
«Почему Claude Code каждый раз запрашивает 400 тысяч входных токенов? Откуда такие огромные счета?» — это первая реакция многих пользователей Claude Code, когда они заглядывают в статистику использования. На самом деле, большая часть этих 400 тысяч токенов, скорее всего, уже попала в кэш, и реальная стоимость может составлять лишь 1/10 от указанной цифры. Однако, если кэширование не срабатывает, счет действительно может неприятно удивить.
Ключевая ценность: Прочитав эту статью, вы поймете механизм автоматического кэширования Claude Code, 8 распространенных причин сбоя кэша и 6 практических советов, как сократить количество входных токенов с 400 тысяч до 50 тысяч.
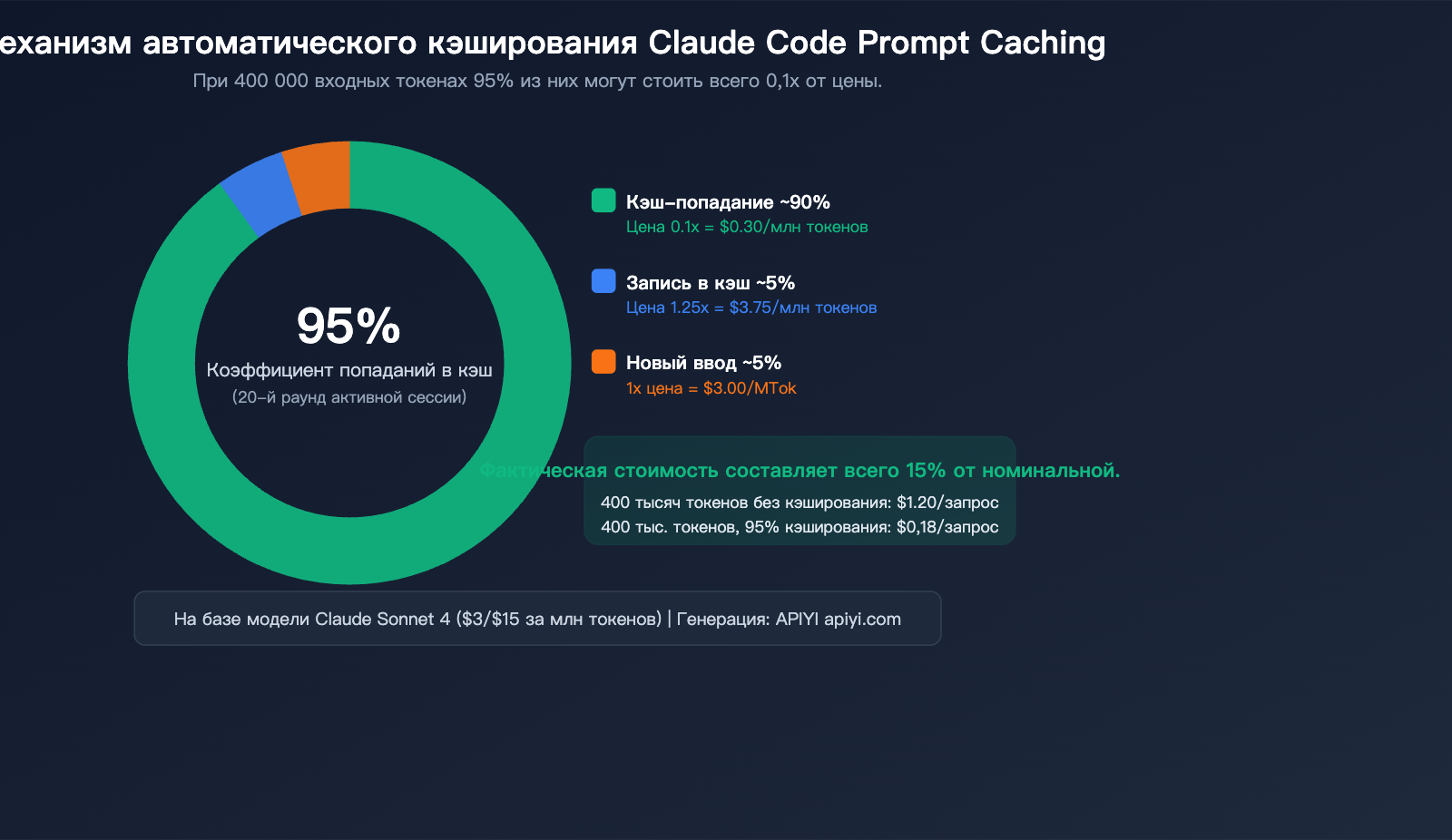
Подробный разбор механизма автоматического кэширования промптов в Claude Code
Автоматически ли Claude Code использует кэширование?
