
Если вы только что начали внедрять gpt-image-2 в продакшн, то наверняка уже столкнулись с двумя главными проблемами: лимиты скорости (rate limits) и стабильность. Официальные лимиты OpenAI для прямого подключения к gpt-image-2 довольно жесткие: для аккаунтов Tier 1 это всего 5 запросов в минуту. Стоит запустить пакетную обработку, как тут же прилетает ошибка 429. А если случаются сбои 5xx, запросы начинают сыпаться один за другим. Поэтому многие команды переходят на «официальные обратные каналы» (reverse proxy) — они используют бэкенд gpt-image-2, встроенный в ChatGPT Pro/Codex CLI, что дает более высокие квоты RPM и стабильный канал связи.
Модель gpt-image-2-vip, доступная на APIYI (apiyi.com), как раз и работает через такой «обратный» канал Codex. В этой статье мы разберем 5 ключевых особенностей, 30 вариантов размеров, 3 совместимых эндпоинта и приведем примеры кода, чтобы вы могли сразу внедрить этот интерфейс в свои проекты.

Что такое «официальный реверс» Codex API: 3 ключевых отличия от прямого подключения
Многие разработчики, впервые услышав термин «официальный реверс Codex», ошибочно принимают его за нелегальный интерфейс. На самом деле речь идет о реверс-инжиниринге цепочки вызовов gpt-image-2, встроенной в Codex CLI и ChatGPT Pro от OpenAI. Когда в апреле 2026 года OpenAI выпустила gpt-image-2, она одновременно интегрировала её в Codex CLI (функция $imagegen) и клиент ChatGPT. Эти две точки входа используют общий пул лимитов, который отличается от политики ограничения скорости (rate limit) публичного API.
Суть «официального реверса» Codex заключается в следующем: поток данных внутри Codex выставляется как REST API. Это позволяет вам использовать gpt-image-2 так же, как обычный API OpenAI, но фактически запросы проходят через бэкенд ChatGPT. Модель gpt-image-2-vip — это именно такая реализация. У неё есть 3 принципиальных отличия от прямого официального подключения.
| Параметр | Официальное подключение OpenAI | Канал «официального реверса» (gpt-image-2-vip) |
|---|---|---|
| Лимиты скорости | Tier 1: 5 RPM, требуется пополнение для разблокировки | Использует общий пул Codex, значительно выше Tier 1 |
| Модель тарификации | Оплата по размеру/качеству изображения | Единая цена $0.03 за шт., 30 размеров по одной цене |
| Стабильность | Прямая зависимость от колебаний 5xx у OpenAI | Пул из нескольких аккаунтов + автоповтор, сглаживание ошибок |
Параметр quality |
Поддерживает low/medium/high/auto | Не поддерживается (использует встроенную стратегию Codex) |
Пакетный параметр n |
Поддерживает 1-4 изображения | Не поддерживается, возврат по 1 изображению |
| Срок действия URL | 60 минут | ~24 часа |
🎯 Главное: «Официальный реверс» — это не «взлом». Это предоставление доступа к внутренней цепочке вызовов собственного продукта OpenAI (Codex CLI) через REST API. APIYI (apiyi.com) превращает этот канал в коммерческий продукт. Его главная ценность не в обходе OpenAI, а в предоставлении пользователям API более стабильных лимитов скорости, доступных в Codex.
5 ключевых особенностей gpt-image-2-vip
Разобравшись с различиями каналов, перейдем к конкретным характеристикам. Ниже приведены 5 пунктов, которые отличают gpt-image-2-vip от моделей серии gpt-image-2-all и официальной gpt-image-2. Это важные детали, которые часто упускаются из виду в документации.
