 1 小时 | 写入一次可重复读取多次 |
| 对话历史(每轮都变) | 5 分钟 | 频繁变化时,低写入成本更划算 |
成本计算公式
判断缓存是否划算,核心公式:
5 分钟 TTL 回本条件: 缓存内容在 5 分钟内至少被读取 1 次
- 写入成本:1.25 倍 → 额外 0.25 倍
- 读取节省:每次省 0.9 倍
- 1 次读取即回本(0.9 > 0.25)
1 小时 TTL 回本条件: 缓存内容在 1 小时内至少被读取 2 次
- 写入成本:2.0 倍 → 额外 1.0 倍
- 读取节省:每次省 0.9 倍
- 2 次读取才回本(0.9 × 2 = 1.8 > 1.0)
常见问题
Q1: Claude Code 中能把 5 分钟 TTL 改成 1 小时吗?
Claude Code CLI 工具本身不支持用户手动修改 TTL。Max 订阅用户自动获得 1 小时 TTL(服务端 feature flag 控制),Pro 和 API Key 用户固定为 5 分钟 TTL。如果你需要 1 小时 TTL 但不想升级到 Max 订阅,可以直接通过 API 调用(设置 cache_control.ttl: "1h"),在 API易 apiyi.com 等平台上按量付费调用。
Q2: 5 分钟 TTL 是固定 5 分钟过期吗?还是会自动续期?
5 分钟 TTL 会在每次缓存命中时自动重置计时器。如果你每 1-2 分钟发一次消息(比如 Claude Code 编程对话),计时器一直被重置,缓存永远不会过期。只有当你连续 5 分钟不发消息时,缓存才会失效。所以对于高频使用场景,5 分钟 TTL 已经完全够用。
Q3: AWS Bedrock 上的缓存计费和 Anthropic 官方 API 一样吗?
大致相同但有细微差异:
- 写入溢价均为 ~1.25 倍(5 分钟)和 ~2.0 倍(1 小时)
- 读取折扣均为 ~0.1 倍
- 差异点:Bedrock 上的 1 小时 TTL 目前仅支持 Opus 4.5、Sonnet 4.5、Haiku 4.5 等部分模型,最新的 4.6 系列模型需确认
- 通过 API易 apiyi.com 调用可获得与官方 API 一致的完整缓存支持
总结
Claude Prompt 缓存 TTL 的核心要点:
- 两档 TTL 可选: 5 分钟(写入 1.25 倍,1 次读取回本)和 1 小时(写入 2 倍,2 次读取回本),读取均为 0.1 倍
- Claude Code CLI 不能改 TTL: Max 订阅自动 1 小时,Pro/API Key 固定 5 分钟,只能关闭不能切换
- Claude API 可自由选择: 通过
cache_control.ttl参数设置,同一请求可混合两种 TTL - 高频对话选 5 分钟: 每次命中自动续期,写入成本更低;间歇使用选 1 小时避免过期
缓存命中 = 输入费用打一折,是 Claude 最核心的省钱机制。推荐通过 API易 apiyi.com 统一接口调用,完整支持缓存配置,一个 Key 即可测试不同 TTL 策略的实际成本差异。
📚 参考资料
-
Anthropic 官方文档 – Prompt Caching: TTL 配置、计费规则、cache_control 语法的权威来源
- 链接:
platform.claude.com/docs/en/build-with-claude/prompt-caching - 说明: 5 分钟/1 小时 TTL 的完整计费公式和代码示例
- 链接:
-
Anthropic 官方文档 – 定价: 所有模型的基础价格和缓存价格
- 链接:
platform.claude.com/docs/en/about-claude/pricing - 说明: Opus/Sonnet/Haiku 各模型的缓存写入和读取费率
- 链接:
-
AWS 官方文档 – Bedrock Prompt Caching: Bedrock 平台的缓存支持详情
- 链接:
docs.aws.amazon.com/bedrock/latest/userguide/prompt-caching.html - 说明: Bedrock 上各模型的 TTL 支持范围和计费标准
- 链接:
-
Claude Code Camp – Prompt 缓存工作原理: 深度解析 Claude Code 的缓存实现
- 链接:
claudecodecamp.com/p/how-prompt-caching-actually-works-in-claude-code - 说明: 了解 Claude Code 如何自动管理缓存断点
- 链接:
-
GitHub Issue #19436 – 多层缓存 TTL 功能请求: 社区对更灵活 TTL 配置的讨论
- 链接:
github.com/anthropics/claude-code/issues/19436 - 说明: 社区提出的基于内容变化频率的多层 TTL 方案
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论 Claude 缓存配置经验,更多模型调用教程可访问 API易 docs.apiyi.com 文档中心