Да. Claude Code автоматически активирует функцию Prompt Caching от Anthropic для каждого API-запроса. Это встроенное поведение, которое работает «из коробки» и не требует дополнительных настроек.
Каждый раз, когда вы отправляете сообщение в Claude Code, содержимое запроса к API формируется в следующем порядке:
| Порядок сборки | Содержимое | Примерный объем | Поведение кэша |
|---|---|---|---|
| Уровень 1 | Определения инструментов (Read/Edit/Bash и т.д.) | ~5 000 токенов | Почти не меняется, высокая частота попаданий |
| Уровень 2 | Системный промпт + CLAUDE.md | ~3 000–10 000 токенов | Не меняется в рамках сессии, высокая частота попаданий |
| Уровень 3 | История диалога (все предыдущие сообщения) | Постоянно растет | Совпадение префикса, постепенное накопление кэша |
| Уровень 4 | Текущее новое сообщение | Переменное | Никогда не попадает в кэш |
Ключевой механизм: кэширование основано на совпадении префикса — если первые N токенов запроса полностью совпадают с тем, что уже находится в кэше, эти N токенов будут считаны из кэша. В ходе длительного диалога, начиная примерно с 20-й итерации, более 95% входных токенов обычно считываются из кэша.
Стоимость кэширования: почему попадания в кэш так важны
| Тип операции | Относительная цена | Цена Sonnet 3.5 (за млн токенов) | Цена Opus 3 (за млн токенов) |
|---|---|---|---|
| Обычный ввод (без кэша) | 1x | $3.00 | $15.00 |
| Запись в кэш (5 мин) | 1.25x | $3.75 | $18.75 |
| Запись в кэш (1 час) | 2x | $6.00 | $30.00 |
| Попадание/чтение из кэша | 0.1x | $0.30 | $1.50 |
| Вывод | — | $15.00 | $75.00 |
Конкретный пример: допустим, ваш запрос содержит 400 000 входных токенов:
Сценарий А: Без кэширования
├── 400 тыс. токенов × $3/млн (Sonnet) = $1.20 за запрос
Сценарий Б: 95% попаданий в кэш (типичная сессия Claude Code)
├── Чтение из кэша 380 тыс. токенов × $0.30/млн = $0.114
├── Запись в кэш 10 тыс. токенов × $3.75/млн = $0.0375
├── Новый ввод 10 тыс. токенов × $3/млн = $0.03
├── Итого = $0.18 за запрос
└── Реальная стоимость составляет лишь 15% от стоимости без кэша
🎯 Техническая заметка: сервис-прокси API APIYI (apiyi.com) также поддерживает механизм Prompt Caching. При попадании в кэш стоимость входных токенов снижается на 90%. Если ваш проект использует Claude через API, рекомендуем грамотно проектировать структуру промптов для максимальной эффективности кэширования.
TTL кэша: скрытое преимущество для пользователей Max
| Тарифный план | TTL кэша | Стоимость записи | Примечание |
|---|---|---|---|
| API (оплата по факту) | 5 минут | 1.25x | Если нет активности более 5 минут, кэш истекает |
| Pro / Team | 5 минут | 1.25x | Аналогично |
| Max 5x / 20x | 1 час | 2x | Запись дороже, но окно попадания в 12 раз больше |
Хотя для пользователей Max стоимость записи в кэш составляет 2x (против стандартных 1.25x), TTL в 1 час означает, что кэш сохранится, даже если вы отойдете выпить кофе. Для разработчиков, работающих с перерывами, эта разница очень ощутима.