Особенность 1: Свободный выбор из 30 размеров и единая цена $0.03
Главная инженерная ценность gpt-image-2-vip заключается в том, что «размер» стал параметром первого класса. Модель поддерживает 10 соотношений сторон × 3 уровня разрешения = 30 фиксированных размеров. Их можно просто указать в параметре size, не тратя время на подбор промпта. Тарификация максимально прозрачна: все 30 размеров стоят одинаково — $0.03 за изображение. Больше нет скрытых переплат за «большой размер». Для команд, занимающихся шаблонной генерацией или созданием превью в больших объемах, это дает отличную предсказуемость затрат.
| Уровень разрешения | Короткая сторона (пикс.) | Длинная сторона (пикс., макс.) | Сценарии использования |
|---|---|---|---|
| 1K | ~1024 | ~1820 | Превью, обложки лент, соцсети |
| 2K | ~2048 | ~3640 | Плакаты, главные фото товаров, карточки контента |
| 4K | ~2880 | ~3840 | Печать высокого качества, видеоматериалы |
10 вариантов соотношений сторон покрывают все основные форматы: 1:1, 16:9, 9:16, 4:3, 3:2, 21:9 и другие, что избавляет от необходимости постобработки. Еще одно скрытое преимущество единой цены — возможность менять разрешение в конвейере генерации в зависимости от задач бизнеса без влияния на бюджет. Например, при A/B-тестировании можно сгенерировать один и тот же промпт в 1K и 4K для сравнения: затраты будут полностью предсказуемы.
Особенность 2: Полная совместимость с тремя эндпоинтами
gpt-image-2-vip поддерживает три стандартных эндпоинта OpenAI: /v1/images/generations (текст-в-изображение), /v1/images/edits (изображение-в-изображение и редактирование) и /v1/chat/completions (генерация изображений через чат). Это критически важно, так как вам не нужно переписывать существующий код SDK. Достаточно сменить model на gpt-image-2-vip и переключить base_url на наш сервис-прокси API.
Особенность 3: Слияние изображений и изображение-в-изображение
Через эндпоинт /v1/images/edits можно загрузить от 1 до N изображений и, добавив промпт, выполнить перенос стиля, объединение контента или изменение макета. Например, можно объединить «фото товара + фото модели + фон» в одно изображение для карточки товара. Рекомендуется сжимать каждое изображение до 1.5 МБ, иначе расход входных токенов значительно возрастет.
Особенность 4: Нативная поддержка китайского языка
gpt-image-2-vip использует тот же бэкенд вывода, что и официальная gpt-image-2, унаследовав способность рендеринга текста на китайском, японском, корейском, хинди и бенгальском языках. Китайские промпты не нужно переводить на английский: заголовки и кнопки на плакатах будут отображаться корректно, чего не могут предложить Midjourney или Stable Diffusion.
Особенность 5: Неудачные запросы не тарифицируются
Это важная деталь для масштабного производства. Любые запросы, вернувшие ошибку 5xx, тайм-аут или заблокированные политикой безопасности, не оплачиваются. Списываются средства только за успешную генерацию. Это позволяет спокойно настраивать повторные попытки (exponential backoff), не опасаясь, что они «съедят» бюджет. В сочетании с фиксированной ценой в $0.03, прогнозирование затрат становится элементарным: если нужно 10 000 изображений, бюджет составит около $300. Не нужно строить сложные модели затрат — финансовый отдел и продакт-менеджеры могут легко принять решение.
Процесс вызова и пример кода: начнем с 5 строк на Python
Логика подключения максимально проста: она полностью совместима с официальным SDK OpenAI, нужно лишь изменить base_url и model. Ниже приведен минимально рабочий пример генерации изображения, где base_url указывает на единый сервис-прокси API от APIYI (apiyi.com).
from openai import OpenAI
import base64
# Инициализация клиента с параметрами APIYI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Вызов модели для генерации изображения
resp = client.images.generate(
model="gpt-image-2-vip",
prompt="Визуализация для технологичной презентации, в центре неоновый заголовок 『APIYI · gpt-image-2 запущен』, в левом нижнем углу мелкий текст 2026",
size="2048x1152"
)
# Декодирование и сохранение результата
img_b64 = resp.data[0].b64_json
with open("poster_2k.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Если вам нужно выполнить задачу «изображение-в-изображение» или объединение нескольких изображений, просто замените client.images.generate на client.images.edit и добавьте image=[open("a.png","rb"), open("b.png","rb")]. Форматы тел запросов для всех трех эндпоинтов соответствуют официальной спецификации OpenAI.