Каждое попадание в кэш сбрасывает таймер TTL, поэтому пока вы активно работаете, кэш практически не будет истекать.
Почему кэш не попадает в цель? 8 частых причин и способы решения
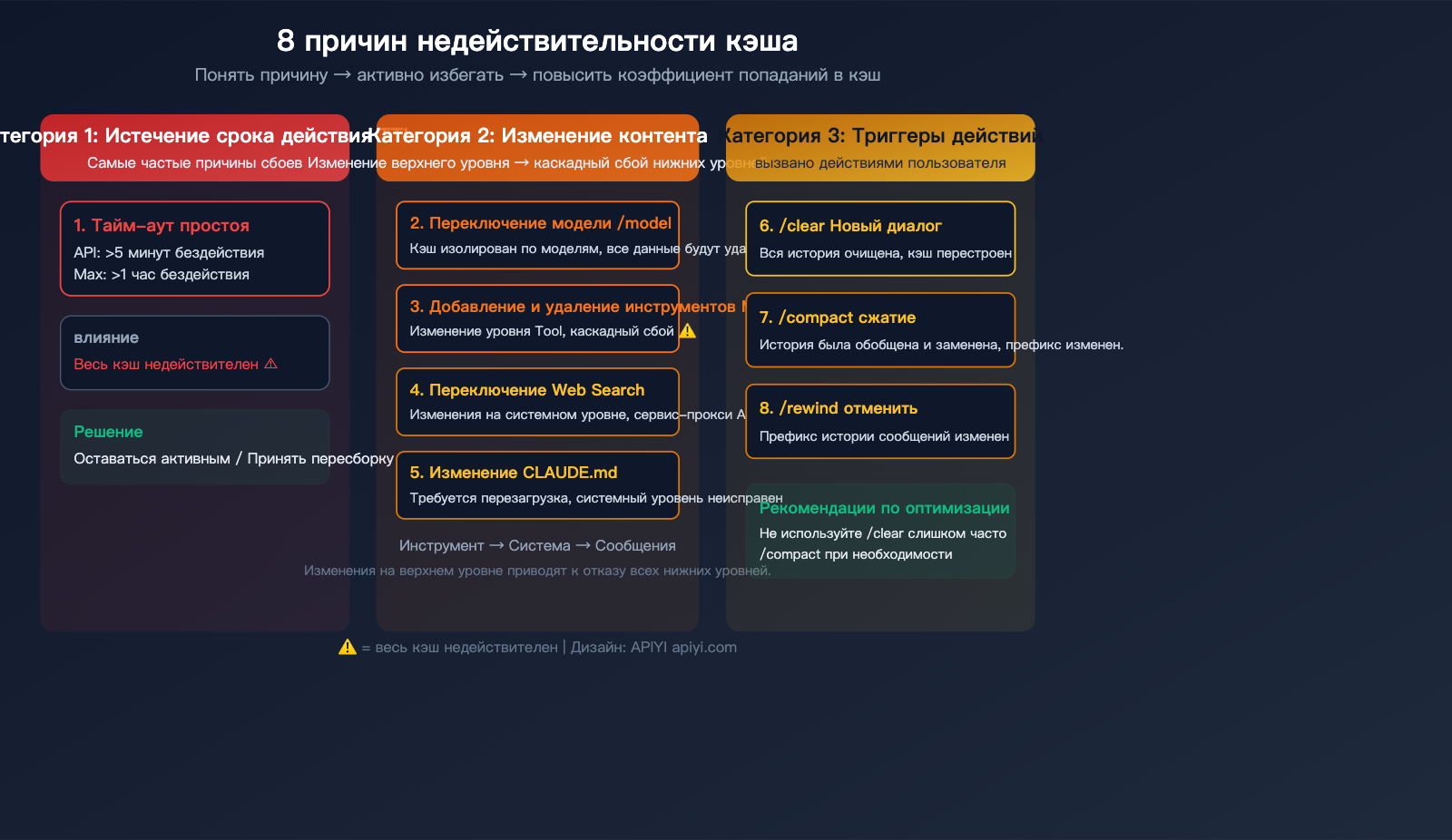
Основная причина сбоя кэширования одна: префикс запроса не совпадает с содержимым кэша. Если говорить о Claude Code, то вот 8 ситуаций, которые приводят к инвалидации кэша:
Категория 1: Истечение TTL
| Причина | Условие срабатывания | Область влияния | Решение |
|---|---|---|---|
| 1. Тайм-аут простоя | >5 мин бездействия для API, >1 часа для Max | Весь кэш сбрасывается | Поддерживать активность или смириться с пересборкой |
Это самая частая причина. Если вы отвлеклись от кодинга более чем на 5 минут (для пользователей API) или на 1 час (для пользователей Max), следующий запрос вызовет полную пересборку кэша.
Категория 2: Каскадный сбой из-за изменения контента
Кэш имеет строгую иерархическую структуру: определение инструментов (Tools) → системный промпт → история диалога. Изменения на верхнем уровне делают невалидным всё, что находится ниже.
| Причина | Условие срабатывания | Область влияния | Серьезность |
|---|---|---|---|
| 2. Смена модели | Команда /model |
Весь кэш (изолирован по моделям) | ⚠️ Высокая |
| 3. Добавление/удаление MCP | Установка или удаление MCP-сервера | Уровень инструментов + всё ниже | ⚠️ Высокая |
| 4. Переключение поиска | Включение/выключение веб-поиска | Системный уровень + всё ниже | ⚠️ Средняя |
| 5. Изменение CLAUDE.md | Редактирование конфига проекта и перезапуск | Системный уровень + всё ниже | ⚠️ Средняя |
Категория 3: Сбой из-за действий пользователя
| Причина | Условие срабатывания | Область влияния | Серьезность |
|---|---|---|---|
| 6. Новый диалог | Команда /clear или создание сессии |
Весь кэш (очистка истории) | ⚠️ Высокая |
| 7. Команда /compact | Принудительное сжатие истории | Кэш уровня истории диалога | ⚠️ Средняя |
| 8. Команда /rewind | Отмена предыдущих сообщений | Изменение префикса истории | ⚠️ Средняя |
Важное техническое ограничение: минимальный размер кэша
Если ваш промпт короче указанного ниже количества токенов, кэширование будет молча пропущено без каких-либо ошибок:
| Модель | Мин. длина для кэширования |
|---|---|
| Claude Opus 4.6 / Haiku 4.5 | 4 096 токенов |
| Claude Sonnet 4.6 | 2 048 токенов |
| Claude Sonnet 4.5 / 4 | 1 024 токена |
Для Claude Code это ограничение почти неактуально, так как определения инструментов и системный промпт уже занимают более 5 000 токенов. Однако, если вы создаете приложение через API самостоятельно, учитывайте этот порог.
💡 Совет: Если вы используете APIYI (apiyi.com) для вызова Claude API в своих проектах, убедитесь, что длина системного промпта превышает минимальный порог кэширования для выбранной модели, иначе кэш просто не заработает.
Почему вы видите 400 тысяч входных токенов: структура контекста Claude Code
Разобравшись с механизмом кэширования, давайте разложим по полочкам, из чего именно складываются те самые «400 тысяч входных токенов», которые так пугают при первом взгляде.