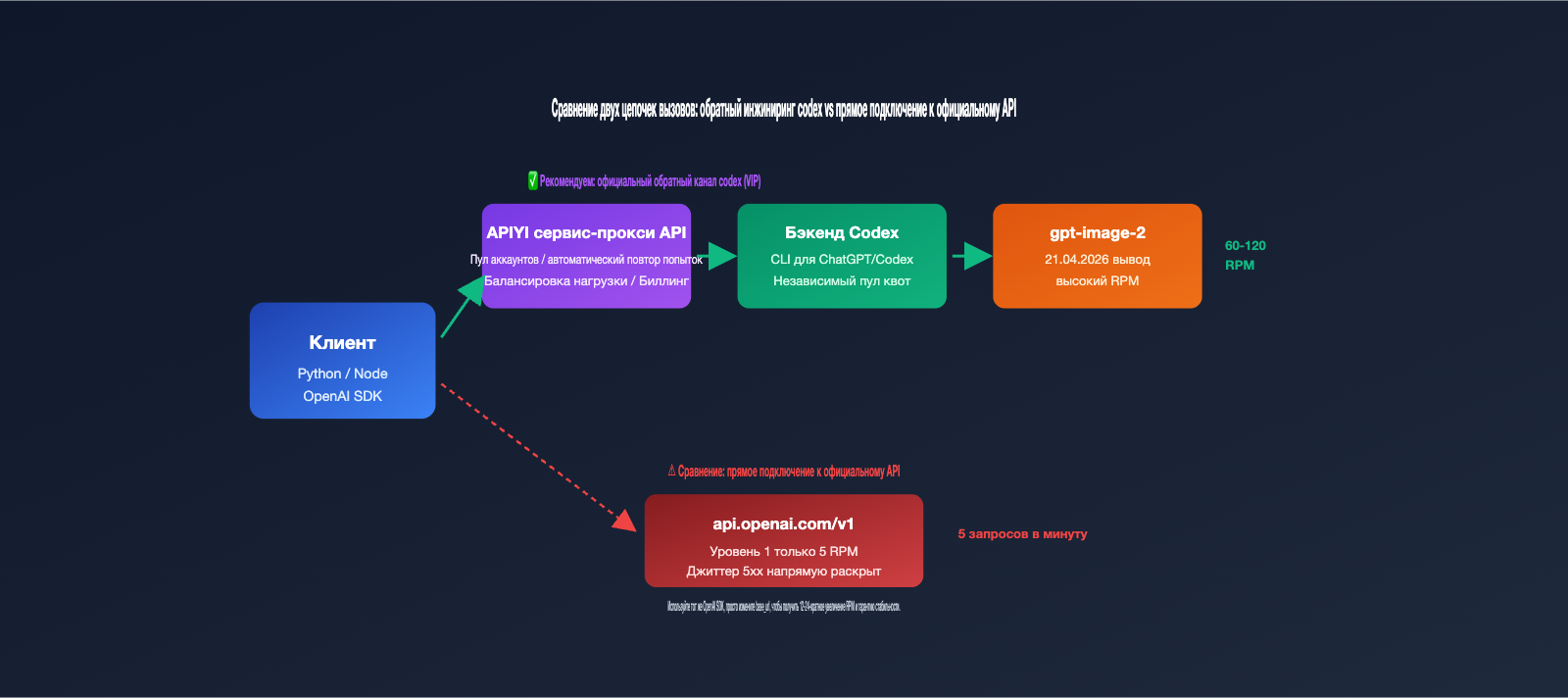
🎯 Совет по быстрому старту: Чтобы запустить этот процесс за 30 секунд, рекомендуем сначала создать API-ключ на APIYI (apiyi.com), а затем сгенерировать тестовое изображение с помощью
gpt-image-2-vipи любого размера. Ошибочные запросы не тарифицируются, поэтому можно смело экспериментировать с параметрами.