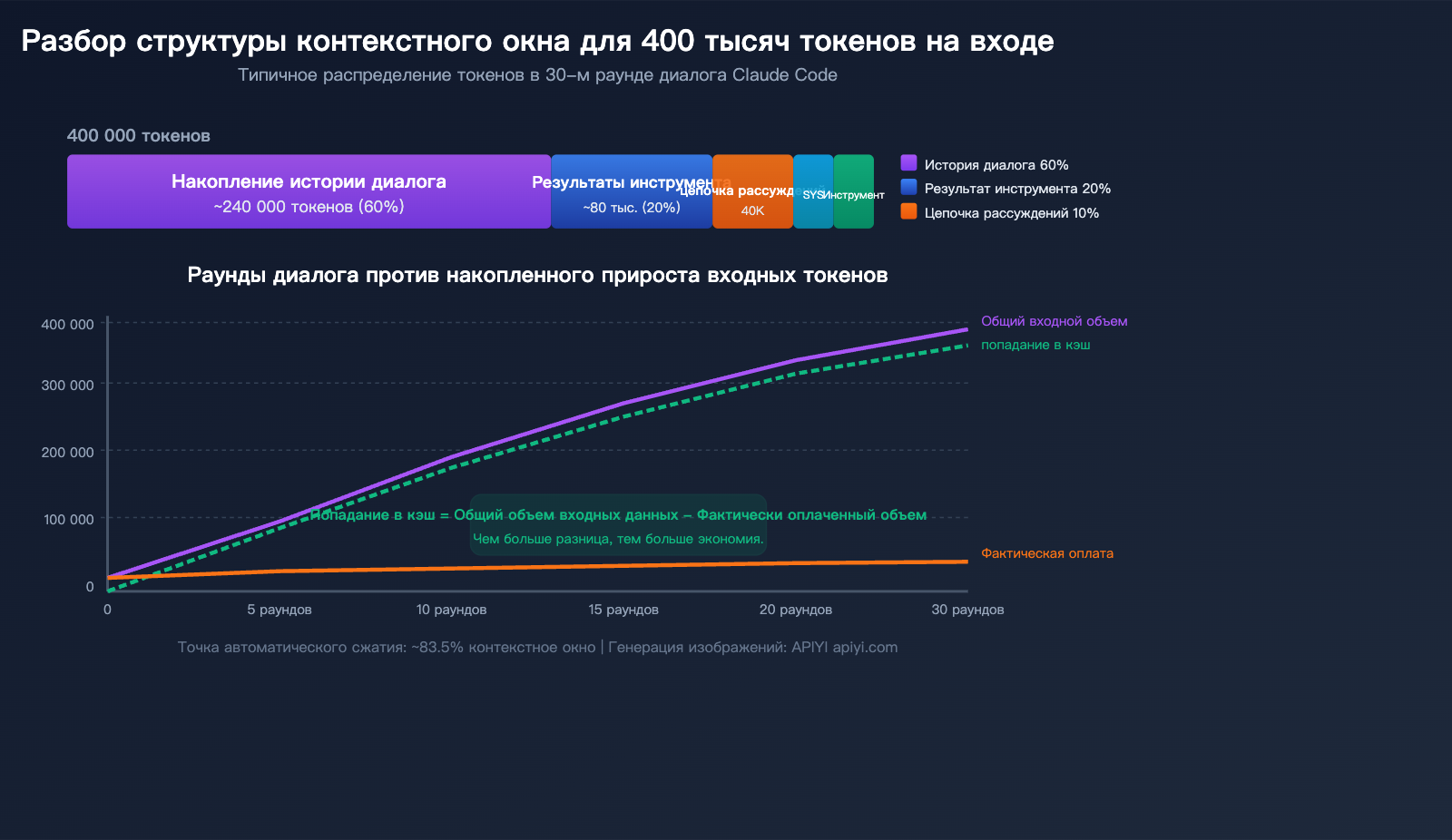
5 главных источников расхода токенов
| Источник | Доля | Примерно в 400к | Особенности |
|---|---|---|---|
| Накопленная история диалога | ~60% | ~240 тыс. | Полная история пересылается с каждым новым запросом |
| Результаты вызова инструментов | ~20% | ~80 тыс. | Результаты чтения файлов и grep-поиска остаются в контексте |
| Цепочка рассуждений (CoT) | ~10% | ~40 тыс. | Блоки thinking из предыдущих шагов становятся частью ввода |
| Системный промпт + CLAUDE.md | ~5% | ~20 тыс. | Передаются с каждым сообщением |
| Определения инструментов | ~5% | ~20 тыс. | Схема всех доступных инструментов |
Главная правда: чем длиннее диалог, тем больше входных данных
Claude Code работает по принципу повторной отправки всей истории диалога при каждом запросе. Это значит:
- 1-й раунд: ~20 тыс. токенов (системный промпт + определения инструментов + ваш вопрос).
- 5-й раунд: ~100 тыс. токенов (накопилась история за 4 раунда).
- 15-й раунд: ~250 тыс. токенов (включая результаты чтения множества файлов).
- 30-й раунд: ~400 тыс. токенов и более (приближаемся к порогу автоматического сжатия).
Но обратите внимание: подавляющее большинство этих токенов попадает в кэш. В 400 тысячах токенов на 30-м раунде лишь 10–20 тысяч могут быть новыми, некэшированными данными.
Специфика работы с большими кодовыми базами
Claude Code не загружает автоматически весь репозиторий в контекст. Он читает файлы по мере необходимости. Однако в крупных проектах:
- Один поиск
grepможет вернуть огромный объем данных, который целиком попадает в контекст. - Исследовательское чтение нескольких файлов приводит к тому, что содержимое каждого из них оседает в истории диалога.
- В режиме агента Claude выполняет многошаговые операции, и результаты каждого вызова инструментов накапливаются.
Если вы видите 400 тысяч токенов на каждом шаге, скорее всего, сложились следующие факторы:
- Кодовая база большая, и Claude Code прочитал много файлов для анализа.
- Слишком длинная история диалога.
- Вы не использовали команды
/compactили/clearдля очистки контекста. - Файл
CLAUDE.mdможет быть слишком объемным.
6 практических советов: как сократить входные токены с 400к до 50к
Совет 1: Точные инструкции вместо глобального сканирования
Это самый важный и простой в реализации способ оптимизации.
❌ Размытые инструкции (запускают сканирование всего проекта):
"Помоги мне оптимизировать производительность этого проекта"
"Проверь код на наличие багов"
"Рефактори этот модуль"
✅ Точные инструкции (читают только нужные файлы):
"Оптимизируй время отклика функции processRequest в src/api/handler.ts"
"Исправь исключение нулевого указателя на 45-й строке в src/auth/login.ts"
"Перенеси функцию formatDate из moment на dayjs в src/utils/format.ts"
Размытые команды заставляют Claude Code использовать Glob + Grep + Read для «понимания» вашего запроса, из-за чего содержимое множества файлов навсегда оседает в истории диалога. Точные инструкции позволяют модели прочитать лишь 1–2 релевантных файла.
Экономия токенов: сокращение использования токенов на вызов инструментов на 60–80%.
Совет 2: Своевременное использование /clear и /compact
# Очистка диалога при переключении на другую задачу
/clear
# Сжатие истории, если диалог длинный, а задача еще не завершена
/compact
# Сжатие с инструкцией для сохранения важного
/compact сохрани примеры кода и определения API-интерфейсов, остальное можно сократить
| Команда | Эффект | Когда использовать | Примечание |
|---|---|---|---|
/clear |
Полная очистка истории | При смене задачи | Весь кэш сбрасывается |
/compact |
ИИ суммирует историю, заменяя оригинал | В середине долгого диалога | Часть кэша сбрасывается, но контекст сильно уменьшается |
Реальный результат: диалог на 400 000 токенов после /compact обычно сжимается до 50–80 000 токенов.
Совет 3: Оптимизация файла CLAUDE.md
Файл CLAUDE.md загружается в каждое сообщение. CLAUDE.md объемом 10 000 токенов будет отправлен 30 раз за 30 итераций диалога (хотя при попадании в кэш вы платите только 0.1x, он все равно занимает драгоценное место в контекстном окне).
Рекомендации по оптимизации:
├── Держите CLAUDE.md в пределах 500 строк (только основные правила)
├── Перенесите подробные инструкции по рабочим процессам в Skills (загрузка по запросу)
├── Справочную документацию храните в knowledge-base/ (читайте при необходимости)
└── Избегайте больших блоков примеров кода в CLAUDE.md
🚀 Совет: Сокращение CLAUDE.md не только экономит токены,
но и помогает Claude Code лучше фокусироваться на главных правилах.