Как выбрать из 30 вариантов размера: шпаргалка по сценариям
Многие при виде 30 вариантов size первым делом задаются вопросом: «Что выбрать?». Мы классифицировали их по бизнес-сценариям. Важно понимать: цена не зависит от размера, поэтому выбирайте тот, который нужен для вашей задачи, не жертвуя качеством ради экономии.
| Бизнес-сценарий | Рекомендуемое соотношение | Рекомендуемое разрешение | Типичный size |
|---|---|---|---|
| Обложка статьи / Превью | 16:9 / 3:2 | 2K | 2048×1152 |
| Вертикальный контент (TikTok/Reels) | 9:16 / 4:5 | 2K | 1152×2048 |
| Карточка товара / Детализация | 1:1 | 2K или 4K | 2048×2048 или 2880×2880 |
| Hero-изображение для сайта | 21:9 / 16:9 | 4K | 3840×1640 или 3840×2160 |
| Иллюстрация для презентации | 16:9 | 1K или 2K | 1820×1024 |
| Печатная продукция / Плакаты | 3:4 / 2:3 | 4K | 2880×3840 |
| Миниатюры в ленте | 1:1 | 1K | 1024×1024 |
| Баннер (горизонтальный) | 21:9 | 1K | 1820×780 |
🎯 Совет по выбору размера: Для продакшена мы рекомендуем в первую очередь использовать формат 2K — размер одного изображения составляет около 1-3 МБ, что обеспечивает идеальный баланс между скоростью загрузки и визуальным качеством. Формат 4K стоит использовать только для печати или демонстрации на больших экранах, а 1K оставьте для миниатюр и других малоформатных задач.
Сравнение трех каналов серии gpt-image-2: vip / all / официальный
На платформе APIYI (apiyi.com) доступны три модели, связанные с gpt-image-2. Легко ошибиться при выборе, поэтому давайте разберем их различия, чтобы вам не пришлось переделывать интеграцию после запуска.
gpt-image-2 (официальное прямое подключение) работает через публичный API OpenAI, поддерживает параметры quality и n, но вам придется самостоятельно обрабатывать низкий лимит скорости в 5 RPM. gpt-image-2-all — это агрегированный канал, он поддерживает все параметры, но размер изображения регулируется промптом, что не всегда дает точный результат. gpt-image-2-vip — главный герой этой статьи, работает через обратный инжиниринг Codex. Его сильные стороны: точная фиксация size, единая тарификация и высокий RPM.
| ID модели | Тип канала | Скорость | Контроль размера | Параметр quality | Кол-во за раз | Рекомендуемый сценарий |
|---|---|---|---|---|---|---|
gpt-image-2 |
Официальный | Лимит Tier | Точный size | ✅ | 1-4 | Чувствительность к качеству, редкие вызовы |
gpt-image-2-all |
Агрегированный | Средняя | Через промпт | ✅ | 1-4 | Миграция старого кода, нужен параметр quality |
gpt-image-2-vip |
Codex (обратный инж.) | Высокий RPM | Точный size | ❌ | 1 | Массовое производство, фиксированный размер, стабильность |

Краткий итог: если вам нужна стабильность для больших объемов, фиксированный размер и предсказуемая тарификация — выбирайте gpt-image-2-vip. Если вы обязаны использовать quality=high для высокой точности, выбирайте gpt-image-2-all. Только в случае редких вызовов и необходимости полного набора параметров стоит рассматривать gpt-image-2.
Рекомендации по обеспечению стабильности: тайм-ауты, повторные попытки и время жизни URL
Модель gpt-image-2-vip работает быстрее официальной, но время генерации изображения выше: если стандартный вывод занимает 30–60 секунд, то VIP-канал из-за дополнительного уровня проксирования и механизмов повторных попыток обычно требует 90–150 секунд. Ваш производственный код должен быть настроен с учетом этих временных рамок, иначе вы столкнетесь с массовыми ошибками по тайм-ауту.
Практика №1: Установка тайм-аута на 300 секунд
По умолчанию OpenAI SDK устанавливает тайм-аут 60 секунд, чего для gpt-image-2-vip явно недостаточно. Рекомендуется явно передавать timeout=300 при инициализации клиента. В редких случаях сложные промпты могут обрабатываться до 200 секунд, поэтому запас в 300 секунд будет надежным решением.
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=300,
max_retries=2
)
Практика №2: Экспоненциальная задержка для ошибок 5xx
Хотя на уровне прокси-сервиса уже реализованы повторные попытки, добавление еще одного слоя экспоненциальной задержки (1с → 2с → 4с) на стороне клиента дополнительно повысит процент успешных вызовов. Неудачные запросы не тарифицируются, поэтому повторные попытки для вас бесплатны.
Практика №3: Загрузка изображения в течение 24 часов
URL-адреса изображений, возвращаемые gpt-image-2-vip, действительны около 24 часов, после чего они становятся недоступны (ошибка 404). Поэтому, получив ссылку, немедленно скачайте изображение в свое хранилище (OSS/S3). Не стоит сохранять этот URL в базу данных для долгосрочного использования. Для пакетных задач рекомендуется завершать загрузку в течение 5 минут после генерации.
Практика №4: Сжатие входных изображений до 1.5 МБ
Входные изображения для интерфейса /v1/images/edits обрабатываются с высокой точностью, а расход токенов напрямую зависит от количества пикселей. Разница в потреблении токенов между 4K-изображением и 1024px может достигать 4 раз. Предварительно измените размер изображения на стороне клиента (длинная сторона 1024–2048 пикселей) перед загрузкой — это сэкономит деньги и ускорит генерацию.
Практика №5: Используйте асинхронные очереди вместо блокировки потоков
Поскольку генерация одного изображения занимает 90–150 секунд, категорически нельзя использовать синхронные циклы. В противном случае обработка 100 изображений растянется на 2–3 часа. Рекомендуемый подход — отправлять запросы на генерацию в очередь асинхронных задач (Celery/asyncio). Бизнес-логика должна сразу возвращать ID задачи, а фронтенд — получать результат через опрос (polling) или WebSocket. Это позволит полностью задействовать пропускную способность 60 RPM и раскрыть преимущества VIP-канала.
Три сценария практического применения
Разобрав теорию, давайте посмотрим, как эффективно использовать gpt-image-2-vip в реальных бизнес-задачах. Эти три сценария чаще всего обсуждаются в нашем сообществе, и для них требуются довольно лаконичные реализации.
Сценарий №1: Пакетная генерация изображений товаров для e-commerce
Вход: изображение товара на белом фоне + рекламный текст. Выход: 30 изображений в разных стилях. Процесс использует фиксированный шаблон промпта с подстановкой переменной «стиль». Запускается пакет из 30 вызовов /v1/images/edits, размер каждой картинки фиксируется на 2048x2048 (стандарт для e-commerce). Стоимость 30 изображений составляет $0.9, общее время — около 2 минут (при параллелизме 60 RPM).
Сценарий №2: Локализация многоязычных постеров
Вход: исходный постер на английском + текст на целевом языке. Выход: версии постера на китайском, японском и корейском языках. Используя возможности gpt-image-2-vip по рендерингу текста, промпт можно сформулировать так: «Измени заголовок на "新品上市" (Новинка), используй шрифт Source Han Sans, сохрани исходную верстку». Один вызов позволяет получить локализованную версию без необходимости правки в PSD.
Сценарий №3: Конвейер иллюстраций для презентаций (PPT)
Вход: описание слайдов, сгенерированное LLM. Выход: по одной иллюстрации на страницу. Это ключевой этап для инструментов «PPT в один клик». Все иллюстрации приводятся к формату 1820x1024 (стандарт 16:9), качество по умолчанию установлено на высокий уровень через VIP-канал. Стоимость одной страницы — $0.03, общие затраты на 20 слайдов — всего $0.6. С учетом стоимости LLM, создание полноценной презентации обойдется менее чем в $1.
Общая архитектура для этих сценариев выглядит так: внешний планировщик задач, вызов gpt-image-2-vip внутри, немедленное сохранение результата в OSS. Для отображения на фронтенде используйте постоянные ссылки из вашего OSS, а не временные URL, возвращаемые моделью.
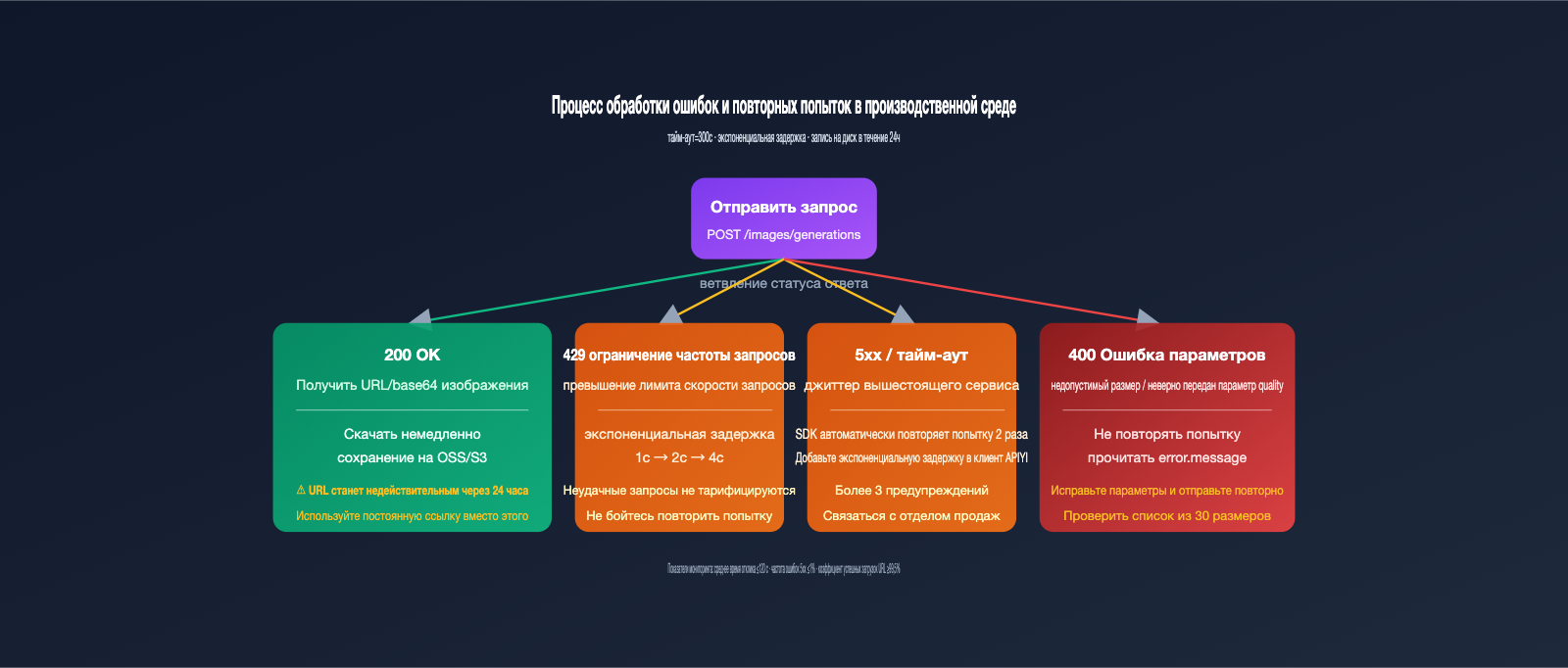
Распространенные ошибки и их устранение
В таблице ниже собраны самые частые ошибки, с которыми пользователи обращаются в службу поддержки. Сверка с этим списком поможет решить 90% проблем при интеграции.
| Ошибка | Причина | Решение |
|---|---|---|
| 408 / 504 Timeout | Слишком короткий таймаут | Увеличьте таймаут до 300 секунд |
| 400 invalid size | Размер не входит в список из 30 допустимых | Используйте стандартные размеры из документации |
| 400 unsupported_parameter | Переданы quality или n>1 |
VIP-канал их не поддерживает, удалите эти поля |
| 404 для URL изображения | Ссылка просрочена (более 24 часов) | Скачивайте изображение в свое хранилище сразу после генерации |
| Иероглифы отображаются как «кракозябры» или квадраты | В промпте используются редкие символы | Используйте более распространенные символы или добавьте в промпт указание «использовать шрифт Source Han Sans» |
| input_tokens выше ожидаемого | Слишком большой размер эталонного изображения | Сожмите изображение на стороне клиента до 1.5 МБ |
Часто задаваемые вопросы (FAQ)
Q1: Есть ли разница в качестве изображений между gpt-image-2-vip и официальным API?
Базовая модель идентична — это снапшот gpt-image-2-2026-04-21. Разница заключается только в маршрутизации: официальный API использует пул квот API, а VIP-канал — пул квот Codex. Визуальное качество идентично, при слепом тестировании разницу заметить невозможно.
Q2: Почему не поддерживается параметр quality?
Внутренний вызов Codex CLI использует фиксированную стратегию quality=high. VIP-канал использует этот же путь, поэтому мы не можем вывести опцию quality на верхний уровень. Если для оптимизации затрат вам действительно нужны уровни low/medium, используйте gpt-image-2-all.
Q3: Действительно ли за неудачные запросы не списываются средства?
Да, политика тарификации APIYI (apiyi.com) — «оплата за успешный ответ». Ошибки 4xx (ошибки параметров), 5xx (ошибки сервера) и таймауты не учитываются в расходе. Вы можете сверить это по каждой строке в биллинге.
Q4: Можно ли вызывать API напрямую с российских серверов?
Да. Домен api.apiyi.com работает через внутренние каналы, VPN не требуется. Это одна из главных причин, почему многие команды выбирают наш сервис-прокси API.
Q5: Какой лимит RPM у VIP-канала?
Жесткого публичного лимита нет, все зависит от текущей нагрузки на пул аккаунтов. Обычно бизнес-задачи стабильно работают на 60–120 RPM, что значительно выше, чем 5 RPM на официальном уровне Tier 1. Если вам нужна более высокая параллельность, свяжитесь с отделом продаж для расширения лимитов.
Q6: API возвращает только одно изображение за раз, как делать пакетную обработку?
Используйте параллельные вызовы на стороне клиента. Python-библиотеки asyncio.gather или concurrent.futures.ThreadPoolExecutor легко справляются с нагрузкой в 60 RPM. Поскольку VIP-канал выполняет инференс асинхронно, параллельная отправка не ограничена CPU, узким местом является только RPM сервиса-прокси.
Q7: Будут ли результаты одинаковыми при использовании одного и того же промпта?
Нет, не будут. gpt-image-2-vip использует встроенную стратегию Codex и не поддерживает параметр seed, поэтому каждое изображение будет уникальным. Если вам нужен воспроизводимый результат, сделайте промпт максимально конкретным (например, укажите точные коды цветов, описание композиции) или используйте полученное изображение в качестве эталонного изображения в эндпоинте /v1/images/edits для доработки.
Q8: Как мониторить стабильность в продакшене?
Рекомендуем отслеживать три метрики на стороне клиента: среднее время генерации, частоту ошибок 5xx и процент успешных скачиваний по URL. При нормальной нагрузке среднее время генерации должно составлять до 120 секунд, частота ошибок 5xx — менее 1%, а успешность скачивания URL — более 99.5%. Отклонение любого из этих показателей означает, что нагрузка на пул аккаунтов слишком высока и нужно связаться с менеджером для перераспределения ресурсов.
Резюме
gpt-image-2-vip — это коммерческий продукт для генерации изображений, построенный на базе реверс-инжиниринга официального канала Codex. Мы решили основные проблемы прямого подключения к официальному API с помощью 5 ключевых преимуществ: 30 вариантов размеров + единый тариф $0.03 + совместимость с тремя эндпоинтами + нативная поддержка китайского языка + отсутствие оплаты за неудачные запросы. Для команд, занимающихся созданием контента, подготовкой материалов для e-commerce, автоматизацией PPT и массовой генерацией постеров, это одно из самых выгодных решений для интеграции gpt-image-2 на текущий момент.
Для подключения достаточно изменить всего два параметра: base_url и model, при этом код SDK остается полностью совместимым с официальным форматом OpenAI. Для продакшн-среды мы рекомендуем установить таймаут на 300 секунд, использовать экспоненциальную задержку при ошибках 5xx и сохранять URL изображений на диск в течение 24 часов. Если вы учтете эти три нюанса, система будет работать стабильно под высокой нагрузкой. Если вы сейчас оцениваете варианты интеграции gpt-image-2, можете зайти на APIYI (apiyi.com), создать аккаунт и протестировать VIP-канал на реальных бизнес-задачах перед принятием окончательного решения.
Об авторе: Команда APIYI специализируется на агрегации мультимодальных моделей и инфраструктуре для высоконагруженного инференса. Мы ежедневно обрабатываем множество запросов по интеграции API для генерации изображений. Данная статья подготовлена на основе реальных производственных данных. Подробные параметры
gpt-image-2-vipможно найти на docs.apiyi.com.