Если вы используете APIYI (apiyi.com) для создания подобных AI-ассистентов,
также рекомендуем следить за длиной системного промпта.
Совет 4: Используйте Subagent для изоляции объемного вывода
Когда нужно выполнить операцию, генерирующую много данных, используйте Subagent вместо прямого выполнения:
❌ Прямое выполнение в основном диалоге (весь вывод попадает в контекст):
"Запусти тесты и проанализируй причины падений"
→ Вывод тестов может занимать 50 000+ токенов, которые останутся в истории
✅ Использование Subagent (вывод изолирован в дочернем процессе):
"Запусти тесты в подзадаче и верни мне только названия упавших тестов и причины"
→ В основной контекст добавится лишь ~500 токенов с кратким отчетом
Экономия токенов: одна такая операция может сэкономить от 10 000 до 50 000 токенов в основном контексте.
Совет 5: Выбор подходящей модели и уровня effort
| Тип задачи | Рекомендуемая модель | Уровень effort | Пояснение |
|---|---|---|---|
| Простые правки/форматирование | Sonnet | low | Глубокие размышления не нужны |
| Обычная разработка | Sonnet | medium | Лучшее соотношение цены и качества |
| Сложная архитектура | Opus | high | Требует глубоких рассуждений |
| Code Review | Sonnet | medium | Эффективнее, чем Opus |
# Снижение глубины размышлений для уменьшения thinking-токенов
/effort low
# Или ограничение через переменную окружения
MAX_THINKING_TOKENS=8000
Цепочка рассуждений (thinking) в последующих итерациях становится частью входных токенов. Снижение уровня effort значительно уменьшает накопление токенов в будущем.
Совет 6: Мониторинг распределения токенов через /context
# Просмотр текущего распределения токенов
/context
Команда /context покажет, какая часть контекста потребляет больше всего токенов. Что обычно обнаруживается:
- Результат grep-поиска занял 20 000 токенов, хотя полезными были лишь 5%.
- Большой файл, прочитанный ранее, больше не нужен, но все еще висит в контексте.
- CLAUDE.md занимает неоправданно много места.
Обнаружив проблему, используйте /compact или /clear для точечной очистки.
💰 Совет по затратам: Для пользователей с оплатой API по факту использования эти советы помогут существенно снизить счета.
Статистика на платформе APIYI (apiyi.com) позволяет наглядно видеть распределение токенов в каждом запросе,
помогая выявлять «горячие точки» расходов.
Практический кейс: как снизить расходы с $60 до $8 в день
Вот реальный пример процесса оптимизации:
До оптимизации (крупный Python-проект, активный пользователь Claude Code)
Ежедневное использование:
├── Количество диалогов: ~50 в день
├── Средний объем входящих токенов: 350-450 тыс./диалог
├── Коэффициент попадания в кэш: ~70% (из-за частых /clear и переключения моделей)
├── Ежедневные расходы на API (Opus 3.5): ~$60
└── Ежемесячные расходы: ~$1,320
После оптимизации (применили 6 приемов)
Ежедневное использование:
├── Количество диалогов: ~40 в день (более точные запросы, меньше лишних итераций)
├── Средний объем входящих токенов: 80-120 тыс./диалог (точные промпты + регулярный compact)
├── Коэффициент попадания в кэш: ~92% (минимум лишних прерываний кэширования)
├── Ежедневные расходы на API (в основном Sonnet 3.5, Opus только для сложных задач): ~$8
└── Ежемесячные расходы: ~$176
| Оптимизация | Экономия | Комментарий |
|---|---|---|
| Точные промпты вместо размытых задач | ~35% | Самый эффективный метод |
| Регулярные /compact и /clear | ~25% | Контроль раздувания контекста |
| Sonnet вместо Opus (80% задач) | ~20% | Разница в качестве незаметна |
| Оптимизация CLAUDE.md | ~8% | Снижение фиксированных затрат на запрос |
| Изоляция длинных выводов через Subagent | ~7% | Чтобы не засорять контекст |
| Снижение уровня effort | ~5% | Уменьшение накопления токенов размышлений |
Часто задаваемые вопросы
Q1: Если Claude Code показывает 400 тыс. токенов, списывают ли за все 400 тыс.?
Нет. Claude Code автоматически использует Prompt Caching. В активной сессии более 95% входящих токенов обычно попадают в кэш, что стоит всего 0.1x от базовой цены. Из 400 тыс. токенов по полной цене могут тарифицироваться только 20-40 тыс. Вы можете проверить реальный коэффициент кэширования через команду /context. При использовании API через сервис-прокси APIYI (apiyi.com) механизм кэширования также полностью поддерживается.
Q2: Нужно ли следить за расходом токенов, если у меня подписка Max?
Да, но по другой причине. Подписка Max не тарифицирует токены напрямую, но имеет еженедельный лимит использования. Чрезмерное потребление токенов приведет к тому, что вы быстрее упретесь в этот лимит. Лаконичный контекст не только продлевает время работы, но и помогает Claude Code точнее понимать ваши задачи (чем точнее контекст, тем лучше ответ).
Q3: Что лучше: /compact или /clear?
Зависит от ситуации. Если вы начинаете совершенно новую задачу, лучше использовать /clear для полной очистки. Если вы продолжаете ту же задачу, но диалог стал слишком длинным, используйте /compact, чтобы сжать объем, сохранив ключевой контекст. /compact поддерживает кастомные инструкции, например: /compact сохранить историю изменений кода и определения API.
Q4: Оптимизирует ли обновление Claude Code расход токенов автоматически?
Да, рекомендую всегда использовать последнюю версию. Anthropic постоянно улучшает стратегии управления контекстом в Claude Code, включая автоматическое сжатие (сейчас срабатывает при заполнении контекста примерно на 83.5%) и отложенную загрузку определений инструментов MCP (загружаются только имена, полная схема подтягивается по мере необходимости). Новые версии обычно обеспечивают лучший кэш-рейт и более умное управление контекстом.

Итог: понимание кэширования + точное использование = контроль над расходами
Функция Prompt Caching в Claude Code — это мощный механизм автоматической оптимизации. Вам не нужно ничего настраивать, она уже экономит ваши деньги. Но если вы поймете, как она работает и при каких условиях кэш сбрасывается, вы сможете повысить эффективность экономии с «автоматических 70%» до «осознанных 95%».
Запомните эти 3 главных принципа:
- Поддерживайте активность кэша: избегайте лишних действий, которые могут его сбросить (частая смена моделей, бездумное использование
/clear). - Контролируйте раздувание контекста: используйте точные промпты + регулярную команду
/compact, чтобы история диалога не росла бесконечно. - Выбирайте правильные инструменты и модели: для 80% задач вполне достаточно Sonnet, а Opus оставьте для действительно сложных сценариев.
Пользователям, оплачивающим API по факту использования, рекомендуем централизованно управлять вызовами Claude API через сервис-прокси API APIYI (apiyi.com). Используйте встроенные инструменты мониторинга платформы, чтобы постоянно оптимизировать расход токенов. Активным пользователям интерактивных инструментов советуем сразу переходить на подписку Claude Max — в сочетании с советами из этой статьи это даст наилучшее соотношение цены и качества.
📝 Автор статьи: Техническая команда APIYI | APIYI — единая платформа для доступа к API 300+ больших языковых моделей.
Справочные материалы
-
Документация Anthropic по Prompt Caching: подробный разбор механизма кэширования.
- Ссылка:
docs.anthropic.com/en/docs/build-with-claude/prompt-caching - Описание: TTL кэша, коэффициенты ценообразования и требования к минимальной длине.
- Ссылка:
-
Руководство по управлению расходами в Claude Code: официальные рекомендации по оптимизации токенов.
- Ссылка:
code.claude.com/docs/en/costs - Описание: стратегии контроля затрат, рекомендованные Anthropic.
- Ссылка:
-
Лучшие практики Claude Code: управление контекстом и оптимизация эффективности.
- Ссылка:
anthropic.com/engineering/claude-code-best-practices - Описание: практические советы, включая использование точных промптов и команды compact.
- Ссылка: